











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
La modelación de ecuaciones estructurales (SEM) es una metodología estadística que toma un enfoque confirmatorio para el análisis de una teoría estructural relacionada con algún fenómeno (Byrne, 2010). En esta modelación SEM, existen dos técnicas en las ciencias sociales: 1) la basada en la covarianza (CB-SEM), que significa covariance-based structural equation modeling (modelación de ecuaciones estructurales basadas en la covarianza), y 2) la basada en la varianza partial least squares (PLS-SEM). La modelación CB-SEM se usa fundamentalmente para confirmar o rechazar teorías. Es una técnica paramétrica en la que se tendrán que cumplir ciertos supuestos estadísticos para su aplicación, como la normalidad de los datos, el tamaño de muestra, entre otros. En cambio, la PLS-SEM es una técnica no paramétrica, enfocada en primera instancia en la predicción, aunque Henseler (2018) argumenta que puede ser utilizada para todos los tipos de investigación (confirmatoria, explicativa, exploratoria, descriptiva y predictiva).
En este contexto de ecuaciones estructurales, el presente artículo se sustenta en la metodología CB-SEM para explicar el análisis factorial confirmatorio. Este enfoque paramétrico se conforma por dos tipos de modelos: 1) el modelo de medida y 2) el modelo estructural. Por lo tanto, el análisis factorial confirmatorio (AFC) es un modelo multivariante en el análisis de estructuras de covarianza (CB-SEM), el cual tiene como objetivo contrastar un modelo de medida a través de datos empíricos provenientes de una muestra, que teóricamente refleje las características de la población objeto de estudio, cuyo punto de partida es la construcción de un modelo sustentado en la teoría y en el análisis factorial exploratorio (AFE).
En la práctica, podemos encontrar AFC de primer, segundo o más niveles, según sea el objetivo de la investigación. El AFC de primer nivel muestra variables exógenas y la covarianza entre ellas, mientras que el AFC de segundo nivel constituye una extensión del primer nivel, en donde se incorpora un nuevo constructo latente que es especificado por los factores de primer nivel, cuyo objetivo es definir las variables del modelo y la relación existente entre ellas. De esta manera, la diferencia entre ambos consiste en que las correlaciones entre los factores son sustituidas por saturaciones de esos mismos factores en la nueva variable exógena de orden superior que agrupa los constructos de primer nivel.
Las Figuras 1, 2, 3 y 4 muestran modelos de medida de primer y segundo orden o nivel superior, así como modelos de análisis causal donde se puede aplicar el AFC.

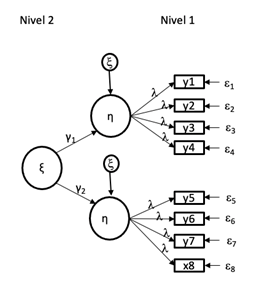


Por lo tanto, el análisis factorial confirmatorio estima el modelo de medición con la finalidad de conseguir la fiabilidad y validez del modelo para posteriormente estimar el modelo estructural, que corresponde al modelo de investigación. El AFC se compone, por lo general, de seis fases: 1) especificación del modelo, 2) identificación, 3) estimación de parámetros, 4) ajustes del modelo, 5) interpretación y 6) reespecificación, aspectos que deben tener como base la teoría y el análisis factorial exploratorio (Lévy y Varela, 2006).
El análisis factorial exploratorio (AFE) es una técnica estadística que permite explorar un conjunto de variables observables (ítems) a través de un número reducido de factores que muestran las correlaciones entre el conjunto de variables observadas. En el conjunto de datos de variables se buscan aquellas que están muy relacionadas (o correlacionadas) y se agrupan para formar una nueva dimensión. En primera instancia, esta técnica -al analizar las relaciones entre los ítems- permite determinar si tiene sentido efectuar el análisis. Si las variables no estuvieran asociadas linealmente, las correlaciones entre ellas serían nulas y, por consiguiente, sería una matriz identidad que impide la realización del análisis (Ferrán, 2001). Además, es recomendable cumplir con el principio de parsimonia e interpretabilidad, donde los fenómenos se deben explicar con el menor número de elementos posibles para ser susceptibles de interpretación sustantiva (Martin, Cabero y De Paz, 2008).
El procedimiento del AFE permite agrupar los ítems de acuerdo con la correlación hacia un factor. Existen varios estadísticos descriptivos que analizan la matriz de correlaciones, entre los más usuales el test de esfericidad de Barlett, que se emplea para someter a comprobación la hipótesis nula de que la matriz de correlación es cero; mientras que el índice KMO de Kaiser-Meyer-Oklin mide la magnitud de los coeficientes de correlación dentro del parámetro de 0 a 1.
Por su parte, Garza, Morales y González (2013) consideran que valores de KMO de .90 en adelante son excelentes, de .80 a .90 buenos, de .70 a .80 aceptables, .60 a .70 regulares, de .50 a .60 bajos, y menores de .50 inaceptables. Es importante analizar cada variable mediante la diagonal de dicha matriz. Los valores deberán ser ≥ .5; en caso de ser menores, la variable deberá de ser eliminada del análisis y proceder a un nuevo proceso ( Garza et al., 2013).
En cuanto al método de extracción de factores, existen diversos, aunque los más usados en paquetes de programas estadísticos son los componentes principales (PC) y el de máxima verosimilitud (ML). En este caso, se usó el de PC, que extrae factores basados en autovalores mayores que 1 y determina la varianza explicada. Asimismo, para que este alcance un nivel satisfactorio es recomendable que sea de 75 % u 80 % (Martin et al., 2008). En lo que respecta a las rotaciones factoriales que indican la relación entre los factores y las variables, es recomendable utilizar el método Varimax, que minimiza el número de variables que tienen saturaciones altas en cada factor para una interpretación; aquí se analiza la carga del factor que permite ver la relación de las variables con cada factor (Martin et al., 2008).
En lo que respecta a la escala de medición, debe contener principalmente asimetría y equidistancia. Además, debe estar sustentada por la teoría subyacente al problema, y la muestra debe cumplir con los requisitos paramétricos en cuanto al tamaño. Las Figuras 5 y 6 enseñan la diferencia entre un modelo factorial exploratorio y un confirmatorio.
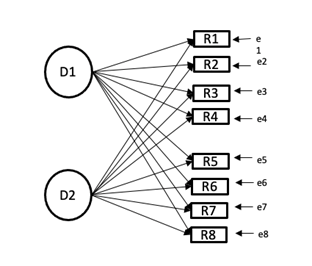

En estas figuras se observa que existen ciertas diferencias en su estructura; en primer lugar, el AFE hace una búsqueda de relaciones de correlación donde el científico tiene que evaluar en cuál factor o dimensión se tiene mayor o menor carga factorial para determinar a qué dimensión corresponde cada reactivo. Esto necesariamente tiene que evaluarse con la revisión de la literatura, lo que respalda a los reactivos con sus dimensiones correspondientes para que, si es necesario, el investigador haga los ajustes respectivos, ya que un ítem pude cargar en ambos factores.
Por otra parte, Jöreskog (1969) desarrolló el procedimiento confirmatorio donde establece que la principal diferencia conceptual en ambas estructuras es que en el AFC se puede comprobar la hipótesis acerca de la estructura factorial de una serie de variables; además, el investigador especifica el número de factores en el modelo teórico para contrastar los datos.
Es importante considerar algunos supuestos estadísticos para el uso de esta técnica paramétrica, como la normalidad de los datos, el número de indicadores y el tamaño de la muestra. En cuanto al tamaño de la muestra, se consideran alrededor de 200 sujetos cuando existan al menos tres indicadores por variables latentes (Anderson y Gerbing, 1984).
Con base en esta argumentación teórica y supuestos estadísticos, la finalidad de la presente investigación es dar a conocer el uso de la técnica estadística del análisis factorial confirmatorio (AFC) a partir de datos empíricos recabados en el año 2020 de gestión del conocimiento. No se probó ninguna relación estadística o prueba de hipótesis: únicamente se aborda la aplicación de la técnica del análisis factorial confirmatorio para estimar el modelo de medición y conseguir la fiabilidad y validez.
En síntesis, este documento posee la siguiente estructura: primero se ofrece la perspectiva teórica para describir las variables objeto de estudio; segundo, el método de trabajo; tercero, el procedimiento de análisis de datos; cuarto, la fiabilidad y validez de modelo, y en el último apartado se presenta la discusión de los hallazgos.
Fundamentación teórica
La teoría basada en los recursos
La presente investigación se centra en la teoría de recursos (Barney, 1991; Wernerfelt, 1984) y en la visión basada en el conocimiento (Grant, 1996). La teoría de recursos es ampliamente reconocida como una de las más prominentes y poderosas para describir, explicar y predecir las relaciones en la organización (Barney, 2011 et al..). Esta postula que la fuente de una ventaja competitiva proviene de sus recursos internos, ya sean tangibles e intangibles. Uno de los rasgos más importantes de los recursos es que deben ser heterogéneos, raros, inimitables, valiosos y no sustituibles (Barney 1991, 2001; Wernerfelt, 1984). Por lo tanto, el conocimiento es un recurso intangible valioso y estratégico que aporta la contribución más importante para las organizaciones. Esto significa que el éxito depende de la capacidad de la organización para crear y desarrollar sus activos basados en el conocimiento como recurso clave para el crecimiento, la innovación, el desempeño y la ventaja competitiva sostenible de las empresa (Nawab, Nazir, Mohsin y Muhammad, 2015; Yusof y Bakar, 2012; Salajarvi, Sveiby y Furu, 2005; Hill, Nancarrow y Wright, 2002; Teece, 2000).
Por su parte, Krstić y Petrović (2011) argumentan que la gestión del conocimiento es un proceso mediante el cual una organización genera valor en un entorno contemporáneo dinámico de cambios tecnológicos a través de la explotación eficaz y eficiente del saber como recurso clave de la economía del conocimiento. En un mundo donde las tecnologías, los mercados, los productos, los competidores e incluso la sociedad cambian muy rápidamente, el conocimiento se ha trasformado en un activo invaluable para que las organizaciones mantengan una ventaja competitiva sostenible (Nonaka, Toyama y Byosiere, 2001). Por ende, Quinn (1992) subraya que la ventaja competitiva de una empresa depende cada vez más de los intangibles basados en el conocimiento.
Asimismo, diversos autores argumentan que la gestión del conocimiento representará el factor más significativo de ventaja competitiva para las organizaciones (Drucker, 1993; Quinn, 1992; Toffler, 1990). Por lo tanto, el desarrollo y la práctica de gestión del conocimiento están continuamente incrementándose en las organizaciones (Halawi, Aronson y McCarthy, 2005). Así, la gestión del conocimiento ha sido aplicada a actividades diseñadas para administrar e intercambiar, crear y mejorar los activos intelectuales de la organización (Haggie y Kinston, 2003). En este contexto, Zaman, Mahtab y Raxa (2014) enfatizan que la gestión del conocimiento es una combinación de aptitudes y competencias básicas tanto en la información como en la gestión de los recursos humanos, y que se reconoce cada vez más como un activo clave de la organización, puesto que genera riqueza de sus recursos intelectuales basados en el conocimiento.
Por su parte Nonaka y Takeuchi (1995) proponen dos tipos de conocimientos: el explícito y el tácito. El primero puede ser escrito, codificado, archivado y procesado por los sistemas de información de la organización, mientras que el conocimiento tácito es el que poseen las personas y se almacena en su cerebro, de ahí que sea considerado como activo intangible. El AFC de esta investigación se sustenta en el modelo SECI de Nonaka y Takeuchi (1995), que a continuación se describe.
Proceso de creación del conocimiento
Nonaka (2008) enfatiza que la teoría dinámica de creación de conocimiento organizacional considera que el saber es creado a través de una interacción entre el conocimiento tácito y el explícito, lo cual es representado mediante una espiral de dos dimensiones: 1) una epistemológica que fundamenta el conocimiento explícito y el conocimiento tácito, y 2) una ontológica que contempla los niveles de conocimiento (individual, grupal, organizacional e interorganizacional) a través de los cuatro modos de conversión del conocimiento: 1) socialización; 2) externalización; 3) combinación, y 4) internalización.
En este sentido, Nonaka, Toyama y Byosiere (2001) describen los cuatro modos de conversión o creación del conocimiento: la socialización es el proceso de adquirir conocimientos tácitos a través de experiencias compartidas, ya que es específico del contexto y difícil de formalizar. La clave para adquirir conocimiento tácito es comúnmente mediante el compartir de actividades; por ejemplo, en ciertas ocasiones las personas aprenden su arte no mediante la lectura, sino a través de la observación minuciosa del proceder de su maestro y con la práctica.
La externalización es el proceso de articular el conocimiento tácito como conocimiento explícito. Este modo de conversión transfiere lo explícito a tácito. Cuando el conocimiento tácito se hace explícito, el conocimiento se ha concretado, momento en el que puede ser compartido por otros y puede transformarse en el básico para el nuevo conocimiento. La externalización se produce, por ejemplo, cuando un equipo de investigación y desarrollo (R y D) intenta aclarar el concepto de un producto nuevo.
La combinación es la forma de conexión de conocimiento explícito en un conjunto de conocimiento explícito que es intercambiado por medios como documentos, reuniones, conversaciones y redes de comunicación computarizada.
Finalmente, la internalización es el proceso de incorporar conocimiento explícito como tácito, de ahí que se relacione con el aprender haciendo. Mediante la internalización, el conocimiento creado es compartido a través de la organización, por lo que se utiliza para ampliar, extender y replantear los dos tipos de conocimiento existentes en la institución.
Método de trabajo
Enfoque y diseño de investigación
El diseño de la investigación fue no experimental y transversal. Se utilizó la modelación (SEM-CB), cuya finalidad es evaluar múltiples relaciones simultáneas para efectuar, en este caso, el análisis factorial confirmatorio (Hair, Anderson, Tatham y Black, 2008; Lévy y Varela, 2006). Este análisis de estructuras de covarianzas ofrece la posibilidad de examinar un conjunto de relaciones de dependencia simultáneas entre múltiples variables.
Esta técnica es principalmente empleada para contrastar teorías (cuando se pone a prueba un modelo teórico). Un análisis completo de la técnica implica la evaluación de dos modelos: el de medida y el estructural. En este caso, únicamente se analizó el modelo de medida, el cual refleja las relaciones entre las variables observadas y las latentes, lo que especifica cuáles indicadores definen cada constructo.
Muestra
Para cumplir el objetivo de explicar el uso del análisis factorial confirmatorio, los datos considerados fueron 225 empleados y directivos que corresponden a organismos de la Universidad Autónoma del Estado de México, para lo que se efectuó un muestreo por conveniencia debido a la facilidad para obtener la información. Las características de la muestra fueron las siguientes: 55 % mujeres y 45 % hombres, la mayoría con edades que oscilaban entre los 40 y los 49 años.
Medición de variables
En esta investigación, se construyó un instrumento para medir el proceso de gestión del conocimiento a partir de la base teórica de diversos autores (Choi y Heeseok, 2002; Choi y Lee, 2002; Nonaka y Takeuchi, 1995; Nonaka, Toyama y Konno; 2000; Nonaka, Toyama y Byosiere 2001). Esto permitió medir los cuatro modos de conversión o creación de conocimiento (socialización, externalización, combinación e internalización). La medición fue en escala Likert (1 = totalmente en desacuerdo y 5 totalmente de acuerdo).
Variación del método común
El método común vías es un aspecto importante que se debe de tomar en cuenta en la construcción de escalas de medida. Este refiere a la medida en que la varianza entre las correlaciones deriva del método de medición, y no a los constructos que se miden. Al respecto, Podsakoff, MacKenzie, Lee y Podsakoff (2003) sugieren varios remedios estadísticos para evitar el sesgo del método común, los cuales fueron revisados.
Procedimiento de análisis de datos
Para evaluar si los constructos fueron evaluados correctamente, en primer lugar, se efectuó el análisis factorial exploratorio y, posteriormente, el análisis factorial confirmatorio.
Análisis factorial exploratorio
En este tipo de análisis se determinó el índice de adecuación muestral Kaiser-Meyer-Oklin (KMO), cuyo valor fue de KMO = .897. Al respecto, cabe señalar que su parámetro de validez es de 0 a 1 (cuanto más cerca de 1 la correlación es más fuerte). En relación con la prueba de esfericidad de Bartlett, requiere que el resultado sea significativo. En lo que respecta a las cargas, se recomienda que sean superiores a 0.05 (Castañeda, Cabrera, Navarro y DeVries, 2010). Al final, se determinó la varianza explicada de 78.56 %.
Fiabilidad de la escala
Se analizó la escala por medio de un análisis de fiabilidad para determinar el alfa de Cronbach. Se reportó que la socialización presentó una fiabilidad de 0.85; la externalización 0.82; la combinación 0.89, y la internalización 0.86. La fiabilidad compuesta es una medida de la consistencia interna de los indicadores del constructo, y debe ser calculada para cada constructo. Su umbral recomendable debe ser igual o superior a 0.70; cuando el valor es menor, puede ser aceptado si la investigación tiene carácter exploratorio (Hair, Anderson, Tatham y Black, 2007).
Análisis factorial confirmatorio
Una vez que el análisis factorial exploratorio presentó índices adecuados, se procedió a realizar el análisis factorial confirmatorio (CFA) para confirmar la fiabilidad y validez del modelo de los cuatro modos de conversión o creación del conocimiento. En este sentido, el AFC también permitió probar si las medidas eran consistentes con la teoría. Por lo tanto, para este análisis se utilizó un programa estadístico de ecuaciones estructurales (AMOS). En primer lugar, se estimó el modelo de medida, y se examinaron los coeficientes estandarizados (cargas factoriales λ) para identificar la varianza de cada indicador que explicó el constructo. Todas las cargas factoriales estandarizadas excedieron .70, y la varianza promedio extraída (AVE) excedió .50. Estos resultados muestran fiabilidad y validez convergente.
En cuanto a la validez discriminante, la Tabla 1 muestra que el AVE es mayor que las correlaciones, lo que permite inferir que existe validez discriminante (Fornell y Larcker, 1981; Nunnally, 1978).
Tabla 1 Fiabilidad de constructo y validez convergente
| Constructo | Fiabilidad | AVE |
| S | 0.95 | 0.83 |
| E | 0.90 | 0.82 |
| C | 0.90 | 0.75 |
| I | 0.86 | 0.77 |
Fuente: Elaboración propia
En primera instancia, se revisó la multicolinealidad según los datos de la Figura 7. Como se observa, las variables socialización y combinación presentan la mayor covarianza de .39, lo cual no es un problema representativo de multicolinealidad. No obstante, también se llevó a cabo un análisis de colinelidad para evaluar la multicolinealidad, en donde se analizó el factor de inflación de la varianza (FIV), la tolerancia y el índice de condición. Se reportó lo siguiente: FIV = 2.9, tolerancia 0.84 y IC = 11.23, lo que indica que no existen problemas de colinealidad, ya que un FIV > 3.3, tolerancia abajo de 0.20 y IC > 30 presentan problemas de colinealidad (Belsley, 1991; Diamantopoulos y Siguaw, 2006).

La fiabilidad por medio del AFC se calculó tomando como base las cargas y el AVE de los indicadores del constructo, que se muestran en la Figura 7. A continuación, se presenta un ejemplo del cálculo de un constructo, donde se resta 1 de cada varianza (1-.80 = 0.20; 1-.83 = 0.17; 1-.64 = 0.36).
Igualmente, se ofrece un ejemplo de la determinación del AVE. La cantidad total de varianza de los indicadores tenida en cuenta por cada uno de los constructos latentes. Una manera es utilizar una fórmula establecida o determinar el promedio por constructo. Para muestra se ilustra el siguiente ejemplo C = 0.80 + 0.83 + 0. 64/3 = 0.75
Como se puede observar en la Tabla 1, la fiabilidad de todos los constructos supera el umbral establecido de 0.75, mientras que la varianza media extraída siempre debe ser superior a 50 % (Lévi y Varela, 2006). Por lo tanto, estos resultados muestran la idoneidad de los indicadores para la explicación empírica de los constructos latentes.
Tabla 2 Fiabilidad y validez (convergente y discriminante)
| Variable | Fiabilidad | Socialización | Externalización | Combinación | Internalización |
| Socialización | 0.812 | (0.83) | |||
| Externalización | 0.901 | 0.285 | (0.82) | ||
| Combinación | 0.876 | 0.377 | 0.555 | (0.75) | |
| Internalización | 0.921 | 0.395 | 0.379 | 0.356 | (0.77) |
Nota: Los valores mostrados entre paréntesis son la varianza media extraída (AVE), que implica la validez convergente.
Fuente: Elaboración propia
Evaluación del ajuste del modelo de media
Para verificar si los datos se ajustan al modelo, se analizaron los índices de bondad de ajuste a través de tres tipologías de ajuste global (Bollen, 1989; Hair, Anderson, Tatham y Black, 2007; Lévy y Varela, 2006; Marsh y Hocevar, 1985; Mohamad y Wan, 2013; Tanaka y Huba 1989):
Índices de ajuste absoluto. Establecen en qué medida el modelo predice a partir de los parámetros estimados la matriz de covarianza observada; donde se evalúa el índice de chi-cuadrado (Chi Squared, χ2) que analiza la hipótesis nula de que un modelo es no significativo; es decir, indica la significatividad de las diferencias de las matrices de covarianza o correlaciones, cuyo valor recomendable es χ2/df < 5 (Ghorbanhosseini, 2013). Sin embargo, existen críticas en contra de este estadístico en relación con el tamaño de muestra (Bagozzi, 1994. Para resolver ese problema de chi-cuadrado al tamaño muestral se proponen otras medidas de ajuste, como el índice de la raíz cuadrada media del error de la aproximación (Root Mean Squaree Error of Approximation, RMSEA), que considera un valor menor a 0.05 como buen ajuste (Kline, 2011; Levy y Varela, 2006); aunque otros autores consideran valores ≤ 0.08, que representan un error aceptable de aproximación a la población (Ghorbanhosseini, 2013), y el índice de bondad de ajuste (Goodness of Fit Index, GFI), cuyo valor está comprendido entre 0 y 1, indicando este último un ajuste del modelo perfecto; sin embargo, un ajuste aceptable es 0.90 (Jöreskog y Sörbom, 1984).
Índices de ajuste incremental. Comparan el ajuste global del modelo analizado con otro nulo (modelo especificado con ninguna relación entre las variables). Las medidas de ajuste incremental más utilizadas son el índice de ajuste normalizado (Normalized Fit Índex, NFI), que mide la reducción proporcional en la función de ajuste adecuado cuando pasamos del modelo nulo al propuesto; el índice de ajuste comparativo (Comparative Fit Index, CFI), que mide la mejora en la medición de la no centralidad de un modelo, cuyos valores se encuentran entre 0 y 1. El valor debe ser superior a 0.9 (Levy y Varela, 2006; Ghorbanhosseini, 2013).
Índices de ajuste de parsimonia. Aquí se tienen los siguientes índices: criterio de información de Akaiké (Akaike Information Criterion, AIC), que es un comparativo entre modelos, cuyo valor próximo a cero indica un buen ajuste (Levi y Varela, 2006); el índice de ajuste parsimónico normalizado (Parsimonious Normed Fit, PNFI); el índice de bondad del ajuste parsimónico (Parsimonious Goodness of Fit Index, PGFI), cuyo umbral oscila de 0 a 1 (los valores cercanos a 1 indican mejor ajuste).
De acuerdo con estos parámetros establecidos, el modelo del análisis factorial confirmatorio objeto de estudio se ajusta de manera satisfactoria, pues cumple con los principales índices de bondad de ajuste que comúnmente se reportan del modelo (Hu y Bentler, 1999): χ2 = 738.03, gl = 263, p < .001; χ2/gl = 2.685. Índice de Tucker-Lewis (TLI) = .924; índice de ajuste comparativo (CFI) = .930; índice de ajuste incremental (IFI) = .931; residuo cuadrático medio de la raíz estandarizada (SRMR) = 0.052; error cuadrático medio de aproximación (RMSEA) = 0.062.
Discusión
La finalidad de la presente investigación fue dar a conocer el uso de la técnica estadística del análisis factorial confirmatorio (AFC) a partir de datos empíricos recabados sobre el modelo SECI. En este sentido, el modelo de medida fue válido y fiable, por sus resultados de la consistencia interna (alfa de Cronbach) y los referentes al análisis factorial exploratorio (KMO, prueba de esfericidad de Bartlett y varianza explicada). En cuanto los resultados del análisis factorial confirmatorio (las cargas factoriales y los índices de bondad de ajuste global del modelo de las tres tipologías [índices de ajuste absoluto, índices de ajuste incremental e índices de parsimonia], así como la validez convergente y discriminante, y la fiabilidad y validez del modelo a través de la fiabilidad del constructo y la varianza media extraída) fueron acordes a los parámetros establecidos (Bagozzi, 1994; Bollen, 1989; Ghorbanhosseini, 2013; Hair, Anderson, Tatham y Black, 2007, 2008; Jöreskog y Sörbom, 1990; Kline, 2011; Lévy y Varela, 2006; Marsh y Hocevar, 1985; Mohamad y Wan, 2013; Tanaka y Huba 1989).
Estos resultados son consistentes con Stock, Tsai Jiang y Klein (2021), quienes abordan un modelo de conocimiento compartido, aunque cabe señalar que su AFC es muy limitado en cuanto a los índices que reportan, ya que solo toma la fiabilidad del alfa de Cronbach y algunos índices de la evaluación del ajuste del modelo de medida. En la misma línea, Zhang, Dawson y Kline (2020) evalúan un modelo de investigación con el uso de la modelación (CB-SEM), donde aplica el AFC, que, a vez, también limita el reporte de los estadísticos de fiabilidad, validez y ajuste del modelo de media.
Limitaciones e implicaciones prácticas de la investigación
Esta investigación se realizó en organismos académicos de la Universidad Autónoma del Estado de México, para lo cual se recopilaron datos de 235 sujetos. Por ende, los resultados no pueden generalizarse, pues el objeto de la investigación no soportó ninguna argumentación hipotética, sino solo la explicación del uso de la técnica del AFC.
Sin embargo, se sugiere que las IES incorporen prácticas de gestión del conocimiento mediante los cuatro modos de conversión explicados, los cuales podrían otorgar mayor valor a los activos intangibles del conocimiento. Al respecto, cabe recalcar que el conocimiento se ha convertido en el motor de la economía actual, de ahí que su gestión y su explotación permitirán desarrollar capital intelectual indispensable para generar ventaja competitiva (Chou y Ta, 2005; Quinn, 1992).
Conclusiones
Validar una escala de medida mediante el análisis factorial confirmatorio (AFC) permitió explicar toda la técnica estadística y mostrar de qué manera se consigue la fiabilidad y validez del modelo. En las ciencias sociales y del comportamiento, este tipo de técnicas es recomendable, siempre que se cumplan los supuestos paramétricos que exige la técnica (principalmente, la normalidad de los datos y el tamaño de la muestra), lo que sería una de las exigencias paramétricas.
En tal sentido, esta técnica tiene las siguientes bondades: 1) permite evaluar modelos de medida de muestras grandes, 2) es una técnica robusta en su algoritmo matemático, 3) permite probar una escala de medida sustentada en la teoría, y 4) existen diversos softwares estadísticos para poder aplicarla, como Amos, EQS, Lisrel, entre otros. En cuanto a las debilidades, no es recomendable para muestras pequeñas ni para estadística no paramétrica.
En resumen, el modelo factorial confirmatorio muestra la validación de las cuatro dimensiones sustentado en la revisión de la literatura, específicamente a través de los índices de bondad de ajuste de tres tipologías de ajuste global con los parámetros establecidos, lo que indica que el modelo factorial presenta fiabilidad, validez y se ajusta correctamente a sus factores.
Futuras líneas de investigación
El modelo propuesto por Nonaka, Toyama y Byosiere (2001) describe los cuatro modos de conversión o creación del conocimiento que pueden ser aplicados en cualquier organización. Por eso, se alienta a investigadores para que amplíen este trabajo a través de pruebas empíricas que usen este modelo aunque con otros constructos, ya sean de primer orden o de orden superior. Además, el modelo puede ser estudiado como una variable independiente o dependiente, o fungir como un constructo mediador o moderador.

