










Servicios Personalizados
Revista
Articulo
 texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista mexicana de ciencias forestales
versión impresa ISSN 2007-1132
Rev. mex. de cienc. forestales vol.7 no.37 México sep./oct. 2016
Articles
Dominant height growth model for Pinus pseudostrobus Lindl. in Guerrero state
1Instituto Tecnológico de El Salto. Pueblo Nuevo, Dgo. México. Correo-e: cobos_cruz@yahoo.com.mx
2C.E. Valle del Guadiana, CIR Norte-Centro. Inifap. México.
Forest productivity can be expressed mathematically through equations describing growth patterns according to the different factors involved in the development of each species. The aim of the present study was to evaluate the fit of three dynamic growth equations in dominant height in generalized algebraic difference (GADA), in order to construct a family of site index curves with a reference age of 15 years. The trunk analyzes of 55 Pinus pseudostrobus trees were used, which were analyzed longitudinally, in order to obtain the true height of the central ring that surrounds the core of the tree. The adjustments were made using the nested iterative method, which is invariant with respect to the base age; in addition, the structure of the error was simulated with a second order autoregressive model to correct the dependence of longitudinal errors inherent to the data obtained in the stems of the trees. The equations in GADA form allowed the definition of a family of polymorphic curves with variable asymptotes, which implies that each site has different growth rates. A dynamic equation based on the Chapman-Richards model was selected because it showed the best fit quality; the coefficient of determination (
Key words: Dominant height; growth curves; GADA; site index; Pinus pseudostrobus Lindl.; complex polymorphism
La productividad forestal puede expresarse matemáticamente por medio de modelos que describen los patrones de desarrollo de acuerdo a los diferentes factores involucrados en el desarrollo de cada especie. El objetivo del presente estudio fue evaluar el ajuste de tres ecuaciones dinámicas de crecimiento en altura dominante en diferencia algebraica generalizada (GADA), con el fin de construir una familia de curvas de índice de sitio con una edad de referencia de 15 años. Se utilizaron los análisis troncales de 55 ejemplares de Pinus pseudostrobus, que fueron analizados de manera longitudinal, con el propósito de calcular la altura verdadera del anillo central que rodea a la médula del árbol. Los ajustes se realizaron mediante el método iterativo anidado, que es invariante con respecto a la edad base; además, se simuló la estructura del error con un modelo autorregresivo de segundo orden para corregir la dependencia de errores longitudinales inherentes a los datos procedentes del fuste. Las fórmula tipo GADA definieron una familia de curvas polimórficas con asíntotas variables, lo que implica que en cada lugar existen tasas de crecimiento diferentes. Se seleccionó una expresión dinámica basada en el modelo de Chapman-Richards porque mostró la mejor calidad de ajuste; el coeficiente de determinación (
Palabras clave: Altura dominante; curvas de crecimiento; GADA; índice de sitio; Pinus pseudostrobus Lindl.; polimorfismo complejo
Introduction
Site quality is the basis for developing forest land classification systems according to their productive capacity (Mora and Meza, 2003). It is defined as the timber production potential of a site, stand or forest, for a given species, in which a better quality, volume production is greater, reason why the productive capacity of a stand is closely related to the imber volume measured in the final harvest (Clutter et al., 1983). To quantify this productive potential there are direct and indirect methods in which the site index is classified as an indirect method using a dominant height growth pattern at a predefined reference age or base age (Vanclay, 1994; Martín et al., 2008; Quiñonez et al., 2015).
Several methods have been developed for modeling and forest biometrics for the construction of functions of dominant height and site index. The most used are the guiding curve method, the Algebriac Difference Approach (ADA) and the Generalized Algebraic Difference Approach (GADA) method (Rodríguez et al., 2015). In the first one, the original mathematical expression and structure of the base models are used to obtain the value of the parameters that are used to construct the families of growth curves by regression, which can be polymorphic or anamorphic; in the ADA or GADA method, the base models are precisely manipulated algebraically and are fitted according to whether one or more parameters are made dependent on the station quality (Clutter et al., 1983; Cieszewski, 2002). The expressions thus obtained are dynamic equations that fit into interval or longitudinal databases (trunk analyzes).
With the ADA methodology families of anamorphic or polymorphic growth curves are obtained, while the GADA methodology combines the two properties and gives rise to the asymptotic polymorphism. The parameters that result from the methods for designing families of growth curves at dominant height can be global, that is, common to all stands, or local, specific to each stand (García, 2006). Equations are effective tools for estimating stand productivity, and allow the implementation of appropriate forest management practices. Therefore, correct prediction of dominant height and site index with dynamic equations is essential for modeling growth and timber production (Vargas et al., 2013).
The equation method in GADA considers that a growth equation can be expanded to allow more than one parameter to depend on the station quality; it is assumed to depend on an artificial variable that represents the factors that determine the station quality and the families of curves obtained are more flexible and applicable in the management of contemporary or incoetaneous stands (Cieszewski and Bailey, 2000; Cieszewski, 2001). With the GADA methodology families of curves with complex polymorphism can be generated, that is, that they have variable growth rates and multiple asymptotes (Cieszewski, 2002), which is ideal in forest management, since the stands have these characteristics.
Complex polymorphism equations better describe height growth patterns than anamorphic or simple polymorphic models (Cieszewski, 2003). These equations consider the sum of factors such as management regimes, soil conditions and ecological and climatic elements defined by an artificial variable denoted by “X” (unobservable and independent variable) (Cieszewski, 2002); also, they preserve the logical properties of invariance of the reference age and the route of way of simulation (Cieszewski, 2003), in which the projections of the dominant height can be towards the future or the past, without affecting the predictive capacity of the equation.
For the fit of the dynamic equations of dominant height in ADA or GADA, pairs of observations of heights and ages taken at intervals of time or in a longitudinal way, that is, measured at different time or in a repeated way, as in permanent plots or trocal analyzes (Diéguez et al., 2006).
Pinus pseudostrobus Lindl. is found mainly in the pine and pine-oak forests of Mexico; it grows in volcanic soils and in temperate and warm-temperate climates, with annual precipitation between 800 mm and 1500 mm (López, 2002). It is commercially important due to its high growth rates in sites with good productivity, it provides high quality timber with dimensions at adult ages between 25 and 40 m in height and 40 to 80 cm in normal diameter. This is why it is a good alternative for the current policies of plant production and reforestation of degraded areas of Guerrero state, as well as to raise the production and productivity of forest lands through an efficient management and that is based on studies that describe the dynamics of its growth.
Thus, the aim of the present work was to generate dynamic growth equations in dominant height and site index to construct a family of site index curves with complex polymorphism, based on longitudinal truncal analysis data of Pinus pseudostrobus trees in ejido El Balcón at the state of Guerrero, Mexico.
Materials and Methods
Study area
The study area is located in the El Balcón ejido, which belongs to the municipality Ajuchitlán del Progreso, in the center of the Sierra Madre del Sur of the state of Guerrero, between the geographical coordinates 17°3’00” to 17°51’00” North and 100°27’30” to 100°36’45” West. The ejido has an area of 25 565 ha, of which 10 000 ha are covered by coniferous forest as well as by tropical and subtropical associations. The predominant ecosystem is pine and pine-oak forest with some scattered patches mountain cloud forest and forest of Abies religiosa (Kunth) Schltdl. et Cham. in the higher parts. The altitudinal range is from 1 050 m to 2 960 m, with an average of 2 213 m. The climate of the place is temperate sub-humid with rains in summer, with an average annual precipitation of 1 400 mm.
Data base
The database that was used to fit the equations in GADA comes from individual trees in young stands, with an average age of 19 years. 55 dominant specimens free of damage were selected, which were felled and sectioned. The sample was distributed at different altitudes and exposures, and all station qualities present in the study area were covered. A longitudinal cut was made along the stem of each individual, in order to measure true growth for each stage of the tree’s life, that is, the height at which the annual growth ring ends. The number of rings was counted in the stump, in the section where the normal diameter is taken and at intervals of 2 m until reaching the tip of the tree. The descriptive statistics of the considered variables are gathered in Table 1.
Table 1 Descriptive statisics of the analyzed variables in the fit of the dynamic equations.

DS = Standard deviation; H = Height (m); DN = Normal diameter (cm); t = Age (years).
For modeling dominant height growth and site index related to age, three equations were chosen whose mathematical structure in GADA comes from the basic model of Chapman-Richards (Richards, 1959), Korf (Lundqvist, 1957) and Hossfeld (Hossfeld, 1922) (Table 2).
Table 2 Assessed basic models and dynamic equations in GADA to model dominant height and site index in Pinus pseudostrobus Lindl.
H = Dominant height (m); t = Age (years); α1, α2 and α3 = Parameters of the basic model; β1, β2 y β3 = Global parameters of the dynamic equation; X0 = Independient non perceptive variable that describes the productivity of a site as a sum of management regimes, soil conditions and ecoloogical and climatic factors; H0 = Dominant height in the initial time t0; H1 = Dominant height in the initial time t1; exp = Exponential function.
Dynamic equations fit by statistical regresión
The quality of fit of the dynamic equations was assessed through a comparative numerical analysis of the fitted determination coefficient (
Where:
Yi ,
n = Number of observations
p = Number of parameters of the model
The estimation of the parameters for the dynamic equations of dominant height and site index implies different statistical considerations: structures and independence of errors, homogeneity of variances and balance in the used data (Diéguez et al., 2006), so it must be confirmed that these assumptions of the regression theory are fulfilled and, if necessary, corrected in the same fitting process.
The models were fittted when the basic age was taken as invariable, and simultaneously the global and specific parameters for each tree, for which the nested iterative procedure (Tait et al., 1988), was used, which generates good results on the basis of data greater than 800 pairs of height and age (Cieszewski, 2003; Krumland and Eng, 2005; Diéguez et al., 2006).
The equations were fitted using the MODEL procedure of the SAS/ETS® statistical package (SAS, 2004), which allows the dynamic updating of the residuals. The iterative process consists of the following steps i) the global parameters are fitted and the local parameter (H0) is considered constant for each tree which varies for each tree and to which initially is assigned the value of the observed average height at the age of 15 years; ii)the values of the global parameters are considered as constant and the specific site parameter (H0) is refitted; the observed values for each tree (H0) are taken as initial for the fit; iii) the estimated data (H1) they are transformed into observed values and the global parameters are fitted again. This sequence is repeated until the succesive estimations of the global parameter are stabilized (Cieszewski and Bailey, 2000), for which the criterion was that the square mean error between two iteractions was lower than 0.0001 (Vargas et al., 2010).
To correct the autocorrelation of the error term, the equations were adjusted with weighted least squares, using a continuous autoregressive error structure (CAR2), based on the distance between height measurements for each tree (Zimmerman and Núñez, 2001; Vargas et al., 2013). The autoregressive model was as follows:
Where:
eij = j th residual of the sampling unit
dk = 1 for > k and 0 for j = k (k = 1, 2 )
ρk = Autoregresive parameter of the k order to be estimated
tij - tij - k = Time or distance that divides the j th measure form the j th -k measure in each sampling unit tij > tij - k
εij = Independent error that follows a normal distribution with mean zero and constant variance
Results and Discussion
The estimators of the parameters for the three dynamic equations fitted to the observations were statistically significant in the hypothesis test, with a level of significance of 1 %; there were no significant differences in the RMSE and in
Table 3 Estimated and statistical parameters of goodness of fit of the dominant height dynamic equations evaluated.

EE = Standard Error Estándar of the estimator of the parameter; P>t = Value of the probabiity of the distribution of the Studet t; RMSE = Square mean error;
The continuous autoregressive error structure (CAR2) correctly corrected the problem of autocorrelation of the errors in the evaluated expressions, which achieved the independence of the residuals of the dominant height as a function of age, which favored estimators of the most efficient and unbiased parameters (Parresol and Vissage, 1998). This prevents the underestimation of the covariance matrix of the parameters and can perform the statistical tests of the estimators of the parameters of these equations (West et al., 1984).
From the practical point of view, the parameters considered to model the error structure are generally not used for predictions of the dominant height (Rodríguez et al., 2015; Castillo et al., 2013; Diéguez et al., 2006), since the main purpose is to achieve consistent estimates of parameters and standard errors (Cieszewski, 2001). In this way, the dominant height of the trees of a stand is calculated according to its age, which is incorporated directly into the model, in addition to its height at that initial age for the projection of the dominant height to a future or past age.
Figure 1 shows the comparison of the families of growth curves for site indexes 13, 16, 19 and 22 m at the base age of 15 years for the fitted dynamic equations. It can be noticed that equation 2 underestimates the dominant height for ages less than 3 years and the asymptote of the curves does not follow the tendency of the observed data, especially for the indexes of 19 and 22 m, and that is why it tends to overestimate height.
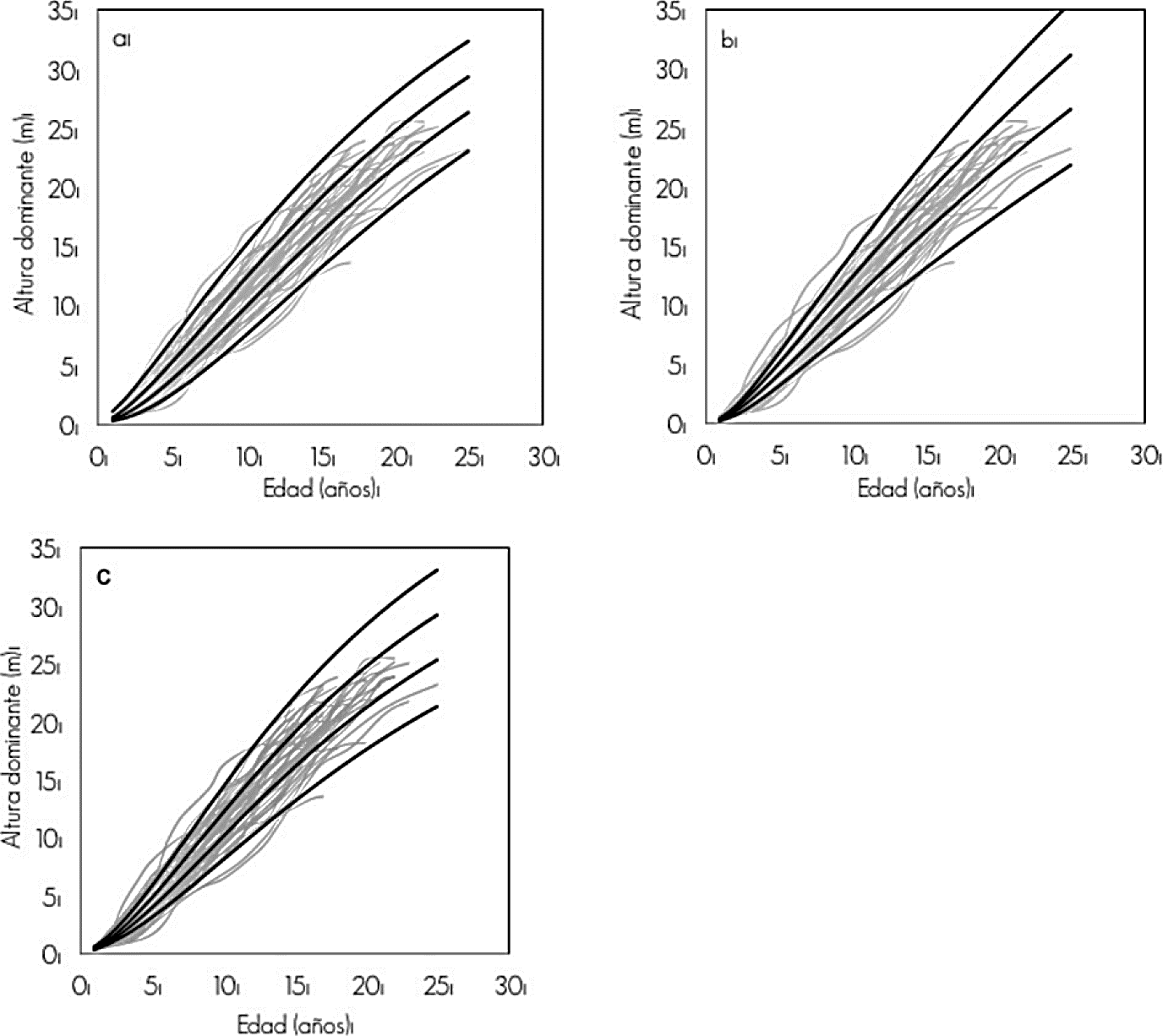
Figure 1 Curve families for 13, 16, 19 and 22 m site indexes at a 15 years reference age that generate the 1 (a), 2 (b) and 3 (c) dynamic equations overlapped at the observed heights.
On the other hand, the family of curves generated by equation 3 suggests that the fitted curve for 13 m site indexes does not follow the asymptote trend of the data observed in the age range over 15 years; for this reason, the dynamic equations 2 and 3 were discarded to model the dominant height growth in P. pseudostrobus trees.
The SI curves derived from equation 1 are those that best describe the behavior of growth in dominant height, since they clearly follow the path defined in all age classes and mark the asymptote in the four site indexes. Although the dynamic evaluated equations do not present obvious differences in the goodness of fit, they must be analyzed by graphs if they are different, given the asymptotic trajectories of the curves. Therefore, the dynamic equation 1 was selected as the best to express growth patterns in dominant height of P. pseudostrobus and also Vargas et al. (2013) chose it for the species of interest in northeastern Mexico, confirming the practical and flexible condition of the base model as well as the dynamic equation for diverse ecological regions.
Even though the observations come from young trees and stands that have not yet fully develop, the trend of the current annual increase (ICA) curves and average annual increase (MAI) in the dominant height is projected (Figure 2); then it can be recognized that the absolute turn (age at which maximum growth at dominant height is achieved) occurs before 10 years for rich sites, whereas for poorer places the shift occurs after the age of 20, thus demonstrating that the species studied exhibits different patterns of growth in dominant height in relation to the quality of the site in which the sample is taken. This means that the absolute shifts will be different in regard to site indexes, which will occur later for the stands with productivity or lower site index (Quiñonez et al., 2015). Therefore, silvicultural practices in management planning must obey a particular species, its biology and site conditions in order to shorten absolute shifts and improve the growth patterns of the species.

Figure 2 Curve families of the current annual increment (ICA) (continuous line) and mean annual increment (IMA) (dashed line), with 13, 16, 19 and 22 m site index categories.
In spite of the tact that P. pseudostrobus is currently operated with the Método Mexicano de Ordenación de Bosques Irregulares (MMOBI) (Mexican Management Method of Irregular Forests (MMOBI), with selection in groups, and even considering biological diversity and market characteristics, the results showed that intensive silvicultural management can be applied in the studied stands; therefore it is necessary to develop, adopt or adapt new schemes by rethinking the objectives and technologies that are relevant to the new ecological, socio-cultural, economic, legislative and institutional realities of forest areas (Torres et al., 2016).
All the curve families obtained with the dynamic equations show complex polymorphism, an inflexion point at ages lower than 7 years, and are invariant in regard to the simulation trail. Similar results are reported by López et al. (2015) with dominant height models in Pseudotsuga menziesii (Mirb.) Franco plantations in Spain.
Although the family of growth curves at dominant height that generates the selected dynamic equation follows the trend of the observed data, it must be taken into account that the total height of the tree is a sum of periods more extensive than the upper limit of age analyzed in this study (Huang, 1999), such as soil erosion due to poor management practices and high forest density in the sites (Daniel et al., 1982); therefore, such curves are only valid for application in stands with ages up to 25 years to estimate the dominant height and to qualify productivity through site index.
Figure 3a shows the linear graphical behavior of the residuals of equation 1, against a delay of residuals (Lag1) without considering the autoregressive parameters; this linear trend disappears after correcting the autocorrelation with a continuous autoregressive structure of second-order errors (CAR2), which provides a random pattern in the residuals by using three delays (Lag3) (Figure 3b); Castillo et al. (2013) report similar results in site index models for four pine species in Santiago Papasquiaro, Durango State.

Conclusions
A dynamic equation of dominant height and GADA-type site index, based on the Champan-Richard model, had the best fit quality to the trunk analysis data, so it was selected to predict growth in dominant height and to qualify the productivity level of Pinus pseudostrobus stands through the site index in the study area. The fit of this equation should be updated and the observations of older trees should be incorporated, in order to cover the full range of the age of the shift and obtain better predictions.
The selected site index dynamic equation is recommended for estimating the productivity of young stands and should be validated to determine the feasibility of using it in older stands of Pinus pseudostrobus and to take into account the forestry management treatments applied to the forest.
With the use of longitudinal truncal analyzes, acceptable results in the adjustment of the dynamic equations are obtained, so it is proposed to use this methodology for later research work.
Conflict of interests
The authors declare no conflict of interest.
Contribution by author
Miguel Ángel González Méndez: data analysis, model fit, elaboration and review of the manuscript; Francisco Cruz Cobos: data analysis, model fit, elaboration and review of the manuscript; Gerónimo Quiñonez Barraza: data analysis, model fit, elaboration and review of the manuscript; Benedicto Vargas Larreta: data analysis, model fitt, elaboration and review of the manuscript; Juan Abel Nájera Luna: data analysis, model fit, elaboration and review of the manuscript.
Acknowledgements
The authors wish to express their appreciation to the Dirección General de Educación Superior Tecnológica (DGEST) (General Directorate of Higher Technological Education, DGEST) for the” Movilidad Nacional de Posgrado” (National Graduate Mobility)” grant awarded to the first author. And to the El Balcón ejido, Ajuchitlán del Progreso municipality, Guerrero State, Mexico for its good will to let the collection of field data.
REFERENCES
Castillo L., A., E. Vargas L., J. J., Corral R., J. A. Nájera L., F. Cruz C. y J. Hernández, F. 2013. Modelo compatible altura-índice de sitio para cuatro especies de pino en Santiago Papasquiaro, Durango. Revista Mexicana de Ciencias Forestales 4(18): 86-103. [ Links ]
Cieszewski, C. J. 2001. Three methods of deriving advanced dynamic site equations demonstrated on inland Douglas-fir site curves. Canadian Journal of Forest Research 31(1): 165-173. [ Links ]
Cieszewski, C. J. 2002. Comparing fixed-and variable-base-age site equations having single versus multiple asymptotes. Forest Science 48(1): 7-23. [ Links ]
Cieszewski, C. J. 2003. Developing a well-behaved dynamic site equation using a modified Hossfeld IV Function Y 3=(axm)/(c+ x m-1), a simplified mixed-model and scant subalpine fir data. Forest Science 49(4): 539-554. [ Links ]
Cieszewski, C. J. and L. Bailey. 2000. Generalized algebraic difference approach: theory based derivation of dynamic site equations with polymorphism and variable asymptotes. Forest Science 46(1): 16-126. [ Links ]
Cieszewski, C. J. and M. Strub. 2008. Generalized algebraic difference approach derivation of dynamic site equations with polymorphism and variables asymptotes from exponential and logarithmic functions. Forest Science 54(3): 303-315. [ Links ]
Clutter, J., J. Forston, L. Pienaar, G. Brister and R. Bailey 1983. Timber management: a quantitative approach. John Wiley and Sons Inc. New York, NY, USA. 331 p. [ Links ]
Daniel, T. W., J. A. Helms y F. S. Baker. 1982. Principios de silvicultura. Litográfica Ingramex, S. A. México, D. F., México. 492 p. [ Links ]
Diéguez A., U., H. E. Burkhart and R. L. Amateis. 2006. Dynamic site model for lobolly pine (Pinus taeda L.) Plantations in the United States. Forest Science 52(3): 262-272. [ Links ]
García, O. 2006. Site index: concepts and methods. In: Cieszewski, C. J. andM. Strub. (eds). Second International Conference on Forest Measurements and Quantitative Methods and Management. Warnell School of Forestry and Natural Resources. University of Georgia. Athens, GA, USA. pp. 275-283. [ Links ]
Goelz, J. C. G. and T. E. Burk. 1992. Development of a well-behaved site index equation: jack pine in north central Ontario. Canadian Journal of Forest Research 22: 776-784. [ Links ]
Hossfeld J., W. 1922 Mathematik für Forstmänner, Ökonomen und Cameralisten. Gotha, Thüringen, Deutschland. 310 p. [ Links ]
Huang, S. 1999. Development of compatible height and site index models for young and mature stands within an ecosystem-based management framework. In: Amaro, A. and M. Tomé (eds). Empirical and process- based models for forest tree and stand growth simulation. Ediçoes Salamandra-Novas Tecnologias. Lisbon, Portugal. pp. 61-98. [ Links ]
Krumland, B. and H. Eng. 2005. Site index systems for major young-growth forest and woodland species in northern California. California Department Forestry and Fire Protection. Davis, CA, USA. California Forestry Report Num. 4. 220 p. [ Links ]
López S., C. A., J. G. Álvarez G., U. Diéguez A. and R. Rodríguez S. 2015. Modelling dominant height growth in plantations of Pseudotsuga menziesii (Mirb.) Franco in Spain. Southern Forests: a Journal of Forest Science 77(4): 315-319. [ Links ]
López U., J. 2002. Pinus pseudostrobus Lindl. In: Vozzo A., J. A. (ed.). Tropical Tree Seed Manual. USDA Forest Service. Washington, DC, USA. pp. 636-638. [ Links ]
Lundqvist, B. 1957. On the height growth in cultivated stands of pine and spruce in northern Sweden. Medd Fran Statens Skogforsk Band 47(2): 1-64. [ Links ]
Martín B., D., G. Gea I., M. Del Río and I. Cañellas. 2008. Long-term trends in dominant-height growth of black pine using dynamic models. Forest Ecology and Management 256: 1230-1238. [ Links ]
Mora, F. y V. Meza. 2003. Comparación del crecimiento en altura de la teca (Tectona grandis) en Costa Rica con otros trabajos previos y con otras regiones del mundo. Seminario y Grupo de Discusión Virtual en Teca. Heredia, Costa Rica. http://www.una.ac.cr/inisefor (3 de julio de 2016). [ Links ]
Parresol, B. R. and J. S. Vissage. 1998. White pine site index for southern forest survey. Res. Pap. SRS-10. US Department of Agriculture, Forest Service, Southern Research Station. Asheville, NC, USA. 8 p. [ Links ]
Quiñonez B., G., H. M. De los Santos P., F. Cruz C., A. Velázquez M., G. Ángeles P. y G. Ramírez V. 2015. Índice de sitio con polimorfismo complejo para masas forestales de Durango, México. Agrociencia 49(4): 439-454. [ Links ]
Richards, F. J. 1959. A flexible growth function for empirical use. Journal of Experimental Botany 10(2): 290-301. [ Links ]
Rodríguez C., A., F. Cruz C., B. Vargas L. y F. J. Hernández. 2015. Modelo compatible de altura dominante-índice de sitio para táscate (Juniperus deppeana Steud.). Revista Chapingo. Serie Ciencias Forestales y del Ambiente 21(1): 97-108. [ Links ]
Statistical Analysis System Institute Inc. (SAS). 2004. SAS/ETS User’s Guide, 9.1. Version. Cary, NC, USA. 1315 p. [ Links ]
Sharma, R. P., A. Brunner, T. Eid and B. H. Øyen 2011. Modelling dominant height growth from national forest inventory individual tree data with short time series and large age errors. Forest Ecology and Management 262(12): 2162-2175. [ Links ]
Tait, D. E., C. J. Cieszewski and I. E. Bella. 1988. The stand dynamics of lodgepole pine. Canadian Journal of Forest Research 18(10): 1255-1260. [ Links ]
Torres R., J. M., R. Moreno S. and M. A. Mendoza B. 2016. Sustainable forest management in Mexico. Current Forestry Reports 2(2): 93-105. [ Links ]
Vanclay, J. 1994. Modelling forest growth and yield. applications to mixed tropical forests. CAB International. Wallingford, UK. 312 p. [ Links ]
Vargas L., B., O. A. Aguirre C., J. J. Corral R., F. Crecente C., y U. Diéguez A. 2013. Modelos de crecimiento en altura dominante e índice de sitio para Pinus pseudostrobus Lindl. en el noreste de México. Agrociencia 33(1): 91-106. [ Links ]
Vargas L., B. , J. G. Álvarez G. J. J. Corral R. y O. A. Aguirre C. 2010. Construcción de curvas dinámicas de índice de sitio para Pinus cooperi Blanco. Fitotecnia 33(4): 344-351. [ Links ]
West, P. W., D. A. Ratkowsky and A. W. Davis. 1984. Problems of hypothesis testing of regressions with multiple measurements from individual sampling units. Forest Ecology and Management 7(3) :207-224. [ Links ]
Zimmerman, D. L. and V. Núñez A. 2001. Parametric modeling of growth curve data: an overview (with discussion). Test 10(1): 1-73. [ Links ]
Received: August 08, 2016; Accepted: September 30, 2016
 Este es un artículo publicado en acceso abierto bajo una licencia Creative Commons
Este es un artículo publicado en acceso abierto bajo una licencia Creative Commons
