










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkRevista mexicana de ciencias forestales
Print version ISSN 2007-1132
Rev. mex. de cienc. forestales vol.4 n.18 México Jul./Aug. 2013
Artículo
Modelo compatible altura- índice de sitio para cuatro especies de pino en Santiago Papasquiaro, Durango
Compatible height and site index model for four pine species in Santiago Papasquiaro, Durango
Albert Castillo López1, Benedicto Vargas-Larreta2, José Javier Corral Rivas3, Juan Abel Nájera Luna2, Francisco Cruz Cobos2 y Francisco Javier Hernández2
1Programa de Maestría en Ciencias. Instituto Tecnológico de El Salto (ITES). Correo-e: bvargas@itelsalto.edu.mx
2Instituto Tecnológico de El Salto
3Facultad de Ciencias Forestales
Fecha de recepción: 23 de febrero de 2012.
Fecha de aceptación: 19 de julio de 2013.
Resumen
La productividad forestal es un concepto biológico que puede expresarse matemáticamente. En el presente estudio se describen modelos compatibles altura dominante - índice de sitio para Pinus arizonica, P. durangensis, P. leiophylla y P. teocote en la región de Santiago Papasquiaro, Durango, una de las zonas forestales más importantes de México. Los datos utilizados fueron obtenidos de análisis troncales de 202 árboles dominantes. Se ajustaron los modelos de Korf, Hossfeld y Bertalanffy-Richards, para lo cual se utilizó el método de Diferencias Algebraicas Generalizadas (GADA). La principal ventaja de este método es que depende de la calidad de estación y no de un parámetro de los modelos, con lo que las curvas obtenidas son polimórficas y con múltiples asíntotas. Durante el ajuste se modeló la estructura del error a través de un modelo autorregresivo de segundo orden para corregir la dependencia de datos longitudinales. Con base en los estadísticos de ajuste y el análisis gráfico, se recomienda el modelo de Bertalanffy-Richards para calificar la calidad de estación de las cuatro taxa. La ecuación de este modelo es polimórfica con múltiples asíntotas e invariante con respecto a la edad de referencia, además estima directamente la altura dominante y el índice de sitio a cualquier altura y edad. El uso de estas ecuaciones permitirá mejorar significativamente la estimación actual del potencial productivo de las especies estudiadas.
Palabras clave: Calidad de estación, diferencias algebraicas generalizadas, invarianza, modelo autorregresivo, productividad forestal, Santiago Papasquiaro.
Abstract
Forest productivity is a biological concept that can be expressed mathematically. Compatible dominant height-site index models are of the most important forest zones of Mexico. The data used were obtained from the stem analyses of 202 dominant trees. Korf, Hossfeld and Bertalanffy-Richards models were adjusted by the method of Generalized Algebraic Differences (GADA). The principal advantage of this method is that it depends on the quality station more than one parameter of the models, so that the curves obtained are polymorphic and with multiple asymptotes. A second-order autoregressive error structure was used in the fitting process to correct the serial correlation of the longitudinal data. Based on the goodness of fit statistics and a graphical analysis, the Bertalanffy-Richards model is recommended to qualify the quality station of the four species. This equation is polymorphic with multiple asymptotes and base-age invariant, and also directly estimates the dominant height and the site index at any height and reference age. Using these equations will significantly improve the current estimate of the productive potential of the species studied.
Key words: Quality station, generalized algebraic difference, invariance, autoregressive model, forest productivity, Santiago Papasquiaro.
Introducción
La calidad de estación se define como el potencial de producción de madera de un rodal para una determinada especie o tipo de bosque (Clutter et al., 1983), la que resulta de la interacción de un conjunto de factores biológicos, climáticos, topográficos y edáficos, que influyen en la capacidad productiva del mismo; la combinación de estos factores puede resultar favorable para el desarrollo de los árboles generando su máximo potencial de crecimiento.
El crecimiento y la producción de las masas forestales para una determinada especie dependen en gran medida de lo siguiente: (i) la edad de la masa o, en el caso de masas irregulares, la distribución de edades; (ii) la capacidad de producción innata del área que soporta la masa; (iii) el grado de utilización de esa capacidad productiva en el pasado y en el momento actual; y (iv) los tratamientos silvícolas aplicados (aclareos, podas y control de la vegetación competidora) (Clutter et al., 1983). De lo anterior, el segundo componente corresponde a lo que generalmente se denomina "calidad de estación", la que puede describirse como la capacidad productiva de un área determinada para el crecimiento de árboles, y es la respuesta en el desarrollo de una determinada especie a la totalidad de las condiciones ambientales existentes en el mismo (Prodan et al., 1997); esto es, la calidad de una estación forestal es su capacidad productiva, por lo que se puede considerar, entonces, como una propiedad inherente del terreno, crezcan o no árboles en un momento dado (Davis et al., 2001).
La productividad forestal es un concepto biológico que puede expresarse matemáticamente. Es por ello que se ha optado por representar la calidad de sitio a través de un valor o índice el cual es una expresión cuantitativa de la calidad de sitio. En ese sentido, la utilización del crecimiento en altura de los árboles que viven en condiciones de poca competencia como indicador de la calidad de estación de un rodal forestal se justifica debido a que áreas de buena calidad de estación son también áreas de buenos crecimientos en altura para muchas especies. En otras palabras, para la mayoría de las especies la producción potencial en volumen y el crecimiento en altura están positivamente correlacionados (Diéguez-Aranda et al., 2009). La utilidad práctica de dicha correlación proviene de la evidencia empírica que indica que el patrón de crecimiento en altura de los árboles de mayores dimensiones en masas regulares (correspondientes a las clases sociológicas dominante y codominante, y por tanto con poca competencia de los restantes árboles) está poco afectado por la densidad del rodal y por las cortas intermedias efectuadas, dentro de unos límites moderadamente amplios de espaciamiento, lo que depende de la especie (Clutter et al., 1983). Por ello, las técnicas más habituales para estimar la calidad de estación de un rodal se basan en el análisis de la evolución de la altura media de los árboles dominantes con la edad, que se denomina altura dominante.
Casi todas las curvas de índice de sitio publicadas recientemente se han desarrollado utilizando en especial la metodología de ecuaciones en diferencias algebraicas (ADA por sus siglas en inglés) (Bailey y Clutter, 1974) o su generalización (GADA por sus siglas en inglés) (Cieszewski y Bailey, 2000). La principal limitación de la metodología ADA es que la mayoría de los modelos derivados son anamórficos o tienen una asíntota común (Bailey y Clutter, 1974; Cieszewski y Bailey, 2000), mientras que con su generalización pueden obtenerse familias que sean a la vez polimórficas y con múltiples asíntotas (Cieszewski, 2002).
Dado que en la región forestal de Santiago Papasquiaro, Durango, no se cuenta con ecuaciones de índice de sitio validadas científicamente, el objetivo de este trabajo fue construir curvas de calidad de estación para Pinus arizonica Engelm., P. durangensis Martínez, P. leiophylla Schiede ex Schltdl. & Cham y P. teocote Schiede ex Schltdl. & Cham, mediante el Método de Diferencias Algebraicas Generalizado.
Materiales y Métodos
Área de estudio
El estudio se llevó a cabo en la región forestal de Santiago Papasquiaro, ubicada al noroeste del estado de Durango, y que abarca 628 000 ha, aproximadamente. Se localiza entre los 24°52’22" de latitud norte y los 106°03’46" de longitud oeste (Figura 1). La altitud varía entre 2 400 y 3 000 m. La temperatura media anual oscila entre los 12 - 21 °C, mientras que la precipitación promedio anual alcanza de los 800 hasta los 1 200 mm (UAFSP, 2010).

Figura 1. Localización geográfica del área de estudio.
Figure 1. Geographical location of the study area.
Datos
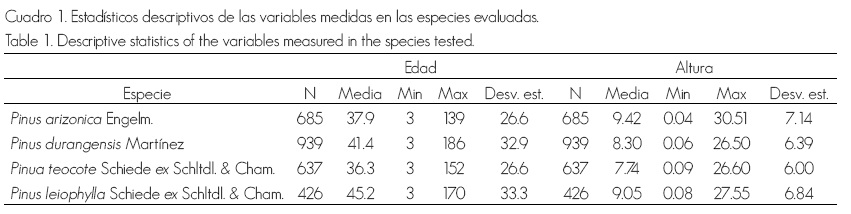
Se utilizaron pares de datos altura dominante-edad procedentes del análisis troncal de 202 árboles dominantes de todas las calidades de estación, y distribuidos de la siguiente manera: 46 árboles de Pinus arizonica, 73 de P. durangensis, 29 de P. leiophylla y 54 de P. teocote. Los árboles fueron derribados a una altura del tocón de 0.3 m, que posteriormente fueron seccionados a la altura del diámetro normal (1.3 m) y a intervalos de alturas variables (de 1 a 2.5 m) a partir de los 1.3 m. La edad de cada sección y alturas verdaderas fueron determinadas en por medio del algoritmo de Fabbio et al. (1994). El valor máximo, mínimo y medio, así como la desviación estándar de la altura total y la edad de los árboles muestra se presentan en el Cuadro 1, donde N, Media, Min, Max y Desv. est., son el número de pares de datos de altura-edad, los valores medio, mínimo y máximo y la desviación estándar, respectivamente.
Cuadro 1. Estadísticos descriptivos de las variables medidas en las especies evaluadas.
Table 1. Descriptive statistics of the variables measured in the species tested.
Estimación de las alturas verdaderas
La altura de cada sección de corta sobrestima la altura real que el árbol tenía a la edad que indica la sección, ya que la sección de corte en la troza rara vez coincide con el comienzo de un año, introduciendo un sesgo en los cálculos posteriores (Dyer y Bailey, 1987; Fabio et al., 1994).
Para solucionar este inconveniente se utilizaron el algoritmo de Carmean (1972) y la modificación propuesta por Newberry (1991) para la troza final, metodologías que han presentado los mejores resultados al calcular las alturas verdaderas (Dyer y Bailey, 1987; Fabio et al., 1994). Este método se basa en dos supuestos: a) el árbol crece a un ritmo constante entre dos secciones, y b) el corte se realiza, como media, en el centro del crecimiento en altura de un año. La ecuación empleada para calcular la altura verdadera varía según la parte del árbol (ecuaciones 1, 2 y 3).

Donde:
H1 y H2 = Alturas de las secciones inferior y superior de la troza
N1y N2= Número de anillos de las secciones inferior y superior de la troza
N0 = Edad del árbol, es decir el número de anillos del tocón (en el tocón N0 = N1)
T0 = Edad del árbol cuando alcanzó la altura H1, es decir N0 - N1
T = Número entero de 1 a N1 – N2
Modelos analizados
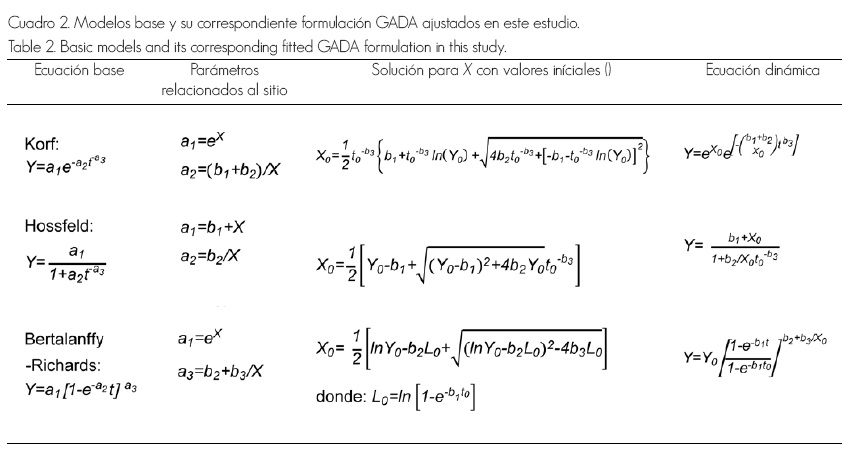
En el presente estudio se ajustaron tres modelos en forma GADA ampliamente utilizados para describir el crecimiento en altura dominante con relación a la edad: Korf, Hossfeld y Bertalanffy-Richards (Barrio et al., 2006; Castedo et al., 2007; Vargas-Larreta et al., 2010). La expresión de los modelos base así como su formulación GADA se presentan en el Cuadro 2.
Descripción de la metodología GADA
Muchos modelos que describen la relación altura dominante-edad están expresados en forma de diferencias algebraicas (ADA), metodología introducida en el campo forestal por Bailey y Clutter (1974). Éstas se fundamentan en el hecho de poder modelar el crecimiento de una determinada variable con una familia de curvas originadas por una ecuación base cuya forma es Y=f(t) con todos los parámetros comunes excepto uno, que es un parámetro especifico del sitio forestal, de forma que se podrían obtener para cada modelo base, diferentes ecuaciones según sea el número de parámetros que este contenga.
Cuadro 2. Modelos base y su correspondiente formulación GADA ajustados en este estudio.
Table 2. Basic models and its corresponding fitted GADA formulation in this study.
Donde:
Y = Altura dominante (m),
ti = Edad de referencia o edad base (años),
ai = Parámetros en la ecuación base,
bi = Parámetros globales en la ecuación dinámica (formulación GADA).
Para la mayoría de los modelos base, solamente uno de los parámetros que se va a estimar a1,…,an depende directamente de las condiciones del sitio forestal y el resto son comunes, lo que da lugar a dos tipos de curvas de calidad, en función de la naturaleza de las curvas altura-edad que generan: i) anamórficas con varias asíntotas y, ii) polimórficas con una única asíntota. En muchos casos, la metodología ADA puede ser suficiente para modelar la altura dominante con relación a la edad de una especie en particular. En otras ocasiones es necesario generar una familia de curvas polimórficas con múltiples asíntotas, por lo que Cieszewski y Bailey (2000) propusieron una generalización de esta metodología a la cual llamaron método de ecuaciones en diferencias algebraicas generalizado (Generalized Algebraic Difference Approach, GADA), la cual permite que más de un parámetro de un modelo dependa de la calidad de estación.
El primer paso de la metodología GADA es seleccionar una ecuación base e identificar en ella los parámetros que se desea que sean específicos del sitio. A continuación, debe definirse de forma explícita cómo cambian dichos parámetros entre las diferentes estaciones reemplazándolos con funciones explícitas de X (una variable independiente oculta que describe la productividad del sitio como resultado de las prácticas de manejo, las condiciones del suelo y los factores ecológicos y climáticos) y nuevos parámetros. De este modo, la ecuación base bidimensional inicialmente seleccionada (Y=f(t)) se expande en una ecuación tridimensional (Y=f(t,X)) que describe tanto cambios transversales como longitudinales con dos variables independientes (t y X). Debido a que X no se puede medir con precisión e incluso no se puede definir en términos funcionales, el último paso de la metodología GADA consiste en sustituir X por condiciones iniciales equivalentes que representan observaciones puntuales de las dos variables observables t e Y (e. g. t0, Y0), de manera que el modelo se pueda definir implícitamente (e. g. Y=f(t, t0, Y0)) (Cieszewski y Bailey, 2000; Cieszewski, 2002). Durante este proceso a menudo se eliminan parámetros redundantes, de lo que se obtiene un modelo con un número de parámetros menor o igual el de la ecuación base original.
Métodos de ajuste
El procedimiento de ajuste para la estimación de los parámetros fue el denominado método iterativo (nested iterative procedure) (Cieszewski, 2003) que es un método invariante con respecto a la edad de referencia, el cual ha sido utilizado en otros estudios (Vargas-Larreta et al., 2010). Este método estima los efectos específicos del sitio y asume que los datos siempre contienen errores de medición y errores aleatorios, los cuales deben ser modelados (Diéguez-Aranda et al., 2005).
Este proceso comienza con la estimación de los parámetros globales (b1, b2 y b3 en las ecuaciones dinámicas del Cuadro 2), que considera constante el parámetro local (H0), mismo que varía para cada árbol y al que, en principio, se le asigna como valor, la altura media observada a una edad base determinada. En el segundo paso los valores estimados de los parámetros globales también se toman como constantes y el parámetro local (H0) se estima para cada árbol, y se ajusta una vez más el modelo empleando como valor inicial para los parámetros locales la altura observada a la mitad de la edad del árbol. Posteriormente, el valor estimado para cada árbol del parámetro local es una constante y se ajusta el modelo para estimar de nuevo los parámetros globales. Este procedimiento se repite sucesivamente hasta que los parámetros globales se estabilizan utilizando como criterio que la reducción del error medio cuadrático del modelo entre dos o más iteraciones consecutivas sea menor de 0.0001 (Vargas-Larreta et al., 2010).
Análisis estadístico
En el análisis de ecuaciones de regresión que describen el comportamiento de individuos a lo largo del tiempo (datos longitudinales) es frecuente que los errores no sean independientes (presencia de autocorrelación). La autocorrelación conlleva a estimaciones sesgadas de los errores estándar asociados a los parámetros, lo que invalida los procedimientos de contraste de hipótesis y de estimación de intervalos de confianza de las estimaciones de los parámetros. En este trabajo se utilizó un modelo autorregresivo (CAR(x)) para corregir la dependencia inherente a los datos longitudinales empleados (Gregoire et al., 1995). De acuerdo a Zimmerman y Núñez-Antón (2001), en una estructura autorregresiva de orden x (CAR(x)) el término de error se expande como:

Donde:
Hij = Predicción de la altura utilizando Hj (altura j), ti (edad i), y tj (edad j≠i) como variable predictoras
β = Vector de parámetros a estimar
eij = j-ésimo residuo del i-ésimo individuo
eij-k = j-k-ésimo residuo del i-ésimo individuo
Ik = 1 cuando j>k y 0 cuando j<k,
r k= Parámetro autorregresivo continuo de orden k a ser estimado, y hij-hij-k es la distancia de la j-ésima a la j-k-ésima observación en cada árbol i, con hij > hij-k.
εij = Término del error, ahora independiente y con distribución normal de media cero.
El ajuste simultáneo de la ecuación de crecimiento y de la estructura del error dada por el modelo autorregresivo, se realizó con el procedimiento MODEL del paquete estadístico SAS/ETSTM (SAS Institute Inc., 2004), que permite una actualización dinámica de los residuos.
Selección del mejor modelo
El análisis de la capacidad de ajuste de los modelos se basó en comparaciones numéricas y gráficas. Se calcularon los siguientes estadísticos: la raíz del error medio cuadrático (REMC) y el coeficiente de determinación para regresión no lineal (R2). Aunque existen varias objeciones relacionadas con el uso de la R2 en regresión no lineal, la utilidad general de alguna medida global de la capacidad predictiva del modelo parece anular algunas de esas limitaciones (Ryan, 1997). La expresión de estos estadísticos es la siguiente:
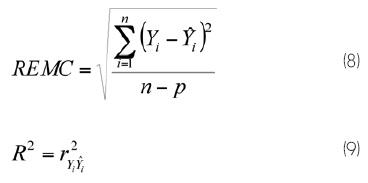
Donde:
 = Valores observado, estimado y promedio de la variable dependiente,
= Valores observado, estimado y promedio de la variable dependiente,
 = Número total de observaciones utilizadas para ajustar el modelo
= Número total de observaciones utilizadas para ajustar el modelo
p = Número de parámetros a estimar y
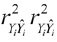 = Coeficiente de correlación entre
= Coeficiente de correlación entre
Entre los diferentes métodos gráficos disponibles para la evaluación de la bondad de ajuste de los modelos se emplearon los siguientes: i) superposición de las curvas ajustadas sobre las trayectorias de las alturas observadas a lo largo del tiempo, ii) representación de los residuos frente a los valores predichos por el modelo y, iii) representación de los residuos frente a residuos con diferentes retrasos para comprobar la corrección de la autocorrelación de los errores mediante la modelización de la estructura del error.
Resultados y discusión
Estructura de la media de los datos
En la Figura 2 se presentan las trayectorias de crecimiento en altura provenientes de los análisis troncales y la estructura real de la media para cada una de las especies estudiadas. En general, existió una caída de la media en torno a los 100 años, aunque para la mayoría de las especies se observó una caída a edades entre 60 y 80 años lo que indica una falta de información en las mejores calidades de estación. La representación de la estructura real de la media es importante porque una caída de éstas puede tener efecto en la calidad de los ajustes debido a la falta de datos en esas edades (Álvarez-González et al., 2005).

Figura 2. Superposición de los datos de análisis troncales y la estructura real de la media (línea sólida).
Figure 2. Overlapping of the data from stem analysis and the real structure of the mean (solid line).
Selección del mejor modelo
Para detectar problemas de autocorrelación entre los residuos de un mismo árbol se realizó el ajuste de los modelos 4, 5 y 6 (Cuadro 2) sin tener en cuenta los parámetros de la estructura de autocorrelación del error (ri). El Cuadro 3 presenta las estimaciones de los parámetros y los estadísticos de bondad de ajuste obtenidos en el ajuste de los tres modelos base sin considerar la estructura del error para cada una de las especies.
Cuadro 3. Parámetros estimados y estadísticos de ajuste de los modelos evaluados sin considerar la estructura del error.
Table 3. Parameter estimates and fit statistics of the models evaluated without considering the structure of the error.

Los errores medios (REMC) obtenidos con el modelo de Korf para todas las especies osciló entre 0.77 (P. teocote) y 0.99 m (P. arizonica) (Cuadro 3), destacando que las ecuaciones 5 y 6 presentaron valores de REMC similares. Para todas las especies los tres modelos explicaron más del 94% de la varianza del crecimiento en altura dominante en función de la edad, destacando en todos los casos el modelo de Korf (ecuación 4), con valores de R2 mayores de 0.98; excepto para P. leiophylla, este modelo fue el que presentó los mejores ajustes, aunque la diferencia con el mejor para esta especie (ecuación 5) fue mínima.
Para Pinus teocote las tres ecuaciones mostraron buenos ajustes, sin embargo, el parámetro b1 del modelo de Korf (ecuación 4) fue no significativo, situación que también ocurrió para P. leiophylla, para la cual a pesar de sus estadísticos de ajuste altos, el parámetro b2 de los modelos de Korf (ecuación 4) y Bertalanffy-Richards (ecuación 6) fueron no significativos a nivel de 1%.
Dado que las diferencias entre los estadísticos de bondad de ajuste fueron mínimas, la selección del mejor modelo se apoyó en el análisis gráfico sobreponiendo las curvas de calidad generadas con cada modelo sobre los datos originales para comparar su capacidad para describir la relación altura dominante-edad (Figura 3).

Figura 3. Sobreposición de las curvas de calidad a los datos originales generadas con los modelos de Korf (línea discontinua), Hosffeld (línea punteada) y Bertalanffy-Richards (línea continua).
Figure 3. Overlay curves of the original data quality models generated with Korf (discontinuous line), Hosffeld (dotted line) and Bertalanffy-Richards models (solid line).
La comparación gráfica permite observar que la ecuación de Bertalanffy-Richards (ecuación 6) describe ligeramente mejor las tendencias individuales de crecimiento en altura, principalmente a edades superiores a los 80 años para todas las especies. En todos los casos, las curvas generadas con la ecuación 6 presentan valores asintóticos más plausibles que las generadas con las ecuaciones 4 y 5, con las cuales la asíntota se alcanza a edades mucho mayores de 180 años. Por ejemplo, para P. teocote la asíntota se aprecia a una edad aproximada de 140 años con el modelo de Bertalanffy-Richards, con un valor de 33 m para la mejor calidad de estación, altura cercana a la máxima reportada para esta especie en la región (García y González, 2003), mientras que con las ecuaciones 4 y 5 las asíntotas se manifiestan en a alturas de 38 y 40 m, valores muy por encima de los máximos que esta especie puede llegar a tener.
En cambio, para P. durangensis la asíntota obtenida con la ecuación 6 en la mejor calidad de estación fue 38 m, valor cercano a la altura máxima reportada para esta especie (40 m) en el estado de Durango (García y González, 2003), en cambio con la ecuación 4 (Korf) el crecimiento en altura dominante no se estabilizó hasta una edad cercana a los 180 años, mientras que con la ecuación 5 (Hossfeld) la asíntota se alcanza a una altura de 33 m, muy por debajo de las alturas máximas que esta especie puede alcanzar en las mejores calidades de estación.
Este análisis refuerza lo señalado por Diéguez-Aranda et al. (2006), quienes afirman que diferentes modelos pueden presentar los mismos estadísticos de bondad de ajuste o de comparación pero una respuesta distinta.
Finalmente, se analizó la tendencia del sesgo (Figura 4) de cada modelo en la estimación de las alturas por clases de edad para cada especie.

Figura 4. Sesgo en las predicciones de altura estimadas con los modelos de Korf (línea discontinua), Hosffeld (línea punteada) y Bertalanffy-Richards (línea continua).
Figure 4. Bias in estimated height predictions with Korf (dashed line), Hosffeld (dotted line) and Bertalanffy-Richards models (solid line).
En general, la estimación de alturas con el modelo de Bertalanffy-Richards describe una distribución del sesgo alrededor de la línea del cero, mientras que las ecuaciones de Korf y Hossfeld muestran un sesgo mayor prácticamente en todas las clases de edad, en particular entre los 40 y 60 años y para edades jóvenes.
Vargas-Larreta et al. (2010) encontraron que el modelo de Bertalanffy-Richards también resultó ser el mejor para describir el crecimiento en altura dominante de Pinus cooperi en la región de El Salto, Durango, destacando que los otros modelos comparados por estos autores fueron también el de Korf y Hossfeld. Los resultados de este trabajo también son consistentes con los reportados por Santiago et al. (2009). Con base en lo anterior se decidió seleccionar el modelo de Bertalanffy-Richards para posteriores análisis.
Modelización de la estructura del error
Una vez seleccionado el mejor modelo (ecuación 6), se procedió a ajustarlo nuevamente integrando un modelo autorregresivo de segundo grado (CAR(2)) con la finalidad de corregir la potencial autocorrelación de los errores. La Figura 5 ilustra la tendencia de los residuales al ajustar la ecuación 6 sin tener en cuenta la autocorrelación de los errores. Después de la corrección de la autocorrelación usando el modelo autorregresivo de segundo orden, la tendencia en los residuales desaparece (Figura 5).

Figura 5. Residuos frente a: residuos de la observación anterior (residuos LAG1) y residuos de la observación realizada tres mediciones antes (residuos LAG3) para la ecuación [6] ajustada a los datos de P. arizonica Engelm., P. durangensis Martínez, P. leiophylla Schiede ex Schltdl. & Cham. y P. teocote Schiede ex Schltdl. & Cham, sin considerar los parámetros autocorregresivos (1ª columna) y usando un modelo autorregresivo de orden 2 CAR (2) (2ª columna).
Figure 5. Residuals versus residues of the previous observation (LAG1 residuals) and residuals of the observation made three measurements earlier (LAG3 residuals) to the equation [6] fitted to the data of P. arizonica Engelm., P. durangensis Matínez, P. leiophylla Schiede ex Schltdl. & Cham. and P.teocote Schiede ex Schltdl. & Cham., regardless of the autocorregresive parameters (1st column)and using an autoregressive model of a 2 CAR (2) order (2nd column).
El modelo que considera la corrección de la autocorrelación de los errores explica por encima del 99% de la varianza del crecimiento en altura dominante de todas las especies (Cuadro 4), con un error medio entre 0.60 (P. teocote) y 0.69 m (P. arizonica y P. leiophylla), valores ligeramente menores a los obtenidos en el ajuste sin considerar el modelo autorregresivo (Cuadro 3), además de proveer un patrón aleatorio de los residuos alrededor de la línea del cero con varianza homogénea y sin detectarse ninguna tendencia clara (Figura 6); estos son resultados similares a los obtenidos por Diéguez-Aranda et al. (2005), Corral-Rivas et al. (2004) y Vargas-Larreta et al. (2010).
Cuadro 4. Estimaciones de los parámetros y estadísticos de bondad de ajuste del modelo 6 integrando un modelo autorregresivo CAR(2).
Table 4. Parameter estimates and goodness-of-fit of the model 6 CAR integrated autoregressive model (2).

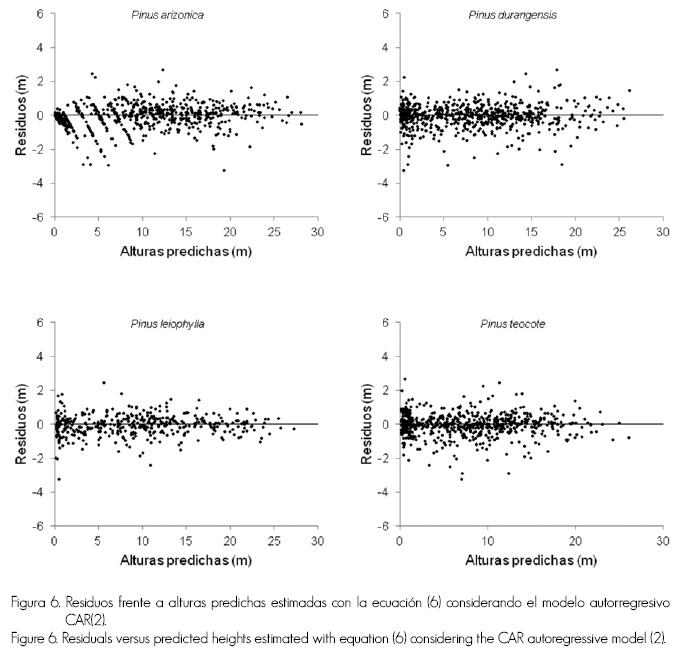
Figura 6. Residuos frente a alturas predichas estimadas con la ecuación (6) considerando el modelo autorregresivo CAR(2).
Figure 6. Residuals versus predicted heights estimated with equation (6) considering the CAR autoregressive model (2).
Es importante señalar que desde el punto de vista práctico, los parámetros ρ1 y ρ2, utilizados para modelar la estructura del error, generalmente no se utilizan (Diéguez-Aranda et al., 2006). El propósito principal de modelar la estructura del error es obtener estimaciones consistentes de los parámetros y sus errores estándar, y el parámetro especifico de la calidad de estación estimado para cada individuo se suprime de forma similar como en el proceso de autocorrelación (Cieszewski, 2001), así, la altura estimada en función de su edad en un nuevo individuo se incorpora directamente para realizar predicciones.
La expresión final de la ecuación en forma GADA para cada especie basada en el modelo de Bertalanffy-Richards se muestra en el Cuadro 5, mientras que en la Figura 7, las curvas de calidad generadas con las mencionadas ecuaciones (8, 9, 10 y 11) (Cuadro 5).
Cuadro 5. Expresión final de las ecuaciones desarrolladas.
Table 5. Final expression of the formulated equations.
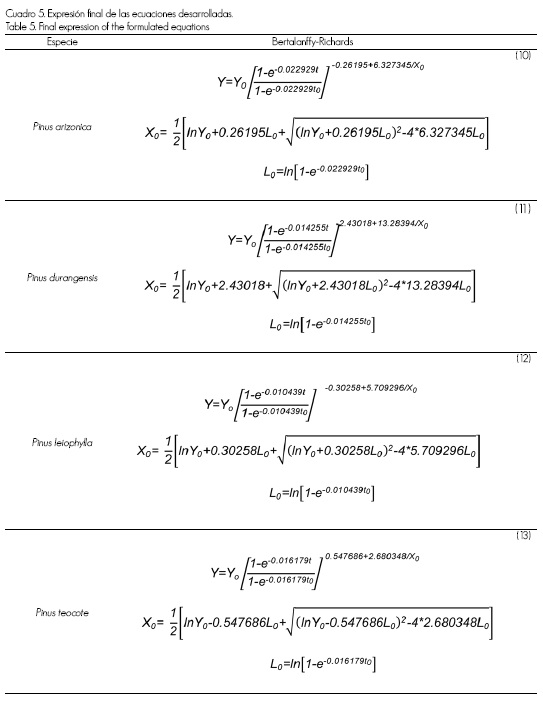

Figura 7. Curvas de calidad a la edad de referencia de 50 años para P. arizonica (arriba-izq.), P. durangensis (arriba-der.), P. leiophylla (abajo-izq.) y P. teocote (abajo-der.) construidas con el modelo dinámico de Bertalanffy-Richards ajustado con el modelo autorregresivo CAR(2).
Figure 7. Quality curves at the reference age of 50 years for P. arizonica Engelm. (up-left), P. durangensis Martínez up-right), P. leiophylla Schiede ex Schltdl. & Cham. (down-left) and P. teocote Schiede ex Schltdl. & Cham.(down-right) built with the dynamic model of Bertalanffy-Richards fitted with the CAR(2) autoregressive model.
Donde:
Y0 = Altura dominante (m) a la edad t0 (años)
Y = Altura estimada (m) a la edad t (años)
Conclusiones
Los parámetros de bondad de ajuste no mostraron diferencias significativas entre modelos, sin embargo, el análisis grafico permitió concluir que el modelo de Bertalanffy-Richards fue el que presentó el comportamiento biológico más lógico al sobreponer las curvas de índice de sitio sobre los datos originales.
Las ecuaciones obtenidas son polimórficas con múltiples asíntotas e invariantes con respecto a la edad de referencia, además estiman directamente la altura dominante y el índice de sitio a cualquier altura y edad de referencia.
El uso de estas ecuaciones permitirá mejorar significativamente la estimación actual del potencial productivo de las especies estudiadas, a través de su incorporación a los programas de manejo forestal vigentes para la región forestal de Santiago Papasquiaro, Durango.
Referencias
Álvarez-González, J. G., M. Barrio, F. Castedo, U. Diéguez-Aranda y A. D. Ruíz-González. 2005. Modelos para la gestión forestal: una revisión de las metodologías de construcción de modelos de masa. EDP Sciences. Madrid, España. 13 p. [ Links ]
Bailey, R. and J. Clutter. 1974. Base-age invariant polymorphic site curves. For. Sci. (20):155-159. [ Links ]
Barrio-Anta, M., F. Castedo-Dorado, U. Diéguez-Aranda, J. G. Álvarez-González, B. R. Parresol and R. Rodríguez Soalleiro. 2006. Development of a basal area growth system for maritime pine in northwestern Spain using the generalized algebraic difference approach. Can. J. For. Res. 36(6): 1461-1474. [ Links ]
Carmean, W. H. 1972.Site index curves for upland oaks in the Central States. For. Sci. 18:109-120. [ Links ]
Castedo-Dorado, F., U. Diéguez-Aranda, M. Barrio-Anta and J. G. Álvarez-González. 2007. Modelling stand basal area growth for radiata pine plantations in northwestern Spain using the GADA. Ann. For. Sci. 64: 609-619. [ Links ]
Cieszewski, C. J. 2001. Three methods of deriving advanced dynamic site equations demonstrated on inland Douglas-fir site curves. Can. J. For. Res. 31:165-173. [ Links ]
Cieszewski, C. J. 2002. Comparing fixed-and variable-base-age site equations having single versus multiple asymptotes. For. Sci. 48:7-23. [ Links ]
Cieszewski, C. J. 2003. Developing a well-behaved dynamic site equations using a modified Hossfeld IV function Y3=(axm)/(c+xm-1), a simplified mixed-model and scant subalpine fir data. For. Sci. 49:539-554. [ Links ]
Cieszewski, C. J. and R. L. Bailey. 2000. Generalized algebraic difference approach: theory based derivation of dynamic site equations with polymorphism and variable asymptotes. For. Sci. 46(1): 116-126. [ Links ]
Clutter, J., J. Fortson, L. Piennar, H. Brister and R. Bailey. 1983. Timber management: a quantitative approach. John Wiley & Sons, Inc. New York, NY USA. 125 p. [ Links ]
Corral-Rivas, J. J., J. G. Álvarez-González, A. D. Ruíz and K. Gadow. 2004. Compatible height and site index models for five pine species in El Salto, Durango (Mexico). For. Ecol. Manage. 201:145-160. [ Links ]
Davis L., S., K. N. Johnson, P. S. Bettinger and T. E. Howard. 2001. Forest Management: to sustain ecological, economic and social values. McGraw-Hill Series in Forest Resources. 4th Ed. New York, NY USA. 804 p. [ Links ]
Diéguez-Aranda, U., J. G. Álvarez-González, M. Barrio-Anta and A. Rojo-Alboreca. 2005. Site quality equations for Pinus sylvestris L. plantations in Galicia (north-west Spain). Ann. For. Sci. 62: 143-152. [ Links ]
Diéguez-Aranda, U., H. E. Burkhart and R. L. Amateis. 2006. Dynamic Site Model for Loblolly Pine (Pinus taeda L.) plantations in the United States. For. Sci. 52(3): 262-272. [ Links ]
Diéguez-Aranda, U., A. Rojo-Alboreca, F. Castedo-Dorado, J. G. Álvarez-González, M. Barrio-Anta, F. Crecente-Campo, J. M. González-González, C. Pérez-Cruzado, R. J. Rodríguez-Soalleiro, C. A. López-Sánchez, M. A. Balboa-Murias, J. J. Gorgoso-Varela y F. Sánchez-Rodríguez. 2009. Herramientas silvícolas para la gestión forestal sostenible en Galicia. Dirección Xeral de Montes, Consellería do Medio Rural, Xunta de Galicia. 272 p. [ Links ]
Dyer M., E. and R. L. Bailey. 1987. A test of six methods for estimating true heights from stem analysis data. For. Sci. 33:3-13. [ Links ]
Fabbio, G., M. Frattegiani and C. C. Manetti. 1994. Height estimation in stem analysis using second differences. For. Sci. 40: 329-340. [ Links ]
García, A. and M. S. González. 2003. Pináceas de Durango. Instituto de Ecología, A.C. - CONAFOR. Durango, México. 90 p. [ Links ]
Gregoire T., G., O. Schabenberger and J. P. Barrett. 1995. Linear modelling of irregularly spaced, unbalanced, longitudinal data from permanent-plot measurements. Can. J. For. Res. 25:137-156. [ Links ]
Newberry J., D. 1991. A note on Carmean’s estimate of height from stem analysis data. For. Sci. 37(1):368-369. [ Links ]
Prodan, M., R. Peters, F. Cox y P. Real. 1997. Mensura forestal. Instituto Interamericano de Cooperación para la Agricultura (IICA)/Deutsche Gesellschaft für Technische Zusammemarbeit (GTZ). San José, Costa Rica. 561 p. [ Links ]
Ryan, T. P. 1997. Modern regression methods. John Wiley and Sons, Inc. New York, NY USA. 128 p. [ Links ]
Santiago J., W. 2009. Método de diferencias algebraicas generalizado para la estimación del índice de sitio de Pinus cooperi Blanco, en El Salto, Durango. Tesis de Maestría. Instituto Tecnológico de El Salto, Dgo. 41 p. [ Links ]
System Statistical Analysis (SAS). 2004. User´s Guide SAS. SAS/ETS™. Version 9.1. SAS Institute Inc. Cary, NC USA. s/p [ Links ]
Vargas-Larreta, B., J. G. Álvarez-González, J. J. Corral-Rivas y O. Aguirre C. 2010. Construcción de curvas dinámicas de índice de sitio para Pinus cooperi Blanco. Fitotecnia Mexicana. 33(4):343-351. [ Links ]
Zimmerman D., L. and V. Núñez-Antón. 2001. Parametric modelling of growth curve data: An overview (with discussion). Test 10:1-73. [ Links ]

