










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista mexicana de ciencias pecuarias
versión On-line ISSN 2448-6698versión impresa ISSN 2007-1124
Rev. mex. de cienc. pecuarias vol.3 no.4 Mérida oct./dic. 2012
Notas de Investigación
Prueba de grupo. Una eficiente alternativa para estimar prevalencia animal
Group testing. An efficient alternative for estimating animal prevalence
Osval Antonio Montesinos Lópeza, Abelardo Montesinos Lópezb, Ignacio Luna Espinozac, Laura Sanely Gaytán Lugod, Teodoro Espinosa Solarese
a Facultad de Telemática, Universidad de Colima, Colima, México. oamontes1@ucol.mx. Correspondencia al primer autor.
b Departamento de Estadística, Centro de Investigación en Matemáticas (CIMAT).
c Universidad del Itsmo, Campus Ixtepec.
d Facultad de Ingeniería Mecánica y Eléctrica. Universidad de Colima.
e Departamento de Ingeniería Agroindustrial. Universidad Autónoma Chapingo.
Recibido el 3 de Junio de 2010.
Aceptado el 17 de Octubre de 2011.
RESUMEN
La estimación de prevalencia animal o detección de agentes infecciosos, es de vital importancia para una nación o estado para proteger su seguridad alimentaria y garantizar el comercio local y exterior. Sin embargo, realizar estas dos tareas (estimación y detección) eficientemente requiere de significativos recursos materiales y humanos. Por ello, el presente artículo presenta una revisión del proceso de estimación y detección usando la técnica estadística conocida como prueba de grupo (group testing) que puede contribuir al ahorro de recursos cuantiosos para la estimación y detección de enfermedades infecciosas en ciencia animal cuando la prevalencia es menor o igual al 10%. Group testing es una ingeniosa técnica estadística propuesta por Dorfman (1943). Esta técnica consiste en juntar el material de k individuos, mezclarlos perfectamente y en lugar de realizar una prueba de laboratorio para cada individuo, se realiza una sola prueba con la mezcla de los k individuos. De esta forma se logran ahorros significativos. Por ello, se muestra el funcionamiento de algunos métodos para clasificar individuos; se expone el proceso de estimación puntual y por intervalo de prevalencia animal; y se ilustra el cálculo del tamaño de muestra bajo este modelo, con la finalidad de que los investigadores en ciencia animal la utilicen y ahorren recursos significativos.
Palabras clave: Prueba de grupo, Prevalencia animal, Tamaño de muestra, Estimación, Detección.
ABSTRACT
An estimate of animal prevalence or the detection of infectious agents is of vital importance to a country or state to protect food safety and to safeguard local and foreign trade. However, significant human and material resources are required to perform these two tasks. This article presents an overview of the estimate and detection processes with the statistical technique known as group testing. In animal science, group testing can help save substantial resources in the estimate and detection of infectious diseases when the prevalence is less than or equal to 10%. Group testing is a sound statistical technique proposed by Dorfman (1943). It consists of mixing the material of k individuals. Instead of a diagnostic test for each individual, only one test is performed with the resulting mixture of the material. This allows significant savings. Furthermore, this paper presents some methods to classify individuals, it describes the process of point and interval estimation of animal prevalence, and it illustrates the calculation of sample size according to this model. The intention is to help researchers in animal science to use this technique and save significant resources.
Key Words: group testing, animal prevalence, sample size, estimate, detection.
El método de prueba de grupo (group testing) fue propuesto por Dorfman(1) para detectar individuos con sífilis durante la segunda guerra mundial. La esencia de esta técnica consiste en mezclar el material (sangre en el caso de Dorfman) de k individuos y sobre esta mezcla realizar una sola prueba de laboratorio. Si la prueba del grupo (mezcla de k individuos) resulta positiva, entonces se realizan pruebas individuales a los individuos dentro del grupo positivo para identificar a los individuos enfermos. Por otro lado, si la prueba de grupo resulta negativa, se concluye que los k individuos que forman el grupo están libres de dicha enfermedad. Es importante mencionar que la selección de los individuos para formar los grupos se hace de manera aleatoria (Figura 1).
La prueba de grupo se ha utilizado para estimar y detectar diversas enfermedades, como el virus de inmunodeficiencia humana (VIH), hepatitis B y C, y el virus del Nilo (West Nile virus)(2). También se ha usado para detectar enfermedades en la donación de sangre(3); para detectar drogas(4); para estimar la prevalencia y detección de enfermedades humanas(5), de plantas(6) y de animales(7); para detectar plantas transgénicas(8,9); para resolver problemas de teoría de la información(10) y hasta de ciencia ficción(11).
La gran aceptación de esta técnica obedece principalmente al ahorro significativo de recursos materiales y económicos que produce. En el contexto de enfermedades infecciosas, la prueba de grupo es típicamente usada para: 1) detectar o identificar individuos que tienen cierta enfermedad; y 2) para estimar la prevalencia de enfermedades, es decir, para estimar la proporción p de individuos en la población que tienen una enfermedad específica(12).
A pesar de la amplia gama de aplicaciones y ventajas por usar la prueba de grupo, ésta es subutilizada en los países en vías de desarrollo. En los países desarrollados, su uso en los laboratorios de salud pública es reciente. Por ejemplo, sólo 12% de los laboratorios de Estados Unidos reportan el empleo de esta técnica(13). También se reporta que más de 15 % de las bases de datos utilizadas para detectar expresiones genéticas utilizan pruebas de grupo(14). La subutilización de la prueba de grupo obedece básicamente a que la mayor parte de las aplicaciones son altamente técnicas y teóricas, lo cual ha restringido su aplicación directa por directores de laboratorios y técnicos laboratoristas(2).
Este trabajo hace una revisión sobre la prueba de grupo, resaltando sus ventajas y desventajas. También se presentan algunos métodos para clasificar individuos, los estimadores apropiados para el proceso de estimación puntual y por intervalo de la prevalencia de enfermedades, la determinación del tamaño de muestra, y las restricciones bajo las cuales la prueba de grupo no produce buenos resultados.
Cuando la prueba de grupo se utiliza para detectar enfermedades y el grupo resulta positivo, entonces a los individuos que conforman dicho conjunto se les realiza una prueba de laboratorio en forma individual, o en subgrupos hasta identificar a todos los individuos que padecen la enfermedad; es decir, si el grupo resulta positivo, entonces se requieren de pruebas de laboratorio adicionales ("retesting") para identificar a los individuos positivos. Por otro lado, cuando el propósito es sólo la estimación de la prevalencia, si el grupo resulta positivo, entonces ya no se realizan pruebas adicionales a los individuos o subgrupos que conforman al grupo positivo.
Los algoritmos para detectar o clasificar individuos positivos se pueden dividir en jerárquicos y arreglos matriciales. Dentro de los jerárquicos se tienen el modelo de Dorfman, el método de Sterrett's, y el método "halving".
El procedimiento de Dorfman realiza una prueba individual a cada elemento dentro de un grupo que resultó positivo. Por lo tanto, si un grupo de tamaño k resulta positivo, entonces se requerirán k+1 pruebas de laboratorio para clasificar a todos los individuos que conforman al grupo positivo; pero si el grupo resulta negativo, entonces se declaran libres de la enfermedad a los k individuos que lo conforman.
El número relativo esperado de pruebas de laboratorio individuales (X) usando el procedimiento de Dorfman, es igual a 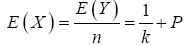 ; donde E (Y) es el número esperado de pruebas requeridas usando pruebas por grupo, n (tamaño de muestra) es el número de pruebas requeridas haciendo pruebas individuales, P denota la probabilidad de que un grupo sea positivo y se determina por
; donde E (Y) es el número esperado de pruebas requeridas usando pruebas por grupo, n (tamaño de muestra) es el número de pruebas requeridas haciendo pruebas individuales, P denota la probabilidad de que un grupo sea positivo y se determina por 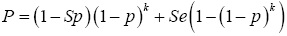 , Se y Sp son lasensibilidad y es pecificidad de la prueba de laboratorio, respectivamente, y p es la prevalencia de la enfermedad en la población. Por lo tanto, el porcentaje de ahorro esperado realizando pruebas adicionales es igual a 100(1-E(X))%, mientras que sin pruebas adicionales es igual a 100(1-1/k)%.
, Se y Sp son lasensibilidad y es pecificidad de la prueba de laboratorio, respectivamente, y p es la prevalencia de la enfermedad en la población. Por lo tanto, el porcentaje de ahorro esperado realizando pruebas adicionales es igual a 100(1-E(X))%, mientras que sin pruebas adicionales es igual a 100(1-1/k)%.
Aunque este procedimiento produce ahorros significativos, existen otros procedimientos que son aún más eficientes(11).
El método de Sterrett' (1957) es más eficiente que el de Dorfman porque requiere de menos pruebas de laboratorio. Bajo el supuesto de haber encontrado un grupo positivo, este método consiste en seleccionar al azar a individuos dentro del grupo positivo y a cada individuo realizarle una prueba de laboratorio hasta que se encuentre un positivo. Una vez encontrado el primer individuo positivo, los demás elementos de este grupo se mezclan para formar un nuevo grupo. Si este nuevo grupo resulta negativo en la prueba de laboratorio, el proceso de clasificación termina, y los individuos dentro del nuevo grupo son declarados negativos. Si el nuevo grupo resulta positivo, el proceso comienza nuevamente seleccionando individuos al azar y realizándoles la prueba de laboratorio hasta encontrar otro positivo (el segundo). Una vez que el segundo positivo ha sido encontrado, los demás individuos de este grupo son mezclados nuevamente para formar otro grupo y determinar si este es positivo o negativo. Este proceso se repite hasta que ya no se encuentran grupos o individuos positivos(11).
El procedimiento halving es otro método jerárquico y consiste en dividir a la mitad a los grupos que resultan positivos y aplicar una prueba de laboratorio a cada mitad. Si las dos mitades resultan negativas, el proceso de clasificación termina; pero si al menos una resulta positiva, se subdivide a la mitad nuevamente y se aplica otra vez la prueba de laboratorio a cada una de éstas. Por ejemplo, suponiendo que un grupo de tamaño 16 resulta positivo; este grupo se divide en dos subgrupos de tamaño ocho y a cada subgrupo se le aplica una prueba de laboratorio. Cualquier nuevo grupo que resulte positivo se subdivide en grupos de tamaño cuatro. De igual manera, si alguno de estos sub-subgrupos resulta positivo, entonces se divide en grupos de tamaño dos y finalmente a los grupos que resulten positivos se les aplican pruebas individuales. Cuando el grupo no es divisible entre dos, se forman dos subgrupos de tamaño diferente. Por ejemplo, un grupo de tamaño 11 puede dividirse en dos grupos, uno de tamaño seis y otro de tamaño cinco. Para el grupo de tamaño cinco, la subdivisión pude ser un grupo de tamaño tres y otro de tamaño dos, y finalmente el grupo de tamaño tres puede sub-subdividirse en un grupo de tamaño dos y un grupo con sólo un elemento(11).
Dentro de los arreglos matriciales, los arreglos cuadrados son los más comunes. Los arreglos cuadrados consisten en acomodar k2 individuos en una matriz de orden kxk. Con la muestra se forman grupos de tamaño k con los elementos de la misma hilera o la misma columna. Bajo el supuesto de que no existen pruebas falsas negativas, los 2k grupos son analizados. En este escenario, todos los individuos positivos ocurrirán en la intersección de un grupo hilera positivo y un grupo columna positivo. Cuando más de una hilera y columna resultan positivas, se realizan pruebas individuales a los individuos que se encuentran en la intersección hilera-columna, completando así el proceso de clasificación. Algunas veces el tamaño de muestra no es múltiplo de k2. Por ejemplo, suponiendo que se dispone con una cuadricula de 15x15 para las pruebas de laboratorio y se necesitan clasificar 245 individuos. Esta cuadricula hace buen trabajo para los primeros 225 individuos, pero no para los restantes 20. Los 20 individuos pueden tratarse usando una hilera de tamaño 15 y los otros cinco elementos empleando el procedimiento de Dorfman(11). En la Figura 2 se muestran gráficamente tres estrategias para la utilización de la prueba de grupo utilizando los algoritmos mencionados.
Es importante mencionar que en los arreglos matriciales también existen arreglos rectangulares, así como otras modificaciones a los procedimientos jerárquicos, los cuales pueden consultarse en Kim y colaboradores(12).
Cuando el único objetivo es la estimación de la prevalencia (p), una vez que se determina el estado de cada grupo, positivo o negativo, no es necesario realizar retesting en los grupos que resultaron positivos, ya que para realizar la estimación de la prevalencia es suficiente disponer sólo con la información del estado de los grupos originales. Es decir, en la estimación de la prevalencia de una enfermedad no se realizan pruebas adicionales a los grupos que resultaron positivos, sólo es necesario conocer el número de grupos positivos ( y ) resultantes entre los g grupos de tamaño k. Los g grupos se forman con los n elementos que integran la muestra seleccionada.
A continuación se presentan los estimadores de la proporción, la varianza, los intervalos de confianza y el cálculo del tamaño de muestra bajo el marco de la prueba de grupo. El proceso se ilustra estimando la prevalencia de una enfermedad.
Sin utilizar la prueba de grupo y considerando que la prueba de laboratorio es perfecta, el estimador de máxima verosimilitud (EMV) de p es igual a: 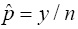 , donde y es el número de individuos que resultaron positivos en la prueba de laboratorio entre los n que conforman la muestra.
, donde y es el número de individuos que resultaron positivos en la prueba de laboratorio entre los n que conforman la muestra.
Cuando se utiliza la prueba de grupo y se asume que la prueba de laboratorio no es perfecta, de acuerdo con Tu y colaboradores(15) el EMV de la proporción p es igual a:

donde g es el número de grupos formados con los n individuos de la muestra y cada grupo es de tamaño k (el tamaño de grupo es el número de individuos a mezclar por grupo); y es el número de grupos positivos; Se es la sensibilidad de la prueba de laboratorio y Sp es la especificidad. Se asume que tanto Se como Sp son mayores a 0.5, lo cual aplica en la mayoría de las pruebas de laboratorio. Para que exista el EMV se requiere que 1 - Sp ≤ y / g ≥ Se, esto asegura que p esté entre cero y uno. En un contexto de baja prevalencia es necesario que 1 - Sp ≤ y / g . Cuando esta condición no se cumple y bajo una especificidad dada, se observarán menos grupos positivos de lo esperado, dando como resultado un valor negativo para p. Cabe mencionar que si Sp=Se=1 , el EMV de p se reduce a 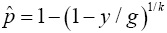 . Si además el tamaño del grupo es igual a k=1, el EMV de p en la Ecuación (1) se reduce a . Por otro lado, si Se, Sp < 1 y k=1, entonces
. Si además el tamaño del grupo es igual a k=1, el EMV de p en la Ecuación (1) se reduce a . Por otro lado, si Se, Sp < 1 y k=1, entonces 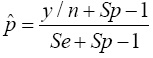 .
.
Se ha documentado que usando prueba de grupo, el estimador de p en la Ecuación (1) es sesgado hacia la derecha, con una magnitud de sesgo aproximadamente igual a [(k-1) Var(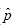 )] /[2(1 -p)](15). Sin embargo, el sesgo es insignificante cuando el número de individuos n=gk es grande, el tamaño del grupo es moderado y la proporción a estimar es menor de 10%.
)] /[2(1 -p)](15). Sin embargo, el sesgo es insignificante cuando el número de individuos n=gk es grande, el tamaño del grupo es moderado y la proporción a estimar es menor de 10%.
De acuerdo con Tu y colaboradores(15), la varianza estimada del estimador dado en la Ecuación (1) es:
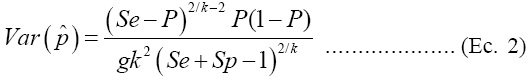
donde 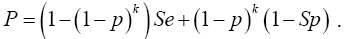 P es la probabilidad de que un grupo sea positivo. De igual manera, si Sp=Se=1, entonces la varianza de p se reduce a
P es la probabilidad de que un grupo sea positivo. De igual manera, si Sp=Se=1, entonces la varianza de p se reduce a 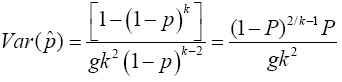 con P = 1 -(1 - p)k. Si no se conoce P, una estimación de la varianza puede obtenerse sustituyendo P por
con P = 1 -(1 - p)k. Si no se conoce P, una estimación de la varianza puede obtenerse sustituyendo P por 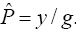
El correspondiente intervalo de confianza (IC) de Wald para p, de acuerdo con Hepworth(16) y Tebbs y colaboradores(17), es igual a:

donde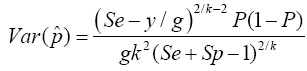 ;
; 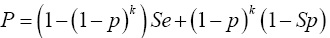 ; Z1-α/2 es el cuantil 1-α/2 de la distribución normal estándar; y
; Z1-α/2 es el cuantil 1-α/2 de la distribución normal estándar; y 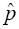 ; es el EMV calculado con la Ecuación (1).
; es el EMV calculado con la Ecuación (1).
El IC aproximado dado en la Ecuación (3) es fácil de calcular y permite derivar una solución analítica (fórmula) para el tamaño de muestra. Sin embargo, cuando g y p son pequeños la aproximación normal para el IC no es muy buena, produciendo limites negativos para el IC(16,17). Además, la probabilidad de cobertura del IC es a menudo menor que la probabilidad nominal 100(1 -α)%.
Otro IC con solución analítica que ha demostrado tener cobertura muy cercana a la nominal 100(1 -a)%, es el intervalo de Wilson(6). Para su construcción primero se forma el intervalo de confianza en términos de grupos, el cual es igual a:
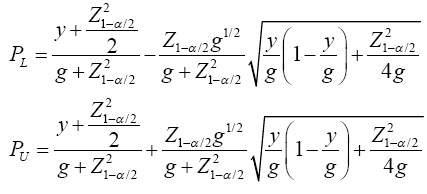
Posteriormente se determina el IC para p de la siguiente forma:
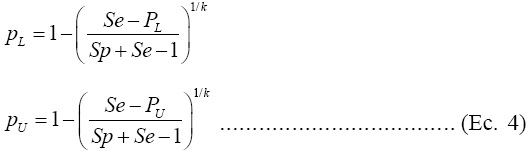
Este intervalo es superior al de Wald porque la distribución de p es menos simétrica. También se puede construir un IC para p transformando el intervalo de Clopper-Pearson(18) en términos de P. En la escala de grupo, los límites inferior y superior del IC son: PL = B α/2,y,g-y+1 y PU = B 1-α/2,y+1,g-y, , respectivamente, donde Bγ,a,b es el cuantil γ de la distribución beta(a,b)(6). Los límites inferior y superior para p se obtienen empleando a PL y Pu en la Ecuación (4). El límite inferior es igual a cero cuando y=0, mientras que el superior es igual a uno cuando y =g. El intervalo de Clopper-Pearson(18) es exacto pero no tiene solución analítica. Diversas investigaciones señalan que el IC de Wilson produce resultados mejores al IC de Clopper-Pearson, con la ventaja de que el IC de Wilson tiene solución analítica.
Para determinar el tamaño de muestra, Montesinos-López y colaboradores(19) proporcionaron una expresión que asegura precisión en la estimación de la proporción p asumiendo sensibilidad y especificidad de 100%. La expresión está dada por:
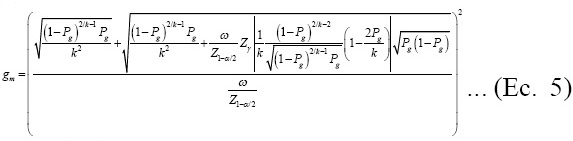
donde γ representa el nivel de seguridad deseado (probabilidad requerida) para que la amplitud del IC (W) para p no sea más amplia que el valor deseado (ω ); Zγ es el cuantil γ de la distribución normal estándar; y Pg = 1 -(1 - p )k es la probabilidad de que un grupo sea positivo. Note que si γ =0.5, entonces Zγ=0.5 = 0(el cuantil 50% de una distribución normal estándar); en este caso la formula que determina el número de grupos, dada en la Ecuación (5 ), se reduce a 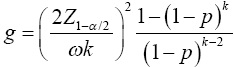 , asumiendo que la varianza de la proporción, V (), es conocida y fija. En la práctica se desconoce a V (); esto implica que la amplitud deseada del IC se alcance sólo 50% de las veces. Por otro lado, si k=1, la Ecuación (5) se reduce a:
, asumiendo que la varianza de la proporción, V (), es conocida y fija. En la práctica se desconoce a V (); esto implica que la amplitud deseada del IC se alcance sólo 50% de las veces. Por otro lado, si k=1, la Ecuación (5) se reduce a:
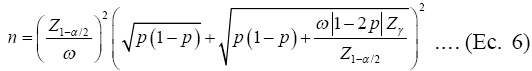
Esta fórmula (Ecuación 6) es apropiada para determinar el tamaño de muestra sin usar pruebas de grupo (sin formar grupos), garantizando que W será menor a a con una probabilidad γ. La Ecuación (6) es la contraparte analítica a los tamaños de muestra exactos propuestos por Montesinos-López y colaboradores(18) en el caso de muestreo aleatorio simple. En otras palabras, solo 100(1- γ )% de las veces W será más grande que la amplitud deseada del IC, ω.
También note que si γ =0.5, la Ecuación 6 (sin usar pruebas de grupo) se simplifica a la fórmula 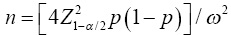 , la cual es el tamaño de muestra estándar para estimar una proporción bajo muestreo aleatorio simple (MAS); aunque en esta última expresión la naturaleza estocástica de la amplitud del IC no es considerada.
, la cual es el tamaño de muestra estándar para estimar una proporción bajo muestreo aleatorio simple (MAS); aunque en esta última expresión la naturaleza estocástica de la amplitud del IC no es considerada.
La Ecuación (5), propuesta por Montesinos-López y colaboradores(19), determina el tamaño de muestra mínimo, gm , que garantiza que W será menor o igual a ω con una probabilidad de al menos γ ; esto se logra porque la Ecuación (5) considera la naturaleza estocástica de la varianza, V(), vía el nivel de aseguramiento γ. Por esta razón γ ≥ 0.5 . Es importante mencionar que la expresión (5) se derivó usando el intervalo de Wald para pruebas de grupo, por lo que estos tamaños de muestra son aproximados. Para investigadores interesados en tamaños de muestra para group testing (prueba de grupo) exactos usando el intervalo de Clopper-Pearson, los puede encontrar en Montesinos-López y colaboradores(19); sin embargo, estos tamaños de muestra no tienen solución analítica.
Para la aplicación exitosa de este método, se debe cuidar la elección del tamaño del grupo (k) para que la sustancia de interés no se diluya y afecte la sensibilidad de las pruebas de laboratorio y, por ende, no se aumente la tasa de falsos negativos. Por lo tanto, la elección apropiada del tamaño de grupo g es vital para obtener estimaciones precisas y con ahorros de recursos significativos. Un grupo demasiado grande puede provocar que se diluya la sustancia de interés y se incremente la tasa de falsos negativos; mientras que un grupo demasiado pequeño produce pocos ahorros.
Para determinar el tamaño del grupo k se han propuesto varios métodos. Por ejemplo,
Thompson(20) propone utilizar 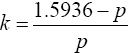 k , el cual minimiza el cuadrado medio del error. Chiang y Reeves(21) sugieren un tamaño de grupo igual a k = log(1/2) / log(1 - p), el cual produce grupos positivos y negativos con la misma probabilidad(22). Otra forma exclusiva para el método de Dorfman(1) en dos etapas, consiste enelegir k=p-1/2. Hernández-Suárez y colaboradores(8) proponen usar k = ( c / d) -1, donde c, la concentración de la sustancia de interés por individuo, y d, el límite de detección de la prueba de laboratorio, son conocidos. Este método produce valores muy grandes de k, como el método de Thompson(20).
k , el cual minimiza el cuadrado medio del error. Chiang y Reeves(21) sugieren un tamaño de grupo igual a k = log(1/2) / log(1 - p), el cual produce grupos positivos y negativos con la misma probabilidad(22). Otra forma exclusiva para el método de Dorfman(1) en dos etapas, consiste enelegir k=p-1/2. Hernández-Suárez y colaboradores(8) proponen usar k = ( c / d) -1, donde c, la concentración de la sustancia de interés por individuo, y d, el límite de detección de la prueba de laboratorio, son conocidos. Este método produce valores muy grandes de k, como el método de Thompson(20).
Los criterios para seleccionar el tamaño de grupo dados anteriormente, no son siempre la mejor opción en la práctica. Una mejor alternativa consiste en calibrar las pruebas de laboratorio para asegurar precisión en la prueba de grupo, como se realiza con las pruebas de laboratorio individuales.
El tamaño óptimo del grupo k es una función del modelo estadístico y de la naturaleza química de la prueba de laboratorio usada en la detección de grupos positivos. Por ejemplo, si se sospecha que la prevalencia es igual a 1/400, el método de Thompson(20) recomienda un tamaño de grupo de 635, mientras el método de Chiang y Reeves(21) sugiere un tamaño de grupo de 277. Ambos son probablemente más grandes que el tamaño máximo que pueden manejar las pruebas de laboratorio. La mayoría de las pruebas basadas en PCR (polymerase chain reaction) han mostrado que son capaces de manejar un máximo de 100 individuos por grupo, con niveles de sens ibilidad y especificidad aceptables(22). En forma similar, la mayoría de las pruebas basadas en anticuerpos pueden usar un tamaño de grupo máximo de 50 unidades. Esto muestra que la naturaleza bioquímica de las pruebas de laboratorio imponen los límites del tamaño óptimo del grupo. Además, es importante que la sensibilidad y especificidad de las pruebas sea evaluada rigurosamente, considerando varios tamaños de grupo, con la finalidad de elegir el tamaño que asegure la detección de grupos positivos sin hacer un sacrificio importante en la sensibilidad y especificad de la prueba de laboratorio(22).
Suponiendo que un investigador realizó un estudio en una región para estimar la prevalencia animal de una enfermedad. La muestra que utilizó fue de n =10,000 animales, bajo MAS, entre los cuales encontró a tres con dicha enfermedad. Por lo tanto, la prevalencia estimada es de = 3 /10,000, es decir, 0.03%. Dado que el investigador no conocía la existencia de la prueba de grupo, el estudio fue bastante costoso. A continuación se ilustra como usando la prueba de grupo se obtiene una estimación muy precisa de la prevalencia pero con un considerable ahorro de tiempo y recursos materiales y económicos.
La primera línea del Cuadro 1 muestra la estimación de la prevalencia sin usar prueba de grupo (k=1). La prevalencia estimada de la enfermedad en la población es = 3/10,000 = 0.0003; en este caso el porcentaje de ahorro es de cero (0%). Por otro lado, usando la prueba de grupo y bajo el modelo Dorfman, con un tamaño de grupo de k=10 individuos y asumiendo que y =3 grupos son positivos (cada grupo positivo contiene a un solo elemento enfermo dado que se asume que la población tiene exactamente tres individuos enfermos), el número de grupos a considerar es igual a g=10,000/10=1,000, es decir, sin hacer retesting se tiene un ahorro de 90% en la cantidad de pruebas de laboratorio, ya que en lugar de 10,000 pruebas sólo se realizarán 1,000. Realizando retesting en los grupos positivos, el ahorro esperado es de 89.7%. Por otro lado, dado que la prueba de laboratorio es perfecta (Se=Sp=1), la prevalencia estimada con la prueba de grupo con k=10 es igual a:
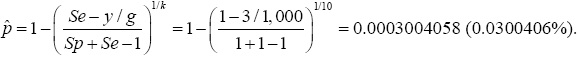
La estimación usando la prueba de grupo (0.0300406%) es ligeramente mayor a la estimación hecha con pruebas individuales (0.03%), aunque está cercano al valor estimado sin usar pruebas de grupo.
Cuando el tamaño del grupo es k=50 y asumiendo el mismo número de grupos positivos y = 3, se forman g=10,000/50=200 grupos, lo cual produce un ahorro de 98% en la cantidad de pruebas de laboratorio requeridas cuando no se realiza retesting y de 96.5% si se realiza retesting en los grupos que resulten positivos. En este caso la prevalencia estimada es igual a:
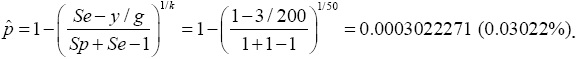
Esto muestra nuevamente que la estimación por usar la prueba de grupo es muy cercana a la prevalencia (Cuadro 1). También se observa que mientras se mantenga el mismo número de grupos positivos (en este caso y =3) las estimaciones puntual y por intervalo de la prevalencia son prácticamente idénticas a la estimación sin el uso de la prueba de grupo. Sin embargo, al incrementar el tamaño del grupo puede ocasionar que se detecten menos de tres grupos positivos. Por ejemplo, si los tamaños de grupo son de 100 ó 200 y sólo se detectan dos grupos positivos, la estimación de la prevalencia (0.0002020067 y 0.0002040891, respectivamente) será menor que la prevalencia sin usar prueba de grupo (0.0003).
Si el tamaño de grupo es muy grande, es muy probable que un grupo tenga más de dos individuos positivos.
Los resultados del Cuadro 1 muestran que aunque la prueba de grupo produce es timaciones ligeramente sesgadas, éstas son muy confiables. Además, hay que tener presente que la prueba de grupo produce buenas estimaciones cuando la proporción a estimar es menor o igual a 0.1 (10%).
Ahora se ilustra la determinación del tamaño de muestra. Suponiendo que un investigador está interesado en estimar la prevalencia p de cierta enfermedad. Se asume que p=0.01; y se requiere un IC de 95%, un tamaño de grupo de k=25, una amplitud absoluta igual a Wx = (pU-pL) ≥ ω = 0.007, y un nivel de aseguramiento de 99 % (γ =0.99). En primer lugar se calcula pg :
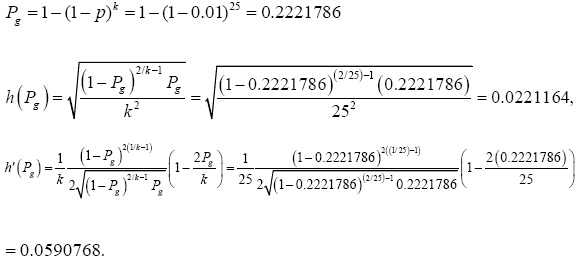
Como se requiere un IC de 95%, entonces Z1-005/2 = 1.96. El nivel de aseguramiento es de 99% (γ = 0.99), así Z099 = 2.33, y k=25. Por lo tanto,
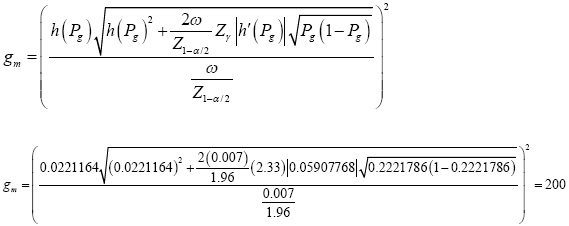
El tamaño de muestra que garantiza con una probabilidad de 99% que la amplitud observada del intervalo de confianza será menor o igual a la amplitud deseada ω =0.007, es igual a 200. Para el cálculo de este tamaño de muestra se utilizó el formato de doble precisión, ya que de no usarse ocurrirá una ligera sobrestimación del tamaño de muestra. Es necesario resaltar que si γ =0.05, el valor de Zγ =0 y el número de grupos requeridos es igual a 140; pero este tamaño de muestra no garantiza buena precisión en la estimación de la proporción.
Para otros escenarios de estimación puede consultarse Montesinos-López y colaboradores(19), donde se proporcionan tablas con diversos valores de los parámetros y un programa en el paquete R para realizar la determinación del tamaño de muestra de forma fácil y rápida. De igual manera, si se desean tamaños de muestra exactos usando pruebas de grupo para estimar una proporción, puede consultarse Montesinos-López y colaboradores(9), donde se proporcionan tablas con su respectivo programa R para calcular los tamaños de muestra.
Finalmente, debido al ahorro significativo de tiempo y recursos materiales y económicos al utilizar las pruebas de grupo, el uso de esta técnica incrementa día a día. Sin embargo, hay que tener presente que esta técnica es útil sólo para estimar prevalencias pequeñas, menores o iguales a 10% cuando la variable respuesta es binaria. Además, también hay que ser cuidadoso en la elección del tamaño de grupo para no incrementar la tasa de falsos negativos, y estar conscientes que el método aquí presentado supone que la distribución de individuos con la característica de interés es homogénea. A pesar de estas restricciones para su aplicación, pero debido a que los gobiernos dan gran importancia a los programas de vigilancia epidemiológica por la creciente amenaza de epidemias, esta técnica puede ser de gran ayuda para los investigadores en ciencia animal para detectar y estimar la prevalencia de enfermedades específicas a costos mucho más bajos. Consecuentemente, con ello se podría disminuir el riesgo de plagas o enfermedades que puedan ocasionar daños a los consumidores y productores. Si bien es cierto que se están creando nuevas generalizaciones para hacer esta técnica más eficiente, aún con sus restricciones se recomienda usar esta técnica porque produce resultados muy precisos y ahorros altamente significativos, lo cual puede ayudar a científicos en países en vías de desarrollo para detectar animales enfermos así como para estimar la prevalencia de ciertas enfermedades que amenazan estas regiones.
LITERATURA CITADA
1. Dorfman R. The detection of defective members of large populations. Ann Math Stat 1943;14(4):436-440. [ Links ]
2. Westreich DJ, Hudgens MG, Fiscus SA, Pilcher CD. Optimizing screening for acute human immunodeficiency virus infection with Pooled Nucleic Acid Amplification tests. J Clin Microbiol 2008;46(5):1785-1792. [ Links ]
3. Dodd R, Notari E, Stramer S. Current prevalence and incidence of infectious disease markers and estimated window-period risk in the American Red Cross donor population. Transfusion 2002;42:975-979. [ Links ]
4. Remlinger K, Hughes-Oliver J, Young S, Lam R. Statistical design of pools using optimal coverage and minimal collision. Technometrics 2006;48:133-143. [ Links ]
5. Verstraeten T, Farah B, Duchateau L, Matu R. Pooling sera to reduce the cost of HIV surveillance: a feasibility study in a rural Kenyan district. Trop Med Int Health 1998;3:747-750. [ Links ]
6. Tebbs J, Bilder C. Confidence interval procedures for the probability of disease transmission in multiple-vector-transfer designs. J Agric Biol Environ Stat 2004; 9(1):79-90. [ Links ]
7. Peck C. Going after BVD. Beef 2006;42:34-44. [ Links ]
8. Hernández-Suárez CM, Montesinos-López OA, McLaren G, Crossa J. Probability models for detecting transgenic plants. Seed Sci Res 2008;18:77-89. [ Links ]
9. Montesinos-López OA, Montesinos-López A, Crossa J, Eskridge K, Hernández-Suárez CM. Sample size for detecting and estimating the proportion of transgenic plants with narrow confidence intervals. Seed Sci Res 2010;20:123-136. [ Links ]
10. Wolf J. Born again group testing - multi access communications. IEEE Transactions on Information Theory 1985;31(2):185-191. [ Links ]
11. Bilder CR. Human or Cylon? Group testing on Battlestar Galáctica. Chance 2009;22(3):46-50. [ Links ]
12. Kim HY, Hudgens MG, Dreyfuss JM, Westreich DJ, Pilcher CD. Comparison of group testing algorithms for case identification in the presence of test error. Biometrics 2007;63:1152-1163. [ Links ]
13. Lindan C, Mathur M, Kumta S, Jerajani H, Gogate A, Schachter J, Moncada J. Utility of pooled urine specimens for detection of Chlamydia trachomatis and Neisseria gonorrhoeae in men attending public sexually transmitted infection clinics in Mumbai, India, by PCR. J Clin Microbiol 2005;43(4):1674-1677. [ Links ]
14. Kendziorski C, Irizarry RA, Chen KS, Haag JD, Gould MN. On the utility of pooling biological samples in microarray experiments. Proc Natl Acad Sci. USA, 2005;102:4252-4257. [ Links ]
15. Tu XM, Litvak E, Pagano M. Studies of AIDS and HIV serveillance, screening tests: can we get more by doing less? Statistics in Medicine 1994;13:1905-1919. [ Links ]
16. Hepworth G. Exact CIs for proportions estimated by group testing. Biometrics 1996;52:1134-1146. [ Links ]
17. Tebbs JM, Bilder CR, Moser BK. An empirical Bayes group-testing approach to estimating small proportions. Communications in statistics: Theory and methods 2003;32(5):983-995. [ Links ]
18. Montesinos-López OA, Montesinos-López A,Santos-Fuentes EE, Valladares-Celis PE, Magaña-Echeverría MA. Tamaños de muestra para estimar prevalencia animal que aseguran cortos intervalos de confianza. Rev Mex Cienc Pecu 2011; 2(2):229-245. [ Links ]
19. Montesinos-López OA, Montesinos-López A, Crossa J, Eskridge K, Sáenz-Casas RA. Optimal sample size for estimating the proportion of transgenic plants using the Dorfman model with a random confidence interval. Seed Sci Res 2011; 21:235-245. [ Links ]
20. Thompson KH. Estimation of the proportion of vectors in a natural population of insects. Biometrics 1962;18:568-578. [ Links ]
21. Chiang CL, Reeves WC. Statistical estimation of virus infection rates in mosquito vector populations. Amer J Hygiene 1962;75:377-391. [ Links ]
22. Katholi CR, Unnasch TR. Important experimental parameters for determining infection rates in arthropod vectors using pool screening approaches. Am J Trop Med Hyg 2006;74:779-785. [ Links ]

