










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
 Citado por SciELO
Citado por SciELO Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista mexicana de ciencias pecuarias
versión On-line ISSN 2448-6698versión impresa ISSN 2007-1124
Rev. mex. de cienc. pecuarias vol.2 no.2 Mérida abr./jun. 2011
Notas de investigación
Tamaños de muestra para estimar prevalencia animal que aseguran cortos intervalos de confianza
Sample size determination for estimating animal prevalence that assure narrow confidence intervals
Osval Antonio Montesinos Lópezª, Abelardo Montesinos Lópezb, Eric Eduardo Santos Fuentesª, Patricia Edwigis Valladares Celisc, Martha Alicia Magaña Echeverríad
ª Facultad de Telemática, Universidad de Colima, Colima, México. oamontes1@ucol.mx. Correspondencia al primer autor.
b Departamento de Estadística, Centro de Investigación en Matemáticas (CIMAT).
c Bachillerato 22. Universidad de Colima, Colima, México.
d Dirección General de Planeación, Universidad de Colima.
Recibido el 22 de enero de 2010
Aceptado el 27 de septiembre de 2010
RESUMEN
El cálculo del tamaño de las muestras juega un rol importante en el diseño óptimo de experimentos veterinarios y agrícolas para la estimación de proporciones de una población, incluyendo la prevalencia de enfermedades. Esta investigación propone un método de tres pasos para determinar el tamaño de muestra exacto para datos binomiales que asegura precisión en la estimación de la proporción, y muestra numéricamente el grado de subestimación que produce el uso de la fórmula tradicional (aproximación normal) para el cálculo del tamaño de la muestra. El paso 1 obtiene un tamaño de muestra que garantiza que la anchura relativa completa del intervalo de confianza (ϖr) es más estrecha que la amplitud deseada (re); el paso 2 incrementa iterativamente el tamaño de muestra hasta que ϖr es mas pequeño que la amplitud deseada (re) con un grado de certeza especificado (γ) y el paso 3 obtiene el número de conglomerados requeridos. Datos simulados fueron creados para ilustrar el método propuesto; además se presenta un cuadro con escenarios útiles para los investigadores. Un programa en el paquete estadístico R es dado y explicado, de tal manera que reproduce los resultados de una manera sencilla.
Palabras clave: Tamaño de muestra, Distribución binomial, Cortos intervalos de confianza, ARCIC.
ABSTRACT
Sample size calculation plays an important role in the design of optimal veterinary and agricultural experiments for estimate population proportions including disease prevalence. This research proposes a method with three steps to determine the exact sample size for a binomial distribution that ensures precision in the estimated proportion and numerically displays the degree of underestimation that occurs using the traditional formula (normal approximation) for calculating the sample size. Step 1 obtain a sample size that guarantees that the relative mean width of the CI (ϖr) is narrower than the desired width (re); the step 2 iteratively increase the sample size until ϖr is smaller than the desired width (re) with a specified degree of certainty (γ) and step 3 get the required number of clusters. Simulated data were created and tables presented showing possible scenarios. An R program is given and explained that will reproduce the results in an easy way.
Key words: Sample size, Binomial distribution, Narrow confidence intervals, CIRW.
Las decisiones en salud animal para los programas de control de enfermedades, comercio de animales, o las certificaciones de estar libre de enfermedades, confían en los conocimientos precisos y con base científica de los estados de salud de animales en una población animal específica. La cuestión fundamental es conocer en qué extensión o magnitud (incidencia/nivel de predominio) ocurre en realidad la enfermedad en la población(1). Por ello, los gobiernos de países desarrollados y en desarrollo le han dando mucha importancia a estos programas de monitoreo y sistemas de vigilancia animal(2).
Cuando se intenta estimar la prevalencia animal o la ausencia de agentes infecciosos en poblaciones, los métodos de muestreo son de suma importancia(3). Por esta razón, el cálculo del tamaño de muestra juegan un papel importante en el diseño óptimo de experimentos veterinarios y agrícolas para la estimación de proporciones en poblaciones, incluyendo la prevalencia de una enfermedad(4). Esto debido a que, una muestra demasiado pequeña no puede asegurar la precisión suficiente en la estimación del parámetro de interés, mientras que una muestra muy grande es un desperdicio innecesario de recursos(5).
En lo que respecta a determinar el tamaño de muestra, tradicionalmente, estadísticos han formulado sus requerimientos en términos de potencia. Este enfoque es consistente con las pruebas de hipótesis para inferencia y presentan los resultados en términos de valores p (p–values). Recientemente, ha crecido mucho el interés en el uso de intervalos de confianza (ICs) en lugar de pruebas de hipótesis para la realización de inferencias(6). De hecho, algunas revistas, reconociendo posibles problemas con las pruebas de hipótesis, últimamente han adoptado políticas editoriales o emitido declaraciones editoriales alentando el uso de ICs en los artículos que en ellas se publican, cuando dichos intervalos son justificados. Una gran ventaja de los ICs en la presentación de resultados en comparación con los valores p (p values que proporcinan las pruebas de hipótesis) es que son relativamente cercanos a los datos, estando en la misma escala de medida, mientras que los valores p (p–values) son una probabilidad abstracta(7). Además, los ICs ayudan a asegurarse no sólo de que la magnitud del efecto puede ser evaluado, si no que el efecto en cuestión puede ser fácilmente identificado por un lector. Es importante destacar que los intervalos de confianza transmiten información sobre magnitudes y precisión, manteniendo estos dos aspectos de medición cercanamente ligados(7,8). El usual intervalo de confianza bilateral es simplemente interpretado como un margen de error de una estimación puntual(7).
Por estas razones una creciente atención se ha dado en el diseño de métodos para calcular tamaños de muestra apropiados para ICs. Este enfoque ha sido denominado precisión en la estimación de parámetros (AIPE por sus siglas en inglés), ya que cuando la anchura del IC con (l–α) 100 % de confianza disminuye, la exactitud esperada en la estimación incrementa(8,9,10). Aunque el enfoque AIPE para la planificación del tamaño de muestra no es nuevo(11), ha sido examinado más en las ciencias sociales que en ciencias veterinarias y agrícolas.
Para determinar los tamaños de muestra, es necesario obtener información de algunos parámetros. No obstante, en la práctica, estos parámetros son desconocidos y son usualmente estimados basándose en literatura o estudios piloto. Estas estimaciones son tratadas como parámetros verdaderos. Consecuentemente, no se toma en cuenta la incertidumbre inducida por dichas estimaciones. Como resultado, el tamaño de muestra resultante puede no alcanzar la anchura deseada para estimar un parámetro como fue planeado(5). Para dar cuenta de tal incertidumbre inducida por usar una estimación del parámetro desconocido, Kelley(8), y Kupper y Hafner(12) enfatizan que la naturaleza estocástica de la anchura del IC debe ser considerada para evitar serias subestimaciones de los tamaños de muestra requeridos para lograr la anchura deseada. En particular, muestran este fenómeno de subestimación en forma numérica para estimar el promedio de una muestra que proviene de una distribución normal y para estimar dos medias que provienen de dos muestras normales asumiendo igualdad de varianzas. Wang y Kupper(13) amplian esta metodología para el caso de muestras aleatorias de dos poblaciones normales con varianzas desiguales.
El objetivo de esta investigación es proponer un método exacto para la determinación de tamaños de muestra (n) para la estimación de la prevalencia animal (proporción binomial; p) que asegura un estrecho IC, esto es, asegurar precisión en la estimación de p. El método requiere tres pasos y fue construido tratando la amplitud del IC de manera aleatoria. El primer paso del método propuesto permite a los investigadores planear los tamaños de muestra para que la anchura relativa completa del IC para p sea lo suficientemente pequeña. Una modificación permite un grado de seguridad deseado (γ) que está incorporado al método, para que el IC obtenido sea lo suficientemente pequeño con alguna probabilidad específica; es decir, el segundo paso toma en cuenta la naturaleza estocástica de la amplitud del IC. El tercer paso proporciona el número de conglomerados requeridos cuando el esquema de muestreo es por conglomerados en dos etapas.
Al planearse el tamaño de la muestra, para obtener una amplitud suficientemente estrecha del IC calculado con el enfoque AI PE, se necesita usar un proceso iterativo(8). Sea pL(X) = pL el límite inferior de confianza de p y pU (X) = pU el límite superior de confianza de p ; para un nivel de confiabilidad especificado, donde X representa la matriz de datos observados sobre los cuales el intervalo de confianza (IC) esta basado. La amplitud completa del IC con el método de Clopper–Pearson(7,14) es w = pU – pL, donde PL = Bα/2,y,n–y+1 y Pu=Bα/2,y,+1,n–y (límites inferior y superior para basados en una distribución Beta(a,b)). No obstante, la amplitud relativa completa del IC (ARCIC) es igual a

Se usará re como la amplitud relativa deseada del IC (error relativo), especificada previamente por el investigador. También, para planear el tamaño de la muestra con los objetivos de AIPE, debe ser conocido (o estimado). Para obtener >(wr), es necesario conocer el tamaño de la muestra (n) así como también el número de eventos (y). Sin embargo, dado que el tamaño de la muestra (n) es desconocido, no es posible conocer cuántos individuos resultarán positivos (y) tras el muestreo. Por lo tanto, wr no puede ser determinada exactamente. No obstante, de acuerdo con Vollset(14) y Newcombe(7), es posible determinar el valor exacto de la ARCIC promediando las amplitudes de los intervalos asociados con el número de eventos de entre 0≤ y ≤n dados n, y p usando la expresión

Donde wr es la ARCIC, que se calcula con la ecuación (1), para Y = y individuos positivos, dados la proporción (p) y el tamaño de muestra (n).
Para determinar el tamaño de muestra óptimo que asegura cortos intervalos de confianza, se requieren dos pasos. El primero, calcula el tamaño de muestra inicial (o preliminar). Este paso consiste en empezar con algún tamaño de muestra mínimo, digamos n0, para que podamos encontrar el valor de n que satisfaga
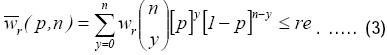
Para simplificar, escribiremos ϖr(p,n) como ϖr, tomando en cuenta que la amplitud relativa necesariamente dependerá de 1 – α , p y n. Si la ARCIC es más ancha que el valor deseado (re), el tamaño de muestra debe de ser aumentado en uno, y la ARCIC debe de ser determinada nuevamente. Este proceso iterativo de incrementar el tamaño de muestra y recalcular la ARCIC deberá de continuar hasta que ϖrire≤re (donde i representa la i–ésima iteración). Este método encuentra el tamaño de muestra requerido para conseguir que la ARCIC sea lo suficientemente reducida. Aún así, no garantiza que para cualquier IC la anchura observada será lo suficientemente pequeña porque la ARCIC, ϖr ,es una variable aleatoria ( ) que oscila de muestra a muestra si no sabemos el valor exacto de p. Para demostrar esto, necesitamos calcular la probabilidad de obtener ARCICs menores que el valor especificado (re), que puede ser calculado con
) que oscila de muestra a muestra si no sabemos el valor exacto de p. Para demostrar esto, necesitamos calcular la probabilidad de obtener ARCICs menores que el valor especificado (re), que puede ser calculado con
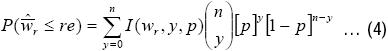
Donde I(wr,y,p) es una variable indicadora que muestra si la ARCIC actual calculada con la ecuación (1) no es más grande que re, y es considerada una variable aleatoria puesto que no sabemos el valor exacto de p.
En el Cuadro 1, se ilustra la determinación del tamaño de la muestra con el enfoque AI PE para un IC de 95% y para varios valores de la proporción (p) en la población y se comparan con los del método tradicional 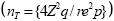 . Con el enfoque AIPE el tamaño de muestra requerido preliminar se calcula con la ecuación (3) y la probabilidad de P(≤re) que la ARCIC ϖes menor del valor especificado (re = 0.3) con la ecuación (4). Esto es hecho con el objetivo de mostrar que el tamaño de muestra preliminar (np, segunda columna) calculado con la ecuación (3) tiene una probabilidad de alrededor de 0.50 (50 %) de que la ARCIC sea menor o igual al error relativo especificado re = 0.3 (tercera columna). Por ejemplo, cuando p=0.1, el tamaño de muestra preliminar (np) es 1,600 y la probabilidad de obtener una ARCIC ≤ re = 0.3 es 0.4878. Con p=0.25, el tamaño de muestra preliminar es 536 y sólo podemos estar el 48.34 % seguros de que la ARCIC será menor o igual a 0.3. No obstante, cuando los tamaños de muestra aumentan en 100 (nm100 , cuarta columna), la probabilidad de que se cumpla la amplitud relativa deseada del IC incrementa. Por ejemplo, cuando p=0.1 y hay 1,700 unidades en la muestra, P(≤0.3) = 0.8439, y para un tamaño de muestra de 1,900 unidades, P(≤0.3) = 0.9992 , es decir, incrementa significativamente la probabilidad de que se cumpla la ARCIC.
. Con el enfoque AIPE el tamaño de muestra requerido preliminar se calcula con la ecuación (3) y la probabilidad de P(≤re) que la ARCIC ϖes menor del valor especificado (re = 0.3) con la ecuación (4). Esto es hecho con el objetivo de mostrar que el tamaño de muestra preliminar (np, segunda columna) calculado con la ecuación (3) tiene una probabilidad de alrededor de 0.50 (50 %) de que la ARCIC sea menor o igual al error relativo especificado re = 0.3 (tercera columna). Por ejemplo, cuando p=0.1, el tamaño de muestra preliminar (np) es 1,600 y la probabilidad de obtener una ARCIC ≤ re = 0.3 es 0.4878. Con p=0.25, el tamaño de muestra preliminar es 536 y sólo podemos estar el 48.34 % seguros de que la ARCIC será menor o igual a 0.3. No obstante, cuando los tamaños de muestra aumentan en 100 (nm100 , cuarta columna), la probabilidad de que se cumpla la amplitud relativa deseada del IC incrementa. Por ejemplo, cuando p=0.1 y hay 1,700 unidades en la muestra, P(≤0.3) = 0.8439, y para un tamaño de muestra de 1,900 unidades, P(≤0.3) = 0.9992 , es decir, incrementa significativamente la probabilidad de que se cumpla la ARCIC.
Los resultados en el Cuadro 1 muestran que para lograr P(≤ re = 0.3) con una alta probabilidad de éxito, necesitamos aumentar significativamente el tamaño de muestra. Por lo tanto, con el enfoque AIPE se puede observar que el tamaño de muestra preliminar (np) es insuficiente (probabilidad de alrededor del 50 %) para garantizar que se cumpla la amplitud relativa deseada (re) de la ARCIC, por esto es de vital importancia agregar cierto nivel de aseguramiento. Por otro lado, comparando los tamaños de muestra preliminar (np) con los tradicionales que asumen normalidad se puede ver que los tamaños de muestra tradicionales producen tamaños de muestra considerablemente más pequeños que los exactos sin aseguramiento con el enfoque AIPE. Esto sugiere que se debe de abandonar el uso de los tamaños de muestra tradicionales cuando se usa la amplitud relativa completa del IC o 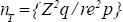 cuando se usa la mitad de la amplitud relativa del IC) porque producen una subestimación muy grande y la probabilidad de que la ARCIC sea menor que el error relativo especificado a priori es menor al 50 %.
cuando se usa la mitad de la amplitud relativa del IC) porque producen una subestimación muy grande y la probabilidad de que la ARCIC sea menor que el error relativo especificado a priori es menor al 50 %.
Por lo tanto, se requiere de un segundo paso para garantizar un tamaño de muestra que asegure una ARCIC no más ancha que la amplitud deseada con un cierto nivel de probabilidad. Es decir, se requiere de una modificación al procedimiento previo para la determinación del tamaño de muestra con el objeto de garantizar un IC suficientemente estrecho. Para ello, se incorpora una afirmación (declaración) probabilística dentro del procedimiento de planificación del tamaño de muestra. Por lo tanto, se utilizará el tamaño de muestra inicial (np) para poder calcular el tamaño de muestra modificado. En cualquier muestra dada, el valor de calculado no será igual a p, aún si se conoce el valor verdadero de p. Aproximadamente la mitad de las veces la estimación de p será más grande (o más pequeña) que p. Por esta razón, el tamaño de muestra preliminar (np) producido por la ecuación (3) solamente asegura una probabilidad de 50 % de que el intervalo sea más angosto que el requerido (Cuadro 1), porque p variará de muestra a muestra.
Para incrementar la probabilidad de que la ARCIC no sea más amplia de lo requerido, proponemos una modificación al tamaño de muestra inicial calculado en el paso 1 (Ecuación 3). Esto producirá un tamaño de muestra modificado ( nm) de tal manera que el investigador puede estar 7 por ciento seguro de que la ARCIC (ϖr) observada será menor o igual al requerido (re). La ecuación (3) brinda el tamaño de muestra preliminar y para obtener nm (tamaño de muestra modificado) necesitamos resolver

El procedimiento involucra incrementar el tamaño de muestra preliminar (np) por una unidad y recalcular la ecuación (5) cada vez hasta lograr el grado deseado de certeza (γ). Esto producirá el tamaño de muestra modificado (nm) que asegure con una probabilidad de por lo menos y, que la ARCIC (ϖr) no será más ancha que re. En otras palabras, nm asegura que el investigador tendrá aproximadamente 100 γ % de certeza de que el IC calculado será de la amplitud requerida o menos. Por ejemplo, si el investigador requiere un nivel de aseguramiento de 90 % de que la ARCIC (ϖr) no sea más grande que la anchura deseada (re), 1–γ sería definido como 0.10, y habría solamente un 10 % de probabilidad de que la amplitud del IC, alrededor de  , sea más grande que el valor especificado (re)(9).
, sea más grande que el valor especificado (re)(9).
En cuanto a escoger un nivel de aseguramiento de 100 porciento para la estimación de la proporción y a escoger un IC del 100(1–α) porciento para pruebas de hipótesis, se pueden señalar importantes diferencias. La diferencia más obvia es que (1–γ) representa la probabilidad de obtener una ARCIC observada (ϖr) que es más grande que la amplitud requerida, re, mientras que a es la probabilidad de rechazar la hipótesis nula dado que es verdadera (Error tipo I). También, a comúnmente toma los valores de 0.05 (5%) ó 0.01 (1%), mientras que γ (γ≥0.5(50%)) es escogido por el investigador para lograr algún grado de certeza deseado de que la precisión del parámetro deseado se logre. Esto es, el IC formado en el contexto de pruebas de hipótesis tiene diferentes metas al IC formado cuando el investigador desea obtener un cálculo preciso del parámetro de interés(8,9).
Hay que tener presente que los dos pasos anteriores producen un tamaño de muestra ( nm) que asegura cortos intervalos de confianza pero con muestreo aleatorio simple. Sin embargo, en el área de veterinaria debido a la limitada disponibilidad de marcos de muestreo confiables y altos costos de transporte, es usualmente imposible e impráctico seleccionar una muestra aleatoria simple de individuos de una población(15). Una solución bastante usada en la mayoría de las encuestas es tomar una muestra de conglomerados (grupo de individuos) donde el hato o la comunidad es la unidad de muestreo y seleccionar aleatoriamente un número de animales de cada hato o comunidad (muestreo por conglomerados en dos etapas). Sin embargo, hay que tener presente que para un número dado de individuos, la precisión de una muestra por conglomerados es menor a la obtenida por medio de muestreo aleatorio simple, debido a la correlación intraconglomerados (tasa de homogeneidad); es decir, 20 animales de un mismo hato proporcionan menos información que 20 animales de diferentes hatos(15,16). Esta reducción en la precisión debe ser considerada al calcular el tamaño de muestra en un muestreo por conglomerados o etapas múltiples(15). Una medida del incremento del error estándar de la prevalencia debido al procedimiento de muestreo utilizado está dado por la raíz cuadrada del efecto de diseño, Deƒƒ=1+(b–r)ro donde: b es el número promedio de individuos medidos por conglomerado y ro es el coeficiente de correlación intraconglomerados de la enfermedad en estudio. En un muestreo aleatorio simple de conglomerados ro es equivalente a la correlación intraclase(15).
En muestreo por conglomerados la decisión que usual mente tiene que ser considerada es, cuántos conglomerados de tamaño b serán necesarios para obtener la precisión deseada, ya que b suele estar limitado por el tamaño del hato y otras consideraciones prácticas. Si el efecto de diseño es conocido, el número de conglomerados puede calcularse con

Donde: nm es el tamaño de muestra modificado o preliminar bajo muestreo aleatorio simple (proporcionado por los dos pasos anteriores usando las ecuaciones (3) y (5), Deƒƒ=1+(b–r)ro es el efecto de diseño y para calcularlo se necesita conocer ro y b. Valores aproximados de ro pueden obtenerse de una muestra piloto o de resultados de encuestas previas, considerando que ro variará de región a región y de encuesta a encuesta(15,16).
Aunque el apéndice que se presenta proporciona información sobre la implementación de los métodos propuestos, y discute como obtener lCs suficientemente angostos para cualquier combinación de p, re, γ, α, ro, b, usando el paquete R(17), también se proporcionan cuadros para algunas condiciones. Los cuadros no incluyen todas las condiciones potencialmente interesantes; en lugar de esto se pretende que proporcionen al investigador: una forma conveniente de planear el tamaño de muestra cuando la situación de interés es aproximada por los escenarios cubiertos por las tablas; y también una forma de ilustrar la relación entre p, re, γ, α, ro, b,y el tamaño de muestra (n) y número de conglomerados, C, requeridos. Los valores en el Cuadro 2 se basan en condiciones que deberían ser útiles para detectar y calcular la proporción de interés para algunos valores de p.
Los tamaños de muestra se presentan para valores p de 0.05 a 0.5 con incrementos de 0.05, para valores re de 0.05, 0.1, 0.2, 0.3, para valores de y de 0.5 0.90 y 0.99, para los cuales se presentan o subcuadros (tamaño de muestra preliminar, np sin aseguramiento (y=0.5) y tamaños de muestra modificado, nm , para valores de de 0.90 y 0.99, cada uno para coberturas del lC de 95 y 99 %) (Cuadro 2). Cada condición se cruza con todas las otras condiciones de una manera factorial, resultando un total de 240 situaciones para planear un tamaño de muestra.
Suponiendo que un investigador está interesado en calcular la prevalencia animal (p) de la influenza aviar en el sur de México. Para determinar el tamaño de la muestra se necesita una estimación de p. Después de hacer una revisión de literatura de otros estudios, para la estimación de la prevalencia de esta enfermedad, se hipotetiza que p=0.1, el lC de 95%, ro= 0.196 (coeficiente de correlación intraconglomerados), b=7 (promedio de individuos a extraer por conglomerado) y se asume que la ARCIC final deseada es 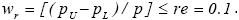 La aplicación del método conduce a una muestra preliminar de np =14,026. Este tamaño de muestra está contenido en el primer sub–cuadro ( np sin γ, γ=0.5) del Cuadro 2 donde p=0.1, y re=0.1. Tomando en cuenta que np =14,026 conducirá a un lC relativo suficientemente estrecho solamente el 50 % de las ocasiones, el investigador incorpora un nivel de aseguramiento de γ= 0.99, lo cual implica que la amplitud del IC relativo de 95 % será más grande que lo requerido (re=0. 1) no más del 1 % por ciento de las veces. Del tercer subcuadro del Cuadro 2 ( nm con γ= 0.99), se puede apreciar que el tamaño de muestra modificado requerido es de nm =14736, pero este tamaño de muestra es con muestreo aleatorio simple (MAS). Sin embargo, dado que se requiere la selección con muestreo por conglomerados el Deƒƒ=1 + (b–1)ro= 1 +(7–1)0.196= 2.34. Por lo tanto, el número de conglomerados (que pueden ser ranchos) a seleccionar de la población es igual a
La aplicación del método conduce a una muestra preliminar de np =14,026. Este tamaño de muestra está contenido en el primer sub–cuadro ( np sin γ, γ=0.5) del Cuadro 2 donde p=0.1, y re=0.1. Tomando en cuenta que np =14,026 conducirá a un lC relativo suficientemente estrecho solamente el 50 % de las ocasiones, el investigador incorpora un nivel de aseguramiento de γ= 0.99, lo cual implica que la amplitud del IC relativo de 95 % será más grande que lo requerido (re=0. 1) no más del 1 % por ciento de las veces. Del tercer subcuadro del Cuadro 2 ( nm con γ= 0.99), se puede apreciar que el tamaño de muestra modificado requerido es de nm =14736, pero este tamaño de muestra es con muestreo aleatorio simple (MAS). Sin embargo, dado que se requiere la selección con muestreo por conglomerados el Deƒƒ=1 + (b–1)ro= 1 +(7–1)0.196= 2.34. Por lo tanto, el número de conglomerados (que pueden ser ranchos) a seleccionar de la población es igual a 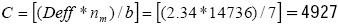 , es decir, se requieren 4,927 conglomerados para garantizar con una probabilidad de 99 % de que el lC relativo obtenido para será no más ancho que 0.1 unidades. De manera similar, en la parte inferior del Cuadro 2 se muestra el tamaño de muestra requerido para un lC de 99 %, pero estos son con MAS, y si se desean con muestreo por conglomerados hay que multiplicar estos por el efecto de diseño y dividirse entre el promedio de individuos por conglomerado (b).
, es decir, se requieren 4,927 conglomerados para garantizar con una probabilidad de 99 % de que el lC relativo obtenido para será no más ancho que 0.1 unidades. De manera similar, en la parte inferior del Cuadro 2 se muestra el tamaño de muestra requerido para un lC de 99 %, pero estos son con MAS, y si se desean con muestreo por conglomerados hay que multiplicar estos por el efecto de diseño y dividirse entre el promedio de individuos por conglomerado (b).
Para mejorar la comprensión del procedimiento propuesto, se presenta otro ejemplo. Suponiendo que un investigador está interesado en estimar la proporción (p) de plantas de maíz transgénico (maíz AP) en la región de Oaxaca, México, donde Quist y Chapela(18,19) reportaron encontrar maíz AP. Después de una revisión de literatura, se hipotetiza que p=0.05, b=20, ro= 0.35, se desea un IC de 99 % y se asume que la ARCIC es  La aplicación del método propuesto conduce a un tamaño de muestra preliminar de np =12,805 (bajo MAS). Este tamaño de muestra está contenido en el segundo subcuadro (np sin γ, γ=0.5) del Cuadro 2, donde p=0.05 y re=0.2.
La aplicación del método propuesto conduce a un tamaño de muestra preliminar de np =12,805 (bajo MAS). Este tamaño de muestra está contenido en el segundo subcuadro (np sin γ, γ=0.5) del Cuadro 2, donde p=0.05 y re=0.2.
Tomando en cuenta que np =12,805 conducirá a un IC suficientemente angosto, solamente la mitad de las veces el investigador incorpora un nivel de aseguramiento de γ=0.99, lo cual implica que la anchura del IC relativo de 99 % será más amplio que lo requerido (i.e., 0.2) no más que el 1 % de las veces. Del segundo sub–cuadro del Cuadro 2 ( nm con γ=0.99)), se puede ver que el tamaño de muestra modificado es nm =13,840 (también con MAS) que proporcionará un 99 % de seguridad de que el IC obtenido por p no será más ancho que 0.2 unidades. Sin embargo, dado que es impráctico usar MAS, la selección se realizará con muestreo por conglomerados. Por lo tanto, el  Esto implica que se requieren
Esto implica que se requieren  conglomerados (que pueden ser predios) para garantizar con una probabilidad de 99 % de que el lC relativo obtenido para p será no más ancho que 0.2 unidades.
conglomerados (que pueden ser predios) para garantizar con una probabilidad de 99 % de que el lC relativo obtenido para p será no más ancho que 0.2 unidades.
Con el Cuadro 2 se puede obtener el tamaño de muestra requerido que asegura cortos intervalos de confianza con MAS, pero, este cuadro incluye solamente algunas condiciones (solamente algunos valores de p) para la obtención de tamaños de muestra. Por esta razón, se propone un programa en R (Apéndice), donde el investigador puede obtener tamaños de muestra para otros escenarios, y si el esquema de selección es por conglomerados, los tamaños de muestra proporcionados se tienen que multiplicar por el efecto de diseño y dividirse entre b (promedio de individuos por conglomerado) para obtener el número de conglomerados requeridos.
Para afianzar como obtener el número de conglomerados requeridos. En el Cuadro 3 se presentan los coeficientes de correlación intraconglomerados (ro) y efectos de diseño (Deƒƒ) para 14 serovariedades de Leptospira para Yucatán México reportados por Segura–Correa et al(15). Los efectos de diseño se obtienen con la expresión: Deƒƒ=1 + (b–1)ro, asumiendo un valor de b = 7 (número promedio de animales medidos por rancho). En seguida para cada serovariedad se calcula el tamaño de muestra tradicional con la expresión 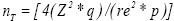 asumiendo p = 0.2, re=0.3 y un IC de 95% (Z=1.96). Posteriormente, con el método propuesto (enfoque AI PE) se calculan para cada serovariedad los tamaños de muestra preliminar (np sin γ,γ=0.5), tamaños de muestra modificados con niveles de aseguramiento de 90 % (γ=0.90) y 99 % (γ=0.99) de igual manera asumiendo una proporción de 0.2, un error relativo de 0.3 y un IC de 95 %. Aquí se puede resaltar nuevamente que el tamaño de muestra tradicional ( nT) es menor que el preliminar y modificado, lo que muestra claramente que la expresión
asumiendo p = 0.2, re=0.3 y un IC de 95% (Z=1.96). Posteriormente, con el método propuesto (enfoque AI PE) se calculan para cada serovariedad los tamaños de muestra preliminar (np sin γ,γ=0.5), tamaños de muestra modificados con niveles de aseguramiento de 90 % (γ=0.90) y 99 % (γ=0.99) de igual manera asumiendo una proporción de 0.2, un error relativo de 0.3 y un IC de 95 %. Aquí se puede resaltar nuevamente que el tamaño de muestra tradicional ( nT) es menor que el preliminar y modificado, lo que muestra claramente que la expresión  para el cálculo del tamaño de muestra tradicional produce una seria subestimación. Finalmente, para cada uno de estos cuatro tamaños de muestra se reporta el número de conglomerados requeridos de tamaño 7 que se calculan con la expresión
para el cálculo del tamaño de muestra tradicional produce una seria subestimación. Finalmente, para cada uno de estos cuatro tamaños de muestra se reporta el número de conglomerados requeridos de tamaño 7 que se calculan con la expresión  , para i=T, p, m1 y m2. También se observa que el número de conglomerados con el enfoque tradicional ( CT) subestima el número de conglomerados requeridos.
, para i=T, p, m1 y m2. También se observa que el número de conglomerados con el enfoque tradicional ( CT) subestima el número de conglomerados requeridos.
Se concluye que el método propuesto es útil para planear tamaños de muestra, cuando se desea precisión en la estimación de la proporción, y aunque garantiza precisión en la estimación de p, no puede ser resuelto en forma analítica; es por esto que se proporcionan cuadros con tamaños de muestra para algunos escenarios, que podrían ayudar a los investigadores a planear su tamaño de muestra que les garantice un reducido IC en la estimación de una proporción binomial. No obstante, no es posible cubrir todas las combinaciones posibles de (p, re, γ, a, ro, b); es por esto que se realizó un programa en el paquete R(17) para que el usuario de una forma rápida y sencilla pueda calcular el tamaño de muestra que requiere de acuerdo a sus necesidades (Apéndice). Es importante aclarar que el método presentado supone una prueba perfecta (sensibilidad = especificidad = 1) y que si se desea usar muestreo por conglomerados el usuario debe de conocer o estimar con una muestra piloto el valor del coeficiente de correlación intraconglomerados (ro) y además especificar el valor de b (promedio de individuos a medir por conglomerado).
LITERATURA CITADA
1. Salman MD. Animal disease surveillance and survey systems: methods and applications, Iowa USA: Iowa State Press; 2003. [ Links ]
2. Montesinos–López OA, Hernández–Suárez CM, Sáez RA, Luna–Espinoza I. Modelo estocástico para determinar la mejor estrategia de cuarentena en granjas ganaderas. Tec Pecu Méx 2009;47(3):271–284. [ Links ]
3. Hernández–Suárez CM, Montesinos–López OA, McLaren G, Crossa J. Probability models for detecting transgenic plants. Seed Sci Res 2008;18:77–89. [ Links ]
4. Fosgate GT. A cluster–adjusted sample size algorithm for proportions was developed using a beta–binomial model. J Clin Epidemiol 2007;60:250–255. [ Links ]
5. Wang H, Chow SC, Chen M. A bayesian approach on sample size calculation for comparing means. J Biopharm Stat 2005;15:799–807. [ Links ]
6. Pan Z, Kupper L. Sample size determination for multiple comparison studies treating confidence interval width as random. Stat Med 1999;18:1475–1488. [ Links ]
7. Newcombe RG. Two–sided CIs for the single proportion: comparison of seven methods. Stat Med 1998;17:857–872. [ Links ]
8. Kelley K, Maxwell SE, Rausch JR. Obtaining power or obtaining precision: Delineating methods of sample size planning. Eval Health Prof 2003;26:258–287. [ Links ]
9. Kelley K, Maxwell SE. Sample size for multiple regression: Obtaining regression coefficients that are accurate, not simply significant. Psychol Methods 2003;8:305–321. [ Links ]
10. Kelley K, Rausch JR. Sample size planning for the standardized mean difference: Accuracy in parameter estimation via narrow confidence intervals. Psychol Methods 2006;11:363–385. [ Links ]
11. Mace AE. Sample size determination. New York: Reinhold; 1964. [ Links ]
12. Kupper LL, Hafner KB. How appropriate are popular sample size formulas? Am Stat 1989;43:101–105. [ Links ]
13. Wang Y, Kupper LL. Optimal sample sizes for estimating the diference in means between two normal populations treating confidence interval length as a random variable. Commun Stat 1997;26:727–741. [ Links ]
14. Vollset SE. CIs for a binomial proportion. Stat Med 1993;12:809–824. [ Links ]
15. Segura–Correa JC, Segura–Correa VM, Solís–Calderón JJ. Efecto de diseño para 14 serovariedades de Leptospira en Yucatán, México. Rev Biomed 2002;13:33–36. [ Links ]
16. Montesinos–López OA, Luna–Espinoza I, Hernández–Suárez CM, Tinoco–Zermeño MA. Muestreo Estadístico. Tamaño de muestra y estimación de parámetros. Colima, México: Editorial Universidad de Colima; 2009. [ Links ]
17. R Development Core Team. R: A language and environment for statistical computing [Computer software and manual], R Foundation for Statistical Computing 2007. Retrieved from www.r–project.org. [ Links ]
18. Quist D, Chapela IH. Transgenic DNA introgressed into traditional maize landraces in Oaxaca, Mexico. Nature 2001;414:541–543. [ Links ]
19. Quist D, Chapela IH. Quist and Chapela reply. Nature 2002;416:602. [ Links ]

