











 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Para garantizar la transparencia de la salud vegetal es necesario controlar la propagación de enfermedades asegurando la sanidad de las plantas en determinada población. La mejora de la sanidad vegetal tiene beneficios claros para la salud del hombre (control de enfermedades fitopatológicas, seguridad alimentaria, inocuidad y sanidad de los alimentos), repercusiones positivas para el desarrollo económico y la producción de productos agrícolas. Es por ello que los países desarrollados y en vías de desarrollo han dado mucha importancia a los programas de monitoreo y sistemas de vigilancia vegetal (Ragan, 2002).
Dentro de una población existen elementos con bajas tasas de prevalencia (un subconjunto pequeño de la población total), estos son denominados raros, escasos o evasivos (Graham y Dallas, 1988; Sudman et al., 1988) tienen como casos típicos plantas, animales y personas con enfermedades, tratamientos clínicos, y en general, todos aquellos grupos con baja frecuencia de unidades que poseen una característica determinada. Algunos autores como Czaja et al. (1996) consideran que las poblaciones raras están presentes en menos de 3% del universo de estudio.
Para estimar la prevalencia vegetal (ausencia de enfermedades en poblaciones) los métodos de muestreo son de suma importancia (Hernández-Suárez et al, 2008). Por esta razón, el cálculo del tamaño de muestra óptimo es importante en el diseño de experimentos agrícolas para la estimación de proporciones en poblaciones, incluyendo la prevalencia de una enfermedad (Fosgate, 2007).
En la estimación de parámetros asociados con características escasas de una población, los diseños muestrales tradicionales no ofrecen las mejores condiciones metodológicas, principalmente por la dificultad de localizar los elementos con la característica deseada. Es por ello, que debe recurrirse a otras técnicas especiales, tales como el muestreo inverso o binomial negativo. Este método ha sido utilizado en el campo de la hematología, genética, inspección (Zhu y Lakkis, 2014), investigaciones epidemiológicas (Singh y Aggarwal, 1991; Lui, 2001; Tang et al, 2008), ecología (Sheaffer y Leavenworth, 1976; Krebs, 2001), detección de enfermedades en plantas y animales (Madden et al, 1996), medición de la eficacia de tratamientos clínicos (George y Elston, 1993) entre otras.
Para detectar la presencia de un evento raro en una población se requiere probar un número lo suficientemente grande de individuos, y el costo de dichas pruebas por lo general excede los recursos humanos y económicos disponibles. Además de ser una actividad laboriosa, consume mucho tiempo y esfuerzo. El muestreo inverso es un método antiguo (George y Elston, 1993) para estimar una proporción p, se basa en la distribución binomial negativa con una serie de ensayos Bernoulli en el que no se deja de muestrear hasta obtener un número deseado de individuos con la característica de interés. Sin embargo, cuando la probabilidad de encontrar el atributo deseado es prácticamente nula (p ≤ 0.1) usar el muestreo binomial (donde se fija previamente el número de elementos de la muestra) no es la mejor opción porque según Haldane (1945) el uso de una distribución binomial no siempre proporciona una estimación insesgada y precisa de p cuando ésta es pequeña (p ≤ 0.1).
George y Elston (1993) recomiendan el uso de muestreo geométrico (que consiste en parar el proceso de muestreo hasta que se encuentra a un individuo con la característica de interés) cuando la probabilidad del evento de interés es pequeña. En su investigación se proporciona la obtención de intervalos de confianza (IC's) para la prevalencia basados en pruebas individuales y bajo un modelo geométrico. También, Haldane (1945) asevera que el uso de una distribución binomial no siempre proporciona una estimación insesgada y precisa de p cuando ésta es pequeña (p ≤ 0.1). Lui (2000) amplió el trabajo de George y Elston (1993) para IC's al considerar el uso del muestreo binomial negativo (detener el proceso de muestreo hasta que se encuentren a r > 1 individuos con la característica de interés) y mostró que a medida que r aumenta, la amplitud del intervalo de confianza (IC) se reduce. Esta extensión aplica para pruebas individuales.
Históricamente, investigadores han enfatizado la planeación del tamaño de muestra en la investigación empírica, para obtener información útil de los estudios experimentales y observacionales desde una perspectiva de potencia analítica pura. Aunque la estructura de potencia analítica ha dominado la forma en que los investigadores conceptualizan la planeación del tamaño de muestra, no es ni el único, ni el mejor acercamiento que puede ser tomado para estimar el número apropiado de participantes a incluir en algún estudio de interés. Muchas veces la estimación de parámetros exactos es una meta aun potencialmente más significativa que el obtener significancia estadística (Kelley et al., 2003). Esto muestra que el método apropiado para la planeación del tamaño de muestra, y el tamaño apropiado de la muestra en sí, dependen de las metas deseadas en una investigación.
Un enfoque alternativo según Kelley (2007) para el marco de potencia analítica para la determinación de tamaños de muestra es el que garantiza la exactitud en la estimación de parámetros (AIPE por sus siglas en inglés). El objetivo de AIPE es garantizar que los parámetros estimados correspondan con la exactitud fijada para estimar dicho parámetro poblacional. Autores como Montesinos-López et al. (2011) han desarrollado procedimientos para el cálculo de tamaños de la muestra bajo el enfoque AIPE, enfoque que garantiza cortos IC's para la estimación de parámetros bajo muestreo binomial y pruebas de grupo. Los IC's también transmiten información para determinar con precisión la magnitud del efecto a partir de los datos disponibles (Beal, 1989; Montesinos-López et al., 2012). Por ello, la determinación de tamaños de muestra bajo este enfoque puede contribuir a inferir en teorías más fuertes y precisas sobre algún fenómeno en estudio.
Realizar los cálculos necesarios para determinar tamaños de muestra y estimar otros parámetros importantes bajo muestreo inverso, resulta sin duda alguna una tarea laboriosa. Montesinos-López et al. (2012) proponen un algoritmo computacional en el paquete estadístico R, donde se calculan tamaños de muestra con enfoque AIPE para el muestreo inverso, pero cabe destacar que sólo se enfoca al muestreo por grupos (en inglés Group Testing), además de carecer de una interfaz gráfica, amigable y de fácil uso.
Por lo tanto, los propósitos de este artículo son: 1) derivar una expresión para calcular tamaños de muestra para la estimación de una proporción (p) bajo muestreo inverso (binomial negativo) bajo el enfoque AIPE, 2) mostrar a través de ejemplos el proceso de cálculo para el tamaño de muestra y 3) desarrollar un software para realizar la determinación de tamaños de muestra así como la estimación de parámetros de interés bajo este enfoque.
Materiales y métodos
Suponga que Yi= yi individuos son probados hasta encontrar el primer individuo positivo y Y1, Y2,Y3,...Yr son observados para obtener el r-ésimo individuo positivo. Dado que, Yi (i=1, 2,...,r) tiene una distribución geométrica. Por lo tanto, se registra el número total de individuos para encontrar r individuos positivos que es igual a  La prevalencia es denotada por p, el número de individuos probados hasta encontrar el primer individuo positivo es Yi= yi , y el número de veces que el experimento se lleva a cabo está denotado por r. Es importante mencionar que en este documento se considera que: (i) el tamaño de muestra es el valor de r que representa el número requerido de individuos positivos para detener el proceso de muestreo y las pruebas, y (ii) el número total de individuos probados es el valor de
La prevalencia es denotada por p, el número de individuos probados hasta encontrar el primer individuo positivo es Yi= yi , y el número de veces que el experimento se lleva a cabo está denotado por r. Es importante mencionar que en este documento se considera que: (i) el tamaño de muestra es el valor de r que representa el número requerido de individuos positivos para detener el proceso de muestreo y las pruebas, y (ii) el número total de individuos probados es el valor de  Por lo tanto, la estadística suficiente y completa
Por lo tanto, la estadística suficiente y completa 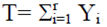 tiene una distribución binomial negativa (dbn) con parámetro r y probabilidad de éxito p (George y Elston, 1993). De acuerdo con George y Elston (1993) la estimación de máxima verosimilitud (EMV) de p usando muestreo inverso es:
tiene una distribución binomial negativa (dbn) con parámetro r y probabilidad de éxito p (George y Elston, 1993). De acuerdo con George y Elston (1993) la estimación de máxima verosimilitud (EMV) de p usando muestreo inverso es:
 1)
1)
Donde: r es el número fijado requerido de individuos positivos. Este EMV de p para muestreo inverso asume una prueba diagnóstica perfecta (especificidad y sensibilidad iguales a uno). Por otro lado, la varianza de / de acuerdo a George y Elston (1993) está dada por V (/): 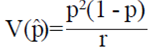 y tomando en cuenta el factor de corrección de población finita es igual a
y tomando en cuenta el factor de corrección de población finita es igual a  , donde q= (1 - p). De acuerdo a George y Elston (1993) el IC de Wald es el siguiente:
, donde q= (1 - p). De acuerdo a George y Elston (1993) el IC de Wald es el siguiente:
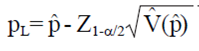
 2)
2)
Donde: Z1-α/2 es el cuantil 1-α/2 de la distribución normal estándar, y p es el EMV. Esta aproximación del IC es fácil de calcular y permite derivar fórmulas del tamaño de la muestra de forma cerrada. Sin embargo, cuando r es pequeña, la aproximación normal para EMV es dudosa; puesto que en tales casos, el IC de Wald frecuentemente produce puntos finales negativos. Además, la probabilidad de cobertura de los IC's construidos por el IC de Wald es frecuentemente menor que 100 (1 - α)%.
La cantidad 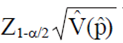 (añadida y sustraída de la proporción observada,
(añadida y sustraída de la proporción observada,  ) en la Ec. 2 se define como W/2 (donde W es la amplitud del IC; W o W/2 se puede establecer a priori por el investigador dependiendo de la precisión deseada). La amplitud del IC observado para cualquier realización de este intervalo de confianza (A partir de la Ec. 2) se puede expresar como:
) en la Ec. 2 se define como W/2 (donde W es la amplitud del IC; W o W/2 se puede establecer a priori por el investigador dependiendo de la precisión deseada). La amplitud del IC observado para cualquier realización de este intervalo de confianza (A partir de la Ec. 2) se puede expresar como:
 3)
3)
Sea ra la amplitud deseada del IC; entonces el enfoque AIPE básicamente trata de encontrar el tamaño mínimo de la muestra que garantiza que la amplitud esperada del IC sea lo suficientemente estrecha (Kelley, 2007; Kelley y Rausch, 2011). En otras palabras, el enfoque AIPE busca el tamaño de muestra mínimo de tal manera que E(W) ≤ ω. El problema es que la amplitud esperada del IC es una cantidad desconocida, aunque se puede aproximar.
Por consiguiente, el valor esperado de W es:  (Lui, 1995).
(Lui, 1995).
Ahora bien, si se establece el E(W) para la amplitud deseada del IC, ω:
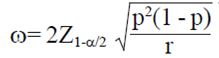 4)
4)
De acuerdo con Lui (2001) resolviendo r (Ec. 4) se obtiene la siguiente fórmula:
 5)
5)
Sin embargo, la Ec. 5 requiere el valor poblacional de p, que es desconocido y en la práctica se sustituye por una estimación de la proporción real. Aunque, la Ec. 5 se proporciona el tamaño de muestra necesario para alcanzar la amplitud deseada del IC, E(W), que es suficientemente estrecha para la estimación de la proporción. Sin embargo, esto no garantiza que para cualquier IC en particular, la amplitud esperada del IC observado, E(W), sea lo suficientemente estrecha, porque el valor esperado sólo se aproxima a la amplitud del intervalo de confianza promedio. Kelley y Rausch (2011) afirman que este problema es similar al caso donde se estima un promedio a partir de una distribución normal, aunque la media muestral es un estimador insesgado de la media poblacional, es casi seguro que la media muestral sea más pequeña o más grande que el valor de la población. Esto se debe a que la media muestral es una variable aleatoria continua, como lo es la anchura del IC, debido a que ambos se basan en datos aleatorios. Por lo tanto, aproximadamente la mitad de las veces, la anchura calculada del IC será mayor que la anchura previamente especificada (Kelley y Rausch, 2011).
Debido a que la Ec. 3 utiliza una estimación de p, la anchura del IC (W) es una variable aleatoria que fluctuará de muestra a muestra. Esto implica que usando rp de la Ec. 5, alrededor del 50% de la distribución de muestreo de W será menor que ω (Tercer columna del Cuadro 1). Para demostrar esto, se debe calcular la probabilidad de obtener una amplitud del IC menor al valor especificado ω). Esto se puede calcular por medio de:
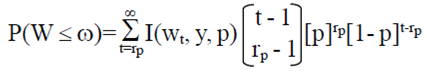
Donde: I (wt, y, p) es una función indicadora que muestra si la anchura calculada de IC real usando la Ec. 3 es ≤ ω, p es la proporción verdadera de la población y rp es el tamaño de la muestra obtenida mediante la Ec. 5. Debido a las limitaciones computacionales se utiliza la siguiente aproximación para calcular esta probabilidad.
 6)
6)
Donde: t= rp, rp + 1, rp+2,.. .t*, y W se considera una variable aleatoria ya que el valor exacto de p no se conoce y t* es el valor que satisface P(T ≤ t*)= 0.9999. Se utiliza el valor de t* ya que la operación en el Paquete R no puede sumar hasta infinito.
Derivación del tamaño de muestra bajo AIPE para muestreo inverso
A continuación se muestra el procedimiento para derivar la expresión para el cálculo de tamaños de muestra para la estimación de una proporción (p) para muestreo inverso bajo el enfoque AIPE.
Suponga que Y1...,Yr es una muestra aleatoria de tamaño r de una distribución geométrica (p). Sea  . Entonces para ≠
. Entonces para ≠ 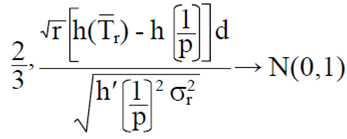
Esto es,  ; donde
; donde  . Note que
. Note que 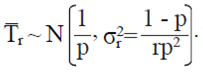 . Entonces, si
. Entonces, si 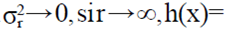
 es diferenciable con respecto a x∈ (0,1) y
es diferenciable con respecto a x∈ (0,1) y 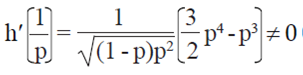 . Para
. Para  entonces usando el método delta (Oehlert, 1992) se obtiene,
entonces usando el método delta (Oehlert, 1992) se obtiene, 
Entonces, el valor entero más pequeño rm tal que:


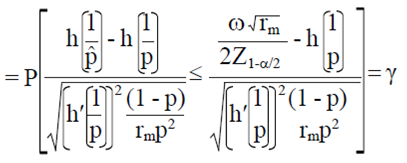

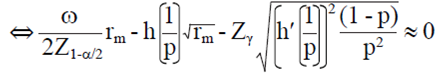
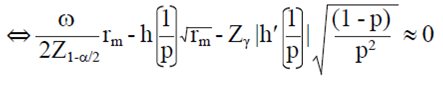 7)
7)
Note que la Ec. 7 tiene una forma cuadrática ax2 + bx+c= 0, con 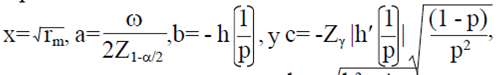 con dos soluciones dadas por
con dos soluciones dadas por 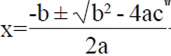 . Tomando
. Tomando 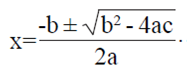 Por lo tanto, para un ω fijo, el rm deseado está dado por
Por lo tanto, para un ω fijo, el rm deseado está dado por 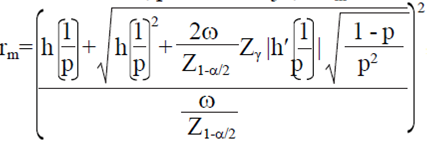 , en el que después de remplazar
, en el que después de remplazar 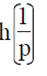 y
y  se obtiene
se obtiene 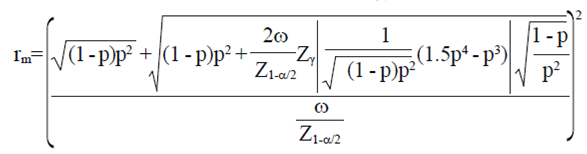
 8)
8)
Este procedimiento muestra la expresión para el cálculo de tamaños de muestra que garantizan exactitud en la estimación de parámetros de interés.
Resultados y discusiones
Subestimación del tamaño de muestra utilizando la Ec. 5.
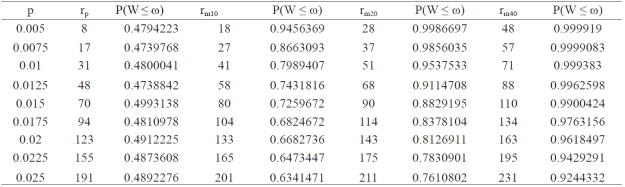
Para mostrar el grado en que rp es subestimado por la Ec. 5, se proporciona un ejemplo (Cuadro 1) en el que se utiliza la Ec. 6 para calcular P (W ≤ ω), es decir, la probabilidad de que W sea menor o igual a la amplitud deseada ω del IC para un valor dado rp (número unidades positivas) obtenido con la Ec. 5. El ejemplo numérico en el Cuadro 1 se da para varios valores de la proporción poblacional (p) con un IC de 95%, y para una anchura deseada ω = 0.007. El Cuadro 1 presenta el tamaño de muestra preliminar calculando rp con la Ec. 5, y otros tres incrementos: rm10= rp + 10, rm20= rp + 20 y rm40= rp+40. Para cada tamaño de muestra, la probabilidad de que W sea menor que el valor especificado (ra= 0.007) es P (W < ra) y se calcula utilizando la Ec. 6. Esto se hace para mostrar que el número requerido de unidades positivas para estimar la proporción (rp de la segunda columna) calculada utilizando la Ec. 5 tiene una probabilidad de alrededor de 0.50 de que W ≤ ω =0.007 (tercera columna). Por ejemplo, cuando p= 0.0125, el tamaño de la muestra preliminar (rp) es 48 y la probabilidad de obtener un W ≤ ω = 0.007 es 0.4738842. Con p= 0.02, rp= 123, sólo podemos estar 49.12 % seguros de que W será ≤ ω = 0.007. Cuando el número de unidades positivas aumenta en 10 (rm10, cuarta columna) o 20 (rm20, sexta columna), la probabilidad P (W ≤ ω = 0.007) aumenta.
Por ejemplo, cuando p= 0.0125, hay rm20= 68 unidades en la muestra con P (W ≤ ω = 0.007)= 0.9114708; para ^0= 88 unidades positivas en la muestra, la P (W ≤ ω = 0.007)= 0.9962598. Por lo tanto, los resultados del Cuadro 1 muestran que para garantizar una alta P (W ≤ ω =0.007), se requiere un tamaño de muestra (número de unidades positivas) mayor que el valor rp calculado con la Ec. 5. Además, el Cuadro 1 muestra que en los 9 casos el tamaño de la muestra preliminar (número de observaciones positivas) resultante del uso de la Ec. 5 produce una P (W ≤ ω < 0.50, es decir, 100% de las veces P (W ≤ ω = 0.007) es menor que 50%.
Caso de estimación de la prevalencia vegetal bajo muestreo inverso
Como ejemplo de estimación para la utilización de las técnicas mencionadas se desarrolla el siguiente caso:
Ejemplo 1. Suponga que un investigador está interesado en estimar la proporción de plantas infectadas con virus en una empresa agrícola, cuya población es de N= 4 300 plantas, se decide usar muestreo inverso bajo muestreo aleatorio simple (MAS). Dado que la prevalencia de plantas infectadas es baja se establece detener el proceso de muestreo hasta que se encuentren r=5 plantas infectadas. , se lleva el registro del total de plantas extraídas y analizadas. Es decir, se extraerá sin remplazo una planta y se analizará si está infectada. Este proceso de extracción continuará hasta que se encuentren 5 plantas infectadas. El número total de plantas analizadas hasta encontrar las 5 infectadas fue de n=250. Los cálculos se realizarán con una precisión de 10% (d= 10/100) de la proporción preliminar (p), una confiabilidad (1 - a) de 95% (a= 95/100) y un nivel de aseguramiento (γ) de 99% (γ= 99/100). En el Cuadro 2 se muestran los cálculos correspondientes para la estimación de varios parámetros de interés.

Del Cuadro 2 se tiene que la proporción de plantas infectadas es de p= 0.02 con 95% de confiabilidad se estima que la proporción verdadera está entre 0.003158 y 0.036842, es decir, entre 0.31 y 3.68%. Se estima que el total verdadero es de 86 plantas infectadas, y está entre 13.57 y 158.42.
Finalmente se tiene que los tamaños de muestra bajo el enfoque tradicional y bajo el enfoque AIPE son de 71 y 73 respectivamente.
Es evidente que hacer manualmente los cálculos del Cuadro 2 resulta tardado, laborioso y con una alta probabilidad de equivocarse. Por lo tanto, se consideró la necesidad de elaborar un software de distribución libre que permita la obtención de estos parámetros de manera rápida, efectiva y segura.
Software-ejemplo para muestreo inverso
El software para muestreo se planteó a partir de dos propósitos: a) determinar el tamaño de muestra para un estudio bajo el esquema de muestreo inverso para una proporción y b) realizar la estimación de los parámetros resultantes de aplicar este esquema de muestreo.
Para el cálculo de un tamaño de muestra hay una contradicción al tener que conocer, en la fase de diseño, el valor de un parámetro que sólo se podrá estimar una vez extraída la muestra. Para resolver este problema se cuenta con dos opciones, la primera es estimar el parámetro a partir de una muestra piloto; la segunda es obtener un valor aceptable a través de las referencias que se tengan de trabajos o experiencias similares ya realizados. En el software para muestreo inverso se optó por la opción 1. Además, también se requiere especificar el nivel de significancia (a) el cual normalmente es un valor menor a 0.2 (20%) y la precisión, la cual se define como el alejamiento máximo permitido entre el parámetro y su estimación. El software permite al usuario brindar su precisión requerida (forma directa) u obtenerla en forma indirecta como un porcentaje con respecto a la proporción preliminar estimada. Sin embargo, dado que los tamaños de muestra se calculan bajo el enfoque AIPE también se debe de especificar el nivel de aseguramiento (y) y este debe ser un valor mayor a 0.5 (50%).
A continuación se ilustra la utilización del software resolviendo el Ejemplo 1. Primeramente se introducen los datos solicitados por el software y se da clic en calcular como se ilustra en la Figura 1:
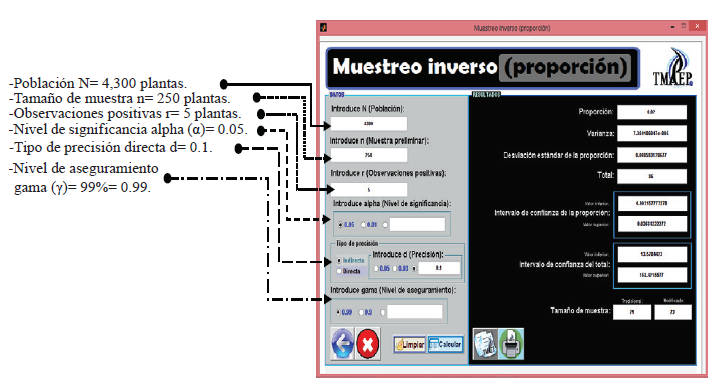
No hay que perder de vista que la muestra de 250 es una muestra piloto que sólo sirve para obtener la muestra definitiva. En este caso se puede observar en el área de resultados (Figura 1) que el tamaño de muestra modificado (definitivo), es de 73 plantas. Este tamaño de muestra garantiza que se cumplirá la precisión con una certidumbre de 99%.
Es importante resaltar que este tamaño de muestra es mayor al tamaño de muestra estimado de manera tradicional que es 71 (Figura 1), el cual sólo asegura que se cumpla la precisión requerida en un 50% de las veces, debido a que no toma en cuenta que el parámetro estimado con la muestra preliminar es una estimación. Por lo tanto, es claro que el tamaño de muestra bajo el enfoque AIPE (tamaño de muestra modificado) es normalmente mayor para garantizar el nivel de aseguramiento especificado.
Finalmente el investigador hará las estimaciones de los parámetros de su interés (porcentajes, totales, IC's) con la muestra definitiva utilizando el mismo software pero usando la información recabada de la muestra definitiva. Es decir, la muestra preliminar sólo se utiliza para obtener la muestra definitiva y para verificar posibles problemas en la aplicación de la encuesta. Por lo tanto, el investigador debe realizar la encuesta nuevamente pero parar el proceso de muestreo hasta que encuentre a 73 (tamaño de muestra modificado) elementos positivos y con esta información recabada puede utilizar el mismo software para realizar la estimación de los parámetros de su interés que serán estimaciones válidas para toda la población bajo estudio.
Es importante mencionar que el software no está limitado al muestreo inverso, sino que también se puede usar para los muestreos: aleatorio simple, sistemático, aleatorio estratificado, por conglomerados en una etapa, para estimar un promedio o proporción y aún con métodos como respuesta aleatorizada (versión Horvitz) y pruebas de grupo (Group testing). Se puede consultar el manual detallado de todas las capacidades del software en https://dl.dropboxusercontent.com/u/97440566/Manual%20TMAPEP.pdf.
Conclusiones
La fórmula presentada para el cálculo del tamaño de muestra para estimar la prevalencia de plantas bajo muestreo inverso con enfoque AIPE garantiza que con una probabilidad y (nivel de aseguramiento ≥ 0.5) la precisión fijada a priori del IC se cumpla. Lo cual produce mayor exactitud en el estudio de interés realizado.
El software diseñado de distribución libre para muestreo inverso es una excelente herramienta que permite a investigadores y estudiantes lograr estimaciones exactas en los parámetros de su interés y se recomienda usar cuando la proporción a estimar es rara. Si bien la presentación de los casos mostrados es limitada, puesto que, sólo se proporciona un ejemplo para el esquema de muestreo inverso, este software puede ser utilizado para estimar puntualmente o por intervalo un promedio, una proporción o un total bajo muestreo aleatorio simple, estratificado, sistemático y por conglomerados en una etapa y aún para esquemas de muestreo muy especializados como son muestreo inverso, respuesta aleatorizada y pruebas de grupo. A pesar de que sólo se ilustra un tipo de utilización del software es evidente que se utiliza tanto para la determinación del tamaño de muestra, así como para la estimación de los parámetros de interés utilizando una muestra piloto. Aunque el software obliga al usuario considerar una muestra piloto, y así determinar el tamaño de muestra definitivo, esto garantiza calidad en las estimaciones definitivas.
Para que el investigador o estudiante tenga éxito al usar el software cabalmente, no sólo para muestreo inverso debe entender en qué consiste este esquema de muestreo y sus características, así como también tener claros los parámetros que desea estimar para su correspondiente estudio. Por ello, si todas las decisiones en esta fase son justificadas de manera adecuada, el software desarrollado le será de gran ayuda, debido a que, desde el punto de vista estadístico y computacional el software es muy confiable.

