











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La evaluación de la ciencia ha sido objeto de debate en distintos momentos de la historia, encontrando los primeros vestigios sobre este rubro en siglo XVII, con el anuncio de Francis Bacon (1561-1626) sobre su método universal para la generación y evaluación de la ciencia en su Novum Organum en 1620, este poderoso trabajo inspiró a muchos académicos ingleses, algunos de los cuales participaron en reuniones informales para discutir y debatir sus puntos de vista sobre el desarrollo de la ciencia y fue hasta 1660 cuando acordaron formar una sociedad académica oficial (Spier, 2002), otro evento relevante sobre este aspecto fueron las primeras dos revistas de divulgación del conocimiento, las cuales, son: Journal des Scavans y Philosophical Transactions, la primera nació en enero y la última en marzo de 1665. En la Journal des Scavans se publicaban catálogos de libros, necrologías de personajes famosos, las decisiones de mayor relevancia de los tribunales religiosos, civiles y reportes de experimentos y observaciones en física, química, anatomía y meteorología, sin embargo, en la revista Philosophical Transactions se publicaban estudios con mayor relevancia científica (Zuckerman & Merton, 1972), en una primera etapa las publicaciones en esta revista podían o no tener la revisión de especialistas, ya que Henry Oldenburg (1618-1677) fue el primer editor y él decidía si requería o no de la colaboración del algún especialista para los manuscritos en cuestión (Spier, 2002), fue la primera revista que estableció un consejo editorial bajo la dirección de Oldenburg (Elsevier, 2018) y en 1752 a casi 100 años del nacimiento de la revista se integró un grupo selecto de académicos denominado Royal Society de Londres, el cual, asumió la responsabilidad de la revisión de los artículos que se aceptarían para la publicación en la revista Philosophical Transactions. Considerando la fecha anterior, es en este momento, en cual, se puede considerar como el nacimiento de la revisión por pares (Spier, 2002).
Como se puede observar la revisión por pares tiene más de 260 años de haberse establecido y actualmente se considera que los revisores o árbitros desempeñan un papel fundamental en las publicaciones académicas, contribuyen a mejorar la calidad de los estudios y aumenta las posibilidades de creación de redes dentro de las comunidades de investigación. A pesar de las críticas sobre la transparencia, el tiempo utilizado para la revisión, el sesgo por género, nacionalidad, prestigio del autor entre otros, la revisión por pares sigue siendo el único método ampliamente aceptado para validar las investigaciones y ha continuado con éxito, con cambios relativamente menores desde su nacimiento (Elsevier, 2018).
A mediados del siglo XIX había más espacio en las revistas que artículos para su impresión, lo cual, hacía que los editores dirigieran sus esfuerzo para el llenado de esos espacios, sin embargo, en el XXI, con el incremento en la cantidad de investigadores en el mundo, así como por la utilización de las herramientas de última generación como; la computadora, la internet, software, la nube etc., podemos observar una mayor demanda de espacios por los investigadores en las revistas especializadas con un factor de impacto alto y como consecuencia las revistas se dan el lujo de discriminar estudios con una revisión superficial o sin revisión, tal como lo demuestra el estudio realizado por (Campos-Arceiz, Primack, & Koh, 2015) sobre la revista Biological Conservation, la cual recibió en un periodo de siete años la cantidad de 4475 artículos, encontrando que el 71% de los artículos enviados a la revista por investigadores chinos fueron rechazados sin revisión en contraste con el 51% de los artículos enviados por investigadores de habla inglesa, en síntesis el 25% de los artículos de los investigadores de habla inglesa fueron publicados en contraste con el 12% de los investigadores chinos. En otro estudio realizado en 2015 por Publishing Research Consortium, encontró que el 74% de los investigadores encuestados manifestaron que la revisión por pares asegura la mejora continua en la calidad de las publicaciones de los artículos en las revistas, sin embargo, en estos resultados los encuestados manifestaron que la revisión por pares es insostenible, considerando que la cantidad de árbitros es limitada y como consecuencia el tiempo de espera para conocer el resultado de la revisión es demasiado (Publishing Research Consortium, 2016). Por lo anterior, es indispensable mejorar la revisión por pares en sus diferentes acepciones tales como: ciego simple, doble ciego, triple ciego y por pares abierta entre otras modalidades, con la finalidad de incrementar la transparencia, disminuir los tiempos de revisión, disminuir el sesgo, por género, nacionalidad, falta de fiabilidad, incapacidad para detectar errores, fraudes, inconsistencia entre revisores (Maj Gen A.K, 2016). Considerando lo antes expuesto, en este estudio se propone el método de bloques incompletos para evaluar ponencias, artículos, proyectos de investigación, el cual, puede contribuir a mejorar los métodos de revisión actuales.
La generación de la ciencia implica una evaluación constante para mejorar en forma continua el conocimiento Actualmente existe en la sociedad mexicana un alto nivel de desconfianza y bajo nivel de credibilidad a las convocatorias de asignación de apoyos económicos para proyectos de investigación científica emitidas por los organismos descentralizados del gobierno federal. En particular del procedimiento de evaluación y asignación de recursos, ya que la selección de proyectos ganadores se ve comprometido por el sesgo de los evaluadores, la selección correcta de beneficiados se convierte en un gran reto, considerando las condiciones extremas, y en ocasiones, apresuradas.
En el caso de los proyectos para la investigación científica, la evaluación por pares es la piedra angular para el proceso de asignación de recursos, sin embargo, la participación por parte de la comunidad científica es insuficiente y frecuentemente poco transparente, añadiendo que la calidad de las evaluaciones es altamente heterogénea debido a la formación de los evaluadores, así como, un proceso al que se suma la lenta asignación de revisores por parte del organismo encargado de la administración de los recursos financieros y un tiempo corto para realizar las evaluaciones de los proyectos en cuestión, por parte de los revisores, que aunque un organismo descentralizado del gobierno federal como el Consejo Nacional de Ciencia y Tecnología (CONACYT) intente mitigarlo a través de su código de ética (SINECYT, 2012), esto nos lleva a tener un dictamen constantemente errado e insuficiente.
Tal es el caso de la convocatoria del año 2016 para el Programa de Estímulos a la Investigación, Desarrollo Tecnológico e Innovación (PEI), donde el proceso de evaluación del PEI, requirió que cada uno de los 2,881 proyectos recibidos fuera evaluado por tres distintos miembros del Registro CONACYT de Evaluadores Acreditados (RCEA) según (CONACYT, 2016), sin embargo, en (CONACYT, 2015) informan que «Se consideran como propuestas aprobatorias y candidatas a apoyo económico, aquellas propuestas cuyo promedio de las tres evaluaciones más los puntos adicionales, cuando correspondan, sumen al menos 75 puntos», donde el punto perjudicial se genera cuando no se descuenta el efecto de los evaluadores (revisión laxa o estricta) del promedio obtenido y por lo tanto, el dictamen resulta sesgado.
En general, la metodología para la evaluación de proyectos científicos con financiamiento, de convocatorias por instituciones gubernamentales u organizaciones privadas, en esencia no es diferente del proceso de evaluación de tratamientos en las áreas de ciencias básicas. Para minimizar este problema, en este estudio se plantea una solución utilizando la ciencia estadística a través del uso de diseños experimentales, que según sea la estructura de los tratamientos y unidades experimentales con las que se cuenta, se tiene un diseño apropiado a implementar, por lo anterior, se plantean dos diseños: el primero es el de diseño de bloques incompletos balanceados (Muhammad & Wahida, 2018), diseño que permite a través de su implementación una flexibilidad y tolerancia a datos faltantes al no tener que asignar todos los tratamientos a cada bloque (evaluador), por limitantes de espacio, tiempo o presupuesto; y el segundo es el diseño de bloques Alpha, éste asigna una fracción de los tratamientos a cada evaluador y, además, toma en cuenta los grupos de evaluadores, entendiendo como grupo a la formación de bloques de evaluadores que comparten características en común; lo cual ayuda a incrementar el nivel de precisión en la estimación de los promedios ajustados de cada tratamiento, ya que el efecto del evaluador y del grupo de evaluadores es removido para la estimación final, eliminando el sesgo del promedio ajustado de cada proyecto.
En suma, si bien no hay un sistema de evaluación que esté exento de vicios, se pueden hacer modificaciones y mejoras que contribuyan a disminuirlos. En esta investigación se propone el uso de los diseños experimentales estadísticos de bloques incompletos balanceados y bloques Alpha para su aplicación en la evaluación de proyectos, se proporcionan los elementos básicos de cada diseño y fórmulas para la construcción de los diseños y las directrices para generarlos a través de un software estadístico de uso libre y gratuito llamado R. En la evaluación se presentan 4 ejemplos, 2 para cada uno de los diseños planteados, que incluye la comparación de resultados entre éstos y el método tradicional, además se describe la manera de implementarlos.
Método
Diseño de Bloques Incompletos Balanceados (BIB)
El diseño de bloques incompletos tiene la ventaja de poder superar algunas limitaciones que se presentan al momento de realizar evaluaciones de proyectos, donde los árbitros o evaluadores no pueden revisar todos los trabajos. BIB permite asignar a cada evaluador una fracción de los proyectos, recibidos por el organismo responsable de la convocatoria, los cuales, son asignados de forma probabilística para garantizar una repartición estandarizada y óptima para la estimación de la calificación de cada proyecto. Además, este tipo de diseño tiene la capacidad de eliminar el “ruido” generado por el evaluador, es decir, remueve el efecto del evaluador considerando que éste, sea más o menos exigente al formular el dictamen final del proyecto de referencia.
Este diseño experimental ha sido implementado en diferentes áreas del conocimiento, entre ellas la agricultura (Mead, 2010) y (González- Hernández, 2006) nos menciona que el espacio físico del terreno no permite que se prueben todos los tratamientos a la vez en el mismo bloque de terreno y, por ello, estos se reparten en varios bloques, es decir solo algunos tratamientos se asignan a un bloque y los restantes tratamientos a los bloques siguientes de terreno. Asignar solo una fracción de ellos a cada tratamiento, de tal manera que todos los tratamientos se puedan acomodar en todos los bloques, es una asignación óptima en el sentido de que permite estimar el promedio ajustado (removiendo el efecto de bloques) de tal manera que estas estimaciones tengan un nivel similar de precisión.
Este diseño también se utiliza en la industria, por ejemplo: para encontrar los valores óptimos de la temperatura para el mantenimiento de productos orgánicos, la presión adecuada para la conversión de metilglucósido en isómeros de monovinil, entre otras aplicaciones (Mendoza & López, 2001).
Además, la implementación de este diseño de experimentos es relativamente simple en los software estadísticos que existe en el mercado, por ello, el uso de este diseño experimental en la evaluación de proyectos, permitirá a las distintas instituciones de gobierno y organizaciones privadas realizar evaluaciones más flexibles, justas y sobre todo estandarizadas, ya que permite estimar los promedios de los tratamientos con un nivel similar de precisión además de que remueve el efecto de bloques, el cual, puede castigar o favorecer proyectos dependiendo del contexto y juicio del evaluador.
Fórmulas para la construcción de BIB
Supongamos que en la nueva convocatoria en la cual se establece que se asignarán recursos financieros del Consejo Nacional de Ciencia y Tecnología (CONACYT) llegan un total de 50 solicitudes (proyectos), para determinar cuántos evaluadores se necesitan, se puede utilizar la siguiente ecuación (Mendoza & López, 2001) que determinar la cantidad de veces que deberá de ser evaluado cada proyecto.
Donde r es la cantidad de veces que se evaluará cada proyecto, b es el número de evaluadores (bloques), t la cantidad de proyectos o solicitudes (tratamientos) a evaluar y k el número de proyectos asignados a cada evaluador. Por lo que, despejando la función se puede encontrar el número de evaluadores:
Entonces, supongamos que deseamos que los 50 proyectos o solicitudes sean evaluados r = 2 veces cada uno, asignando k = 4 proyectos a cada evaluador, entonces tenemos que el número requerido de evaluadores es:
Y si, por otro lado, se tiene una cantidad limitada de evaluadores y queremos encontrar la cantidad óptima de proyectos por asignar a cada evaluador, despejando la primera ecuación tenemos que:
Entonces, si solo contamos con 10 evaluadores, 50 proyectos y cada proyecto contará con solo 2 evaluaciones, tenemos que:
Estas reglas proporcionadas por el diseño experimental en bloques incompletos deberán de respetarse, ya que, si los valores óptimos se alteran sin realizar el debido ajuste (utilizando las fórmulas anteriores), el diseño de bloques incompletos podrá quedar desbalanceado o no podrá ser implementado. Esto es de gran importancia para lograr estimaciones de los promedios con similar nivel de precisión y que los evaluadores se les asigne el mismo número de proyectos a evaluar.
Diseño de Bloques Alpha
Por otro lado, el diseño de bloques Alpha tiene la ventaja de tomar en cuenta las variaciones que se pueden presentar en los juicios de los evaluadores debido a su área de conocimiento (u otro factor de heterogeneidad) su categoría o nivel en un grupo, es decir, que debido a que dos personas no juzgan de la misma manera un proyecto, se puede considerar que una parte de este efecto puede ser causado por su “experiencia” o su área de conocimiento, donde prestará atención a otros puntos que alguien ajeno a ello no tomaría en cuenta.
Este diseño ha sido implementado en áreas como la agricultura entre otras áreas (Mead, 2010) y (González- Hernández, 2006). Para realizar este tipo de experimentos hay que agrupar a los evaluadores (bloques incompletos) en distintas categorías que se le conocen como repeticiones, a diferencia del diseño presentando anteriormente, este es un diseño de bloques con repeticiones, es decir que en cada repetición se deberán de evaluar todos los tratamientos.
Para poder construir un diseño de bloques Alpha se presentan las siguientes fórmulas a tomar en cuenta.
Fórmulas para la construcción de Bloques Alpha
Supongamos que en la nueva convocatoria de CONACYT se reciben un total de 50 proyectos para una convocatoria específica, para determinar cuántos evaluadores deberán de presentarse se deberá de tomar en cuenta la ecuación (González- Hernández, 2006) siguiente:
Donde b es la cantidad de evaluadores (bloques incompletos), s es la cantidad de evaluadores por repetición y r el número de repeticiones para el diseño (categoría o grupos de evaluadores), es decir, si tenemos 20 evaluadores, y el diseño cuenta con 2 repeticiones que corresponden al grupo al que pertenece los evaluadores en el sistema nacional de investigadores (SNI), donde la repetición 1 corresponde a evaluadores que pertenecen al nivel I del SNI, mientras que la repetición 2 son los evaluadores que pertenecen al nivel II del SNI, la cantidad de evaluadores por repetición se determinaría por la ecuación siguiente:
Y sustituyendo:
Es decir, que la cantidad de evaluadores requeridos son 10 pertenecientes al nivel I del SNI y 10 al nivel II del SNI, por otro lado, para determinar la cantidad de tratamientos que el diseño permite, se deberá utilizar la ecuación siguiente:
Donde t es la cantidad de tratamientos (proyectos por evaluar), s la cantidad de evaluadores por repetición, y k la cantidad de proyectos asignados por evaluador, por otro lado, si queremos ajustar el diseño de bloques Alpha a la cantidad de proyectos con respecto a la cantidad de evaluadores por categoría, deberemos despejar la ecuación con respecto a k, es decir, si tenemos 50 proyectos y sabemos que son 10 evaluadores por cada repetición, tenemos que k es:
Es decir que cada evaluador deberá evaluar 5 proyectos y emitir 5 dictámenes. Lo antes expresado muestra la forma de construir utilizando las fórmulas de los dos diseños bajo estudio. A continuación se presentan los resultados con ejemplos que ilustran como aplicar estos dos diseños de experimentos. El primer ejemplo es para la evaluación de proyectos y el segundo para la evaluación de ponencias. Cada uno de los dos ejemplos se aborda bajo los dos diseños de experimentos.
Resultados
En esta sección se presentan dos ejemplos primero bajo el diseño experimental BIB y posteriormente otros dos ejemplos bajo el diseño de bloques Alpha.
Diseño experimental BIB
Se presentan dos ejemplos, el primero para la evaluación de proyectos y segundo para la evaluación de ponencias.
Ejemplo 1. Evaluación de proyectos
Construcción del diseño BIB para la evaluación de proyectos
Utilizando la librería “crossdes” desarrollado por (Sailer, 2013) y que está disponible en el software estadístico R se puede construir experimentos en bloques incompletos balanceados (BIB) de manera sencilla, supongamos que son t = 50 proyectos a evaluar por b = 25 evaluadores y k = 4proyectos para cada evaluador entonces uno de los posibles diseños es el siguiente:
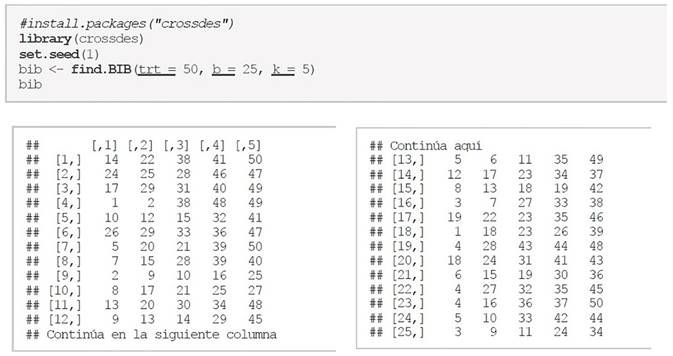
Donde cada fila es el i-ésimo evaluador y cada columna es el j-ésimo proyecto por evaluar por el i-ésimo evaluador y cada celda es el identificador del proyecto por evaluar. Es decir, el evaluador 1 evaluará 5 proyectos que corresponden a los identificadores 14, 22, 38, 41 y 50, el evaluador 2 evaluará 5 proyectos que corresponden a los identificadores 24, 25, 28, 46 y 47, continuando así sucesivamente.
Generación de datos sintéticos ejemplo evaluación de proyectos
Para generar datos sintéticos para las calificaciones de cada proyecto bajo el diseño BIB se han utilizado las librerías dplyr desarrollado por (Wickham, Francois, Henry, & Müller, 2017) y tidyr desarrollado por (Wickham & Henry, tidyr: Easily Tidy Data with 'spread()' and 'gather()' Functions, 2017) para transformar el objeto (bib) en un objeto del tipo data.frame que será donde se almacenarán los datos sintéticos. Además, con el comando head(…) se muestra como quedan ordenados los datos (solo se muestran los primeros 6 de 50 para una fácil interpretación):

Observe que la salida está dada por el comando head (Eval_Proyecto), el cuál retorna 6 observaciones con dos columnas. La primera columna es Id_Proyecto (identificador del proyecto) y la segunda el Id_Evaluador (identificador del evaluador), donde se observa que las primeras 5 evaluaciones forman parte del evaluador 1 para los proyectos 14, 22, 38, 41 y 50, mismos que se observan en la sección de Construcción del diseño BIB. Hay que recordar que este resultado se da por el tratamiento de la matriz bib, para ajustarlo a un formato más comprensible para el lector y para el software estadístico R, ya que es bajo este formato el que trabajan los paquetes que se usarán para el análisis de datos.
Posteriormente se simulan datos bajo el diseño experimental BIB para los 50 proyectos asumiendo normalidad en la respuesta con una media de 7 y una desviación estándar de 1 y las respuestas mayores a 10 se eliminan, los resultados se añaden como una nueva columna llamada Calificacion al objeto Eval_Proyecto y se presentan las primeras 6 observaciones de 50:

Nuevamente la salida está dada por el comando head (Eval_proyecto), a la cual se ha añadido la columna Calificacion (calificación asignada por el i-ésimo evaluador al proyecto asignado) con los datos obtenidos de la generación de datos sintéticos. Los datos completos pueden ser consultados en el cuadro incluido en el Apéndice C.1.
Estimación de promedios ajustados para la evaluación de proyectos
Para implementar las evaluaciones realizadas bajo un diseño experimental BIB, será necesario utilizar la librería llamada nlme (instalarla con install.packages("nlme")) y cargada al entorno de R antes de comenzar el análisis. Posteriormente, se utilizará la función lme(…) como se muestra a continuación para realizar el análisis que nos dará los promedios ajustados de calificación de cada proyecto removiendo el efecto de evaluadores (bloques):
Observe que la función lme (…) recibe como primer parámetro la fórmula del modelo de la siguiente manera:

Misma que puede ser interpretada de la siguiente manera:
Como segundo parámetro el nombre del objeto que contiene a dichos elementos (en este caso el objeto datos), previo a calcular la calificación promedio final de cada tratamiento (proyecto), se realizará el análisis de varianza con la función anova(…), como se muestra a continuación:

Posteriormente, para obtener los promedios ajustados (calificación final) de cada tratamiento (proyecto), se deberá utilizar otra librería llamada emmeans (que deberá de ser instalada y cargada al entorno de R antes de utilizarse). Una vez, obtenido dichos promedios, será posible dictaminar con un nivel similar de precisión los proyectos en cuestión. Para lograr lo anterior, primeramente, se harán los cálculos de los promedios y posteriormente se reordenarán de manera descendente, con base en la columna de medias (emmean), para consultar solo los primeros 5 lugares se consultan a través de los índices del objeto, como se muestra en el bloque de código siguiente:

Comparaciones entre el método tradicional y el diseño BIB
Utilizando la librería dplyr, se obtiene el promedio tradicional con la fórmula
Para este ejemplo, primero, se ordenan los promedios obtenidos con el método tradicional y se presentan los primeros 15 lugares con el comando head (…) y con el comando cbind (…) se unen los promedios obtenidos bajo el método tradicional y los obtenidos bajo el diseño BIB como se muestra a continuación:

Observe que ha sido el proyecto 16 el que ha obtenido la mejor calificación (con 7.51 puntos), seguido del proyecto 9 (con 7.49 puntos), en tercer lugar, el proyecto 44 (con 7.33 puntos), en cuarto lugar, el proyecto 29 con (7.30 puntos) y, en quinto lugar, el proyecto 7 (con 7.24 puntos). Por otro lado, los 5 últimos lugares se pueden consultar a través de las ultimas 5 posiciones del objeto, como se muestra en el siguiente bloque de código.
En el caso del método tradicional el mejor proyecto evaluado es el Proyecto 48 con un promedio de 9.333, mientras que utilizando el diseño BIB que remueve el efecto de bloques en los promedios obtenidos, el proyecto 48 se encuentra en la posición número 15 con una calificación promedio de 6.816. De igual manera, el Proyecto 12 que se encuentra en la segunda posición utilizando el método tradicional, sin embargo, utilizando el diseño experimental BIB se encuentra en la posición número 10 con una calificación promedio de 7.02.
Para resumir el resto de los resultados, se presenta la Figura 1, donde se comparan los promedios obtenidos utilizando ambos métodos (tradicional y BIB) para el ejemplo evaluación de proyectos. Las calificaciones promedio finales se encuentran ordenadas de mayor a menor con respecto al método tradicional. Además, se aprecia claramente que el método tradicional presenta mayor variabilidad (errores estándar más grandes, tal como se observa en el espectro de color gris que rodea al método tradicional). Por otro lado, se aprecia claramente que el método BIB resulta con un error estándar más reducido, y los promedios en su mayoría son diferentes a los obtenidos aplicando el método tradicional.
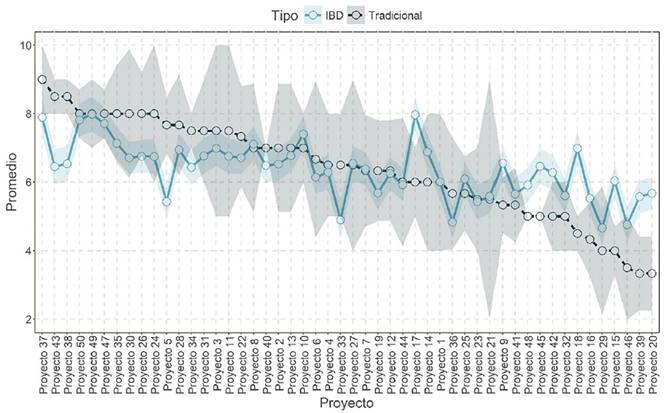
Figura 1 Comparación entre el modelo tradicional y el modelo BIB entre las calificaciones obtenidas de los proyectos, donde el espectro del color de su respectivo modelo representa el error estándar
El código completo (sin la generación de datos sintéticos y gráficas) se puede obtener en el Apéndice A para una rápida y sencilla implementación.
Ejemplo 2. Evaluación de ponencias
Construcción del diseño BIB para la evaluación de ponencias
Suponga que se desean evaluar un total de 40 ponencias y que se cuenta con 20 evaluadores, y se decide que cada evaluador revisará 4 ponencias, dicho diseño de bloques se muestra a continuación:

Observe que los datos fueron asignados a un objeto distinto (bib2) al mostrado en el ejemplo anterior (bib), esto con la finalidad de no confundir al lector.
Recordando que cada fila corresponde al i-ésimo evaluador y cada columna es el j-ésimo proyecto por evaluar y cada celda es el identificador del proyecto por evaluar, se tiene que los evaluadores revisarán 4 ponencias cada uno y el primer evaluador deberá revisar los proyectos con los identificadores 5, 22, 28 y 40, el segundo evaluador deberá revisar los proyectos con los identificadores 10, 15, 31 y 37, continuando así con el resto de los evaluadores.
Generación de datos sintéticos para la evaluación de ponencias
Para simular los datos en este ejemplo se utiliza un código similar al presentado anteriormente en el ejemplo de evaluación de proyectos, las diferencias radican en el tamaño de bloques (la variable b2), así como el nombre de las columnas y el objeto donde se almacenan los datos de este ejemplo (Eval_Presentacion) como se muestra en el código siguiente:
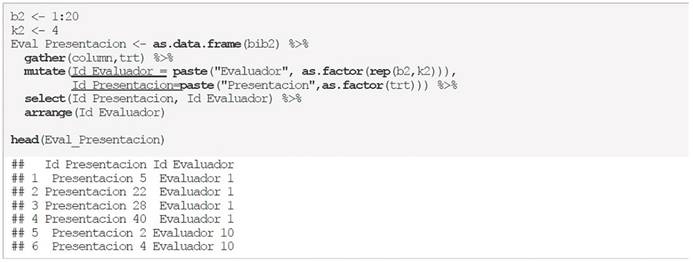
Observe que la salida solo muestra las primeras 6 observaciones ya que también se utilizó el comando head (Eval_Presentacion). La primera columna es el Id_Presentacion (identificador de la presentación) y la segunda Id_Evaluador (identificador del evaluador), donde se observa que las primeras 4 evaluaciones forman parte del evaluador 1 para los proyectos 5, 22, 28 y 40, mismos que se observan en la sección de Ejemplo 2. Evaluación de ponencias.
Construcción del diseño BIB para la evaluación de ponencias
Además, para simular los datos de las calificaciones de cada proyecto, se utilizan nuevos coeficientes beta (β) como se muestra en el siguiente código:

Nuevamente la salida está dada por el comando head (Eval_Presentacion), a la cual, se ha añadido a la columna Score (calificación asignada por el i-ésimo evaluador al proyecto asignado) con los datos obtenidos de la generación de datos sintéticos. Los datos completos pueden ser consultados en el cuadro del apéndice C.2.
Estimación de promedios ajustados para la evaluación de ponencias
Recuerde que los datos deben de ser ingresados con una estructura ordenada, donde cada fila es una observación, y cada una de las tres columnas representa el identificador del proyecto, el identificador del evaluador y la calificación (score asignado a cada tratamiento por el evaluador), como se muestra a continuación.

Ahora se implementará el análisis de varianza con los comandos siguientes:

Posteriormente se utilizará la función anova (…), como se muestra a continuación:

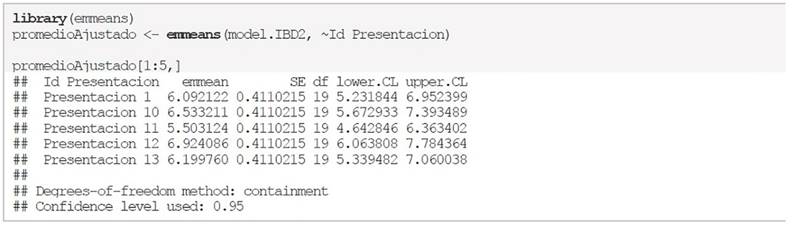
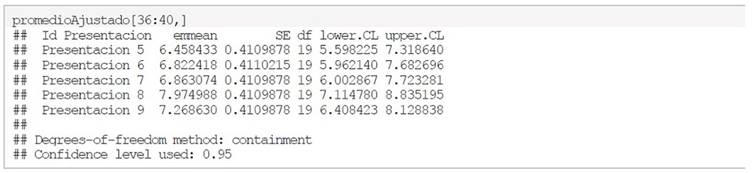
Y para obtener las medias se utilizan los comandos siguientes, además se presentan las primeras 5 promedios ajustados:
Por otro lado, los 5 últimos lugares se pueden consultar utilizando sus últimas 5 posiciones como se muestra a continuación:
Comparaciones entre el método tradicional y el diseño BIB
En este ejemplo también se obtienen los promedios a través del método tradicional (que es un simple promedio de las evaluaciones de cada proyecto) y el BIB, y después se ordenarán con base a las mejores calificaciones obtenidas con respecto al método tradicional. De igual forma, se presenta una comparación entre los primeros 6 lugares.

Observe que en el caso del método tradicional la mejor ponencia evaluada es la Ponencia 26, con un promedio de 9.5, mientras que con el método BIB este proyecto se encuentra en la posición número 2, con una calificación promedio de 7.66. La Ponencia 8, que se encuentra en la primera posición con un promedio de con el 7.97 utilizando el método BIB, mientras que con el método tradicional se encuentra en la quinta posición con un promedio de 8.5.
En la Figura 2 se comparan ambos métodos para el ejemplo evaluación de ponencias. En dicha Figura, se aprecia que el error estándar del método tradicional tiene una mayor variabilidad que el método BIB. Además, se observan significativas diferencias en el ranking de las mejores ponencias utilizando los dos métodos y por supuesto siendo evaluadas con un nivel similar de precisión como se puede observar en el ranking obtenido bajo el método BIB, ya que remueve el efecto del evaluador.
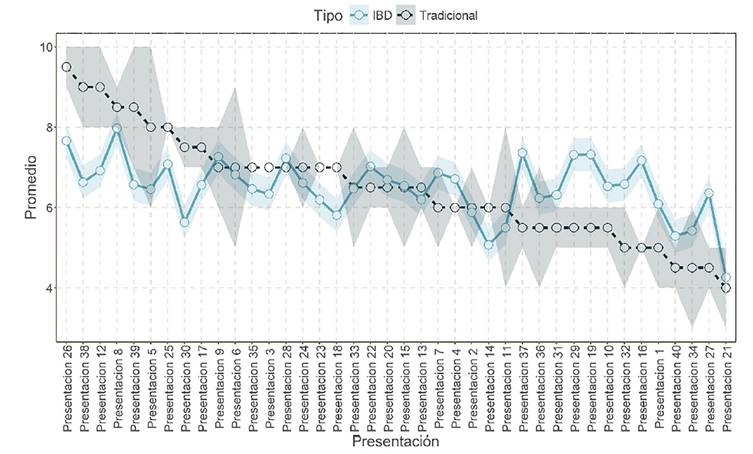
Figura 2 Comparación entre el modelo tradicional y el modelo BIB entre las calificaciones obtenidas por las ponencias, donde el espectro del color de su respectivo modelo representa el error estándar
El código completo (sin la generación de datos sintéticos y gráficas) se puede obtener en el Apéndice A para una rápida y sencilla implementación.
Diseño Alpha
Ejemplo 1. Evaluación de proyectos
Construcción del diseño de bloques Alpha para la evaluación de proyectos
Utilizando la librería “agricolae” desarrollado por (De Mendiburu, 2017) y que se puede encontrar en el software estadístico R se puede construir de manera sencilla los diseños experimentales para bloques Alpha (BDα), supongamos que son t = 50proyectos a evaluar, cada evaluador deberá evaluar 5 proyectos y existen 3 réplicas, donde las réplicas lo conformará el tipo de evaluador. En este caso el tipo de evaluador lo conformarán los investigadores que pertenecen al nivel I, II y III del SNI. Observe que, en esta ocasión, no fue necesario definir la cantidad de evaluadores, será el propio diseño el que determina la cantidad de bloques (evaluadores) necesarios.
Para ello, se crean los vectores con los datos a utilizar y la construcción del bloque se realiza a través de la función design.alpha (…) incluida en la librería nombrada anteriormente, donde se incluyen los tratamientos, la cantidad de evaluaciones por bloque, las réplicas y además como parámetro extra se incluye a seed que sirve para que el diseño propuesto bajo los otros parámetros sea siempre el mismo, esto para efectos de replicar los ejemplos propuestos. Entonces uno de los posibles diseños es el siguiente:
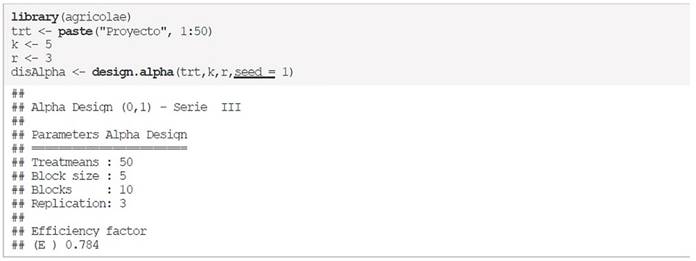
Observe que, en esta ocasión, se han declarado los vectores fuera de la función design.alpha (…), el vector trt contiene el nombre de los 50 proyectos, el vector k incluye el valor de las evaluaciones por bloque y r es la cantidad de réplicas, el resultado que retorna la función, describe los parámetros utilizados para diseñar los bloques.
El objeto disAlpha tiene una estructura que contiene no solo el diseño de los bloques, sino que también incluye la lista para añadir las calificaciones obtenidas para cada tratamiento, para analizar la estructura de dicho objeto, se utiliza la función str (…) el cuál solo incluye como parámetro el objeto a analizar.
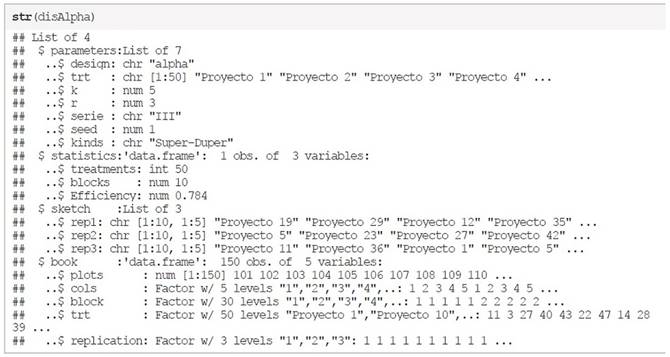
La lista de manera jerárquica incluye cuatro componentes principales, parameters que son los parámetros utilizados, statistics que es un pequeño análisis de la eficiencia del bloque propuesto, sketch que es el diseño de bloques y book que es la lista preparada para hacer el tratamiento de los datos.
Para observar la distribución de los bloques entre las repeticiones solo basta con llamar al objeto que se nombró como disAlpha y extraer el diseño de bloques como se muestra en el siguiente bloque de código:

Debido a que los 30 evaluadores están divididos en tres grupos (SNI nivel I, II y III) con 10 evaluadores por ensayo, entonces en cada repetición de este diseño, el i-ésimo evaluador del k-ésimo grupo evaluará 5 proyectos donde cada observación es el identificador del proyecto a evaluar.
Entonces, en el primera ensayo se encuentran los evaluadores del grupo nivel I y el primer evaluador de este grupo, revisará los proyectos 19, 11, 33, 45 y 48, mientras que, en el segundo ensayo, el primer evaluador del grupo nivel II del SNI, revisará los proyectos 5, 19, 16, 47 y 1, mientras que en el tercer ensayo el primer evaluador del grupo nivel III, revisará los proyectos 11, 30, 46, 42 y 20.
Como se mencionó anteriormente, el objeto no solo contiene el sketch, sino también incluye los datos tratados para simplemente añadir la columna de calificaciones para realizar el análisis, para observar cómo está distribuida dicha lista, se puede hacer la consulta con el siguiente comando, donde se añadió la función head (…) para mostrar solo las primeras 6 observaciones:

Observe que las primeras dos columnas corresponden a datos a los que no se les dará uso en el presente documento, mientras que las siguientes columnas corresponden a los bloques (el identificador del evaluador), los tratamientos (el identificador del proyecto) y el ensayo (el identificador del grupo).
Generación de datos sintéticos para la evaluación de proyectos
Para la simulación de datos sintéticos, se presentan los mismos códigos que se presentan en el diseño de bloques incompletos, pero con la modificación para tomar en cuenta un efecto de bloque extra, que representa a las repeticiones, esto se logra con una segunda matriz diseño Z2.
El resto de los datos pueden ser consultados en el cuadro incluido en el apéndice C.3.
Estimación de promedios ajustados para la evaluación de proyectos
Para calcular los promedios ajustados bajo un diseño Alpha, se utilizará la función lmer (…) misma que proviene del paquete lme4 desarrollado por (Bates, Máchler, Bolker, & Walker, 2015), y que deberá de ser instalada como los paquetes anteriores, y posteriormente cargada al entorno de R como se muestra a continuación:

Observe que al inicio del código se han modificado los nombres de las columnas para que sean nombres significativos y también nótese que la función lmer (…) recibe como primer parámetro la fórmula del modelo de la manera siguiente:
Donde se toma en cuenta el efecto de tratamientos (como efecto fijo), bloques y bloques anidados en réplica, ambos como efectos aleatorios. Y como segundo parámetro el nombre del objeto que contiene a dichos elementos (en este caso el objeto datos), para realizar el análisis de varianza se usa también la función anova (…), como se muestra a continuación:

Para obtener los promedios ajustados de cada tratamiento se utiliza el comando emmeans, como se muestra en el código siguiente:

Observe que los dos proyectos con las más bajas calificaciones han sido el proyecto 36 (con 4.49 puntos) y el proyecto 29 (con 4.23 puntos).
Comparaciones entre el método tradicional y el diseño de bloques Alpha
Utilizando la librería dplyr, se obtiene el promedio tradicional que es un simple promedio de todas las evaluaciones realizadas a cada proyecto, pero sin corrección por el efecto de evaluador (bloque). Además, también se reporta el error estándar de cada tratamiento evaluado. Posteriormente se ordenan los promedios obtenidos del diseño de bloques Alpha con respecto a los promedios obtenidos bajo el método tradicional y se presentan los primeros 15 lugares con el comando head (…) y el comando cbind (…) une los resultados de los métodos Tradicional e Alpha.

Observe que ha sido el proyecto 10 el que ha obtenido la mejor calificación (con 7.73 puntos), seguido del proyecto 47 (con 7.66 puntos), en tercer lugar, el proyecto 50 (con 7.66 puntos), en cuarto lugar, el proyecto 49 con (7.61 puntos) y, en quinto lugar, el proyecto 3 (con 7.59 puntos). Por otro lado, los 5 últimos lugares se pueden consultar utilizando sus últimos 5 índices.
Se observa que utilizando cualquiera de los dos métodos el Proyecto 10 se mantiene en la posición número uno, pero con un promedio distinto de 8.66 utilizando el método tradicional y 7.73 empleando el diseño experimental Alpha. Por otro lado, el segundo lugar aplicando el método tradicional es el Proyecto 35 con un promedio de 8.66, el cual se muestra en la posición número 7 utilizando el diseño Alpha con un promedio de 7.37. Mientras que el segundo lugar de los proyectos evaluados a través del método de diseño Alpha, se encuentra en el décimo lugar tratando los datos con el método tradicional.
La Figura 3 compara el método tradicional y el método de diseño Alpha con el ejemplo evaluación de proyectos. En dicha Figura, se aprecia que el error estándar del método tradicional tiene una mayor variabilidad que tratando los datos con el método BDα. Además, que los rankings de los proyectos son diferentes entre ambos métodos.
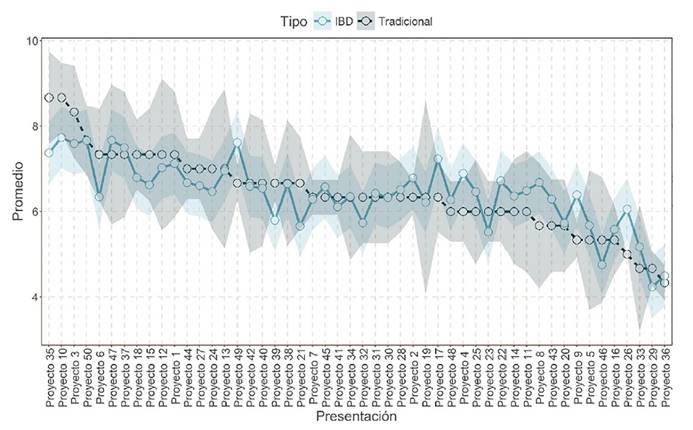
Figura 3 Comparación entre el modelo tradicional y el modelo Diseño de bloques Alpha entre las calificaciones obtenidas de los proyectos, donde el espectro del color de su respectivo modelo representa el error estándar
El código completo (sin la generación de datos sintéticos y gráficas) se puede obtener en el Apéndice B para una rápida y sencilla implementación.
Ejemplo 2. Evaluación de ponencias
Construcción del diseño de bloques Alpha para la evaluación de ponencias
De igual manera con la librería agricolae del software estadístico R se realiza el diseño para bloques Alpha (BDα), pero ahora con t = 50proyectos a evaluar, cada evaluador deberá dictaminar 5 proyectos y existen 2 repeticiones en donde uno pertenece a un grupo de evaluadores del área de tecnologías y el segundo a un grupo de evaluadores del área de ciencias exactas.

Para observar cómo se distribuyen los bloques entre las repeticiones solo basta con llamar al objeto que se nombró como disAlpha2 y extraer el diseño de bloques como se muestra en el bloque del código siguiente:
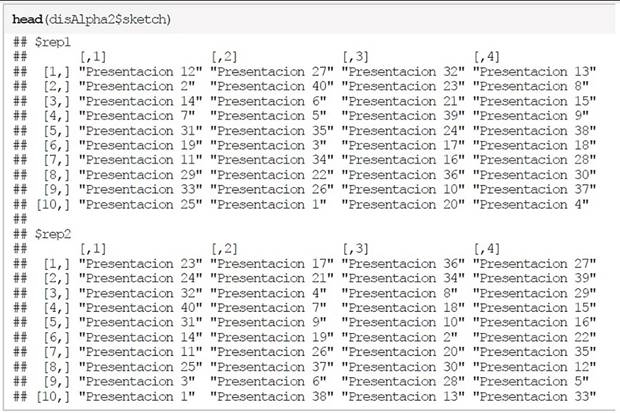
Debido a que los 20 evaluadores están divididos en dos grupos (área de tecnologías y área de ciencias exactas) con 10 evaluadores por grupo, entonces en cada repetición del método el i-ésimo evaluador del k-ésimo grupo realizará 4 evaluaciones donde cada observación es el identificador del proyecto a evaluar.
Entonces, en el primer grupo se encuentran los evaluadores del área de tecnologías y el primer evaluador de este grupo, revisará los proyectos 12, 27, 32 y 13, mientras que, en el segundo grupo, el primer evaluador del área de ciencias exactas revisará los proyectos 23, 17, 36 y 27.
Como se mencionó anteriormente, el objeto no solo contiene el sketch, sino también incluye los datos tratados para simplemente añadir la columna de calificaciones (evaluaciones) para realizar el análisis, para observar cómo está distribuida dicha lista, se puede hacer la consulta con el siguiente comando, donde se añadió la función head (…) para mostrar solo las primeras 6 observaciones:

Como se mencionó en el ejemplo anterior, las primeras dos columnas corresponden a datos a los que no se les dará uso en el presente documento, mientras que las siguientes columnas que corresponden a los bloques (el identificador del evaluador), los tratamientos (el identificador del proyecto) y el identificador del grupo serán utilizadas durante el análisis de las calificaciones.
Generación de datos sintéticos para la evaluación de ponencias
Para la simulación de datos sintéticos, se presentan los mismos códigos que se presentan en el diseño de bloques incompletos, pero ahora también se toma en cuenta el efecto las repeticiones lo cual se incluye en una segunda matriz diseño Z2:

El resto de los datos pueden ser consultados en el cuadro incluido en el apéndice C.4
Estimación de promedios ajustados para la evaluación de ponencias
De igual manera para implementar el diseño Alpha para este ejemplo se utilizan los comandos que se muestran a continuación:

Mientras que, para el análisis de varianza, se utiliza lo que se muestra a continuación:

También para los promedios ajustados de cada tratamiento (proyecto) se usa el comando emmeans, como se muestra en el código siguiente:
Comparaciones entre el método tradicional y el diseño de bloques Alpha
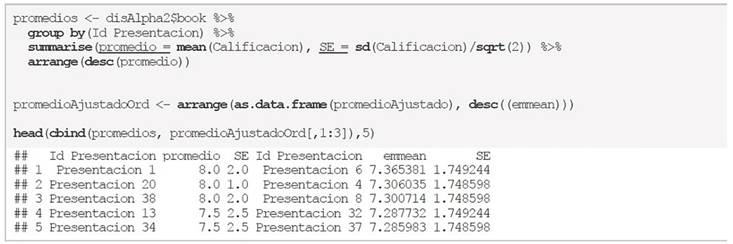
Utilizando la librería dplyr, se obtiene el promedio tradicional como un simple promedio de todas las evaluaciones realizadas a cada ponencia, pero sin corrección por el efecto de evaluador (bloque). Además, también se reporta el error estándar de cada tratamiento evaluado. Después estos se fusionan con los promedios ajustados obtenidos con del diseño de bloques Alpha y ordenando los promedios con respecto a los resultados con el método tradicional se presentan los primeros 5 lugares con el comando head(…) y el comando cbind(…) los une al método Alpha.
En la Figura 4, se comparan los promedios obtenidos utilizando el método tradicional y el diseño experimental Alpha para el ejemplo de evaluación de ponencias. En dicha figura, se aprecia que el error estándar de ambos métodos es bastante amplio y además también se observa que los rankings entre ambos métodos son diferentes.
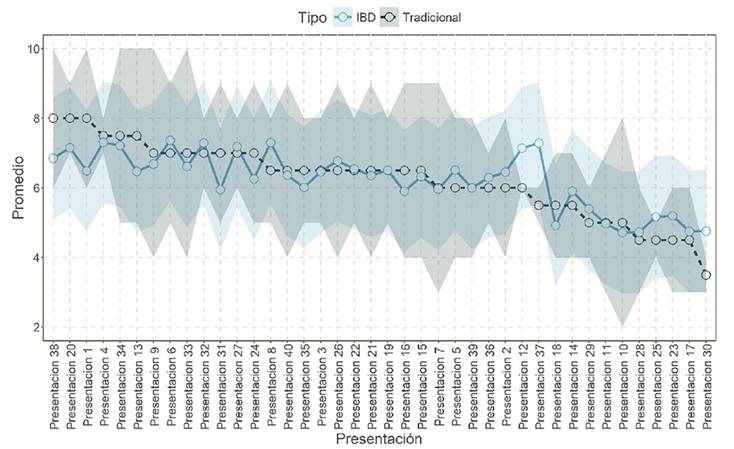
Figura 4 Comparación entre el modelo tradicional y el modelo Diseño de bloques Alpha entre las calificaciones obtenidas por las ponencias, donde el espectro del color de su respectivo modelo representa el error estándar
El código completo (sin la generación de datos sintéticos y gráficas) se puede obtener en el Apéndice B para una rápida y sencilla implementación.
Discusión y Conclusiones
La implementación de estos dos métodos muestra que los métodos tradicionales como: ciego simple, doble ciego, triple ciego y por pares abierta entre otras modalidades, y los métodos basados en los diseños de experimentos BIB y bloques Alpha producen rankings diferentes de los tratamientos o proyectos evaluados. Esto es de esperarse, ya que los métodos tradicionales al ser calculados como un simple promedio, entre las evaluaciones emitidas por los revisores a quienes se les asigno dichos proyectos, está sesgado por no remover el efecto del revisor. Mientras que los dos diseños experimentales aquí propuestos (BIB y Alpha) tienen la capacidad de remover el efecto del revisor o evaluador (BIB) y del revisor y grupo de revisores o evaluadores (Alpha); por lo anterior, los promedios son significativamente diferentes a los obtenidos con el método tradicional. Por la capacidad que tienen estos diseños para remover el efecto de bloques producen estimaciones menos sesgadas y sobre todo se logran evaluaciones con un nivel similar de precisión. Es claro que, si la variabilidad entre los revisores es muy fuerte, se pueden cometer injusticias en el proceso de la evaluación de los proyectos y en consecuencia no utilizar adecuadamente los recursos financieros. Bajo los métodos tradicionales, se beneficiará aquellos proyectos que fueron asignados a revisores o evaluadores menos exigentes, mientras que afectará significativamente a aquellos proyectos que se asignaron revisores más exigentes; resultados que pueden no reflejar la calidad real de los proyectos.
Por lo anterior, en este trabajo, proponemos los elementos necesarios para la construcción y análisis de estos experimentos para la evaluación de proyectos de instituciones gubernamentales y no gubernamentales; con el objetivo de brindar evaluaciones con mayor grado de precisión que pueden contribuir a reducir las críticas e inconformidades que actualmente existen en los procesos de evaluación. Además, estamos convencidos que la implementación de este proceso de evaluación de proyectos en las dependencias gubernamentales es relativamente simple, ya que como se describió detalladamente en la presente publicación existe software libre que pude utilizarse para la construcción y estimaciones correspondientes en la evaluación de los proyectos de forma automática. La implementación de estos diseños también puede abonar a la transparencia de las instituciones encargadas de asignar recursos públicos o privados para la implementación de proyectos en beneficio de la sociedad, ya que garantiza un proceso transparente en la asignación de recursos financieros.
Si bien es cierto, que el uso de estos diseños experimentales no es nuevo en la ciencia, si puede ser, de gran provecho que se implementen en la administración pública, para la asignación de recursos para proyectos tanto de ciencia, tecnología o de cualquier índole, con lo cual se suma a la transparencia de las instituciones que en países en vías de desarrollo como México, donde frecuentemente son cuestionadas las instituciones a cargo de asignar los recursos financieros, a personas físicas o morales. Además, también es importante mencionar que en la literatura estadística de diseño de experimentos existen otros diseños de bloque incompletos que pueden ser también incorporados a la evaluación de proyectos que pueden ser más flexibles que los aquí presentados.
Finalmente, es importante resaltar que las calificaciones asignadas a los proyectos evaluados debe de estar en una escala continua (en este caso una calificación entre 0 y 10) para que los métodos propuestos sean válidos, ya que si la calificación asignada es binaria u ordinal el método de análisis deberá adaptarse bajo el contexto de modelos lineales generalizados con respuestas binarias y ordinales, lo cual, no es difícil de adaptar pero se debe de tomar en cuenta, ya que de no hacerlo, los resultados esperados pueden estar sesgados.
La aportación más importante de este trabajo es que promueve el uso de herramientas cuantitativas (estadísticas) con la finalidad de reducir los diferentes tipos de sesgos que se generan con los métodos tradicionales
Conclusiones
En este artículo se propone el uso de dos diseños experimentales comunes en el área de ciencias biológicas (Diseño de bloques incompletos balanceados y diseño de bloques Alpha), para el proceso de evaluación de proyectos en instituciones gubernamentales y no gubernamentales. De acuerdo con los ejemplos realizados, ambos diseños experimentales producen resultados similares, pero que son bastante diferentes al método tradicional; básicamente, esto se debe a la capacidad de los diseños experimentales propuestos de remover el efecto del evaluador a diferencia del método tradicional. Este efecto se ve reflejado en la dictaminación final de los proyectos, ya sea en beneficio o perjuicio, ya que el ranking resultante está enmascarado con las calificaciones verdaderas de los proyectos más el efecto del evaluador, llegando a revertir este ranking.
Como contribución adicional del trabajo, se proporciona el código en software R para la implementación de estos diseños experimentales para la evaluación de proyectos. Finalmente, el uso apropiado de estos diseños experimentales proporciona una evaluación más justa de los proyectos y puede contribuir a mejorar la transparencia y profesionalismo de las dependencias u organizaciones encargadas de asignar proyectos con recursos financieros a personas físicas o morales.








