




![[ARTÍCULO RETRACTADO]Teleconexiones atmosféricas-oceánicas (océanos Pacífico y Atlántico) moduladoras de veranos húmedos y secos en el Núcleo del Monzón de Norte América](/img/es/next.gif)






 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La Investigación de Operaciones es la rama de las matemáticas que estudia y aborda problemas de toma de decisiones. Dentro de este campo, la optimización discreta se enfoca en problemas donde la naturaleza de las variables de decisión es de carácter discreto. En particular, en este trabajo se aborda el problema de p-centro capacitado (CpCP, por sus siglas en inglés: Capacitated p-Center Problem), que consiste en ubicar p instalaciones y asignar usuarios a cada una de ellas, de tal manera que se minimice la distancia máxima entre cualquier usuario y su instalación asignada, sujeto a la capacidad en la demanda restringida por cada instalación.
El CpCP es un problema de marcada importancia y relevancia en el campo de ciencias de localización, ya que existen diversas aplicaciones prácticas que pueden ser modeladas como un CpCP. El criterio minmax que compone al problema es usualmente aplicado para minimizar los efectos adversos en el peor de los casos durante un servicio proporcionado. Usos comunes pueden ser encontrados en la planificación de distritos escolares o en el diseño del sistema de cobertura en salud, particularmente problemas que surgen en situaciones de emergencia, tales como proporcionar servicios médicos mediante la localización de instalaciones de emergencia o ambulancias, o la ubicación de las estaciones de bomberos, donde es claro que el preservar la vida humana es lo más importante. Las aplicaciones anteriores, naturalmente muestran la presencia de un límite en la capacidad de servicio que cada instalación puede ofrecer.
Éste problema se define como sigue: se tiene un conjunto de nodos V que representan a los usuarios o clientes (nodos que generan demanda) que necesitan algún tipo de servicio, y un conjunto de nodos U que contiene a puntos donde pueden ubicarse las instalaciones; una demanda
El problema de p-centro en su versión sin capacidad ha sido ampliamente estudiado. Farahani y Hekmatfar (2009), y Elloumi et al. (2004) ofrecen una extensa revisión bibliográfica. Sin embargo la investigación en el CpCP ha sido más limitada. El trabajo más significativo desde la perspectiva de optimización exacta se debe a Özsoy y Pınar (2006) y Albareda-Sambola et al. (2010). En el primer trabajo, los autores presentan un método exacto basado en la solución de una serie problemas de cobertura (SCP por sus siglas en inglés: set covering problem), usando un solucionador de programas lineales entero-mixtos (MILP por sus siglas en inglés: mixed-integer linear programming) durante una búsqueda iterativa de las distancias de cobertura. En el segundo trabajo, los autores proponen un método exacto basado en una relajación lagrangiana con una reformulación de cobertura. Evidentemente, dada la complejidad del problema, estos métodos exactos exhiben ciertas limitaciones, particularmente cuando se intentan aplicar a la resolución de instancias del problema de tamaño relativamente mayor.
Hasta donde se conoce, el método heurístico más significativo para el CpCP se debe a Scaparra et al. (2004). En su trabajo, los autores desarrollaron una heurística basada en una búsqueda local a gran escala, con un vecindario de múltiples intercambios representado por un grafo de mejora, explotando los principios de teóricos de la optimización en redes; aquí se abordan instancias con 402 nodos y 40 instalaciones. En los últimos 13 años no ha habido, hasta donde tenemos conocimiento otro método heurístico para el CpCP más exitoso que el de Scaparra et al. (2004).
El objetivo principal de nuestro trabajo es la integración de varios componentes heurísticos avanzados que han tenido éxito en otros problemas de optimización combinatoria dentro de una metaheurística para el CpCP. El término metaheurística se refiere a un método de solución de problemas de optimización que guía y orquesta una interacción entre procedimientos heurísticos constructivos, de búsqueda local y estrategias algorítmicas para crear un proceso sistemático capaz de escapar de óptimos locales y llevar a cabo una búsqueda robusta sobre un espacio de soluciones más amplio. Si bien, una metaheurística utiliza procedimientos y estrategias más sofisticadas que una heurística, esto no garantiza encontrar un óptimo global al problema. Para este fin, se desarrolla un método voraz-adaptativo con una selección probabilística durante la construcción de la solución. Además, el método se ve reforzado por una fase de búsqueda local voraz iterada y una búsqueda descendente por entornos variables.
El valor y contribución del trabajo consiste precisamente en saber explotar adecuadamente la estructura particular del problema para poder desarrollar componentes que impacten significativamente en la calidad de las soluciones obtenidas. Los resultados experimentales del trabajo empírico donde se evalúan ampliamente cada uno de los componentes, así como la metaheurística propuesta en forma global, indican el exitoso impacto de cada uno de los componentes integrados en la metaheurística. Cuando se compara con el trabajo existente, el alcance de la heurística propuesta ofrece en la mayoría de los casos soluciones de mejor calidad que los encontrados por la heurística existente, así como un esfuerzo computacional significativamente menor. Por otra parte, si se compara con todo en el trabajo existente, incluyendo los mejores métodos exactos desarrollados hasta ahora, nuestra heurística resulta ser más robusta en la búsqueda de soluciones factibles para los conjuntos de instancias más difíciles.
Formulación del Problema
Sea
Donde: 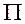 es el conjunto de soluciones factibles del problema, es decir, la colección de todas las p-particiones de V, y la función objetivo (a ser minimizada) está dada por la distancia entre la unidad más alejada del centro y el centro de cada territorio, es decir,
es el conjunto de soluciones factibles del problema, es decir, la colección de todas las p-particiones de V, y la función objetivo (a ser minimizada) está dada por la distancia entre la unidad más alejada del centro y el centro de cada territorio, es decir,
Para un
Descripción de la Heurística
En los últimos años, una importante tendencia en el campo de las metaheurísticas es el de integrar diferentes componentes, dando como resultado métodos híbridos exitosos que tratan de explotar la estructura de un problema específico. Como consecuencia de esto, a veces no está claro cómo nombrar una metaheurística, ya que utiliza los conceptos de diversos métodos. En este sentido, el método de solución propuesto utiliza un procedimiento de búsqueda local voraz iterada (IGLS por sus siglas en inglés: iterated greedy local search) como marco principal. En su fase de construcción, se emplea un método voraz-adaptativo con una selección probabilística. A este mecanismo de construcción se le conoce como GRASP (Feo y Resende, 1995) y ha sido muy utilizado con éxito en problemas de optimización combinatoria similares, tal como la segmentación de distritos comerciales (Ríos-Mercado y Fernández, 2009; Ríos-Mercado y Escalante, 2016). Posteriormente, en la fase de mejora se aplica un método IGLS con una búsqueda descendente por entornos variables (VND por sus siglas en inglés: variable neighborhood descent). IGLS es una técnica originalmente propuesta por Ruiz y Stützle (2007), que resulta de una extensión de una heurística, llamada búsqueda local iterada (ILS por sus siglas en inglés: iterated local search), Lourenço et al. (2002), proporcionan una extensa explicación y revisión bibliográfica de este método. IGLS aplica iterativamente fases de destrucción, reconstrucción y búsqueda local a una solución inicial dada. Con el fin de escapar de un óptimo local y explorar otras regiones en el espacio de soluciones, IGLS aplica un procedimiento de perturbación para generar nuevos puntos de partida para la búsqueda local, cambiando la solución actual. La destrucción/reconstrucción o perturbación consiste en la eliminación de algunos elementos de la solución actual con un criterio específico, seguido por un algoritmo voraz para obtener una nueva solución. Después de que una solución ha pasado a través de una fase de perturbación, se aplica un procedimiento de búsqueda local. El último paso es decidir, con base en un criterio de mejora, si la solución obtenida después de la búsqueda local debe sustituir a la solución incumbente en la siguiente iteración. IGLS sigue iterando hasta que se cumple algún criterio de parada. Una ventaja de IGLS es que permite diversificar y mejorar a lo largo de la búsqueda sin la necesidad de emplear estructuras de memoria complejas. Su simplicidad hace que sea aplicable a varios problemas de optimización combinatoria. Por ejemplo, Ruiz y Stützle (2007, 2008), Fanjul-Peyro y Ruiz (2010) y Urlings et al. (2010) proveen resultados significativos en el estado del arte para diferentes problemas de secuenciación de máquinas. Huerta-Muñoz et al. (2017) aplican exitosmente IGLS a un problema de segmentación de mercados.
El método VND (Hansen y Mladenović, 1999) es un algoritmo de mejora iterativo donde son usados t vecindarios que, por lo general, se ordenan según su tamaño. El algoritmo comienza con un primer vecindario realizando procesos de mejora iterativa hasta que se alcanza el óptimo local. Cuando no se encuentra una mejora para el h-ésimo vecindario entonces VND continúa la búsqueda en el (h+1)-ésimo vecindario. Si se encuentra una mejora, el proceso de búsqueda comienza de nuevo en el primer vecindario. Cuando se termina de examinar el último vecindario, entonces el proceso de búsqueda termina y el procedimiento devuelve la solución final, que es un óptimo local con respecto a todos los t vecindarios. Se ha demostrado que VND puede mejorar considerablemente el rendimiento de los algoritmos de mejora iterativos respecto a la calidad de la solución final y el tiempo requerido en comparación con otros algoritmos iterativos. La idea de hibridar ILS con VND ha sido utilizado con éxito anteriormente en otros problemas de optimización combinatoria (Subramanian et al. 2010; Martins et al. 2011).
El enfoque IGLS/VND propuesto se representa en el Algoritmo 1. Una solución inicial se obtiene en los (pasos 2-3). La búsqueda local (pasos 6-7) se realiza mientras la solución sigue mejorando. Sea B(X) el subconjunto de particiones cuello de botella en X, es decir las particiones que contienen a la máxima de las distancias entre un usuario y un centroide actual, definido por
Este criterio se cumple si X' disminuye el valor de la función objetivo o si X' reduce el número de particiones cuello de botella mientras no se incremente el valor de la función objetivo, sin crear nuevas particiones y nodos con algún cuello de botella. La solución X se actualiza si se encuentra una mejor solución de acuerdo con el criterio (3); en caso contrario, se aplica una perturbación de la solución X' (paso 11). El algoritmo se detiene cuando se alcanza el número máximo de iteraciones (indicado por rmax).
Algoritmo 1. Pseudo-código de IGLS que toma como entrada: un conjunto de nodos  , un número
, un número 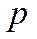 de instalaciones deseadas, un valor
de instalaciones deseadas, un valor 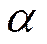 , de destrucción de la solución durante la fase de perturación, y el máximo número de iteraciones
, de destrucción de la solución durante la fase de perturación, y el máximo número de iteraciones  .
.

El método contiene cuatro componentes, descritos brevemente a continuación:
Construcción: Consta de dos etapas: (a) localización de instalaciones y (b) asignación de usuarios. La primera etapa realiza una estrategia basada en método voraz aleatorizado y adaptativo con selección probabilística, que diversifica el conjunto de centros potenciales. En la segunda etapa, un método voraz determinista con un criterio de distancia y capacidad realiza la asignación de los usuarios.
Perturbación: Aplica una destrucción y reconstrucción de la solución. El
objetivo es reducir los elementos cuello de botella. La fase de destrucción
consiste en desconectar el α% definido como parámetro de destrucción () de nodos
localizados en 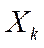 (excluyendo al centro localizado en
(excluyendo al centro localizado en  ) que tengan una probabilidad
mayor de empeorar la solución, definida por un criterio de distancia y
capacidad.
) que tengan una probabilidad
mayor de empeorar la solución, definida por un criterio de distancia y
capacidad.
VND: Emplea dos diferentes estructuras de vecindario denotadas por
 y
y
 , que
realizan movimientos de reinserción (cambio de un nodo
, que
realizan movimientos de reinserción (cambio de un nodo  a la partición
a la partición
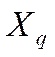 ) e
intercambio (intercambio de los nodos j ϵ x y x ϵ j a la partición
) e
intercambio (intercambio de los nodos j ϵ x y x ϵ j a la partición
 y
y
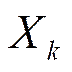 respectivamente). Para cada uno de los vecindarios, el movimiento potencial toma
en cuenta los factores de distancia y capacidad.
respectivamente). Para cada uno de los vecindarios, el movimiento potencial toma
en cuenta los factores de distancia y capacidad.
Agitación: Este método realiza una eliminación y reconstrucción total de varias particiones 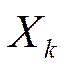 candidatas, lo cual diversifica parcialmente la estructura de la solución actual, guiando el método a otras regiones de la búsqueda más prometedoras durante las siguientes fases de mejora.
candidatas, lo cual diversifica parcialmente la estructura de la solución actual, guiando el método a otras regiones de la búsqueda más prometedoras durante las siguientes fases de mejora.
Un mayor detalle de la composición formal de los métodos se discute en Quevedo-Orozco y Ríos-Mercado (2015).
Resultados Computacionales
La heurística propuesta se evalúa en un conjunto de instancias de prueba obtenidos de la literatura especializada. A continuación, se detalla cada uno de los componentes de la experimentación.
Descripción de las instancias de prueba: Para cada experimento, se utilizaron cinco conjuntos de instancias distintas, los cuales han sido utilizados en trabajos anteriores sobre este problema.
(Grupo A) Beasley OR-Library: Este conjunto de instancias, propuesto en Beasley (1990) para el problema de la p-mediana capacitada (CpMP, por sus siglas en inglés: capacitated p-median problem), contiene dos subgrupos de 10 casos con capacidad igual en cada instalación. El primer subgrupo contiene 50 nodos de demanda y 5 instalaciones, el otro subconjunto tiene 100 nodos de demanda y 10 instalaciones que deben ser ubicadas.
(Grupo B) Galvão y ReVelle: Este conjunto de instancias se ha generado por Scaparra et al. (2004) específicamente para el CpCP basado en el conjunto de instancias de Galvão y ReVelle (1996) para el SCP. Este conjunto contiene instancias con 100 y 150 usuarios, y de 5 a 15 instalaciones, con capacidad de la instalación variable. El conjunto original se compone de dos redes de nodos que se han generado aleatoriamente.
(Grupo C) Lorena y Senne: Este conjunto, propuesto en Lorena y Senne (2004) para el CpMP incluye 6 instancias a gran escala cuyo tamaño varía entre 100 y 402 usuario y de 10 a 40 instalaciones, con igual capacidad en cada instalación.
(Grupo D) Ceselli y Righini: existe un conjunto de instancias agregado recientemente a la OR-Library y propuesto en Ceselli y Righini (2005), el cual se considera difícil de resolver por los problemas de localización capacitados, tales el CpMP y CpCP, ya que la complejidad de su solución se ve significativamente influenciada por la relación entre el número de nodos (n) y el número de instalaciones a ubicar (p). Cuanto menor sea la relación  la instancia tiende a ser más difícil de resolver debido a la complejidad combinatorial del problema (Kariv, O., y Hakimi, S.L., 1979). Se observa un comportamiento similar cuando se utiliza este conjunto para el CpCP. En los conjuntos anteriores A, B, y C, esta relación n/p es 10 o más. El conjunto D está compuesto por 4 subconjuntosα, (, ( y δ, cada subconjunto consta de 40 instancias creadas a partir de la siguiente serie: 20 de ellas tienen un grafo con 50 y 100 nodos; los otros 20 casos fueron generados aleatoriamente con cardinalidad entre 150 y 200. Los mismos 40 casos fueron resueltos con diferente número de centros para cada subconjunto de instancias: ( con
la instancia tiende a ser más difícil de resolver debido a la complejidad combinatorial del problema (Kariv, O., y Hakimi, S.L., 1979). Se observa un comportamiento similar cuando se utiliza este conjunto para el CpCP. En los conjuntos anteriores A, B, y C, esta relación n/p es 10 o más. El conjunto D está compuesto por 4 subconjuntosα, (, ( y δ, cada subconjunto consta de 40 instancias creadas a partir de la siguiente serie: 20 de ellas tienen un grafo con 50 y 100 nodos; los otros 20 casos fueron generados aleatoriamente con cardinalidad entre 150 y 200. Los mismos 40 casos fueron resueltos con diferente número de centros para cada subconjunto de instancias: ( con 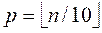 , ( con
, ( con  , γ con
, γ con  y δ con
y δ con  . La capacidad total se mantiene en todos los subconjuntos como
. La capacidad total se mantiene en todos los subconjuntos como  . Nos referimos a estos cuatro conjuntos de instancias diferentes como D-α, D-(, D-γ, y D-δ, cuyo literal expresa la complejidad de cada subconjunto, donde D-α se refiere al subconjunto fácil y D-δ al subconjunto difícil.
. Nos referimos a estos cuatro conjuntos de instancias diferentes como D-α, D-(, D-γ, y D-δ, cuyo literal expresa la complejidad de cada subconjunto, donde D-α se refiere al subconjunto fácil y D-δ al subconjunto difícil.
(Grupo E) Reinelt: Este conjunto fue generado por Lorena y Senne (2004) específicamente para el CpMP basado en las instancias del TSPLIB compilado por Reinelt (1994). El conjunto contiene 5 instancias con 3,038 usuarios y entre 600 a 1,000 instalaciones, con una capacidad de la instalación por instancia, calculada por 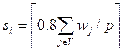 . Este conjunto se considera de gran escala y con proporciones de n/p entre 3 y 5.
. Este conjunto se considera de gran escala y con proporciones de n/p entre 3 y 5.
Condiciones computacionales: La heurística se implementó en C++ y fue compilada con la versión GNU g++ 4.4.5. Para obtener soluciones exactas o cotas inferiores, se utilizaron los métodos exactos de Özsoy y Pinar (2006), denominado como OP, y Albareda-Sambola et al. (2010), denominado como ADF. En estos métodos se utiliza ILOG CPLEX 12.5 como solucionador del subproblema de programación lineal (LP, por sus siglas en inglés). Se estableció el límite de tiempo de 1 hora y un uso máximo de memoria de 1 Gb para los conjuntos de instancias de prueba A, B, C, D-(, D-(, D-( y D-(; para el conjunto E se fijó en 6 horas y un uso de memoria de 4 Gb. Cada uno de los experimentos se llevó a cabo en un equipo con AMD Opteron 2.0 GHz (x16), 32 GiB de RAM en Debian 6.0.8 GNU/Linux Kernel 2.6.32-5 en una arquitectura de 64 bits.
Ajuste de parámetros algorítmicos: El propósito de este experimento es primeramente afinar la heurística con respecto al parámetro ( para cada conjunto de instancias. Esto se consigue mediante un detallado análisis estadístico tal como se describe a continuación. La variable de respuesta estudiada es el promedio del porcentaje de la desviación relativa o DR, definida de la manera siguiente:
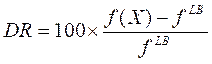 ,
(4)
,
(4)
Donde:  es el valor de la función objetivo, encontrada por el método para cada caso en particular y
es el valor de la función objetivo, encontrada por el método para cada caso en particular y  su mejor cota inferior conocida. Esta cota se obtuvo mediante la aplicación de cualquiera de los métodos exactos OP o ADF. En algunos casos, esta cota inferior resultó ser la solución óptima, pero cuando un método exacto cumple la condición de parada por límite de tiempo o uso de la memoria, se reporta una cota inferior. En otras palabras, DR indica una sobrestimación de la calidad de solución en términos de qué tan lejos está del óptimo global del problema. Por ejemplo, un DR=5% indica que la solución reportada por el método está a un 5% o menos de distancia del valor óptimo global. El límite de iteración heurística se fijó en 100 para los conjuntos de instancias A, B, C, D-(, D-(, D-( y D-(, y 50 para el conjunto E; y se ha ejecutado para todos los valores del parámetro ( entre 0 y 1 en intervalos de 0.1, en todos los conjuntos de instancias, realizando 5 repeticiones en este experimento. Se separaron los resultados en 8 bloques, de acuerdo con el número de conjuntos de instancias con sus respectivos subconjuntos y estudiamos un solo factor ( de cada bloque compuesto por 5 repeticiones, donde DR es la variable de respuesta.
su mejor cota inferior conocida. Esta cota se obtuvo mediante la aplicación de cualquiera de los métodos exactos OP o ADF. En algunos casos, esta cota inferior resultó ser la solución óptima, pero cuando un método exacto cumple la condición de parada por límite de tiempo o uso de la memoria, se reporta una cota inferior. En otras palabras, DR indica una sobrestimación de la calidad de solución en términos de qué tan lejos está del óptimo global del problema. Por ejemplo, un DR=5% indica que la solución reportada por el método está a un 5% o menos de distancia del valor óptimo global. El límite de iteración heurística se fijó en 100 para los conjuntos de instancias A, B, C, D-(, D-(, D-( y D-(, y 50 para el conjunto E; y se ha ejecutado para todos los valores del parámetro ( entre 0 y 1 en intervalos de 0.1, en todos los conjuntos de instancias, realizando 5 repeticiones en este experimento. Se separaron los resultados en 8 bloques, de acuerdo con el número de conjuntos de instancias con sus respectivos subconjuntos y estudiamos un solo factor ( de cada bloque compuesto por 5 repeticiones, donde DR es la variable de respuesta.
Basado en una prueba Tukey con diferencia significativa honesta (HDS, por sus siglas en inglés: honest significant difference) del 95%, que permitirá identificar diferencias significativas entre los diversos bloques de prueba. Se observó que el conjunto {0.7, 0.6, 0.7, 0.6, 0.4, 0.5, 0.4, 0.4} de valores del parámetro ( dio los mejores resultados para los conjuntos de instancias A, B, C, D-(, D-(, D-(, D-( y E, respectivamente. Para los experimentos siguientes, se han utilizado estos valores de ( y ejecutado la heurística con 1,000 iteraciones como límite para los conjuntos de instancias A, B, C, D-(, D-(, D-( y D-(, y 200 iteraciones como límite para el conjunto E, con 30 repeticiones.
Comparación con el estado del arte: El principal propósito de estos experimentos es proporcionar una comparación detallada entre la heurística propuesta (denominada ahora como QR y descrita en el Algoritmo 1) y la de Scaparra et al. (2004) (denominado SPS) que es la mejor existente para este problema. Además, se ha decidido incluir los resultados obtenidos por los métodos exactos OP y ADF. La Tabla 1 resume la comparación entre los métodos para todos los conjuntos de instancias en términos de su promedio de DR, tiempo de ejecución, y el número de casos infactibles para cada método. La sección de "Tiempo promedio (s)" da el tiempo de ejecución en segundos y "Promedio de desviación (%)" expresa el porcentaje de DR con respecto del valor óptimo o la mejor cota inferior conocida para cada método. En el caso de los métodos exactos, la desviación representa la diferencia entre la cota inferior y superior. Para el método propuesto QR, se muestra el rendimiento promedio de tiempo durante las 30 repeticiones independientes, donde "QR2" indica el promedio del mejor DR encontrado para la instancia, sobre todas las repeticiones. La sección de "Número de fallos" representa el total de instancias infactibles por cada uno de los métodos. Se dice que una solución es infactible cuando esta es reportada después de que el criterio de paro es satisfecho, pero no cumple alguna de las restricciones del problema.
Tabla 1: Resumen de la comparación entre los métodos para todos los conjuntos de instancias.
| Conjunto | Promedion de desviación (%) | Tiempo promedio (s) | Número de fallos | |||||||||
| ADF | OP | SPS | QR2 | ADF | OP | SPS | QR | ADF | OP | SPS | QR | |
| A | 0.00 | 0.00 | 5.41 | 0.23 | 27.53 | 33.46 | 5.34 | 0.39 | 0 | 0 | 0 | 0 |
| B | 0.00 | 0.00 | 6.70 | 3.41 | 178.53 | 154.52 | 27.30 | 0.76 | 0 | 0 | 0 | 0 |
| C | 0.00 | 0.00 | 31.79 | 3.58 | 233.63 | 414.76 | 285.43 | 2.39 | 0 | 0 | 0 | 0 |
| D-α | 0.18 | 0.00 | 12.62 | 2.72 | 255.36 | 139.72 | 25.22 | 0.84 | 1 | 0 | 0 | 0 |
| D-ᵝ | 4.74 | 1.62 | 18.03 | 18.17 | 640.68 | 498.19 | 26.47 | 2.73 | 9 | 6 | 5 | 0 |
| D-γ | 4.27 | 0.86 | 16.99 | 29.68 | 941.87 | 496.28 | 27.05 | 4.49 | 12 | 3 | 8 | 0 |
| D-δ | 5.75 | 1.93 | 17.56 | 58.85 | 1320.19 | 453.30 | 44.66 | 5.55 | 14 | 4 | 21 | 2 |
| E | 167.34 | - | 445.91 | 190.50 | 21600.00 | 1167.06 | 1877.61 | 350.42 | 5 | 5 | 0 | 0 |
Analizando esta tabla, se observa que QR es considerablemente más rápido para todos los conjuntos de instancias en todos los métodos. Respecto a la calidad de la solución, el método propuesto proporciona soluciones aceptables para los conjuntos de instancias A, B, C y para los subconjuntos D-α y D-β. En los subgrupos D-γ y D-δ, la comparación entre QR y SPS en términos de calidad de la solución no tiene demasiado sentido, porque SPS falla en la búsqueda de soluciones factibles para un gran número de casos. Como podemos ver SPS falla en la búsqueda de una solución factible en 34 casos, mientras QR falla sólo en 2. En el análisis del conjunto de instancias E, QR claramente supera a todos los métodos, cuyo tiempo de cómputo y recursos crecen considerablemente; en el aspecto de factibilidad, QR es aún mejor, ya que fue capaz de encontrar soluciones factibles para todos los casos de este conjunto de instancias. Cuando se compara con los métodos exactos sobre todos los conjuntos de instancias, QR es aún más confiable en términos de número de soluciones factibles encontradas. Los métodos exactos ADF y OP, fallaron en la búsqueda de soluciones factibles en 41 y 18 instancias, respectivamente, mientras QR falló en sólo 2 instancias.
Análisis de los componentes: En este último experimento, evaluamos el valor que cada componente da a la heurística. Consideramos los tres componentes esenciales del método: Perturbación, VND y Agitación. El experimento consiste en deshabilitar un componente a la vez y ejecutar la heurística utilizando 1,000 iteraciones como límite para los conjuntos de instancias A, B, C, D-(, D-(, D-( y D-(, y 200 como límite de iteraciones para el conjunto E, con 30 repeticiones. Se utiliza el mismo conjunto de valores α del experimento anterior.
La Tabla 2 muestra la comparación de los componentes de cada conjunto de instancias. En esta tabla, la columna "Todos" representa la diferencia promedio cuando todos los componentes están habilitados, que coincide con el valor que se muestra en la columna QR2 de la Tabla 1. Cada columna en la sección "Componentes" representan el componente deshabilitado durante el experimento y muestra el valor promedio de desviación obtenido. La sección "Contribución %" muestra el porcentaje que el componente ofrece con respecto al valor total que se muestra en "Todos". Por ejemplo, en la fila asociada al conjunto A, QR obtiene soluciones que tienen una desviación promedio de 0.23%. Cuando QR se ejecuta con el componente de Perturbación deshabilitado, la desviación media empeora al 17.25%. Esto representa una contribución de 77.25%, como se indica en la Contribución (%), calculada de la manera siguiente:
Tabla 2 Analisis de los componentes desntro de la Heurístice QR
| Conjunto | Todos | Componentes | Contribución (%) | ||||
| Perturbación | VND | Agitación | Perturbación | VND | Agitación | ||
| A | 0.23 | 17.25 | 2.77 | 2.70 | 77.25 | 11.52 | 11.23 |
| B | 3.41 | 12.53 | 4.66 | 5.33 | 74.19 | 10.16 | 15.65 |
| C | 3.58 | 36.63 | 8.32 | 15.59 | 66.38 | 9.51 | 24.12 |
| D-α | 2.72 | 31.87 | 5.61 | 5.39 | 83.98 | 8.32 | 7.70 |
| D-ᵝ | 18.17 | 106.97 | 33.19 | 29.04 | 77.42 | 13.09 | 9.48 |
| D-γ | 29.68 | 195.23 | 46.81 | 45.03 | 83.60 | 8.65 | 7.75 |
| D-δ | 58.85 | 261.94 | 105.76 | 92.62 | 71.57 | 16.53 | 11.90 |
| E | 190.58 | 496.62 | 245.65 | 192.91 | 84.20 | 15.15 | 0.64 |
 (5)
(5)
Donde: c es el número total de los componentes, y D i es la calidad promedio de la solución obtenida cuando el i-ésimo componente es desactivado. Es notable que el componente más influyente dentro de la heurística es la perturbación, seguido de VND y Agitación. Esto es consistente con el análisis estadístico, el cual demostró que el parámetro (, utilizado en la perturbación, influye en la variable de respuesta. Sin embargo, los otros dos componentes agregan valor al rendimiento general. La aportación de VND varía de 8.32% a 16.53%, y la aportación del método de Agitación varía de 0.64% a 24.12%.
Análisis Asintótico: La Figura 1 muestra una comparación de los métodos en términos de su tiempo de ejecución asintótica, y recursos de memoria utilizadas con respecto al tamaño de la instancia. La estadística de la memoria indica el tamaño máximo de bits utilizado (Loosemore et al. 2012), es decir, el número máximo de bits de memoria física que cada método utilizó simultáneamente. Como puede verse, los recursos utilizados por el método propuesto son más bajos que los utilizados por los otros tres métodos. En particular, los requisitos de uso de memoria de los dos métodos exactos, como se esperaba, son considerablemente más grandes.

Conclusiones
En este trabajo de investigación se ha ilustrado la aplicación de un método heurístico que integra varios componentes avanzados de la optimización metaheurística, tales como un método voraz-adaptativo con una selección probabilística y búsqueda local voraz iterada con una búsqueda descendente por entornos variables para uno de los problemas de mayor importancia en el campo de ciencias de localización.
Los resultados revelan contundentemente que la heurística propuesta supera a la mejor heurística conocida en términos de calidad de la solución, el tiempo de ejecución y confiabilidad en la búsqueda de soluciones factibles en los casos más difíciles, convirtiéndose en un avance significativo en el estado del arte en esta rama del conocimiento. El rendimiento del método propuesto es más robusto que el de los métodos exactos existentes, requiriendo menos esfuerzo computacional y memoria para la obtención de soluciones de calidad razonablemente buena para los conjuntos de instancias A, B, y C. Para los casos difíciles en los conjuntos de instancias D-γ y D-δ, las desviaciones respecto a optimalidad de las soluciones heurísticas resultaron ser de calidad aceptable, sin embargo, son obtenidas más rápidamente que el método existente. Para este conjunto difícil, nuestra heurística encontró soluciones factibles para casi todos los casos probados, que es claramente superior a la heurística de SPS, ya que ésta última falló en varias ocasiones. Para el conjunto a gran escala E, ambos métodos exactos fracasaron en la búsqueda de soluciones óptimas en todas las instancias. Nuestra heurística encontró mejores soluciones que la mejor solución reportada por los métodos exactos y además superó claramente a SPS. En un análisis detallado de los componentes, hemos visto que el éxito de la heurística se debe principalmente al método de Perturbación y VND. Sin embargo, para los conjuntos de instancias A, B, y C, el método de Agitación resultó muy útil también.
El método propuesto ofrece soluciones robustas en un corto tiempo para los problemas discutidos previamente en la literatura. Para los conjuntos D y E analizados en este trabajo, el método garantiza un mayor éxito en la búsqueda de soluciones factibles que la de la heurística existente. Esto se logró gracias a una explotación adecuada de la estructura matemática del problema, lo cual permitió una eficaz e inteligente explotación de la misma en el desarrollo de los componentes, superando notablemente a los mejores métodos existentes. Por ejemplo, fue necesario definir los conjuntos cuellos de botella que dependen a su vez de la estructura minmax de la función objetivo.

