











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
El sistema presentado en este trabajo pretende que un agente artificial aprenda dos conceptos espaciales básicos. El primero lo hemos denominado "distancia a" y se refiere a una noción de distancia a los obstáculos que se encuentran en su ambiente. En segundo lugar investigamos el concepto de "pasabilidad" y se refiere a una noción mediante la cual el agente puede discernir por cúal, de entre dos pasajes de diferente tamaño, puede pasar sin colisionar.
Trabajamos bajo el supuesto de que la percepción de distancia no recae en un mecanismo que realiza un cálculo geométrico sino más bien en un proceso de simulación sensoriomotriz (Turvey, 2004, Braund, 2007). Este proceso de simulación es llevado a cabo por un modelo directo, el cual es un modelo interno capaz de crear asociaciones sensoriomotrices de la interacción del agente con el ambiente. El uso de estos modelos permite al agente aprender conceptos espaciales básicos en términos de sus capacidades y características propias a diferencia de métodos tradicionales de robótica y visión artificial en donde este tipo de conocimiento es codificado en los agentes por un diseñador.
La investigación reportada en este artículo se encuentra enmarcada en la robótica cognitiva. Aquí, se busca estudiar e implementar modelos y teorías, provenientes de las ciencias cognitivas, en agentes artificiales, con el doble propósito del diseño sintético. En primer lugar, dotar a agentes con capacidades cognitivas básicas para interactuar con su ambiente, en segundo lugar, al implementar modelos cognitivos, se espera poder tener un impacto en el desarrollo de la teoría detrás de éstos (Pfeifer y Scheier, 1999).
El resto de esta sección está dedicada a dar el contexto de la investigación desarrollada, la sección 2 describe lo que significa para un agente natural la percepción de distancia, así como las formas tradicionales de resolver este problema en visión artificial, cerrando la sección describiendo el enfoque con el que se ha estudiado desde la robótica cognitiva. En la sección 3 se presenta el agente artificial usado para la implementación, así como el sistema propuesto. La sección 4 presenta los experimentos y resultados obtenidos que sirven como prueba de concepto del sistema. Finalmente, en la sección 5 se concluye el artículo.
1.1. Inteligencia Artificial
Hasta principios de los años 90, la inteligencia artificial estuvo influenciada por la propuesta de Newell y Simon en la cual la cognición era reducida a un simple procesamiento de información mediante la manipulación formal de símbolos abstractos (Newell y Simon, 1976). Esta forma de entender la cognición predominó en la mayoría de los laboratorios de inteligencia artificial, donde era práctica estándar hacer la analogía directa entre la forma en que se entendía el procesamiento de información en el cerebro y en las computadoras. Por esta razón la cognición fue estudiada a través del uso de algoritmos computacionales donde ésta era considerada lineal y unidireccional, llevando la información de entrada a una caja negra de procesamiento para terminar en una salida que era ejecutada en el medio ambiente. Esta concepción representacionalista y simbólica de la cognición nunca estuvo libre de críticas desde diferentes áreas del conocimiento incluyendo a la filosofía y la psicología.
Un parteaguas importante en la historia de la inteligencia artificial fue el ejercicio mental del "cuarto chino" propuesto por el filósofo John Searle (Searle, 1980). Con este experimento Searle expone a los sistemas de cómputo manipulando símbolos abstractos como carentes de significado, capaces de manejar sintaxis pero no semántica.
Más tarde Stevan Harnad formula el problema de la cimentación de símbolos (Harnad, 1990) y propone una solución a éste. Para Harnad, la cimentación de símbolos es el problema de cómo las palabras adquieren su significado y propone una arquitectura híbrida basada en redes neuronales para tratar de solucionarlo. Al mismo tiempo, Harnad propone que los agentes mismos deberían ser los encargados de extraer las características relevantes del ambiente, para así lograr que los conceptos mentales obtengan significado.
Estos dos trabajos son muy influyentes en la inteligencia artificial al señalar temas que no estaban considerados en esta comunidad. Estas y otras críticas, propiciaron la búsqueda de un nuevo enfoque para el estudio de los procesos cognitivos que subyacen al fenómeno de la inteligencia natural en miras de su implementación en agentes artificiales.
1.2. Robótica Cognitiva
Al mismo tiempo, en la robótica, la visión puramente representacionalista de la inteligencia fue criticada entre otros por Rodney Brooks, quien propuso la implementación en agentes autónomos de una arquitectura basada en actividades formadas por módulos (Brooks, 1991). Cada uno de estos módulos interactúa con el ambiente tanto para su entrada como para su salida y al mismo tiempo tiene un funcionamiento completo, esto es, cada módulo codifica un comportamiento específico. Además cada módulo que se añade a la arquitectura, se conecta con los módulos existentes. El principio teórico de la arquitectura es que comportamientos cada vez más complejos se sobreponen, interactuan y hacen uso de los comportamientos existentes. La principal aportación de esta idea es que se deja de lado el uso de un procesador central que forma las representaciones necesarias para que el agente pueda interactuar con su entorno. Brooks criticó fuertemente la concepción representacionalista de la inteligencia, proponiendo la interacción con el ambiente como el primer factor a considerar para el desarrollo de agentes inteligentes. Además de esto, es a Brooks a quien se le acredita la propuesta de que la mejor representación del mundo es el mundo mismo (Brooks, 1991).
Por otro lado, la obtención de comportamientos o habilidades más complejas en los agentes artificiales no es una tarea sencilla. Habilidades cognitivas como la atención, el pensamiento abstracto, la memoria y la categorización, entre otras, han sido todo un desafío para la inteligencia artificial debido a su compleja naturaleza.
Por ejemplo, la categorización es una habilidad que desarrollamos a pesar de la gran variabilidad en la representación sensorial que origina un objeto. Sin embargo, este proceso es observado durante el desarrollo de comportamientos exploratorios en bebés (Rochat, 1989), en el cual la percepción y la acción están involucradas en la recolección de información de una forma activa y simultánea a través de las diferentes modalidades sensoriales, con el propósito de reconocer y categorizar a los objetos en función de los usos potenciales que éstos pueden llegar a ofrecer para el agente que interactúa con ellos (Gibson, 1950).
En la robótica, los trabajos de Scheier y Lambrinos (1996) y Pfeifer and Scheier (1997) muestran precisamente cómo esta habilidad de categorizar y reconocer objetos puede ser lograda en un agente artificial a través de un proceso de coordinación sensoriomotriz. La contribución principal de estos trabajos consistió en mostrar cómo se reduce de manera significativa la complejidad del proceso de categorización al considerarla desde esta perspectiva, en lugar de intentar predefinir las categorías o de incluir un sensor específico para cada tipo de objeto.
Dentro de las ciencias cognitivas se ha acuñado el término cognición cimentada (Barsalou, 2008) para agrupar las diferentes posturas que sostienen que los procesos cognitivos están íntimamente vinculados a la interacción del agente con el entorno, resaltando el papel que desempeña el cuerpo, el ambiente y la acción en la cognición (Wilson, 2002).
Es todo esto lo que ha llevado a la investigación en inteligencia artificial al uso de agentes artificiales autónomos como plataformas de prueba y experimentación, dando origen a una nueva forma de estudio acerca de la cognición. Así mismo, se ha entendido que los comportamientos necesarios para que los agentes autónomos sean capaces de interactuar con su entorno son demasiado complejos para poder ser codificados de manera directa, diseñados por un programador. Actualmente, se busca que los agentes artificiales obtengan comportamientos inteligentes a través de la interacción con su medio ambiente, imitando el desarrollo que los agentes naturales siguen durante su crecimiento. Por tal motivo, la robótica cognitiva ha tratado de traer a su área de investigación modelos provenientes de las ciencias cognitivas. Estos modelos, se espera ayuden a tener agentes artificiales capaces de interactuar con su entorno y adaptarse a las situaciones dinámicas de éste. A su vez estos agentes deberán servir como plataformas de experimentación y evaluación de las diversas hipótesis acerca de la cognición que se originan en las ciencias cognitivas.
Diversos trabajos han mostrado de forma explícita el vínculo y la forma de trabajo entre la robótica y las ciencias cognitivas. Pfeifer describió varios ejemplos del uso de agentes artificiales como plataformas de investigación en torno a la inteligencia en Pfeifer (2002). La recopilación reportada en Lungarella et al. (2003) muestra con numerosos casos de estudio cómo se relacionan y complementan estas disciplinas en la investigación en torno al desarrollo de procesos cognitivos. Finalmente, en Pezzulo et al. (2012) se ha propuesto un marco teórico que busca unificar el lenguaje en torno al estudio de la cognición mediante el uso de la modelación computacional y la implementación de estas propuestas en agentes artificiales.
2. Relaciones Espaciales
Los humanos hacemos uso de diversas pistas visuales a través de las cuales nos es posible obtener la distancia a la cual están ubicados los objetos en nuestro entorno. Estas pistas son obtenidas a partir de la información que llega a cada una de nuestras retinas y pueden ser clasificadas en pistas monoculares, binoculares y oculomotrices (ver Goldstein, 2010, cap. 10).
Las pistas monoculares son aquellas que nos permiten inferir la distancia a los objetos observados a partir de una sola imagen gracias a la información que ésta contiene. Entre éstas se encuentran: el tamaño relativo, la brillantez, la superposición, la perspectiva, la altura en el plano y las sombras.
Entre las pistas oculomotrices se distinguen la acomodación del cristalino y los movimientos de vergencia de ambos ojos. Sin embargo, la pista que brinda la información más importante para determinar la distancia a los objetos proviene de percibir una escena con ambos ojos desde una perspectiva ligeramente distinta. Esto se conoce como disparidad binocular y es la responsable de originar el fenómeno denominado estereopsis (Julesz, 1971), es decir, la impresión de profundidad que se crea en el cerebro cuando se percibe una escena. A diferencia de las pistas monoculares, la estereopsis es un proceso que no depende de las pistas contenidas en la información pictórica, sino que por el contrario depende de la disparidad de las representaciones en la retina de los objetos observados.
Recientes trabajos en las ciencias cognitivas apuntan a que la percepción de distancia en los seres humanos no se genera a través de un proceso geométrico. En su lugar encontramos:
1.Asociación de información multi-modal. La percepción de distancia es el resultado de la asociación de información proveniente de diferentes modalidades incluidas la modalidad motriz, la visual y la táctil (Braund, 2007).
2.Hacemos uso de unidades relativas que están escaladas (cimentadas) a nuestras propias dimensiones corporales y no un sistema dimensional absoluto (Proffitt, 2006).
3.Los usos potenciales que adquieren los objetos para el observador son obtenidos mediante la interacción agente-ambiente; son estos usos los que definen el concepto de espacio y no simplemente entidades como puntos, líneas o planos pertenecientes a una geometría abstracta (Gibson, 1950).
4.La preparación de la acción (Wexler y Boxtel, 2005) y las propiedades del entorno (Lappin et al., 2006) son aspectos suficientes para modificar de forma directa la percepción del espacio que se forma el observador.
2.1 Soluciones Clásicas
En las áreas de robótica y visión artificial, tradicionalmente la estimación de la distancia ha sido estudiada dentro del marco de la geometría. Como analogía a la visión binocular se ha trabajado con un par de cámaras estéreo (dos cámaras sobre el mismo plano), separadas entre sí por una distancia conocida y cuyos ejes ópticos son paralelos. Con esta configuración es posible calcular la ubicación exacta de cada uno de los objetos de la escena que se está observando (Marr7 y Poggio, 1979; Faugeras, 1993; Moons, 1998). En general, estos métodos buscan encontrar la correspondencia de características relevantes que aparecen en ambas imágenes, tales como bordes o segmentos de líneas, correlación entre regiones de píxeles, transformaciones de Fourier y métodos de minimización de energía (Alvarez et al., 2002). El resultado de esta correspondencia es el llamado mapa de disparidad representado por una imagen en niveles de gris cuya intensidad está en función de la distancia a los objetos. Aunque estos métodos son muy precisos, dependen de un delicado proceso de calibración de las cámaras en las que la intervención del usuario es indispensable. Así mismo, la medida de distancia representada en el mapa de disparidad depende de los parámetros de cada una de las cámaras y de las condiciones lumínicas del entorno.
En el contexto de la robótica cognitiva un detalle significativo es que el cálculo de la distancia a partir de este enfoque geométrico, es una cantidad dimensional que necesita ser interpretada por un agente externo.
2.2 Enfoque desde la Robótica Cognitiva
Dentro de la robótica cognitiva, diversos trabajos han enfrentado el problema de adquirir una noción de distancia y capacidades espaciales cimentadas en las capacidades del robot. A través de métodos de evolución artificial, Nolfi y Marocco (2001) obtuvieron agentes artificiales capaces de discriminar visualmente entre objetos de diferente tamaño y ubicados a diferentes distancias exhibiendo una estrategia de coordinación sensoriomotriz.
Una herramienta conceptual que encapsula las ideas y principios de la cognición cimentada y la cognición corporizada son los Modelos Directos. Estos fusionan naturalmente diferentes modalidades sensoriales y motrices. Originalmente propuestos en la teoría de control clásico (Jordan y Rumelhart, 1992), los modelos directos han sido adoptados en las ciencias cognitivas para explicar el funcionamiento de diferentes comportamientos cognitivos de bajo nivel en agentes naturales (Blakemore et al., 1998). Un modelo directo (forward model) es un predictor, que recibe como entrada una situación sensorial a un tiempo t (St ), y un comando motriz a un tiempo t (Mt ) y proporciona como salida la situación sensorial resultante al tiempo t + 1 ( S* t+1 ). El comando motriz es una copia eferente, esto tiene como consecuencia y ventaja que puede o no ser ejecutado en el mundo real. Es así que una secuencia de comandos motrices no ejecutados provee a los agentes con una simulación interna de una cadena de eventos. Los modelos directos permiten a un agente hacer predicciones acerca de sus acciones para poder elaborar estrategias de control y al mismo tiempo evitar situaciones no deseadas. Las predicciones realizadas proporcionan a los agentes una noción de las relaciones espaciales de los objetos existentes en su entorno.
Implementaciones de estos modelos para adquirir nociones espaciales se han usado para navegación segura en un agente autónomo como en el trabajo de Hoffmann y Möller (2004), donde se utiliza la predicción de situaciones sensoriales con el fin de dotar a un agente artificial con la capacidad de conocer su posición respecto al centro, en un entorno de obstáculos dispuestos alrededor de éste en forma circular.
Posteriormente Hoffmann implementó un modelo directo que provee a un robot con las consecuencias sensoriales visuales de llevar a cabo una acción. En base a la predicción de imágenes omnidireccionales (imágenes con un campo visual de 360 grados) de la escena, el autor establece una métrica para la estimación de distancia (Hoffmann, 2007). Las predicciones sensoriales del modelo son usadas para construir una ruta de navegación con el fin de atravesar un camino de obstáculos o en dado caso, determinar si éstos están dispuestos en una configuración de un camino cerrado. En otro trabajo, Möller and Schenck (2008) hacen uso de modelos directos en un agente artificial para predecir las coordenadas de obstáculos en un ambiente virtual. Usando estos modelos el agente es capaz de predecir las nuevas coordenadas del centro de los obstáculos tras la ejecución de diferentes comandos motrices (izquierda, frente y derecha). Cabe resaltar que en estos trabajos, los autores utilizan píxeles como unidad de medición no relacionada a las capacidades sensoriomotrices del agente.
En un trabajo relacionado, Escobar et al., (2012) llevaron a cabo la implementación de un modelo directo que realiza predicciones visuales y táctiles de las acciones de un agente. Los autores hacen uso de los métodos tradicionales de visión artificial para calcular el mapa de disparidad a partir de dos imágenes del mismo instante, tomadas por una cámara estereoscópica.
Finalmente, Gaona et al., (2012) presentaron un modelo directo que lleva a cabo predicciones visuales y táctiles de acciones, los autores reportan un sistema capaz de llevar a cabo hasta tres simulaciones internas o predicciones de largo plazo así como predicciones táctiles.
Es importante resaltar, en referencia a Escobar et al., (2012) y Gaona et al., (2012) que estos son antecesores de lo que se presenta en este trabajo. A pesar de que los experimentos parecieran similares, conceptualmente, el trabajo actual intenta retirar al diseñador un paso más.
2.3 Solución propuesta
En este trabajo, proponemos que la obtención de una noción de distancia debería estar basada en las capacidades sensoriomotrices propias del agente. De forma específica, hacemos uso de un modelo directo para simular una secuencia de acciones y sus consecuencias sensoriales, esta simulación puede ser usada por el agente para estimar la distancia a obstáculos en su ambiente. Nuestra propuesta presenta las siguientes características clave tomando en cuenta las ideas descritas en la Sec. 2:
Llevar a cabo simulaciones internas.
No hacer uso de los modelos tradicionales de visión artificial (por ejemplo un cálculo geométrico de la disparidad).
Utilizar unidades de medida basadas en las capacidades sensoriomotrices del agente.
3. Diseño del Sistema
El trabajo reportado aquí se implementó en un robot móvil Pioneer 3D-X (Figura 1). Este robot tiene dos ruedas laterales y una rueda que gira libremente ubicada en la parte posterior para darle estabilidad mientras se desplaza. El agente cuenta con un arreglo de sonares dispuestos en forma de anillo capaces de reportar la distancia a los objetos en un rango de 0 a 5000 mm. El sistema de visión está compuesto por una cámara estéreo que proveen imágenes a color de 320 × 240 píxeles (en la Figura 2 se observa un ejemplo de estas imágenes).

Figura 1 Agente artificial: Robot Pioneer 3-DX con un arreglo de sonares y una cámara estéreo en el frente

La representación esquemática del modelo directo propuesto se observa en la Figura 3. Este recibe como entrada una situación sensorial al instante t (St ) compuesta por las imágenes izquierda (Ii,) y derecha (Id ) provenientes del par estéreo. Así mismo recibe un comando motriz a ejecutar Mt , éste puede ser un movimiento hacia adelante o giros hacia la izquierda o derecha. El modelo directo proporciona una predicción de lo que sucedería si el comando motriz fuese ejecutado. En la salida al instante t + 1, la situación sensorial predicha ( S* t+1 ) está compuesta por dos modalidades. La modalidad visual está dada por las imágenes izquierda y derecha (Ii, Id )* t+1, mientras que la modalidad táctil T * t+1 está dada por un estado binario de los parachoques del robot, indicando si hay o no colisión con un obstáculo. Aunque el robot cuenta con sensores de choque, por razones prácticas estos valores se obtuvieron de umbralizar los valores de los sonares.

Figura 3 Esquema del modelo directo propuesto. La entrada está compuesta por las imágenes izquierda y derecha (Ii, Id ) y el comando motriz (M) al tiempo t. La salida está compuesta por la predicción de las imágenes izquierda y derecha (Ii, Id )* y el estado táctil (T)* al tiempo t + 1.
Un modelo directo provee al agente con la posibilidad de construir predicciones de largo plazo (PLP). Una PLP es un proceso de simulación interna que permite conocer de forma anticipada las consecuencias sensoriales de ejecutar una serie de comandos motrices. Esto consiste en utilizar la predicción del estado visual (Ii, Id )* junto con un nuevo comando motriz M al instante t + 1 como entradas al modelo obteniendo las predicciones para el instante t + 2. Idealmente, este proceso se puede repetir hasta que se considere necesario.
En nuestro caso, la combinación de 3 diferentes comandos motrices permite la construcción de diferentes PLPs. Estas combinaciones pueden ser representadas en una gráfica de árbol, donde el nodo inicial es el estado visual actual del robot y cada rama es derivada a partir del comando motriz a ejecutarse (ver Figura 4).

3.1 Preparación de los Datos de Entrada
La asociación de las imágenes y el comando motriz implica un problema de alta dimensión
alidad debido a que cada una de las imágenes provenientes del par estéreo tiene un tamaño de 320×240 píxeles, resultando en un total de 153,600 datos. Para reducir el tamaño de este espacio de entrada se utilizaron dos estrategias: la elección de una región de interés (RDI) y la implementación de un algoritmo de "fovealización" (ver Figura 5).

La elección de la RDI tiene como objeto seleccionar la porción de la imagen de entrada (Ver Figura 5a) con mayor relevancia para las dimensiones y capacidades motrices del agente en su interactuar con el entorno. Por ejemplo, el robot tiene una altura de 30 cm por lo que objetos más altos de esto no afectan su navegación segura. La RDI elegida se muestra en la Figura 5b; tomando como referencia el origen en la parte superior de la imagen, la RDI comienza en la coordenada vertical del píxel 95 y termina en el píxel 239. A la RDI se le realizó un proceso de segmentación para resaltar la información relevante para el agente, esto es, obstáculos en su camino en una tarea de navegación.
En primer lugar, se obtuvo una imagen de la RDI en valores de intensidad al seleccionar, en base a su histograma, el canal de color que representa con mayor contraste a los obstáculos sobre el fondo del entorno. A diferencia del canal utilizado generalmente (rojo) se optó por el canal correspondiente a la tonalidad del color verde, únicamente por las características de las imágenes proporcionadas por la cámara. En segundo lugar, se le realizó un recorte con umbral utilizando el método de Otsu (1975) El resultado es una imagen en la que los obstáculos de la escena aparecen en niveles de gris mientras que el fondo aparece de color negro, ver Figura 5c.
La segunda estrategia consistió en implementar un algoritmo de fovealización estableciendo una analogía con el ojo humano, éste presenta una mayor densidad de células fotorreceptoras en la región conocida como fóvea. El resultado de esta operación es que las partes centrales de la imagen son representadas con un mayor número de píxeles mientras que las periféricas aparentan estar desvanecidas. Este proceso es análogo a tener un sensor de cámara con diferentes resoluciones para diferentes áreas de la escena, mayor en el centro y menor en la periferia.
Para tal efecto se eligió el método de mapeo exponencial dimensionalmente independiente 1 (Peters y Sowmya, 1998) consistente en un muestreo exponencial en las direcciones vertical y horizontal. El muestreo producido es tal que se realiza una selección de puntos más densa hacia el centro de la imagen que en su periferia. El resultado de aplicar esta fovealización a la RDI se puede apreciar en la Figura 5d cuyas dimensiones son ahora de 32 × 10 píxeles, logrando así una reducción de la información visual de 153,600 a 320 píxeles.
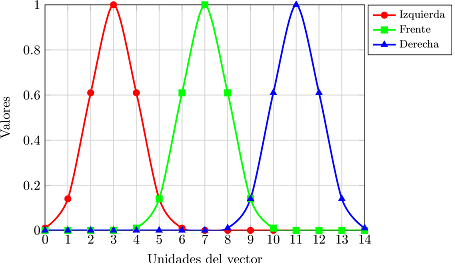
El espacio motriz del agente consiste en un conjunto de 3 acciones, girar 5º a la derecha, moverse hacia adelante 15 cm o girar 5º a la izquierda. Cada uno de estos comandos motrices se transformó a un vector de 15 valores mediante el uso de 3 funciones gaussianas con igual desviación estándar σ=1 pero con distinta media μ, μ = 3 para el giro hacia la izquierda, μ = 7 para el movimiento hacia adelante y finalmente μ = 11 para el giro hacia la derecha. Las curvas de la codificación de los comandos motrices se pueden observar en la. Figura 6. La codificación de los comandos motrices por un vector de 15 valores está basada en buscar un equilibrio en los efectos que las tres modalidades (visual, táctil y motriz) deberán tener en el aprendizaje para cada una de las redes (ver sección 3.2).
3.2 Sistema de Redes Neuronales Artificiales
El modelo directo (ver Figura 3) fue codificado a través de un sistema de redes neuronales artificiales (RNA) tipo perceptrón multicapa para realizar una predicción simétrica local. Esto significa que cada red recibe de cada imagen de entrada una región de 12 × 2 píxeles y un vector de 15 datos que codifica al comando motriz y produce regiones de 2 × 2 píxeles para cada una de las imágenes de salida y para el estado táctil, a excepción de las regiones predichas para la primera y última columna, las cuales son de 2 × 1 píxeles. El objetivo de este ajuste es lograr que las regiones de salida correspondan a la parte central de las regiones de entrada. En la Figura 7 se observa en color azul la conexión típica de una de las redes que predicen una región de 2 × 2 píxeles y en color rojo la conexión de una de las redes para una región de 2 × 1 píxeles.
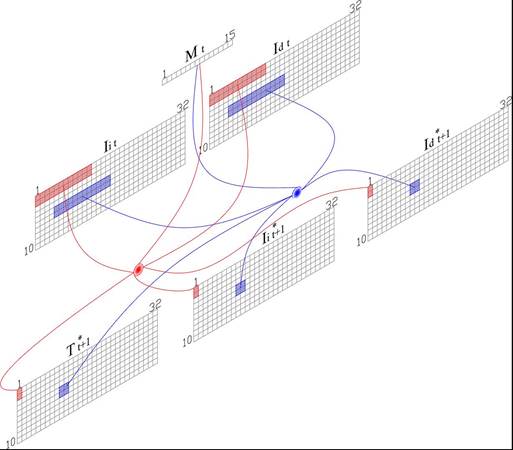
Figura 7 Distribución esquemática de la conexión de 2 redes neuronales artificiales que codifican el modelo directo. En azul se muestra la conexión típica de las redes del sistema y en rojo se aprecia la conexión para las redes de la primera y última columna.
Dado que el tamaño de las regiones de entrada es mayor que el de las regiones de salida, existe un traslape, en la dirección horizontal, en todas las regiones de entrada a excepción de los bordes izquierdo y derecho en donde 4 redes reciben la misma información de entrada. Como resultado, se obtuvo un sistema compuesto por 85 redes neuronales artificiales distribuidas en una malla de 17 redes en el sentido horizontal y 5 redes en el sentido vertical.
El protocolo de recolección de patrones para el entrenamiento consistió en la preparación de una arena con el robot ubicado en el centro y obstáculos cilíndricos de diámetros 6.5, 11.5 y 16.5 cm, dispuestos alrededor de éste. Se recolectaron 5727 patrones durante la ejecución de 150 trayectorias de movimientos en el entorno. Cada trayectoria se llevó a cabo seleccionando un comando motriz (adelante, izquierda, derecha) de forma aleatoria en cada paso. La trayectoria terminaba si se reportaba una señal de colisión por alguno de los 4 sonares frontales o si se alcanzaba la ejecución de 50 pasos sin presentarse una colisión. La señal de colisión se representó mediante una variable binaria que tomaba el valor de 1 cuando se detectaba un obstáculo a menos de 500 mm (medida que equivale al tamaño del robot) o de 0 en caso contrario. En cada paso de las trayectorias se almacenó el par de imágenes proveniente de la cámara estéreo antes y después de ser ejecutado el comando motriz, el propio comando motriz y el estado de colisión. El entrenamiento de las redes fue realizado por medio de una variación del algoritmo estándar de retro-propagación del error conocido como retro-propagación fuerte (resilient back-propagation) (Riedmiller y Braun, 1993), el cual es comparativamente más rápido y eficiente.
4. Experimentos
Con el objeto de explotar la habilidad del agente de llevar a cabo predicciones sensoriomotrices utilizando el modelo directo, se estudió el desarrollo de dos conceptos espaciales básicos: distancia a y la pasabilidad.
4.1 Adquisición del concepto distancia a
La capacidad del agente para estimar distancia como un concepto cimentado está íntimamente relacionada a su habilidad para realizar PLPs y la calidad de éstas. Esto es, en una escena, el agente lleva a cabo una PLP la cual incluye la predicción de los estados visuales y táctiles futuros. La evaluación de estas predicciones sensoriomotrices puede considerarse como el concepto "en X pasos colisiono". Aquí X pasos es una distancia en el sentido de que cada paso está relacionado a un comando motriz de desplazamiento en términos de las capacidades del agente.
4.1.1Análisis de una PLP
En la Figura 8, se muestra un escenario en donde el agente se sitúa frente a un obstáculo. El agente colisionaría con el obstáculo si se desplazara 5 comandos motrices hacia adelante o lo que es lo mismo una distancia de 75 cm.

Figura 8 Entorno de prueba para la estimación de distancia a. Se indican las distancias mínima (15 cm) y máxima (225 cm) durante el experimento, las cuales equivalen respectivamente, a la ejecución de 1 y 15 movimientos hacia adelante por parte del agente.
Las imágenes capturadas por el par estéreo y sus correspondientes fovealizaciones para la situación mostrada en la Figura 8 se pueden observar en la Figura 9. Se aprecia como el obstáculo está desplazado con respecto al centro en la imagen derecha y en menor grado en la imagen izquierda. Las imágenes fovealizadas repiten esta característica siendo el desplazamiento de mayor magnitud en la imagen izquierda donde la representación del obstáculo se magnificó por el efecto del proceso mismo de fovealización.

Figura 9: Imágenes originales y fovealizadas de la situación inicial con el obstáculo ubicado a 75 cm.
Las predicciones visuales resultantes se observan en la Figura 10. Durante la primera predicción correspondiente al instante t + 1 y hasta la predicción en t + 5 se puede observar como el obstáculo va ocupando cada vez una mayor área en el extremo derecho para la imagen izquierda y de forma inversa para la imagen derecha. Implicando así, que conforme avanzan los instantes de la PLP, la representación del obstáculo en las predicciones se va desplazando hacia el centro del agente. A partir del instante t + 5, se puede ver que la representación del obstáculo alcanzó los extremos en ambas imágenes. A partir de t + 7, surge de manera significativa ruido y falsas regiones en cada una de las predicciones.

Figura 10: Imágenes izquierda y derecha, resultantes de una predicción de largo plazo (PLP). La predicción es de 15 movimientos hacia adelante con un obstáculo situado a 75 cm.
De forma correspondiente con las predicciones visuales mostradas en la Figura 10, las predicciones del estado táctil para la misma situación se muestran en la Figura 11. Cada una de estas gráficas fueron codificadas usando un mapa de calor, donde la mínima activación corresponde al valor de 0 y está indicado por las zonas de color azul, mientras que el máximo valor corresponde a 1 indicado por las zonas de color rojo.
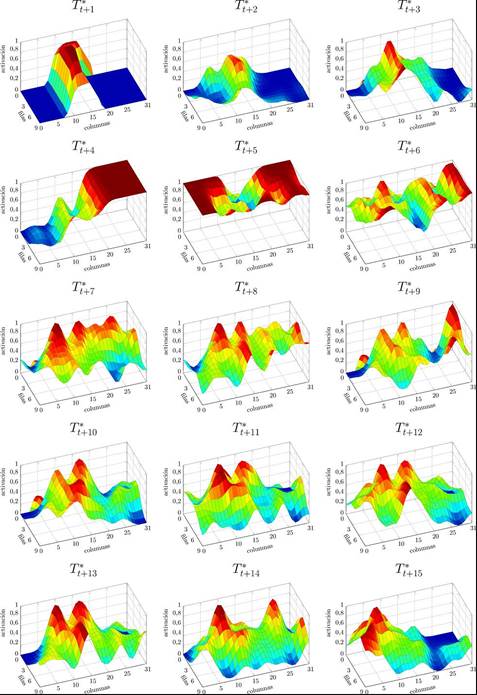
Figura 11: Representación tridimensional para las predicciones del estado táctil (T ∗) en cada uno de los instantes de la PLP de 15 movimientos hacia adelante con el obstáculo ubicado a 75 cm.
El primer aspecto a resaltar es el hecho de tener valores continuos en un rango de [0-1], contrario a los valores binarios codificados durante el entrenamiento, donde 1 representó una colisión y 0 cualquier otro caso (Ver sección 3). La activación es mayor en las regiones que corresponden a la posición de los obstáculos, lo cual codifica un mapeo directo en los estados táctiles, basado en la entrada visual. Este fenómeno emergente fue reportado y controlado anteriormente en Gaona et al., 2014.
Al analizar estas gráficas se observa que desde el instante t + 1 hasta el t + 3 existe una activación en la región central llegando a un máximo en el instante t + 5 donde la gran mayoría de las activaciones se muestran en color rojo. A partir del instante t + 6 la forma de las gráficas en estos mapas de calor ya no describe una estructura definida y se mantienen fluctuando hasta el final de la PLP. Cabe recordar que la Figura 10 y Figura 11 muestran resultados de PLP cuando el obstáculo está localizado a t + 5. Este hecho se puede observar en la predicción táctil del sistema, donde a partir de una activación promedio máxima (0.83), esta fluctúa sin necesariamente mostrar una correlación con las predicciones visuales. Esto es, a partir de la predicción producida al instante t+6 tanto la información visual como la táctil reportan solamente ruido.
4.1.2 PLP para diferentes distancias
Para evaluar el modelo y su capacidad de predicción se llevaron a cabo predicciones a largo plazo para obstáculos situados a diferentes distancias del agente. El primer obstáculo se colocó a 15 cm y se llevó a cabo una predicción de 15 movimientos hacia adelante. En seguida el obstáculo se colocó a 30 cm del agente llevándose a cabo la misma PLP. Este procedimiento se repitió incrementalmente cada 15 cm hasta que el obstáculo se encontró a 225 cm del agente.
Para cada movimiento simulado y para cada PLP se registraron las predicciones visuales y táctiles. En la Figura 8 se muestra la escena cuando el obstáculo se encuentra a 5 comandos motrices de distancia y las distancias mínimas y máximas a las cuales se ubicó el obstáculo para este análisis.
Con el propósito de caracterizar el desempeño del sistema, se calculó el promedio de la activación del estado táctil en cada instante de las PLPs. En la Figura 12 se muestra este valor promedio para 9 de las 15 diferentes distancias del obstáculo.
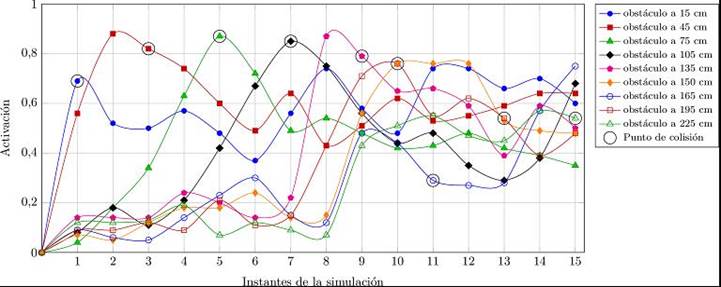
En primer lugar, se puede ver que en cada una de las curvas, la activación se incrementa a medida que el instante simulado se acerca al punto de colisión con el obstáculo, alcanza un máximo y disminuye ligeramente en el instante correspondiente a la colisión para posteriormente decrecer rápidamente y mantenerse oscilando alrededor de cierto valor.
En segundo lugar, se puede apreciar que para las posiciones en las que el obstáculo se encuentra a menos de 10 movimientos para colisionar, el punto en el que ocurriría la colisión (indicado en la figura como un círculo rodeando un punto en cada serie de datos) se correlaciona con los valores de mayor activación de las predicciones táctiles. A partir de la posición del obstáculo que corresponde a una distancia de 11 movimientos, la activación promedio no aumenta de manera significativa ni antes ni después del punto de colisión. De aquí que el máximo número de instantes simulados para obtener una PLP que pueda anticipar una posible colisión de manera confiable, es de 10.
Finalmente, el valor de la máxima activación, en cada una de las PLPs donde el obstáculo se ubicó a menos de 150 cm del agente, se encuentra alrededor de 0.8. Estableciendo de esta manera, un valor umbral para indicar un estado de colisión en el instante donde éste se presenta o en el inmediatamente posterior. El hecho de que este valor sea el mismo para cada una de estas pruebas, da cuenta de la capacidad del sistema para estimar la distancia a un obstáculo en función del número de movimientos antes de que presente una colisión.
4.2 Adquisición del concepto pasabilidad
El objetivo de este experimento es mostrar cómo, desde la robótica cognitiva, es posible proveer a un agente artificial con la capacidad para juzgar la "pasabilidad" de una apertura. Este concepto de "pasabilidad" es similar al de "distancia a" descrito en el experimento anterior.
En humanos se ha encontrado que disponemos de una medida escalada a nuestras dimensiones corporales para juzgar el ancho de una apertura. Específicamente se encontró una relación que da cuenta de la habilidad para juzgar la "pasabilidad" en términos de las dimensiones corporales de cada persona en base al ancho de los hombros y al ancho de la apertura que se pretende atravesar (Warren y Whang, 1987).
Haciendo uso de las asociaciones multi-modales aprendidas, el agente es capaz de generar estructuras de tipo árbol basadas en la representación del modelo directo a manera de nodo (ver Figura 4). El análisis de las predicciones táctiles es suficiente para dotar al agente con el concepto de " pasabilidad"
El experimento consiste en situar al agente frente a dos aperturas o entradas, donde una de ellas es más pequeña que el tamaño de su cuerpo y la otra de mayor tamaño (Ver Figura 13). Generando un árbol basado en las PLPs, éste podría determinar cuál de ellas es por la que puede pasar sin colisionar y cual no; esto sin la necesidad de ejecutar de forma explícita una secuencia de acciones.

Figura 13: Ambiente para el estudio del concepto de pasabilidad. El agente se encuentra situado frente a una escena visual que muestra dos aperturas, según la imagen por la de la izquierda el agente no puede pasar mientras que por la de la derecha sí.
En este contexto, este experimento se dividió en dos etapas. Una etapa inicial de carácter exploratorio y otra de corrección de la trayectoria. El propósito de la primera etapa es reconocer la ubicación de la apertura por la que el agente podría pasar y comenzar a dirigirse hacia ella. Durante la segunda etapa se corrige el curso de la trayectoria para que el agente logre pasar a través de la apertura sin colisionar con los bordes de la misma.
Para la primera etapa se construye un árbol de predicciones de profundidad 10 y de 11 ramas (ver Figura 14a), esto se logra al realizar 11 diferentes PLPs con 10 instantes de simulación cada una, esto es, para cada PLP se simulan 10 comandos motrices. La dirección de las flechas indica el tipo de comando motriz elegido en cada paso de la simulación. Por ejemplo, la rama 1 indica la simulación de 5 giros hacia la derecha y en seguida 5 movimientos hacia adelante (d-d-d-d-d-a-a-a-a-a), la rama 6 indica 10 movimientos hacia adelante (a-a-a-a-a-a-a-a-a-a) y la rama 11, 5 giros hacia la izquierda y 5 movimientos hacia adelante (i-i-i-i-i-a-a-a-a-a).
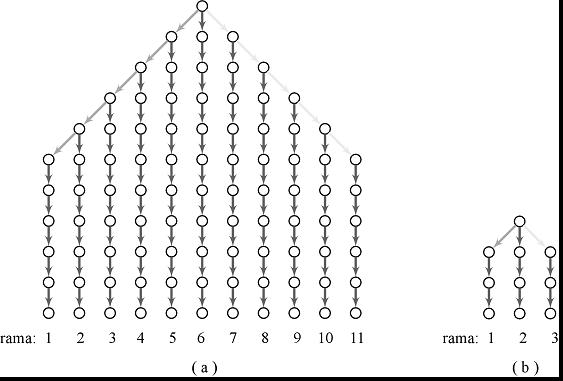
Figura 14: Árboles de exploración inicial y para la corrección de trayectoria con profundidad de 10 y 3 niveles, ( a ) y ( b ) respectivamente.
La elección de estas ramas para el árbol de predicciones, obedeció al hecho del aumento exponencial del número de éstas a medida que aumenta la profundidad del árbol (para una profundidad de 10 existen: 310 = 59049 ramas). Por esta razón se eligieron únicamente las ramas que indican los comandos motrices más relevantes para el agente, es decir, aquellas en donde predominan los movimientos hacia adelante, ya que éstos son los únicos en los que se podrían presentar colisiones. La profundidad de 10 niveles corresponde al máximo número de instantes simulados con los que se puede anticipar una colisión de manera confiable (ver Figura 12 de la sección 4.1.2).
Una vez que se realizaron las 11 PLPs se eligió la de menor activación táctil y se ejecutaron únicamente los movimientos indicados por esta rama hasta el instante t+6. Esto permite llevar a cabo correcciones de la trayectoria mediante un segundo árbol de predicciones en caso de ser necesario. La elección del instante t+6 para disparar el segundo árbol es porque asegura que cualquiera que haya sido la rama con menor activación, como mínimo se ejecute un movimiento hacia adelante (e.g. las ramas en los extremos del árbol).
Para la segunda etapa se ejecuta un árbol de predicciones de profundidad 3 y 3 ramas: (d-a-a), (a-a-a) y (i-a-a), donde d significa un giro a la derecha, a un movimiento hacia adelante e i un giro a la izquierda (ver Figura 14b). La elección de una profundidad de 3 niveles estuvo de acuerdo al umbral de colisión que se fijó durante el entrenamiento del sistema, de tal forma que si se llega a elegir la rama central del árbol (a-a-a), la distancia total recorrida por el agente (450 mm) sea la máxima posible antes de superar al umbral de colisión (500 mm) descrito en la sección 3.2.
4.2.1Primera etapa: Predicciones para una exploración inicial
Con el objeto de caracterizar el desempeño del árbol de predicciones inicial se muestra la gráfica de las activaciones promedio acumuladas para cada una de las ramas que lo conforman, (ver Figura 15).

Figura 15: Activaciones promedio acumuladas del árbol de predicciones para la primera etapa. Se resalta el instante t + 6.
En primer lugar se observa que la rama con mayor activación es la rama 6 del árbol, siendo la rama crítica ya que si se llegaran a ejecutar los movimientos hacia adelante indicados por ésta, llevaría a que el agente colisione con el grupo de obstáculos en la parte central.
En segundo lugar, las ramas de menor valor son las del extremo derecho del árbol (9, 10 y 11), con un valor de activación acumulada menor a 1.50. Estas indican una serie de movimientos que dirigirían al agente hacia la apertura por la que puede pasar, sin embargo la rama con la mínima activación acumulada es la rama 10 (i-i-i-i-a-a-a-a-a-a), con un valor final de 1.24.
Finalmente se muestra en una línea resaltada el instante t + 6, el cual fija el máximo número de movimientos a ejecutarse e inicia la etapa de corrección de la trayectoria.
4.2.2 Segunda etapa: Predicciones para corrección de trayectoria
La tarea restante consiste en corregir el curso de la trayectoria a través de la ejecución del árbol de predicciones de profundidad 3 (Figura 14b).
La primera PLP en llevarse a cabo es la correspondiente a la rama 2 del árbol (a-a-a) con el objeto de determinar si al final de los 3 movimientos el agente llegaría a colisionar, es decir, si la activación promedio acumulada para la predicción táctil superara el valor de 0.8. En caso de que sucediera esto, se llevarían a cabo las PLPs para las otras 2 ramas del árbol con el objeto de determinar cual tendría la menor activación acumulada. En caso contrario, el agente únicamente ejecuta la secuencia de movimientos indicados por esta rama.
Al inicio de esta segunda etapa, la PLP de la rama 2 superó el valor de 0.8, haciendo necesaria la realización del árbol de predicciones con sus 3 ramas. La gráfica que indica la activación promedio acumulada para este árbol se muestra en la Figura 16, en la que se aprecia que la rama 2 supera el valor umbral, mientras que la rama 1 (d-a-a) es la que tiene el valor mínimo.
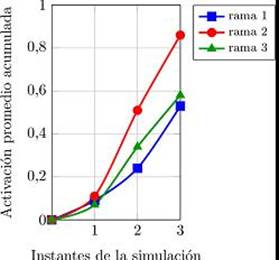
Figura 16: Activaciones promedio acumuladas para el árbol de predicciones durante la corrección de la trayectoria del agente.
4.2.3. Ruta seguida por el agente
La trayectoria seguida por el agente se ilustra en el árbol de la Figura 17) donde se muestran las activaciones promedio acumuladas en cada instante de la secuencia de movimientos ejecutados por el agente. El color de cada nodo es proporcional a la activación donde el azul y el rojo codifican los valores de mínimo y máximo, respectivamente.

En el caso del árbol de predicciones correspondiente a la etapa de exploración inicial, se observa que la rama con menor valor al instante t + 10 es la rama 10. Debido a esto, se ejecutaron la secuencia de movimientos (i-i-i-i-a-a) indicados por esta rama. Se puede observar la tendencia que tuvieron las demás ramas de PLPs, de las cuales la rama 6 presenta el valor de mayor activación mientras que las ramas 9, 10 y 11 son las que tienen un menor valor.
En seguida, el agente lanzó un árbol de predicciones de profundidad 3 y corrigió su trayectoria al elegir la rama 1 que corresponde a la secuencia: d-a-a. Posteriormente el agente ejecutó únicamente movimientos hacia adelante, ya que ninguna de las PLP para la rama central de estos árboles superó el valor umbral de colisión fijado en 0.8, por lo que el agente no necesitó realizar otra corrección adicional en el curso de su trayectoria, logrando de esta forma pasar a través de la apertura correcta. El vídeo del experimento se puede encontrar en el siguiente vínculo: http://youtu.be/rEBNrrAymM4.
5 Conclusiones
El trabajo presentado constituye un esfuerzo más por estudiar modelos provenientes de las ciencias cognitivas a través de su implementación en agentes artificiales (Pfeifer, 2002). Todo esto, dentro del marco de trabajo de la cognición cimentada (Barsalou, 2008), la cual enfatiza el papel que desempeña el cuerpo, el entorno y los procesos motrices para la estructuración y el surgimiento de habilidades cognitivas en los agentes.
Este trabajo se originó a partir de diversos estudios acerca de la percepción de distancia en los humanos, los cuales proponen que ésta no es una capacidad generada a través de un proceso geométrico, sino que por el contrario es el resultado de la asociación multi-modal (Braund, 2007), expresado en términos de unidades escaladas a nuestro cuerpo e influenciado por la acción (Proffitt, 2006).
El objetivo principal fue desarrollar un modelo capaz de dotar a un agente artificial con la capacidad de adquirir una noción de distancia a los objetos de su entorno. Este se basó en la implementación de un modelo directo, el cual provee de forma anticipada las consecuencias sensoriales de un comando motriz que se pretende llevar a cabo. El estado sensorial fue representado a través de las modalidades visual y táctil, mientras que el espacio motriz por tres movimientos diferentes, un movimiento hacia adelante y giros hacia la izquierda y derecha.
En los experimentos realizados, se encontró que las predicciones realizadas por el modelo directo para la modalidad táctil estuvieron en un rango continuo de [0-1], a pesar que durante la fase de entrenamiento ésta fue codificada con un valor binario representando un estado de colisión o no colisión, este aspecto resultó ser una característica emergente del sistema que le permitió al agente realizar una asociación multi-modal de la información visual y táctil percibida.
El modelo implementado le proporcionó al agente la capacidad para realizar un juicio perceptual de la distancia a un objeto, en función del número de movimientos que podría ejecutar antes de que ocurra una colisión.
En el primer experimento se colocó un único obstáculo frente al agente a diferentes distancias en intervalos de 15 cm. Para cada una de las distancias el agente llevo a cabo predicciones de largo plazo (PLP). El propósito de esto fue observar el valor presentado por las predicciones táctiles y caracterizar lo que llamamos un concepto de distancia a colisión cimentado en las capacidades sensoriomotrices del agente. Este concepto resultó ser consistente con un valor constante para la activación promedio de la modalidad táctil para PLPs de hasta 10 simulaciones. Este valor umbral, es un aspecto que va acorde con uno de los principios de diseño de agentes artificiales completos que se propone en Pfeifer y Scheier, (1999) y concerniente al principio del valor, el cual establece la existencia de alguna medida intrínseca que le indique al agente la conveniencia de experimentar una determinada situación sensorial.
Una vez cimentado este concepto se diseñó un experimento buscando escalar la complejidad de los procesos cognitivos. La tarea del agente consistió en determinar de entre dos pasajes o entradas por cuál de ellos podía pasar sin colisionar. Para lograr esto el agente utiliza lo que nos atrevemos a llamar un concepto de pasabilidad. Haciendo uso de PLPs, el agente encontró el mejor camino de manera segura antes de ejecutar ningún movimiento explícito. Este experimento se relaciona al reportado en humanos por Warren y Whang (1987). Para tal efecto se implementó un árbol de 11 PLPs con secuencias de 10 combinaciones distintas de los tres movimientos del repertorio motriz del agente. Se mostró como las ramas de PLP que indicaban una secuencia de movimientos hacia la apertura más amplia, presentaron los valores menores de activación táctil, mientras que las demás ramas tuvieron valores mayores. La máxima activación correspondió a la secuencia de acciones que conducirían a una colisión con los obstáculos frente al agente. En seguida, se realizó una corrección de la trayectoria en plena ejecución de ésta, gracias a la implementación de un árbol de PLPs de 3 ramas y 3 combinaciones de los tres movimientos. Esto le permitió al agente anticipar una futura colisión con uno de los bordes de la apertura y terminar la tarea de manera exitosa.
Es importante resaltar las principales diferencias con trabajos relacionados en el área y que están vinculadas a las características especificadas en la sección 2.3. A diferencia de los trabajos reportados en Hoffmann (2007) y en Möller y Schenck (2008), el modelo reportado aquí utiliza una unidad de medición que está basada en las características propias del agente, como son las unidades de movimiento, es decir, en X pasos ocurrirá una colisión. El sistema no necesita de una calibración o interpretación externa pues relaciona el espacio sensorial con las acciones que es capaz de realizar. Así, 3 movimientos hacia adelante o 3 comandos motrices se convierten para el observador en 45 cm. Esta unidad de medición es tomada por Escobar et al., (2012) en su implementación de un modelo directo, sin embargo, los autores usan los métodos de la visión artificial tradicional para resolver el problema geométrico que se presenta al calcular el mapa de disparidad. En el modelo presentado aquí, este mapa no es necesario ya que se toman las imágenes tal como son obtenidas de la cámara estereoscópica.
Lo mismo es presentado por Gaona et al. (2012) donde el modelo directo toma dos imágenes y predice los cambios de éstas, así como una situación táctil. Sin embargo, este sistema ofrece una predicción muy inferior a la presentada en este trabajo. Nuestro sistema lleva a cabo predicciones visuales de hasta 10 pasos como se muestra en la sección 4. Más aún, la predicción táctil está construida de manera que simula el mapa de disparidad obtenido por otros métodos, manteniendo una alta correlación con las imágenes reales y predichas.
Sin lugar a duda, el trabajo a futuro en términos de comportamientos más complejos presenta retos importantes. Creemos que estos experimentos proveen bases sólidas para la cimentación de conceptos y acciones en agentes artificiales, abriendo discusiones importantes sobre la toma de decisiones y la posibilidad de planificación. Estamos seguros de que la investigación de comportamientos de bajo nivel usando información motriz y sensorial cimentada en los agentes y sus capacidades es un fundamento necesario para continuar en la búsqueda de agentes inteligentes y autónomos. Entre otras, una de las direcciones que esta investigación debe tomar es la de predicciones de acciones de otros agentes. Una vez que un agente ha aprendido su esquema sensoriomotriz y sus capacidades en esos términos, deberá entonces ser capaz de entender las acciones de otros agentes (Oztop et al., 2006). Todo esto dentro del marco de la robótica cognitiva, la interacción de los agentes con su ambiente y las representaciones y predicciones sensorimotrices.

