










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkNova scientia
versión On-line ISSN 2007-0705
Nova scientia vol.5 no.10 León oct. 2013
Ciencias naturales e ingenierías
Modelado de un Sistema de Neuronas Espejo en un Agente Autónomo Artificial
Model of a Mirror Neuron System in an Artificial Autonomous Agent
David Castillo Arceo1, Esaú Escobar2, Jorge Hermosillo2 y Bruno Lara2
1 Maestría en Ciencias Cognitivas, Universidad Autónoma del Estado de Morelos, México.
2 Facultad de Ciencias, Universidad Autónoma del Estado de Morelos, México.
E-mail: davidcarceo@gmail.com; bruno.lara@uaem.mx.
Recepción: 04-12-2012
Aceptación: 15-04-2013
Resumen
La presente investigación está basada en el importante trabajo interdisciplinario desarrollándose en las ciencias cognitivas y que estudia tópicos tales como Neuronas Espejo, Reconocimiento de Comportamientos, Imitación, y Robótica Cognitiva.
Abordando una perspectiva anclada en la Teoría de la Simulación y basado en modelos computacionales sobre Sistemas de Neuronas Espejo se ha diseñado un sistema, implementado en un Agente Autónomo Artificial. Dicho sistema deberá reconocer los movimientos de otro agente, basado en el aprendizaje de sus movimientos y las relaciones que surgen de éstos con la percepción del mundo.
El diseño de este sistema se propone parta de dos supuestos: (1) El Sistemas de Neuronas Espejo visto como un acoplamiento de los Modelos Internos Inverso y Directo - siendo el segundo y su función de predictor lo que se hipotetiza es la función de las Neuronas Espejo - y (2) que la base para el reconocimiento de las conductas de otros está en la habilidad de los seres vivos de empatar en un lenguaje común las conductas propias, desarrolladas a lo largo de su experiencia, con las conductas ejercidas por otros.
Presentamos un ejercicio donde nuestro Agente imita a otro para comprobar que el reconocimiento de las conductas de los otros es posible desde la perspectiva que se ha adoptado. Creemos que nuestro experimento es una prueba de concepto y presenta una base sólida para investigaciones futuras.
Palabras Clave: Neuronas Espejo, Imitación, Modelos Internos, Aprendizaje Sensorimotriz, Inteligencia Artificial (IA).
Abstract
The research presented here is based on the on going multi-disciplinary work in the cognitive sciences addressing topics such as Mirror Neurons, Behavior Recognition, Imitation and Cognitive Robotics.
The work involves the design of a system, implemented on an Artificial Autonomous Agent, addressing a perspective grounded in Simulation Theory and based in computational models of Mirror Neuron Systems. As a base and first step, the agent learns associations between its movements and the sensory consequences these have on the world; once this knowledge forms part of its baggage, the agent is capable of imitating the movements of a second agent.
The design of the proposed system is based on two assumptions: (1) The mirror neuron system seen as the coupling of Inverse and Forward Internal Models - being the latter, and its function as predictor, the hypothesized function of mirror neurons, (2) The basis for the recognition of other's behaviors is the ability of living things to link their own behaviors with behaviors performed by others by means of a common language developed during their experience on interacting with their environment.
We present an experiment where an agent imitates a second one to proof whether the recognition of the other's behavior is possible from the adopted perspective. We believe that our experiment is a proof of concept and presents a very solid ground for further research.
Keywords: Mirror Neurons, Imitation, Internal Models, Sensorimotor Learning, Artificial Intelligence (AI).
1. Introducción
En nuestras experiencias cotidianas las interacciones sociales son comunes y fluidas y, sin embargo, la pregunta básica sobre "Cómo entendemos las conductas de los otros" es algo en lo que las Ciencias interesadas en la Mente no tienen acuerdos1, aún a pesar de lo indispensable que es esto para la interacción: Uno debe entender lo que el otro hace para poder actuar en acorde a lo entendido.
Tratando de dar respuesta a ésta pregunta existe la propuesta llamada Teoría de la Simulación que argumenta existe un lenguaje común entre las conductas propias y las observadas en otros (Gordon, 1999). Este lenguaje produce una simulación interna y automática de las acciones observadas permitiendo con ello el reconocimiento y la predicción, facilitando la interacción. Las investigaciones actuales en neurociencia han fortalecido esta propuesta sobre todo ante el descubrimiento de las Neuronas Espejo (NE) (Gallese & Goldman, 1998).
Las NE son un tipo específico de neuronas, encontradas en áreas pre-motoras de la corteza cerebral en la especie Macaco Rhesus (Macaca Mulatta), que disparan tanto en la realización de conductas motoras específicas como ante la observación de otros realizando las mismas conductas (Rizzolatti & Sinigaglia, 2006), lo que sugiere un lenguaje común entre acciones propias y lo percibido en el otro. La cualidad sensorimotriz de estas neuronas pone en entredicho los esquemas tradicionales de las neurociencias sobre el funcionamiento serial y encapsulado del cerebro.
En Inteligencia Artificial se han creado Modelos Computacionales que buscan plasmar el comportamiento de dichas neuronas ya sea en aislado, con interacción de otras regiones, o, en un sentido más abstracto, modelando las hipótesis sobre sus funciones.
Este trabajo busca demostrar, desde el marco de la Robótica Cognitiva, la factibilidad de que los Sistemas de Neuronas Espejo (SNE) sean vistos como un Sistema de Modelos Inversos y Directos acoplados, desarrollados en la experiencia mediante la interacción del agente con su entorno.
Para ello se ha diseñado un sistema, implementado en un agente autónomo (Robot Pioneer 3DX), que obtiene su base de conocimiento sensorimotriz bajo un proceso de Balbuceo Motriz (Motor Babbling). El sistema esta compuesto por un Modelo Directo codificado mediante una red neuronal artificial (perceptrón multi-capa) entrenada con retropropagación del error y un Modelo Inverso que mediante un proceso de selección de candidatos sugiere comandos motrices a partir de la base de conocimiento adquirida previamente.
El artículo se encuentra estructurado de la siguiente manera: En la Sección 2 se hace una breve introducción a la teoría sobre Modelos Internos - Modelo Directo e Inverso. La sección 3 hace mención a Modelos Computacionales de Sistemas de Neuronas Espejo que comparten algunas características con nuestro modelo y se precisa nuestra estrategia ante el problema de la correspondencia sensorial-motriz que debe existir para el reconocimiento de las acciones del otro. En la Sección 4 se describe el sistema propuesto y las características técnicas de la implementación en el Agente Autónomo Artificial - Motor Babbling, Modelo Directo y Modelo Inverso. En la Sección 5 se presenta el experimento realizado así como los resultados. Por último, en la Sección 6 se discuten los alcances y resultados de nuestro trabajo.
2. Modelos Internos
La propuesta de Modelos Internos tiene sus orígenes en la teoría de control, propuestos después como mecanismos neuronales que pueden mimetizar las características de las entradas, salidas - o inversiones de éstas - del aparato motor (Kawato, 1999). Se han postulado principalmente dos modelos internos que interactúan entre sí: El Modelo Directo y el Modelo Inverso involucrados en la predicción y ejecución de acciones respectivamente.
Un Modelo Directo (MD) es un Modelo Interno que produce la predicción de una situación sensorial (S*t+1) basado en el estado actual (St) y una acción que podría o no realizarse (Mt), es decir, predice las consecuencias de una acción dada en el contexto de un vector de estados dados (Jordan & Rumelhart, 1992).
Por otra parte un Modelo Inverso (MI) es una representación neural de la transformación de la trayectoria de movimiento que se desea en un objeto, en comandos motrices requeridos para alcanzar dicha meta (Wolpert et al., 1998). Dicho de otro modo el MI propone un comando motriz (Mt) dado un contexto actual (St) para alcanzar un estado deseado o conocido (St+1).
3. Modelos Computacionales de SNE
Existen varios modelos computacionales de SNE la gran mayoría de ellos relacionados con movimientos mano- brazo (una revisión general del tema se puede ver en Oztop et al., 2006). Citaremos a continuación dos ejemplos de Modelos de SNE e Imitación que guardan bastante relación con nuestro modelo.
Demiris & Hayes (2002) propusieron una arquitectura constituida por un conjunto de acoplamientos Comportamientos- Modelos Directos. El Comportamiento es un encapsulamiento de Conductas bastante similar al Modelo Inverso en términos de ser un controlador salvo que ésta arquitectura tiene una retroalimentación del Comportamiento en base a la predicción del MD.
Una contribución bastante importante anterior a la Demiris y Hayes - que forma la base de nuestro modelo - es conocida como MOSAIC propuesta por Wolpert et al. (1998). MOSAIC es una serie de MI-MD acoplados y compitiendo entre si para analizar el comando motriz sugerido a ejecutarse. La competencia se da en términos de una normalización, buscando cuál de las predicciones de cada MD acerca del movimiento propuesto por su MI tienen mayor probabilidad de dar como resultado el estado sensorial observado en el demostrador.
Para ser utilizado en el reconocimiento de conductas de otros e imitación se siguen tres procesos (Oztop et al., 2006, pag. 276):
1. La información visual observada en un demostrador debe ser convertida a un formato que pueda ser usada como entrada para el sistema motriz del imitador,
2. Cada controlador (MI) debe sugerir el comando motriz requerido (Mt) para lograr la trayectoria observada, las salidas de los MI sirven de entradas al predictor (MD);
3. Las predicciones que el MD hace (S*t+1) pueden ser comparadas con el estado siguiente del demostrador (St+1) lo que provee un error de la predicción que posibilita elegir uno de los comandos sugeridos como conducta a realizar por el imitador o, en el caso de solo el reconocimiento, para señalar cuál tiene una mayor confianza de ser la conducta observada.
Este sistema no tiene aprendizaje en linea (no se agregan nuevas conductas). La imitación entonces será en términos de su base de conocimientos, dada por sus MIs. El flujo de esta arquitectura mantiene relación con las investigaciones de los SNE si la salida del predictor (MD) se considera análoga a la actividad de las neuronas espejo, sostenidos en la hipótesis de que el papel de las NE es predecir las consecuencias de conductas (observadas o propias) ayudando así al proceso de reconocimiento (Oztop et al., 2005).
Con base en la teoría propuesta por Heyes (2009), nosotros postulamos que debe existir un código común entre lo que se observa en el demostrador y lo que el imitador ha hecho en su aprendizaje previo aunque ambos movimientos no correspondan completamente. El lenguaje sensorimotriz común se da por un aprendizaje asociativo y podría estar en un punto de atención que el imitador observa tanto cuando ejecuta sus movimientos como cuando observa los de alguien más.
Digamos por ejemplo, que aprendimos un patrón motriz al mover la cabeza teniendo como punto de atención un objeto en el ambiente, por ejemplo la nariz del otro. Vimos cómo este objeto se desplaza a lo largo de nuestro campo de visión si nos movemos. Si después observamos a alguien mover la cabeza y fijamos la atención en la nariz de éste mientras mueve su cabeza veríamos igualmente un desplazamiento de la nariz en relación a nosotros. En este caso particular la relación sería directa a nuestro aprendizaje: si el otro mueve su cabeza a la derecha, su nariz se desplazaría a la izquierda con respecto a nuestro campo de visión y nuestro movimiento para observar esto, nuestro aprendizaje, sería movernos a la derecha también. Es a partir de estos cambios que el sistema que proponemos relaciona las observaciones.
4. Modelo Propuesto
Antes de hablar del modelo en forma hay que señalar la importancia del método en que el robot adquiere el marco de conocimiento del mundo.
En Psicología Piaget & Inhelder (1969) propusieron un esquema de desarrollo de la inteligencia en el ser humano haciendo énfasis en el papel de la experiencia sensorimotriz en los primeros meses de vida. Estructuras sensorimotrices se desarrollan a partir de movimientos reflejos llegando a la construcción de hábitos; esquemas de asociaciones que están dados por sus propios movimientos en interacción con el mundo.
Dentro de la Robótica Cognitiva se propone, a partir de estas hipótesis y en búsqueda de acercarse a los procesos naturales de los seres vivos, estrategias llamadas Aprendizaje Motriz Activo (Active Motor Learning). Estas se basan en que el robot explore el ambiente y extraiga de ahí la información necesaria para construir los modelos internos de su cuerpo en relación con la percepción del ambiente. El balbuceo motriz (Motor Babbling (Caligiore et al., 2008)) es una de estas estrategias de aprendizaje y es la que se adopta en el presente trabajo.
En un primer momento el robot obtendrá relaciones causales entre los cambios que suceden en su aparato perceptual - la cámara conectada a éste y la identificación de un marcador - y los movimientos realizados - los desplazamientos realizados por cada una de sus ruedas a una velocidad aleatoria para cada una y por un tiempo también aleatorio. Esto forma la base de conocimiento del agente, es su aprendizaje sensorimotriz con el cual puede predecir los cambios sensoriales que suceden a sus movimientos.
Un siguiente paso que se propone es el uso de este aprendizaje sensorimotriz como una herramienta para el reconocimiento e interpretación de los cambios sensoriales que no son efectos producidos por éste; es decir, un ejercicio de predicción inversa donde lo que se predice son los movimientos que se requieren para el cambio observado. Desde esta predicción inversa el agente tendrá un primer acercamiento al reconocimiento de movimientos realizados por otros agentes, como más adelante lo demuestran los experimentos.
Para dicho reconocimiento se propone una variante del acoplamiento de modelos internos que sugiere Wolpert & Kawato (1998) en su estructura MOSAIC (ver Figura 1).
Nuestro sistema esta formado por un único Modelo Inverso (MI) que sugiere un número de comandos motrices (Mt)n que mantienen correspondencia visual con los cambios sensoriales observados (St y St+1). Estas sugerencias motrices entran al Modelo Directo (MD) junto con el estado sensorial actual (St) para generar predicciones sobre cómo se vería el punto de atención si fuera el propio agente quien hiciera el movimiento (S*t+1)n. En seguida se comparan las predicciones del MD con el estado sensorial siguiente observado, esto es (S*t+1 contra St+1), seleccionándose la de menor error. El comando motriz (Mt) que produjo dicho S*t+1 es el que se ejecutará.
Alternativamente se puede repetir el ciclo para simular una Predicción de Largo Plazo (PLP), esto es, usar (St+1)s como el siguiente St. La PLP puede ser usada para corregir los posibles errores - recordemos que la predicción del MD y la corrección de errores es lo que Oztop et al. (2005) proponen como función de las Neuronas Espejo.
4.1. Implementación del Modelo
El modelo es implementado en un Robot Pioneer 3-DX al que se le acopló una cámara web con la que se recopilaron las coordenadas (x, y, z) de un marcador de referencia o fiduciario con origen en la cámara del robot, usando la librería GNU ARToolkit versión 2.722. Se utiliza dicha herramienta ya que dada la geometría conocida del marcador y después de la apropiada calibración, este es invariante a rotación y translación. La calibración permite asimismo obtener la coordenada z aún con sólo una imagen.
Estas coordenadas representan los estados sensoriales actuales (St) y siguientes (St+1) que se utilizan en: la recolección de datos (Motor Babbling), el entrenamiento de la red de nuestro MD, la selección de comandos sugeridos de nuestro MI y, en el caso del experimento de reconocimiento-imitación, los estados del agente observado.
El escenario tanto de recolección de datos como del experimento es una arena rectangular libre de obstáculos con un marcador (imagen simple monocromática cuadrada de 8cms de lado) a distancias de entre 40 cm. a 2 metros.
La recolección de datos (Motor Babbling) consiste en la generación de patrones a partir de los movimientos aleatorios del robot sumando un total de 2746 patrones tipo:
(x,y,z)t, (Vdt, Vi-t,)t, (x, y,z)t+1
donde :
• (x, y, z)t son las posiciones en el estado inicial (St),
• (Vd·t y Vi·t)t son la velocidad durante un tiempo -ambos aleatorios- de la rueda derecha e izquierda respectivamente, finalmente esto representa un desplazamiento o Comando Motriz (Mt);
• (x, y , z)t+1 son las coordenadas en que se encuentra nuestro marcador una vez ejecutado el comando motriz, el estado siguiente (St+1).
El Modelo Inverso utiliza un algoritmo de selección secuencial de los patrones recolectados -la base de conocimiento del Agente- y sugiere aquellos con los cuales se produce un cambio sensorial semejante al observado. El algoritmo realiza las siguientes comparaciones entre St y St+1:
• Distancia en el eje z,
• Distancia euclidiana
• Distancias en los ejes x y z.
Este proceso representa una simulación interna en términos de: "¿qué movimiento necesito hacer para observar, por medio de mis movimientos, los cambios que sucedieron en el marcador?". Cada evaluación reduce el número de patrones candidatos, al final del proceso se toman los mejores 10 patrones, los comandos motrices asociados a estos son los que se usarán en la simulación realizada por el modelo directo.
El Modelo Directo es una Red Perceptrón Multicapa entrenada con una variación del método de retropropagación del error (Resilient Back Propagation) (Riedmiller & Braun, 1993) cuya entrada es la situación sensorial actual (x, y, z)t y un comando motriz sugerido (Vd·t, Vi ·t)t y Z la salida es la situación sensorial al siguiente tiempo (x, y, z)t+1.
Se entrenó la red durante 5000 ciclos offline, alcanzando un error de 0.000169. Se probó la red con 50 patrones de prueba que no habían sido expuestos a la red previamente, encontrando un error promedio en x de 16.6 milímetros, en y de 2.93 milímetros y en z de 30.97 milímetros. Estos errores se explican por la dificultad de aproximar el movimiento angular y en profundidad debido a que sólo se usa una cámara y resolver estos problemas geométricos está fuera del alcance de nuestro trabajo. Cabe resaltar que aún con estos errores el sistema presenta el comportamiento esperado.
Finalmente, cada predicción sensorial realizada por el modelo directo es evaluada al compararse con la situación sensorial deseada. El comando motriz que produjo la predicción con menor error es el que ejecutará el sistema.
5. Experimento: Reconocimiento - Imitación
En esta sección comprobamos la factibilidad de que el modelo es útil y que además puede generalizarse en eventos cotidianos. Para ello se diseñó un experimento que hemos nombrado de "Reconocimiento-Imitación".
Desde una perspectiva anclada en la teoría de la simulación para reconocer el movimiento de otro se hace uso del propio aprendizaje sensorimotriz y de una simulación interna sobre lo que se observa, esto mientras exista un lenguaje común entre nuestros movimientos y nuestras observaciones, de modo tal que: una vez reconocida la conducta bajo la base de conocimiento y experiencias sensorimotrices propias, el acto de imitar es la ejecución de la conducta identificada (Rizzolatti & Sinigaglia, 2006).
El experimento consiste en que el robot Pioneer - que tiene montado el modelo propuesto – identifique en sus propios movimientos los cambios visuales que suceden debido al movimiento observar este mismo cambio, a esto le llamamos reconocimiento de los movimientos del otro. Enseguida ejecuta la conducta motriz que sugiere haber reconocido, imita al otro.
La Figura 2 (a) muestra el escenario general que se utilizó para el experimento. El marcador se muestra en la parte superior sostenido por un carro-teledirigido y en la parte inferior de la imagen el Robot Pioneer detecta los cambios observados.
El proceso es el siguiente:
1. El agente que contiene el sistema de modelos internos (Robot Pioneer) reconoce las coordenadas del marcador que lleva el carro-teledirigido, asignándolas dentro de su sistema como el estado sensorial inicial (St);
2. Se ejecuta un movimiento predefinido en el carro teledirigido que en el caso de las figuras 2.(b) y 2.(c) fueron giros - movimiento de una de las ruedas del carro.
3. El Agente reconoce las nuevas coordenadas del marcador y asigna estas coordenadas a la entrada sensorial a un estado siguiente (St+1).
4. Una vez que tenemos las entradas sensoriales de dos instantes consecutivos, éstas pueden alimentar a nuestro modelo y es entonces cuando se puede llevar a cabo una simulación interna en términos de:
4.1. El Modelo Inverso sugiere candidatos de movimiento - busca en su base de conocimiento cuales acciones deberá realizar para encontrar un cambio sensorial similar al observado - y se envían al Modelo Directo.
4.2. El Modelo Directo hace una predicción del estado sensorial siguiente para cada uno de los candidatos motrices sugeridos a partir del estado inicial del marcador.
4.3. Se escoge el comando motriz que tenga una predicción dentro del Modelo Directo más parecida a los cambios sensoriales reales, éste será para el Robot Pioneer el comando motriz reconocido desde su base de conocimientos.
5. Puesto que el comando motriz lleva a un movimiento en espejo se realiza una inversión de signos en las velocidades de cada motor a fin de producir el movimiento imitativo en el sentido del carro teledirigido
6. Por último se ejecuta el comando motriz que el modelo selecciona como el movimiento correspondiente al observado - con los signos de los motores invertidos.
En la Figura 2.(b) y 2.(c) se pueden ver ejemplos típicos de prueba en donde el carro- teledirigido realiza giros y el agente, después de procesar con el modelo implementado la entrada visual y hacer la Simulación Interna, es capaz de reconocer los giros y ejecutar el comando imitativo.
Se realizaron diversas pruebas de reconocimiento-imitación con distintas distancias al marcador y diferentes movimientos del carro-teledirigido.
La Figura 3 muestra los resultados de una parte del experimento en donde el carro-teledirigido realizó únicamente giros a diferentes ángulos - en incrementos de 5 grados; hacia la izquierda marcado como grados negativos y a la derecha como positivos - y la correlación que existe con los giros que realiza el Robot Pioneer.
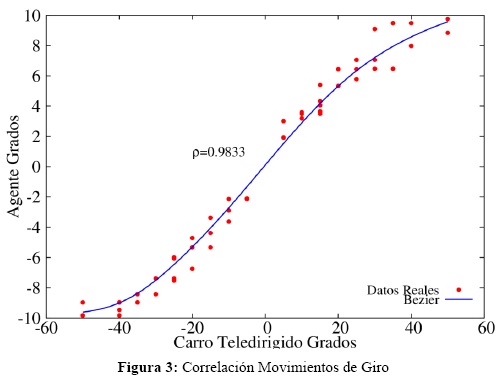
En la gráfica puede observarse una diferencia de escalas y diferentes movimientos ante un mismo giro. Por ejemplo, mientras que el Carro-Teledirigido realiza giros de 20 grados el Robot Pioneer los realiza a grados de entre 5 y 7. Esto sucede por dos razones:
La primera, las diferencias en escalas, se debe a la ventana de observación del Robot Pioneer. Hay una incongruencia entre la observación de la amplitud de sus propios giros y la amplitud de los giros del carro- teledirigido. Alissandrakis et al. (2007) sugieren varias soluciones para este Problema de Correspondencia corporal a partir de una "librería de correspondencia" retroalimentada por las experiencias con el otro agente.
La segunda razón responde al hecho de por qué los movimientos del Pioneer no son deterministas y esto se debe a que el experimento no se realizó a una misma distancia siempre, en este sentido las observaciones del giro varían y por tanto también las conductas realizadas por el robot que responden mejor a los cambios.
Las diferencias entonces surgen del aprendizaje corporizado del agente. Bajo un esquema sensorimotriz y corporal propio, dado por las experiencias que el Robot tuvo en su etapa de aprendizaje - los patrones recolectados en la etapa de Motor Babbling - y sus capacidades sensoriales y motrices, el Robot debe interpretar eventos que nunca antes observó a partir del parecido que hay entre estos y su Base de Conocimiento. Esto sucede también en agentes naturales, un ser vivo no adquiere todas las experiencias que necesitará para interpretar su mundo en eventos posteriores y sin embargo las relaciones causales de sus experiencias ayudarán a interpretar el mundo a partir de generalizaciones de su aprendizaje previo.
Aun con estas diferencias, se puede observar en la prueba una correlación bastante alta entre los giros del robot Pioneer y el carro teledirigido (Coeficiente de Correlación de Pearson r=0.9833), con una tendencia lineal.
Al igual que en los giros, se probó el sistema con desplazamientos del carro-teledirigido al frente y atrás encontrándose también una relación lineal alta (Coeficiente de Correlación de Pearson r = 0.9488), como se muestra en la figura 4.
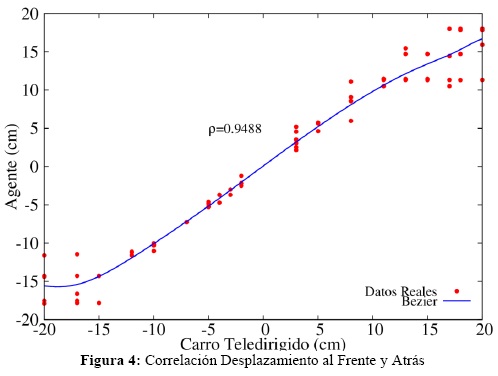
Al hacerse la prueba a diferentes distancias con respecto al carro se observan diferentes conductas que se acercan a lo observado - como en el caso de los giros. Los desplazamientos en éste caso no muestran diferencias de escalas pero, debido a las restricciones de movimientos del sistema en la etapa de aprendizaje sensorimotriz donde los desplazamientos del Robot Pioneer no son mayores a 18 cms de distancia - desplazamientos máximos de 6cm/seg por 3seg - el resultado es que ante desplazamientos del carro teledirigido mayores a 18cms el Robot Pioneer efectuará el movimiento que mejor cubra la observación, esto es, desplazamientos cercanos a los 18 cms.
Este tipo de errores, debidos a las capacidades del sistema, se puede mejorar haciendo ciclados del Modelo, es decir, una simulación sobre la primera simulación interna. Si el Modelo Directo predice que la observación ante el comando motriz elegido no es lo bastante parecida - si el error es muy alto - se puede mandar la predicción como estado inicial para que el Sistema proponga un segundo movimiento que se acerque a la observación.
Esto se comprueba con el experimento que se muestra en el video: http://youtu.be/sl2k5NpdKMs. Es una prueba donde el Robot Pioneer imita una secuencia de movimientos del carro- teledirigido. El sistema se retroalimenta un ciclo más después de realizado el primer movimiento de la siguiente manera:
La predicción del estado sensorial siguiente del Comando Motriz ejecutado (St+1s) que da el Modelo Directo en la primera simulación interna - esto es, lo que el modelo predice que se observará en el marcador ante el primer movimiento realizado - es mandado como entrada sensorial al tiempo t (St) para una segunda Simulación de modo que todo el sistema vuelva a ejecutarse partiendo de dicha predicción. Así el Robot Pioneer realizará un nuevo comando motriz intentando acercarse al estado en que ha quedado el marcador una vez que el carro teledirigido realizó el movimiento (St+1).
Esta predicción de largo plazo, representa una corrección del primer movimiento realizando un segundo movimiento ante la predicción de que el primero no será suficiente para llegar a los cambios en la observación del carro-teledirigido.
Este ciclado para llegar al estado que mostró el carro teledirigido es una buena estrategia si se busca que el Agente siga al carro: El Robot hará la primera conducta y enseguida una nueva para mantener al carro teledirigido en el campo de visión en que se observó. En apartados anteriores se ha dicho que Oztop et al. (2005) han propuesto esta predicción para corregir el error como la función principal de las neuronas espejo en áreas premotoras.
6. Discusión
El trabajo realizado constituye un ejercicio sobre las posibles vías de interacción y funciones que el sistema de neuronas espejo desarrolla.
Los descubrimientos sobre NE no dan aún conclusiones contundentes y, aunque la mayoría de los investigadores suelen ver en ellas un mecanismo específico de reconocimiento de las conductas de otro (Rizzolatti & Sinigaglia, 2006; Gallese & Goldman, 1998; Iacoboni, 2009), Heyes (2009) en su hipótesis de aprendizajes por asociación como base para la construcción de Sistemas Espejo en el cerebro propone un mecanismo global de asociaciones, sensorimotrices en el caso de los movimientos del Agente y la relación con su medio, demostrando que es posible replicar la activación y capacidades de un sistema de neuronas espejo bajo ésta postura. Nuestro trabajo contribuye a las demostraciones de ésta hipótesis. La advertencia de la autora es en últimos términos mirar el sistema como parte del conjunto y no como una entidad aislada.
Nuestro experimento trabaja la hipótesis de solo una parte del sistema y es claro que requiere de mecanismos extensos para acercarse a la realidad de los seres vivos: retroalimentaciones internas que fortalezcan y disminuyan las asociaciones que hace el sistema y su presencia en la conducta final, mayor número de entradas sensoriales interactuando entre sí enriqueciendo la experiencia y el aprendizaje, incremento en línea de las conductas adquiridas, mayor análisis del contexto y la visión. Cada uno de estos puntos requiere un esfuerzo igual de grande y en Inteligencia Artificial es tratado regularmente por separado.
Sin embargo existe en el trabajo una gran posibilidad abierta: si las Neuronas Espejo en zonas premotoras funcionan como predictores de las conductas observadas o a realizarse a partir de un aprendizaje asociativo de experiencias sensorimotrices - lo cual es la perspectiva adoptada en en este trabajo - es posible entonces que dicho sistema pueda ser diseñado para su simulación en Agentes Autónomos Artificiales a partir de Modelos Directos e Inversos y que ello pueda darnos nuevas preguntas que responder.
Los experimentos que se realizan en este trabajo demuestran que un mecanismo simple como el modelo propuesto puede ayudar en la imitación extrapolando un conocimiento del mundo en relación a los movimientos propios a una interpretación de los cambios en el mundo ajenos a nuestros movimientos, todo esto a partir de este aprendizaje sensorimotriz. En resumen la evidencia actual en los sistemas de neuronas espejo pareciera robustecer la idea de que el cerebro hace simulaciones internas y que a nivel motriz las simulaciones que ejerce permiten hacer predicciones del mundo lo que ayuda al Agente a interactuar adecuadamente (Rizzolatti & Sinigaglia, 2006, pag.125).
Si tomamos las hipótesis de Piaget & Inhelder (1969) sobre el desarrollo de esquemas sensorimotrices y pre-lingüísticos en el neonato, al aprendizaje tipo motor babbling de nuestro sistema simula el aprendizaje natural de dichos esquemas y, como nuestro experimento lo demuestra, esto puede servir como una de las bases para el reconocimiento de las acciones de otros.
Las capacidades posteriores del niño son afinadas en la retroalimentación causal de los actos realizados en su medio y las consecuencias de los mismos para el niño (Piaget, 1952). Esto dentro de la Teoría de Modelos Internos se puede considerar un refinamiento del modelo directo del agente.
Nuestro Agente Artificial aprende de un mundo en el que no hay más movimiento que el propio y la retroalimentación de esos movimientos corresponden directamente con los cambios en éste mundo. Después debe enfrentarse a otro mundo donde el movimiento existe no solo para si, en el que los cambios observados no son causalmente ocasionados por sus movimientos. El Agente debe hacer uso de su experiencia y conocimiento del mundo para interpretar los cambios que presencia. Bajo estas dificultades está claro que las interpretaciones no serán exactas.
Esta es una de las principales problemáticas que se debe asumir cuando se intenta simular Agentes Naturales; la perspectiva subjetiva, el "sesgo" del observador que tanto Filósofos como Psicólogos adheridos a la corriente Fenomenológica han descrito ampliamente.
Nuestro Agente, esta claro, tiene solo un pequeño número de experiencias en comparación a un ser vivo y más aún una posibilidad perceptual y de interacción bastante menor, pero el ejercicio sin embargo sirve para comprobar la posibilidad de reconocer las conductas del otro a partir de un esquema propio y bajo una simulación interna de modo prácticamente automático, sin necesidad de inferencias de alto nivel que requieran un tiempo excesivo, ni de representaciones abstractas y amodales que aquejaron a la inteligencia artificial por mucho tiempo.
Nuestro trabajo no pretende entonces un reduccionismo con respecto a los modos en que aprendemos a reconocer las conductas del otro, sabemos que en los seres vivos y en particular en los humanos los ambientes físicos y sociales son ricos y complejos; sin embargo este ejercicio permite comprobar que el Reconocimiento y la Imitación son posibles a partir de Aprendizajes Asociativos.
A nivel tecnológico la pregunta que hiciera Schaal (1999) sobre si la imitación es la ruta para la construcción de Robots Humanoides aún no puede ser respondida, aún falta mucho que descubrir sobre los seres vivos y su estructura. Sin embargo creemos que los avances que se han logrado en los últimos años son promisorios, sobre todo ante los primeros intentos dentro de la IA por modelar la cognición corporizada de los Agentes Naturales.
Mientras mantengamos el nexo y distancia adecuada entre la teoría y la simulación en Robótica Cognitiva es posible que paulatinamente logremos diseñar sistemas donde los robots obtengan aprendizajes significativos a partir de la imitación.
Con todo esto, la presente investigación funciona dentro de un ciclo de diseño sintético donde la teoría, la implementación y la simulación se retroalimentan, colaborando así en el entender de los sistemas descritos, sus posibles explicaciones y los alcances que tienen.
Referencias
Alissandrakis, A., Nehaniv, C. L., & Dautenhahn, K.(2007). Solving the correspondence problem in robotic imitation across embodiments: synchrony, perception and culture in artifacts. Culture, (pp. 1-24). [ Links ]
Caligiore, D., Farrauto, T., Parisi, D., Accornero, N., Capozza, M., & Baldassarre, G.(2008). Using motor babbling and Hebb rules for modeling the development of reaching with obstacles and grasping. En International Conference on Cognitive Systems. volumen (CogSys-2008). [ Links ]
Carruthers, P., & Smith, P. K. (1996). Theories of theories of mind. (1a ed.). Cambridge University Press. [ Links ]
Demiris, Y., & Hayes, G.(2002). Imitation as a dual-route process featuring predictive and learning components: A biologically-plausible computational model. En K. Dautenhahn, & C. Nehaniv(Eds.), Imitation in animals and artificats Imitation in animals and artifacts. Cambridge, Ma:MIT Press. [ Links ]
Gallese, V., & Goldman, A.(1998). Mirror Neurons and the Simulation Theory of Mind-reading. II Trends in Cognitive Sciences, (pp. 493-551). [ Links ]
Gordon, R. M.(1999). Simulation vs. Theory-Theory . En R. A. Wilson, & F. C. Keil(Eds.), The MIT Encyclopedia of the Cognitive Sciences (pp. 765-6). Massachusetts Institute of Technology. (1a ed. [ Links ]).
Heyes, C.(2009). Where do mirror neurons come from?Neuroscience and Biobehavioral Reviews.
Iacoboni, M.(2009). Las Neuronas Espejo "Empatia, neuropolítica, autismo, imitación, o de cómo entendemos a los otros". (1a ed.). Katz-conocimiento. [ Links ]
Jordan, M., & Rumelhart, D.(1992). Forward models: Supervised learning with a distal teacher. Cognitive Science, 16, 307-54. [ Links ]
Kawato, M.(1999). Internal models for motor control and trajectory planning. Current Opinion in Neurobiology, 9, 718-27. [ Links ]
Oztop, E., Kawato, M., & Arbib, M.(2006). Mirror Neurons and Imitation: A computationally guided review. Neural Networks, 19, 254-71. [ Links ]
Oztop, E., Wolpert, D. M., & Kawato, M.(2005). Mental State Inference using visual control parameters. Brain Research, Cognitive Brain Research, 129-51. [ Links ]
Piaget, J.(1952). The Origins of Intelligence in Children. New York: Press, Ed. Newyork. [ Links ]
Piaget, J., & Inhelder, B.(1969). El nivel senso-motor. En Psicología del Niño capítulo 1. (pp. 15-37). Ediciones Morata. (10a ed. [ Links ]).
Riedmiller, M., & Braun, H. (1993). A direct adaptive method for faster backpropagation learning: the RPROP algorithm. (pp. 586-591). [ Links ]
Rizzolatti, G., & Sinigaglia, C.(2006). Las Neuronas Espejo "Los Mecanismos de la empatia emocional". (1a ed.). Ediciones Paidos Ibérica. [ Links ]
Schaal, S.(1999). Is imitation learning the route to humanoid robots? Trends in Cognitive Sciences, 3. [ Links ]
Wolpert, D. M., & Kawato, M.(1998). Multiple paired forward and inverse models for motor control. Neural Networks, 11, 1317-29. [ Links ]
Wolpert, D. M., Miall, R. C., & Kawato, M.(1998). Internal models in the cerebellum. Trends in Cognitive Sciences, 2, 338-47. [ Links ]
1 Para una revisión extensa sobre este tema ver Carruthers & Smith (1996).
2 Para mayor información ver el sitio web de ARToolKit, http://www.hitl.washington.edu/research/shared space/download/.

