











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkI. Introduction
During the recent years, the interest of the research community in the Robotics field has been rapidly increasing: robotic platforms are spreading in our domestic environments and the research on Service Robotics is becoming a hot topic. A significant aspect in this context is the study of the interaction between humans and robots, especially when this communication involves non-expert users. For this reason, natural language is a key component in human-robot interfaces. Specifically, the task of Spoken Language Understanding (SLU) is related to the interpretation of spoken language commands and their mapping into actions that can be executed by a robotic platform in the operational environment. Hence, the input of a typical SLU process is the user's speech, while the output can be either the corresponding action or, more in general, a response. When dealing with this problem, manifold approaches can be adopted. On the one hand, grammar-based approaches allow the design of systems that embed the entire process in a single stage, from the speech recognition up to the semantic interpretation, e.g., [1], [2], [3]. These systems rely on grammars generated by knowledge engineers, that aim at covering the (possibly vast) plethora of linguistic phenomena the user may be interested into. Moreover, these grammars can be provided with semantic attachments [4], that enable for a structured representation of the meaning of the sentence. On the other hand, approaches relying on statistical methods [5] alleviate the need to explicitly encode the information required by the NLU process, but they require training data annotated with the targeted (linguistic) phenomena the final system is expected to capture.
Regarding the Automatic Speech Recognition (ASR) systems, most of the existing off-the-shelf solutions are based on very well-performing statistical methods [6], that enable their adoption in everyday scenarios. Nevertheless, these tools rely on general-purpose language models and false positives might be generated in specific scenarios. For example, they may be optimized to transcribe queries for a Search Engine, that are characterized by different linguistic constructions with respect to a command for a robot. However, it is reasonable to expect that domain-specific scenarios provide knowledge and specific information that can improve the performance of any off-the-shelf ASR. To this regard, several works proposed techniques where a hybrid combination of free-form ASRs and grammar-based ASRs is employed to improve the overall recognition accuracy. In these approaches, the grammar-based ASR is often used to prune the transcriptions hypothesized by the free-form ASR [7], [8] or to generate new training sentences [9], [10]. Nevertheless, the above approaches are subject to several issues. In fact, as often emphasized, e.g., [11], grammar-based approaches may lack of adequate coverage, especially in dealing with the variability of (often ungrammatical) spoken language, causing a high rate of failures in the recognition of the transcription of the ASR system. On the contrary, a highly complex grammar can improve the coverage of the captured linguistic phenomena. However, this complexity may introduce ambiguities. Moreover, the cost of developing and maintaining a complex grammar may be inapplicable in realistic applications.
In this work, we propose an approach to increase the robustness of an off-the-shelf free-form ASR system in the context of Spoken Language Understanding for Human-Robot Interaction (HRI), relying on grammars designed over specific domains. Our target is house service robotics, with the special purpose of understanding spoken commands. We rely here on the semantic grammar proposed in [2]: this is modeled around the task of interpreting commands for robots expressed in natural language by encoding (i) the set of allowed actions that the robot can execute, (ii) the set of entities in the environment that should be considered by the robot and (iii) the set of syntactic and semantic phenomena that arise in the typical sentences of Service Robotics in domestic environment. In [2], this grammar has been used to directly provide a semantic interpretation of spoken utterances. However, this interpretation requires every sentence to be entirely recognized by this grammar: even a single word or syntactic construct missing in the process may potentially cause the failure of the overall process.
We propose here to adopt a grammar to improve the robustness of an ASR system by relying on a scaling-down strategy. First, we relax some of the grammar constraints allowing the coverage of shallower linguistic information. Given a grammar, we derive two lexicons designed to recognize (i) the mention to robotic actions (ii) the mention to entities in the environment. For each lexicon, we define a specific cost that is inversely proportional to its correctness. The transcriptions initially receive a cost that is inversely proportional to the rank provided by the ASR system and, each time one of them is recognized by the grammar or a lexicon, the corresponding cost decreases. The more promising transcription is the one minimizing the corresponding final cost. The final decision thus depends on the combination of all the costs so that, even when none of the transcriptions is recognized by the complete grammar, their rank still depends on the lexicons. In this way, those transcriptions that do not refer to any known actions and/or entities are accordingly penalized.
The proposed re-ranking strategy has been evaluated on the Human Robot Interaction Corpus (HuRIC, [12]) a collection of utterances semantically annotated and paired with the corresponding audio file. This corpus is related with the adopted semantic grammar as this has been designed by starting from a subset of utterances contained in HuRIC. Experimental results show that the proposed method is effective in re-ranking the list of hypotheses of a state-of-the-art ASR system, especially on the subset of utterances whose transcriptions are not recognized by the grammar, i.e., no pruning strategy is applicable.
In the rest of the paper, Section II provides an overview of the existing approaches to improve the quality of ASR systems. Section III presents the proposed approach and defines individual cost factors. In Section IV an experimental evaluation of the re-ranking strategy is provided and discussed. Finally, Section V derives the conclusions.
II. Related work
The robustness of Automatic Speech Recognition in domain-specific settings has been addressed in several works. In [13], the authors propose a joint model of the speech recognition process and language understanding task. Such a joint model results in a re-ranking framework that aims at modeling aspects of the two tasks at the same time. In particular, re-ranking of n-best list of speech hypotheses generated by one or more ASR engines is performed by taking the NLU interpretation of these hypotheses into account. On the contrary, the approach proposed in [14] aims at demonstrating that perceptual information can be beneficial even to improve the language understanding capabilities of robots. They formalize such information through Semantic Maps, that are supposed to synthesize the perception the robot has of the operational environment.
Regarding the combination of free-form ASR engines and grammar based systems, in [15] two different ASR systems work together sequentially: the first is grammar-based and it is constrained by the rule definitions, while the second is a free-form ASR, that is not subject to any constraint. This approach focuses on the acceptance of the results of the first recognizer. In case of rejection, the second recognizer is activated. In order to improve the accuracy of such a decision, the authors propose an algorithm that augments the grammar of the first recognizer with valid paths through the language model of the second recognizer. In [7], a robust ASR for robotic application is proposed, aiming at exploiting a combination of a Finite State Grammar (FSG) and an n-gram based ASR to reduce false positive detections. In particular, a hypothesis produced by the FSG-based decoder is accepted if it matches some hypotheses within the n-best list of the n-gram based decoder. This approach is similar to the one proposed in [16], where a multi-pass decoder is proposed to overcome the limitations of single ASRs. The FSG is used to produce the most likely hypothesis. Then, the n-gram decoder produces an n-best list of transcriptions. Finally, if the best hypothesis of the FSG decoder matches with at least one transcription among the n-best, then the sentence is accepted. A hybrid language model is proposed in [8]. It is defined as a combination of a n-gram model, aiming at capturing local relations between words, and a category-based stochastic context-free grammar, where words are distributed into categories, aiming at representing the long-term relations between these categories. In [9], an interpretation grammar is employed to bootstrap Statistical Language Models (SLMs) for Dialogue Systems. In particular, this approach is used to generate SLMs specific for a dialogue move. The models obtained in this way can then be used in different states of a dialogue, depending on some contextual constraints. In [17], n-grams and FSG are integrated in one decoding process for detecting sentences that can be generated by the FSG. They start from the assumption that sentences of interest are usually surrounded by carrier phrases. The n-gram is aimed at detecting those surrounding phrases and the FSG is activated in the decoding-process whenever start-words of the grammar are found.
All the above approaches can be considered complementary to the one proposed here. However, the advantages of our method are mainly in the simplicity of the proposed solution and the independence of the resulting work-flow from the adopted free-form ASR system: our aim is to define a simple yet applicable methodology that can be usable in every robot.
III. A robust domain-specific approach
In this section, we propose an approach to select the most correct transcription among the results proposed by a Automatic Speech Recognition (ASR) system. Given a spoken command from the user, e.g., move to the fridge, such a system produces a rank of possible transcriptions such as
1) move to the feet
2) more to the fridge
3) move to the fridge
4) move to the fate
5) move to the finch
In this case, the correct transcription is ranked as third. In order to choose this sentence, we apply a cost function to the hypotheses based on (i) the adherence to the robot grammar, as it describes the typical commands for a robot, (ii) the recognition of action(s) applicable/known to the robot (as for move) and (iii) the recognition of entities, like nouns referring to objects recognized/known to the robot, e.g., fridge. The cost function we propose decreases along with the constraints satisfied by the sentence, e.g., the second sentence satisfies (iii), but not (i) and (ii) (as more is not an action); as a consequence it results into a higher cost with respect to the third transcription. Before discussing the cost function as a ASR ranking methodology, we define the grammatical framework used in this work, in line with [2].
A. Grammar-based SLU for HRI
Robots based on speech recognition grammars usually rely on speech engines whose grammars are extended according to conceptual primitives, generally referring to known lexical theories such as Frame Semantics [18]. Early steps in the HRI chain are based on ASR modules that derive a parse tree encoding both syntactic and semantic information based on such theory. Parse trees are based on grammar rules activated during the recognition, and augmented by an instantiation of the corresponding semantic frame, that corresponds to an action the robot can execute. Compiling the suitable robot command proceeds by visiting the tree and mapping recognized frames into the final command.
The applied recognition grammar jointly models syntactic and semantic phenomena that characterize the typical sentences of HRI applications in the context of Service Robotics. It encodes a set of imperative and descriptive commands in a verb-arguments structure. Each verb is retained as it directly evokes a frame, and each (syntactic) verb argument corresponds to a semantic argument. The lexicon of arguments is semantically characterized, as argument fillers are constrained by one (or more) semantic types. For example, for the semantic argument THEME of the BRINGING frame, only the type TRANSPORTABLE_OBJECTS is allowed. As a consequence, a subset of words referring to things transportable by the robots, e.g., can, mobile phone, bottle is accepted. A subset of the grammar for the BRINGING frame, covering the sentence Bring the book to the table is reported hereafter:

We will distinguish between terminals denoting entities (such as can, book, bottle that belong to the lexicon of TRANSPORTABLE_OBJECTS) from the lexicon of possible actions (such as bring, take or carry characterizing the actions of the frame BRINGING) as they will give rise to different predicates augmented with grammatical constraints. Moreover, transcribed sentences covered by the grammar, i.e., belonging to the grammar language, are more likely to correspond to the intended command expressed by the user, and should be ranked first in the ASR output.
B. A grammar-based cost model for accurate ASR ranking
A first interesting type of constraint is posed by the ASR system itself. In fact the rank proposed by an ASR system is usually driven by a variety of linguistic knowledge in the ASR device. A basic notion of cost can be thus formulated ignoring the domain of the specific grammar.
Given a spoken utterance ʋ, let H(ʋ) be the corresponding list of hypotheses produced by the ASR. The size |H(ʋ)| = N corresponds to the number of hypotheses. Each hypothesis h ∈ H(ʋ) is a pair <s; ω(s)>, where s is the transcription of ʋ, and ω(s) is a cost attached to s. Let p(s) be its position in the ASR systems ranking. According to this cost function, the higher is ω(s), the lower the confidence in h being the correct transcription.
Since many off-the-shelf ASR systems do not provide the confidence score for each transcription, in order to provide a general solution, only the rank is taken into account: let ʋ be a spoken utterance and H(ʋ) the corresponding list of transcriptions, then, ∀s ∈ H(ʋ) the ranking cost ωrc is defined as follows:
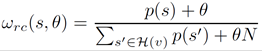 (1)
(1)
where p(s) corresponds to the position (1;...; |H(ʋ)|) of s in H(ʋ). Here θ is a smoothing parameter that enables the tuning of the variability allowed to the final rank with respect to the initial rank proposed by the ASR system.
The overall cost assigned to a transcription s depends on the ASR ranking as well as on the grammar. Let s ∈ H(ʋ), let ωi be a parametric cost depending on the grammar G, the overall cost ω(s) can be defined as:
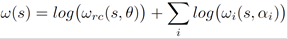 (2)
(2)
where the different ωi capture different aspects of the grammar G with scores derived from the grammatical or lexical criteria. Higher values of ωi correspond to stronger violations. Moreover, ωrc(s; θ) is the ranking cost as in Equation (1), while αi is the parameter associated to each cost ωi.
In this paper we investigate three possible cost factors, i.e., i = 1; 2; 3, to enforce information derived by different grammatical, i.e., domain-dependent, constraints. As these can be different, we designed three different cost factors:
- ωG(s; αG) is the complete-grammar cost that is minimal when the transcription belongs to the language generated by the grammar G, and maximal otherwise;
- ωA(s; αA) is the action-dependent cost that is minimal when the transcription explicitly refers to actions the robot is able to perform, and maximal otherwise;
- ωE(s; αE) is the entity-dependent cost that takes into account the entities targeted by the commands, and is minimal if they are referred into the transcription s and maximal otherwise.
These cost factors are detailed hereafter.
Complete-grammar cost. When dealing with the Spoken Language Understanding with robots we may want to restrict the user sentences to a set of possible commands. This is often realized by defining a grammar covering the linguistic phenomena we want to catch. Moreover, if the grammar is designed to embed also semantic information as in [2], it can be introduce also higher level semantic constraints. For instance, the BRINGING action can be applied only to TRANSPORTABLE_OBJECTS. As an example, a sentence a transcription such as bring me the fridge is discarded by the grammar if the fridge is not a TRANSPORTABLE_OBJECTS.
Let G be a grammar designed for parsing commands for a robot R. Let L(G) be the language generated by the grammar, i.e., the set of all possible sentences that G can produce. Then, the complete-grammar cost ωG is computed as
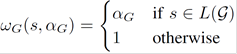 (3)
(3)
where αG ∈ (0; 1] is a weight that measures the strength of the violation and can be used to weight the impact of an "out-of-grammar" transcription. Notice that the weight αG can be either set as a subjective confidence or tuned through a set of manually validated hypotheses. If αG is set to 1, no grammatical constraint is applied and the complete grammar cost has no effect.
Action-dependent cost. Robot specifications enable the construction of the lexicon of potential actions A, hereafter called LA. Let A be the set of actions that a robot can perform, e.g., MOVE, GRASP, OPEN. For each action α ∈ A, a corresponding set of lexical entries can be used to linguistically refer to α: we will denote such a set as L(α) C LA.
The action-dependent cost ωA for a transcription s ∈ H(ʋ) is thus given by:
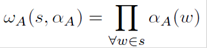 (4)
(4)
where αA(ω) is defined as:
 (5)
(5)
αA ∈ (0; 1] is a weight that favors words corresponding to actions that are in the repertoire of the robot. The weight αA can be either set as a subjective preference or tuned over a set of manually validated hypotheses. Note that if αA is set to 1, no action dependent constraint is applied and the corresponding cost is not triggered.
Entity-dependent cost. Exploiting environment observations can be beneficial in interpreting commands. Notice that the objects of the robot's environment are more likely to be referred by correct transcriptions rather than by the wrong ones, as these are usually "out of scope". Let G be the grammar designed for commands. Given the set of terminals of G, in the lexicon LG a specific set of terms is used to make (explicit) reference to objects of the environment. For each entity e (e.g., MOVABLE OBJECTS such as bottles, books,..., or FURNITURES, such as table or armchair) the set of nouns used to refer to e in the language LG is well defined, and it is denoted by L(e).
The entity-dependent cost ωE for a transcription s ∈ H(ʋ) is thus given by:
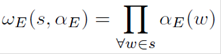 (6)
(6)
where αE(ω) is defined as:
 (7)
(7)
and αE ∈ (0; 1] is a weight that favors words corresponding to entities the robot is able to recognize in the environment. The weight αE can be either set as a subjective preference or tuned over a set of manually validated hypotheses. Also αE, when set to 1, produces no entity dependent constraint and corresponds to a null impact on the final cost.
IV. Experimental evaluations
The grammar employed in these evaluations has been designed in [19], lately improved in [2], and its definition is compliant to the Speech Recognition Grammar Specification [4]. The grammar takes into account 17 frames, each of which is evoked by an average of 2.6 lexical units. On average, for each frame 27.9 syntactic patterns are defined. Entities are clustered in 28 categories, with an average amount of items per cluster of 11.2 elements. We extracted an Actions Lexicon L(a) containing 44 different verbs. The Entities Lexicon L(e) is composed of 216 and 97 single and compound words, respectively, with a total amount of 313 entities. The dataset of the empirical evaluation is the HuRIC corpus1, a collection of utterances annotated with semantic predicates and paired with the corresponding audio file. HuRIC is composed of three different datasets, that display an increasing level of complexity in relationship with the grammar employed.
The Grammar Generated dataset (GG) contains sentences that have been generated by the above speech recognition grammar. The Speaky for Robot dataset (S4R) has been collected during the Speaky for Robots project2 and contains sentences for which the grammar has been designed, so that the grammar is supposed to recognize a significant number of utterances. While the grammar is expected to cover all the sentences in the GG dataset, this may be not true for the S4R one, as some sentences are characterized by linguistic structures not considered in the grammar definition. The Robocup dataset (RC) has been collected during the 2013 Robocup@Home competition [20] and it represents the most challenging section of the corpus, given its linguistic variability. In fact, even referring to the same house service robotics, it contains sentences not constrained by the grammar structure, as, during the acquisition process, speakers were allowed to say any kind of sentence related to the domain.
The experimental evaluation aimed at measuring the effectiveness of the approach we proposed. To this end, the cost function ω(s) has been used in different settings. The αi can be used to properly activate/deactivate the costs operating on specific evidences. In fact, if αi = 1, the corresponding cost is not triggered. However, whenever a cost is activated, its parameter has been estimated through 5-fold cross validation (with one fold for testing), as well as the θ smoothing parameter of the ranking cost ωrc. Performances have been measured in terms of Precision at 1 (P@1), that is the percentage of correctly transcribed sentences occupying the first position in the rank, and Word Error Rate (or WER). All audio files are analyzed through the official Google ASR APIs [21]. In order to reduce the evaluation bias to ASR errors, only those commands with an available solution within the 5 input candidates were retained for the experiments.
A. Experimental Results
Table I shows the mean and standard deviation of the P@1 and the WER across the 5 folds. The results have been obtained by testing our cost function on the aforementioned HuRIC corpus. The transcription have been gathered in January 2016. The sizes of the GG, S4R and RC datasets were of 100, 97 and 112 utterances, each paired with 5 transcriptions derived from the ASR system.
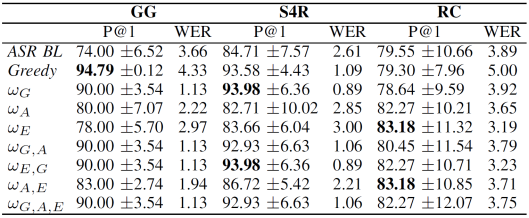
We compared our approach, where hypotheses are re-ranked according to our cost function ω(s), to two different baselines. In the first baseline (ASR BL), the best hypothesis is selected by following the initial guess given by the ASR, i.e., the transcription ranked in first position. The second baseline (Greedy) selects the first transcription, occurring within the list, that belongs to the language generated by the grammar. Conversely, the row ωG refers to the cost function setting when αA and αE are set to 1, i.e., just the cost ωG is actually triggered. In general, ωi,j,k refers to the cost function when the costs ωi, ωj and ωk are considered.
The Greedy approach seems to be effective when the sentences are more constrained by the grammar, i.e., it is likely that the correct transcription is recognized by the grammar. In fact, this approach is able to reach high scores of P@1 in both GG and S4R datasets, i.e., 94.79 and 93.58, respectively. Moreover, when the complete-grammar cost is triggered, i.e., ωG, ωG,A and ωG,A,E, we get comparable results, specially on the S4R dataset, with a relative increment of +10.94%. These observations do not apply for the RC dataset, where the structures and lexicon of the sentences are not constrained by the grammar. In fact, the complete-grammar cost does not seem to provide any actual improvement.
Conversely, we observe a drop of performance when the full constrained grammar is employed, i.e., both Greedy and ωG. On the other hand, when the action-dependent and entity-dependent costs are considered, we reach the best results. In particular, ωE and ωA,E are able to outperform both the ASR BL and the grammar constrained approaches. This behavior seems to depict a sort of scaling-down strategy: when the grammar does not fully cover the sentence, or it is not available, we can still rely on simpler, but more effective, information. Nevertheless, even though it does not perform the best, the strategy where all costs are triggered, i.e., ωG,A,E, seems to be the most stable across different sentence complexity conditions.
We conducted experiments on the transcription lists that have been employed in [14]. These have been gathered by relying on the same ASR engine, but almost two years earlier (May 2014). Hence, a different amount of sentences are employed in this experiment. In fact, the GG, S4R and RC datasets are composed of 51, 68 and 80 lists, respectively. The results are shown in Table II. We observe here similar trend, with both Greedy and complete-grammar cost reaching the highest scores in GG and S4R datasets. Even though the results obtained on these corpora are still comparable with the ones presented in [14], the interesting behavior observed on the RC dataset represents the main substantial difference. Even on this dataset, the trend seems to be the same, with the ωA,E outperforming any other approach with relative improvements in P@1 up to +20:06%. The trend of ωG,A,E is confirmed here, making it the best solution as the most stable approach.

V. Conclusions
In this work, we presented a practical approach to increase the robustness of an off-the-shelf free-form Automatic Speech Recognition (ASR) system in the context of Spoken Language Understanding for Human-Robot Interaction (HRI), relying on grammars designed over specific domains. In particular, a cost is assigned to each ASR transcription, that decreases along with the number of constraints satisfied by the sentence with respect to adopted grammar. Despite to the simplicity of the proposed method, experimental results show that the proposed method allows to significantly improve a state-of-the-art ASR system over a dataset of spoken commands for robots. Future work will consider the adoption of this re-ranking strategy within full chains of Spoken Language Understanding in the context of HRI, as the one presented in [5]. Moreover, the simple proposed method can be jointly used with supervised learning methods ([14]) that may exploit evidenced derived from the grammar to learn more expressive re-ranking functions.

