











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkI. Introduction
PERVASIVE denotes something "spreading throughout," thus a pervasive computing environment is the one that is spread throughout anytime anywhere and at any moment. From the computing science point of view what is interesting to analyze is how computing and software resources are available and provide services that can be accessed by different devices. For facilitating availability to these resources, they are wrapped under the same representation called service. A service is a resource handled by a provider, that exports an application programming interface (API). The API defines a set of method headers using an interface definition language. consider a scenario where multiple users evolve within an urban area carrying GPS-enabled mobile devices that periodically transmit their location. For instance, the users location is notified by a stream data service with the following (simplified) interface:
consisting of a subscription operation that, after invocation, will produce a stream of location tuples, each with a nickname that identifies the user and her coordinates. A stream is a continuous (and possibly infinite) sequence of tuples ordered in time.
The rest of the data is produced by the next two on-demand data services, each represented by a single operation:
The first provides a single person tuple denoting a profile of the user, once given a request represented by her nickname. The second produces, given the nickname as well, a list of s_tag tuples, each with a tag or keyword denoting a particular interest of the user (e.g. music, sports, fashion, etc.) and a score indicating the corresponding degree of interest.
Users access available services for answering some requirement expressed as a query. For instance, assume that Bob needs to find friends to make decisions whether he can meet somebody downtown to attend an art exposition. The query can be the following:
Find friends who are no more than
3 km away from me,
who are over 21 years old
and that are interested in art
But issuing the query from a mobile device, is not enough for evaluating it, some Service Level Agreements (SLA) need to also be expressed. For example, Bob wants the query to be executed as soon as possible, minimizing the battery consumption and preferring free data services.
Of course, the query cannot be solved by one service, some information will come for Google maps and Google location, other by Bob's personal directory, the availability of Bob's friend in their public agendas. Thus, the invocation to the different services must be coordinated by a program or script that will then be executed by an execution service that can be deployed locally on the user device or not. In order to do so, other key infrastructure services play an important role particularly for fulfilling SLA requirements. The communication service is maybe the most important one because it will make decisions on the data and invocation transmission strategies that will impact SLA.
Focussing on the infrastructure that makes it possible to execute the services coordination by making decisions on the best way to execute it according to given SLAs, we identify two main challenges:
- Enable the reliable coordination of services (infrastructure, platform and, data management) for answering queries.
- Deliver request results in an inexpensive, reliable, and efficient manner despite the devices, resources availability and the volume of data transmitted and processed.
Research on query processing is still promising given the explosion of huge amounts of data largely distributed and produced by different means (sensors, devices, networks, analysis processes), and the requirements to query them to have the right information, at the right place, at the right moment. This challenge implies composing services available in dynamic environments and integrating this notion into query processing techniques. Existing techniques do not tackle at the same time classic, mobile and continuous queries by composing services that are (push/pull, static and nomad) data providers.
Our research addresses novel challenges on data/services querying that go beyond existing results for efficiently exploiting data stemming from many different sources in dynamic environments. Coupling together services, data and streams with query processing considering dynamic environments and SLA issues is an important challenge in the database community that is partially addressed by some works. Having studied the problem in a general perspective led to the identification of theoretical and technical problems and to important and original contributions described as follows. Section II describes the phases of hybrid query evaluation, highlighting an algorithm that we propose for generating query workflows that implement hybrid queries expressed in the language HSQL that we proposed. Section III describes the optimization of hybrid queries based on service level agreement (SLA) contracts. Section V discusses related work and puts in perspective our work with existing approaches. Section VI concludes the paper and discusses future work.
II. Hybrid Query Evaluation
We consider queries issued against data services, i.e., services that make it possible to access different kinds of data. Several kinds of useful information can be obtained by evaluating queries over data services. In turn, the evaluation of these queries depends on our ability to perform various data processing tasks. For example, data correlation (e.g. relate the profile of a user with his/her interests) or data filtering (e.g. select users above a certain age). We must also take into consideration restrictions on the data, such as temporality (e.g. users logged-in within the last 60 minutes).
We denote by "hybrid queries" our vision of queries over dynamic environments, i.e. queries that can be mobile, continuous and evaluated on top of push/pull static or nomad services. For example, in a mobile application scenario, a user, say Mike, may want to Find friends who are no more than 3 km away from him, who are over 21 years old and that are interested in art. This query involves three data services methods defined above. It is highly desirable that such query can be expressed formally through a declarative language named Hybrid Service Query Language (HSQL)1. With this goal in mind we adopt a SQL-like query language which is similar to CQL [1], to express the query as follows:
SELECT p.nickname, p.age, p.sex, p.email
FROM profile p, location l [range 10 min],
interests i
WHERE p.age >= 21 AND
l.nickname = p.nickname AND
i.nickname = p.nickname AND
'art' in i.s_tag.tag
AND dist(l.coor, mycoor) <= 3000
The conditions in the WHERE clause enable to correlate profile, location, and interests of the users by their nickname, effectively specifying join operations between them. Additional conditions are specified to filter the data. Thus, users who are older than 21 and whose list of interests includes the tag 'art', and whose location lies within the specified limit are selected. For the location condition, we rely on a special function dist to evaluate the distance between two geographic points corresponding to the location of users, the current location of the user issuing the query is specified as mycoor. Since a list of scored tags is used to represent the interests of an user, we use a special in operator to determine if the tag 'art' is contained in the list, while the list in question is accessed via a path expression.
Since the location of the users is subject to change and delivered as a continuous stream, it is neither feasible nor desirable to process all of the location data, therefore temporal constraints must be added. Consequently, the location stream in the FROM clause is bounded by a time-based window which will consider only the data received within the last 10 minutes. Given that the query is continuous, this result will be updated as the users' location changes and new data arrives. This is facilitated by a special sign attribute added to each tuple of the result stream, which denotes whether the tuple is added to the result (positive sign) or removed from it (negative sign).
In order to evaluate a declarative hybrid query like the one presented in the example we need to derive an executable representation of it. Such executable representation in our approach is a query workflow.
A. Query Workflow
A workflow fundamentally enforces a certain order among various activities as required to carry out a particular task. The activities required to evaluate a hybrid query fall into two basic categories: data access and data processing. Both of these types of activities are organized in a workflow following a logical order determined by the query. The execution of each of the activities, in turn, is supported by a corresponding service; data access activities by data services and data processing activities by computation services.
Following our service-based approach, the workflow used to evaluate a hybrid query consists of the parallel and sequential coordination of data and computation services. For example, the workflow representation for the query in the example is depicted in Figure 1.
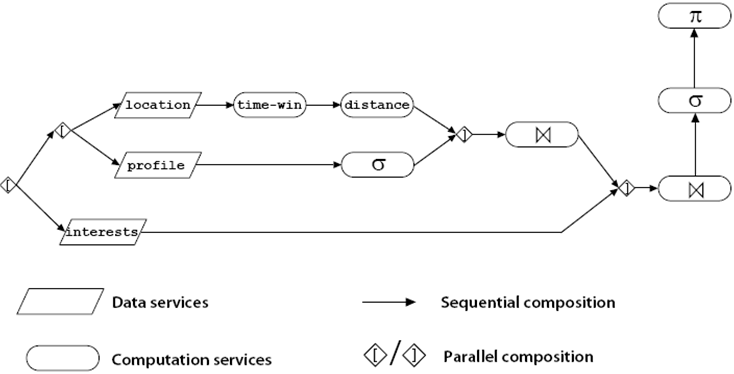
The data services are represented by parallelograms, whereas computation services are represented as rounded rectangles and correspond to traditional query operators such as join or selection. The arrows indicating sequential composition not only imply order dependencies among the activities but also data dependencies; in particular, tuples that need to be transmitted between the different activities that produce and consume them.
Since the workflow enabling the evaluation of a given hybrid query acts in fact as a service coordination (comprising data and computation services), we refer to it as query workflow. Evaluating a hybrid query from a given query coordination depends first on finding the adequate (data and computation) services, second on their invocation, and finally on their communication and interoperation.
B. Computing a Query Workflow Cost
In order to use SLA's to guide query workflows evaluation, it is necessary to propose a cost model that can be used to evaluate a query workflow cost. The query workflow cost is given by a combination of QoS measures associated to the service methods it calls2, infrastructure services such as the network and the hosting device it uses. The cost model considered for query workflows is defined by a combination of three costs: execution time, monetary cost and battery consumption. These costs are computed by calculating the cost of activities of a query workflow.
Query workflow cost: is computed by aggregating its activities costs based on its structure. The aggregation is done by following a systematic reduction of the query workflow such as in [2], [3]. For each sequential or parallel coordination, the reduction aggregates the activities costs. For the nested coordinations, the algorithm is applied recursively. The resulting cost is computed by a pondered average function of the three values.
We assume that the activity costs are estimated according to the way data are produced by the service (i.e., batch for on-demand services, continuous by continuous services).
Cost of an activity calling an on-demand service: For data produced in batch by on-demand services, the global activity cost is defined by the combination of three costs:
- Temporal cost given by (i) the speed of the network that yields transfer time consumption, determined by the data size and the network's conditions (i.e., latency and throughput) both for sending the invocation with its input data and receiving results; (ii) the execution of the invoked method has an associated approximated method response time which depends on the method throughput3.
- Economic cost given by (i) the type of network: indeed, transmitting data can add a monetary cost (e.g., 3G cost for mega octets transfer); (ii) the cost of receiving results from a service method invocation sent to a specific service provider, for example getting the scheduled activities from the public agenda of my Friends can have a cost related to a subscription fee.
- Energy cost produced as a result of using the network and computing resources in the device hosting the service provider that will execute the method called. These operations consume battery entailing an energy cost.
Cost of an activity calling a continuous service cost: For data produced by continuous services the global activity cost is defined by the combination of three costs that depend on the data production rate resulting from the invocation of a method. The costs are multiplied by the number of times data must be pulled and transferred. The economic cost can be associated to a subscription model where the cost is determined by the production rate. For example receiving data frequently (e.g., give my current position every five minutes, where five minutes is the expected production rate) can be more expensive than receiving data in specific moments (e.g., the number of times Bob went to the supermarket during a month). The temporal and energy costs are also determined by the frequency in which data are processed (processing rate): data can be processed immediately, after a threshold defined by the number of tuples received, or the elapsed time, or a buffer capacity. Both production rate and processing rate impact the execution time cost, execution economic cost, and battery consumption cost.
III. Optimizing Hybrid Queries Using SLA Contracts
Given a hybrid query and a set of services that can be used for answering it, several query workflows can be used for implementing it. For example, consider the query workflow in Figure 2a that is a version of the friend finder example. The figure shows a query workflow coordinating activities in parallel for retrieving the profile and the location datasets. Then, the filtering activity that implements a window operator is placed just after the activity that retrieves the location. This activity reduces the input dataset size. Then, both datasets are correlated and finally the last activity filters the dataset to get data related only to 'Joe'. Placing the last activity just after of the retrieval of the profile dataset can reduce the processing time.
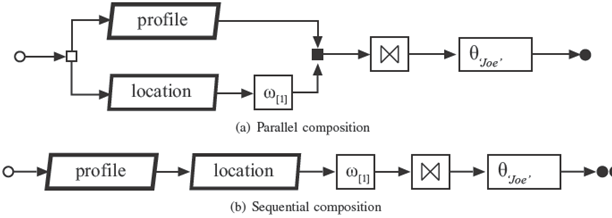
Now consider the query workflow in Figure 2b that coordinates activities sequentially. Each activity in the control flow consumes and produces data that at the end result in a dataset which is equivalent with the first one.
Optimizing a hybrid query implies choosing the query workflow that best implements it with respect to a given SLA. Similar to classic query optimization techniques, we propose an optimization process that consists in two phases: (i) generating its search space consisting in "all" the query workflows that implement a hybrid query and (ii) choosing the top-k query workflows with costs that are the closest to the SLA.
A. Generating Potential Query Workflow Space
We use rewriting operations (e.g. split, aggregate, parallelize, etc.) for generating a set of "semantically" equivalent query workflows The rewriting process is based on two notions: function and data dependency relationships.
- Function: represents a data processing operation. We consider the following functions:
1) fetch for retrieving a dataset from a data provision service (e.g., get Bob's friends);
2) projection of some of the attributes of each item (e.g., tuple) of a dataset (e.g., get name and location of Bob's friends assuming that there each friend has other attributes);
3) filter the items of a dataset according to some criterion (e.g. Alice's friends located 3 Km from her current position); and,
4) correlation of the items of two datasets according to some criterion (e.g., get friends shared by Bob and Alice that like "Art").
- Data dependency relationships between functions. Intu itively, given two functions with input parameters and an output of specific types, they are
1) F1 independent F2 if they do not share input datasets;
2) F1 concurrent F2 if they share common input datasets;
3) F1 dependent F2 if they use common input datasets.
We propose rewriting rules and algorithms for generating a representation of an HSQL expression as a composite function and a data dependency tree. This intermediate representation is used for finally generating a query workflow search space. This generation is based on composition patterns that we propose for specifying how to compose the activities of a query workflow. Let F1 and F2 be functions of any type according to their dependency relationship they can give rise to two activities A1 and A2 related according to the composition patterns shown in Figure 3.
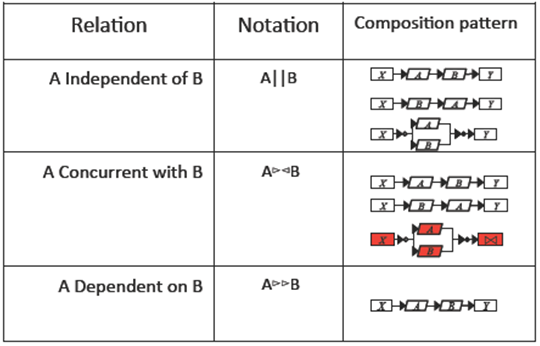
F1 independent F2 leads to three possible compo sition patterns: A1 sequence A2 or A1 sequence A2 or A1 parallel A2.
F1 concurrent F2 leads to the same sequential patterns of the previous case. In the case of the parallel pattern, it works only if and only if F1 and F2 are filtering functions or one of them is a filtering function and the other a correlation function.
F1 dependent F2 leads to a sequential composition pattern A1 sequence A2.
The search space generation algorithm ensures that the resulting query workflows are all deadlock free and that they terminate4. Once the search space has been generated, the query workflows are tagged with their associated three dimensional cost. Then, this space can be pruned in order to find the query workflows that best comply with the SLA expressing the preferences of the user. This is done applying a top-k algorithm as discussed in the following section.
B. Computing an Optimization Objective
In order to determine which are the query workflows that answer the query respecting the SLA contract, we compute an optimization objective taking as input the SLA preferences and assuming that we know all the potential data and computing services that can be used for computing a query workflow. The SLA expressed as a combination of pondered measures, namely, execution time, monetary cost and energy. Therefore we propose an equation to compute a threshold value that represents the lowest cost that a given query can have given a set of services available and required for executing it and independently of the form of the query workflow (see Equation 1).
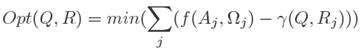 (1)
(1)
The objective is to find the combination of resources (R i.e., services) that satisfies a set of requirements (Q, i.e., the preferences expressed by the user and associated to a query). Every service participating in the execution of a query exports information about its available resources and used resources.
For example the number of requests that a service can handle and the number of requests that are currently being processes. The principle of the strategy is described as follows: determine to which extent the required resources by Q can be fulfilled by a the resources provided by each service. The total result represents the combination of resources provided by available services that minimize the use of the global available resources (A) and the resources currently being used (Ω).
As shown in Figure 4 this value can be represented as a point in an n dimensional space where each dimension represents a SLA measure. Similarly, as shown in Figure 4, the query workflows cost which is also defined as a function of these dimensions, can be represented as a point in such n-dimensional space. The optimization process looks for points that are closest to the objective point by computing the Euclidean distance.
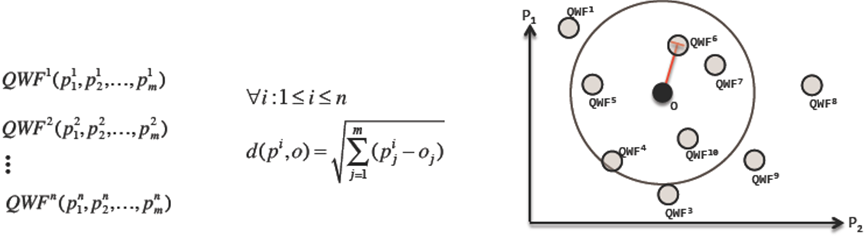
C. Choosing an Optimum Plan Family
We adopt a top-k; algorithm in order to decide which of the k query workflows that represent the best alternative to implement a hybrid query for a given SLA. We adopt the Fagin's algorithm [4]. The top-k; algorithm assumes m inverted lists L1,...,Lm each of which is of the form [...,(qwi, ci,j),...] with size |S| where i ∈ [1... |S|], and j ∈ [1...m]. The order of the inverted lists depends on the algorithm.
The Fagin algorithm assumes that each list Lj is ordered by ci, j in ascending order. The principle is that the k query workflows are close to the top of the m lists. In the worst case, the ck, j is the last item for some j ∈ [1, ...,m]. The algorithm traverses in parallel the m lists by performing sequential access. Once k items have been visited in all the m lists, it performs random access over the m lists by looking for the already visited items and computes their scores. The scores are arranged in a sorted list in ascending order and thus the first k items are on the top of the score list. The main steps of the algorithm are:
Access in parallel the m lists by performing sequential access.
Stop once k query workflows have been seen in the m lists.
Perform random access over the m lists to obtain the m scaled attributes of each query workflow that has been processed and compute its score.
Sort in ascending order the scores.
Return the k query workflows on the top.
It is applied for obtaining an ordered family of query workflows that compose the optimum plan family. According to a descending order, the first query workflow will be executed. The rest of the queries can be stored as knowledge and they can be used for further optimizations. We do not consider learning based optimization [5] but we believe that such a technique can be applied in this case.
IV. Implementation and Experiments
We developed a proof of concept of our approach by implementing a service-based hybrid query processor named HYPATIA for enacting query workflows. Figure 5 left side presents its architecture. The system is based on the Java platform. Queries in HYPATIA are entered via a GUI and specified in our HSQL query language. Once a query is provided to the system it is parsed and then its corresponding query workflow is generated according to the algorithm that we described in Section III-A. The query parser and the query workflow constructor components perform these tasks. The parser was developed using the ANTLR5 parser generator. The GUI also enables the user to visualize the query workflow, as well as the sub-workflows corresponding to composite computation services, which is facilitated by the use of the JGraph6 library.
To implement stream data services we developed a special-purpose stream server framework, which can be extended to create stream data services from sources ranging from text files to devices and network sources. This framework employs Web Service standards to create subscription services for the streams. Stream data access operators in query workflows subscribe to these services and also receive the stream via special gateway services.
The evaluation of a query is enabled by two main components that support the computation services corresponding to data processing operations. A scheduler determines which service is executed at a given time according to a predefined policy. Composite computation services communicate via asynchronous queues and are executed by an ASM interpreter that implements our workflow model.
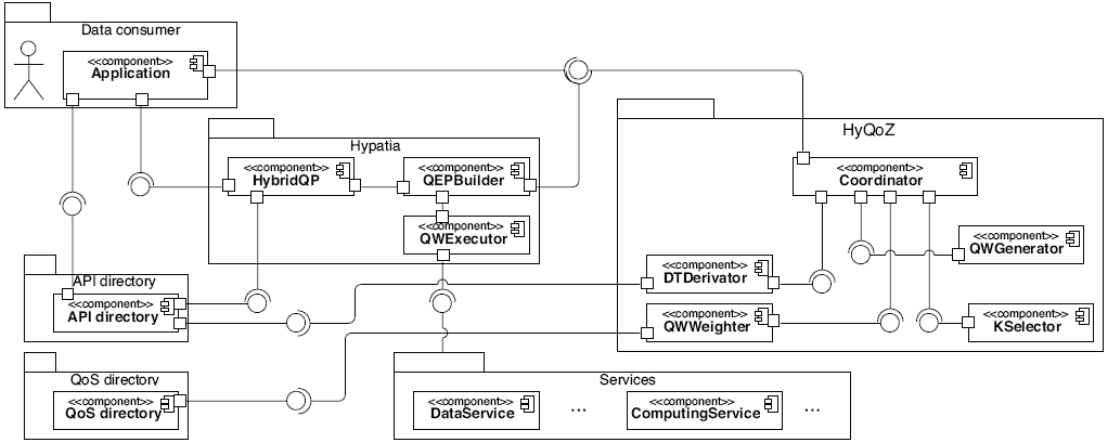
A. Hybird Query Optimizer
We implemented a HYbrid Query Optimizer (HyQoZ) that we integrated to the hybrid query evaluator HYPATIA. Figure 5 shows the component diagram for processing hybrid queries with HyQoZ. An application representing a data consumer expresses hybrid queries based on the information about service instances provided by the APIDirectory, and define the SLA to fulfill. Applications may require either the evaluation of the hybrid query or the optimum query wrkffow implementing the hybrid query for its further execution. In such cases applications request either the evaluator HYPATiAor the optimizer HyQoZ.
Its components are described by REST interfaces and they exchange self-descriptive messages. The messages instantiate different coordinations for implementing the hybrid queries optimization. The interfaces and messages turn our optimization approach self-contained.
- HYPATlAaccepts the hybrid query evaluation requests. HybridQP validates the expression according to the information provided by the APIDirectory. QEPBuilder derives the optimization objective from the SLA contract and requests the hybrid query optimization to HyQoZ. The resulting query workflow is executed by the QWExecutor.
- HYQoZaccepts hybrid query optimization requests and looks for the satisfaction of the optimization objectives derived from the SLA contracts. HYQoZis composed by a series of components that implement the optimization stages.
Internally, HYQoZis composed by a series of orthogonal components that together perform the optimization. Compo nents exchange self-descriptive messages carrying the required information for articulating the optimization.
B. Validation
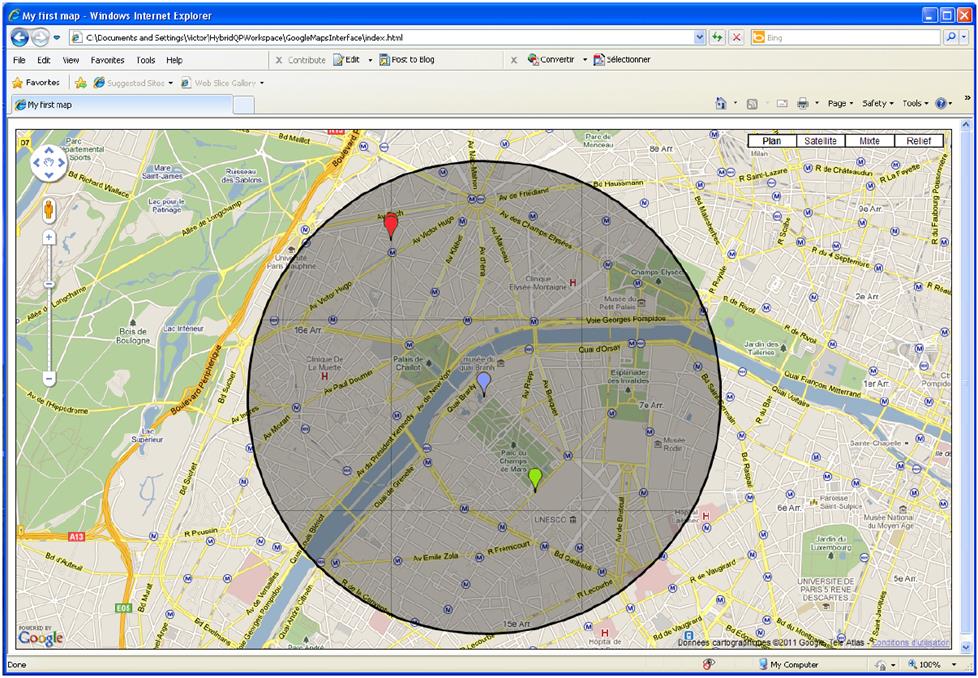
We implemented two test scenarios and their corresponding data services to validate our approach. The first one, mainly a demonstration scenario, is the location-based application. In order to implement the Friend Finder scenario described in the Introduction we developed a test dataset using GPS tracks obtained from everytrail.com. Concretely, we downloaded 58 tracks corresponding to travel (either by walking, cycling, or driving) within the city of Paris. We converted the data from GPX to JSON and integrated it to our stream server to create the location service. For the profile and interests services we created a MySQL database accessible via JAX-WS Web Services running on Tomcat. The profile data is artificial and the interests were assigned and scored randomly using the most popular tags used in Flickr and Amazon. For the nearest-neighbor (NN) points of interest we converted a KML file7 containing the major tourist destinations in Paris into JSON, this data is employed by the corresponding NN service in conjunction with the R-tree spatial indexation service. Finally, we implemented an interface based on Google Maps that enables to visualize the query result, which is presented in Figure 6.
The second scenario was developed to measure the efficiency of our current implementation in a more precise manner; it is based on the NEXMark benchmark8. Our main goal was to measure the overhead of using services, so we measured the total latency (i.e. the total time required to process a tuple present in the result) for a set of six queries (see Table I); first for our service-based system and then for an equivalent system that had at its disposal the same functionality offered by the computation services, but supported by objects inside the same Java Virtual Machine.

NEXMark proposes an auctions scenario consisting of three stream data services, person, auction and, bid, that export the following interfaces:
person: (person_idf, namef,phonef,emailf,incomef)
auction: (open_auction_idf, seller_personf, categoryf, cuantityf)
bid: (person_reff, open_auction_idf, bidf)
Auctions work as follows. People can propose and bid for products. Auctions and bids are produced continuously. Table I shows the six queries that we evaluated in our experiment; they are stated in our HSQL language and for each we provide the associated query workflow and equivalent operator expression that implements them (generated by Hypatia). Queries Q1 -Q2 mainly exploit temporal filtering using window operators, filtering and correlation with and/split-join like control flows. Q3 involves grouping and aggregation functions. Q4 adds a service call to a sequence of data processing activities with filtering and projection operations. Finally, Q5 - Q6 address several correlations organized in and/split-join control flows.
C. Experimental Results
For our experiments we used as a local machine a Dell D830 laptop with an Intel Core 2 Duo (2.10 GHz) processor and equipped with 2 GB of RAM. We also employed as a remote machine a Dell Desktop PC with a Pentium 4 (1.8 GHz) processor and 1 GB of RAM. In both cases running JSE 1.6.0_17, the local machine under Windows XP SP3 and the remote under Windows Server 2008.
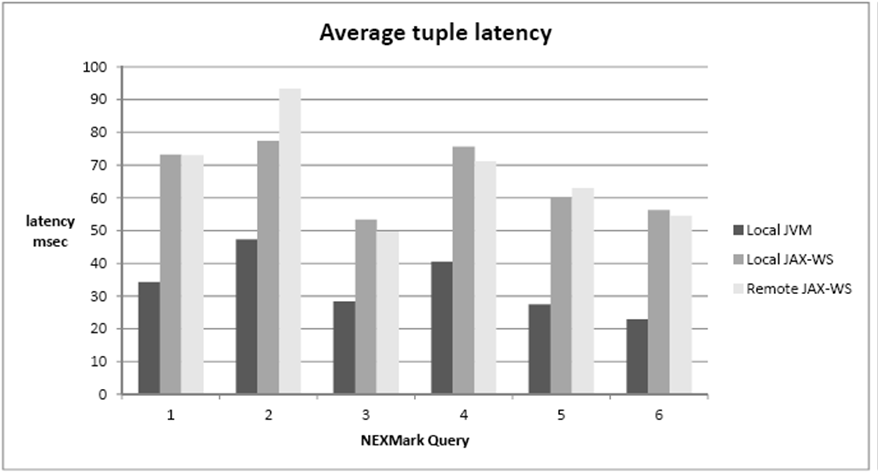
As said before, to validate our approach we established a testbed of six queries based on our adaptation of the NEXMark benchmark. These queries include operators such as time and tuple based windows as well as joins. We measured tuple latency, i.e. the time elapsed from the arrival of a tuple to the instant it becomes part of the result, for three different settings. The first setting corresponds to a query processor using the same functionality of our computation services, but as plain java objects in the same virtual machine. In the second we used our computation services, which are based on the JAX-WS reference implementation, by making them run on a Tomcat container in the same machine as the query processor. For the third setting we ran the Tomcat container with the computation services on a different machine connected via intranet to the machine running the query processor.
The results are shown in Figure 7, and from them we derive two main conclusions. First, the use of services instead of shared memory resulted in about twice the latency. Second, the main overhead is due to the middleware and not to the network connection, since the results for the local Tomcat container and the remote Tomcat container are very similar. We believe that in this case the network costs are balanced-out by resource contingency on the query processor machine, when that machine also runs the container. We consider the overhead to be important but not invalidating for our approach, especially since in some cases we may be obliged to use services to acquire the required functionality.
From our experimental validation we learned that it is possible to implement query evaluation entirely relying on services without necessarily using a full-fledged DBMS or a DSMS (Data Stream Management Systems). Thereby, hybrid queries that retrieve on demand and stream data are processed by the same evaluator using well adapted operators according to their characteristics given our composition approach. The approach can seem costly because of the absence of a single DBMS, the use of a message based approach for implementing the workflow execution, and because there is no extensive optimization in the current version of Hypatia. Now that we have a successful implementation of our approach, we can address performance issues further in order to reduce cost and overhead.
For validating HyQoZ, we developed the testbed that
generates synthetic hybrid queries,
generates the search space of query workflows following a data flow or control flow, and
estimates either the cost by means of a simulation using synthetic data statistics.
We used precision and recall measures to determine the proportion of interesting query workflows that are provided by the optimizer. The precision and recall are around 70% and 60% respectively.
V. Related Work
In dynamic environments, query processing has to be continuously executed as services collect periodically new information (e.g., traffic service providing information at given intervals about the current state of the road) and the execution context may change (e.g., variability in the connection). Query processing should take into account not only new data events but also data providers (services) which may change from one location to another.
Existing techniques for handling continuous spatio-temporal queries in location-aware environments (e.g., see [6, 7, 8, 9, 10, 11]) focus on developing specific high-level algorithms that use traditional database servers [12]. Most existing query processing techniques focus on solving special cases of continuous spatio-temporal queries: some like [8], [10], [11], [13] are valid only for moving queries on stationary objects, others like [14], [15] (Carney et al. 2002) are valid only for stationary range queries. A challenging perspective is to provide a complete approach that integrates flexibility into the existing continuous, stream, snapshot, spatio-temporal queries for accessing data in pervasive environments.
The emergence of data services has introduced a new interest in dealing with these "new" providers for expressing and evaluating queries. Languages as Pig and LinQ combine declarative expressions with imperative ones for programming queries, where data can be provided by services. In general, query rewriting, optimization and execution are the evaluation phases that need to be revisited when data are provided by services and they participate in queries that are executed in dynamic environments. Query rewriting must take into consideration the data service interfaces, since some data may need to be supplied to these in order to retrieve the rest of the data. The existence of a large number of heterogeneous data services may also necessitate the use of data integration techniques. In addition, new types of queries will require the definition of new query operators.
Traditional query optimization techniques are not applicable in this new setting, since the statistics used in cost models are generally not available. Furthermore, resources will be dynamically allocated via computation services, rather than being fixed and easy to monitor and control. Finally, query execution must also be reconsidered. First, the means to access the data is via services rather than scanning or employing index structures. Second, to process the data we depend on computation services, instead of a rigid DBMS.
The work [16] proposes a service coordination approach, where coordinations can optimized by ordering the service calls in a pipelined fashion and by tuning the data size. The control over data size (i.e., data chunks) and selectivity statistics are key assumptions adopted by the approach. Another aspect to consider during the optimization is the selection of services, which can have an impact on the service coordination cost. The authors of [3], [17] optimize service coordinations by proposing a strategy to select services according to multidimensional cost. Service selection is done by solving a multi objective assignment problem given a set of abstract services defined by the coordination. Services implementing the coordination can change but the control flow of the coordination remains the same.
The emergence of the map-reduce model, has introduced again parallelization techniques. Queries expressed in languages such as Pig9, and SCOPE [18] can be translated into map/reduce [19] workflows that can be optimized. The optimization is done by intra-operator parallelization of map/reduce tasks. The work [20] applies safe transformations to workflows for factorizing the map/reduce functions, partitioning of data, and reconfiguring functions. Transfor mations hold preconditions and postconditions associated to the functions in order to keep the data flow consistency. The functional programming model PACT [21] extends the map/reduce model to add expressiveness that are black boxes within a workflow. In [22] the black boxes are analyzed at build-time to get properties and to apply conservative reorderings to enhance the run-time cost. The map/reduce workflows satisfy the need to process large-scale data efficiently w.r.t. execution time. Although we do not address query optimization under such context in the present work, we provide a discussion of its related issues and possible solutions in [23].
VI. Conclusion and Future Work
This paper presented our approach for optimizing service coordinations implementing queries over data produced by data services either on-demand or continuously. Such queries are implemented by query workflows that coordinate data and computing services. The execution of query workflows has to respect Service Level Agreement contracts that define an optimization objective described by a vector of weighted cost attributes such as the price, the time, the energy. The weights define the preferences among the cost attributes for enabling the comparison among query workflows. Our approach for generating the search space of query workflows that can optimize service coordinations, the cost estimation, and the solution space are oriented to satisfy SLA contracts.

