











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkI. Introducción
EN las pasadas dos décadas, la transformada wavelets se convirtió en una herramienta popular y poderosa para diferentes aplicaciones de procesamiento señales/imágenes como cancelación del ruido, detección de rasgos, compresión de datos, etc. No obstante, todavía se presenta el problema de selección adecuada o diseño de wavelet para un problema dado. A diferencia de muchas transformadas ortogonales, la transformada wavelets puede usar diferentes funciones de base, y es importante que la base seleccionada dé la mejor representación de la señal analizada. Por ejemplo, en aplicaciones de detección de señales donde la transformada wavelets calcula la correlación cruzada entre la señal y wavelet, la wavelet acomodada para la señal resulta en un pico grande en el dominio de la transformada. En las aplicaciones de compresión de señales, el acoplamiento de wavelet y señal resulta en una mejor representación de la señal, y por ello, en el nivel de compresión más alto.
La técnica estándar para encontrar bases ortonormales de wavelets con soporte compacto es de Daubechies [1], y en el caso de bases biortogonales la solución clásica para wavelets de soporte compacto y regularidad arbitraria fue dada por Cohen, Daubechies y Feauveau en [2]. Desafortunadamente, estas técnicas no son prácticas por su complejidad e independencia de la señal analizada.
A. Tewfik et al. en [3] propuso el primer método para encontrar las bases wavelets ortonormales óptimas para señales de voz usando su parametrización. Este método se limita a un número finito de escalas y la optimización se realiza en el dominio de tiempo, de una manera recurrida.
Otras técnicas existentes no tratan de diseñar la wavelet directamente, algunas de ellas a diferencia usan un banco de las wavelets diseñadas previamente [4], algunos métodos acoplan las wavelets a la señal proyectándola a las wavelets existentes o transformando las bases de wavelets [5].
Entre técnicas recientes de acoplamiento de wavelets más interesantes se encuentran propuestas por Chapa y Rao [6] A. Gupta et al. [7]. En [6], los autores adaptan la wavelet generalizada de Meyer, minimizando la diferencia entre la wavelet y espectro de la señal, pero su método es complejo computacionalmente porque requiere una sincronización de fase, y es diseñado sólo para la detección de señales determinísticas. En [7], el método para estimación de filtros pasa altas de análisis wavelets se propone para señales que representan procesos similares de sí mismos y cuya autocorrelación se puede modelar analíticamente usando el índice de similitud propia. Aunque los autores afirman que su método es simple, se requiere un estimador de máxima verosimilitud del índice de similitud propia; además. Este método generalmente produce bancos de filtros que no tienen la propiedad de restauración perfecta de la señal.
En este artículo, se considera la aplicación de la transformada discreta wavelets para la compresión de imágenes sin pérdidas de información. Para tal aplicación, ampliamente se usa la transformada rápida wavelets que se implementa con esquema lifting propuesta por W. Sweldens [8], como un método estándar para la transformada de números enteros [9]. Los usados en el esquema lifting filtros wavelets se obtienen de los filtros de wavelets biortogonales conocidos factorizando las matrices polifase [8, 10]. Para la compresión sin pérdidas de imagines digitales, los más populares son filtros de lifting de un solo paso CDF (2,2) y CDF (4,4) [9].
Se conocen varias pruebas de mejorar el rendimiento de la compresión de imágenes sin pérdidas ajustando parámetros de filtros lifting, ya que estos filtros son fáciles de modificar obteniendo así la restauración perfecta de la imagen original [11-15]. Como regla, los autores de estos trabajos tratan de optimizar el filtro predictor lifting minimizando el error cuadrático promedio de predicción en la salida, minimizando así la energía de los coeficientes en el dominio de la transformada. Con ello, autores [11, 12, 14] obtienen (a veces, dependiendo de los datos) unos resultados positivos combinando con otras mejoras, pero H. Thielemann [13] reportó resultados negativos de la optimización de mínimos cuadrados en comparación con el rendimiento de filtros lifting CDF (2,2). Es interesante destacar, que la técnica propuesta en [14] optimiza el predictor lifting con el mismo criterio del error cuadrático promedio de predicción pero haciendo uso de diferencias de señal para calcular la autocorrelación sobre estas diferencias y no sobre la señal misma que es la técnica de cálculo estándar.
Una alternativa a la optimización minimizando el error cuadrático promedio fue propuesta en [15], donde la minimización del error de predicción se realiza usando norma l1 en lugar de norma l2 , en otras palabras, minimizando el valor absoluto del error en lugar de energía del error. Además, los autores de este artículo propusieron minimizar la norma l2 de la diferencia entre aproximaciones de señal en la salida del filtro lifting de renovación y la salida del filtro ideal pasa bajas. Desafortunadamente, la minimización de norma l1 es mucho más compleja que la minimización de norma l2 y requiere técnicas sofisticadas. Los autores consideraron el caso de compresión de imagines sin perdidas, y los resultados obtenidos muestran comportamiento un poco mejor comparando con los filtros lifting CDF (2,2). Por otra parte, la complejidad del algoritmo lifting adaptativo es muy alta.
En el presente artículo, nosotros proponemos usar técnicas de inteligencia artificial para mejorar el rendimiento de los filtros wavelets lifting; se propone desarrollar un modelo para el diseño automático de filtros wavelet para la compresión de imágenes sin pérdidas. Por lo tanto, en este artículo nosotros consideramos la aplicación de los algoritmos de clasificación de patrones como 1-NN, para clasificar de una manera global los coeficientes espectrales de cada imagen a comprimir en el dominio de la transformada discreta de coseno. Como resultado; se obtienen los coeficientes para filtros wavelet lifting de predicción y de renovación que realizan la transformada wavelets de las imágenes obteniéndose la tasa de compresión sin pérdidas, mayor que producen los filtros wavelets lifting estándares CDF (2,2) y CDF (4,4).
Este artículo está organizado de la siguiente forma: En la sección 2 se describe la generalización del esquema lifting, de la cual se formulan las condiciones necesarias para las modificaciones de los coeficientes de filtros wavelet lifting. En la sección 3 se describe la generalización del método de reconocimiento de patrones K-NN. En la sección 4 se presenta el método propuesto con el cual se obtienen los coeficientes del esquema lifting para la transformada wavelet discreta. En la sección 5 se muestran los resultados obtenidos para el conjunto inicial de las diferentes imágenes iniciales de prueba. Para terminar con las conclusiones en la sección 6.
II. Generalización del Esquema Lifting
El algoritmo clásico de la transformada discreta wavelets (DWT) de banco de filtros de Vetterli-Mallat [16] [17] [18] para la descomposición y reconstrucción de una señal de 1 etapa puede ser descrito como sigue: la señal de entrada de una dimensión (1D) es filtrada y sobremuestreada siendo descompuesta en dos partes: una señal pasa-baja (LP) y una señal pasa-alta (HP). En el caso de la descomposición de una imagen, los pasos de procesamiento usando un algoritmo compuesto de un banco de filtros se representa por el esquema de descomposición subbanda y se describen como:
aplicar los filtros LP y HP, submuestreando sobre las filas;
la señal que fue filtrada sobre las filas, es pasada a través de dos filtros de 1D, un LP y un HP y submuestreada sobre las columnas.
Con ello, se obtienen los 4 cuadrantes de los coeficientes de la imagen transformada: 3 cuadrantes de los detalles horizontales, verticales y diagonales. Y el cuadrante que corresponde a la señal pasada por dos filtros LP, de filas y columnas, son aproximaciones y sirve como entrada para otro nivel de descomposición; tal procedimiento se repite hasta que el tamaño de aproximaciones alcanza el tamaño de los filtros LP o HP.
En el caso de la transformada rápida wavelets, o transformada wavelets lifting, la descomposición de una señal discreta de 1D s={sk}, k=1,...,N y la wavelet más sencilla, la wavelet de Haar puede ser descrita como sigue [8] [19]:
La primera etapa consiste en dividir la señal s en muestras pares e impares: {dj} y {ej }. Durante la segunda etapa, la predicción, las muestras impares son predichas usando interpolación lineal, como sigue:
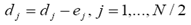 (1)
(1)
Durante la tercera etapa las muestras pares son actualizadas también con el fin de preservar el valor promedio de las muestras. Para esto se usa la siguiente expresión:
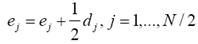 (2)
(2)
Los próximos niveles de descomposición de la DWT son obtenidos aplicando el esquema de lifting a los datos actualizados {ek }de la señal original.
La transformada inversa para el esquema lifting para nuestro ejemplo es como sigue:
- actualización de datos inversa:
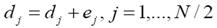 (3)
(3)
- predicción inversa:
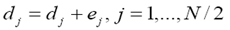 (4)
(4)
- composición de la señal de salida:
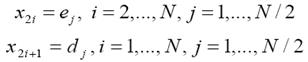 (5)
(5)
El ejemplo considerado presenta el esquema lifting de un nivel de descomposición y reconstrucción de la señal para la bien conocida wavelet Haar, también conocida como la wavelet de Cohen-Daubechies-Feauveau de primer orden con un momento de desvanecimiento, o CDF (1,1) [2]. La forma wavelet más popular para la compresión de imágenes sin pérdidas de información de este tipo es la CDF (2,2), la cual posee dos momentos desvanecidos para ambas la wavelet primitiva y la wavelet dual. Las etapas de predicción y actualización de los datos del esquema lifting para el caso de wavelet CDF (2,2) de números enteros son las siguientes [9]:
 (6)
(6)
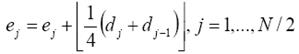 (7)
(7)
donde ⎣·⎦ denota la operación del redondeo al número entero más cercano [9]. Para la síntesis de la señal original, las sumas se cambian por restas, y restas por sumas.
Como fue mencionado anteriormente, la ventaja principal del esquema lifting es que se requieren 2 veces menos operaciones que el algoritmo clásico de banco de filtros. Además, el esquema lifting permite redondear los valores en las etapas de predicción y actualización de datos. Esto permite operar con números enteros, lo cual es importante para las aplicaciones de compresión de datos sin pérdidas de información.
Las funciones de transferencia correspondientes de filtros lifting de orden (4,4) se pueden escribir, como:
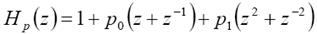 (8)
(8)
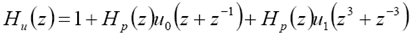 (9)
(9)
El filtro de la ecuación (8) es el filtro de predicción lifting, entonces, es un filtro pasa altas que tiene que cumplir con la condición de tener un cero el punto z = 1 del plano complejo Z que corresponde a la frecuencia ω = 0 [20]. Esto significa, que la condición de admisibilidad los filtros wavelet lifting de predicción es:
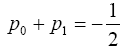 (10)
(10) Con los valores de {pi} que cumplen la condición
 (11)
(11)
 (12)
(12)
Lo que significa, que el filtro de predicción tiene ganancia 2 en la frecuencia más alta ω = π y una ganancia unitaria en la frecuencia
Siguiendo la técnica del análisis considerada, los coeficientes del filtro de la actualización, que es un filtro paso bajas, se pueden encontrar. De esta manera, el filtro paso bajas Hu(z) debe tener un cero en el punto z = -1 del plano complejo Z que corresponde a la frecuencia ω = π [20]. Esta condición se cumple cuando:
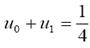 (13)
(13)
La ecuación anterior (13) es la condición de admisibilidad para los filtros escala lifting (filtros de actualización, o renovación). Cuando los coeficientes del filtro H u(z) satisfacen la condición (13), entonces, Hu(1)|z=1=1 lo que significa que el filtro tiene ganancia unitaria en la frecuencia ω = 0.
Una simplificación elegante de fórmulas (10) y (13), para el caso de lifting de orden (4,4) se propuso en [21]. Las fórmulas para los coeficientes de filtros wavelet se muestran a continuación:
 (14)
(14)
 (15)
(15)
Donde a y b son los parámetros que controlan las propiedades de la transformada wavelet. También, en [21] se encontró la correspondencia entre estos parámetros de control y los filtros wavelet convencionales (que no usan lifting). Con esta correspondencia, los filtros estándar CDF(2,2) tienen coeficientes con valores a = 0 y b = 0, y los coeficientes de los filtros CDF(4,4) son a = 16 y b = 8. Tal caracterización de cada filtro wavelet por un solo coeficiente entero permita guardar estos coeficientes junto con los datos de imagen sin incrementar mucho el tamaño del archivo resultante.
III. Clasificador k-NN
El método de k vecinos más cercanos (k-NN) [22] es un método de clasificación supervisada [23]. El método K-NN es uno de los algoritmos de clasificación más eficientes y a la vez más simples que existen; este algoritmo está basado en el enfoque de métricas y está fundado en la suposición de que los patrones cercanos entre si pertenecen a la misma clase y por ello un nuevo patrón a clasificar se determina la proximidad de este patrón por medio de alguna medida de similitud. Generalmente, se usa la distancia Euclidiana, y se va calculando la distancia con respecto a los n patrones ya existentes dentro del conjunto fundamental. se clasifica a la clase del patrón k más cercano, donde k es un entero positivo generalmente impar. Desde los artículos pioneros de este método hasta modificaciones al método original como los presentados en [24], [25], [26], [27], [28] en los cuales se presentan variación del método original o la combinación de clasificadores. Los cuales han demostrado en las diferentes aplicaciones que se ha utilizado este método, que es uno de más eficientes que existen para el reconocimiento y clasificación de patrones.
El algoritmo a seguir para k =1 es el siguiente:
Se escoge una métrica a utilizar (normalmente la Euclidiana).
Se calculan las distancias de un patrón x desconocido por clasificar, a cada uno de los patrones del conjunto fundamental.
Se obtiene la distancia mínima.
Se asigna al patrón x la clase del patrón con la mínima distancia.
Cuando se usa un k mayor a 1, se sigue el mismo procedimiento antes descrito, tan solo que para asignar la clase del patrón a clasificar se usa la regla de mayoreo.
IV. Modelo propuesto de la compresión de imágenes
En esta sección se describirá de forma general el método propuesto y los pasos para la obtención automática de los coeficientes de los filtros wavelets.
El método propuesto se puede describir por los pasos del algoritmo:
Primer paso del algoritmo propuesto es calcular el espectro de potencia de la imagen adquirida.
En el siguiente paso, el espectro se analiza usando técnicas de inteligencia artificial, para obtener los coeficientes de los filtros wavelets lifting.
Teniendo ya los coeficientes de los filtros wavelets se aplica la transformada discreta wavelet lifting, la cual permita reducir la entropía de los datos.
Finalmente, la imagen transformada se procesa con una de las técnicas existentes de búsqueda de los árboles de los coeficientes wavelets diferentes de cero [29] y se codifica con uno de los codificadores de entropía existentes [30].
En la etapa 4 se realiza el propio proceso de compresión de la imagen, pero en el presente artículo nosotros concentraremos más en los pasos 1) - 3).
El primer paso del algoritmo propuesto es aplicar a la imagen analizada s de tamaño M x N la transformada discreta del coseno (DCT) [20], para obtener el espectro de potencia promediado, como:
 (16)
(16)
donde: M es el número de filas y N es número de columnas que contenga la imagen a procesar,
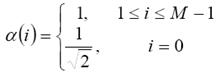
Posteriormente se obtiene el vector resultante xi , interpolado para tener longitud fija de 16 elementos:
 (17)
(17)
donde
Con ello se obtiene el vector característico y reducido x de la imagen. Con este vector se va generando el método de aprendizaje y clasificación utilizando el clasificador 1-NN, en conjunto con los coeficientes de los filtros wavelets previamente seleccionados por la búsqueda exhaustiva.
Los coeficientes utilizados para la generación de los patrones para entrenamiento de clasificación y recuperación son los coeficientes de filtros wavelets lifting de predicción y renovación (8), (9), obtenidos variando coeficientes a, b de la generalización de filtros usada (14), (15). Los coeficientes a, b para formar el conjunto de patrones de entrenamiento fueron obtenidos con la búsqueda exhaustiva de los coeficientes a, b óptimos con el criterio de mínima entropía de tren de bits de datos en el dominio de transformada wavelet; está métrica fue propuesta en [9] para comparar diferentes algoritmos de compresión sin pérdidas:
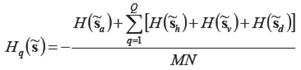 (18)
(18)
donde
 (19)
(19)
donde
Ya con el vector característico y los coeficientes de los filtros se va generando la memoria M para su aprendizaje. La fase de aprendizaje se muestra de forma general en la Figura 1, donde x representa a los patrones espectrales de las imágenes y y a los coeficientes a, b correspondientes. En esta fase es donde se va asociando los coeficientes obtenidos de forma empírica y los patrones obtenidos con el modelo propuesto. El diagrama de la fase de recuperación se muestra en la Figura 2.

En esta fase es donde se va clasificando los patrones que se le presentan a la memoria M para obtener de forma automática los coeficientes de los filtros wavelets, para su empleo en la compresión de imágenes.
V. Resultados
En este capítulo se presentan los resultados obtenidos de aplicar el método anteriormente descrito, los experimentos que se desarrollaron fueron usando un conjunto fundamental de 30 imágenes, algunas de ellas se muestran en la Figura 3. Cabe mencionar que las imágenes son de diferentes tamaños como por ejemplo 2048 x 2560, 1524 x 1200, 1465 x 1999, 1024 x 1024 y 512 x 512 pixeles, y todas son en escala de gris de 8 bits por pixel.

Fig. 3 Imágenes naturales de prueba: Tiffany, baboon, peppers, man, couple, Lenna, sailboat, gold, f-16, Tiffany, hotel, tools.
Dentro del conjunto fundamental de imágenes también se usaron imágenes artificiales o con cierto retoque como se muestra la Figura 4.

Para la clasificación se usó la memoria generada M, y para poder comparar los resultados con esta memoria se realizaron los experimentos utilizando el clasificador 1-NN. Los resultados obtenidos muestran que con este clasificador las imágenes de prueba dentro del conjunto fundamental presentaron un 100% de rendimiento, es decir se clasificaron correctamente el total de las imágenes del conjunto fundamental.
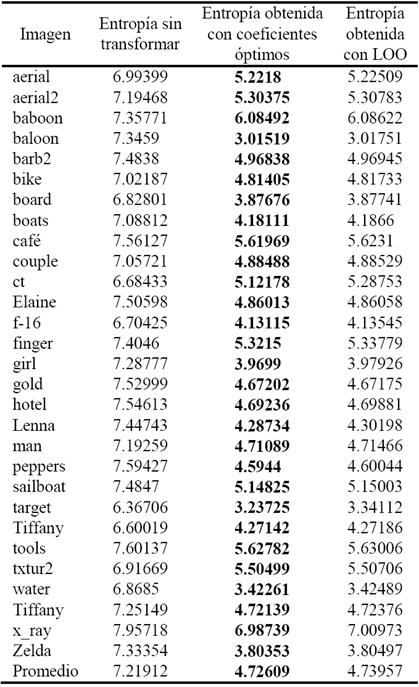
Para realizar un estudio comparativo de los resultados obtenidos contra los métodos ya establecidos, se utiliza un comparativo de la entropía de shannon entre las imágenes originales (del conjunto fundamental) contra la entropía obtenida con el método presentado. Utilizando la técnica de Leave-One-Out (LOO) [31] para la validación del conjunto fundamental se obtuvieron los resultados que se muestran en la Tabla comparativa número 1, donde se presenta los resultados de entropía de la imagen sin transformar y la entropía obtenida con los coeficientes óptimos así como con la técnica LOO para cada imagen del conjunto fundamental.
Tabla I Resultados de compresión de imágenes de prueba (bits/pixel). Los mejores resultados se marcan con la letra negrita.
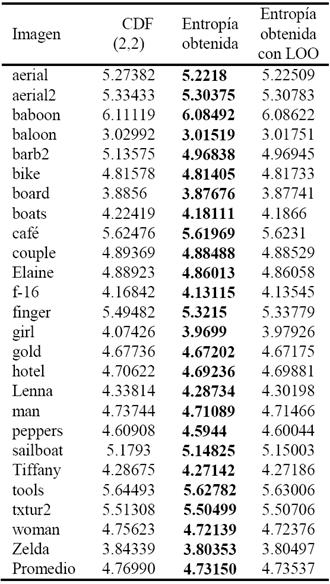
Con estos resultados se procedió a realizar el proceso de compresión del conjunto fundamental y la obtención de la entropía de cada imagen, para su comparativo contra la entropía obtenida por los filtros estándares de la familia de wavelets CDF. En la Tabla 2 se realiza un comparativo del filtro CDF (2,2) contra la entropía de imágenes comprimidas con el modelo propuesto. se puede ver que en un 100% de mejoría del método propuesto con respecto a los resultados obtenidos con el filtro CDF (2,2) y el promedio total del conjunto fundamental es menor con el método presentado.
Tabla II Resultados de experimentos con CDF (2,2) vs técnica propuesta (bits/pixel). Los mejores resultados se marcan con la letra negrita.
En la Tabla 3 se muestra el estudio comparativo con el filtro CDF (4,4) y el método presentado. Se puede ver que el estudio comparativo se tiene un 100% de mejora contra los resultados obtenidos por el filtro clásico CDF (4,4), esta mejora es para cada imagen del conjunto fundamental así como también se mejora la entropía promedio del conjunto general de las imágenes.
Tabla III Resultados de experimentos con CDF (4,4) vs técnica propuesta (bits/pixel). Los mejores resultados se marcan con la letra negrita.

Como se puede apreciar, el método propuesto es competitivo contra los métodos ya establecidos dentro de la literatura en el caso de imágenes naturales usando coeficientes óptimos globales para cada imagen.
VI. Conclusiones
Se desarrolló un modelo de generación automática de coeficientes para filtros wavelets analizando las propiedades espectrales de las imágenes en el dominio de la transformada DCT y usando modelos de inteligencia artificial, específicamente, 1 -NN, el cual se demostró ser competitivo contra los modelos ya establecidos dentro de la bibliografía.
Se probó el algoritmo desarrollado con diferentes datos de imágenes para la compresión sin pérdidas y se comparó con los resultados obtenidos con las técnicas existentes, encontrándose y demostrándose las bondades de la aportación descrita en el presente trabajo. se obtuvo una mejor compresión de las diferentes imágenes con relación a la entropía obtenida, que es competitiva contra los filtros de la familia CDF(2,2) y CDF(4,4) en imágenes naturales.
Cabe señalar que el método propuesto utiliza los coeficientes a,b óptimos globales para cada imagen; por otra parte, se pueden encontrar los coeficientes a,b óptimos para cada cuadrante de descomposición wavelets, y con ello realizar clasificación a nivel de cada cuadrante de descomposiciones para obtener así el nivel de compresión aún más alto. En mismo tiempo, la mejor técnica para algunas imágenes artificiales fue CDF(2,2), que significa que el modelo propuesto debe de tener la entrada de un parámetro de "artificialidad en los datos" para una mejor clasificación de coeficientes a,b. Estas mejoras pueden ser el objetivo del trabajo futuro.

