











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
En los mercados financieros, los inversionistas se encuentran expuestos a un sinnúmero de riesgos entre los que se encuentran el riesgo de crédito, riesgo operacional, riesgo de liquidez y riesgo de mercado entre otros. Si bien, estos riesgos son objeto de estudio por parte del mercado, se hace necesario conocer las diferentes metodologías de estimación del valor en riesgo en distintos marcos de tiempo; para tal efecto, se presenta un análisis comparativo de las metodologías de estimación semiparamétricas y vine cópulas del valor en riesgo (VaR) del mercado de renta variable en Colombia para el período 2015-2017.
Las metodologías por desarrollar son no convencionales debido a que, tradicionalmente el sistema financiero ha venido utilizando en la estimación del VaR (Valor en Riesgo): la simulación histórica y montecarlo entre otras, las cuales no toman en cuenta la dependencia no lineal entre los datos causando varios problemas en la gestión de riesgos.
Consecuencia de lo anterior, se hace una breve revisión teórica a nivel nacional como internacional de los principales expositores que han abordado el estudio del valor en riesgo bajo las diferentes metodologías. Posteriormente se hace un análisis teórico de las metodologías semiparamétricas y vine cópulas para finalizar con un trabajo aplicado al mercado de renta variable colombiano utilizando las metodologías no convencionales de estimación del VaR.
2. Literatura Nacional e Internacional
En Colombia, la estimación del valor en riesgo en activos financieros ha sido impuesta a las entidades financieras, quienes han venido asumiendo está medición a través de la implementación de la circular básica contable y financiera de la Superintendencia Financiera No XXI (Supefinanciera, 2007).
En lo que atañe a la medición del VaR, de acuerdo con, las directrices de la Superfinanciera, ha sido sujeta a críticas por parte de las entidades financieras, quienes ven este procedimiento, un poco alejado de la realidad en la medida en que los eventos de los últimos años se ha caracterizado por altos niveles de volatilidad, que han generado pérdida de credibilidad en su estimación; por lo tanto, las estimaciones que han realizado o vienen realizando las entidades distan de lo que está sucediendo en la realidad (Caicedo & Enrique, 2014).
De conformidad con lo anterior, se hace necesario explicitar otro tipo de metodologías que se alejen de lo convencional y que de alguna manera expongan mejor la realidad del mercado de renta variable colombiano.
2.1 Literatura Internacional
Los autores que han aportado en la construcción de metodologías no convencionales en la estimación del valor en riesgo (VaR) son los siguientes:
1) Thomas Breuer, quien facilitó la conceptualización y las metodologías matemáticas para la utilización de la teoría del valor extremo (EVT), valor extremo condicional (EVC) y valores extremos en modelos con volatilidad (Feria, J & Oliver, M, 2006).
2) Mathias Hofmann y Claudia Czado, proponen el uso de VineCopulas utilizando estimaciones bayesianas para modelos de tipo GARCH multivariado en la estimación del valor en riesgo (Hofmann, M & Czado, C, 2011).
3) Jostein Larsen Benterud, Magnus Solli Haukaas y Paul Ingebrigt Huse, proponen el uso del modelado de vine-cópulas para describir el comportamiento de modelos de riesgo comparando las estimaciones en el valor en riesgo con las metodologías clásicas (Larsen, J; Solli M & Ingebrigt P, 2013).
2.2 Literatura Nacional
En la literatura local los autores que han estudiado la estimación del riesgo de mercado son las siguientes:
1) Luis Fernando Melo y Oscar Becerra Camargo proponen una estimación del VaR para la tasa interbancaria de Colombia utilizando metodologías ARMA-GARCH-EVT en donde identifican las técnicas con mejor y peor desempeño en la estimación (Melo V, Luis Becerra C, Oscar, 2005).
2) Daniel Mariño Ustacara y Luis Fernando Melo proponen la utilización de métodos semiparamétricos mediante el uso de la regresión cuantílica lineal y no lineal comparándolas con las técnicas tradicionales para la estimación del VaR en activos financieros (Mariño, D Melo, L, 2016).
3) Pamela Cardozo propone la estimación del valor en riesgo en activos financieros utilizando la metodología de la teoría del valor extremo en la estimación del VaR comparándola con el método delta-normal. (Cardozo, 2004).
A continuación, se exponen los métodos no clásicos de estimación del valor en riesgo a nivel teórico:
3. Metodologías semiparamétricas y Vine cópulas
El cálculo del VaR frecuentemente necesita del modelamiento de la volatilidad de los retornos de los activos financieros por medio de metodologías que asumen distribuciones sobre el logaritmo de los retornos de los precios de los activos (metodologías perimétricas), y aquellas metodologías que no asumen ningún tipo de comportamiento para los retornos. Las metodologías semi-paramétricas permiten la flexibilidad para adaptar las técnicas de estimación a los movimientos dinámicos del mercado (Melo V, Luis Becerra C, Oscar, 2005)
3.1 Estimación del VaR usando la Teoría de Valor Extremo (EVT)
Esta metodología, parte de asumir dependencia en el cálculo del VaR, tomando en cuenta eventos extremos como son la dependencia en las colas de distribución. Este método es uno de los más acertados para estimar el VaR, al contar con soluciones para generar decaimientos en la heterocedasticidad, y correlación serial dada por modelos de tipo GARCH multivariado (Mariño, D Melo, L, 2016).
La teoría del valor extremo nació como uno de las disciplinas más grandes en la estadística aplicada en los últimos 50 años, por su capacidad para cuantificar la conducta de procesos a niveles grandes o pequeños. (Cardozo, 2004)
Los indicios de la estimación del valor en riesgo a través del EVT buscan de algún modo, cuantificar el comportamiento de las pérdidas a través de la probabilidad mediante el análisis del comportamiento de las colas de la distribución de los retornos dados por un portafolio de inversión. Este método semiparamétrico, proporciona medidas más fuertes en cuanto a las colas de la distribución de los retornos obtenidos mediante comportamientos extremos en los datos, que no solucionan las medidas paramétricas y no paramétricas.
La EVT ofrece un buen modelado de los datos utilizando el comportamiento extremo de las colas de las distribuciones de pérdidas asociadas a las observaciones a través de estimaciones con asociaciones paramétricas que permiten encontrar la cola de la distribución.
Según (Fernandez, 2003) el comportamiento actual de la EVT está basado en el identificar momentos estadísticos de los retornos de un portafolio de inversión, así como el cálculo de la distribución de los retornos financieros; sin embargo, para este trabajo se centrará en el cálculo de aplicaciones multivariadas en la estimación del valor en riesgo.
La teoría del valor extremo parte de los siguientes supuestos y condiciones:
Sea
La distribución de
Para el cálculo del valor en riesgo, a través de esta metodología se deben tener en cuenta los siguientes supuestos sobre la teoría del valor extremo:
1. Para límites muy altos la cola de la distribución de los datos converge a la distribución generalizada de Pareto5.
2. Se posee una distribución de excesos o extremos por encima del umbral
Lo que permite que para valores grandes de
Donde
Lo anterior implica, que a largas distribuciones el dominio máximo de atracción sea de tipo: normal, log normal, chi-cuadrado, t, gamma, f, etc.
Asumiendo los anteriores aspectos, es necesario el cálculo de las colas de la distribución de pérdida, teniendo en cuenta como se mencionó antes, que a cantidades de umbral
Siguiendo lo anterior, se puede encontrar la aproximación para la distribución
Donde la función del umbral
La estimación de la distribución se escribe de la siguiente manera:
(Mariño, D Melo, L, 2016) indica que los parámetros para encontrar esta distribución se estiman vía máxima verosimilitud.
En lo que concierne a la estimación del VaR después de tener la distribución de los retornos negativos se selecciona un nivel de confianza entre 0<conf<1, y se calcula la siguiente fórmula (Hao Li, Xiao Fan, Yu Li, Yue Zhou, Ze Jin Zhao Liu, 2014)
3.2 Estimación del VaR usando Cuasi-verosimilitud
La volatilidad es el comportamiento principal en el modelado de activos financieros; se puede observar en la práctica usualmente que ésta se aglomera y está autocorrelacionada a lo largo del tiempo. Los modelos GARCH son la mejor aproximación para explicar el comportamiento de explosión y calma en los activos, convirtiéndose en una herramienta muy útil en el manejo del riesgo financiero.
La estimación del VaR con supuestos normales, evidencian en la aplicación, una presencia amplia de sesgo y curtosis, lo que resulta en poca o mucha cobertura de las estimaciones calculadas. Por lo que asumir otro tipo de distribuciones y realizar modelos para el manejo de riesgo, resulta en muchas ocasiones un factor óptimo en la estimación oportuna del VaR (Embrechts, 2016).
En la práctica es bastante común utilizar modelos auto-regresivos de heterocedasticidad condicional (ARCH) y generalizados (GARCH) ya que estos, capturan los movimientos no constantes de la varianza a través del tiempo, luchando contra los constantes cambios en la volatilidad. En la práctica los modelos más utilizados de esta clase son los ARCH (1), GARCH (1,1) y EGARCH(1,1); en el caso de este documento se estimará el VaR por medio del modelo GARCH(1,1)
Sea
Donde
Los valores no predictivos se pueden escribir como procesos de tipo ARCH
Con lo anterior, la varianza condicional del modelo ARCH(q) se escribe como:
Donde
Donde si
El modelo GARCH(p,q), según (Lei, Fan J Xiu D, 2014) propone una solución bastante buena frente a problemas con la volatilidad, y las colas pesadas de la distribución de los retornos, por lo que genera estimaciones confiables al incluir este factor difícil de modelar y pronosticar.
Por otro lado, este modelo carece de eficiencia por las limitaciones que posee, en cuanto a la varianza dependiente de la magnitud y no de los
En el caso, de la estimación de los parámetros de los modelos GARCH (p,q) es frecuente usar la estimación por máxima verosimilitud (MLE), asumiendo normalidad en la distribución de los errores
En general, la técnica de estimación frecuentemente utilizada en los modelos GARCH por medio de QMLE es la Cuasi-verosimilitud Gaussiana (GQMLE) la cual garantiza la mejora en eficiencia de las estimaciones (Timotheos A, Benos A Degiannakis S, 2003)
Método de Cuasi-verosimilitud
Sea el siguiente vector aleatorio yt que satisface la siguiente ecuación:
donde
Se tiene que
con la siguiente función de quasi-verosimilitud
donde
y la estimación de
Para el uso del método de cuasi-verosimilitud en el caso del proceso GARCH (p,q), se tienen que tener en cuenta algunas consideraciones. Sea un proceso GARCH (p,q) definido de la siguiente manera:
y
donde
permite la estimación por (QL) para
Entonces dando el valor de 0 en el tiempo 0 para
El estimador QL usando la estimación para
El estimador para
Entonces la estimación de los parámetros por cuasi-verosimilitud
En el caso del modelo GARCH(1,1) se tiene en cuenta la siguiente forma para la varianza
donde
Y el estimador de cuasi-verosimilitud para
En este caso dando valores iniciales para
la solución
Las estimaciones se obtienen con el anterior procedimiento iterativo tomando en consideración los valores iniciales para
Al considerar la anterior estimación de la varianza para el modelo GARCH se encuentra el cuantil
En donde
3.3 Estimación del VaR con el uso de Cópulas
Teniendo en cuenta la volatilidad de las series financieras, en la mayoría de los casos se asume normalidad sobre los retornos, con estos supuestos se realizan los modelos GARCH; sin embargo, es clave entender la relación de dependencia no lineal existente entre los retornos por medio de la teoría de cópulas. Una cópula es entendida como la relación entre dos o mas funciones, la cual denota un vínculo entre la distribución de probabilidad de un vector aleatorio y las distribuciones marginales asociadas a este. En términos multivariados una cópula se puede expresar como:
donde
En finanzas, la aplicación de las cópulas ha ido creciendo en los últimos años, debido a su uso en proceso matemáticos de gran complejidad.
Formalmente las cópulas son funciones multivariadas d-dimensionales con distribuciones marginales en el intervalo
En donde la anterior expresión satisface las siguientes propiedades (Alzghool, 2017):
• Si
es única
• Si F es una función continua d-variada de variables discretas (generalmente mitad continua, mitad discreta), entonces la cópula es unica en el conjunto
Entonces, según (Joe, 2015), para cualquier función de distribución cuyas marginales sean uniformes, es posible obtener una cópula asociada. En la función cópula
donde
1) Teorema de Sklar
De acuerdo con el teorema de Sklar, se establece que si en
2) Vine Cópulas
La implicación del teorema de Sklar muestra que las marginales uniformes pueden ser modeladas de manera separada del modelado de dependencia en términos de la cópula, mostrando algunos problemas de selección en la estructura de dependencia en altas dimensiones. Las cópulas multivariadas como la Gaussiana o t de student son definidas para cualquier dimension; sin embargo, sus propiedades de dependencia suelen presentar limitaciones y pueden presentar dificultades incluso en tres dimensiones. En el caso de las arquimedianas presentan poca flexibilidad en modelar la dependencia con dos o más variables (Brechmann & Schepsmeier, 2013).
Este problema puede ser solucionado con el uso de Vine Cópulas; este método permite escribir una distribución conjunta en términos de una cópula bivariada y una condicional conforme a una estructura gráfica en forma de árbol, por medio de esta permite una medida más flexible para capturar la estructura de dependencia entre los activos financieros. Existen dos clases de Vine Cópulas, los C-Vinces (canonicos) & D-Vines. En estos, la diferencia se basa en la forma estructural del árbol en el que se representan las cópulas condicionales y bivariadas. Estas estructuras han sido utilizadas satisfactoriamente en distintas aplicaciones, siendo la mas usada el riesgo financiero. Las Vine Cópulas están conformadas por una estructura general hecha a partir de cópulas bivariadas o llamadas (Pair Cópulas Constructions PCC), esto permite que una cópula general pueda ser reescrita en un producto entre PCC usando las distribuciones multivariadas con unas marginales dadas.
Sea
donde
Siguiendo con los delineamientos de este trabajo, se tienen tres dimensiones conformadas por los activos con mayor peso en el portafolio, por lo que una posible descomposición para la densidad
lo que implica que
por lo que la descomposición para d=3 es:
esto implica que la estructura gráfica del árbol D-vine tiene la siguiente forma:

Lo que significa que la cópula general para esta estructura resulta del producto entre las PCC como se muestra a continuación:
Familia de cópulas
A continuación, se muestran las posibles cópulas que pueden obtenerse en el modelado de los activos financieros (Nicole Krämer Ulf Schepsmeier, 2011):
Cópula Gaussiana
Se define a la cópula gaussiana como la distribución sobre el espacio medible en el cubo
donde
Cópula t
En términos generales la cópula t puede ser escrita como:
donde
Cópulas arquimedianas
Las cópulas arquimedianas son una clase asociativa de cópulas cuya expresion admite una fórmula explícita; estas son populares por permitir modelar la dependencia en dimensiones altas con un solo parámetro. En general, una cópula se dice arquimediana si se expresa como:
donde
En general las cópulas arquimedianas más importantes son las siguientes:
Tabla 1 Cópulas Arquimedianas
| Cópula | Función de distribución | Parámetro |
|---|---|---|
| Ali-Mikhail-Haq |
|
|
| Clayton |
|
|
| Frank |
|
|
| Gumbel |
|
|
| Joe |
|
|
Fuente: (Nelsen, 2006) y (Triana, Torres Aponte, Alba, Pineda-Ríos, 2017)
Estimación de los parámetros
En general un modelo con la inclusión de una estructura de dependencia (Vine Cópula) posee la siguiente forma:
La selección de la estructura es utilizada por medio de el cálculo del
Los métodos de selección para la cópula a utilizar se basan en test de bondad y ajuste, independencia, criterios como Akaike Information Criterion (AIC) o Bayesian Information Criterion (BIC), o gráficos de contorno que permitan identificar una posible estructura.
En cuanto a la última parte del modelo, la estimación de los parámetros se puede realizar por tres métodos en concreto (Triana, Torres Aponte, Alba, Pineda-Ríos, 2017):
Estimación por máxima verosimilitud
Métodos secuenciales: En estos los parámetros son secuencialmente estimados desde el inicio de la estructura del árbol, generando así pseudo observaciones usadas en la segunda etapa del árbol, en donde esta estimación se realiza bajo máxima verosimilitud bivariada o
Estimación Bayesiana
En el caso de este trabajo la estimación de los parámetros se realizó por máxima verosimilitud por medio del paquete VineCópula del software R.
3.4 Valor en Riesgo Condicional (Expected Shortfall)
El VaR condicional (CVaR), déficit esperado o llamado expected shortfall es una medida del valor en riesgo que responde a la pregunta de “Si las cosas van mal que pérdidas se obtendrían”. Desde un punto de vista estadístico en el CVaR se asume cada dia
Para las variables aleatorias
En términos generales el valor en riesgo condicional se expresa como el promedio de los
donde U es el extremo inferior de los rendimientos y tanto f como F son funciones de densidad de la distribución de los rendimientos. Para el cálculo es necesario tomar en cuenta la siguiente expresión:
donde
4. Medición del Valor en Riesgo en el mercado accionario colombiano bajo metodologías semiparamétricas y Vine Cópulas
El presente trabajo, es de carácter cuantitativo en el que se realizan las distintas técnicas de estimación para el valor en riesgo (VaR) a cada uno de los rendimientos de las acciones que conforman el índice accionario COLCAP; para tal efecto, se toman las acciones que mayor capitalización bursátil presentaron para el período 2015 a 2017: “Preferencial Bancolombia”, “Grupo Sura”, “Ecopetrol” y “Bancolombia”. Una vez efectuados los cálculos se realizan estadísticos descriptivos y gráficos para identificar las características de las series financieras, debido al comportamiento leptocúrtico de los datos y la amplia volatilidad presentada. Con la ayuda del Software Eviews, se aplican métodos de estimación sobre las series con el fin de encontrar los mejores modelos que explique el comportamiento de los rendimientos de las acciones.
Una vez seleccionados los mejores modelos con el criterio AIC (Akaike information criterion), y realizando análisis de independencia y homocedasticidad de los residuales con una significancia del 10%
Finalmente, se construye un portafolio conformado por los rendimientos de las acciones citadas con el fin de estimar el valor en riesgo por medio de Cópulas; en este caso, se optó por una estructura D-Vine para el conjunto de rendimientos. Una vez identificada esta estructura, con los modelos GARCH previamente calculados, se realizó la estimación del valor en riesgo siguiendo la estructura de dependencia no lineal que el portafolio presenta.
4.1 Estimación del Valor en Riesgo bajo metodologías semiparamétricas en el Mercado accionario colombiano período 2008-2016
A continuación, se toman las acciones que mayor peso tienen el índice de COLCAP, las cuales representan el 34% del volumen de negociación en una jornada
4.1.1 Rendimientos de la acción preferencial Bancolombia
En la figura se puede observar visualmente falta de tendencia sobre los rendimientos de la acción preferencial de Bancolombia
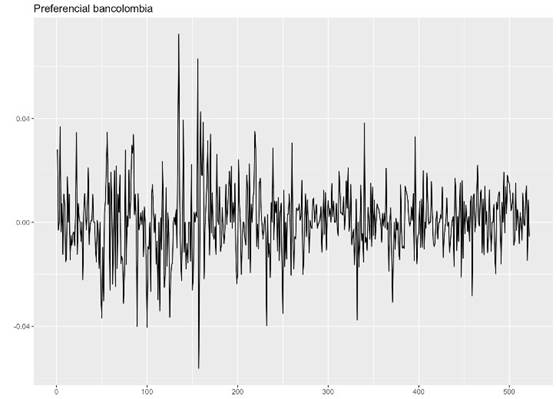
Una vez identificado la falta de presencia de tendencia en la serie se realiza la prueba estadística de Phillips Perron con el fin de identificar de estacionariedad (presencia de raíz unitaria) en los rendimientos como se muestra a continuación:
Tabla 2 Prueba raíz unitaria acción preferencia Bancolombia
Null Hypothesis: PREFBAN has a unit root
Exogenous: Constant
Bandwidth: 8 (Newey-West automatic) using Bartlett Kernel
| Phillips-Perron test statistic | Adj. t-Stat | Prob * | |
|---|---|---|---|
| -22.89901 | 0.000 | ||
| Test critical values | 1% level | -3.442673 | |
| 5% level | -2.866868 | ||
| 10% level | -2.569669 | ||
*Mackinnon (1996) one-sided p-values
Fuente: Elaboración propia
En la anterior tabla, se puede observar que se rechaza la hipótesis nula de ausencia de raíz unitaria en la serie, por lo que esta es estacionaria; debido a esto, se procede a la selección del mejor modelo en series de tiempo para los rendimientos “Preferencial Bancolombia” con el uso del siguiente correlograma:
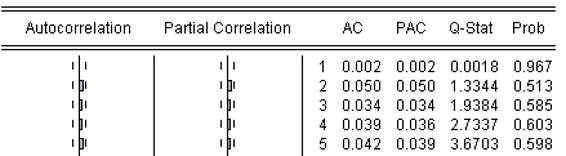
Fuente: Elaboración propia
Figura 3 Diagrama de Autocorrelación y autocorrelación parcial de la Acción preferencial Bamcolombia
Para el caso de los rendimientos, se encontró que el modelo

Fuente: Elaboración propia
Figura 4 Prueba de normalidad para el modelo de la acción preferencial Bancolombia
Se puede observar en la figura 4, que se rechaza la hipótesis nula de normalidad para los residuales. Por último, en el modelado básico de la serie de tiempo se realiza la prueba de heterocedasticidad con el fin de validar el supuesto de volatilidad en los rendimientos de la serie como se muestra a continuación:
Tabla 3 Prueba de heterocedasticidad ARCH para los residuales de la acción preferencial Bancolombia
Heteroskedasticity: Test: ARCH
| F-statistic | 22.02460 | Prob. F (1,519) 0.0000 |
| Obs*R-squared | 21.20942 | Prob. Chi-Square (1) 0.0000 |
Fuente: Elaboración propia
De acuerdo con la tabla 3, se rechaza la hipótesis nula de homocedasticidad en los residuales por lo que existe la presencia de volatilidad. Siguiendo con el análisis, y considerando un nivel de significancia del 10%, se puede concluir que las estimaciones del coeficiente del modelo de corto plazo del proceso en el modelo completo son significativas.
A continuación, se presenta el resultado de la prueba de Ljung-Box para los residuales del modelo identificado.
Tabla 4 Prueba de Ljung-Box sobre los residuales del modelo para la acción preferencial Bancolombia
| Q(lag) | Estadístico | p-value |
|---|---|---|
| 1 | 0.6216 | 0.4304 |
| 11 | 4.3726 | 0.9984 |
| 19 | 7.3334 | 0.8760 |
Fuente: Elaboración propia
Los resultados presentados en la tabla anterior, permiten concluir que no hay correlación serial en los residuales del modelo identificado. Lo anterior indica, que el modelo es adecuado para capturar la correlación serial a corto plazo presente en la serie.
Lo señalado anteriormente, es la prueba suficiente para la inclusión de los modelos GARCH en el análisis de la volatilidad del mercado y su efecto en la estimación del valor en riesgo.
A continuación, se observa el correlograma de los residuales al cuadrado:
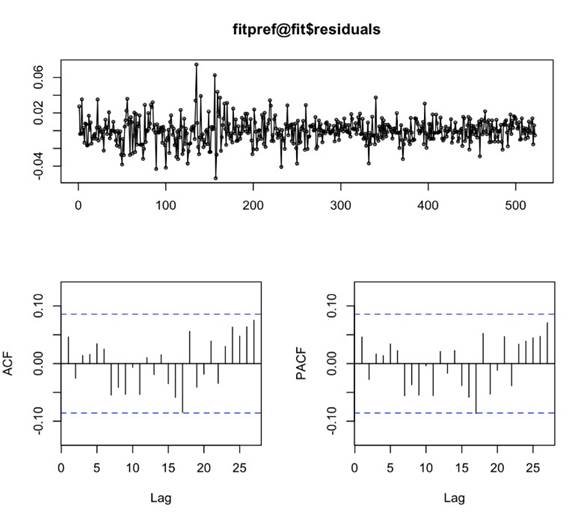
Fuente: Elaboración propia
Figura 5 Diagrama de autocorrelación y autocorrelación parcial de los residuales al cuadrado del modelo para la acción preferencial Bancolombia
Se estableció que el modelo que mejor captura la volatilidad de los rendimientos lo constituye un
Teniendo en cuenta lo descrito anteriormente, se calcularon las siguientes estimaciones para el valor en riesgo:
Tabla 5 Estimaciones del VaR para la acción preferencial de Bancolombia
| Método de estimación | Valor |
|---|---|
| -Valor en Riesgo VaR | -0.0331548230 |
| -Valor en riesgo condicional (CVaR) Expected Shortfall (ES) | -0.0375509408 |
| -VaR - EVT/Distribución Gumbel | -0.0217651757 |
| -VaR - EVT/Distribución generalizada del error | -0.0213318122 |
| -Quasi-verosimilitud | -0.02004189 |
Fuente: Elaboración propia
4.1.2 Rendimientos de la acción Grupo Sura
Se puede observar el posible comportamiento estacionario de los rendimientos en la siguiente figura:
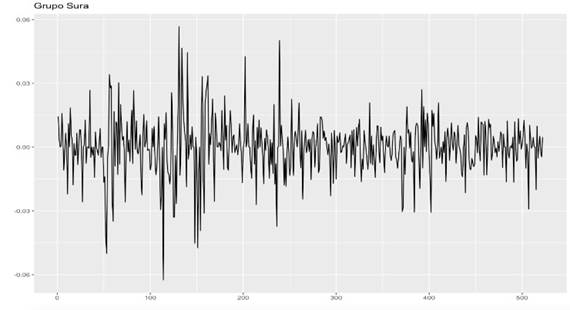
De acuerdo con la figura 6, se pudo identificar la falta de tendencia que presentan los rendimientos; ante este evento, se realiza la prueba estadística de Phillips Perron con el fin de identificar de estacionariedad (presencia de raíz unitaria) en los rendimientos como se muestra a continuación:
Tabla 6 Prueba raíz unitaria acción grupo Sura
Null Hypothesis: GRUPOSURA has a unit root
Exogenous: Constant
Bandwidth: 14 (Newey-West automatic) using Bartlett Kernel
| Phillips-Perron test statistic | Adj. t-Stat | Prob * | |
|---|---|---|---|
| -20.79134 | 0.000 | ||
| Test critical values | 1% level | -3.442673 | |
| 5% level | -2.866868 | ||
| 10% level | -2.569669 | ||
*Mackinnon (1996) one-sided p-values
Fuente: Elaboración propia
De acuerdo con la tabla 6, se puede observar que se rechaza la hipótesis nula de ausencia de raíz unitaria en la serie, por lo tanto, se deduce que es estacionaria. Debido a esto, se procede a la selección del mejor modelo en series de tiempo para los rendimientos “Grupo Sura” con el uso del siguiente correlograma:

Fuente: Elaboración propia
Figura 7 Diagrama de autocorrelación y autocorrelación parcial de la acción Grupo Sura
Para el caso de los rendimientos se encontró que el modelo

Se puede observar en la figura 8, que se rechaza la hipótesis nula de normalidad para los residuales.
Como último, en el modelado básico de la serie de tiempo, se realiza la prueba de heterocedasticidad con el fin de validar el supuesto de volatilidad en los rendimientos de la serie como se muestra a continuación:
Tabla 7 Prueba de heterocedasticidad ARCH para los residuales de la acción grupo Sura
Heteroskedasticity: Test: ARCH
| F-statistic | 3.736531 | Prob. F (1,519) 0.0538 |
| Obs*R-squared | 3.724118 | Prob. Chi-Square (1) 0.0536 |
Fuente: Elaboración propia
De acuerdo con la tabla 7, se rechaza la hipótesis nula de homocedasticidad en los residuales, por lo que deduce la presencia de volatilidad. Siguiendo con este desarrollo, y considerando un nivel de significancia del 10%, se puede concluir que, las estimaciones del coeficiente del modelo de corto plazo del proceso en el modelo completo son significativas. En este aspecto, la prueba de Ljung-Box identificó que después del lag 14 con un p-value del 0.366571 no existen problemas de correlación serial en los residuales del modelo identificado. Lo anterior indica, que el modelo es adecuado para capturar la correlación serial a corto plazo presente en la serie.
Lo dicho anteriormente, es la prueba suficiente para la inclusión de los modelos GARCH en el análisis de la volatilidad; para tal efecto, se realiza el diagrama de autocorrelación y autocorrelación parcial de los residuales al cuadrado:

Fuente: Elaboración propia
Figura 9 Diagrama de autocorrelación y autocorrelación parcial de los residuales al cuadrado del modelo para la acción Grupo Sura
De acuerdo con la figura 9, se estableció que, el modelo
Teniendo en cuenta lo descrito anteriormente, se calcularon las siguientes estimaciones para el valor en riesgo:
Tabla 8 Estimación del VaR para la acción de Grupo Sura
| Método de estimación | Valor |
|---|---|
| -Valor en Riesgo VaR | -0.0305634173 |
| -Valor en riesgo condicional (CVaR) Expected Shortfall (ES) | -0.0348488239 |
| -VaR - EVT/Distribución Gumbel | -0.0200639933 |
| -VaR - EVT/Distribución generalizada del error | -0.0198973944 |
| -Quasi-verosimilitud | -0.01943537 |
Fuente: Elaboración propia
4.1.3 Rendimientos de la acción Ecopetrol
Como se puede observar en la figura 10, no existe tipo de comportamiento alguno relacionado con los rendimientos

Una vez establecido que la serie no presenta ningún tipo de tendencia, se realiza la prueba de Phillips-Perron con el fin de identificar la presencia de raíz unitaria en la serie para luego continuar con el modelado, como se puede ver a continuación:
Tabla 9 Prueba raíz unitaria acción Ecopetrol
Null Hypothesis: ECOPE has a unit root
Exogenous: Constant
Bandwidth: 1 (Newey-West automatic) using Bartlett Kernel
| Phillips-Perron test statistic | Adj. t-Stat | Prob * | |
|---|---|---|---|
| -20.00800 | 0.000 | ||
| Test critical values | 1% level | -3.442673 | |
| 5% level | -2.866868 | ||
| 10% level | -2.569669 | ||
*Mackinnon (1996) one-sided p-values
Fuente: Elaboración propia
De acuerdo con la tabla 9, se puede observar que se rechaza la hipótesis nula de ausencia de raíz unitaria en la serie por lo que esta es estacionaria; debido a esto se procede a la selección del mejor modelo en series de tiempo para los rendimientos de “Ecopetrol” con el uso del siguiente correlograma:
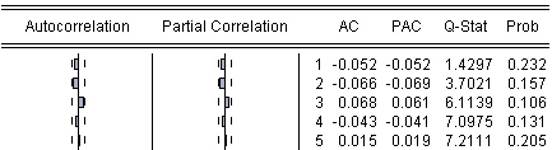
Fuente: Elaboración propia
Figura 11 Diagrama de autocorrelación y autocorrelación parcial de la acción de Ecopetrol
Para el caso de los rendimientos, se encontró que el modelo
Como se puede observar en la figura 12, que con una significancia previamente establecida del 10% se rechaza la hipótesis nula de normalidad en los residuales.
Como última fase en el modelado básico de la serie de tiempo, se realiza la prueba de heterocedasticidad, con el fin de validar el supuesto de volatilidad en los rendimientos de la serie como se muestra a continuación
Tabla 10 Prueba de heterocedasticidad ARCH para los residuales de la acción Ecopetrol
Heteroskedasticity: Test: ARCH
| F-statistic | 5.601329 | Prob. F (1,519) 0.0183 |
| Obs*R- squared | 5.562877 | Prob. Chi-Square (1) 0.0183 |
Fuente: Elaboración propia
De acuerdo con la tabla 10, se rechaza la hipótesis nula de homocedasticidad en los residuales por lo que existe la presencia de volatilidad. Siguiendo con el análisis, y considerando un nivel de significancia del 10%, se puede concluir que, las estimaciones del coeficiente del modelo de corto plazo del proceso en el modelo completo son significativas.
A continuación, se presenta el resultado de la prueba de Ljung-Box para los residuales del modelo identificado:
Tabla 11 Prueba de ljung-box sobre los residuales del modelo para la acción Ecopetrol
| Q(lag) | Estadístico | p-value |
|---|---|---|
| 1 | 0.002182 | 0.9627 |
| 8 | 1.185344 | 1.0000 |
| 14 | 3.282668 | 0.9940 |
Fuente: Elaboración propia
Los resultados presentados en la tabla 11 permiten concluir que no hay correlación serial en los residuales del modelo identificado. Lo anterior indica que, el modelo es adecuado para capturar la correlación serial a corto plazo presente en la serie.
Con el fin de expresar el comportamiento volátil de la serie de rendimientos, se calcula el modelo GARCH teniendo en cuenta el siguiente correlograma de los residuales al cuadrado:

Fuente: Elaboración propia
Figura 13 Diagrama de autocorrelación y autocorrelación parcial de los residuales al cuadrado del modelo para la acción Ecopetrol
De acuerdo con la figura 13, el modelo que mejor captura la volatilidad de los rendimientos lo constituye un
Teniendo en cuenta lo descrito anteriormente, se procede a calcular las siguientes estimaciones para el valor en riesgo:
Tabla 12 Estimaciones del VaR para la acción Ecopetrol
| Método de estimación | Valor |
|---|---|
| -Valor en Riesgo VaR | -0.0491560011 |
| -Valor en riesgo condicional (CVaR) Expected Shortfall (ES) | -0.0568813340 |
| -VaR - EVT/Distribución Gumbel | -0.0322694831 |
| -VaR - EVT/Distribución generalizada del error | -0.0328345307 |
| -Quasi-verosimilitud | -0.02702382 |
Fuente: Elaboración propia
4.1.4 Rendimientos de la acción ordinaria Bancolombia
Se puede observar el posible comportamiento estacionario de los rendimientos de la acción Bancolombia en la siguiente figura:
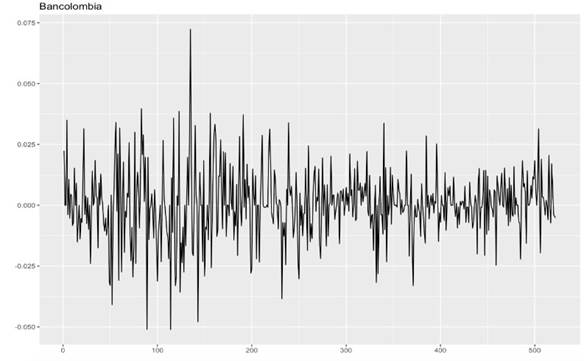
Se puede observar en la figura 14, la falta de tendencia y un posible comportamiento estacionario de los rendimientos, por lo que se procede a verificar dicho comportamiento por medio de la prueba Phillips-Perron, como se muestra a continuación:
Tabla 13 Prueba raíz unitaria acción ordinaria Bancolombia
Null Hypothesis: BCOL has a unit root
Exogenous: Constant
Bandwidth: 7 (Newey-West automatic) using Bartlett Kernel
| Phillips-Perron test statistic | Adj. t-Stat | Prob * | |
|---|---|---|---|
| -21.79115 | 0.000 | ||
| Test critical values | 1% level | -3.442673 | |
| 5% level | -2.866868 | ||
| 10% level | -2.569669 | ||
*Mackinnon (1996) one-sided p-values
Fuente: Elaboración propia
Como se puede observar en la tabla 13, se rechaza la hipótesis nula de ausencia de raíz unitaria en la serie; por lo tanto, se deduce que es estacionaria. Debido a esta situación, se procede a la selección del mejor modelo en series de tiempo para los rendimientos “Bancolombia” con el uso del siguiente correlograma:

Fuente: Elaboración propia
Figura 15 Diagrama de autocorrelación y autocorrelación parcial de la acción ordinaria Bancolombia
Para el caso de los rendimientos se encontró que, el modelo

Fuente: Elaboración propia
Figura 16 Prueba de normalidad para el modelo de la acción ordinaria Bancolombia
De acuerdo con la figura 16 se rechaza la hipótesis nula de normalidad sobre los residuales en el modelo propuesto. Posteriormente a la identificación de la no normalidad en los residuales se realiza la prueba de White de Heterocedasticidad en la cual se evidencia volatilidad en los rendimientos como se muestra a continuación:
Tabla 14 Prueba de heterocedasticidad ARCH para los residuales de la acción ordinaria Bancolombia
Heteroskedasticity: Test: White
| F-statistic | 226.7127 | Prob. F (10,511) 0.0000 |
| Obs*R-squared | 425.9850 | Prob. Chi-Square (10) 0.0000 |
| Scaled explained SS | 842.7783 | Prob. Chi-Square (10) 0.0000 |
Fuente: Elaboración propia
Siguiendo con el modelo, y considerando un nivel de significancia del 10%, se puede concluir que las estimaciones del coeficiente del modelo de corto plazo del proceso en el modelo completo son significativas. A continuación, se presenta el resultado de la prueba de Ljung-Box para los residuales del modelo identificado.
Tabla 15 Prueba de Ljung-box sobre los residuales del modelo para la acción ordinaria de Bancolombia
| Q(lag) | Estadístico | p-value |
|---|---|---|
| 1 | 0.18437 | 0.6676 |
| 10 | 4.085 | 0.9434 |
| 15 | 10.01 | 0.8191 |
Fuente: Elaboración propia
Los resultados presentados en la tabla anterior permiten concluir que no hay correlación serial en los residuales del modelo identificado. Lo anterior indica que el modelo es adecuado para capturar la correlación serial a corto plazo presente en la serie.
Con el fin de expresar el comportamiento volátil de la serie de rendimientos, se calcula el modelo GARCH teniendo en cuenta, el siguiente correlograma de los residuales al cuadrado:

Fuente: Elaboración propia
Figura 17 Diagrama de autocorrelación y autocorrelación parcial de los residuales al cuadrado del modelo para la acción ordinaria de Bancolombia
Se estableció de acuerdo con la figura 17, que el modelo, que mejor captura la volatilidad de los rendimientos, lo constituye un
Teniendo en cuenta lo descrito anteriormente, se calcularon las siguientes estimaciones para el valor en riesgo:
Tabla 16 Estimaciones del VaR para la acción ordinaria Bancolombia
| Método de estimación | Valor |
|---|---|
| -Valor en Riesgo VaR | -0.0332057961 |
| -Valor en riesgo condicional (CVaR) Expected Shortfall (ES) | -0.0376404786 |
| -VaR - EVT/Distribución Gumbel | -0.0217986380 |
| -VaR - EVT/Distribución generalizada del error | -0.0213964142 |
| -Quasi-verosimilitud | -0.018491 |
Fuente: Elaboración propia
4.2 Estimación del VaR por medio de modelos VineCópula
En ninguno de los casos mencionados anteriormente se tuvo en cuenta la estructura de dependencia no lineal entre los activos para la estimación del VaR. Para considerar metodología es necesario tener en cuenta la relación entre los activos dentro de un mismo portafolio de inversión; en este caso se construyó un portafolio constituido con los rendimientos de los siguientes activos:
Teniendo en cuenta los anteriores análisis y la descripción de las 522 observaciones para cada uno de los activos desde el 10 de junio de 2015 hasta el 10 de junio de 2017; se obtuvieron los siguientes modelos previamente calculados con los que se desarrolla esta metodología:
En cuanto a explicar la volatilidad de los rendimientos de los activos financieros en el portafolio, los coeficientes de los modelos GARCH calculados se muestran a continuación:
Tabla 17 Estimación parámetros modelos GARCH
| Parámetro | Preferencial Bancolombia | Grupo Sura | Ecopetrol |
|---|---|---|---|
|
|
3.7387e-06 | 7.198519e-06 | 5.1556e-06 |
|
|
5.7285e-02 | 9.434554e-02 | 5.5947e-02 |
|
|
0.9241 | 0.8716184 | 0.9367 |
| shape | 6.054365 | 3.883865 | 4.034393 |
Fuente: Elaboración propia
Una vez realizadas las estimaciones, se verificó la distribución de los residuales; en este caso, como en las modelaciones anteriores, los residuales de ninguno de los rendimientos presenta distribución normal, por lo que se evidencia un comportamiento leptocúrtico de los datos y las colas pesadas en estos. Se hicieron supuestos sobre una posible distribución t presente en los residuales de cada uno de los modelos ajustados.
A continuación, se muestran los diagramas qplot que permiten identificar estos supuestos:

Fuente: Elaboración propia
Figura 18 Diagramas Qplot para las acciones Preferencial Bancolombia, Grupo Sura y Ecopetrol
Teniendo en cuenta el supuesto de que los residuales del modelo presentan una distribución t por las características en los diagramas presentados, se procede a calcular los grados de libertad respectivos para estas distribuciones por medio de máxima verosimilitud a través del algoritmo de Newton-Rapson para maximización por medio del paquete (maxLik) del lenguaje R.
En la siguiente tabla se pueden observar las estimaciones para cada uno de los grados de libertad:
Tabla 18 Estimación de los grados de libertad para la distribución de los residuales de los modelos GARCH calculados
| Residuales | Estimación | Pr(>t) |
|---|---|---|
| Preferencial Bancolombia | 57.1291309 | <2e-16 *** |
| Grupo Sura | 23.2779885 | <2e-16 *** |
| Ecopetrol | 14.37335 | <2e-16 *** |
Fuente: Elaboración propia
De acuerdo con la tabla 18, se puede observar que la estimación por cada una de las series resulta ser significativa; por lo tanto, la maximización vía Newton-Rapson estima de manera correcta los grados de libertad de los residuales de los modelos calculados.
4.2.1 Selección de la Cópula
Conociendo las distribuciones marginales de los residuales de los rendimientos, se transformaron en datos cópula reescribiéndolos en términos de probabilidades en orden para seleccionar la cópula que logre capturar la dependencia entre los datos, los cuales están denotados como
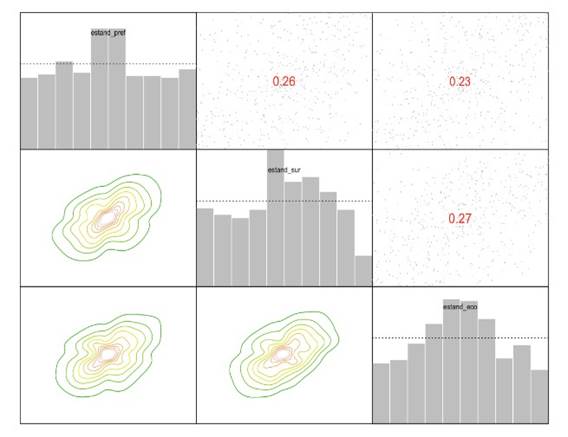
En la figura 20 se puede observar la relación de dependencia no lineal entre los rendimientos de los activos financieros por medio del Tau de Kendall, así como la forma de las cópulas asociadas a la dependencia entre las series. Siguiendo a (Czado, 2013) la estructura PCC para el conjunto de rendimientos se escribe como:6
donde la estructura D-vine está construida a partir de los siguientes pares de cópulas:
Una vez identificada la estructura D-Vine se procede a la estimación de los parámetros establecidos por cada cópula en cada uno de los árboles
Finalmente, las posibles pérdidas se ponderan con las predicciones de la parte volátil del modelo
Teniendo en cuenta la siguiente estructura del modelo calculado con el paquete R Rugarch para evaluar la precisión de las estimaciones del VaR, se realizó la estimación al 90%, 95% y 99% de nivel de confianza mediante el siguiente procedimiento:
donde
Calculando las expresiones previas de la distribución de la cartera después de hacer todas las predicciones, se procede a calcular el valor en riesgo al 90%, 95% y 99% de nivel de confianza con pesos iguales para los retornos
Tabla 19 Estimación del VaR para el portafolio
| 90% | 95% | 99% |
| 0.03293495 | 0.04277162 | 0.06326884 |
Fuente: Elaboración propia
En cuanto al desempeño establecido por parte de las metodologías, el uso de distribuciones de valores extremos es comúnmente mencionado varios los analistas como mejor medida para retener las colas pesadas de las distribuciones de los retornos para los activos financieros. Adicionalmente, el valor en risgo condicional resulta ser una de las alternativas preferidas al tener en cuenta la forma completa de la cola para la perdida esperada, en vez de un único punto.
Para los modelos de volatilidad usando la estimación proveniente de la quasi-verosimilitud se uso de backtesting, se obtuvieron los siguientes resultados usando la prueba incondicional de Kupiec y condicional de Christoffersen:
Tabla 20 Backtesting para estimacion GARCH quasi-verosimil
| Modelo implementado | Excedencias actuales/esperadas | P-valores para test de Kupiec/Christoffersen | Decisión (El modelo se considera:) |
|---|---|---|---|
| Pref. Ban | 10 / 5 | 0.06188/0.07031 | Exacto |
| G. Sura | 14/ 5 | 0.00139/0.00412 | Inexacto |
| Ecopetrol | 11/5 | 0.02680/0.06794 | Indecisión |
| Bancolombia | 11/5 | 0.02680/0.04073 | Inexacto |
Fuente: Elaboración propia
De este backtesting se pudo concluir que en todos los casos se presentó mayor numero de excedencias a las esperadas por el modelo. En el caso del uso de Vine Copulas un cálculo para backtesting representa un alto costo computacional y dispendioso en implementación por lo cual no fue implementado sino a manera de resultado para la metodología propuesta. Esta ultima metodología se estimó para todo el portafolio en conjunto.
5. Conclusiones
De acuerdo con la investigación realizada se puede concluir que la estimación para el valor en riesgo por medio de los modelos vinecópula logran describir de manera adecuada el comportamiento de la volatilidad incesante de los activos relacionados (acción preferencial Bancolombia, Grupo Sura y Ecopetrol) así como la estructura de dependencia no lineal capturada por otras metodologías
De otro lado el método por quasi-verosimilitud da un primer acercamiento libre de supuestos sobre la distribución de los residuales del modelo GARCH calculado para la estimación del valor en riesgo
Las metodologías semiparamétricas como el EVT logran capturar el comportamiento en colas pesadas de las distribuciones de los datos, permitiendo así una estimación mejor a la estadística tradicional en la estimación del valor en riesgo. Aunque hay otras metodologías que permiten la optimización de portafolios con activos cuando los rendimientos se modelan mediante procesos log-estables como la presentada en (Climent-Hernández, 2017), que permite mejorar la eficiencia frente a los modelos log-gaussianos, los modelos Vine-Cópula permiten abrir una nueva ventana de investigación en las que se pueden establecer comparaciones de rendimiento y backtesting entre estas dos metodologías.
Finalmente, de acuerdo con (Acerbi Tasche, 2002) que manifiesta que el VaR no es apto para describir los riesgos de una cartera y que existen alternativas más prácticas en la clase de medidas de riesgo como el CVaR, cuyo objetivo es centrarse en los activos menos rentables, este artículo presenta una metodología para la estimación del riesgo en portafolios que involucran cópulas y que permite acercarse de manera más acertada a la realidad del mercado bursátil colombiano. En trabajos futuros se desea extender la metodología de cópulas y el acercamiento semiparametrico para el cálculo otro indicador de riesgo financiero, sin renunciar a las ventajas del VaR.

