











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. Introducción
Durante las últimas décadas la teoría financiera se desarrolló bajo el supuesto de que las series de rendimientos siguen una distribución normal. La hipótesis Gaussiana no fue cuestionada seriamente hasta que los trabajos pioneros de Mandelbrot (1963) y Fama (1965a-b) fueron publicados. El exceso de curtosis encontrado en las investigaciones de Mandelbrot y Fama les llevó a rechazar la hipótesis normal y proponer la distribución Pareto estable como un modelo estadístico para los rendimientos de los activos.
En años posteriores, la hipótesis Pareto estable fue apoyada por numerosas investigaciones empíricas de diversos autores, tales como (Bawa (1979); Janicki y Weron (1994); Panorska, Mittnik y Rachev (1995); y más recientemente Nolan (1997, 2003, 2013); Rachev y Mittnik (2000); Rachev y Han (2000); Ortobelli, Huber y Schwartz (2002); Curto, Pinto y Tavares (2009); Nolan y Ravishanker (2009); Contreras-Piedragil y Venegas-Martínez (2011); Bonato (2012); Climent-Hernández y Venegas-Martínez (2013) y Climent, Venegas y Ortiz (2015)).
El objetivo de este trabajo de investigación es considerar la familia de distribuciones α-estable en la estimación del VaR como una alternativa en el mercado financiero mexicano. Esta propuesta es atractiva, dado que la distribución estable no Gaussiana posee propiedades similares a la distribución normal. Entre estas propiedades, es importante resaltar que la familia de distribuciones α-estable satisface el Teorema del Límite Central Generalizado, el cual afirma que el único límite no trivial de sumas de variables aleatorias normalizadas independientes e idénticamente distribuidas (i.i.d.) es estable. La segunda propiedad señala que las distribuciones α-estable tienen dominio de atracción, es decir, cualquier distribución en el dominio de atracción de una distribución estable específica, tendrá propiedades similares a la misma. La tercera propiedad es que las distribuciones α-estable capturan la naturaleza leptocúrtica de los datos financieros empíricos (Fama (1965 a); Mandelbrot (1963 y 1967); Cheng y Rachev (1995); McCulloch (1996); Mittnik, Rachev y Paolella (1997)).
Tal vez, el aspecto más atractivo de la hipótesis α-estable es la propiedad de estabilidad, es decir, las distribuciones α-estable son estables con respecto a la suma de variables aleatorias estables i.i.d. La propiedad de estabilidad es deseable, ya que implica que cada distribución estable tiene un índice de estabilidad que sigue siendo el mismo, independientemente de la escala utilizada. El índice de estabilidad desempeña el papel del parámetro que rige las propiedades principales de la distribución subyacente.
Este enfoque, se basa en la estimación de los parámetros de la distribución estable empleando el criterio de máxima verosimilitud. Además, la estimación de la media y varianza condicional de los rendimientos se basa en el modelo TSGARCH con la innovación de la distribución estable.
Por último, el objetivo final de esta investigación es comparar el desempeño de las estimaciones del VaR obtenidas bajo la hipótesis estable y gaussiana durante y después de la crisis financiera del 2008.
Existen numerosas investigaciones que realizan estimaciones del VaR con simulación Montecarlo en períodos de alta volatilidad empleando la metodología econométrica ARMA-GARCH, sin embargo la principal aportación de esta investigación es que propone una distribución condicional alternativa para los rendimientos de los precios de los activos en el mercado financiero mexicano, considerando un modelo GARCH con la innovación de la distribución α-estable.
Además, hasta donde es de nuestro conocimiento no hay evidencia empírica sobre el desempeño en la medición de riesgo de los modelos VaR estable y normal, respectivamente, durante períodos de alta volatilidad en el mercado financiero mexicano. Este trabajo proporciona evidencia de que las estimaciones del VaR mediante el modelo heterocedástico condicional estable muestran una precisión satisfactoria durante períodos de turbulencias financieras.
El resto de la presente investigación se organiza de la siguiente manera. En la sección 2 se presenta la definición del Valor en Riesgo y las metodologías tradicionales para el cálculo del mismo. En la sección 3 se hace una breve descripción de los modelos GARCH. En la sección 4 se describe la familia de distribuciones α-estable y sus principales características. En la sección 5 se describen los datos empleados y se discuten sus propiedades, además se presentan los resultados de la estimación de los modelos GARCH basados en la hipótesis estable y normal, respectivamente. La sección 6 presenta las estimaciones del VaR mediante el modelo heterocedástico condicional estable. En la sección 7 se analiza y compara la estimación del VaR α-estable con los resultados del VaR obtenidos bajo el supuesto de que los rendimientos financieros siguen una distribución Gaussiana. Por último, en la sección 8 se presentan las conclusiones, limitaciones y sugerencias para futuras investigaciones.
2. Valor en Riesgo (VaR)
El Valor en Riesgo se ha convertido en el estándar para medir y evaluar el riesgo, desde que en 1996 el Comité de Supervisión Bancaria de Basilea requiere que las instituciones financieras, como los bancos y firmas de inversión, cumplan con el requisito de capital basado en la estimación del Valor en Riesgo (VaR).
El Valor en Riesgo se define como la máxima pérdida probable de un portafolio o instrumento financiero en un horizonte temporal determinado, para un nivel de confianza dado, bajo circunstancias normales de los mercados y como consecuencia de movimientos adversos de los precios. Sin embargo, el objetivo de esta sección es definir formalmente el VaR y mostrar algunas de las expresiones analíticas utilizadas en el cálculo del mismo.
Definición. Dado un intervalo de tiempo
donde  se define como la mínima de las
cotas superiores para un intervalo de confianza del (1-q)% tal que
se define como la mínima de las
cotas superiores para un intervalo de confianza del (1-q)% tal que
Es decir
De lo cual se deriva lo siguiente
De la definición de VaR en (2), es posible obtener el VaR dada la función de distribución acumulada de los rendimientos del activo financiero:
Donde
es decir el VaR es el cuantil q de
Los métodos de estimación del VaR sugieren diferentes formas de construir esta función. Los más comunes son, el método paramétrico, la simulación histórica y la simulación Monte Carlo.
2.1 Cálculo del VaR por Simulación Montecarlo
A través de este método, se obtiene una aproximación del comportamiento del rendimiento esperado de un portafolio o instrumento financiero, mediante simulaciones que generan trayectorias aleatorias de los rendimientos del portafolio o instrumento financiero, considerándose ciertos supuestos iniciales sobre las volatilidades y correlaciones de los factores de riesgo.
2.2 Cálculo del VaR paramétrico
El Método paramétrico se utiliza bajo el supuesto de que los datos observados siguen algunas reglas o modelos con parámetros desconocidos. Los datos se utilizan para obtener las estimaciones de los parámetros y enseguida se aplica la regla o el modelo establecido para calcular el VaR. En el método paramétrico se utilizan dos tipos enfoques: el enfoque incondicional y el enfoque condicional.
2.2.1 Enfoque incondicional
Se basa en el supuesto de que los rendimientos financieros para cada período de tiempo son variables aleatorias idéntica e independientemente distribuidas (i.i.d.) que siguen una distribución normal multivariada. Sin embargo diversas investigaciones muestran que la distribución empírica de los datos financieros tiene algunas propiedades que no pueden ser explicadas por la distribución Gaussiana multivariada. Por ejemplo Fama (1965 b), Hull y White (1998) señalan que los cambios en varias variables de mercado (precios de las acciones, precios de los bonos cupón cero, tipos de cambio, precios de las materias primas, etc.) son leptocúrticos, es decir, hay demasiados valores cercanos a la media y demasiados en las colas extremas, lo cual aumenta la probabilidad de movimientos muy grandes y muy pequeños en el valor de las variables de mercado y disminuye la probabilidad de movimientos moderados. Por lo tanto, la hipótesis Gaussiana se cuestiona y se sugieren algunas familias de distribuciones alternativas..
Entre estas se encuentra la distribución t Generalizada Asimétrica (GST) introducida en Theodossiou (1998), la cual es una extensión de la distribución t-Student que permite asimetría. Otra es la familia de distribuciones α-estables, propuesta por Mandelbrot (1963), la cual es una generalización de la distribución Gaussiana que permite asimetría y colas pesadas.
Khindanova, Rachev y Schwartz (2001) analizan el uso de la distribución Pareto Estable en el cálculo del VaR y afirman que esta distribución posee un ajuste superior en la estimación del mismo. En la presente investigación se utiliza la distribución Pareto Estable en el cálculo del VaR, pero a diferencia de Khindanova se considera la volatilidad variable en el tiempo.
Por otro lado, en el mundo real, las series financieras no son independientes entre sí, por lo que el supuesto de que las variables aleatorias son idéntica e independientemente distribuidas es cuestionado.
2.2.2 Enfoque condicional.
Admite que las series de tiempo de los rendimientos financieros dependen de la información pasada. Tradicionalmente, la dependencia de la serie se describe por un modelo de media móvil autorregresivo (ARMA), con lo cual se obtiene una serie estacionaria. Sin embargo, los modelos ARMA asumen que la varianza es constante, y dado que en general la volatilidad de las series de tiempo financieras no es constante, estos modelos no son adecuados para modelarlas.
Diversas investigaciones tratan de encontrar modelos que describan la volatilidad variable en el tiempo, característica común de los rendimientos financieros. El más popular es el modelo de Heterocedasticidad Condicional Autorregresiva (ARCH) propuesto por Engle (1982) en el cual la varianza condicionada a la información pasada no es constante, y depende del cuadrado de las innovaciones pasadas. Posteriormente Bollerslev (1986) generaliza los modelos ARCH al proponer los modelos de Heterocedasticidad Condicional Generalizada Autorregresiva (GARCH) en los cuales la varianza condicional depende no solo de los cuadrados de las perturbaciones, como en Engle, sino además, de las varianzas condicionales de períodos anteriores. Es posible combinar ambos modelos con el modelo ARMA, obteniendo los modelos ARMA-ARCH y ARMA-GARCH.
Hoy en día, el modelo GARCH se utiliza ampliamente. En el modelo GARCH estándar, se supone que la distribución de la innovación es gaussiana. Sin embargo, para muchas series de rendimientos financieros, la distribución Gaussiana no es adecuada dado que no considera la leptocurtosis. Por lo tanto, se utilizan varias distribuciones no gaussianas, por ejemplo la distribución GST (Bali y Theodossiou 2007 y Hansen 1994), la distribución Pareto estable (Liu y Brorsen 1995; Panorska, Mittnik y Rachev 1995). Estos modelos de series de tiempo se introducirán en la siguiente sección.
3. Modelos de volatilidad
Entre los modelos populares que explican la volatilidad variable se encuentran los modelos de la familia ARCH (Auto Regressive Conditional Heteroskedasticity) introducidos por Engle (1982), los cuales asumen que las varianzas condicionales siguen procesos autorregresivos. El modelo ARCH (m) supone que los rendimientos de los activos son descritos por el siguiente proceso:
donde 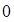 y varianza
y varianza 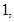
Tradicionalmente,
Bollerslev (1986) propuso el modelo ARCH
generalizado o GARCH. El modelo Autorregresivo con Heterocedasticidad Condicional
Generalizado (GARCH) es una extensión del modelo ARCH, el cual permite que la
varianza actual del término del error dependa también de las varianzas de errores
previos. El modelo 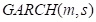 se
escribe como
se
escribe como
donde
De (7) se obtiene que la varianza marginal de r
t
es finita, mientras que su varianza condicional
Por otra parte, vale la pena señalar que existen estudios empíricos que afirman que el modelo GARCH (1,1) es robusto para los datos financieros (véase Bali y Theodossiou 2007, Hansen 1994, Liu y Brorsen 1995 y Panorska, Mittnik y Rachev 1995). Entonces, dados los datos financieros, se pueden estimar los parámetros del modelo mediante el método de máxima verosimilitud.
4. Distribución α-estable
En la gestión del riesgo es esencial encontrar una distribución que describa los datos financieros de una manera adecuada. Comúnmente los rendimientos financieros no se describen adecuadamente por la distribución normal, ya que los resultados empíricos muestran que los datos financieros son por lo general asimétricos y presentan colas pesadas. Sin embargo, actualmente se emplean otras familias paramétricas que describen datos cuya característica es la presencia de colas pesadas.
Entre estas se encuentra la familia de distribuciones α-estables, la cual es una clase rica de distribuciones de probabilidad que permiten asimetría y colas pesadas y además tienen muchas propiedades matemáticas interesantes. Esta clase de distribuciones fue caracterizada por Paul Lévy en su estudio de sumas de términos independientes idénticamente distribuidos en 1920. La ausencia de expresiones analíticas explícitas (fórmulas cerradas) para la función de densidad de probabilidad y para la función de distribución acumulada de las distribuciones estables (excepto las distribuciones de Gauss, Cauchy y Levy), ha sido un gran inconveniente para su implementación. En la actualidad existen programas informáticos confiables para calcular las funciones de densidad estables, las funciones de distribución y sus cuantiles.
Existen múltiples definiciones y notaciones de variables aleatorias estables.1 En este documento, seguimos la notación y definición presentada por Nolan, la cual caracteriza a las distribuciones estables por cuatro parámetros, presentados a continuación.
Definición. Una variable aleatoria X es estable si, para
cualquier
donde
Una variable aleatoria es simétrica estable si es estable y simétricamente distribuida alrededor del 0, es decir
En general, las distribuciones estables no poseen expresiones analíticas explícitas para la función de densidad de probabilidad (PDF) ni para la función de distribución acumulada (CDF). Una variable aleatoria α-estable X, es comúnmente descrita por su función característica (CF), la cual se define como
Donde:
Esta parametrización es conveniente para propósitos teóricos, pero no para cálculos
numéricos o inferencia estadística, y además no es continua en la vecindad de
Además, para
Otra expresión más simple para la función característica de una variable aleatoria α-estable X que es continua para todos los parámetros es
la cual es llamada por Nolan (1997) la
0-parametrización y la denota como
Si
Con función de densidad de probabilidad
Lo cual no se cumple para la parametrización
En esta investigación se usarán la 0-parametrización y 1-parametrización, debido a
que
En lo sucesivo denotaremos
En estudios empíricos, el modelado de datos financieros se realiza normalmente
mediante distribuciones estables con 1<α<2, las cuales corresponden a la
familia de distribuciones Pareto-Estable (PE). A valores pequeños de α le
corresponden distribuciones más leptocúrticas (el pico de la densidad se hace mayor
y las colas son más pesadas). Por lo tanto, el índice de estabilidad α puede ser
interpretado como una medida de curtosis. Si el parámetro de asimetría β=0, la
distribución de X es simétrica, si β>0, la distribución está sesgada hacia la
derecha y si β<0, la distribución es sesgada a la izquierda. Cuando α=2 y β=0,
La Figura 1 muestra algunas distribuciones α-estable para distintos valores de sus parámetros.

Dado que las distribuciones estables no poseen expresiones analíticas explícitas para la función de densidad de probabilidad ni para la función de distribución acumulada (excepto cuando α=2, estas se calculan numéricamente. Uno de los enfoques para aproximar la función de densidad de probabilidad es aplicando Transformada Rápida de Fourier (FFT) a la función característica (ver Khindanova, Rachev, Schwartz (2001)).
Para resumir brevemente la aproximación basada en la FFT, recordemos que la PDF se puede escribir en términos de la CF como
La integral (10) se puede calcular utilizando N puntos igualmente espaciados a una
distancia h tal que
La integración se puede aproximar mediante
donde
Normalizando el k-ésimo elemento de la sucesión por  , se puede utilizar la
interpolación lineal con el fin de obtener su PDF.
, se puede utilizar la
interpolación lineal con el fin de obtener su PDF.
5. Selección de los datos y estimación de los modelos GARCH
5.1 Descripción de los datos
En esta investigación, se han elegido 5 activos que cotizan en la Bolsa Mexicana de Valores (BMV), pertenecientes a 5 diferentes industrias. Estos activos corresponden a las siguientes empresas: Grupo Financiero Banorte, S.A.B DE C.V., serie O (GFNORTE) uno de los grupos financieros mexicanos más grandes, importantes y sin fusiones con la banca extranjera, cuyo porcentaje de participación en el IPC es del 7.73%; Cemex, S.A.B. DE C.V., serie CPO (CEMEX) compañía global de soluciones para la industria de la construcción, que ofrece productos y servicio a clientes y comunidades en más de 50 países en el mundo cuyo porcentaje de participación en el IPC es del 7.22%; Empresas ICA, S.A.B. DE C.V., (ICA) empresa de ingeniería, procuración y construcción más grande de México dedicada a la construcción pesada, industrial o urbano así como a diversas obras de ingeniería y servicios; Grupo México, S.A.B. DE C.V., serie B (GMEXICO) es uno de los principales productores de cobre en el mundo y además, cuenta con el servicio ferroviario de carga multimodal más grande de México, y con una división de infraestructura con gran potencial de crecimiento cuyo porcentaje de participación en el IPC es de 6.61%; y Wal-Mart de México, S.A. DE C.V., (WALMEX) empresa cuyo porcentaje de participación en el IPC es del 8.19%.
La moneda de referencia a utilizar es el peso mexicano, ya que es la moneda de cotización de las empresas. Las cinco series que conforman la canasta que se ha elegido contienen información de los precios diarios de cierre de cada activo, excluyendo fines de semana y festivos.
La muestra total inicia el 3 de enero del 2002 y finaliza el 31 de diciembre del 2015, por lo cual se tienen 3526 observaciones, para cada uno de los activos. La muestra total se divide en dos períodos, esto con la finalidad de evaluar el desempeño de la estimación del modelo VaR α-estable durante y después de períodos de alta volatilidad, como la crisis financiera del 2008. El primer período inicia el 3 de enero del 2002 y finaliza el 31 de diciembre del 2009 y el segundo comprende el período del 4 de enero del 2010 al 31 de diciembre del 2015. Por tanto, el total de observaciones para cada serie correspondientes a cada período son 2017 y 1509 respectivamente.
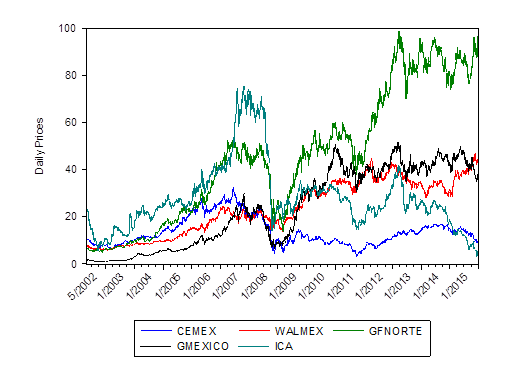
La Figura 2 muestra la gráfica del comportamiento de los precios diarios de cierre de los activos. Cabe señalar que los gráficos y tablas que se exponen en este capítulo son de elaboración propia a partir de las cotizaciones oficiales.
Sea
Por lo cual, la tasa de rendimiento diario de la acción se obtiene aplicando logaritmo a la serie de precios de las acciones
dado que la tasa de rendimientos diarios es muy pequeña, consideramos el porcentaje, es decir
La Figura 3 es la representación gráfica de los rendimientos.
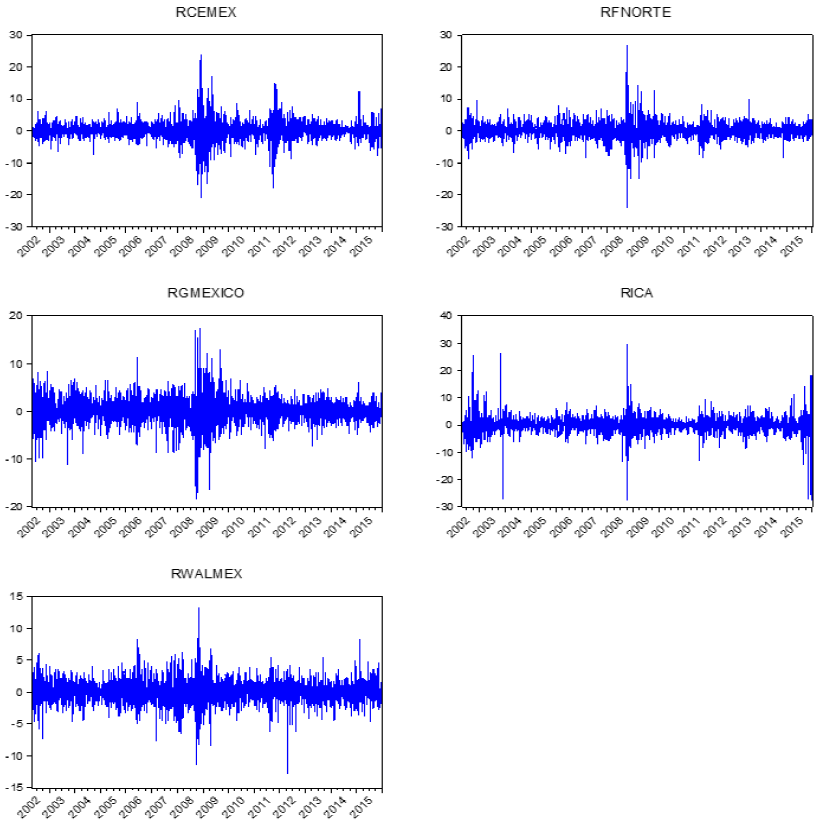
En la Tabla 1 se presentan los estadísticos de los rendimientos para la muestra total y los dos períodos, además, mediante el estadístico Jarque-Bera2 se contrasta la normalidad de los mismos.
Tabla 1. Estadística descriptiva de los rendimientos.
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Sector | Materiales | Financiero | Minero | Industrial | Consumo Básico |
| Periodo 2002-2015 | |||||
| Media | 0.0207 | 0.0840 | 0.0399 | 0.0160 | 0.0498 |
| Varianza | 4.7602 | 5.5260 | 8.5836 | 6.2503 | 3.3197 |
| Asimetría | 0.0497 | 0.0961 | -0.8059 | 0.3374 | -0.0230 |
| Curtosis | 22.0171 | 16.2460 | 14.5645 | 26.5369 | 5.7584 |
| Jarque-Bera | 53134.02 | 25783.00 | 20029.75 | 81456.49 | 1118.161 |
| Probabilidad (JB) | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Periodo 2002-2009 | |||||
| Media | 0.0222 | 0.1131 | 0.1760 | 0.0098 | 0.0764 |
| Varianza | 7.6737 | 7.2571 | 8.8497 | 9.3049 | 3.4883 |
| Asimetría | 0.0503 | 0.0832 | -0.1803 | 0.3659 | 0.0508 |
| Curtosis | 14.7608 | 15.7323 | 7.52237 | 20.6039 | 6.7125 |
| Jarque-Bera | 11625.27 | 13626.49 | 1729.735 | 26089.19 | 1159.199 |
| Probabilidad (JB) | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Periodo 2010-2015 | |||||
| Media | 0.0187 | 0.0452 | -0.1421 | 0.0243 | 0.0142 |
| Varianza | 0.8683 | 3.2128 | 8.1757 | 2.1707 | 3.0942 |
| Asimetría | -0.3246 | 0.0472 | -1.7710 | -0.4317 | -0.1488 |
| Curtosis | 5.8428 | 5.0329 | 25.3131 | 8.3565 | 4.0706 |
| Jarque-Bera | 534.61 | 260.39 | 32092.54 | 1850.86 | 77.6382 |
| Probabilidad (JB) | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
Fuente: Elaboración propia
En la Tabla 1 se observa que tanto como para la muestra completa como para los dos períodos el sesgo de los datos es diferente de cero, es decir los datos son asimétricos. Por otro lado, la curtosis es mayor a 3, lo cual sugiere que los datos presentan colas pesadas. Además, el estadístico Jarque-Bera es también muy grande y estadísticamente significativo, por lo cual la hipótesis de normalidad se rechaza. Por lo tanto, la distribución Gaussiana no es una buena opción para modelar los datos. Por último, se observa que en el período 2002-2009 existe un aumento significativo de la volatilidad.
Dado que las series de rendimientos no son idéntica e independientemente distribuidas a pesar de que muestran poca correlación serial, un modelo ARMA por sí solo no las describiría adecuadamente, por lo cual, se emplea un modelo ARMA-GARCH. Para determinar el orden del modelo ARMA se analiza la función de autocorrelación parcial muestral, dado que las series de rendimientos muestran poca correlación serial, el componente ARMA es innecesario, es decir, elegimos p=q=0. Para el modelo GARCH con el objetivo de evitar carga computacional se utiliza el modelo más simple (m=S=1) con una media, constante, distinta de cero.
Dado que el estadístico Jarque-Bera permite rechazar la hipótesis de normalidad, la distribución Gaussiana no es una buena opción para modelar los datos. En esta investigación, se considera la distribución estable, la cual describe tanto la asimetría como la curtosis de los datos.
6. Modelo Heterocedástico condicional α-estable
Como se observa en la Tabla 1 y la Figura 3, las series de rendimientos muestran no sólo asimetría y colas pesadas, sino también clúster de volatilidad variable en el tiempo. Por lo tanto, para describir tanto la asimetría como las colas pesadas se emplea la distribución α-estable para calcular la innovación en el modelo GARCH.
Por otro lado, como consecuencia de las colas pesadas, no todos los momentos están definidos en la distribución α-estable, excepto cuando α=2, por lo cual se utiliza el TS-GARCH (especificación propuesta por Taylor (1986) y Schwert (1989)). El modelo se describe a continuación.
Los rendimientos de las acciones se modelan como
donde
Para comparar la bondad de ajuste de la distribución α-estable, se consideran dos
pruebas de hipótesis: la prueba de Kolmogorov-Smirnov (KS) y la prueba de
Anderson-Darling (AD). La hipótesis nula de ambas pruebas es
El test KS calcula el estadístico de contraste:
Donde F( ) es la frecuencia acumulada teórica y
Si los valores observados
En el caso de la prueba AD el estadístico de prueba se define como
De esta forma, para un nivel de significancia α, la regla de decisión para este contraste es:
La Tabla 2 muestra los valores observados de
D,
Además, la estimación del test de Razón de Verosimilitud (LR) favorece el modelo estable. El test LR se define como
En el cual la hipótesis nula es H0: Los datos siguen una distribución normal vs H1: Los datos siguen una distribución estable. En la Tabla 2 se muestran los valores del test LR, los cuales exceden el valor crítico (al 99% de confianza) de la distribución Ji-cuadrada con dos grados de libertad. Esto significa un claro rechazo de la hipótesis Gaussiana.
Tabla 2. Pruebas de bondad de ajuste.
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| D | 0.0147 | 0.0195 | 0.0183 | 0.0174 | 0.0181 |
| p-value | 0.4259 | 0.1365 | 0.1877 | 0.2338 | 0.1986 |
| A2 | 1.8582 | 1.7761 | 1.9649 | 1.5025 | 1.8341 |
| p-value | 0.1032 | 0.1216 | 0.1001 | 0.1727 | 0.1167 |
| LR | 143.4259 | 160.4371 | 87.4576 | 555.0117 | 172.4115 |
| Periodo 2002-2009 | |||||
| D | 0.0155 | 0.0278 | 0.0213 | 0.0263 | 0.0188 |
| p-value | 0.7174 | 0.0875 | 0.3147 | 0.1218 | 0.4726 |
| A2 | 1.5243 | 1.9868 | 1.8953 | 1.690 | 1.7311 |
| p-value | 0.1708 | 0.1009 | 0.1137 | 0.1198 | 0.1247 |
| LR | 66.3914 | 113.9657 | 47.9006 | 325.0967 | 42.6780 |
| Periodo 2010-2015 | |||||
| D | 0.0167 | 0.0142 | 0.0175 | 0.0155 | 0.0193 |
| p-value | 0.7892 | 0.9204 | 0.7403 | 0.8611 | 0.6266 |
| A2 | 1.6921 | 1.8988 | 1.8064 | 1.9521 | 1.8998 |
| p-value | 0.1203 | 0.1178 | 0.1177 | 0.1097 | 0.1165 |
| LR | 79.2385 | 38.1091 | 25.9290 | 189.9940 | 121.0522 |
Fuente: Elaboración propia
Para estimar los parámetros en (12), se utiliza el método de máxima verosimilitud (MLE)3, donde la función de densidad de probabilidad de z t se aproximó mediante el programa STABLE4. Los parámetros estimados de la distribución α-estable para la muestra completa y los dos períodos se presentan en la Tabla 3.
Tabla 3. Parámetros de la distribución α-estable.
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| α | 1.7915 | 1.8192 | 1.8811 | 1.7612 | 1.8348 |
| β | -0.0000 | 0.1108 | -0.1428 | -0.0000 | -0.0896 |
| γ | 0.6294 | 0.6305 | 0.6619 | 0.5831 | 0.6346 |
| δ | -0.0014 | -0.0170 | 0.0117 | 0.0101 | 0.0067 |
| Periodo 2002-2009 | |||||
| α | 1.8314 | 1.7556 | 1.8686 | 1.7712 | 1.8678 |
| β | 0.0939 | 0.0722 | -0.0000 | 0.0000 | 0.0000 |
| γ | 0.6413 | 0.6069 | 0.6579 | 0.5781 | 0.6542 |
| δ | -0.0079 | -0.0094 | 0.0090 | 0.0010 | -0.0058 |
| Periodo 2010-2015 | |||||
| α | 1.7612 | 1.9255 | 1.9115 | 1.7380 | 1.8129 |
| β | -0.1042 | 0.4094 | -0.5097 | -0.0957 | -0.1642 |
| γ | 0.6165 | 0.6708 | 0.6726 | 0.5979 | 0.6171 |
| δ | 0.0087 | -0.0268 | 0.0351 | 0.0389 | 0.0256 |
Fuente: Elaboración propia
La Tabla 4 muestra las estimaciones obtenidas por el método de máxima verosimilitud para el modelo TS-GARCH, basado en la distribución α-estable, tanto para la muestra completa como en los dos períodos descritos anteriormente.
Tabla 4. Parámetros del modelo TS-GARCH(1,1) con hipótesis α-estable (errores estándar están en paréntesis).
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| a0 | 0.0433 (0.001823) |
0.0722 (0.008214) |
0.0439 (0.003792) |
0.0862 (0.003805) |
0.0475 (0.007496) |
| a1 | 0.0846 (0.004608) |
0.1235 (0.005897) |
0.0841 (0.004886) |
0.1208 (0.004776) |
0.0759 (0.006578) |
| b1 | 0.9154 (0.003722) |
0.8731 (0.006857) |
0.9159 (0.003823) |
0.8792 (0.004267) |
0.9142 (0.008189) |
| Periodo 2002-2009 | |||||
| a0 | 0.0418 (0.005232) |
0.1041 (0.015910) |
0.0629 (0.010051) |
0.2684 (0.016074) |
0.0343 (0.007693) |
| a1 | 0.0848 (0.006850) |
0.1409 (0.009336) |
0.0990 (0.008893) |
0.2095 (0.008452) |
0.0802 (0.008067) |
| b1 | 0.9152 (0.006522) |
0.8522 (0.012198) |
0.9010 (0.008867) |
0.7521 (0.009790) |
0.9198 (0.008768) |
| Periodo 2010-2015 | |||||
| a0 | 0.0439 (0.006216) |
0.0677 (0.011246) |
0.0553 (0.003760) |
0.0536 (0.036359) |
0.9461 (0.075880) |
| a1 | 0.0829 (0.008406) |
0.1017 (0.011084) |
0.0609 (0.006455) |
0.0920 (0.015397) |
0.1787 (0.007796) |
| b1 | 0.9171 (0.011150) |
0.8823 (0.009366) |
0.9206 (0.004277) |
0.9080 (0.032953) |
0.2207 (0.024740) |
Fuente: Elaboración propia.
La Figura 4 muestra las gráficas de las funciones de densidad estables ajustadas a los datos correspondientes a la muestra completa con los parámetros estimados.
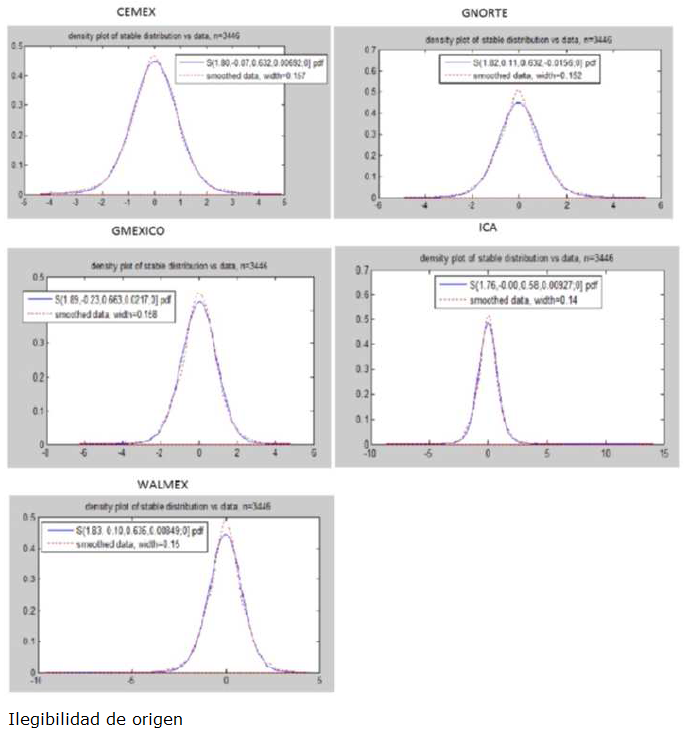
Fuente: Elaboración propia
Figura 4: Funciones de densidad estables ajustadas a las series de datos.
6.1 Modelo Heterocedástico condicional normal
Los rendimientos de las acciones se modelan como como
La Tabla 5 muestra las estimaciones obtenidas por el método de máxima verosimilitud para el modelo GARCH, basado en la distribución Normal, tanto para la muestra completa como para los dos periodos.
Tabla 5. Parámetros del modelo GARCH(1,1) con hipótesis normal (errores estándar están en paréntesis).
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| a0 | 0.0617 (0.00924872) |
0.1385 (0.017730) |
0.0728 (0.0127755) |
0.0710 (0.00740924) |
0.0810 (0.0113105) |
| a1 | 0.0767 (0.00533699) |
0.1123 (0.00718923) |
0.0727 (0.00629053) |
0.0908 (0.00442899) |
0.0609 (0.00610394) |
| b1 | 0.9133 (0.00562217) |
0.8604 (0.00823736) |
0.9149 (0.00745096) |
0.9092 (0.00309637) |
0.9104 (0.0085109) |
| Periodo 2002-2009 | |||||
| a0 | 0.0783 (0.0129735) |
0.2275 (0.0370843) |
0.1396 (0.0275856) |
0.2067 (0.0165732) |
0.0661 (0.0141218) |
| a1 | 0.0823 (0.00846186) |
0.1346 (0.0116431) |
0.0886 (0.00955057) |
0.1087 (0.00783608) |
0.0709 (0.00809405) |
| b1 | 0.9030 (0.00857277) |
0.8304 (0.0144463) |
0.8954 (0.01072) |
0.8737 (0.00629455) |
0.9099 (0.00953091) |
| Periodo 2010-2015 | |||||
| a0 | 0.0375 (0.0114183) |
0.0836 (0.0162941) |
0.0774 (0.0306987) |
0.0288 (0.00803553) |
1.5437 (0.214255) |
| a1 | 0.0711 (0.0067722) |
0.0797 (0.0100462) |
0.0516 (0.0111052) |
0.0715 (0.00602741) |
0.1842 (0.029656) |
| b1 | 0.9253 (0.00678081) |
0.8948 (0.00981304) |
0.9229 (0.0193198) |
0.9285 (0.00451655) |
0.1185 (0.109627) |
Fuente: Elaboración propia.
6.2 Estimaciones del VaR
En esta sección se estima el VaR mediante un modelo heterocedástico condicional que asume que los rendimientos siguen: 1) una distribución estable, y 2) una distribución normal.
El VaR se calcula considerando el horizonte de tiempo de un día
Paso 1 Estimar los parámetros de los modelos GARCH en (12) y (13) empleando el método de máxima verosimilitud.
Paso 2 Estimar los parámetros de la distribución estable y normal en (12) y (13) respectivamente, empleando el método de máxima verosimilitud.
Paso 3 Calcular
Paso 4 Calcular
Paso 5 Realizar S simulaciones de
Paso 6 Estimar los rendimientos simulados
Paso 7 Estimar el VaR como el negativo del q-ésimo cuantil de la distribución de probabilidad simulada.
En la presente investigación el VaR se estima a un nivel de confianza de 99% y 95%, respectivamente. Ambas estimaciones se presentan en las Tablas 6 y 7, respectivamente.
Tabla 6 VaR a un nivel de confianza de 99%.
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| Normal | -0.5735 | -3.3323 | -1.3339 | -0.7998 | -1.3766 |
| α-estable | -0.9909 | -5.8681 | -2.1052 | -1.0364 | -2.5046 |
| Periodo 2002-2009 | |||||
| Normal | -0.4580 | -1.7571 | -1.1547 | -1.3564 | -0.9971 |
| α-estable | -0.8063 | -3.3437 | -1.8983 | -2.7798 | -1.6413 |
| Periodo 2010-2015 | |||||
| Normal | -0.5990 | -3.4170 | -1.3092 | -0.7841 | -1.4847 |
| α-estable | -1.0665 | -4.7365 | -2.0151 | -1.1588 | -2.7530 |
Fuente: Elaboración propia.
Tabla 7. VaR a un nivel de confianza de 95%.
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| Normal | -0.4067 | -2.3214 | -0.9581 | -0.5764 | -0.9523 |
| α-estable | -0.5950 | -3.6855 | -1.3299 | -0.6282 | -1.5278 |
| Periodo 2002-2009 | |||||
| Normal | -0.3257 | -1.2113 | -0.7721 | -0.9810 | -0.7054 |
| α-estable | -0.4980 | -1.8252 | -1.2311 | -1.5932 | -1.0998 |
| Periodo 2010-2015 | |||||
| Normal | -0.4123 | -2.3945 | -0.9248 | -0.5742 | -1.0640 |
| α-estable | -0.6230 | -3.3121 | -1.3486 | -0.6839 | -1.7168 |
Fuente: Elaboración propia.
En ambas estimaciones del VaR, se observa que el modelo α-estable proporciona valores mayores a las estimaciones basadas en la distribución normal, es decir, el modelo del VaR α-estable proporciona estimaciones de las pérdidas potenciales más conservadoras, lo cual es preferido por las instituciones financieras.
6.3 Evaluación del desempeño del VaR
En esta sección, se emplea la prueba llamada backtesting, para evaluar el desempeño del modelo VaR bajo el supuesto de que los rendimientos siguen una distribución normal y estable, respectivamente.
Sea 1-q el nivel de confianza para el cálculo del VaR y k el número de observaciones históricas más recientes empleadas para pronosticar el VaR actual. Entonces, mediante los datos históricos de los dos años más recientes para predecir el VaR actual, se toma k=502, es decir, este valor se utiliza tanto para la muestra total como para los dos períodos considerados.
Si se tiene una serie de rendimientos históricos con un total de n datos, entonces la función indicadora del número de veces en que las pérdidas observadas exceden el VaR se define de la siguiente manera:
donde
El número de veces
De acuerdo a esta distribución se tiene que el número de violaciones al VaR
esperado (media) es
Luego se considera la hipótesis nula
la cual sigue una distribución binomial con parámetros k y q. La hipótesis nula se rechaza a un nivel de significancia x, si
donde t es el tiempo actual y k es la longitud del intervalo de prueba.
Para valores grandes de K y niveles de confianza del VaR suficientemente altos, la distribución binomial se puede aproximar mediante la distribución normal. Por lo tanto, la hipótesis nula se rechaza a un nivel de significancia x, si
donde
El rango para el cual el número de veces
Tabla 8. Rango y frecuencia de violaciones del VaR aceptables a un nivel de significancia del 1%.
| VaR1-q | k | Rango de violaciones del VaR aceptable | Frecuencia de violaciones del VaR aceptables |
| 99% | 502 |
|
|
| 95% | 502 |
|
|
Fuente: Elaboración propia.
Con el objetivo de investigar si el modelo propuesto VaR α-estable tiene la capacidad de predecir el VaR en períodos de alta volatilidad como la crisis del 2008, se evalúa el desempeño del VaR en períodos distintos. En particular para el período 2002-2009, se emplean las observaciones históricas de los años 2008 y 2009 para pronosticar el VaR durante períodos de gran volatilidad.
Los resultados del backtesting se muestran en las Tabla 9 y Tabla 10. Los números resaltados en negritas, indican que el número excedió el rango y frecuencia de violaciones del VaR aceptables al 1% de significancia.
Tabla 9. Backtesting del VaR al nivel de confianza de 99%.
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| Normal | 9 | 4 | 5 | 20 | 8 |
| α-estable | 0 | 1 | 1 | 4 | 0 |
| Periodo 2002-2009 | |||||
| Normal | 16 | 14 | 10 | 14 | 12 |
| α-estable | 0 | 2 | 2 | 3 | 1 |
| Periodo 2010-2015 | |||||
| Normal | 12 | 4 | 7 | 8 | 6 |
| α-estable | 1 | 1 | 0 | 4 | 0 |
Fuente: Elaboración propia.
Tabla 10. Backtesting del VaR al nivel de confianza de 95%
| Series | CEMEX | GFNORTE | GMEXICO | ICA | WALMEX |
| Periodo 2002-2015 | |||||
| Normal | 33 | 22 | 21 | 33 | 26 |
| α-estable | 7 | 3 | 4 | 11 | 5 |
| Periodo 2002-2009 | |||||
| Normal | 43 | 36 | 35 | 41 | 30 |
| α-estable | 21 | 14 | 8 | 13 | 14 |
| Periodo 2010-2015 | |||||
| Normal | 32 | 21 | 24 | 31 | 21 |
| α-estable | 10 | 5 | 4 | 15 | 5 |
Fuente: Elaboración propia.
En la Tabla 9 se puede observar que durante el período de la crisis financiera del 2008 el número de violaciones del VaR, bajo el supuesto de normalidad al 99% para las series de rendimientos (excepto GMEXICO), se encuentran por encima del intervalo admisible, lo que implica que el VaR al 99% bajo el supuesto de normalidad subestima significativamente las pérdidas potenciales durante períodos de crisis.
En contraste, el número de violaciones del modelo VaR α-estable al 99% proporciona un número admisible de excepciones durante el período de crisis, lo cual sugiere que este modelo muestra una precisión satisfactoria durante períodos de turbulencias financieras para niveles de confianza altos.
Por otro lado, para el período posterior a la crisis del 2008 ambos modelos proporcionan estimaciones del VaR al 99% dentro del rango permitido (excepto CEMEX para el caso normal), sin embargo, el número de veces en el cual es excedido el VaR es menor para el modelo VaR α-estable, lo cual sugiere que este modelo proporciona estimaciones de las pérdidas potenciales más conservadoras.
En la Tabla 10 se puede observar que las estimaciones del VaR al 95% bajo el supuesto de normalidad durante el período de crisis, sobrepasan el rango permitido en el caso de CEMEX e ICA. Por otro lado, la estimación del VaR α-estable se encuentra ligeramente debajo del rango permitido para el caso de la serie GMEXICO.
Para el período posterior a la crisis las estimaciones del VaR al 95% bajo el supuesto de normalidad se encuentran dentro del rango permitido. Sin embargo, los resultados del modelo VaR α-estable no son satisfactorios, el número de violaciones del VaR de las series (excepto ICA) están por debajo del rango permitido.
7. Conclusiones
En esta investigación se consideró a la familia de distribuciones estables en la estimación del VaR como una alternativa en el mercado financiero mexicano y se propuso comparar las estimaciones del VaR obtenidas bajo la hipótesis estable y gaussiana durante y después de la crisis financiera del 2008.
Los resultados estadísticos sugieren que el modelo VaR α-estable proporciona estimaciones del VaR al 99% y 95% más precisas en períodos de alta volatilidad, es decir, las estimaciones del VaR son más eficientes bajo el supuesto de que los rendimientos siguen una distribución estable durante períodos de turbulencias financieras.
Por otro lado, los resultados muestran que el modelo bajo la hipótesis gaussiana subestima significativamente el VaR al 99% durante períodos de crisis, por el contrario en el período posterior a la crisis los resultados son aceptables, sin embargo las estimaciones del VaR α-estable exceden un menor número de veces el rango permitido, es decir estas son más conservadoras.
Además, en el período posterior a la crisis las estimaciones del VaR al 95% bajo la hipótesis gaussiana se encuentran dentro del rango permitido y en contraste las obtenidas bajo el modelo α-estable se encuentran por debajo del rango admisible, lo cual sugiere que este modelo sobrestima el VaR al 95% durante este período.
Concluyendo, esta investigación proporciona evidencia de que el modelo VaR α-estable estima satisfactoriamente el VaR para niveles altos de confianza incluso en períodos de alta volatilidad.
En contraste, en períodos de relativa tranquilidad para niveles de confianza bajos
este modelo sobrestima las pérdidas potenciales. Al respecto, se sugiere desarrollar
un trabajo futuro considerando el grado de persistencia de la volatilidad de los
rendimientos. En esta línea, es posible considerar el trabajo de Brooks, Clare y Persand (2000) en el cual se
argumenta que los modelos GARCH típicamente exageran el grado de persistencia de la
volatilidad de los rendimientos y sugieren una modificación simple del modelo GARCH,
la cual consiste en la introducción de una variable proxy, la cual explica el nivel
de persistencia de la volatilidad y señalan mejora la precisión de las estimaciones.
Sin embargo, el trabajo de Brooks, Clare y Persand
(2000) se desarrolla bajo la hipótesis normal en la perturbación
aleatoria del modelo GARCH, dado que en este trabajo se emplea la distribución
Asimismo, en una investigación adicional, sería conveniente desarrollar un trabajo futuro considerando algunas otras distribuciones que también capturen las características empíricas de las series de datos financieros y comparar su desempeño con el modelo α-estable aquí propuesto. Además, se sugiere construir en otro trabajo futuro un portafolio de inversión y emplear funciones cópula para describir las correlaciones entre los rendimientos de las acciones empleando la distribución estable como la distribución marginal de los activos que conforman el portafolio.

