











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. Introducción
Los gráficos estadísticos son parte de la cultura estadística necesaria en la sociedad actual. Además, son un instrumento esencial en el análisis estadístico, pues permiten obtener información no visible en los datos, mediante su representación sintetizada. Ello siempre que se elija un gráfico adecuado y no se introduzcan errores en su construcción, pues dichos errores pueden llevar a conclusiones incorrectas en el análisis estadístico posterior.
En España su estudio se inicia en el primer ciclo de la Educación Primaria (Ministerio de Educación y Ciencias, MEC, 2006; Ministerio de Educación, Cultura y Deportes, MECD, 2014), lo que requiere la adecuada formación de los profesores de este nivel educativo. El análisis de los errores que cometen los futuros profesores en la construcción de gráficos estadísticos es importante para proponer acciones formativas dirigidas a los mismos. Arteaga y Batanero (2010) clasificaron los errores cometidos por una muestra de 207 futuros profesores españoles, en los gráficos que construyeron al comparar dos variables como parte de una tarea abierta.
El objetivo del presente trabajo es completar el anterior en varios puntos: a) Primeramente, se clasif ican los errores en los gráficos construidos por los mismos futuros profesores durante la misma sesión para comparar otros dos pares de variables, que no fueron analizados en el estudio de Arteaga y Batanero (2010); b) Seguidamente, se utiliza la idea de conflicto semiótico (Godino, Batanero & Font, 2007) para proporcionar una explicación a una parte de estos errores; c) Finalmente, se estudia la independencia entre el uso o no del ordenador en la construcción de los gráficos y la distribución de gráficos correctos, parcialmente correctos e incorrectos.
A continuación presentamos los fundamentos, método, resultados y discusión, finalizando con algunas implicaciones para la formación de profesores.
2. Marco teórico y antecedentes
2.1. Marco teórico
Dentro del enfoque onto-semiótico, Godino y Batanero (1998) señalan que en las prácticas matemáticas intervienen objetos ostensivos (símbolos, palabras, elementos gráficos) y no ostensivos (que evocamos al hacer matemáticas). Los símbolos (significantes) remiten a entidades conceptuales (significados) y sirven para facilitar la enseñanza, pero a veces causan dificultades en los estudiantes. Godino y otros (2007) toman de Eco (1977) la noción de "función semiótica" como "correspondencia", que pone en juego tres componentes:
- Un plano de expresión (objeto inicial o signo);
- Un plano de contenido (objeto final o significado del signo, esto es, lo representado);
- Un criterio o regla de correspondencia (código interpretativo que relaciona los planos de expresión y contenido).
Cualquier posible objeto matemático (concepto, propiedad, argumento, procedimiento, etc.) puede jugar el papel tanto de expresión como de contenido, en una función semiótica, y esta complejidad puede explicar algunas dificultades y errores de los estudiantes. Godino y otros (2007) denominan conflicto semiótico a las interpretaciones de expresiones matemáticas por parte de los estudiantes que no concuerdan con las pretendidas por el profesor. Estos conflictos semióticos no son debidos a falta de conocimiento, sino a no haber relacionado adecuadamente los dos términos de una función semiótica. Por tanto, los conflictos semióticos explicarían algunos errores de los estudiantes. De acuerdo a Rojas (2010), esta noción indica que el aprendizaje es una actividad de carácter fuertemente semiótico que debe afrontar, entre otras tensiones, la existente entre lo institucional y lo personal.
2.2. Competencia en la realización de gráficos estadísticos
Varias investigaciones evalúan la construcción de gráficos estadísticos por parte de los estudiantes. Para comprenderlas, es preciso recordar que, en la construcción de gráficos, además de los convenios de construcción, es necesario conocer los elementos estructurales, que según Friel, Curcio y Bright (2001) son los siguientes: (a) El título y las etiquetas, que aportan información sobre el contenido contextual del gráfico y las variables representadas; (b) El marco del gráfico, que incluye los ejes, las escalas y las marcas de referencia en cada eje, y que proporciona información sobre las unidades de medida de las magnitudes representadas; (c) Los especificadores o elementos usados para representar los datos, por ejemplo, los rectángulos en los histogramas.
El primer paso es la elección de un gráfico adecuado, aunque algunos estudiantes, según Li y Shen (1992) utilizan gráficos inadecuados al tipo de variable o problema; por ejemplo, diagramas de barras para representar datos bivariantes. Los autores encuentran también los siguientes problemas en las escalas de los gráficos construidos: (a) Elegir una escala inadecuada (por ejemplo no se cubre todo el campo de variación de la variable representada); (b) Omitir las escalas en alguno de los ejes; (c) No especificar el origen de coordenadas y (d) No proporcionar suficientes divisiones en las escalas.
Wu (2004) encuentra los siguientes errores en la construcción de gráficos: (a) errores en las escalas, (b) errores en títulos o etiquetas (c) problemas de proporcionalidad en un pictograma, (e) confusión entre gráficos parecidos, pero de naturaleza distinta (por ejemplo, entre histograma y gráfico de barras), y (f) confusión entre frecuencia y valor de la variable.
El ordenador en ocasiones contribuye a empeorar los resultados. Ben-Zvi y Friedlander (1997) describen el uso acrítico del software, cuando los estudiantes construyen gráficos rutinariamente, aceptando las opciones por defecto del software, aunque no sean adecuadas.
2.3. Investigaciones sobre comprensión gráfica en futuros profesores
Son pocas las investigaciones centradas en la comprensión gráfica de los profesores, la mayoría de las cuáles son resumidas en González, Espinel y Ainley (2011). Bruno y Espinel (2005) analizan la construcción de gráficos, a partir de una lista de datos, que llevan a cabo futuros profesores. Los errores cometidos incluyen intervalos mal representados, omisión de intervalos de frecuencia nula, o uso de rectángulos no adosados en variables continuas. Aunado a ello, en el polígono de frecuencias no unen las marcas de clase, omiten el intervalo de frecuencia nula o confunden la frecuencia y el valor de la variable. Espinel (2007) evalúa la interpretación de gráficos en futuros profesores, comparando los resultados con los de estudiantes universitarios americanos con un mismo cuestionario, convenientemente traducido. Encontró mayor dificultad en los futuros profesores, sobre todo al predecir la forma de un gráfico a partir de la descripción verbal de variables conocidas o al leer los histogramas.
Monteiro y Ainley (2006, 2007) estudian la competencia de futuros profesores en la lectura de gráficos tomados de la prensa diaria, encontrando que muchos no tenían conocimientos matemáticos suficientes para llevar a cabo dicha lectura. Indican que la dificultad es debida a que la interpretación de gráficos moviliza conocimientos y sentimientos que inciden en su comprensión.
Batanero, Arteaga y Ruíz (2010) evalúan los gráficos producidos por 93 futuros profesores de educación primaria, al trabajar con un proyecto abierto de análisis de datos. Los autores definen los siguientes niveles de complejidad en los gráficos producidos: En el nivel 1 el futuro profesor representa únicamente sus propios datos, sin tener en cuenta el conjunto de datos de la clase; en el nivel 2 se representan todos los datos, en el orden en que fueron recogidos, sin llegar a formar la distribución; en el nivel 3, forma la distribución de frecuencias para cada par de variables a comparar, representado las mismas en distintos gráficos; finalmente en el nivel 4, el estudiante realiza gráficas multivariantes, representando en un mismo gráfico pares de distribuciones a comparar. Dos tercios de los participantes en el estudio realizan gráficos de niveles 3 y 4, donde llegan a formar la distribución de frecuencias de las distintas variables que tuvieron que analizar. También se analizaron los niveles de lectura, según la clasificación de Curcio (1987) y Friel y otros (2001), indicando que pocos de estos profesores alcanzaron el nivel más alto de "lectura más allá de los datos", donde se requiere realizar inferencias sobre datos no incluidos en el gráfico.
3. Metodología del estudio
3.1. Muestra e instrumento de recogida de datos
Participaron en el estudio 207 futuros profesores de Educación Primaria de la Universidad de Granada; en total 6 grupos de estudiantes (aproximadamente 35 por grupo). Los participantes habían estudiado estadística y gráficos estadísticos durante la educación secundaria y en la Universidad en el año académico previo, como parte de la asignatura de Matemáticas y su Didáctica.
Los datos se tomaron como parte de una práctica de la asignatura Currículo de Matemáticas en Educación Primaria. Dicha asignatura, eminentemente práctica, abarca cuatro bloques temáticos: Números y operaciones, Medida y magnitudes, Geometría y, Estadística y Probabilidad. En la citada práctica, los participantes tuvieron que trabajar con un proyecto abierto de análisis de datos, llamado Comprueba tus intuiciones sobre el azar (descrito con detalle en Godino, Batanero, Roa y Wilhelmi, 2008). Los futuros profesores tuvieron que recoger los datos a través de un experimento aleatorio, analizar sus datos y concluir sobre las intuiciones del conjunto de la clase sobre los fenómenos aleatorios. La secuencia de actividades fue la siguiente:
Presentación del problema y del experimento: Los futuros profesores llevaron a cabo un experimento aleatorio para decidir si tenían o no buenas intuiciones sobre el azar. El experimento constaba de dos partes. En la primera (secuencia simulada) cada participante tuvo que inventar una secuencia de 20 lanzamientos de una moneda, sin realmente lanzarla, de tal modo que otra persona pudiera pensar que se trataba de una secuencia aleatoria. En la segunda parte (secuencia real) los participantes anotaron los resultados de lanzar 20 veces una moneda.
Recogida de datos. Cada futuro profesor realizó las dos partes del experimento y registró sus resultados. Seguidamente, se inició una discusión dirigida por el formador de profesores, sobre cómo comparar las secuencias simuladas y reales de todo el grupo. Algunos futuros profesores sugiriendo recoger datos del número de caras y del número de rachas, y comparar sus distribuciones en las secuencias real y simulada. El formador de profesores sugirió comparar también la longitud de la racha más larga. Cada futuro profesor proporcionó los resultados de estas variables en su experimento y todos estos resultados fueron anotados en una hoja de registro (Ver ejemplo de los datos recogidos por 10 de los participantes en la Tabla I).
Instrucciones para el análisis de datos. Al final de la sesión se dio a cada participante una copia de la hoja de registro con los datos obtenidos por el conjunto de la clase para los tres pares de variables a estudiar. Puesto que los estudiantes estaban divididos en 6 grupos, los datos de cada grupo contenían entre 30 y 40 filas. Los futuros profesores tuvieron una semana para realizar un informe escrito, en éste tenían que comparar los tres pares de variables estadísticas para obtener información que les permitiese concluir sobre las intuiciones del conjunto de su grupo de clase. Tuvieron libertad para usar los análisis de datos que creyesen convenientes, así como de realizar o no de gráficos estadísticos. Los informes debían contener el análisis estadístico llevado a cabo por cada participante, así como las conclusiones finales a las que habría llegado.
Puesto que nos interesamos por la capacidad de los futuros profesores a la hora de representar datos estadísticos, tendremos en cuenta sólo aquellos participantes que realizan gráficos en la elaboración de sus informes.
3.2. Método de análisis
Recogidos los informes elaborados por los futuros profesores, se hizo un análisis cualitativo de los gráficos realizados para cada uno de los tres pares de variables que se debían comparar, clasificándolos en tres categorías: básicamente correctos, parcialmente correctos e incorrectos. Cada una de estas categorías fue a su vez subdividida en otras, mediante un proceso inductivo, teniendo en cuenta la actividad matemática realizada por el estudiante y los errores cometidos.
En cada categoría se eligió un ejemplo representativo, y se llevó a cabo un análisis semiótico detallado de dicho ejemplo, siguiendo el método empleado por Mayén, Díaz y Batanero (2009). Para ello, se analizaron las funciones semióticas (Godino, 2002) requeridas durante la elaboración del gráfico, identificando los objetos matemáticos que el estudiante debe aplicar (lenguaje matemático, procedimientos, conceptos y propiedades utilizados).
La comparación de la cadena de funciones semióticas previstas en el proceso correcto de construcción del gráfico con la realmente llevada a cabo por el futuro profesor en cada solución errónea, permite identificar los conflictos semióticos, es decir los significados que no concuerdan con los considerados correctos desde el punto de vista institucional (Godino y otros, 2007). Los resultados obtenidos se describen a continuación.
4. Resultados y discusión
4.1. Errores en la construcción de los gráficos
A pesar de que no se pidió explícitamente la realización de gráficos, al resolver la actividad propuesta, 181 (87.4% de los participantes) utilizaron gráficos para comparar el número de caras en las secuencias real y simulada, 146 (70.5%) para el número de rachas y 129 (62.3%) para la longitud de la racha más larga. La alta proporción de alumnos que construye un gráfico sin habérsele requerido explícitamente indica la necesidad que sienten de construir un gráfico para encontrar alguna información no presente en los datos brutos que le permita resolver el problema. La proporción de gráficos es mayor en el número de caras que en las otras dos variables al ser esta variable la más familiar para los futuros profesores.
A continuación se describen las diferentes categorías en que se ha clasificado los gráficos producidos por los futuros profesores, según presencia o no de errores en su construcción y en caso de haber errores, según el tipo de error.
C1. Gráficos básicamente correctos. Muchos participantes realizaron gráficos correctos, lo que supone ser capaz de elegir un gráfico adecuado al tipo de problema y a las variables representadas, tener en cuenta los convenios de construcción y elementos estructurales (Friel y otros, 2001), construir adecuadamente las escalas y representar los datos correctamente, incluyendo rótulos y etiquetas claras y precisas.
Algunos de estos gráficos son originales, en el sentido de no ser incluidos en la enseñanza recibida. Por ejemplo, en la Figura 1 a el participante inventa un gráfico no estándar para presentar los resultados de su experimento, donde representa, por un lado, el número acumulado de caras y, por otro, el de cruces, lo que permite visualizar la longitud de la racha más larga de cada uno de los dos resultados. Hemos considerado correctos estos gráficos, pues Watson (2006) sugiere permitir a los alumnos crear gráficos originales, siempre que no contengan incorrecciones. Otros gráficos contienen líneas innecesarias o usan líneas curvas en vez de rectas (ver figura 1b), pero no añaden dificultad a la lectura del gráfico, por lo que se ha considerado básicamente correcto.

A continuación se presentan las categorías encontradas para los gráficos parcialmente correctos (que únicamente tienen errores en las escalas o rótulos) e incorrectos. Para la primera categoría realizamos un análisis semiótico completo, que permite detectar la existencia de conflictos semióticos (Godino, 2002). En el resto de categorías, por razones de extensión comentamos brevemente los conflictos encontrados sin incluir el análisis completo realizado.
C2. Gráfico parcialmente correcto (con errores de escala). Los rótulos de los ejes y las etiquetas de las escalas son parte importante del gráfico, ya que proporcionan información contextual de las variables representadas y unidades de medida utilizadas (Curcio, 1987). Watson (2006) indica tener precaución con las escalas, pues la información que se quiere transmitir con el gráfico puede ser manipulada a través de ellas. Sin embargo, algunos futuros profesores comenten los siguientes errores:
C2.1. Escalas no proporcionales. Cuando construyen escalas no proporcionales a las magnitudes representadas, las distancias que deberían ser iguales entre pares distintos de puntos, no lo son. En la Figura 2 mostramos un ejemplo y su análisis semiótico, donde se desglosan los objetos puestos en juego en su realización, tanto de manera implícita como explícita. No se tiene en cuenta la situación-problema, ya que para todos los estudiantes fue la misma (realización del proyecto estadístico) y tampoco los argumentos, pues nos centramos sólo en los errores de construcción del gráfico y no los de lectura.

Figura 2 Ejemplo de análisis semiótico de un gráfico en la categoría 2.1 (escalas no proporcionales)
Para realizar el gráfico mostrado en la Figura 2, el futuro profesor tendrá que utilizar los conceptos de experimento aleatorio (lanzar la moneda) y variable aleatoria (las variables bajo estudio) así como las variables estadísticas correspondientes a los datos recogidos, formando las distribuciones de estas variables para representarlas. Al construir los ejes necesita las ideas de representación cartesiana, números naturales y su orden. Tendrá que determinar el máximo y mínimo de la distribución (rango), así como de las frecuencias para elegir una escala, marcando en ella los valores numéricos necesarios. Puesto que elige un diagrama de barras, ha de establecer una correspondencia (función semiótica) entre cada valor de la variable y la barra, así como entre la altura de cada barra y la frecuencia del valor que representa. Usa lenguaje gráfico verbal y numérico, así como colores para diferenciar las categorías. Lleva a cabo diferentes procedimientos: clasificación de datos, cálculo de frecuencias, representación de escalas en los ejes y representación de frecuencias mediante la altura de distintas barras. Todos estos elementos los usa correctamente, pero observamos dos conflictos semióticos: por un lado, la escala utilizada en el eje Y para representar las frecuencias no es proporcional, ya que, por ejemplo, la distancia, en el eje vertical, entre 2 y 5 es la misma que entre 5 y 14 y no sigue los convenios de representación de números naturales en la recta numérica. Luego falla al poner en correspondencia la proporcionalidad numérica y geométrica. Un segundo conflicto semiótico es que el estudiante no centra las barras del diagrama en los valores numéricos, es decir, el conflicto se produce al no interpretar correctamente el convenio de construcción de dicho gráfico.
C2.2. Valores numéricos faltantes en la recta real. Bruno y Espinel (2005) describieron algunas representaciones erróneas de los números naturales en la recta real, elaboradas por futuros profesores. Entre ellas destacamos la omisión de los valores de la variable que tienen frecuencia nula (Figura 3). Este error supone un fallo del sentido numérico de los futuros profesores, pues la representación adecuada de números naturales en la recta real es un componente del mismo. El futuro profesor ha aprendido que en el diagrama de barras ha de incluir una barra con altura proporcional a la frecuencia de cada valor de la variable. Implícitamente el formador de profesores quiso dar a entender que "cada valor de la variable" incluye todos los valores del rango, incluyendo los de frecuencia nula. Pero el futuro profesor sólo representa los valores de la variable que han aparecido en el experimento. Es decir, hay un conflicto semiótico de interpretación de la expresión "cada valor de la variable".

C2.3. Rótulos confusos, valores erróneos en las escalas o falta escala. Las palabras que aparecen en el título del gráfico, los rótulos de los ejes y las etiquetas de las escalas son parte esencial del gráfico (Curcio, 1987), pues proporcionan las claves necesarias para comprenderlo. A pesar de ello, y como muestran Bruno y Espinel (2005), muchos futuros profesores tienen dificultades en incluir un rótulo correcto y significativo. En nuestro trabajo son muchos los que incluyen títulos o etiquetas imprecisos, aunque pocos realizan gráficos con títulos o etiquetas totalmente incorrectas o ausentes.
C2.4. Barras no centradas. Las variables estadísticas que tuvieron que estudiar los futuros profesores para realizar el proyecto fueron discretas con valores enteros. A pesar de ello, muchos de ellos construyeron histogramas, que suelen usarse para representar variables continuas y, cuando es necesario, para agrupar los valores de la variable en intervalos. Muchos de estos histogramas son realmente gráficos de barras en los que éstas están unidas unas a otras, como si se tratase de una variable continua. Tanto en los histogramas como en los gráficos de barras algunos participantes no centran las barras o rectángulos en las marcas de clase, aunque las variables en estudio toman solamente valores enteros (Figura 2). Este error fue detectado en futuros profesores por Bruno y Espinel (2005) y Espinel (2007).
C2.5. Representación incorrecta de intervalos de valores en el eje X. Algunos participantes que representan histogramas, al representar los intervalos, tratan intervalos con extremo común como si fuesen intervalos disjuntos. Este error, descrito por Bruno y Espinel (2005), se presenta sobre todo entre los que han utilizado la hoja Excel para realizar sus gráficos. En el ejemplo mostrado en la Figura 4a, subyace una confusión entre histograma y diagrama de barras, y entre los tipos de datos en que pueden aplicarse en uno y en otro. Hay también falta de comprensión del significado de un intervalo de valores en la recta numérica y del propósito del área en un histograma, que es proporcional a la frecuencia de los valores representados. Además, hay confusión entre el significado de los valores extremos de un intervalo en la recta numérica y de la marca de clase del intervalo. El error de este futuro profesor puede haber sido provocado por un uso acrítico del software (Ben-Zvi & Friedlander, 1997), al usar directamente las opciones por defecto de Excel sin cuestionarlas.

C2.6. Escala inapropiada. Li y Shen (1992) encontraron algunos estudiantes que construían una escala que no cubría el campo de variación de la variable representada o con una subdivisión excesiva. En nuestro estudio hemos encontrado estos errores, así como el de utilizar escalas demasiado amplias para el objetivo pretendido (Figura 4b). En el ejemplo mostrado, el gráfico, además, presenta simultáneamente la distribución de número de caras y el número de rachas que no son directamente comparables. Watson (2006) indica la importancia de ser cuidadosos en la construcción de las escalas y Wainer (1997) muestra ejemplos tomados de la prensa en los que una escala inadecuada puede llegar a esconder relaciones importantes entre los datos.
C3. Gráfico incorrecto. Se trata de gráficos claramente inadecuados para el problema planteado. Hemos encontrado las siguientes subcategorías:
C3.1. Altura de la barra, área del rectángulo, o del sector circular, no proporcional a la frecuencia. Supone un conflicto de interpretación de los convenios de construcción de los distintos gráficos. Un ejemplo se muestra en la Figura 5a, donde es difícil leer la frecuencia asociada a cada valor de la variable debido a que los sectores del gráfico no tienen amplitud proporcional a las frecuencias y no se incluyen los valores de dichas frecuencias en el gráfico. El futuro profesor debiera haber dividido la amplitud total del círculo (360o) entre el número de alumnos de la clase, representando, posteriormente, la frecuencia de cada valor de la variable mediante un sector circular con amplitud proporcional a dicha frecuencia. El sujeto falla al aplicar esta proporcionalidad, mostrando un conflicto consistente en no establecer una correspondencia entre la proporcionalidad aritmética, que se presenta en la distribución de datos, y la proporcionalidad geométrica que debe aparecer en el gráfico.
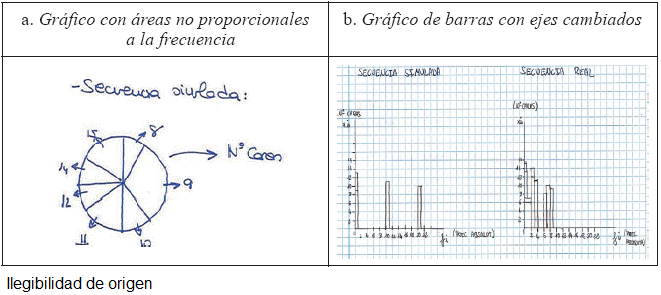
C3.2. Intercambia frecuencia y valor de la variable en los ejes. Al formar la distribución se establece una función donde a cada valor de la variable se asigna la frecuencia con que aparece. Algunos participantes tienen un conflicto al confundir las variables independiente (por ejemplo, número de caras) y dependiente (frecuencias absolutas) en la distribución de frecuencias y construyen la distribución asignando a cada frecuencia diferente obtenida, el valor de la variable que tuvo dicha frecuencia (Figura 5b). Este conflicto, detectado por Ruiz (2006) en un estudio de comprensión de la variable aleatoria, tiene como consecuencia que la función matemática representada no es unívoca (por tanto no es una función en el sentido estricto del término), pues varios valores de la variable podrían tener la misma frecuencia. Como se observa en el ejemplo, donde a la frecuencia 2, por ejemplo, le corresponden los valores 6 y 8, porque cada uno tiene frecuencia 2 en el experimento.
C3.3. Representa cada valor de la variable junto con su frecuencia. Algunos participantes construyen gráficos de barras adosados, representando cada valor de la variable junto con su frecuencia, como si fuesen dos variables diferentes. Generalmente estos gráficos se han construido con Excel, donde el futuro profesor hace una elección incorrecta de los datos a representar, tratando los valores de la variable (que debieran ser etiquetas en Excel) en la misma forma que las frecuencias (ver Figura 6a). Se muestra un conocimiento escaso de las opciones del software por parte del futuro profesor y se hace un uso acrítico del mismo (Ben-Zvi & Friedlander, 1997). Subyace también un conflicto al confundir los conceptos de valor y frecuencia. En los antecedentes de investigación no se encontró el error descrito en esta subcategoría.

C3.4. Representan el valor de la variable multiplicado por su frecuencia. Algunos participantes han introducido en Excel la distribución de datos calculando posteriormente una columna auxiliar con el producto de cada valor de la variable por su frecuencia, para hallar la media, como suma de esta columna, dividida por el número de datos. Posteriormente, al realizar el gráfico, lo mismo que en el caso anterior, hacen una elección incorrecta de los datos a representar y, en lugar de representar únicamente las frecuencias de la variable, representan en un diagrama de barras adosado, tanto las frecuencias como su producto por el valor de la variable. Estos futuros profesores muestran igualmente un uso acrítico del software y una confusión de los conceptos de variable, frecuencia y distribución. En los antecedentes de investigación no se encontró el error descrito en esta subcategoría.
C3.5. Gráfico no apropiado al problema planteado. Algunos futuros profesores eligen gráficos no adecuados para el problema a resolver, o para el tipo de variable. Por ejemplo, en la Figura 6b se representan caso a caso, en un gráfico de barras adosado, dos variables (racha más larga en la secuencia real y simulada), con lo que el gran número de barras impide visualizar la tendencia de los datos y, por tanto, comparar las dos distribuciones. Este participante ha representado los datos uno a uno, sin intentar formar la distribución, mostrando una comprensión incompleta de la misma.
C3.6. Variables no relacionadas en el mismo gráfico. Se representan en el mismo gráfico variables cuya comparación no tiene sentido (error citado por Li y Shen, 1992). Por ejemplo, en la Figura 7a el alumno representa la media, mediana y moda para las tres variables en un diagrama de barras apilado, mostrando una confusión respecto al propósito de dicho diagrama, que es representar valores de una misma variable. Esto pudiera deberse a otro conflicto entre los conceptos de valor de la variable y promedio.

C3.7. Representación de distintos promedios y estadísticos de dispersión en un mismo gráfico, que, como el caso anterior, no tiene sentido comparar. En la Figura 7b se muestra el gráfico realizado por un participante, en el cual, para cada variable en estudio, compara promedios con el rango, lo cual es una comparación sin sentido. Hay por tanto un conflicto que consiste en confundir los conceptos de promedio y dispersión, que no se ha reportado, ni estudiado, en la literatura especializada. Este gráfico, además, muestra problemas en relación con el título y los rótulos de los ejes, que hacen más difícil la interpretación de dicha representación.
C3.8. Otros errores. Incluimos acá los gráficos claramente inadecuados que contienen errores pertenecientes a varias de las categorías de error descritas anteriormente. También los errores en cálculo; por ejemplo, al calcular las frecuencias relativas a partir de los datos o al calcular la media o la mediana.
En la Tabla II se muestran los resultados obtenidos del análisis de las producciones de los estudiantes. Algo menos del 50% de los futuros profesores construyen gráficos básicamente correctos en la comparación de las distintas variables puestas en juego en el proyecto: 47% de los que construyen gráficos para el número de caras los construyen correctamente, 43.8% para el número de rachas y 45.7% para la racha más larga.

Hubo alrededor de un 20% de gráficos con errores en escalas (escala no proporcional, representación errónea de números en la recta, etc.), ya encontrados en (Bruno y Espinel, 2005), lo que indica que los errores no son un problema local, sino están extendidos entre los futuros profesores de educación primaria. Otros errores (los clasificados como gráficos incorrectos) considerados más graves, como el intercambio de frecuencias y valores, indican que no se comprende el concepto de distribución; o como el de la inclusión de variables no relacionadas en los gráficos, que muestra un desconocimiento del propósito de los gráficos. Destacan los que representan variables no relacionadas en un mismo gráfico (7.7 al 10.1% dependiendo de la variable) y aquellos que cometen varios errores (aproximadamente un 15% de los que realizan gráficos).
Sumados los gráficos incorrectos y parcialmente incorrectos, más de la mitad de los futuros profesores realizan gráficos con algún tipo de error. Es preocupante la proporción de futuros profesores que cometen errores graves en gráficos que tendrán que enseñar a sus estudiantes.
Para analizar la hipótesis de independencia entre la corrección del gráfico y la variable comparada, se compararon el número total de gráficos correctos, parcialmente correctos e incorrectos, en cada una de ellas, mediante el contraste Chi-cuadrado de independencia. Se comprobaron previamente los supuestos de aplicación del contraste (ninguna frecuencia observada fue menor que 5) y se obtuvo un valor Chi=1.03, con 6 grados de libertad, y valor p=0.98, que indica que no se puede rechazar la hipótesis de independencia. Interpretamos este resultado como indicación de que el grado de corrección del gráfico no depende de la variable representada, sino que serán debidos a falta de la competencia necesaria en la construcción de gráficos por parte de los futuros profesores.
4.2. Conflictos semióticos que explican algunos de los errores observados
El análisis realizado de los objetos matemáticos y funciones semióticas puestos en juego en la construcción de cada gráfico, nos permite analizar la actividad del futuro profesor y sus conflictos semióticos, es decir, las interpretaciones de objetos o expresiones matemáticas que no están de acuerdo con las pretendidas por el formador de profesores o el investigador. Dicho análisis se realizó para cada categoría de error, aunque en este trabajo sólo se ha mostrado el correspondiente a la categoría 2.1, por razones de limitación de espacio. Estos conflictos se pueden clasificar en la forma siguiente:
1. Conflictos relacionados con las convenciones de construcción de los gráficos. Se trata de futuros profesores que hacen una interpretación incorrecta de los convenios o procedimientos de construcción de gráficos. En esta categoría hemos encontrado el siguiente:
- Interpretación errónea de la regla consistente en representar todos los valores de los datos, entendiendo que hay que incluir en el eje X sólo los valores de la variable cuya frecuencia es no nula. Esto lleva a omitir los valores de frecuencia nula en los gráficos de barras, polígonos de frecuencia e histogramas; dicha omisión también fue descrita por Bruno y Espinel (2005).
2. Conflictos relacionados con la interpretación de la finalidad de cada gráfico. Aunque, generalmente un gráfico estadístico puede usarse para diversos fines, también existen convenciones, por lo que algunos gráficos son inadecuados en ciertas situaciones. En general, la adecuación del gráfico dependerá del tipo de variable representada y el número de valores que toma. Algunos errores, causados por estos conflictos, que llevan al alumno a elegir un gráfico inadecuado son los siguientes:
- Representar variables no comparables en el mismo gráfico, error encontrado por Li y Shen (1992). El conflicto subyacente es interpretar incorrectamente el propósito de comparar dos distribuciones en el mismo gráfico.
- Representar estadísticos no comparables en el mismo gráfico. Subyace, también en este caso, una confusión entre los diferentes tipos de resúmenes estadísticos, por ejemplo, entre medidas de tendencia central y dispersión, así como su propósito y el objetivo de comparar varios estadísticos entre sí. No hemos encontrado este error descrito en la literatura previa.
3. Conflictos relacionados con la representación de números en la recta real. Estos conflictos están relacionados con el sentido numérico y todos ellos han sido detectados por Bruno y Espinel (2005) y Espinel (2007), en futuros profesores de educación primaria:
- Conflicto al poner en correspondencia la proporcionalidad aritmética y la geométrica. Lleva a producir escalas no proporcionales, representando diferencias numéricas iguales mediante distancias diferentes.
- Traducción incorrecta de la secuencia numérica a su representación sobre la recta real. Un ejemplo es cuando se omite valores numéricos, al representar los números naturales en la recta real o cuando se representan valores numéricos no ordenados.
4. Conflictos relacionados con la interpretación de conceptos. Cuando los estudiantes confunden conceptos entre sí o los asocian a propiedades inexistentes:
- Confusión entre variable continua y discreta. Como consecuencia, no se centran las barras del histograma en la marca de clase. Otro error producido por este conflicto es la elección de un histograma para representar variables discretas con pocos valores, no apreciándose la diferencia entre histograma y diagrama de barras. Hay confusión sobre las convenciones de agrupación de variables estadísticas, que no tiene sentido si la variable tiene un número limitado de valores. Aunque este error fue descrito por Wu (2004), en estudiantes, y por Bruno y Espinel (2005), en futuros profesores, los autores no describen el conflicto que produce el error.
- Interpretación incorrecta de un intervalo numérico. El estudiante no sabe atribuir valor al intervalo que lo contiene, no diferencia entre intervalos abiertos o cerrados, no diferencia entre intervalos y categoría (que es un valor unitario), o representa como disjuntos intervalos que no lo son. Todos estos errores fueron descritos por Bruno y Espinel (2005) y los relacionan con el sentido numérico. Nosotros lo atribuimos a un conflicto de interpretación del concepto de intervalo.
- Confusión entre valor de la variable y frecuencia, detectado previamente por Wu (2004). No se discriminan estos conceptos, por lo que a veces se representa la frecuencia junto con la variable o se calcula la media de las frecuencias.
- Confusión de la variable dependiente e independiente en la distribución de frecuencias. Este conflicto ya fue detectado por Ruiz (2006) en un estudio de comprensión de la variable aleatoria, pero no había sido descrito para el caso de la variable estadística.
- Asocia la idea de distribución a un conjunto de variables y no a una sola variable. Algunos estudiantes mezclan valores o estadísticos de varias variables en un solo gráfico, no comprendiendo que cada distribución está asociada a una sola variable. No se ha descrito este conflicto en la investigación previa. Una consecuencia inmediata, tampoco descrita anteriormente, es que algunos estudiantes asocian la idea de rango a un conjunto de distribuciones y no a una sola distribución. En consecuencia, al elegir sus escalas usan el mínimo de una de las variables y el máximo de otra.
Por otro lado, también se observaron errores que no hemos podido explicar utilizando la idea de conflicto semiótico. Por ejemplo, desde nuestro punto de vista no habría conflicto semiótico subyacente en añadir líneas innecesarias al gráfico que, aunque dificultan la lectura, no suponen confusión en la interpretación de objetos matemáticos. Estas líneas innecesarias no se deben a una interpretación incorrecta por parte de los estudiantes sino a que quienes las añaden creen que puede facilitarles la construcción de los gráficos.
Tampoco son debidos a conflictos semióticos los errores de cálculo; por ejemplo, cuando confunden el resultado de la división al calcular las frecuencias relativas a partir de las absolutas. Los errores consistentes en elegir escalas demasiado amplias o que no cubren el recorrido de la variable (error encontrado por Wu, 2004) y la subdivisión incorrecta de la escala, encontrada también por Li y Shen (1992), se explicarían por falta de comprensión del papel de las escalas en el gráfico.
Para finalizar indicamos que la tecnología en ocasiones aumenta los conflictos pues los estudiantes tienen poco dominio de ella, como veremos en el siguiente punto. Ello es debido a que también la tecnología tiene convenciones de interpretación (por ejemplo, de los iconos o las funciones) que el futuro profesor desconoce o confunde.
4.3. Uso de ordenadores e influencia en los errores
En los currículos españoles para la Educación Primaria (MEC, 2006; MECD, 2014) se incluye como contenido el uso de Excel en el último ciclo (11-12 años), dentro de un plan global de incorporar la tecnología en todas las materias escolares. Por otro lado, son cada vez más numerosos los centros de educación primaria en que se dota a alumnos y profesores de ordenador personal, o que tienen instalaciones de ordenadores.
Los participantes en nuestro estudio pudieron elegir entre realizar el trabajo a mano o usando los ordenadores. Sólo una cuarta parte de la muestra y menos de la tercera parte de los que realizan gráficos utilizan el ordenador. Deducimos que el manejo de la hoja Excel es todavía poco familiar a estos futuros profesores, a pesar de haber sido utilizada en la asignatura de Matemáticas y su Didáctica, en primer año algunas prácticas de uso de la hoja Excel, precisamente en el tema de estadística.
El problema al usar herramientas como la hoja Excel en el análisis estadístico es que, aparte de los contenidos de estadística necesarios para una determinada tarea, es necesario aprender las opciones del software utilizado. Esto ofrece una dificultad añadida a la tarea propuesta a los estudiantes, por lo que muchos alumnos se limitan a aceptar la salida que proporciona el software sin usar las posibilidades de cambiar escala, tipo de gráfico, etc., como indica Ben-Zvi (2002). Esto ha ocurrido en nuestro estudio, donde, aunque son minoría los estudiantes que usaron ordenador (generalmente la hoja Excel), en general, estos tuvieron mayor número de errores que los que realizaron gráficos de papel y lápiz. En la Tabla III presentamos las frecuencias de uso del ordenador y los porcentajes respecto al total de participantes que analizan cada variable.
Tabla III Frecuencias y porcentaje de estudiantes, según corrección de los gráficos y el uso o no de ordenador

En total 50 futuros profesores utilizan el ordenador para realizar los gráficos del número de caras (27.6% de los que representan esta variable), 40 para el número de rachas (27.4% de los que las grafican) y 40 para la longitud de la racha más larga (31% de los que representan esta variable). En consecuencia, no hay una variación muy grande en el porcentaje de los que usan el ordenador para las tres variables. Observamos que la proporción de gráficos correctos es siempre mayor si no se usa el ordenador y hay menores errores en escalas (gráficos parcialmente correctos), porque el software construye automáticamente las escalas. Sin embargo, hay muchos más gráficos incorrectos (errores importantes) al usar el ordenador. Globalmente, mientras que el 48.2 % de gráficos realizado a mano fueron correctos este porcentaje cae al 39.2% en el caso de usar ordenador, subiendo el porcentaje de gráficos incorrectos del 27% al 47.7%. Este resultado es un motivo de preocupación, puesto que, como se ha dicho, las autoridades educativas tratan de favorecer el uso de ordenadores en la enseñanza.
Para analizar la hipótesis de independencia entre la distribución de gráficos correctos, parcialmente correctos e incorrectos en alumnos que usan o no el ordenador se aplicó el contraste Chi cuadrado, utilizando las dos últimas columnas de frecuencias absolutas de la Tabla III. Se comprobaron los requisitos de aplicación (ninguna frecuencia absoluta es menor que 5) y el resultado del contraste fue estadísticamente significativo (Chi=19.72; p=0,0001 con 2 grados de libertad); por tanto se rechaza la hipótesis de independencia entre estas dos variables.
5. Conclusiones
Los resultados del estudio confirman los de Bruno y Espinel (2005), Espinel (2007) y Monteiro y Ainley (2006, 2007), que resaltan problemas en la comprensión gráfica de los futuros profesores de Educación Primaria. La proporción de gráficos correctamente construidos por los participantes en el estudio no alcanza el 50% y no depende de la variable analizada por los futuros profesores. Alrededor de un 20% de los gráficos presenta errores en las escalas, muchos de los cuáles se deben a problemas en la comprensión de la representación de números en la recta real o con la proporcionalidad. Un 30% de gráficos presentan errores de mayor importancia, lo que indica que los participantes no conocen el propósito o el tipo de variables adecuados a los diferentes gráficos, ni el propósito de la comparación de dos distribuciones.
Asimismo, los resultados confirman la clasificación de errores realizadas por Arteaga y Batanero (2010), para una parte de estos gráficos, y han permitido rechazar la hipótesis de independencia de la distribución de errores en los futuros profesores que usan el ordenador (mayor proporción de errores) y los que no lo usan. Adicionalmente se ha realizado un análisis semiótico cualitativo que permite identificar y clasificar una serie de conflictos semióticos en los gráficos producidos por los futuros profesores. Todos estos resultados son originales, respecto al trabajo de Arteaga y Batanero (2010).
Los resultados indican un pobre conocimiento de los gráficos estadísticos elementales incluidos en la orientaciones curriculares para la Educación Primaria (por ejemplo, MECD, 2014). Por tanto, queremos resaltar la importancia de que los formadores de profesores tomen conciencia de la necesidad de formar estadísticamente a los futuros profesores y, en particular, mejorar su competencia en la producción de los gráficos estadísticos, que tendrán que enseñar a sus futuros alumnos. Dicha enseñanza debe atender a los conocimientos matemáticos, proponiendo a los futuros profesores actividades de construcción y lectura de todos los gráficos estadísticos elementales incluidos en las orientaciones curriculares y libros de texto: gráficos de barras, de líneas y sectores, gráficos de puntos y pictogramas. En las situaciones que se proponga a los profesores se deben tener en cuenta los diversos niveles de lectura de gráficos propuestos por Curcio (1987) y los niveles de complejidad del gráfico propuestos por Batanero y otros (2010).
La clasificación de errores presentada y su explicación, en términos de conflictos semióticos, pueden servir a los formadores de profesores, para tener en cuenta las dificultades que pueden encontrar los futuros profesores en la realización de gráficos y, por lo tanto, para diseñar actividades que ayuden a superarlas. De este modo se atendería a la componente didáctica de su formación. Además, para mejorar su conocimiento de la enseñanza activa de los gráficos, podrían ser útiles las recomendaciones de González, Espinel y Ainley (2011) y basarse en la realización de proyectos similares al descrito en este estudio, puesto que las nuevas directrices curriculares para la educación primaria en España recomiendan el trabajo con proyectos en la enseñanza de la estadística.

