










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkPolítica y gobierno
versión impresa ISSN 1665-2037
Polít. gob vol.17 no.2 Ciudad de México ene. 2010
Nota de investigación
Un modelo Monte Carlo para la Cámara de Diputados en México
A Monte Carlo model for the Chamber of Deputies in Mexico
Javier Márquez* y Francisco Javier Aparicio**
*Javier Márquez, javier.marquez@buendiaylaredo.com, es director de investigación de Buendía & Laredo, S.C. Arquímedes 130–202, Polanco, Del. Miguel Hidalgo, México, D.F. 11560. Tel: +52 (55) 50 83 60 59 / 52 50 59 08.
**Francisco Javier Aparicio, javier.aparicio@cide.edu, es profesor–investigador del Centro de Investigación y Docencia Económicas. Carretera México–Toluca 3655, Lomas de Santa Fe, México, D.F. 01210. Tel: + 52 (55) 57 27 98 00 ext. 2140.
Nota recibida en febrero de 2010
y aceptada para su publicación en abril de 2010.
Resumen:
La literatura sobre el sistema político electoral en México a menudo se interesa en evaluar el efecto de una reforma electoral, o bien de alguna otra variable contextual, sobre la correlación de fuerzas en la Cámara de Diputados. Desde un punto de vista empírico, estimar estadísticamente este tipo de efectos es una tarea difícil que requiere cierta experiencia en programación. Esta nota pretende contribuir al estudio del sistema electoral y del Congreso de dos maneras. Por una parte, presentamos un método estadístico para analizar la composición de la Cámara de Diputados en México. Por otra, facilitamos su implementación con el software camaradip, un módulo para Stata desarrollado por los autores, que permite estimar cantidades de interés relacionadas con la Cámara de Diputados a partir de simulaciones de Monte Carlo. Para mostrar la aplicación de nuestro método evaluamos la repercusión hipotética de dos reformas electorales en la composición de la Cámara: por un lado, homologar el calendario de las elecciones locales y federales en todo el país y, por otro, disminuir el número de diputados plurinominales.
Palabras clave: Cámara de Diputados, reforma electoral, simulaciones de Monte Carlo.
Abstract:
The extant literature on the Mexican political system is often interested in analyzing the effect of electoral reforms, or some other contextual factor, on the political configuration of the Chamber of Deputies. From an empirical point of view, statistical estimation of such effects is a cumbersome task that requires some programming skills. In this research note we seek to contribute to the study of the Mexican electoral system and the Congress in two ways. First, we introduce a statistical model to analyze the composition of seats of the Mexican Chamber. Second, we facilitate the implementation of this model with the software camaradip, a Stata module developed by the authors that allows for the estimation of quantities of interest regarding the Chamber via Monte Carlo simulations. To illustrate the applicability of our model, we evaluate the hypotethical impact of two electoral reforms: the effect of making all local and federal elections concurrent, and the reduction of the number of proportional representation seats.
Keywords: Chamber of Deputies, electoral reform, Monte Carlo simulations.
Introducción
México es uno de los países que ha modificado su sistema electoral en más ocasiones en el mundo. Como señala Weldon (2001), en cada una de las cinco elecciones federales celebradas entre 1985 y 1997 se utilizó un sistema electoral distinto. Más recientemente, en 2007 el Congreso aprobó una reforma electoral que afectó la elección federal de 2009, y tras la cual ya se discuten diversas propuestas para modificar una vez más las reglas electorales vigentes, tales como las diversas iniciativas de reforma política presentadas tanto por el Poder Ejecutivo como por las principales bancadas legislativas desde finales de 2009.
Este espíritu reformista de la transición democrática en México ha estado acompañado por un creciente interés por parte de los investigadores del Congreso en evaluar los efectos de distintas reglas electorales en la conformación partidista de la Cámara de Diputados. Aunque en la literatura existen varios trabajos que tratan este tema de manera teórica o empírica, los análisis propiamente estadísticos son prácticamente inexistentes.1 Una de las causas de esta situación radica en la complejidad propia del método de asignación de curules en un sistema electoral mixto que, aunada al número relativamente elevado de partidos con registro en México, hace que la simulación de escenarios sustantivamente interesantes sea una tarea difícil. Además, la composición del Congreso no es un resultado que se pueda estimar directamente con los modelos estadísticos tradicionales y, en el mejor de los casos, es una tarea que requiere algunas nociones de programación.
Esta nota de investigación pretende contribuir al estudio del Congreso en México de dos maneras. Por una parte, desarrollamos el vínculo entre los modelos estadísticos existentes (Gelman y King, 1994; Honaker et al., 2002; Katz y King, 1999; Tomz et al., 2002) y la Cámara de Diputados en México.
Por otro lado, mostramos la implementación de nuestro método en el software camaradip, un módulo de Stata (StataCorp, 2009) desarrollado por los autores para estimar cantidades de interés relacionadas con la composición de la Cámara de Diputados a partir de simulaciones de Monte Carlo.2 Creemos que camaradip tiene varias características deseables para los investigadores del Congreso mexicano, como las siguientes:
• Está implementado en Stata, un paquete estadístico utilizado comúnmente por los científicos sociales.
• Es fácil de usar, pues está basado en unos cuantos comandos sencillos que requieren pocos pasos.
• No requiere aprender nuevos métodos ni modelos estadísticos distintos a los que se usan normalmente en la ciencia política contemporánea.
• Está basado en métodos de simulación estadística, una herramienta lo suficientemente flexible como para extraer cantidades de interés relacionadas tanto con los resultados electorales como con la composición de la Cámara de Diputados en México (por ejemplo, el efecto de los gastos de campaña, métodos de selección de candidatos, cuotas de género, etcétera).
• El módulo permite al investigador simular el efecto de un amplio abanico de reglas de asignación de curules (por ejemplo, procesos de redistritación, cambios en el número de curules uninominales y plurinominales, modificaciones en las cláusulas de sobrerrepresentación o bien en los umbrales de representación, etcétera).
La nota de investigación está estructurada de la siguiente manera. En la primera sección abordamos algunos aspectos preliminares de nuestro método estadístico para la Cámara de Diputados, mismos que describimos de manera más formal en la segunda parte. En la tercera sección mostramos la implementación del paquete camaradip, seguida de dos aplicaciones ilustrativas: el efecto de la concurrencia entre elecciones federales y locales y, por otro lado, el efecto de reducir el número de curules plurinominales. Finalmente, discutimos algunas áreas de investigación para estudios futuros.
Discusión preeliminar
El objetivo principal del método estadístico que aquí proponemos es extraer cantidades de interés relacionadas con la conformación partidista de la Cámara. Denotemos al número de asientos o curules que le corresponden a cada uno de los partidos políticos con representación en la Cámara como Ψ= [Ψ1, Ψ2, ...,Ψj]. El número de curules para cada partido depende fundamentalmente de dos variables: las preferencias de los votantes, las cuales se observan de manera agregada en el resultado electoral, y las reglas electorales, entre las que destacan las reglas de asignación de curules (figura 1). Las preferencias de los votantes se manifiestan en los votos V= [V1, V2, ...,Vj]. para cada uno de los J partidos (j= 1, ..., J), que a su vez se transforman en posiciones en la Cámara a través de las reglas de asignación.

Generalmente, el investigador desea evaluar el cambio en el número de asientos, Ψ, dado un cambio en las reglas electorales. Nuestro modelo requiere que se distingan dos tipos de reglas. Las primeras son aquellas que afectan el resultado electoral al alterar la participación o las preferencias de los votantes (por ejemplo, los gastos de campaña de los candidatos, el método de selección de los mismos o las cuotas de género en las candidaturas). Las preguntas de investigación relacionadas con estas reglas deben plantearse en términos de "efectos contextuales" y para fines de estimación deben ser observables o medibles en el nivel de los distritos electorales.3
El segundo tipo de reglas se refiere explícitamente a la asignación de curules, es decir, aquellas reglas que determinan mecánicamente el procedimiento mediante el cual los porcentajes de votos se traducen en el reparto de curules entre los partidos; por ejemplo, el porcentaje o umbral mínimo de votación para tener derecho a curules de representación proporcional o el tope máximo de sobrerrepresentación en la Cámara.
Nuestro método estadístico sirve para elaborar predicciones, explicaciones o estimar contrafactuales de la Cámara de Diputados, cuando una reforma electoral modifica los resultados electorales o el método de asignación de curules. Formalmente, el objetivo es describir la distribución de probabilidad de curules, p(Ψ).4 Una manera de hacer esto es por medio de simulaciones de Monte Carlo (Jackman, 2000a, 2000b, 2004; Martin, 2008). Es decir, en lugar de encontrar una solución analítica para estimar el efecto de un cambio en las reglas electorales, podemos obtener varios valores de p(Ψ|V) con la ayuda de un generador de números (seudo)aleatorios, agregar dichos valores, y hacer inferencias con ellos mediante estadísticas descriptivas. Con este método se pueden simular diferentes composiciones hipotéticas de la Cámara a partir de una serie aleatoria de resultados electorales. Díaz–Cayeros (2005) utiliza esta técnica para analizar la composición del Senado en México bajo distintas reglas de asignación de escaños.
El problema se torna un poco más complicado cuando se analiza el efecto de una reforma que presumiblemente puede alterar los resultados de una elección —por ejemplo, al cambiar las preferencias de los votantes o al cambiar las opciones que se le presentan—, pues resulta imposible simular valores aleatorios de p(Ψ|V) de manera directa. No obstante, el método de Monte Carlo sigue siendo una herramienta útil para nuestra aplicación. El algoritmo que aquí se propone incluye estimar un modelo de regresión lineal para explicar los resultados electorales, V, en función de ciertos parámetros θ, de modo que podemos simular valores de la distribución p(θ |V) y, a partir de esos valores, estimar la distribución de asientos como Ψ= h (θ) (véase Jackman, 2000a, 2009, cap. 3).
En términos generales, el modelo estadístico para la Cámara de Diputados que se propone comprende cuatro etapas que se ilustran en la primera columna de la figura 2: 1) especificación y simulación de los parámetros de un modelo de regresión, 2) generación de replicaciones hipotéticas del resultado electoral, así como 3) de la conformación de la Cámara de Diputados, y 4) extracción de cantidades de interés. Con esto el investigador puede analizar tanto la tendencia central como la dispersión de las distribuciones de probabilidad de votos, las distribuciones del número de curules de cada partido, o bien otras cantidades que se derivan de la distribución de votos y asientos —por ejemplo, la probabilidad de que la bancada de un partido sea pivotal en una coalición mínima–ganadora.

En la siguiente sección abordamos brevemente las cuatro etapas del modelo estadístico. En la cuarta sección exponemos intuitivamente nuestra implementación del modelo en el paquete camaradip de Stata (véase la segunda columna de la figura 2). En la quinta sección presentamos dos aplicaciones concretas del método que proponemos para extraer cantidades de interés (tercera columna de la figura 2).
Modelo estadístico
Estimación con datos electorales multipartidistas
Como mencionamos en la sección anterior, el número de asientos que le corresponden a cada partido en la Cámara depende del resultado electoral (la manifestación en votos de las preferencias de los votantes) y de las reglas electorales. En esta parte abordaremos el primero de ellos.
La manera más común de explicar o predecir estadísticamente un resultado electoral es a través de un modelo de regresión (Gelman y Hill, 2007, caps. 3 y 4). Normalmente, el investigador estima el porcentaje de votación de un partido político como una función de diversos factores explicativos a través de un modelo de regresión de mínimos cuadrados ordinarios (MCO). Desafortunadamente, el modelo estándar de regresión es inapropiado para estimar los resultados electorales de un sistema multipartidista (Katz y King, 1999). Por ejemplo, los resultados de la regresión pueden indicar que un partido podría obtener menos de cero votos, o bien que la suma de los votos de todos los partidos podría ser menor o mayor de 100 por ciento.
Estas inconsistencias surgen porque los resultados electorales multipartidistas violan dos supuestos subyacentes del modelo estándar. En primer lugar, el modelo de MCO asume que la variable dependiente (en este caso, la proporción de votos de un partido) es una variable continua irrestricta, es decir, que puede tomar cualquier valor. Naturalmente, la proporción de votos de un partido se encuentra necesariamente acotada entre cero y uno. Denotemos a Vijcomo la proporción de votos del partido j(j= 1, ...,J), en el distrito electoral i ( i= 1, ..., n). Formalmente,

En segundo lugar, el modelo estándar presupone que la proporción de votos de un partido es ortogonal o independiente de la de los demás; sin embargo, es claro que en la composición porcentual de una contienda electoral, el porcentaje de votos de un partido está inversamente relacionado con el de los demás toda vez que la suma de todas las proporciones de votos es igual a uno. Dicho de manera formal,

Para subsanar las inconsistencias del modelo estándar, Katz y King (1999) recomiendan modelar la proporción de votos de los partidos con una transformación logística multivariada Aitchison (1982). Esta técnica consiste en transformar a log ratios la proporción de votos del partido j= 1, ...,J–1, respecto de un partido base J. Así, el vector de J–1 lóg ranos en el distrito i se representa de la siguiente manera:

La transformación logística convierte las proporciones de votos en una escala continua irrestricta —como requiere el modelo MCO—, y tras la estimación las recupera en su escala original (satisfaciendo [1] y [2]) con una transformación logística inversa. Para fines de estimación, asumimos que el vector de log ratios tiene una distribución normal multivariada con su media en el vector µ y matriz de varianza ∑, Y. :N(µ¡, ∑) (Tomz et al, 2002).5 Luego entonces, el resultado electoral esperado en cada distrito, µi, se puede modelar como una función lineal de un vector de variables explicativas Xi y los parámetros β, tal que

Al igual que en cualquier modelo de regresión, la elección de qué variables incluir en el vector Xi; depende de nuestra pregunta de investigación. Si el objetivo es evaluar el efecto causal de una variable en la votación de los partidos (y por lo tanto en las curules que les corresponden), este vector debe excluir aquellas variables que son en parte consecuencia de nuestra variable explicativa clave (Rosenbaum, 1984; King et a/., 1994). En cambio, si el objetivo es hacer pronósticos del resultado electoral (para luego evaluar el efecto de una regla de asignación de curules), la selección de las variables explicativas se rige por otros criterios, de los cuales el más importante es que ayuden a predecir lo mejor posible la variable dependiente (Gelman y Hill, 2007, p. 69).
El sistema de ecuaciones en (3) puede estimarse con J – 1 modelos de regresión con MCO; sin embargo, Jackson (2002) y Tomz et al. (2002) recomiendan utilizar regresiones aparentemente inconexas (seemingly unrelated regression o sur en inglés) por varias razones. En primer lugar, este método es útil para estimar sistemas de ecuaciones con errores correlacionados, y los datos multipartidistas tienen esa estructura dado que un mayor log ratio para un partido significa un menor log ratio para otro. En segundo lugar, si las variables explicativas difieren de una ecuación a otra (como puede ocurrir en las aplicaciones del modelo), sur incorpora la covarianza de las ecuaciones para obtener estimadores más eficientes que MCO. En tercer lugar, sur tiene un buen desempeño en muestras pequeñas (cuando el número de distritos es limitado), y es más flexible que otras alternativas cuando el número de partidos es relativamente grande (J > 3). Finalmente, la implementación de sur en los paquetes estadísticos más comunes facilita al investigador estimar las J – 1 ecuaciones con pocos comandos.
Simulación estadística y cantidades de interés
Como normalmente ocurre con otros modelos de regresión, los parámetros en (3) son difíciles de interpretar y están relacionados sólo de manera indirecta con nuestras preguntas de investigación. Los coeficientes del modelo indican el cambio en el log ratio de los votos de un partido frente a un incremento de una unidad en las variables explicativas. Como veremos más adelante, para interpretar los resultados en términos de porcentajes de votos se requiere aplicar la transformación logística inversa (ecuación 5).
Pero además, para los estudiosos del Poder Legislativo los votos no son importantes por sí mismos. Los votos cobran relevancia cuando se traducen en curules en la Cámara de Diputados y éstos, a su vez, tienen influencia en el control y diseño de políticas públicas concretas. Por ejemplo, para los investigadores del comportamiento electoral puede ser importante conocer el efecto que ejercen las elecciones concurrentes sobre la votación de los partidos; pero a los especialistas del Poder Legislativo podría resultarles más interesante saber si una reforma encaminada a homologar el calendario electoral alteraría de manera significativa la correlación de fuerzas en el Congreso. Si todas las elecciones locales y federales fueran concurrentes, ¿cuál sería la composición partidista de la Cámara de Diputados? ¿La nueva constelación sobrerrepresentaría a un partido en detrimento de los demás? ¿Aumentaría la probabilidad de que el partido del presidente tenga mayoría simple en la cámara baja? Y si la reforma beneficia a la oposición, ¿sus ganancias serían difusas o se concentrarían en un solo partido?
Dicho de manera más general, el objetivo del modelo se puede reformular para estimar la distribución de probabilidad de curules Ψ como una función de los parámetros del modelo de regresión de votos θ= [β, ∑],

El éxito en la empresa depende de la naturaleza de la cantidad de interés: algunas pueden calcularse fácilmente con métodos analíticos tradicionales (e.g., Gelman y King, 1994, p. 532); otras requieren métodos más difíciles, como aproximaciones por series de Taylor (Katz y King, 1999, p. 25), y algunas son imposibles de obtener con cualquiera de los métodos anteriores. Dada la complejidad de las reglas de asignación, la distribución del número de curules de un partido en la Cámara de Diputados puede ser difícil o imposible de obtener de manera analítica. Por eso proponermos calcularla empíricamente con la ayuda de simulaciones. Como King et al. (2000) afirman:
Existe una alternativa basada en simulación para casi cualquier método analítico empleado para calcular cantidades de interés y para realizar pruebas estadísticas, pero no al revés. Así pues, la simulación estadística puede ofrecer respuestas precisas incluso cuando no existen soluciones analíticas (p. 53).
La simulación estadística se basa en el principio de Monte Carlo, según el cual podemos conocer o describir cualquier variable aleatoria obteniendo una muestra de valores que pertenecen a su distribución de probabilidad (Jackman, 2009). De acuerdo con el teorema del límite central, la distribución de probabilidad de los parámetros es (asintóticamente) normal multivariada:6

Por lo tanto, podemos aproximarnos a la distribución de probabilidad de Ψ seleccionando o simulando aleatoriamente t= 1, 2, ...T valores θ(1), θ(2), ..., θ(T) de (4), y evaluando Ψ(t) = h (θ (t)) con cada uno de ellos.
Específicamente, el algoritmo para simular un valor de la distribución de Ψ involucra los siguientes pasos:
1. Estimar el vector de parámetros
mediante SUR.
2. Seleccionar aleatoriamente (simular) un vector de parámetros θa partir de la distribución normal multivariada dada en (4).
3. Elegir valores reales (observados) o bien valores hipotéticos para las variables explicativas del distrito i de acuerdo con la pregunta de investigación. Denotemos al vector de valores como Xihip. Si se desea evaluar únicamente la repercusión de algún método de asignación de curules, Xihip = Xi .
4. Calcular el vector de resultados electorales
con las simulaciones de
del paso 2 y el vector Xihip.
5. Simular
seleccionando aleatoriamente un valor de la distribución
.7
6. Transformar


La predicción del partido usado como base o referencia en la transformación logística,  , está determinada por la expresión:
, está determinada por la expresión: ![]()
7. Repetir los pasos 3 a 6 para cada uno de los distritos. Agregar los resultados en el vector
.
8. Evaluar la distribución de curules
, donde g es una función que representa el procedimiento de asignación de curules de acuerdo con la ley electoral, o bien otra regla hipotética de asignación establecida a priori por el investigador.
Si se repiten los pasos 2 a 8 un número relativamente grande de veces (digamos, T = 1 000), obtenemos ^asignaciones hipotéticas de la Cámara de Diputados, cuya distribución se aproxima a la distribución de probabilidad completa de 
Implementatión
El algoritmo de la sección anterior guarda similitudes con el descrito por King et al. (2000), e implementado en Clarify por Tomz et al. (2003). De hecho, la implementación de nuestro método se apoya en algunas de las rutinas de ese programa; no obstante, nuestra rutina es más parecida a la del "porcentaje correctamente predicho" formulada por Herron (1999).9 Las diferencias entre Clarify y nuestro método pueden ilustrarse fácilmente con el cuadro 1 (adaptado de Gelman y King, 1994). Cada fila representa un distrito, con el número del distrito en la primera columna y el porcentaje de votos observado del partido/en la segunda columna. Las demás columnas representan simulaciones de la distribución del porcentaje de votos. Por ejemplo, el voto observado del partido j en el distrito 1 es V1j, y la primera simulación es  , la segunda es
, la segunda es  y así sucesivamente.
y así sucesivamente.

Normalmente, el investigador utiliza Clarify para analizar el efecto de una variable explicativa en escenarios específicos. En términos generales, el procedimiento consiste en simular los parámetros del modelo de regresión, fijar las variables explicativas en valores hipotéticos de interés (digamos, en sus valores promedio) y calcular el valor esperado de la variable dependiente (Katz y King, 1999; King et al, 2000). En otras palabras, Clarify suele emplearse para obtener T valores esperados de un distrito promedio (i.e., una fila del cuadro 1). En cambio, nuestro método utiliza como insumo las T replicaciones hipotéticas del resultado electoral agregado, lo cual implica trazar simulaciones para cada uno de los distritos (Gelman y King, 1994). En el cuadro 1 se observa que simulando T valores de la distribución de votos para cada distrito (filas), se obtienen T resultados electorales hipotéticos para cada partido (columnas). Considerando el número de partidos y distritos en la última elección en México, usando Clarify se requerirían aproximadamente 5 000 líneas de código (comandos) para obtener una matriz como la del cuadro 1. El módulo camaradip provee un wrapper que automatiza y simplifica notablemente esta tarea y genera, con un solo comando (simuladip), una base datos con T elecciones simuladas para cada distrito y partido similar al cuadro 1.
Otra diferencia más evidente entre Clarify y nuestro algoritmo tiene que ver con la naturaleza de las cantidades de interés. La última fila del cuadro 1 representa el número de curules del partido j, denotado por Ψj para el resultado observado, y por  para las replicaciones hipotéticas. Las cantidades de interés se obtienen con la información de su respectiva columna. Para calcular la primera replicación
para las replicaciones hipotéticas. Las cantidades de interés se obtienen con la información de su respectiva columna. Para calcular la primera replicación 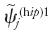 , debemos contar el número de distritos en que el partido j obtuvo más votos que los demás partidos en la primera columna de replicaciones hipotéticas (lo cual representa su número de curules uninominales), y luego asignar las curules plurinominales a las que tendría derecho dada su votación en todos los distritos de esa misma columna. Este ejercicio se repite sucesivamente para cada una de las elecciones hipotéticas de manera que la última fila del cuadro está formada por T simulaciones de la distribución de curules
, debemos contar el número de distritos en que el partido j obtuvo más votos que los demás partidos en la primera columna de replicaciones hipotéticas (lo cual representa su número de curules uninominales), y luego asignar las curules plurinominales a las que tendría derecho dada su votación en todos los distritos de esa misma columna. Este ejercicio se repite sucesivamente para cada una de las elecciones hipotéticas de manera que la última fila del cuadro está formada por T simulaciones de la distribución de curules  .
.
Naturalmente, cuanto mayor sea el número de simulaciones T, la tarea de obtener  se torna tediosa y complicada. Para solucionar este problema resulta práctico generar un programa que realice la asignación de curules por nosotros. El comando asignadip del paquete camaradip ofrece esa herramienta. Por omisión, asignadip aplica el método de asignación ordenado por el Cofipe y que se ha utilizado en México desde la elección federal de 1997. Dicho método consiste en la asignación de 300 diputados uninominales por la regla de mayoría relativa, la asignación de 200 diputados plurinominales por el método de resto mayor, y la reasignación de curules plurinominales cuando un partido tiene más de 300 curules o su porcentaje de curules por ambos principios excede en 8 puntos o más el porcentaje de votación nacional obtenido.10 Pero, además, las opciones de asignadip son lo suficientemente flexibles como para que el investigador pueda experimentar con varios métodos de asignación; por ejemplo, modificar el número de curules uninominales y/o plurinominales, realizar la asignación en varias circunscripciones o en una circunscripción nacional, disminuir el límite máximo de sobrerrepresentación, aumentar el umbral mínimo para tener derecho al reparto de curules plurinominales, etcétera.
se torna tediosa y complicada. Para solucionar este problema resulta práctico generar un programa que realice la asignación de curules por nosotros. El comando asignadip del paquete camaradip ofrece esa herramienta. Por omisión, asignadip aplica el método de asignación ordenado por el Cofipe y que se ha utilizado en México desde la elección federal de 1997. Dicho método consiste en la asignación de 300 diputados uninominales por la regla de mayoría relativa, la asignación de 200 diputados plurinominales por el método de resto mayor, y la reasignación de curules plurinominales cuando un partido tiene más de 300 curules o su porcentaje de curules por ambos principios excede en 8 puntos o más el porcentaje de votación nacional obtenido.10 Pero, además, las opciones de asignadip son lo suficientemente flexibles como para que el investigador pueda experimentar con varios métodos de asignación; por ejemplo, modificar el número de curules uninominales y/o plurinominales, realizar la asignación en varias circunscripciones o en una circunscripción nacional, disminuir el límite máximo de sobrerrepresentación, aumentar el umbral mínimo para tener derecho al reparto de curules plurinominales, etcétera.
En su forma más simple, el modelo estadístico para la Cámara de Diputados puede implementarse en Stata con tres sencillos pasos (figura 2):
• Transformar los porcentajes de votos de los partidos (v1, v2, v3, v4) en log ratios; estimar y simular los parámetros del modelo de regresión con el comando estimadip:
.estimadip (v1 x z) (v2 x z) (v3 x z), base(v4)
• Fijar el valor de las reglas electorales (x) y de otras variables explicativas (z) en sus valores reales o hipotéticos, calcular la distribución predictiva de votos, aplicar la transformación logística inversa y guardar los resultados en las variables p1, p2, p3, p4 de la base simfile, con el comando simuladip:
.simuladip using simfile, gen(p1 p2 p3) set(x 1=0, z 0=1)
• Calcular la distribución de probabilidad de la composición de la Cámara de Diputados con ayuda de un loop (Cox, 2002) y del comando asig–nadip:
.use simfile
.forvalues i = 1/1000 {
2. asignadip p1 p2 p3 p4 if _IDsim == 'i'
3. }
Con unas pequeñas modificaciones —utilizando el comando dos veces—, asignadip se puede adaptar a la reglamentación de las coaliciones electorales vigente a partir de la elección federal de 2009.11
Otra de las virtudes de asignadip es que el usuario tiene acceso a los resultados por medio de escalares y macros guardados en r() con la función return de Stata. Esta utilería es una manera práctica de guardar las distribuciones del número de curules en variables que pueden manipularse fácilmente con otros comandos de estadística descriptiva.
Para presentar los resultados del análisis, las distribuciones pueden describirse con medidas de tendencia central (e.g., media, moda, mediana) o medidas de dispersión (e.g., desviaciones estándar o percentiles que delimitan un intervalo de confianza). También pueden efectuarse pruebas de hipótesis contando la fracción de veces que el número de curules de un partido es mayor o menor a una cifra cualquiera. Por ejemplo, para calcular la probabilidad de que un partido tenga mayoría simple en la Cámara, basta con sumar las veces que el número predicho de curules es igual o mayor a 251, y dividirlo entre T. Además, la distribución del número de curules puede tranformarse en otras distribuciones, como la del número efectivo de partidos en la legislatura, índices de poder, coaliciones mínimas ganadoras, etc. En la siguiente sección mostramos cómo el usuario puede extraer estas y otras cantidades de interés.
Aplicaciones
Elecciones concurrentes
En esta sección presentamos una aplicación del modelo estadístico de la Cámara de Diputados para evaluar una reforma que homologa el calendario de las elecciones locales y federales en todo el país: es decir, elegir a gobernadores y gobiernos locales al mismo tiempo que a los diputados federales. Las elecciones concurrentes pueden producir efectos de arrastre entre el voto por el presidente o gobernador —cargos unipersonales de alta visibilidad— y el voto por los legisladores federales o locales (Mondak y McCur–ley, 1994). Este tipo de efectos se han documentado en países como Argentina, Brasil y México (Jones, 1997; Samuels, 2000; Magar, 2006).
Los datos para el análisis provienen de los cómputos distritales de la elección para diputados federales de 2009, agregados por distrito electoral federal (n=300) (IFE, 2009). Las variables dependientes son el log ratio de la proporción de votos del PAN, PRI, PRD, PVEM, PT, Convergencia y Nueva Alianza respecto a la proporción de votos del PSD. La variable explicativa clave es una variable dicotómica que toma el valor de uno si en un distrito se llevaron a cabo elecciones para elegir gobernador o presidentes municipales, y cero en caso contrario. Existen razones para suponer que el efecto de la concurrencia también puede verse afectado por el partido político que gobierna el estado; por lo tanto, en la regresión incluimos los términos constitutivos de la interacción entre la variable de concurrencia y otras dos variables que indican si el gobernador del estado es de filiación panista o perredista12 (Brambor et al., 2006). También incluimos la proporción de votos de cada partido o coalición en la elección federal previa.13 De este modo, podemos estimar el efecto de una elección concurrente para los diferentes partidos en el gobierno estatal, controlando por la fuerza electoral de cada partido a nivel distrital. Es claro que esta especificación podría mejorarse incluyendo otras variables que capturen el posible efecto de arrastre de las elecciones locales; sin embargo, nuestro propósito aquí es meramente ilustrar con un ejemplo la aplicación de nuestro modelo estadístico para un fenómeno de interés.14
Con este modelo base, podemos estimar el resultado electoral en distritos con y sin elecciones locales concurrentes. El siguiente paso consiste en estimar el resultado electoral en un escenario hipotético en que todos los distritos del país hubieran tenido elecciones concurrentes. Para hacer esto, simulamos mil resultados electorales fijando el valor de nuestra variable binaria clave (concurrencia) igual a 1 para todos los distritos (y modificando sus respectivas interacciones partidistas), mientras que mantenemos las demás variables en sus valores observados.15
El panel A de la figura 3 muestra la distribución del voto distrital simulado para los tres principales partidos políticos, y lo compara con el voto realmente observado en 2009. Las líneas sólidas en cada gráfica indican la media de cada distribución simulada bajo concurrencia, mientras que las líneas punteadas representan el voto distrital promedio observado, y las áreas sombreadas indican los intervalos de confianza en 95 por ciento. Como se puede apreciar, el resultado electoral promedio hubiera sido prácticamente el mismo para el PRI que para el PRD (perderían en promedio menos de un punto porcentual en cada distrito) mientras que el pan obtendría aproximadamente dos puntos porcentuales más en el escenario contrafactual. La distancia entre el voto simulado y observado solamente es estadísticamente significativa en el caso del pan . Este resultado se debe a que el pan obtuvo más votos en las entidades con elecciones concurrentes en 2009 que en el resto de los estados.16

El efecto que ejercen las elecciones concurrentes sobre el porcentaje de votos tiene a su vez un impacto en el número de curules para cada partido. El panel B de la figura 3 muestra las distribuciones de probabilidad del número de curules obtenido por los principales partidos políticos en el escenario hipotético. Estas distribuciones se obtuvieron a partir de las votaciones simuladas en las gráficas del panel A, y con el método de asignación de curules previsto en la ley electoral vigente. Las líneas sólidas indican la moda de las distribuciones, y las líneas punteadas el número de curules observado. Como se aprecia en la gráfica del PRI , la reforma no afectaría de manera significativa el tamaño de su bancada, mientras que la del pan aumentaría en aproximadamente 18 diputados y la del PRD disminuiría en aproximadamente 11 diputados.
La figura 4 ofrece algunos elementos para entender mejor estos resultados. Las gráficas muestran las mismas distribuciones del panel B de la figura 3, en un formato que enfatiza el valor promedio de cada distribución y distingue por separado el resultado para los diputados uninominales y plurinominales. En primer lugar, la gráfica de las curules de mayoría muestra que los cambios que produce la reforma se registran principalmente en el componente mayoritario del sistema electoral. El PAN obtendría 19 diputados uninominales más de los que consiguió en 2009, el PRD 10 diputados menos, y el PRI nueve diputados menos. Estas cifras sugieren que los cambios relativamente pequeños en el porcentaje de voto esperado para cada partido en el panel A de la figura 3 provienen de cambios abruptos en unos cuantos distritos, o bien afectan a varios distritos altamente competidos donde el partido ganador cambia dado el estrecho margen de victoria. Toda vez que el método realiza simulaciones para cada distrito, podemos distinguir entre uno y otro tipo de resultado.

En segundo lugar, la figura 4 muestra que el número de diputados plurinominales es muy parecido al observado para casi todos los partidos. Esto es consistente con el principio de representación proporcional y el hecho de que la reforma no modifica sustancialmente la votación total de los partidos. Sin embargo, el intervalo de confianza del PRI es considerablemente más amplio que el de los demás partidos. Esto sucede debido a la cláusula de sobrerrepresentación: en 2009, al PRI le fueron deducidos 27 diputados para que su porcentaje de curules en la Cámara de Diputados no excediera en más de ocho puntos su porcentaje de votación nacional efectiva. De la misma manera, en 99.4 por ciento de las elecciones simuladas, el PRI se ubicó dentro de los supuestos de la cláusula de sobrerrepresentación. Por lo tanto, la estimación del número de curules plurinominales del PRI reproduce la incertidumbre del resultado en los distritos de mayoría relativa: cuando obtiene menos curules uninominales, recibe más de representación proporcional y viceversa. Por eso, su número total de curules es muy parecido al observado y sus intervalos de confianza son relativamente estrechos.
Otra manera de presentar los resultados del modelo es a través de pruebas de hipótesis. En lugar de utilizar estimaciones puntuales e intervalos de confianza, las gráficas de la figura 5 nos permiten transmitir nuestros resultados en términos probabilísticos. Cada gráfica indica la probabilidad de que el número de curules de un partido sea mayor o igual a cierta cifra o proporción de interés. La construcción de estas gráficas es muy sencilla; por ejemplo, para averiguar la probabilidad de que un partido tenga al menos cien curules con la reforma basta con registrar el número de simulaciones en que ese partido tiene más de cien curules y luego dividirlo entre el total de las simulaciones.
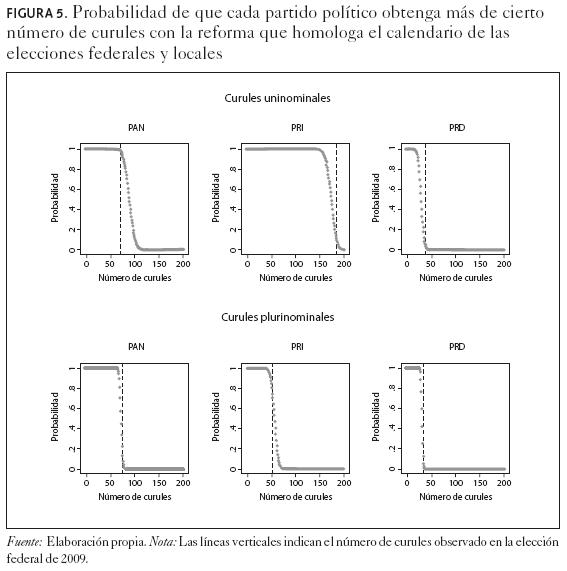
Cabe mencionar que la distribución del número de curules también se puede transformar fácilmente en otras distribuciones de interés. Por ejemplo, podemos aproximar la distribución del índice de Banzhaf (1964), o del número efectivo de partidos, calculándolos para cada simulación de la conformación hipotética de la cámara baja.
Disminución del número de curules plurinominales
En esta sección ilustramos una aplicación de nuestro método estadístico para evaluar una reforma que disminuye el número de curules plurinominales en la Cámara de Diputados; es decir, esta reforma modifica el método de asignación de curules. Lo anterior significa que el modelo de regresión sirve únicamente para para separar a los factores sistemáticos (preferencias de los votantes) de los aleatorios (eventos fortuitos, como errores humanos en el conteo de los votos) (Gelman y King, 1994; King et al., 1994). También significa que el criterio principal para seleccionar las variables explicativas es que ayuden a predecir lo mejor posible las variables dependientes (Gelman y Hill, 2007).
Los datos para el análisis provienen de los cómputos distritales de la elección de diputados federales de 2006, agregados por distrito electoral federal (n = 300) (IFE, 2006). Las variables dependientes son los log ratios de la proporción de votos del PAN , la Alianza por México (APM = PRI + PVEM), la Coalición por el Bien de Todos (PBT = PRD + PT + Convergencia) y Nueva Alianza (NA), respecto a la proporción de votos del partido Alternativa (ASDC). Las variables explicativas son los log ratios de la proporción de votos que esos mismos partidos obtuvieron en la elección presidencial de 2006 y dos variables dicotómicas que indican si el PAN o el PRD obtuvieron más votos que el resto de los partidos en la elección para diputados federales de 2003.17 Puesto que el objetivo de la regresión es predecir el resultado electoral, al simular valores de la distribución fijamos los valores de las variables explicativas en sus valores reales, Xi(hip) = Xi.
¿Qué efecto tiene esta reforma en la composición de la Cámara de Diputados? La figura 6 muestra la asignación de curules que ocurrió en 2006 y la compara con la distribución del número de curules en un escenario contrafactual con sólo cien asientos de representación proporcional. Los puntos indican la media de las distribuciones de probabilidad, las líneas horizontales denotan los intervalos de confianza en 95 por ciento y los círculos, el número de curules observado en 2006. Como se puede apreciar, esta reforma sólo afecta a las diputaciones plurinominales, por lo que las diferencias en el número de curules uninominales entre el resultado observado y nuestro escenario hipotético son muy pequeñas y teóricamente se deben a eventos aleatorios. En cambio, todos los partidos muestran una reducción en el número de curules plurinominales a consecuencia de la reducción del tamaño del Congreso.

Como se puede observar, la reforma que reduce el número de curules plurinominales en 50 por ciento se traduce en una disminución casi proporcional de diputaciones plurinominales para todos los partidos. Esto significa que, en términos porcentuales, prácticamente no existen diferencias entre la composición observada de la Cámara de Diputados y el escenario hipotético. El cuadro 2 muestra el porcentaje de curules que los partidos recibieron en la elección de 2006, y lo compara tanto con el porcentaje de votos obtenidos como con el porcentaje de curules que hubieran obtenido con la reforma. La diferencia entre votos y curules ilustra el sesgo mayoritario del sistema electoral vigente. Sin embargo, los porcentajes de curules con y sin reforma son muy parecidos: en ningún caso la diferencia entre el escenario observado y el hipotético es mayor a un punto porcentual.

Este ejercicio puede generalizarse para diferentes tamaños de la Cámara de Diputados. La figura 7 ilustra el tamaño relativo de las bancadas como una función del número de curules plurinominales en un rango de 0 a 300. Las simulaciones utilizan los resultados electorales de 2006 y asumen que los resultados de los 300 distritos de mayoría relativa permanecen sin cambio. Es decir, estamos simulando una Cámara mixta que va de 300 a 600 asientos con una composición cada vez más proporcional. Como se aprecia, incluso en este rango considerablemente amplio, el porcentaje de curules totales no varía más de cuatro puntos porcentuales respecto al porcentaje observado en realidad (líneas punteadas). Casar (2009) llega a las mismas conclusiones cuando analiza una reforma similar con los resultados de las elecciones federales de 1997 a 2009. La razón de que estas variaciones sean pequeñas es que cien curules de representación proporcional es un número suficientemente grande como para mantener resultados razonablemente proporcionales (Rae, 1967; Taagepera y Shugart, 1989). De hecho, el número de curules plurinominales en Israel —un país al que se recurre con frecuencia para ilustrar los sistemas electorales de representación proporcional "pura"— es de 120.

Conforme la cámara baja se hace más proporcional, la bancada del pan y de la Coalición por el Bien de Todos (PBT) —los partidos punteros en 2006— disminuye en términos relativos. Por otro lado, las bancadas de la Alianza por México (PRI + PVEM), NA y ASDC aumentan relativamente conforme crece el número de plurinominales —tal como es de esperarse en una Cámara menos mayoritaria—. Vale la pena destacar los picos que se observan en el rango de 0 a 25 curules plurinominales. Con cero curules de representación proporcional, el pan hubiera conseguido 45.3 por ciento de la Cámara en 2006 (pues ganó en 135 de 300 distritos uninominales). Sin embargo, al tener 24 curules plurinominales, el PAN hubiera alcanzado el tope de sobrerrepresentación (8 por ciento entre votos y curules totales), razón por la cual su proporción de curules hubiera disminuido bruscamente y se mantendría constante hasta que la Cámara tuviera más de 124 curules de representación proporcional. Al haber suficientes curules plurinominales, el tope de sobrerrepresentación deja de ser vinculante para el pan y su porcentaje de curules se aproximaría paulatinamente a su porcentaje del voto nacional (33.41%). Una lógica similar explica la pendiente negativa de la proporción de curules del PBT, segunda fuerza en la elección de 2006. Por otro lado, conforme la cámara baja se hace más proporcional, la coalición APM consigue un mayor porcentaje de curules.
En diciembre de 2009, el presidente de la república envió al Congreso una iniciativa de reforma que propone disminuir en cien asientos la Cámara de Diputados. A diferencia de nuestro ejemplo, la propuesta busca reducir proporcionalmente las curules de mayoría (de 300 a 240) y de representación proporcional (de 200 a 160). Es probable que la motivación de mantener el ratio de curules uninominales y plurinominales sea mantener el equilibrio de fuerzas en la legislatura. Paradójicamente, una reducción en los asientos de mayoría, y no tanto en los de representación proporcional, modificaría la correlación de fuerzas en la Cámara de Diputados. Esto se debe a que la reducción de los diputados uninominales implica necesariamente un proceso de redistritación, el cual puede modificar notablemente el número de curules de los partidos políticos, en particular de aquellos que tienen una base electoral regionalmente concentrada (Gudgin y Taylor, 1979; Grofman y King, 2007; Taagepera y Shugart, 1989).
Conclusiones
Hace casi veinte años, King (1989) observó que dada la creciente cantidad de datos disponibles para los investigadores en ciencia política, el desarrollo de nuevos métodos estadísticos para analizarlos tendría un efecto "desproporcionado" en la disciplina. Sin lugar a dudas, la literatura sobre el Poder Legislativo en México se encuentra en esa fase de expansión. Por una parte, existen excelentes fuentes de información sobre datos electorales (IFE, Atlas electorales locales) e indicadores censales desagregados al nivel de las unidades electorales. Además, en los últimos meses se han presentado diversas iniciativas de reforma del sistema electoral cuyos efectos potenciales constituyen, por sí mismos, una amplia agenda de investigación tanto teórica como empírica. Finalmente, la metodología política ha tenido enormes avances en la generación de técnicas y herramientas para analizar los datos electorales de países como México. El modelo Monte Carlo para la Cámara de Diputados que presentamos en esta nota de investigación pretende incorporar algunos de estos avances para coadyuvar al desarrollo de los estudios sobre el sistema político mexicano en general y del Congreso en particular.
Entre las propuestas de reforma concretas que nuestro modelo permite analizar se encuentran: cambiar el número de asientos del Congreso, modificar la proporción de asientos uninominales y plurinominales, cambiar tanto el umbral de representación como el tope de sobrerrepresentación. Por otro lado, el modelo es lo suficientemente general y flexible como para adaptarse fácilmente al estudio de otras instituciones legislativas, como el Senado. Además, debido a que las legislaturas estatales tienen un sistema electoral semejante al de la Cámara de Diputados, nuestro modelo también puede utilizarse para analizar el efecto de diversas reformas electorales en el ámbito local.
El marco en que se desarrolla el modelo también puede adaptarse para analizar otras consecuencias de los resultados electorales, más allá de la conformación propia del Congreso, como pueden ser la identificación de bancadas pivotales o la asignación del financiamiento público y el acceso a medios para los partidos políticos. Esto porque desde un punto de vista estadístico no existen grandes diferencias entre analizar cantidades de interés tales como el número de curules, el tamaño relativo de las bancadas, la probabilidad de ganar o perder un distrito o incluso estimar las prerrogativas que corresponderían a cada partido de acuerdo con los resultado electorales.
En el ámbito metodológico, el modelo estadístico también puede complementarse con otros métodos de estimación de los resultados electorales distintos al desarrollado en esta nota. Por ejemplo, las simulaciones pueden obtenerse con métodos bayesianos o de cadenas markovianas (MCMC), adaptarse para bases de datos longitudinales (TSCS, por sus siglas en inglés), o bien extenderse para la especificación de modelos jerárquicos que combinen datos con diferentes niveles de agregación.
Referencias bibliográficas
Aitchison, J. (1982), "The Statistical Analysis of Compositional Data", Journal of the Royal Statistical Society, Series B (Methodological), pp. 139–177. [ Links ]
Banzhaf, J.F. (1964), "Weighted Voting Doesn't Work: A Mathematical Analysis", Rutgers Law Review, 19, pp. 317–343. [ Links ]
Brambor, T., W.R. Clark y M. Golder, "Understanding Interaction Models: Improving Empirical Analyses", Political Analysis, 14(1), pp. 63–82. [ Links ]
Breusch, T.S., J.C. Robertson y A.H. Welsh (1997), "The Emperor's New Clothes: A Critique of the Multivariate t Regression Model", Statistica Neerlandica, 51(3), pp. 269–286. [ Links ]
Casar, M. (2009), "Reformas en el aire", Nexos, 12. [ Links ]
Cox, N.J. (2002), "Speaking Stata: How to Face Lists with Fortitude", The Stata Journal, 2, pp. 202–222. [ Links ]
Díaz–Cayeros, A. (2005), "Endogenous Institutional Change in the Mexican Senate", Comparative Political Studies, 38(10), pp. 1196–1218. [ Links ]
Gelman, A. y G.A. King (1990), "King Estimating the Electoral Consequences of Legislative Redistricting", Journal of the American Statistical Association, 85(410), pp. 274–282. [ Links ]
–––––––––– (1994), "Unified Method of Evaluating Electoral Systems and Redistricting Plans", American Journal of Political Science, 38(2), pp. 514–554. [ Links ]
Gelman, A. y J. Hill (2007), Data Analysis Using Regression and Multilevel/Hierarchical Models, Cambridge, Cambridge University Press. [ Links ]
Greene William, H. (2000), "Econometric Analysis", Handbook of Econometrics, 3. [ Links ]
Grofman, B. y G. King (2007), "The Future of Partisan Symmetry as a Judicial Test for Partisan Gerrymandering after LULAC vs. Perry", Election Law Journal, 6(1), pp. 2–35. [ Links ]
Gudgin, G. y P.J. Taylor (1979), Seats, Votes, and the Spatial Organisation of Elections, Londres, Routledge Kegan y Paul. [ Links ]
Herron, M.C., "Postestimation Uncertainty in Limited Dependent Variable Models", Political Analysis, 8(1), pp. 83–98. [ Links ]
Honaker, J., J.N. Katz y G.A. King (2002), "Fast, Easy, and Efficient Estimator for Multiparty Electoral Data", Political Analysis, 10(1), pp. 84–100. [ Links ]
Instituto Federal Electoral (IFE) (2006), Cómputos distritales de la elección de diputados federales, IFE. [ Links ]
–––––––––– (2009), Cómputos distritales de la elección de diputados federales, IFE. [ Links ]
Jackman, S. (2000a), "Estimation and Inference are Missing Data Problems: Unifying Social Science Statistics Via Bayesian Simulation", Political Analysis, 8(4), pp. 307–332. [ Links ]
–––––––––– (2000b), "Estimation and Inference Via Bayesian Simulation: An Introduction to Markov Chain Monte Carlo", American Journal of Political Science, 44(2), pp. 375–404. [ Links ]
–––––––––– (2004), "Bayesian Analysis for Political Research", Annual Review of Political Science, 7, pp. 483–505. [ Links ]
–––––––––– (2009) Bayesian Analysis for the Social Sciences, Wiley. [ Links ]
Jackson, J.E. (2002), "A Seemingly Unrelated Regression Model for Analyzing Multiparty Elections", Political Analysis, 10(1), pp. 49–65. [ Links ]
Jones, M.P. (1997), "Federalism and the Number of Parties in Argentine Congressional Elections", The Journal of Politics, 59(2), pp. 538–549. [ Links ]
Katz, J.N. y G.A. King (1999), "Statistical Model for Multiparty Electoral Data", The American Political Science Review, 93(1), pp. 15–32. [ Links ]
King, G. (1989), Unifying Political Methodology, Cambridge, Cambridge University Press. [ Links ]
–––––––––– (1997), A Solution to the Ecological Inference Problem: Reconstructing Individual Behavior from Aggregate Data, Princeton, Princeton University Press. [ Links ]
King, G., M. Tomz y J. Wittenberg (2000), "Making the Most of Statistical Analyses: Improving, Interpretation, and Presentation", American Journal of Political Science, 44(2), pp. 347–361. [ Links ]
King, G., R.O. Keohane y S. Verba (1994), Designing Social Inquiry: Scientific Inference in Qualitative Research, Princeton, Princeton University Press. [ Links ]
Magar, E. (2006), "Gubernatorial Coattails and Mexican Congressional Elections since 1979", en M.S. Shugart y J. Weldon (eds.), What Kind of Democracy has Mexico? The Evolution of Presidentialism and Federalism (en prensa), Stanford, Stanford University Press. [ Links ]
Martin, A. (2008), "Bayesian Analysis", en J. Box–Steffensmeier y D. Collier (eds.), The Oxford Handbook of Political Methodology, Oxford, Oxford University Press. [ Links ]
Mondak, J.J. y C. McCurley (1994), "Cognitive Efficiency and the Congressional Vote: The Psychology of Coattail Voting", Political Research Quarterly, 47(1), pp. 151–175. [ Links ]
Rae, D.W. (1967), The Political Consequences of Electoral Laws, New Haven, Yale University Press. [ Links ]
Rosenbaum, P.R. (1984), "The Consequences of Adjustment for a Concomitant Variable that Has Been Affected by the Treatment", Journal of the Royal Statistical Society: Series A (General), 147(5), pp. 656–666. [ Links ]
Samuels, D.J. (2000), "The Gubernatorial Coattails Effect: Federalism and Congressional Elections in Brazil", The Journal of Politics, 62(1), pp. 240–253. [ Links ]
StataCorp (2009), Stata: Release 11: Statistical Software, College Station, Stata Press. [ Links ]
Taagepera, R. y M.S. Shugart (1989), Seats and Votes: The Effects and Determinants of Electoral Systems, New Haven, Yale University Press. [ Links ]
Tomz, M., J.A. Tucker y J. Wittenberg (2002), "An Easy and Accurate Regression Model for Multiparty Electoral Data", Political Analysis, 10 (1), pp. 66–83. [ Links ]
Tomz, M., J. Wittenberg y G. King (2003), "Clarify: Software for Interpreting and Presenting Statistical Results", Journal of Statistical Software, 8(1), pp. 1–30. [ Links ]
Weldon, J. (2001), "The Consequences of Mexico's Mixed–Member Electoral System,1988–1997", en M.S. Shugart y M.P. Wattenberg (eds.), Mixed–Member Electoral Systems: The Best of Both Worlds?, Oxford, Oxford University Press. [ Links ]
Western, B. y S. Jackman (1994), "Bayesian Inference for Comparative Research", The American Political Science Review, 88(2), pp. 412–423. [ Links ]
1 Una notable excepción es Díaz–Cayeros (2005).
2 El paquete funciona en Stata versión 10.0 o superior, y está disponible en: http://www.buendiaylaredo.com/investigacion y http://investigadores.cide.edu/aparicio/camaradip.
3 Por otro lado, cuando el objetivo es analizar un comportamiento individual que genera un resultado agregado, es recomendable emplear un modelo de inferencia ecológica (King, 1997).
4 La distribución de probabilidad es el rango de valores que un parámetro o estadístico puede tomar en una muestra aleatoria de cierta población y las probabilidades asociadas con esos valores.
5 Katz y King (1999) argumentan que la distribución normal multivariada no se ajusta correctamente a los datos electorales multipartidistas, y que en su lugar debería emplearse la distribución t. Sin embargo, los experimentos de Tomz et al. (2002) muestran que ambas distribuciones arrojan resultados muy parecidos, en particular cuando las cantidades de interés son votos o curules en la legislatura. Como los autores afirman, "al adoptar la distribución normal se pierde poco de interés sustantivo pero se gana mucho en términos de facilidad" (p. 71). Su investigación también cita los hallazgos de Breusch et al. (1997), quienes sostienen que "aunque los dos modelos son diferentes matemáticamente, para fines de inferencia estadística son indistinguibles" (p. 269).
6 Este supuesto distribucional es relativamente restrictivo. Como Jackman (2000a, p. 309) afirma: "Si la aproximación asintótica normal es débil, las inferencias y predicciones de los modelos pueden ser erróneas. Esto constituye un verdadero peligro para las simulaciones post–estimación [...], las cuales toman muestras de la distribución asintótica normal multivariada de θ para hacer una aproximación de la distribución posterior de una cantidad auxiliar Ψ =h(θ)". Las simulaciones de Monte Carlo generadas con cadenas de Markov ofrecen una solución a este problema, pues permiten trazar valores de la distribución finita, en lugar de basarse en el teorema del límite central para justificar la aproximación normal multivariada (Western y Jackman, 1994). El comando asignadip resulta útil para los investigadores que prefieren utilizar este método para hallar la distribución posterior del porcentaje de votos de los partidos.
7 Si se desea obtener un valor esperado en lugar de un valor predicho, . Es importante señalar que esta propiedad no es generalizable a otros modelos estadísticos (King et al., 2000, p. 351).
. Es importante señalar que esta propiedad no es generalizable a otros modelos estadísticos (King et al., 2000, p. 351).
8 En este paso agregamos el subíndice/para diferenciar los valores predichos de los partidos en el modelo del valor predicho del partido usado como referencia en la transformación logística multivariada.
9 También véase Tomz et al. (2002).
10 Por "porcentaje de votación" se entiende la votación nacional emitida. Esta disposición no se aplica cuando la sobrerrepresentación se debe a los triunfos en distritos uninominales.
11 Véase el archivo de ayuda tecleando help asignadip en la ventana de comandos de Stata.
12 Los gobiernos priístas son la categoría de referencia.
13 Los detalles de la codificación están disponibles, previa solicitud a los autores.
14 Por ejemplo, podría distinguirse entre la concurrencia de elecciones municipales y federales, por un lado, y la de gobernadores, por otro. Para hacer esto, el número de interacciones partidistas también tendría que duplicarse. Dado el reducido número de casos de elecciones concurrentes del primer tipo en 2009, estimamos el efecto de la concurrencia sin hacer tal distinción.
15 El código para replicar este análisis está disponible, previa solicitud a los autores.
16 Agradecemos a un dictaminador anónimo por señalar este punto.
17 Los distritos ganados por el PRI en 2003 son la categoría de referencia. Los datos consideran el proceso de redistritación que ocurrió entre 2003 y 2006.

