










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkPolítica y gobierno
versão impressa ISSN 1665-2037
Polít. gob vol.17 no.1 Ciudad de México Jan. 2010
Artículos
Las implicaciones empíricas de los modelos teóricos (IEMT): Un marco de referencia para la unificación metodológica
The Empirical Implications of Theoretical Models (EITM): A Framework for Methodological Unification
Jim Granato*, Melody Lo** y M.C. Sunny Wong***
* Profesor–investigador del Centro de Política Pública y del Departamento de Ciencia Política de la Universidad de Houston. 104 Heyne Building Houston, Texas 772045021. Tel: (713) 743 38 87. Correo electrónico: jgranato@uh.edu.
** Profesora asociada del Departamento de Economía en el Colegio de Negocios de la Universidad de Texas en San Antonio. BB 4.03.22, One UTSA Circle–San Antonio, TX 78249–0631. Tel: 210 458 49 10. Correo electrónico: melody.lo@utsa.edu.
*** Profesor asistente del Departamento de Economía de la Universidad de San Francisco. 2130 Fulton Street San Francisco, CA 94117. Tel: (415) 422 61 94. Correo electrónico: mwong11@usfca.edu.
Artículo recibido en junio de 2008.
Aceptado para su publicación en julio de 2009.
Resumen
Ofrecemos un marco de referencia para la iniciativa de las implicaciones empíricas de los modelos teóricos (IEMT). El objetivo de las IEMT es inducir a los especialistas en ciencias políticas y sociales a poner a prueba modelos empíricos directamente vinculados con un modelo formal. Cuando los especialistas fusionan el análisis formal y el empírico, minimizan las prácticas no falsables y sientan las bases de la acumulación en ciencias sociales. Nuestro marco de IEMT involucra tres pasos. El primero es para que los investigadores unifiquen los hechos probables y los conceptos estadísticos aplicados. El segundo paso consiste en desarrollar recursos mensurables ("análogos") para esos mecanismos y conceptos. Y en el último paso se unifican los análogos. La importancia del marco de referencia de las IEMT radica en que promueve que los especialistas utilicen un conjunto de hechos o axiomas plausibles y que luego los modelen de una manera matemática rigurosa, a fin de identificar relaciones causales que expliquen regularidades empíricas.
Palabras clave: implicaciones empíricas de los modelos teóricos (IEMT), conceptos estadísticos aplicados, hechos probables, axiomas, regularidades empíricas.
Abstract
We provide a framework for the Empirical Implications of Theoretical Models (EITM) initiative. The objective of EITM is to encourage political and social scientists to test empirical models that are directly connected to a formal model. As scholars merge formal and empirical analysis they minimize non–falsifiable research practices and lay the foundation for social scientific cumulation. Our EITM framework involves three steps. The first step is for researchers to unify theoretical mechanisms and applied statistical concepts. Step two is to develop measurable devices ("analogues") for these mechanisms and concepts. The final step is to unify the analogues. The significance of the EITM framework is that it encourages scholars to use a set of plausible facts or axioms and then model them in a rigorous mathematical manner to identify causal relations that explain empirical regularities.
Keywords: Empirical Implications of Theorical Models (EITM), applied statistical concepts, plausible facts, axioms, empirical regularities.
Introducción
Antecedentes y justificación
El 9 y 10 de julio de 2001 el Programa de Ciencias Políticas de la National Science Foundation (NSF) convocó a un taller para analizar formas de mejorar la aptitud técnico–analítica en ciencias políticas. Este taller, parte del proceso de planeación involucrado con la iniciativa de las implicaciones empíricas de los modelos teóricos (en adelante IEMT), se celebró para sugerir enfoques constructivos a fin de propiciar la vinculación entre el análisis formal y la modelación empírica.1
En el taller se reconoció que existía un cisma entre los que se dedican a la modelación formal que se concentra en cuantificar matemáticamente conceptos abstractos y quienes emplean la modelación empírica que hace hincapié en la estadística aplicada. Como consecuencia, buena parte de la investigación en ciencias políticas es competente en un área técnica pero deficiente en otra. Este problema se manifiesta en la investigación que involucra la modelación formal con pruebas de escasa calidad (o no) o de modelado estadístico aplicado sin claridad formal. Esa competencia menguada contribuye a la incapacidad de identificar las causas próximas que se explican en una teoría y, a su vez, eleva la dificultad de lograr un avance significativo del conocimiento científico.
Algunos politólogos han escrito acerca de las limitaciones científicas que se vinculan con el trabajo cuantitativo desarticulado. Por ejemplo, Morton (1999) discute estas cuestiones en los siguientes términos:
A medida que ha ido avanzando el uso de técnicas metodológicas en ciencias políticas, los investigadores han descubierto que su estudio empírico lleva con frecuencia a nuevas interrogantes, las cuales requieren una aportación teórica. No obstante, ya sea porque poca de la teoría existente resulta pertinente o porque la teoría bien desarrollada con que se cuenta parece no estar conectada con las cuestiones empíricas, la respuesta habitual consiste en usar métodos más sofisticados de compilación de datos para responder a esas preguntas sin hacer referencia a una teoría plenamente desarrollada. Pero estos nuevos métodos conducen muchas veces a más interrogantes todavía, las que a su vez dan por resultado el uso de métodos aún más sofisticados para recabar o analizar los datos. La conexión con la teoría se pierde, al parecer, en la discusión metodológica. Los investigadores raras veces toman los resultados empíricos y rehacen el marco teórico de referencia que dio principio a la discusión (p. 6).
Estas preocupaciones fueron compartidas también por el taller de IEMT de la NSF en 2001. Al diagnosticar las fuentes de ese statu quo metodológico, el informe de las IEMT de la NSF llegaba a la siguiente conclusión:
Hay por lo menos dos razones que explican este estado de competencia de la investigación. Una es que la formación formal y empírica rigurosa es un acontecimiento relativamente reciente en ciencias políticas. Otra consiste en que existen obstáculos significativos en el actual entorno de la formación en ciencias políticas. El primer obstáculo es el tiempo. Los estudiantes que deseen aprender modelación tanto formal como empírica tardarán más en alcanzar un doctorado, y la mayoría de los programas de posgrado no tienen los recursos necesarios para sostener a los alumnos durante más de cuatro o cinco años. En consecuencia, los estudiantes suelen tomar la secuencia de clases de modelación formal o empírica, pero raras veces ambas secuencias. El segundo obstáculo consiste en establecer centros de competencia en modelación formal y empírica en la formación misma. La disciplina de la economía brinda un buen ejemplo. Los estudiantes de posgrado en economía deben cursar un año completo (por lo general) de matemáticas para economistas. Este enfoque matemático (y cuantitativo) se ve reforzado en cursos sustantivos que suelen impartirse como una ciencia analítica en un estilo de demostración por teoremas.
Estas fuerzas han contribuido a que existan tres prácticas de la estadística aplicada nocivas pero comunes: la minería de datos, los botes de basura y el uso de pesar y parchar las estadísticas (matrices omega).2 Estas prácticas de las estadísticas aplicadas carecen de robustez general, ya que opacan un error fundamental de especificación. Para ver cómo ocurre esto sintetizamos cada una de las prácticas (Granato y Scioli, 2004).
1. Minería de datos: Esta práctica consiste en poner datos en un paquete estadístico con un mínimo de teoría. Luego se calculan las regresiones (probabilidades) hasta que se encuentran uno o más coeficientes estadísticamente significativos que le gusten al autor. Esta búsqueda progresiva no es aleatoria y tiene poco que ver con la identificación de mecanismos causales (véanse Lovell, 1983; Denton, 1985).
2. Botes de basura: Esta práctica, relacionada con la minería de datos, es aquella en la que un investigador incluye en un paquete estadístico, de manera desordenada, una plétora de variables independientes y en algún lado obtiene resultados estadísticos "significativos". Los investigadores que emplean modelos de bote de basura suelen prestarles poca atención a los factores que generan confusión y que podrían corromper las inferencias estadísticas. También son escasos y muy ocasionales los esfuerzos por identificar un mecanismo causal subyacente (Achen, 2005).
3. Matrices omega: Es casi un hecho que los enfoques de la minería de datos y el bote de basura se desmoronarán estadísticamente. La pregunta es qué hacer cuando se producen esas fallas. Hay maneras muy complejas de utilizar técnicas de ponderación para corregir las especificaciones incorrectas de los modelos o para usar otros parches estadísticos que influyen sobre el error estándar (b). Casi en cualquier libro de texto intermedio de econometría se encuentra una sección con el símbolo griego Ω (omega) (véase Johnston y DiNardo, 1997, p. 189). este símbolo es representativo del proceso por el cual un investigador pesa los datos desplegados (en forma de matriz) de manera que los errores estadísticos y, en última instancia, el error estándar que se mencionó antes resultan alterados y se manipula el estadístico t. en teoría no tiene nada de malo conocer la matriz omega de un modelo estadístico determinado. Εl o los errores estándar que produce una matriz omega sólo deberían servir para corroborar si las inferencias se han confundido hasta el punto de cometer un error de tipo I o de tipo II. Con excesiva frecuencia, sin embargo, los investigadores tratan los ponderadores omega (u otros parches estadísticos) como resultados de modelos verdaderos. Esta actitud obstaculiza el progreso científico porque usa los errores de un modelo para oscurecer las fallas.3
También podemos evaluar estas prácticas actuales en relación con la manera en que no logran contribuir a un diálogo, entre la teoría y la prueba, para el modelado (véase la figura 1). Lo que vemos es que los procesos de predicción y validación nunca se aplican directamente. Antes bien, las pruebas empíricas se mantienen en un círculo cerrado o un diálogo consigo mismas. Un proceso iterativo de minería de datos, botes de basura y el uso de parches estadísticos (matrices omega) sustituye a la predicción y la validación.

Hasta aquellos especialistas deseosos de establecer robustez en sus resultados de estadísticas aplicadas observan que las herramientas disponibles son inadecuadas cuando no se usan con una contraparte formal. Por ejemplo, complementar las pruebas estadísticas aplicadas con un análisis de límites extremos (ALE) (Leamer, 1983) proporciona una verificación de la estabilidad de los parámetros, pero la prueba es ex post y no permite una predicción ex ante4 Esto no debería resultar sorprendente si se consideran los efectos de los covariados no especificados previamente en este procedimiento. Cada vez que se vuelve a especificar un modelo estadístico aplicado, todo el modelo está sujeto a cambio. En ese sentido todas las predicciones son frágiles, pero sin el uso a priori de condiciones de equilibrio (es decir, condiciones de estabilidad) en un modelo formal, los "cambios" de parámetro en un procedimiento como el ALE son de origen desconocido.5
Como las prácticas actuales de las estadísticas aplicadas no logran desarrollar modelos formales que analicen estas interacciones, ponemos el énfasis sobre el comportamiento de la modelación. Hay investigación académica más que suficiente para contribuir a esta ruptura con la práctica metodológica vigente. La Comisión Cowles, por ejemplo, tiene un venerable historial de establecimiento de condiciones en las cuales pueden identificarse los parámetros estructurales.6 A fin de contribuir con esta diferenciación se introdujeron condiciones de identificabilidad. Este trabajo forma parte ahora de los textos habituales de econometría.7
No obstante, estas contribuciones han sido marginadas y en la situación actual el trabajo denominado técnico se conecta sólo en forma muy laxa con la consideración científica fundamental de la falsación. Basarse en resultados estadísticamente significativos no quiere decir nada cuando el investigador no se esfuerza demasiado por identificar el origen preciso de los parámetros en cuestión. Al estar ausente este esfuerzo de identificación no resulta evidente dónde se equivoca el modelo. En un sentido diferente, las prácticas actuales se están adelantando a sí mismas: tenemos que establecer, antes que cualquier otra cosa, algún medio de falsar nuestros modelos.
En este artículo describimos un marco de IEMT para redirigir la práctica metodológica de tal forma que los modelos y parámetros tengan orígenes identificables que permitan su falsación. El marco de referencia de IEMT atiende estas cuestiones por medio de la unificación del análisis formal y el empírico; este marco aprovecha las propiedades de reforzarse mutuamente que tienen esos dos tipos de análisis para enfrentarse al reto señalado arriba.
Otro atributo de este marco de referencia es su énfasis en conceptos que son generales e integrales para muchos campos de investigación, pero que pocas veces se modelan y prueban de forma directa. Las IEMT hacen hincapié en encontrar maneras de modelar el comportamiento y la acción humanos y, por ello, contribuyen a crear representaciones realistas que constituyen una mejora en relación con la simple categorización socioeconómica. Numerosas disciplinas de las ciencias sociales concentran mucho esfuerzo de investigación en las interacciones entre el comportamiento del agente y las políticas públicas.
Este trabajo está organizado como sigue. En la próxima sección analizamos los puntos o componentes del marco de las IEMT. En la tercera sección se incluyen dos aplicaciones del mismo a la investigación: "macropartidismo" y votación económica. La última parte sintetiza esos resultados y brinda algunos comentarios a manera de conclusión sobre cómo la formación de posgrado tendrá que evolucionar para proporcionar las herramientas formales y empíricas necesarias a fin de aplicar el marco de referencia de las IEMT a una diversidad de áreas de investigación.
IEMT: Un marco de referencia para la unificación metodológica
Para revertir el actual énfasis metodológico —y construir una ciencia acumulativa de la política— presentamos un marco de referencia que construye a partir de investigaciones cuantitativas previas. Tiene tres objetivos: el primero es usar el marco de las IEMT para sustentar un proceso científico acumulativo dirigido a encontrar un mecanismo causal. La capacidad de un investigador de examinar minuciosamente vínculos causales específicos es fundamental para el trabajo científico. Cuando se utilizan herramientas cuantitativas, un modelo que vincule los enfoques tanto formal como empírico pone sobre aviso a los investigadores en relación con los resultados cuando hay condiciones específicas. Es asimismo una de las mejores maneras de determinar una relación "causal" identificada.
Un segundo objetivo es promover las interacciones interdisciplinarias. El marco de las IEMT que presentamos se basa en el trabajo original de la Comisión Cowles, integrada por un grupo de economistas de inclinaciones cuantitativas. Las contribuciones de esta comisión se basan, en parte, en una visión científica que implicaba fusionar el análisis formal y el de la estadística aplicada.8
El tercer objetivo es difundir el enfoque de la Comisión Cowles. La metodología de la misma creó una nueva investigación dirigida a determinar inferencias válidas al poner el énfasis en la identificación y la invarianza de las propiedades. Para la identificación (es decir, el rango y otras condiciones) se desarrollaron reglas tales que la ecuación de un modelo podría revelar un conjunto de parámetros, pero sólo uno consistente tanto con el modelo como con las observaciones (véase, por ejemplo, Koopmans, 1949). Una segunda cuestión tenía que ver con la invarianza de una relación (estructural).9 Si un mecanismo subyacente es constante en el pasado y en el futuro, la vía de la(s) variable(s) relevante(s) será predecible a partir del pasado, descontando posibles perturbaciones al azar (véase, por ejemplo, Marschak, 1947, 1953).
Si se tienen presentes estos tres objetivos, el marco de referencia de las IEMT usa lo que sabemos acerca de los conceptos teóricos y estadísticos aplicados, ofrece una base rigurosa de esos conceptos mediante el empleo de sus respectivos análogos y después fusiona esos análogos teóricos con los análogos de la estadística aplicada.10 Puede pensarse que un concepto es una idea abstracta o general, inferida o derivada de casos específicos, puede pensarse que un análogo es un recurso con el cual se representa un concepto por medio de cantidades continuamente variables y mensurables. Lo que se desarrollaría sería un mapa de carreteras que otros pueden modificar, corregir o seguir. Algo más importante es que se estaría proporcionando un vínculo transparente entre una teoría y una prueba. Esto, sin embargo, no quiere decir que el modelo sea correcto. Más bien lo que se estaría haciendo sería cumplir con un requisito mínimo: que la teoría y la prueba estén relacionadas y que, por lo tanto, sean falsables.
Pasos del marco de referencia de las IEMT
La modelación tanto formal como estadística aplicada tiene atributos importantes que contribuyen a la falsación y, en última instancia, a la acumulación científica. Los modelos formales, por ejemplo, exigen claridad en torno a los supuestos y conceptos, garantizan consistencia lógica y describen los mecanismos subyacentes que llevan a los resultados (véase Powell, 1999, pp. 23–39). Por otra parte, los modelos estadísticos aplicados proporcionan generalizaciones y descartan explicaciones alternas por medio del análisis multivariado. La estadística aplicada contribuye a distinguir entre causas y efectos, toma en consideración la causación recíproca y también el tamaño relativo de los efectos.
Más adelante discutimos la manera en que ambos métodos de análisis pueden también desalentar la acumulación científica. Si bien ésta se basa en muchas cosas que involucran inferencia y predicción, nosotros nos concentramos en una prueba indicadora ampliamente utilizada —el t–estadístico—, que se define como la razón  . Como aceptamos la importancia que la Comisión Cowles otorga a los parámetros estructurales para demostrar causa y efecto específicos, hacemos especial hincapié en el numerador (b) en lugar de en las prácticas que ponen énfasis en el denominador (s.e.(b)). Sostenemos que la falsabilidad influye en la acumulación científica y que la identificación de (b) es consistente con el logro de dicha falsabilidad.
. Como aceptamos la importancia que la Comisión Cowles otorga a los parámetros estructurales para demostrar causa y efecto específicos, hacemos especial hincapié en el numerador (b) en lugar de en las prácticas que ponen énfasis en el denominador (s.e.(b)). Sostenemos que la falsabilidad influye en la acumulación científica y que la identificación de (b) es consistente con el logro de dicha falsabilidad.
Se espera que estos pasos sean sugerentes. Nos apresuramos a añadir que la práctica de vincular modelos formales y estadísticos aplicados no tiene que incluir necesariamente componentes explícitos de comportamiento. Lo que estamos afirmando es consistente con los esfuerzos por preservar los parámetros estructurales. Nuestro marco de referencia apunta a una alternativa en la cual los modelos formales y estadísticos aplicados revelan propiedades que se influyen mutuamente. Estas IEMT se sintetizan como sigue:
Unificar los hechos probables y los conceptos de la estadística aplicada
Dado que los seres humanos son los agentes de la acción, los mecanismos deben reflejar los procesos sociales y de comportamiento globales. Ejemplos de ello son (aunque no se limitan a éstos): toma de decisiones, negociaciones, expectativas, aprendizaje e interacción social. También resulta importante encontrar un concepto estadístico apropiado que se corresponda con el concepto teórico. Ejemplos de conceptos de la estadística son (aunque no se limitan a ellos): persistencia, error de medición, elección nominal y simultaneidad.
Desarrollar análogos de comportamiento (formales) y estadísticos aplicados
Necesitamos análogos a fin de vincular los conceptos con las pruebas. Un análogo es un recurso en el cual un concepto se representa por medio de cantidades continuamente variables y mensurables. Ejemplos de análogos para los conceptos de comportamiento (formales) como toma de decisiones, expectativas y aprendizaje incluyen (aunque no se limitan a los mismos): teoría de la decisión (es decir, máxima utilización), procedimientos de expectativas condicionales y procedimientos de aprendizaje adaptativos y bayesianos. Ejemplos de análogos estadísticos aplicados para los conceptos estadísticos aplicados de persistencia, error de medición, elección nominal y simultaneidad incluyen (respectivamente): estimación autorregresiva, regresión de error en las variables, modelación de la elección discreta y estimación de multietapas (es decir de mínimos cuadrados en dos etapas).
Unificar y evaluar los análogos
El tercer paso unifica las propiedades mutuamente reforzadas de los análogos formales y empíricos. Hay varios métodos para establecer la vinculación. Por ejemplo, cuando los investigadores asumen que los ciudadanos (votantes) o agentes económicos son actores racionales que toman decisiones para maximizar sus propios beneficios, un análogo común es la maximización de la utilidad (o la ganancia). Cuando se cuenta ya con este análogo teórico, la otra consideración es determinar el concepto y el análogo estadístico apropiado para poner a prueba la relación teórica. Considérese un modelo de votación básico downsiano, en el que los votantes deciden votar por uno de los partidos para maximizar sus utilidades (por ejemplo la teoría de las decisiones). Este concepto/análogo teórico puede unificarse con el concepto estadístico aplicado, elección nominal, y su análogo, modelado de la elección discreta.
IEMT en la práctica
Demostraremos ahora el marco de referencia de las IEMT usando investigaciones publicadas. El primer ejemplo, que tiene que ver con la perseverancia de la identificación partidista, involucra vincular el concepto de expectativas, que es del ámbito del comportamiento, con el concepto estadístico aplicado de la persistencia. El segundo ejemplo observa cómo los conceptos de comportamiento de expectativas e incertidumbre, cuando se relacionan con el concepto estadístico aplicado de error de medición, crean distintas hipótesis en la bibliografía de la votación económica.
Ejemplo 1: Macropartidismo
Un debate importante en ciencias políticas se centra en la persistencia de la identificación partidista o lo que se ha denominado macropartidismo (Erikson, MacKuen y Stimson, 2002, pp. 109–151). Usamos el ejemplo de una formulación IEMT de Clarke y Granato (2004), quienes asumen que los anuncios de las campañas políticas influyen sobre el público. Sostienen también que el incesante trabajo de asesores de partidos políticos rivales para detectar e influir (mediante el uso de publicidad política) sobre los votantes reduce la bien conocida persistencia en el macropartidismo. Como consecuencia, las influencias sobre el macropartidismo pueden amplificarse o extinguirse rápidamente, de acuerdo con las acciones del asesor del rival político.
Paso 1: Relacionar los conceptos de comportamiento y de estadística aplicada: expectativas y persistencia
Clarke y Granato (2004) relacionan las expectativas del agente con la persistencia de su comportamiento. Demuestran de qué manera un estratega político rival puede usar los anuncios de campaña para influir sobre la persistencia agregada en la identificación con el partido. Su modelo comprende tres ecuaciones. Cada ciudadano (i) está sujeto a un evento (j) en el tiempo (t). La agregación entonces se hace sobre los individuos y eventos a fin de que la notación sólo tenga el subíndice t.


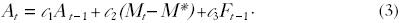
La primera ecuación (1) especifica qué influye sobre la identificación agregada con el partido (Mt). La variable Mt–1 toma en cuenta la posibilidad de la persistencia. Los ciudadanos tienen también una expectativa respecto a qué parte de la población se identificará con el partido (Et–1Mt). Asumen que, al formar sus expectativas, los ciudadanos utilizan toda la información disponible y pertinente (hasta el momento t–1) tal como se especifica en el modelo (expectativas racionales). Clarke y Granato asumen además que la identificación partidista depende de lo favorablemente que vea el ciudadano el partido nacional (Ft). Por último, la identificación con un partido puede estar sujeta a impactos estocásticos no previstos (realineaciones) (μ1t), donde μ1t ~ N (0, σ2μ1t). Se asume que las relaciones son positivas: a1, a2, a3 > 0.
La ecuación (2) representa la impresión que tienen los ciudadanos ("favorabilidad") de un partido político (Ft). En este modelo la favorabilidad es una función lineal del rezago de la favorabilidad (Ft_1) y una variable del recurso de los anuncios (At). Hay muchas maneras de medir los recursos promocionales políticos. μ2t es un impacto estocástico que representa eventos no previstos (incertidumbre), donde μ2t ~ N (0, σ2μ2t). El parámetro b1 > 0, mientras b2 0, depende del tono y el contenido del anuncio.
0, depende del tono y el contenido del anuncio.
La ecuación (3) presenta el plan de contingencia o la regla que usan los asesores políticos (rivales). Clarke y Granato sostienen que los asesores políticos investigan su gasto de recursos en promoción durante el periodo previo (At–1) y reaccionan a la tasa de favorabilidad de ese periodo para el partido nacional (rival) (Ft_1). Los asesores políticos basan también su gasto actual en recursos publicitarios sobre el grado en el que el macropartidismo (Mt) se aproxima a un objetivo especificado con antelación y deseado (M*). Idealmente los asesores políticos quieren que (Mt – M*) = 0. Los parámetros c1 y c3 son positivos. El parámetro c2 es contracíclico (–1 < c2 < 0): refleja la disposición de un asesor político a aumentar o mantener sus recursos para promoción, según si el macropartidismo está por encima (reducción de la promoción) o por debajo (aumento de la promoción) del objetivo.
Paso 2: Análogos formales y estadísticos aplicados: expectativas condicionales y estimación autorregresiva11
La forma reducida para macropartidismo se determina sustituyendo (3) en (2). Adviértase que hay un componente autorregresivo (Θ1Mt–1) en la forma reducida para macropartidismo.

donde 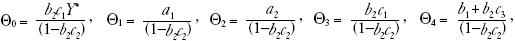 y
y 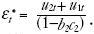 Ahora el sistema está simplificado en un modelo de macropartidismo que depende del macropartidismo rezagado y también de la expectativa convencional en el tiempo t – 1 del macropartidismo actual. Esta variable dependiente rezagada es el análogo para la persistencia. Adviértase que también pueden tener efecto los valores previos de promoción y favorabilidad.
Ahora el sistema está simplificado en un modelo de macropartidismo que depende del macropartidismo rezagado y también de la expectativa convencional en el tiempo t – 1 del macropartidismo actual. Esta variable dependiente rezagada es el análogo para la persistencia. Adviértase que también pueden tener efecto los valores previos de promoción y favorabilidad.
Como (4) posee un operador de expectativas condicionales, debemos hacer de él una función de otras variables (no de operadores). En este ejemplo, "cerrar el modelo" y averiguar el equilibrio de expectativas racionales (EER) implica tomar la expectativa condicional en el tiempo t – 1 de la ecuación (4) y sustituir después nuevamente este resultado en la ecuación (4):

La ecuación (5) es la solución de la variable de estado mínimo (VEM) (McCallum, 1983) del macropartidismo.12 El macropartidismo (Mt) depende también de su historia pasada, el componente autorregresivo (Mt–1).
Paso 3: Vincular los análogos formales y estadísticos aplicados
Se demuestra ahora que la persistencia del macropartidismo (Π2) depende de la persistencia y disposición de los asesores políticos rivales para mantener un objetivo macropartidista rival (c2). En otras palabras, el vínculo de las IEMT es la VEM con el componente AR(1) de la expresión (5). Esto puede demostrarse si se examina la forma reducida del coeficiente AR(1) en la expresión Π2:

Tomamos la derivada de (6) respecto a (c2) y encontramos la relación siguiente:
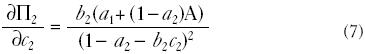
donde A = (b1 + c1 + b2c3). Dados los supuestos respecto a los signos de los coeficientes en el modelo, el numerador es positivo siempre que a2< 1. Por lo tanto, en estas condiciones, sabemos que la relación es positiva 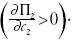
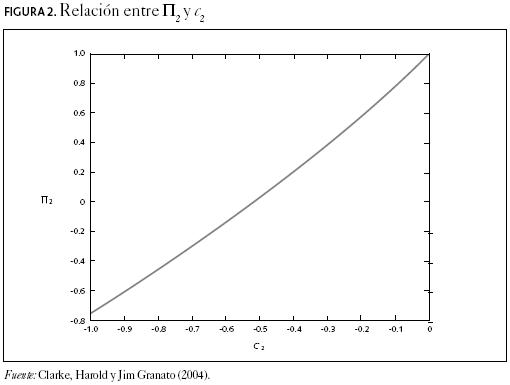
La relación entre Π2 y c2 se demuestra en la figura 2. Utilizamos los siguientes valores: a1 = a2 = b1 = b2 = c1 = c3 = 0.5. El parámetro c2 varía de 0.0 a –1.0. A medida que cambiamos el valor de c2 dentro de ese rango, observamos que la persistencia (autocorrelación) del macropartidismo (Π2) —en igualdad de circunstancias— es cero cuando c2 = –0.8. Por otro lado, el macropartidismo se vuelve altamente autorregresivo (Π2  1.0) cuando los asesores políticos rivales no reaccionan (c2 0.0) a las desviaciones de su objetivo preespecificado. La conclusión de este modelo es que la promoción negativa por parte de partidos políticos rivales puede influir en la persistencia de la identificación partidista nacional de sus oponentes.
1.0) cuando los asesores políticos rivales no reaccionan (c2 0.0) a las desviaciones de su objetivo preespecificado. La conclusión de este modelo es que la promoción negativa por parte de partidos políticos rivales puede influir en la persistencia de la identificación partidista nacional de sus oponentes.
Ejemplo 2: Votación económica
Con frecuencia ocurre que, con el tiempo, muchos parámetros se alejan y muestran también periodos de volatilidad. Los parámetros constantes no son necesariamente una característica. Cuando se vinculan las expectativas y los análogos de incertidumbre con un análogo de error de medición (regresión de error en las variables) es posible demostrar que los parámetros de la regresión reflejan la varianza (es decir la incertidumbre) creciente de las variables de interés.
Paso 1: Relación de conceptos de comportamiento y de estadísticas aplicadas: expectativas, incertidumbre y error de medición
Si empezamos con Kramer (1983) y continuamos con trabajos que incluyen (sin limitarse) a Alesina y Rosenthal (1995), Suzuki y Chappell (1996), y Lin (1999), hay una considerable bibliografía cuantitativa acerca de cómo la economía afecta la votación. Para nuestros fines demostramos de qué manera el trabajo combinado de Alesina y Rosenthal, y Suzuki y Chappell, han aportado, a su modo, partes constitutivas del estudio de la votación económica.
La incertidumbre a la que se enfrentan los votantes podría ponerse a prueba, idealmente, al utilizar el marco de referencia de las IEMT. La relación de las IEMT puede encontrarse de la siguiente manera: cuando las expectativas y los análogos de incertidumbre se vinculan con un análogo de error de medición (regresión de error en las variables) es posible demostrar que los parámetros de la regresión reflejan la creciente varianza (es decir, la incertidumbre) de las variables de interés. En otras palabras, a medida que cambian las expectativas y los análogos de incertidumbre, cambia asimismo el efecto económico posible de ser sometido a prueba en la votación.
Paso 2: Análogos formales y estadísticos aplicados13
Empezamos con un modelo formal que comprende los conceptos de comportamiento de expectativas e incertidumbre. Alesina y Rosenthal (1995, pp. 191–195) proporcionan ese modelo formal. Su modelo de crecimiento económico se basa en una curva de expectativas aumentadas de oferta agregada:

donde  representa la tasa de crecimiento económico (crecimiento del PIB) en el periodo t,
representa la tasa de crecimiento económico (crecimiento del PIB) en el periodo t,  es la tasa natural de crecimiento económico, πt es la tasa de inflación en el momento t,
es la tasa natural de crecimiento económico, πt es la tasa de inflación en el momento t,  es la tasa de inflación esperada en el momento t formada en el momento t – 1.
es la tasa de inflación esperada en el momento t formada en el momento t – 1.
Una vez establecidas las expectativas de inflación, pasamos al concepto de incertidumbre. Asumamos que los votantes desean determinar si atribuirle el crédito o la culpa de los resultados del crecimiento económico (yt) al gobierno vigente. No obstante, los votantes se enfrentan a la incertidumbre de determinar qué parte de los resultados económicos se debe a la "competencia" (es decir, inteligencia económica) del gobierno en el poder o a la simple buena suerte.
La ecuación (9), que es el impacto en la ecuación (8), puede modificarse para presentar el siguiente análogo de la incertidumbre:

La variable εt representa el impacto que comprende las dos características no observables que se señalaron antes: competencia o buena suerte.14 La primera, representada por ηt, releja la "competencia" que puede atribuirse a la administración en el poder. La segunda, que simbolizamos ξ, se refieren a la influencia sobre el crecimiento que está más allá del control (y la competencia) del gobierno. Tanto ηt como ξt tienen una media de cero con una varianza de  y
y  respectivamente.
respectivamente.
Adviértase también que la competencia puede persistir y apoyar la reelección. Este rasgo puede caracterizarse como un proceso MA(1):

donde μt es iid(0,  ). El parámetro ρ representa la fuerza de la persistencia. La brecha o brechas toman en consideración los juicios retrospectivos del votante.
). El parámetro ρ representa la fuerza de la persistencia. La brecha o brechas toman en consideración los juicios retrospectivos del votante.
Si nos referimos nuevamente a la ecuación (8), asumamos que los juicios de los votantes incluyen un sentido general de la tasa promedio de crecimiento () y de la capacidad de observar el crecimiento real (). Así, los votantes evalúan la diferencia entre ambas ( – ). La ecuación (8) también implica que cuando los votantes predicen la inflación sin error sistemático (es decir = πt), el resultado es un crecimiento no inflacionario que no afecta en forma adversa los salarios reales.
A continuación vinculamos el desempeño del crecimiento económico con la incertidumbre de los votantes. Formalizamos de qué manera es posible atribuir las desviaciones de la tasa de crecimiento económico a la competencia del gobierno o a acontecimientos fortuitos:

La ecuación (11) muestra que cuando la tasa de crecimiento económico real es mayor que su tasa promedio o "natural" (es decir que > ), entonces εt = ηt + ξt > 0. Una vez más los votantes se enfrentan a la incertidumbre para distinguir entre la competencia del presidente en turno (ηt) y el impacto económico estocástico (ξt). Sin embargo, como la competencia puede persistir, los votantes utilizan esta propiedad para hacer predicciones y darle mayor o menor ponderación a la competencia a lo largo del tiempo.
Para demostrar este efecto del comportamiento, hay que sustituir la ecuación (10) en la (11):

Ahora determinamos la estimación óptima de la competencia, ηt+1, donde los votantes sólo ven . Demostramos este resultado haciendo una predicción para un periodo en la ecuación (10) y la resolvemos después para obtener su valor esperado (expectativa condicional) en el momento t.
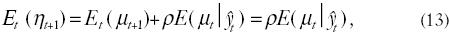
donde Εt(μt+1) = 0. Al utilizar este análogo para las expectativas en la ecuación 13, advertimos que la competencia ηt+1, puede preverse al predecir μt+1 y μt. Como no hay información disponible para predecir μt+1, los votantes sólo pueden prever μt basándose en un observable (en el momento t) de la ecuación (12).
Paso 3: Vincular los análogos formales y estadísticos aplicados
Al emplear el método de la proyección recursiva y la ecuación (12) ilustramos cómo se vincula el análogo de comportamiento de las expectativas con el análogo empírico de error de medición (una "ecuación" de error en las variables):15

donde  . La ecuación (14) muestra que los votantes pueden predecir la competencia usando la diferencia entre – , pero también la brecha "pesada" de μι (es decir ρμt–1).
. La ecuación (14) muestra que los votantes pueden predecir la competencia usando la diferencia entre – , pero también la brecha "pesada" de μι (es decir ρμt–1).
En la ecuación (14) el valor esperado de la competencia se correlaciona positivamente con las desviaciones de la tasa de crecirniento económico. La valoración del votante se filtra con el coeficiente  , que representa una proporción de competencia que los votantes son capaces de interpretar y observar. Las implicaciones relacionadas con el comportamiento son claras. Si los votantes interpretan que la variabilidad de los impactos económicos proviene exclusivamente de la competencia del gobernante en turno por ejemplo, 0), entonces 1. Por otro lado, el aumento de la variabilidad de los impactos no controlados, , confunde la observabilidad de la competencia del gobierno vigente, ya que se reduce el coeficiente de la señal
, que representa una proporción de competencia que los votantes son capaces de interpretar y observar. Las implicaciones relacionadas con el comportamiento son claras. Si los votantes interpretan que la variabilidad de los impactos económicos proviene exclusivamente de la competencia del gobernante en turno por ejemplo, 0), entonces 1. Por otro lado, el aumento de la variabilidad de los impactos no controlados, , confunde la observabilidad de la competencia del gobierno vigente, ya que se reduce el coeficiente de la señal
En síntesis, Alesina y Rosenthal ofrecen una conexión de las IEMT entre las ecuaciones (8), (10) y sus pruebas empíricas. Vinculan los conceptos relativos al comportamiento —expectativas e incertidumbre— con sus respectivos análogos (expectativas condicionales y error de medición) y desarrollan un problema de extracción de la señal. Si bien el modelo empírico se asemeja a una especificación de error en las variables, que puede someterse a prueba con métodos dinámicos, como regresión rolling (Lin, 1999), más bien estiman la estructura de covarianza de los residuales.
Discusión y conclusión
En este artículo hemos descrito las debilidades de las actuales prácticas de investigación y la manera en que su naturaleza no falsable no contribuye a un diálogo de modelado. La incapacidad de relacionar teorías con pruebas y de proporcionar una retroalimentación importante significa que la acumulación científica resulta lesionada. En respuesta a este statu quo —ya que corresponde a la metodología cuantitativa— elaboramos el marco de referencia de las IEMT. Como parte de la iniciativa de las IEMT de la National Science Foundation, este marco de referencia pone énfasis en desarrollar análogos de comportamiento y de estadística aplicada y vincularlos.
El marco de referencia de las IEMT requerirá ciertos cambios de la formación que se imparte en posgrado. La preparación en compartimientos estanco en la enseñanza tanto formal como de estadística aplicada tendrá que ceder el paso a un enfoque pedagógico, no sólo para aprender parte de lo básico de cada una de ellas sino con el fin de pensar maneras de vincularlas.
En las ciencias políticas y sociales hay numerosas áreas de investigación en las que se ha aplicado el marco de referencia de las IEMT. Una muestra de ello y las herramientas formales y empíricas que se requerirían incluye:
La economía política de la macropolítica: La vinculación entre el concepto de las expectativas, que se relaciona con el comportamiento, y el concepto empírico de persistencia. El modelo de contrato de salario real de Granato y Wong (2006) demuestra una relación entre la política monetaria, las expectativas de inflación del público y la persistencia de la inflación. Las herramientas requeridas para establecer esta relación incluyen ecuaciones diferenciales (de varios órdenes), los procedimientos de solución de las mismas, y condiciones de estabilidad. Junto con estas herramientas idóneas de modelado formal se presenta una discusión de la estimación empírica y de las propiedades de los procesos autorregresivos.
Los partidos políticos y la representación política: Un área que ha sido bien investigada se centra en cuándo y por qué los votantes escogen un partido en lugar de los demás, con base en la posición política relativa de los partidos. Los trabajos de Kedar (2005), Merrill y Grofman (1999), Groseclose (2001), Ansolabehere, Snyder y Stewart (2001) y Adams, Merrill y Grofman (2005) no son más que algunos ejemplos. Las herramientas que se necesitan para adecuarlo al marco de referencia de las IEMT involucran la vinculación de modelos teóricos de decisión con resultados discretos.
Asistencia a las urnas: La vinculación de las IEMT es el concepto teórico de aprendizaje combinado con el concepto empírico de elección discreta (Hetherington, 2001; Plutzer, 2002; Gerber, Green y Shachar, 2003). Otros ejemplos incluyen a Achen (2006), Dhillon y Peralta (2002) y Shachar y Nalebuff (1999). En estos últimos artículos los autores desarrollan un modelo de aprendizaje bayesiano y lo asocian con un modelo empírico de elección discreta. Las herramientas requeridas incluyen la teoría bayesiana del aprendizaje y una introducción a los modelos estadísticos de elección discreta (logit y probit).
Conflicto y cooperación internacionales: La vinculación de las IEMT incluye los conceptos relativos al comportamiento de negociación y de interacción estratégica, combinados con el concepto empírico de elección discreta; véase el trabajo de Signorino (1999) sobre respuesta de equilibrio cuántico (REQ) —técnica que se utiliza para fusionar la teoría de juegos y los modelos de elección discreta—. Las herramientas necesarias son elementos de la teoría de juegos, modelado de elección discreta y cómo éstas sustentan la REQ.
Desde luego, nuestro marco de referencia no tiene la última palabra sobre la vinculación de modelos formales y estadísticos aplicados. En última instancia, las IEMT significan una clara ruptura con las prácticas actuales, como la minería de datos, los botes de basura y las matrices omega. La antigua disposición a considerar que los problemas de estadística aplicada requieren simplemente parches estadísticos tendrá que ceder el paso al ver que esos estorbos tienen una base teórica. Con ese nuevo punto de vista, un investigador puede aprovechar las propiedades que se refuerzan mutuamente del análisis tanto formal como estadístico aplicado y poner a prueba con datos reales la vinculación de parámetros identificados–vinculación específica.
Referencias bibliográficas
Achen, Christopher H. (2005), "'Let's Put Garbage–Can Regressions and Garbage–Can Probits where They Belong", Conflict Management and Peace Science, núm 22, pp. 327–339. [ Links ]
––––––––––(2006), "Expressive Bayesian Voters, their Turnout Decisions, and Double Probit: Empirical Implications of a Theoretical Model", mecanoscrito, Princeton University. [ Links ]
Adams, James, Samuel Merrill III y Bernard Grofman (1999), A Unified Theory of Voting: Directional and Proximity Spatial Models, Cambridge, Cambridge University Press. [ Links ]
––––––––––(2005), A Unified Theory of Party Competition: A Cross–National Analysis Integrating Spatial and Behavioral Factors. Cambridge: Cambridge University Press. [ Links ]
Alesina, Alberto y Howard Rosenthal (1995), Partisan Politics, Divided Government, and the Economy, Nueva York, Cambridge University Press. [ Links ]
Ansolabehere, Stephen D., James M. Snyder Jr., y Charles Stewart III (2001), "Candidate Positioning in US House Elections", American Journal of Political Science, vol. 45, pp. 136–159. [ Links ]
Clarke, Harold y Jim Granato (2004), "Autocorrelation: From Practice to Theory", en Kimberly Kampf–Leonard (ed.), Encyclopedia of Social Measurement, San Diego, Academic Press. [ Links ]
Cooper, Gershon (1948), "The Role of Econometric Models in Economic Research", Journal of Farm Economics, vol. XXX, núm. 1, pp. 101–116. [ Links ]
Denton, Frank T. (1985), "Data Mining as an Industry", The Review of Economics and Statistics, vol. 67, núm. 1, pp. 124–127. [ Links ]
Dhillon, Amrita y Susana Peralta (2002), "Economic Theories of Voter Turnout", The Economic Journal, vol. 112, núm. 480, pp. 332–352. [ Links ]
Engle, Robert F., David F. Hendry y Jean Frangois Richard (1983), "Exogeneity", Econometrica, vol. 51, núm. 2, pp. 277–304. [ Links ]
Erikson, Robert S., Michael B. MacKuen y James A. Stimson (2002), The Macro Polity, Nueva York, Cambridge University Press. [ Links ]
Evans, George y Seppo Honkapohja (2001), Learning and Expectations in Macroeconomics, Princeton, Princeton University Press. [ Links ]
Ezekiel, Mordecai (1938), "The Cobweb Theorem", Quarterly Journal of Economics, vol. 52, núm. 2, pp. 255–280. [ Links ]
Gerber, Alan, Donald Green y Ron Shachar (2003), "Voting may be Habit Forming", American Journal of Political Science, vol. 47, núm. 3, pp. 540–550. [ Links ]
Granato, Jim y Frank Scioli (2004), "Puzzles, Proverbs, and Omega Matrices: The Scientific and Social Significance of Empirical Implications of Theoretical Models (EITM)", Perspectives on Politics, vol. 2, núm. 2, pp. 313–323. [ Links ]
Granato, Jim y M.C. Sunny Wong (2006), The Role of Policymakers in Business Cycle Fluctuations, Cambridge, Cambridge University Press. [ Links ]
Groseclose, Tim (2001), "A Model of Candidate Location when One Candidate has a Valence Advantage", American Journal of Political Science, vol. 45, núm. 4, pp. 862–886. [ Links ]
Haavelmo, Trygve (1943), "The Statistical Implications of a System of Simultaneous Equations", Econometrica, vol. 11, pp. 1–12. [ Links ]
––––––––––(1944), "The Probability Approach in Econometrics", suplemento de Econometrica, vol. 12, pp. S1–115. [ Links ]
Heckman, James (2000), "Causal Parameters and Policy Analysis in Economics: A Twentieth Century Retrospective", Quarterly Journal of Economics, vol. 115, núm. 1, pp. 45–97. [ Links ]
Hetherington, Marc (2001), "Resurgent Mass Partisanship: The Role of Elite Polarization", American Political Science Review, vol. 95, núm. 3, pp. 619–631. [ Links ]
Hood, William C. y Tjalling C. Koopmans (eds.) (1953), Studies in Econometric Method, Cowles Commission, monografía núm. 14, Nueva York, John Wiley & Sons. [ Links ]
Johnston, Jack y John DiNardo (1997), Econometric Methods, Nueva York, McGraw–Hill. [ Links ]
Kedar, Orit (2005), "When Moderate Voters Prefer Extreme Parties: Policy Balancing in Parliamentary Elections", American Political Science Review, vol. 99, núm. 2, pp. 185–199. [ Links ]
Klein, Lawrence (1947), "The Use of Econometric Models as a Guide to Economic Policy", Econometrica, vol. 15, núm. 2, pp. 111–151. [ Links ]
Koopmans, Tjalling (1945), "Statistical Estimation of Simultaneous Economic Relations", Journal of the American Statistical Association, vol. 40, pp. 448–466. [ Links ]
––––––––––(1949), "Identification Problems in Economic Model Construction", Econometrica, vol. 17, núm. 2, pp. 125–144. [ Links ]
––––––––––(ed.) (1950), Statistical Inference in Dynamic Economic Models, monografía núm. 10, Cowles Commission, Nueva York, John Wiley & Sons. [ Links ]
Koopmans, Tjalling y Olav Reiersol (1950), "The Identification of Structural Characteristics", The Annals of Mathematical Statistics, vol. XXI, núm. 2, pp. 165–181. [ Links ]
Kramer, Gerald (1983), "The Ecological Fallacy Revisited: Aggregate Versus Individual–Level Findings on Economics, and Elections, and Sociotropic Voting", American Political Science Review, vol. 77, núm. 1, pp. 92–111. [ Links ]
Leamer, Edward (1983), "Let's Take the 'Con' Out of Econometrics", American Economic Review, vol. 73, núm. 1, pp. 31–43. [ Links ]
Lin, Tse–min (1999), "The Historical Significance of Economic Voting, 1872–1996", Social Science History, vol. 23, núm. 4, pp. 561–591. [ Links ]
Lovell, Michael (1983), "Data Mining", The Review of Economics and Statistics, vol. 65, pp. 1–12. [ Links ]
Marschak, Jacob (1947), "Economic Structure, Path, Policy, and Prediction", American Economic Review, vol. 37, núm. 2, pp. 81–84. [ Links ]
––––––––––(1953), "Economic Measurements for Policy and Prediction", en William Hood y Tjalling Koopmans (eds.), Studies: Econometric Method, Nueva York, John Wiley Sons. [ Links ]
McCallum, Bennett (1983), "On Non–uniqueness in Linear Rational Expectations Models: An Attempt at Perspective", Journal of Monetary Economics, vol. 11, núm. 2, pp. 134–168. [ Links ]
Mizon, Grayham (1995), "A Simple Message to Autocorrelation Correctors: Don't", Journal of Econometrics, vol. 69, núm. 1, pp. 267–288. [ Links ]
Morgan, Mary (1990), The History of Econometric Ideas, Cambridge, Cambridge University Press. [ Links ]
Morton, Rebecca (1999), Methods and Models: A Guide to the Empirical Analysis of Formal Models in Political Science, Nueva York, Cambridge University Press. [ Links ]
Muth, John F. (1961), "Rational Expectations and the Theory of Price Movements", Econometrica, vol. 29, núm. 3, pp. 315–335. [ Links ]
Plutzer, Eric (2002), "Becoming a Habitual Voter", American Political Science Review, vol. 96, pp. 41–56. [ Links ]
Powell, Robert (1999), In the Shadow of Power, Princeton, Princeton University Press. [ Links ]
Sala–i–Martin, Xavier (1997), "I Just Ran Two Million Regressions", American Economic Review, vol. 87, núm. 2, pp. 178–183. [ Links ]
Sargent, Thomas (1987), DynamicMacroeconomic Theory, Orlando, Academic Press. [ Links ]
Shachar, Ron y Barry Nalebuff (1999), "Follow the Leader: Theory and Evidence on Political Participation", American Economic Review, vol. 89, núm. 3, pp. 525–547. [ Links ]
Signorino, Curtis (1999), "Strategic Interaction and the Statistical Analysis of International Conflict", American Political Science Review, vol. 93, núm. 2, pp. 279–297. [ Links ]
Suzuki, Motoshi y Henry W. Chappell Jr. (1996), "The Rationality of Economic Voting Revisited", Journal of Politics, vol. 58, núm. 1, pp. 224-236. [ Links ]
Vining, Rutledge (1949), "Methodological Issues in Quantitative Economics: Koopmans on the Choice of Variables to be Studied and of Methods of Measurement", Review of Economics and Statistics, vol. 21, núm. 2, pp. 77–86. [ Links ]
Apéndice 1: Notas sobre análogos para el ejemplo 1
Apéndice 2: Notas sobre análogos para el ejemplo 2
Traducción del inglés de Victoria Schussheim.
Este trabajo se presentó en el programa de verano de IEMT 2004 (Duke University), en la reunión anual de la Southern Political Science Association (6–8 de enero de 2005, Nueva Orleans, Luisiana), la reunión anual de la Canadian Political Science Association (2–4 de junio de 2005, Londres, Ontario), en la Ohio State University, la Penn State University, la University of Texas en Austin y el programa de verano de IEMT 2006 (University of Michigan). Nuestro agradecimiento a Jim Alt, Mary Bange, Harold Clarke, Michelle Costanzo, John Freeman, Mark Jones, Skip Lupia, David Primo y Frank Scioli por sus observaciones y ayuda.
1 El análisis formal se refiere a la modelación empírica en un teorema y la presentación de pruebas o la modelación en computadora que requiere la ayuda de la simulación. El análisis estadístico aplicado involucra el análisis de datos usando herramientas estadísticas. En todo este trabajo utilizaremos de manera indistinta los términos análisis y modelación.
2 Adviértase que consideramos que la modelación formal también puede contribuir en ocasiones a la no acumulación. Es posible que los modelos formales no incorporen hallazgos empíricos que contribuirían a brindar una imagen más precisa de las relaciones que se especifican. Esto da por resultado esfuerzos de modelación que arrojan predicciones inexactas o no coinciden con los hallazgos. De hecho, los datos pueden contradecir no sólo los resultados de un modelo sino también sus supuestos fundacionales. El problema no consiste sólo en los supuestos irreales, porque una manera de construir modelos útiles es empezar con supuestos estilizados, poner a prueba las predicciones del modelo y después modificar los supuestos en forma consistente con un modelo de realidad progresivamente más preciso. Sin embargo, con lamentable frecuencia estos pasos sucesivos no se dan o se dejan inconclusos —con el resultado de que se tiene un modelo que en poco contribuye a mejorar la comprensión y el progreso de la disciplina.
3 Un ejemplo de esta práctica es la "corrección" de la correlación serial (véase Mizon, 1995).
4 Utilizaremos el término inferencia para referirnos a un parámetro en una regresión o probabilidad (b). Empleamos la palabra predicción para referirnos al pronóstico de un modelo de una variable dependiente ( ). Para un tratamiento técnico de estos dos conceptos, véase Engle, Hendry y Richard (1983).
). Para un tratamiento técnico de estos dos conceptos, véase Engle, Hendry y Richard (1983).
5 Para un punto de vista distinto del uso del ALE, véase Sala–i–Martin (1997).
6 La Comisión Cowles, creada en la década de 1930, se diseñó para "propiciar el desarrollo de métodos de análisis lógicos, matemáticos, estadísticos, para su aplicación en economía y en ciencias sociales relacionadas" (véase http://cowles.econ.yale.edu/about–cf/about.htm). Las investigaciones vinculadas con la Comisión Cowles incluyen (de manera no restrictiva), a: Cooper (1948); Haavelmo (1943, 1944); Hood y Koopmans (1953); Klein (1947); Koopmans, (1945, 1949, 1950); Koopmans y Reiersol (1950); Marschak (1947, 1953), y Vining (1949).
7 Junto con su trabajo sobre los parámetros estructurales, la Comisión Cowles también les dio especificidad formal y empírica a cuestiones tales como la exogeneidad y la invariancia política (Morgan, 1990; Heckman, 2000, p. 46).
8 La base de este vínculo fue la idea de que las muestras aleatorias estaban gobernadas por alguna ley del movimiento latente y probabilística (Haavelmo, 1944; Morgan, 1990). Además, esta visión implicaba que era posible interpretar que los modelos formales, cuando se relacionaban con un modelo de la estadística aplicada, creaban una muestra tomada de la ley de movimiento subyacente. Sería posible conseguir una prueba bien fundamentada de una teoría relacionando un modelo formal con un modelo de estadística aplicada y poniendo a prueba este último. La metodología Cowles se veía, entonces, como una representación y un examen válidos de procesos existentes subyacentes.
9 Adoptamos la terminología de Heckman (2000) empleada a continuación:
Los efectos causales estructurales se definen como los efectos directos de las variables en las ecuaciones relativas al comportamiento... Cuando estas ecuaciones son lineales, los coeficientes de las variables causales se denominan parámetros estructurales [cursivas nuestras], y caracterizan plenamente los efectos estructurales.
Heckman señala, asimismo, que existe cierto desacuerdo respecto a qué constituye un parámetro. Este desacuerdo se centra en si se usa un modelo lineal, un modelo no lineal o, más recientemente, un modelo completamente parametrizado. En este último caso los parámetros estructurales también pueden denominarse "profundos" para distinguir entre "las derivaciones de una relación de comportamiento usada para definir efectos causales y los parámetros que generan la misma relación" (p. 60).
10 Los conceptos teóricos se centran en los fenómenos sociales, de comportamiento, políticos y económicos. A lo largo de este artículo usaremos como sinónimos los términos formal y teórico.
11 En este ejemplo el análogo formal es el modelado de expectativas condicionales. El análogo estadístico aplicado es un proceso autorregresivo. Véanse en el apéndice los análogos de comportamiento y estadísticos aplicados.
12 
13 Los análogos formales son: modelado de expectativas condicionales, proyecciones recurrentes y la ley de proyecciones (o expectativas) iteradas. El análogo estadístico aplicado es la regresión de error en las variables.
14 La modificación siguiente suele denominarse problema de "extracción de signo" o de error de medición.
15 La visión tradicional de los errores de medición de la estadística aplicada consiste en que los signos correlacionados de los errores de medición entre variables independientes pueden llevar a signos inapropiados de coeficientes de regresión. Esto es exactamente lo que logran las IEMT y la unificación metodológica. La teoría —el modelo formal— implica un modelo estadístico aplicado con error de medición. En consecuencia, con un enfoque unificado es posible examinar los efectos juntos e identificar la causa. Las herramientas de la estadística aplicada no pueden desentrañar efectos conceptualmente distintos de una variable dependiente.
16 Un modelo de expectativas adaptativas puede definirse como un modelo que convierte a las expectativas que un agente tiene de una variable igual en un promedio geométrico ponderado de los valores pasados de dicha variable. Las expectativas racionales pueden definirse como una expectativa matemática de una variable condicional en relación con todas las variables disponibles que pueden observarse en un momento del tempo. Véanse los detalles en el apéndice 2.
17 El modelo original de la telaraña es una forma reducida de oferta y demanda en un mercado aislado (Ezekiel, 1938; pero también Muth, 1961). Representa un único mercado competitivo en el que existe una brecha temporal en la producción. El modelo describe un proceso de ajuste que, en una gráfica de precio/cantidad o de oferta/demanda, sigue una espiral hacia el equilibro.
18 Un proceso estacionario es un proceso estocástico en el cual la distribución de las variables aleatorias es la misma para cualquier valor del parámetro de las variables. En este ejemplo, el parámetro de las variables es el tiempo. El motivo de esta reducción en la persistencia es el "peso" Φj que se le agrega a cada rezago:

donde Φ0L0=1. Podemos asimismo, representar esta serie de una manera más sintética. Simplemente multiplicando (27) por (1–ΦL). El resultado es:

Dado que el tamaño de la muestra crece progresivamente y n∞, sabemos que  para |Φ|<1. Por lo tanto, tenemos el siguiente resultado:
para |Φ|<1. Por lo tanto, tenemos el siguiente resultado:

y entonces:
19 Con base en el principio de ortogonalidad, ai puede estar determinada de manera única. Véase Sargent (1987, pp. 223–226).

