











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
E l desarrollo e investigación de nuevos fármacos es un proceso complejo. Históricamente, los productos naturales han sido la fuente clásica para su búsqueda. Cada año se invierten fuertes cantidades de dinero con la meta de evaluar e identificar fármacos potenciales. Actualmente, gracias al desarrollo tecnológico es posible realizar en menor tiempo simulaciones de procesos biológicos, cálculo de propiedades y comparar estructuras químicas de manera sistemática. En un principio estas herramientas formaron parte de la denominada Química Computacional. Con el paso del tiempo éstas fueron aplicadas de manera exitosa al descubrimiento y desarrollo de fármacos. Una disciplina relacionada a la Química Computacional es la Quimioinformática que hace uso de ecuaciones, modelos y técnicas computacionales, para resolver problemas en química. La Química Computacional y la Quimioinformática forman parte de un campo del conocimiento más general y aplicado a la Química Farmacéutica: el Diseño de Fármacos Asistido por Computadora (DIFAC).
Desafortunadamente no existe suficiente difusión sobre los avances logrados en DIFAC, principalmente por la poca cantidad de revistas especializadas en el tema. Aunado a lo anterior, la literatura en español referida a la “quimioinformática” es limitada. Por tanto, el objetivo de este trabajo es la mención descriptiva de los procesos más importantes en este campo, con un enfoque particular en los métodos de similitud molecular.
Campos de fuerza, cimientos de la química computacional
A principios del siglo XX, la química avanzó significativamente. Un ejemplo notable es el desarrollo de la mecánica cuántica. Es precisamente por la química cuántica que ocurre el encuentro con la informática, ya que las ecuaciones que describen el carácter electrónico de una molécula sencilla serían bastante laboriosas mediante los métodos tradicionales. Tras la implementación de cálculos cuánticos en programas computacionales, investigadores en distintas universidades decidieron realizar modelos moleculares con ayuda del ordenador. En principio esto podría parecer una tarea tediosa, no obstante, es posible simplificar el modelo: si se considera a una molécula como una serie de esferas unidas por resortes podemos aplicar ecuaciones matemáticas que describen su movimiento y la carga que pueden tener. Después de todo las computadoras ya han demostrado su capacidad de realizar cálculos complejos. A este proceso se le denomina parametrización. Debido a las diferentes consideraciones y combinaciones posibles es que al conjunto descriptivo de ellas se le denomina campo de fuerza (force field). Mediante estas descripciones es posible realizar cálculos de mecánica molecular y comenzar a pensar en simulaciones dinámicas de moléculas en diferentes ambientes. No obstante, los campos de fuerza desarrollados hasta ahora no son universales. Esto quiere decir que de acuerdo al cálculo o simulación que sea de interés, será el campo a elegir, pues algunos son específicos para modelar proteínas, glucósidos o ácidos nucleicos. Si bien el análisis detallado de los campos de fuerza escapa del enfoque de este texto los modelos utilizados sirven de base para realizar simulaciones más complejas, por ejemplo, relajación de una proteína, solvatación de la misma, emular el reconocimiento ligando-proteína. Algunos campos de fuerza usados comúnmente son: AMBER, CHARMM, GROMOS, MARTINI, MMFF94 y OPLS. Si el lector desea ahondar en el tema recomendamos la referencia (Ponder & Case, 2003).
De los métodos in vitro a los métodos in silico
Ya se ha establecido cómo se puede indicar a una computadora que genere modelos moleculares. Ahora , habrá que preguntarse ¿Qué programas usar para ello? Es probable que el lector esté familiarizado con programas para construir y visualizar estructuras químicas como ChemDraw, ChemSketch, Marvin, PyMol. Fuera de estas funciones, estos programas son limitados para hacer DIFAC. Por otra parte, existen bases de datos en internet donde es posible buscar estructuras, actividades biológicas, propiedades fisicoquímicas, etc. (Tabla I).
Tabla I Bases de datos públicas que permiten la búsqueda de estructuras químicas y sus principales propiedades.
| Nombre | URL | Descripción |
|---|---|---|
| Chemspider | http://chemspider.com/ | Repositorio de moléculas pequeñas |
| ChEMBL | https://www.ebi.ac.uk/chembl/ | Repositorio de fármacos y otras moléculas pequeñas |
| Protein Data Bank | http://www.rcsb.org/ | Repositorio de estructuras cristalográficas de proteínas |
| PubChem | https://pubchem.ncbi.nlm.nih.gov/ | Repositorio de moléculas pequeñas |
| Drugbank | http://drugbank.ca/ | Repositorio de fármacos |
| ZINC | http:// zinc.docking.org/ | Repositorio de moléculas para cribado virtual |
La Tabla II resume ejemplos de programas especializados que se pueden usar para hacer cálculos teóricos, química computacional y DIFAC. Dependiendo de los objetivos del proyecto se usa generalmente más de un programa. ¿Es posible comenzar a diseñar y descubrir fármacos potenciales con alguno de estos programas? Probablemente, sí ¿Para ello basta con usar el programa y “un par de clics”? Definitivamente no.
Tabla II Ejemplos de software que permite realizar análisis quimioinformático y/o DIFAC*.
| Nombre | Capacidades | ¿Comercial o académico? | URL |
|---|---|---|---|
| Autodock | Acoplamiento molecular | Académico | www.autodock.scripps.edu/ |
| Chimera | Visualizador, modelado de proteínas y moléculas | Académico | www.cgl.ucsf.edu/chimera/ |
| Datawarrior | Visualizador, cálculo de propiedades y otros descriptores | Académico | www.openmolecules.org/datawarrior/ |
| Gaussian | Cálculo de propiedades cuánticas y cargas semiempíricas | Comercial | www.gaussian.com/ |
| Maestro | Visualizador, modelado de proteínas y dinámica molecular | Comercial/Académico | www.schrodinger.com/maestro |
| Mayachemtools | Cálculo de propiedades y otros descriptores | Académico | www.mayachemtools.org/ |
| Modeller | Modelado de proteínas y modelos por homología | Comercial/Académico | https://salilab.org/modeller/ |
| MOPAC | Cálculo de propiedades cuánticas y cargas semiempíricas | Académico | www.openmopac.net |
| NAMD | Dinámica molecular | Académico | www.ks.uiuc.edu/Research/namd/ |
| Openbabel | Conversión de formatos, cálculo de cargas, torsiones y fragmentos moleculares | Académico | www.openbabel.org |
| Vega ZZ | Cribado virtual | Académico | www.vegazz.net |
| Vina | Acoplamiento molecular | Académico | www.vina.scripps.edu |
| VMD | Cribado virtual | Académico | www.ks.uiuc.edu/Research/vmd/ |
*Se presentan sólo como ejemplos ilustrativos, también se ha dado prioridad a programas de fácil uso y acceso.
El uso correcto de los programas requiere conocimiento, aunque no extenso ni totalmente especializado. Por ello, a continuación se describirán algunos métodos quimionformáticos, ejemplos y aplicaciones.
Cribado virtual: cuando la computadora funge como un filtro antes de pruebas de laboratorio
Al proceso de identificar, diseñar o analizar el potencial farmacológico de una sustancia por métodos computacionales se le conoce como cribado virtual. Un protocolo de cribado virtual incluye cuando menos tres pasos: el curado (o preparación) de las estructuras, el filtrado y pruebas in silico. Una vez terminado este ciclo se pueden añadir pruebas, como un modelo descriptivo con los resultados obtenidos o iniciar el protocolo nuevamente para refinar los resultados.
El curado es el paso más lento pero determinante. Consiste en precisar de manera correcta las estructuras químicas a emplear, asignar la geometría, cargas y quiralidad adecuadas de los compuestos de interés. Los compuestos pueden proceder de bases de datos públicas, mismos que deben depurarse, ya que suelen tener errores. La alternativa es usar compuestos identificados por un grupo de investigación o hacer la propuesta teórica de nuevas estructuras.
El filtrado consiste en la selección de compuestos que mejor cumplan con los criterios de interés. Las pruebas in silico son simulaciones que pueden incluir, por ejemplo, “similitud química” (descrita en párrafos posteriores), acoplamiento molecular y dinámica molecular. Hay que resaltar que los resultados del cribado virtual deben tomarse cum grano salis; es decir, no se puede aseverar que se ha descubierto o diseñado un fármaco hasta comprobarlo con pruebas biológicas. Sin embargo, aunque las técnicas computacionales no podrán sustituir a las pruebas biológicas, sí son herramientas invaluables para optimizar tiempo y recursos.
Una pregunta lógica es ¿el cribado virtual ha sido exitoso? La Tabla III presenta ejemplos representativos de fármacos identificados con la participación del cribado virtual. En las siguientes secciones se abordarán los métodos más comunes usados en quimioinformática.
Tabla III Ejemplos de fármacos desarrollados por métodos DIFAC.
| Nombre | Farmacéutica que lo desarrolló | Uso |
|---|---|---|
| Captropil | Bristol Myers-Squibb | Inhibidor de la ECA (Antihipertensivo) |
| Oseltamivir | Gilead Sciences | Inhibidor de la neuroaminidasa (Antiviral) |
| Dorzolamida | Merck | Inhibidor de la AC-α (Glaucoma) |
| Aliskiren | Novartis | Inhibidor de renina (Antihipertensivo) |
| Boceprivir | Schering-Plough | Hepatitis C (Antiviral) |
Espacio químico: el multiverso de la química
El espacio químico se ha comparado con el universo cósmico y se han hecho analogías entre el número de compuestos químicos que puedan existir con el número de estrellas. Sobre el número de compuestos, estudios recientes hablan de valores que van desde 1040 hasta 10200 (Virshup et al., 2013). Esto lleva a la reflexión de cuánto y qué tanto se conoce este “universo químico”. En la misma analogía con el universo cósmico se ha intentado catalogar y delimitar este espacio, por ejemplo, definir “galaxias químicas” en función de su actividad química, su reactividad, toxicidad, etc.
Para estudiar al espacio químico de N compuestos en forma sistemática (y matemática), se tienen que establecer las características de interés, que servirán como referencia para delimitar al espacio. Las características pueden ser una o más y usualmente se les llama descriptores. De esta manera, se habla en forma genérica de un espacio químico de N compuestos descritos por M características. Estas características pueden ser propiedades fisicoquímicas o propiedades electrónicas, entre otras. Si dos compuestos están cercanos en el espacio químico se infiere que tienen características semejantes y se puede inferir que tendrán un comportamiento químico semejante. Al enunciado anterior se le conoce como “principio de similitud” y aunque intuitivo, es una herramienta útil en la búsqueda de fármacos (Maggiora et al., 2013), ya que la similitud (estructural) en principio puede extenderse a otros rubros como la actividad biológica.
El análisis y visualización del espacio químico se hace cada vez más complicado cuando con cada descriptor la representación física deseada va aumentando en complejidad, por ejemplo, una clasificación con cinco propiedades será entonces un espacio pentadimensional (difícil de imaginar en términos cotidianos). De manera que la representación visual del espacio químico requiere de una simplificación para facilitar la tarea y pasar de las cinco del ejemplo (pentadimensional) a tres dimensiones.
La reducción dimensional puede hacerse por diferentes métodos matemáticos. Uno de ellos se conoce como análisis de componentes principales (Wallisch, 2014). El método consiste en identificar las propiedades de “mayor peso” en la representación o sea, la distribución de las moléculas en el espacio químico se ve más afectada por las propiedades que se conservan menos entre compuesto y compuesto. Una vez identificadas se pueden usar estas propiedades, para representar el espacio multidimensional que tendrá una distribución análoga al original y poder así identificar compuestos semejantes.
Representación visual del espacio químico: dependencia con la representación molecular
El espacio químico depende directamente de los descriptores usados; por tanto, es un concepto relativo a las M características empleadas para definirlo. Para ilustrar este punto la Figura 1 presenta dos representaciones visuales del espacio químico de la misma serie de compuestos. La diferencia entre ambos gráficos es el grupo de descriptores empleados para hacer la representación. En la Figura 1A las características o descriptores corresponden a la “complejidad estructural” de las moléculas; en la Figura 1B se representa la “flexibilidad”. La figura muestra que la distribución y, por tanto, la “similitud” relativa de los compuestos puede cambiar significativamente cuando se modifica la representación molecular. Así, a diferencia del espacio cósmico, el espacio químico es relativo a la descripción molecular. Esta discusión nos lleva a la siguiente pregunta: ¿cómo cuantificar la similitud de dos moléculas en forma consistente?
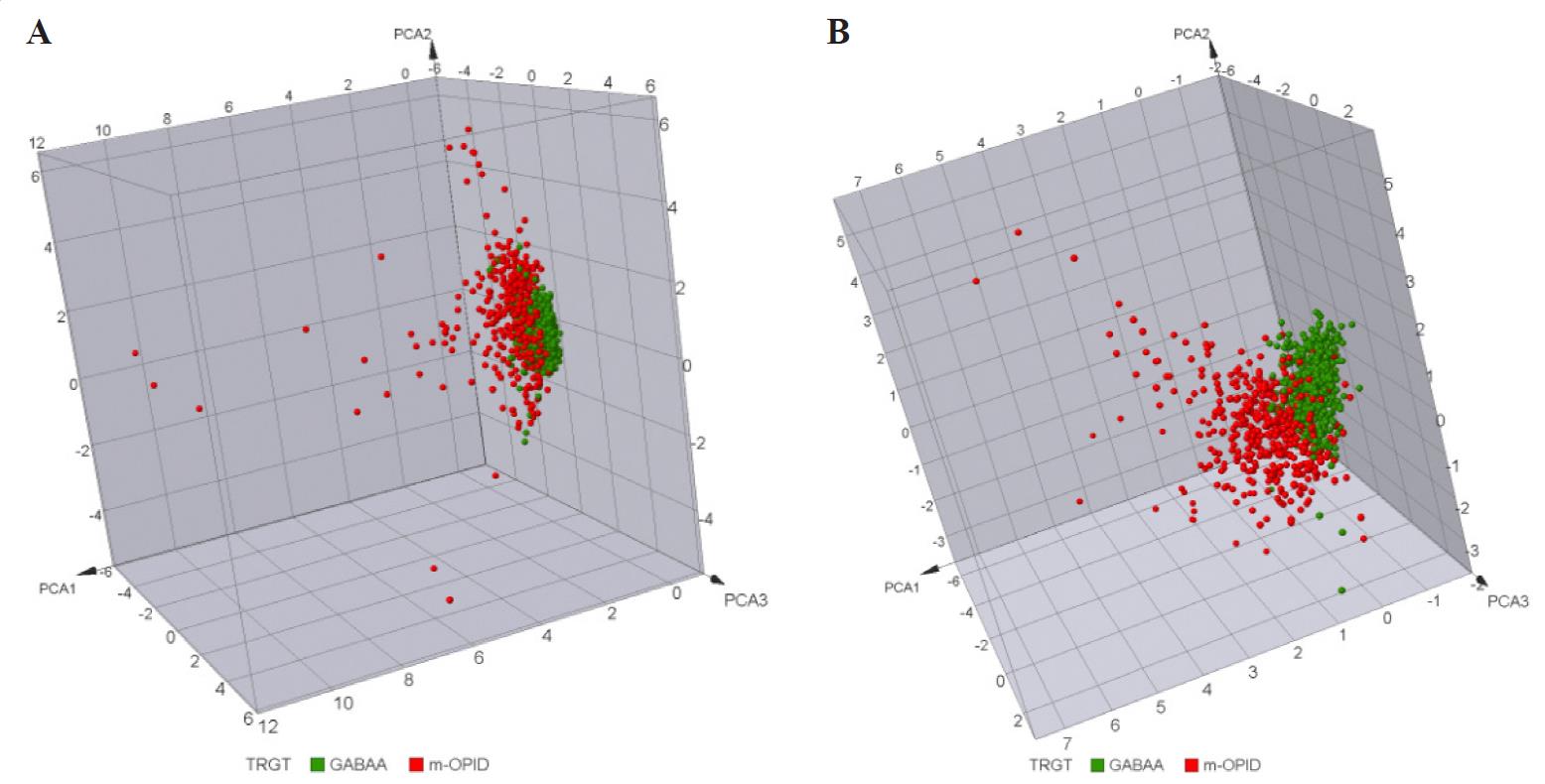
Similitud molecular, una cuestión de perspectiva
Cuando se habla de objetos semejantes se infiere que existe algún parecido, generalmente de naturaleza física. Por ejemplo, una naranja y una mandarina son notablemente semejantes, por ejemplo, respecto al tamaño, color, forma, etc. En cambio, una manzana y una naranja no resultan similares a primera vista. No obstante, es posible encontrar similitudes entre estos dos objetos (frutas) si se consideran otros aspectos, por ejemplo, el contenido de azúcar o vitamina C.
Una forma directa y rápida para comparar estructuras químicas en forma sistemática es mediante el tipo de átomos y cómo están conectados entre sí para establecer la semejanza de los grupos funcionales. Ahora, considere las tres comparaciones de dos moléculas en la Figura 2. La similitud del tipo y conexión de los átomos en el ciclohexano y benceno (Figura 2A) es muy alta. Sin embargo, reconocer características semejantes se va haciendo más difícil al tratar de igualar la identidad y conectividades de los átomos en los pares de moléculas de las Figuras 2B (ácido shikímico y L-tirosina) y 2C (zolpidem y alprazolam).
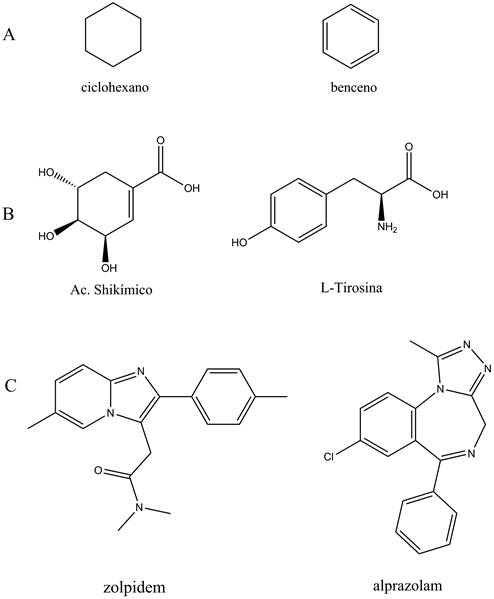
Figura 2 Comparaciones entre pares de moléculas con algún grado de similitud. A) Similitud estructural. B) Similitud bioquímica. C) Similitud farmacológica.
Para medir cuantitativamente la similitud entre dos moléculas en forma consistente, son necesarios dos elementos: A) una representación sistemática y consistente de las estructuras y B) una métrica (o coeficiente) de similitud (Bender et al., 2009).
Una representación sistemática de estructuras químicas: Huellas digitales moleculares
Una forma de codificar de manera única (sistemática) la identidad y conectividad de los átomos es a través de las “huellas digitales moleculares” (molecular fingerprints). Se pueden distinguir dos tipos principales: unas basadas en los fragmentos y otras en la topología (Saldívar-González et al., 2017). Los primeros utilizan fragmentos de referencia y se hace un “pase de lista” sobre las estructuras químicas marcando como presente (1) o ausente (0) cada fragmento del listado. Una de las limitaciones de éste método es que, al conocer una huella digital de una molécula, se puede saber si este fragmento está presente o no, pero no se conoce su ubicación en la estructura. Además, la representación depende de los fragmentos que comprenden la lista de referencia. Esto quiere decir que se pierde información sobre la estructura, específicamente sobre su conectividad. Ejemplos de estas huellas digitales son MACCS keys que se compone de 166 fragmentos (o más) y Pubchem fingerprint con 881 fragmentos.
En las huellas digitales basadas en la topología, se emplea la conectividad propia de las moléculas. El proceso inicia seleccionando un átomo central, para determinar los enlaces y átomos vecinos a una distancia determinada. Estos “caminos”, serán los que se comparen entre una estructura y otra. Por tanto, en este caso se construye una representación “más fiel” de la molécula, con el inconveniente de que la similitud será en general, más baja respecto a la representación por fragmentos pues las estructuras deberán tener conectividad semejante.
Es importante mencionar que las huellas digitales moleculares no son infalibles, ya que existen situaciones donde no serán capaces de distinguir estructuras con suficiente sensibilidad, para arrojar una representación única, esto es muy frecuente en isómeros. Por esta razón, cuando se trabaja con enantiómeros hay que estar bien seguro de que la estereoquímica sea considerada correctamente en pasos posteriores de un cribado.
Cuantificación de la similitud molecular
En la sección anterior se discutió que hay huellas digitales moleculares que representan a las moléculas por medio de fragmentos o subestructuras. Entonces, es posible hacer una relación matemática sencilla para medir su parecido. Esta operación se conoce como Coeficiente de Tanimoto:
donde a y b representan al número de fragmentos totales que tienen los compuestos X e Y; mientras que c representa el número de fragmentos que comparten ambos compuestos. Al ser un cociente, el valor de similitud sólo podrá ir de 0 (compuestos que no comparten ningún fragmento por ejemplo, totalmente diferentes) y 1 (compuestos iguales o que comparten exactamente el mismo número de fragmentos) (Prieto-Martínez et al., 2016). Otro caso sería, retomando la pareja de estructuras en la Figura 2C: usando MACCS keys el coeficiente de Tanimoto entre ambos compuestos es de 0.44 mientras que al usar una representación topológica (ECFP4) es de 0.09.
Si bien el coeficiente de Tanimoto es una métrica ampliamente usada, hay otras métricas que permiten evaluar la similitud. Particularmente, como una función de distancia, se pueden hacer comparaciones matemáticas como la Distancia Euclidiana, Manhattan o Soergel. Otros coeficientes que se pueden emplear son: Similitud coseno o Coeficiente Sorensen-Dice (Bajusz et al., 2015).
En la práctica, ¿cuál es la utilidad de cuantificar la similitud entre dos moléculas? Buscar un uso alterno para fármacos aprobados usando el principio de similitud, ésto se conoce como reposicionamiento. Por ejemplo, se sabe que el omeprazol y sus derivados, además de ser útiles en el tratamiento de la gastritis, tienen una actividad antiparasitaria significativa in vitro (Pérez-Villanueva et al., 2011).
La similitud molecular también es una herramienta que permite identificar moléculas que se unen a más de un receptor. Anteriormente, estas moléculas se descartaban usualmente por sus potenciales efectos secundarios no deseables (Hu & Bajorath, 2010). Sin embargo, mediante el reposicionamiento es posible identificar moléculas que actúan como “llaves maestras” y efectivas en varios padecimientos (Méndez-Lucio et al., 2016). Un ejemplo son los flavonoides; particularmente hesperidina, pues posee actividades antiparasitarias, antinflamatorias, sedantes, antioxidantes, etc., convirtiéndolos en polifármacos.
La baja similitud estructural también es útil. Considere el caso siguiente: de acuerdo al espacio químico resulta que una serie de compuestos propuestos tiene propiedades semejantes a fármacos antivirales. Tras realizar comparaciones de Tanimoto resultan valores de similitud estructural muy bajos. ¿Esto quiere decir que los compuestos deben descartarse? Por el contrario, ya que por el principio de similitud es posible que exista una actividad semejante, valdría la pena probar éstos compuestos. Si al final resultan activos, se habrá identificado una nueva estructura antiviral (un bioisóstero).
En la siguiente sección se aborda el tema de acoplamiento molecular y la simulación de interacciones proteína-ligando.
Acoplamiento molecular
Actualmente, es posible (con ciertas limitaciones), hacer aproximaciones del reconocimiento e interacción molecular. Un acoplamiento básico puede realizarse sin mayor problema en una computadora portátil y no tarda más de unos minutos (en algunos casos se hace en segundos). El proceso se puede realizar en tres formas generales: acoplamiento rígido, flexible y covalente. Este último no se tratará a detalle, por ser un caso muy específico que implica otras metodologías auxiliares. Si el lector está interesado en conocer más del tema, recomendamos estas excelentes referencias (De Cesco et al., 2017; Kumalo et al., 2015).
El acoplamiento rígido se basa en el modelo clásico de Emil Fischer: la llave y la cerradura. En esta aproximación se asume que ligando y proteína están rígidos durante su interacción. Otro tipo de acoplamiento se deriva del modelo de ajuste inducido, considerando que la unión del ligando y la proteína se debe a una influencia directa y flexibilidad entre si (Ferreira et al., 2015). Para modelar las interacciones, se usan campos de fuerza y las ecuaciones de Coulomb, además de las atracciones electrostáticas y fuerzas débiles como la de Lennard-Jones y Van der Waals (Pagadala et al., 2017). Por tanto, detrás de escena, lo que realiza la computadora es una serie de cálculos matemáticos que describen las interacciones entre ambas partes. El proceso global se puede resumir en dos pasos: el programa propone una serie de “soluciones” al problema y posteriormente selecciona a la más óptima como la correcta.
Actualmente, se usa con frecuencia un punto intermedio como aproximación: el acoplamiento semi-flexible donde el ligando se considera “libre” y desplazándose, mientras que el receptor permanece inmóvil. Esto permite un buen balance entre el tiempo de cálculo y la fiabilidad de los resultados. La búsqueda se realiza mediante un algoritmo que genera diferentes conformaciones del ligando en forma sistemática o estocástica (al azar) y las empata con la proteína. Una vez identificadas las diferentes formas de organización molecular, el resultado es la diversidad artísticamente configurada y apreciada en las figuras de este trabajo, evaluadas por una función matemática que calcula la energía de cada conformación al interactuar con la proteína. Este valor de puntaje es el criterio de selección para la solución más óptima, es decir aquella de menor energía. Este proceso, a pesar de simple y elegante, tiene varios problemas. Para comenzar, la selección del modo de unión de menor energía como la correcta no es realista: en prácticamente ningún caso el ligando se encuentra en su conformación más estable cuando interactúa con una proteína. Otro problema actual es que hasta ahora no se ha desarrollado un algoritmo capaz de considerar en forma “natural” la flexibilidad y su influencia en el reconocimiento. A esto se añade, que en pocos casos se considera la contribución del agua durante la unión proteína-ligando, debido a que aún es complicado modelar en forma rápida y precisa las moléculas del agua en forma explícita (Spyrakis & Cavasotto, 2015). Sin embargo, existen varias excepciones a la regla de forma que hay que conocer bien el sistema que se va a simular.
Por todo lo expuesto hasta ahora debe validarse un protocolo de acoplamiento. La validación consiste en determinar la capacidad del programa y su algoritmo para identificar el modo de unión de una molécula de referencia que puede ser el sustrato natural o un inhibidor característico de la misma (Verdonk et al., 2007). Generalmente es posible encontrar el complejo de referencia en el Protein Data Bank (Tabla I). Una vez identificados referencia y modos de unión, se realiza el protocolo de acoplamiento, calculados con el programa (ver Figura 3). Idealmente, lo que se espera es que ambos modos de unión se superpongan en su totalidad. En la práctica se utiliza la métrica de la raíz cuadrada de la desviación media (RMSD, por sus siglas en inglés) para hacer la comparación. Lo que este valor nos dice es la distancia promedio entre todos los átomos de cada modo de unión. Esta distancia debe encontrarse por debajo de los 2 Å para considerar una validación exitosa (Kitchen et al., 2004).
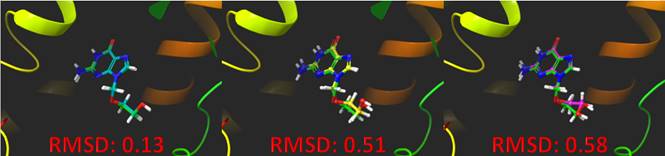
Figura 3 Validación de un acoplamiento molecular hipotético, usando RMSD. Ver la versión a color en línea.
Una vez validado el protocolo de acoplamiento, es posible considerar la energía asignada como un criterio de búsqueda para proponer nuevos compuestos activos. No obstante, es importante recordar que la energía de unión no es relevante si no se conservan las interacciones conocidas con la proteína. Por ejemplo, considere el caso de los bromodominios, pequeñas proteínas que participan en la regulación y expresión genética (Ferri et al., 2016). Recientemente se ha observado que los bromodominios inician el reclutamiento de genes y factores asociados a la inflamación, neoplasia y metabolismo.
En la literatura se reporta que una característica crítica de los inhibidores y sustratos es formar dos puentes de hidrógeno con los residuos 97 y 140 (ver Figura 4). La figura presenta un inhibidor característico (llamado JQ1) con las interacciones esperadas con la diana, mientras que las dos moléculas restantes tienen energías de unión comparables, pero no así sus interacciones.
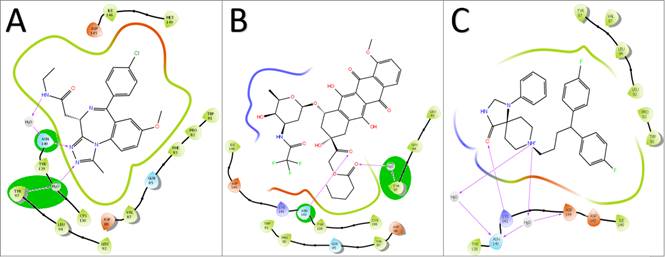
Figura 4 Interacciones moleculares para el BRD4 determinadas por acoplamiento molecular. A) Fármaco de referencia. B) Inhibidor potencial. C) Molécula inactiva. Las interacciones más importantes se resaltan en óvalos grises grandes. Ver la versión a color en línea.
Para superar estas limitaciones es posible “orientar” al programa de acoplamiento. Indicando las características que debe buscar en las moléculas y las interacciones que forman. Esto se conoce como “modelo farmacofórico” y puede obtenerse antes o después de un protocolo de acoplamiento. Otro problema puede surgir cuando la proteína que se desea acoplar no se encuentra en el Protein Data Bank. Esto puede deberse a que es una proteína recién descubierta o simplemente no ha logrado cristalizarse. Ante esto, puede realizarse un modelo tridimensional de la proteína o un llamado “modelo por homología”. Ambos “modelos” se comentarán brevemente, así como su utilidad en el diseño racional y optimización de fármacos.
Modelos farmacofóricos
¿Qué le confiere actividad biológica a una molécula? En farmacología se dice que la actividad está fundamentada en las relaciones estructura-actividad. En Química Farmacéutica estas relaciones son la base para optimizar las propiedades de las moléculas a partir de un núcleo activo. Como se comentó en la sección de similitud molecular (vide supra), estructuras diferentes pueden tener actividades semejantes (bioisósteros). El descubrimiento de núcleos alternativos es muy útil, ya sea para aumentar la selectividad o mejorar el perfil farmacocinético de una sustancia. No obstante, las implicaciones que esto conlleva indican que las relaciones estructura-actividad tienen limitaciones importantes. Además, se han reportado numerosos casos donde las modificaciones químicas sobre un núcleo activo tienen un resultado paradójico: modificaciones que deberían mejorar la actividad, provocan una disminución notable o una pérdida total de la misma. Estos “acantilados de actividad” no han podido explicarse en forma satisfactoria (y pueden estar relacionados con errores experimentales (Medina-Franco, 2013)). Sin embargo, se ha observado que núcleos específicos son más propensos a éste comportamiento. En cualquier caso, todo lo anterior obliga al desarrollo de una mejor representación.
Un modelo farmacofórico, es una representación abstracta de los requerimientos estructurales que “exige” el sitio activo de una proteína/receptor, para reconocer una molécula. Esta descripción incluye: átomos donadores/aceptores de hidrógeno, elementos hidrofóbicos; así como la distancia y ubicación espacial de cada elemento (Koes & Camacho, 2011). La Figura 5 muestra la estructura de Erlotinib, un fármaco antineoplásico. Note los diferentes puntos en la estructura: todos son elementos farmacofóricos. No obstante, de todos ellos, sólo las esferas (donadores de hidrógeno) y los grupos aromáticos son los que confieren su actividad biológica (como antineoplásicos).
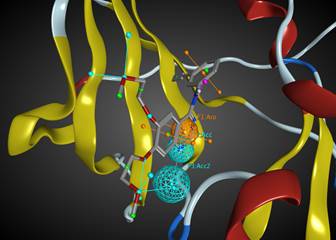
Figura 5 Modelo farmacofórico de Erlotinib, los puntos son elementos de posible interacción; las esferas son las asociadas directamente con la actividad biológica. Ver la versión a color en línea.
Recientemente, la clasificación se ha extendido a elementos de carácter aromático y elementos voluminosos. Cuando se identifican las características cruciales para el reconocimiento y actividad, se pueden identificar los rasgos “haptofóricos”, es decir, aquellos que ayudan al reconocimiento, pero son prescindibles, ya que no confieren actividad a un compuesto. De esta manera, las características haptofóricas son las que se pueden modificar para optimizar una estructura.
Las ventajas de un modelo farmacofórico son notables. En primera instancia, permiten identificar estructuras diversas, siempre y cuando se ajusten a los requerimientos. Además, pueden usarse como criterios de orientación para refinar los resultados de un acoplamiento molecular. La principal desventaja es que, para ser robusto, el modelo debe tener la mayor cantidad de información posible sobre el receptor e inhibidores conocidos, por lo que deberá ser actualizado constantemente para mantener su aplicabilidad y vigencia (Clayton et al., 2007).
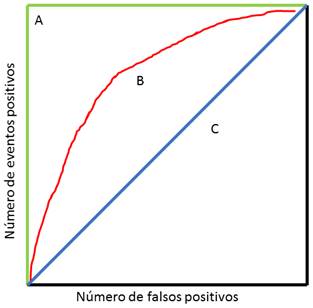
De manera semejante al acomplamiento molecular, un modelo farmacofórico debe validarse para determinar su aplicabilidad y capacidad de predicción. La manera de hacerlo es mediante un análisis de Característica Operativa del Receptor (ROC, por sus siglas en inglés). En general, el análisis consiste en determinar la capacidad del modelo para distinguir entre resultados positivos y falsos positivos (Brown & Davis, 2006) (ver Figura 6). Lo anterior se hace al graficar el número de ambos eventos y ver el comportamiento de la curva. Cuando los resultados son puramente al azar (no existe ningún modelo valioso) se describe una línea recta que corta el plano en diagonal. Un modelo ideal, será aquel que identifica correctamente sólo a los casos positivos formando una “escuadra” en el plano. En consecuencia, un modelo propuesto se encontrará entre la diagonal y la escuadra. Si por alguna razón, la curva se ubica por debajo de la diagonal, quiere decir que el modelo es “engañado” fácilmente por falsos positivos, de hecho, hay mejor oportunidad de encontrar un caso positivo al azar.
Modelos por homología
Cristalizar una proteína es un proceso muy delicado y laborioso para lograr una buena resolución de la estructura. Esto se debe principalmente a las limitaciones de los métodos y la pericia del cristalógrafo para asignar correctamente los aminoácidos y su densidad electrónica. Se considera como buena resolución, un margen de error entre 1.5 y 3 Å en la asignación.
Además, existen proteínas que son bastante difíciles de cristalizar como las proteínas de membrana. Actualmente, el Protein Data Bank es una base de datos pública que recoge más de 100,000 estructuras cristalográficas. Lamentablemente el porcentaje de estructuras únicas y de resolución razonable es pequeño (Warren et al., 2012). Ante esto cabe la pregunta: ¿cuántas proteínas son “modulables” mediante fármacos? Algunos estimados de la década pasada hablaban de alrededor de 300 (actualmente este número se ha duplicado (Santos et al., 2016). En ese entonces el Protein Data Bank se componía de 30,000 estructuras, donde cerca del 60% representaba sólo 34 proteínas de interés farmacéutico (Mestres, 2005).
De esta manera, en ocasiones no hay acceso a receptores o proteínas específicas para hacer pruebas de acoplamiento. Una alternativa a esto es crear un modelo por homología de la proteína de interés. El proceso consiste en crear la “estructura de una “proteína virtual” usando como base (o plantilla) estructuras ya conocidas y cristalizadas. Es probable que el resultado sea una “quimera” proteica, que igualmente requiere un análisis para determinar que fue construida correctamente y que sea útil para el acoplamiento molecular. En resumen, es necesario determinar que la secuencia del modelo sea válida, que su geometría sea correcta, que la estructura se mantenga estable y que el sitio activo sea capaz de reconocer al ligando (Hillisch et al., 2004).
Es cierto que la utilidad real de un modelo por homología puede ser limitada, pero es una herramienta útil para apoyar el diseño de fármacos a dianas, cuyas estructuras tridimensionales no son bien conocidas. Los resultados pueden ser muy significativos (Duan et al., 2015; Leffler et al., 2017).
Conclusiones
Los métodos computacionales son muy diversos y versátiles.Actualmente la capacidad de éstos son bastante notables, probando su utilidad práctica, aunque todavía no sea posible contar con la simulación precisa de sistemas muy complejos. Lo importante es tener expectativas realistas aprovechando al máximo los recursos computacionales. Además, es necesario erradicar paradigmas erróneos como el “descubrimiento en un par de clics” y el uso de cálculos o análisis sin intervención racional del usuario. Debe existir un balance adecuado entre el conocimiento químico, el aporte computacional y el valor farmacológico.
De esta forma, se podrán optimizar tiempo y recursos. Ya sea, dando prioridad a la síntesis de ciertos compuestos o derivados, la presunta evidencia de un mecanismo de acción, reposicionando fármacos o simplemente para disminuir la cantidad de pruebas biológicas. Los métodos computacionales representan un nuevo horizonte en la ciencia, abriendo la puerta a nuevas posibilidades.

