











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
En la actualidad muchos países reconocen la necesidad de proveer políticas de carácter social que se traduzcan en una mejor calidad de vida y bienestar de su población. Así, es indispensable evaluar las grandes tendencias socioeconómicas de la población de estudio, lo que permite identificar las zonas donde se presentan las mayores carencias sociales y de esta manera focalizar los recursos necesarios para el desarrollo de estos sectores. De igual manera, estas evaluaciones permiten conocer el grado de avance en cuanto a las condiciones de una sociedad. Una forma recurrente de evaluación es la que se basa en esquemas y escalas de estratificación social o socioeconómica, principalmente porque son estudios de clasificación utilizados para reflejar la situación de las personas en espacio y tiempo, a través de categorías.
La presente investigación aborda el tema de la estratificación social mediante una propuesta que agrupa a la población mexicana en categorías/ estratos de acuerdo con sus características socioeconómicas. Para efectuar lo anterior, se utilizó la metodología del Proceso Jerárquico Analítico (PJA) (Saaty, 1980), mediante el cual se llevó a cabo la construcción de un índice, ponderando los valores de seis indicadores considerados pertinentes para la tipificación de cada familia en estudio.
Cabe señalar que respecto al tema de estratificación social, existen teorías mediante las cuales se sustentan los diferentes estudios realizados a lo largo de la historia. Primeramente, uno de los conceptos principales es el de estrato social, según Dahrendorf (1959) citado por Francés-García (2009: 46), un estrato es “una categoría de personas que ocupan una posición similar en una escala que jerarquiza ciertas categorías propias de una situación, como pueden ser el ingreso, el prestigio o el estilo de vida”. Las teorías sobre estratificación provienen de dos corrientes principales, la teoría de Karl Marx, que establece que las clases sociales están en función de quien posee y controla los medios de producción, y la teoría de Max Weber, la cual acepta que las clases se basan en condiciones económicas objetivas; sin embargo, este autor aclara que el control y propiedad de los medios de producción sólo es uno de los factores económicos que influyen en la determinación de las clases además de otros como los conocimientos técnicos y las cualificaciones que afectan a los tipos de trabajos que las personas pueden obtener.
Otras teorías desarrolladas posteriormente, basadas en estas mismas corrientes, son las de Erik Olin Wright (desarrollada entre 1978 y 1985) y Frank Parkin (desarrollada entre 1971 y 1979), citadas por Giddens (1995). La primera se enfoca en tres elementos que influyen en la división de clases: a) el control sobre las inversiones y el capital, b) el control de los medios físicos de producción (tierra, fábricas y oficinas), y c) el control sobre la fuerza de trabajo; la segunda está basada en la idea de cierre social que engloba todo aquel proceso mediante el cual los grupos privilegiados tratan de mantener el control exclusivo sobre los recursos, limitando el acceso de los demás a éstos. Existen muchas formas posibles de cierre social, como la religión, el origen étnico e incluso los títulos académicos.
Los estudios sobre estratificación social permiten plantear distintos análisis de la estructura social e involucran aspectos como la ocupación, el estatus, la educación, los ingresos, el capital social, etcétera; los cuales pueden variar en importancia de acuerdo al enfoque de la estrategia de estratificación. Regularmente, los análisis resultantes permiten no sólo realizar comparaciones ordinales sino, además, establecer y cuantificar “distancias sociales” en términos de magnitudes relativas (Francés-García, 2009).
Esquemas, escalas e índices de estratificación
Existen diversas estrategias de estratificación social, cada una puede tomar una perspectiva diferente de acuerdo con los criterios de medición y construcción de las herramientas para estratificar. Podemos citar al respecto algunos de los trabajos elaborados bajo distintos enfoques como el Esquema Nominal de Categorías de Clase de Goldthorpe (EGP), que surge de los estudios de este autor realizados en Gran Bretaña sobre la movilidad social (Regidor, 2001). Este esquema es una medición discreta basada en la creación de categorías nominales. Una de las ideas centrales de dicho esquema es que las sociedades están en sí mismas estratificadas debido al aumento de la diferenciación del trabajo. Se asume un número distinguible de categorías y combina la información ocupacional con información adicional sobre el estatus del empleo (Atria, 2004). Otro ejemplo de estratificación es la Escala de Prestigio de Treiman (SIOPS), basada en la idea del prestigio, es decir, que la posición social de un individuo no sólo se basa en la ocupación en sí misma, sino en las actitudes, experiencias y estilos de vida derivados de las cotas de prestigio de dicha ocupación. Según Treiman (2013), el prestigio es la aprobación y respeto de una ocupación ante los miembros de una sociedad otorgados básicamente por sus servicios a la misma.
Otro tipo de escalas de estratificación son las que toman en cuenta la interacción selectiva entre los integrantes de una sociedad como elemento básico en la organización de la estratificación social. Como ejemplo está la escala Cambridge Social Interaction and Stratification Scale (CAMSIS). Según Prandy (1999), mencionado por Lambert et al. (2013), la interacción selectiva deviene del hecho de que las personas de una posición social común, o al menos similar, tienen una mayor probabilidad de interactuar en términos de igualdad con miembros del mismo grupo social.
También, otra clase de estratificación utilizada comúnmente es la que maneja índices socioeconómicos, cuyo principal atributo es que no parte de juicios subjetivos o de percepción. Por el contrario, éstos se construyen a partir de una suma ponderada de características socioeconómicas de cada ocupación, esencialmente las referentes a educación e ingresos. Como ejemplo está el International Socio-Economic Index (ISEI), este enfoque se basa en los vínculos entre tres actividades de relevante importancia: la educación, la ocupación y los ingresos. Una de las relaciones que asume el modelo es que la ocupación es la forma de convertir un valor educacional en monetario, es decir, una cadena causal simple en donde los ingresos de una persona son efecto del nivel educacional y están mediados por los logros ocupacionales (Jones y McMillan, 2001).
En México, una forma de obtener los niveles socioeconómicos es a través de la regla AMAI 10X6 (López-Romo, 2009), la cual es un índice que clasifica a los hogares en seis niveles, considerando nueve características o posesiones del hogar y la escolaridad del jefe de familia o persona que más aporta al gasto. Otros ejemplos de trabajos que abordan el tema de la composición social en México son el Índice de Marginación del Consejo Nacional de Población (Conapo) y el Índice de Desarrollo Humano (IDH) del Programa de Naciones Unidas para el Desarrollo (PNUD); el primero tiene como objetivo primordial construir una medida que permita identificar las zonas donde se presentan las mayores carencias sociales. Conapo (2012a) presenta diferentes metodologías de obtención de índices de marginación, basadas en la construcción de indicadores socioeconómicos, normalmente utilizando información de los Censos de Población y Vivienda. Por otro lado, y referido al segundo trabajo mencionado, el IDH no es como tal un estratificador social, más bien, como su nombre lo indica, refleja el desarrollo humano en el área de estudio.
Por último, hacemos referencia a un estudio realizado exprofeso para la cuantificación de la clase media en México llamado “Cuantificando la clase media en México: un ejercicio exploratorio”. La investigación usa los datos de la Encuesta Nacional de Ingresos y Gastos de los Hogares de 2010 y utiliza una herramienta de estratificación multivariada desarrollada por el Instituto Nacional de Estadística y Geografía (Inegi) (2013), la cual se sustenta en un análisis cluster bajo el criterio de K-medias.
Muchos de los esquemas de estratificación social están basados en índices o escalas, obtenidos de algunas variables e incluso de una sola (Pressman, 2011). Como ya se mencionó, la presente investigación se basa en la meto-dología del Proceso Jerárquico Analítico (Analytic Hierarchy Process) expuesto por Thomas L. Saaty (1980). A continuación, se describe brevemente.
Proceso Jerárquico Analítico
Este proceso es una herramienta diseñada para resolver problemas complejos de criterios múltiples, es útil para estructurar y ordenar todas las alternativas posibles a una decisión. Operacionalmente ayuda a construir índices, reduciendo la complejidad a un esquema jerárquico simple. El proceso requiere que quien toma las decisiones proporcione evaluaciones subjetivas respecto a la importancia relativa de cada uno de los criterios, y después especifique su preferencia con respecto a cada una de las alternativas de decisión y para cada criterio (Saaty, 2008).
La estratificación socioeconómica planteada en este artículo tiene como principal ventaja su simpleza en cuanto a las variables necesarias para su construcción, lo que hace que sea comparable con poblaciones de las que no se cuenta con mucha información. Además, es importante mencionar que el trabajo de comparación de 1930 con 2010 es el primero de su tipo y proporciona información respecto al avance que se ha tenido durante 80 años en México y no sólo en un punto del tiempo.
El presente artículo se estructura de la siguiente manera: en el apartado dos se muestran de forma breve los antecedentes y contexto histórico relativos a 1930 y 2010. En el apartado tres se presenta el desarrollo de la metodología utilizada para estratificar ambas poblaciones. El apartado cuatro se exhiben los resultados obtenidos al desarrollar la metodología propuesta, y el apartado cinco detalla las conclusiones que se obtuvieron mediante la investigación.
1. Breves antecedentes contextuales relativos a los años de interés
A continuación, se exponen algunos de los acontecimientos relevantes que impactaron en el desarrollo de la población mexicana en los años de estudio, con el objetivo de describir brevemente ambos momentos históricos.
1.1. Contexto 1930
Al igual que en el resto del mundo, la población mexicana ha sufrido cambios drásticos en su estructura a lo largo de los últimos 100 años; particularmente, es importante contextualizar el entorno inmediato anterior a 1930, cuando se realizó el censo bajo estudio. Los principales eventos que tuvieron incidencia en la población, hacen de esta época un punto histórico de especial importancia. En los primeros 30 años del siglo pasado, se registraron tres sucesos importantes que diezmaron a la población mexicana y tuvieron incidencia en su estructura social: 1. La Revolución mexicana (1910-1921); 2. Un brote de influenza conocido como “influenza española” (1918-1919), considerado como uno de los más críticos ocurridos en el país y el mundo y, 3. La Guerra Cristera (1926-1929), (Zamudio-Sánchez et al., 2015: 19). Aunado a estos sucesos, en el periodo 1913-1916 se registró una crisis económica ocasionada por el golpe de Estado de Victoriano Huerta (conocido como la decena trágica del 9 al 18 de febrero de 1913), que afectó prácticamente a todas las ramas de la actividad industrial, a excepción del petróleo y el henequén. Sin embargo, el mayor golpe para la economía mexicana vino con la Gran Depresión mundial de 1929-1932, que derrumbó la producción en México (-14.8 en 1932) y el PIB per cápita en pesos (-16.3 en 1932), de acuerdo con Aparicio-Cabrera (2010).
1.2. Contexto 2010
Por su parte, para 2010 la situación demográfica del país presentaba cambios sustanciales, muchos de los cuales fueron producto de factores impulsados en las décadas pasadas, por ejemplo, la disminución en la mortalidad infantil junto con la mayor esperanza de vida al nacer, el comportamiento de las causas de muerte, el crecimiento del uso de métodos anticonceptivos modernos y el aumento de las migraciones (Conapo, 2014). México fue el mayor receptor de remesas en América Latina y el Caribe, y de acuerdo con datos del Banco de México, éstas constituyeron el segundo lugar como fuente de divisas de la economía nacional (Conapo, 2012b). Además de esto, el Censo General de Población de 2010 registró una población de 112 millones 400 mil habitantes, de los cuales 23.2 era población rural (en contraste con 66.5 de 1930). Otro factor presente este año es la transición demográfica en el país, ya que la población de la tercera edad ha aumentado considerablemente (Secretaría de Salud, 2011). Por último, la población del 2010 en México también sufrió el efecto de la crisis económica mundial en 2008.
2. Metodología
Para desarrollar la presente investigación se analizaron características sociales de la población mexicana en dos puntos en el tiempo, 1930 y 2010. Se realizó un agrupamiento de la población de acuerdo con la similitud de dichas características, para esto, se propuso un índice basado en la metodología del Proceso Jerárquico Analítico (Saaty, 1980), con la finalidad de distribuir a la población en grandes grupos con características similares. Dicho índice otorga una calificación por familia y se replica en cada integrante de la misma.
Puesto que el objetivo principal de la investigación fue realizar una comparación entre los resultados de estratificar las poblaciones de 1930 y 2010, se efectuó un análisis sobre las variables que pudieran ser incluidas para estratificar ambos años, ya que las bases de datos utilizadas para este trabajo provienen de censos que por su distanciamiento en el tiempo no recopilan las mismas características de la población. Igualmente, fue necesario determinar las transformaciones adecuadas de dichas variables con la finalidad de que los indicadores por variable reflejaran la situación social de la familia en dicha variable en una escala ordinal. Además, cada variable debió estar representada de acuerdo a su importancia en el índice, lo cual implicó la compilación de éstas con base en criterios que también fueron especificados durante el desarrollo de la metodología antes mencionada.
Se utilizó la base de microdatos del Censo de Población de 1930, dicha base fue recuperada por la Universidad Autónoma Chapingo con recursos del Fondo sectorial Conacyt-Inegi mediante el proyecto de investigación “Muestreo probabilístico para la recuperación de los microdatos del Censo General de Población de 1930”, y contiene 1,482,453 registros. Para 2010, la base de microdatos correspondiente fue generada por Inegi (2010) mediante un cuestionario ampliado en donde se contemplaron tres temáticas centrales: familias, personas y migración. Dicha base contiene 11,938,402 registros.
Los microdatos censales son las respuestas individuales a los cuestionarios de los censos. Los datos incluyen características como la edad, el sexo, el estado civil, la relación con el jefe de familia, la migración, la educación, la ocupación, etcétera. Los microdatos censales son un recurso de gran valor para la investigación en ciencias sociales ya que son registros individuales que permiten explorar simultáneamente las características de los individuos, las familias, los hogares y las viviendas en que residen, y además proceden de censos que tienen ventajas no comparables con otras fuentes (McCaa et al., 2005).
2.1. Índice de Estratificación Social (InSoc) para 1930 y 2010
A continuación se presentan a detalle todos los pasos que se realizaron para la creación del Índice de Estratificación Social, que en lo sucesivo lo denotaremos como InSoc. Uno de los pasos claves en el análisis fue la selección de variables ya que de esto depende la obtención de resultados congruentes. En el caso de la estratificación social, basada en los microdatos del Censo General de Población de 1930, la dimensionalidad del problema no representó un obstáculo, de hecho, se cuenta con pocas variables para llevar a cabo el trabajo en comparación con ediciones más recientes de los censos en México. Sin embargo, fue importante tener un criterio de selección y un método que ponderara la importancia de cada variable en el índice. Para 1930 se utilizaron las variables: Número de integrantes de la familia, Edad, Sabe o no leer y escribir (dicotómica, sí o no), Profesión u ocupación (múltiples respuestas) y Propiedades (urbanas, rurales, ambas y ninguna). Mediante dichas variables se calcularon los siguientes indicadores por familia: Indicador de Alfabetismo, Indicador de Independencia en la familia, Indicador de Ocupación, Indicador de Sector de Ocupación de acuerdo a su actividad productiva, Bienes Raíces y Edad Promedio de la familia. Estas variables fueron seleccionadas por el equipo de investigación, de acuerdo a su pertinencia en el estudio, el número de integrantes de la familia se incluyó ya que el estudio fue realizado a este nivel de desagregación; la edad se utilizó para dos indicadores, ambos dan una idea (aunque con un enfoque distinto) del peso que tienen en una familia las personas jóvenes y adultas mayores; el alfabetismo es uno de los principales indicadores de desarrollo de una sociedad, mientras que la profesión u ocupación de las personas es una de las variables principales en muchos estudios de estratificación socioeconómica y, junto con Propiedades fungen como variables económicas según el contexto en que se utilizaron en el InSoc.
Los microdatos del Censo de Población y Vivienda 2010 contienen amplia información tanto social como demográfica y económica de la población; sin embargo, para poder hacer una comparación objetiva de la información fue necesario utilizar variables análogas en la medida de lo posible por lo que se decidió incluir las variables: Identificador de la vivienda, Edad, Alfabetismo, Condición de actividad, Ocupación u oficio y Tenencia de la vivienda. Con estas variables se obtuvieron los mismos indicadores de 1930 con una diferencia en el tratamiento de la variable Tenencia de la vivienda, la cual fue ocupada en analogía a la variable Propiedades del Censo de 1930 debido a que ésta no se colectó para 2010.
Ahora se muestran las transformaciones necesarias para obtener los indicadores por familia. Se llevaron a cabo los mismos cálculos para ambas bases de microdatos (1930 y 2010) excepto para el caso del indicador de Bienes Raíces en el que se especifica su obtención para cada año.
Indicador de Alfabetismo (IA): se refiere a la proporción de integrantes de la familia de 15 años o más que saben leer y escribir (Inegi, 2016), ecuación 1.
Indicador de Independencia en la familia (IID): es el valor complementario del Indicador de Dependencia. Este último, resulta de dividir el número de integrantes de la familia cuya edad se ubica por encima de 65 años y por debajo de 15 años, entre el número de personas cuya edad se ubica entre 15 y 65 años. El IID indica el peso de la población potencialmente activa respecto a la población no activa (niños y adultos mayores).
Primeramente, se calculó el Indicador de Dependencia en la Familia (IDF) sin estandarizarlo, ecuación 2.
Los valores de este indicador no son acotados por lo que fue necesario estandarizar su valor obteniendo el Indicador de Dependencia Estandarizado (IDE) mediante la ecuación 3:
donde, IDF i es el Indicador de Dependencia en la Familia i.
La variable IDE no tiene el mismo sentido que las otras variables, es decir, cuando su valor es más bajo significa una mejor condición social; por esta razón es necesario tomar el valor complementario del indicador, es decir:
Indicador de Ocupación (IO): Es la proporción de personas en la familia en edad productiva y que tienen una profesión u ocupación productiva, ecuación 5:
Indicador de Sector de Ocupación de acuerdo a su actividad productiva (IOs): Se refiere a la proporción de personas económicamente activas en la familia, donde cada una de ellas se pondera por el porcentaje de participación del sector en donde desarrolla su actividad productiva. Este porcentaje se refiere a la participación que tuvo cada sector en el PIB de 1930. Los valores usados son 0.537 para el sector terciario, 0.272 para el sector secundario y 0.191 para el primario (Soria-Murillo, 1983). Los valores para 2010 son 0.6391 para el sector terciario, 0.3455 para el sector secundario y 0.0351 para el primario (Inegi citado en SIELOCAL, 2015).
Se calculó el Indicador de Sector de Ocupación sin estandarizar (IOs*) como sigue en la ecuación 6:
donde:
x: es el número de integrantes de la familia en edad productiva que se desempeñan en el sector terciario,
y: es el número de integrantes de la familia en edad productiva que se desempeñan en el sector secundario,
z: es el número de integrantes de la familia en edad productiva que se desempeñan en el sector primario.
La ecuación anterior se presenta para los datos del PIB de 1930. Para 2010 se sustituyeron los datos con los del PIB 2010.
Los valores de este indicador no están acotados por lo que fue necesario estandarizar su valor obteniendo el Indicador del Sector de Ocupación estandarizado (IOs), mediante la ecuación 7:
donde:
Indicador de Bienes Raíces (IBR): Es una medida propuesta por el equipo de investigación que pretende dar un valor de esta variable a cada familia, de tal manera que represente el acceso a mejores o peores opciones de desarrollo utilizando la tenencia o no de propiedades.
En la Tabla 1 se muestran los cálculos realizados para obtener el IBR. El paso uno fue obtener la proporción de personas que contestaron afirmativamente a cada posible respuesta, después se obtuvo el recíproco de cada proporción como se muestra en el paso dos, lo anterior debido a que se busca reflejar una mejor condición conforme el indicador es mayor. El siguiente paso fue obtener la proporción que representaba cada posible respuesta dividiendo su valor entre la suma de todos ellos (54.1235), esto se detalla en el paso tres. Por último, se escalaron los valores de las cuatro respuestas dividiendo cada valor entre el máximo de ellos (0.6887). Los valores escalados se registran en el paso cuatro.
Tabla 1 Obtención de los valores posibles para el Indicador de Bienes Raíces.
| Paso | Descripción | Notación |
Sin propiedades |
Campo | Ciudad |
Ambas propiedades |
|---|---|---|---|---|---|---|
| Uno | Proporción en la base de datos (BD) | WBD i | 0.4869 | 0.4051 | 0.0811 | 0.0268 |
| Dos | Recíproco | R i = 1/WBD i | 2.0539 | 2.4682 | 12.3250 | 37.2764 |
| Tres | Proporción | W i = R i / ΣR i | 0.0379 | 0.0456 | 0.2277 | 0.6887 |
| Cuatro | Valores escalados (IBR) | IBR = W i / max W i | 0.0551 | 0.0662 | 0.3306 | 1 |
Fuente: elaboración propia.
De lo anterior se obtuvieron los valores de la siguiente ecuación:
Para 2010 la variable de la que se obtuvo el IBR es Tenencia de la vivienda, la cual sólo contempla tres categorías: la tenencia de vivienda en municipios urbanos (análogo a Bienes Raíces en la ciudad), tenencia de vivienda en municipios rurales (análogo a Bienes Raíces en el Campo) y no posee casa propia (análogo a No posee Bienes Raíces). Para este caso se llevó a cabo un procedimiento de ponderación distinto debido a que la proporción de familias que tienen la peor condición (no posee casa propia) no es la menor, por lo que si se pondera de la misma manera las familias que tienen la peor condición no tendrían el nivel más bajo del indicador. Se calificó siguiendo el procedimiento del PJA (Saaty, 1980) con una escala de importancia con valores uno, tres, cinco y siete. La respuesta “no posee casa propia” se catalogó con el valor más bajo de la escala (uno), la respuesta “tenencia de vivienda en municipios rurales” con el valor tres, y la respuesta “tenencia de vivienda en municipios urbanos” con el valor más alto (siete). Al estandarizar los valores se obtuvo la siguiente ecuación 9:
Edad media de la familia (PE): Este indicador es un promedio aritmético de las edades de los integrantes en la familia, posteriormente se pondera dicho promedio otorgando valores cercanos a cero cuando el promedio familiar es cercano a 100 y otorgando uno a los cercanos a siete años (los menores de siete se ponderan con 0), ecuación 10:
2.2. Asignación de valores ponderadores a cada variable
Una vez obtenidos los indicadores, se asignaron calificaciones para determinar cuáles de ellos aportaban más información para la asignación de una familia en cierto estrato social. Según la metodología del PJA, se debe construir una matriz de pesos. Saaty (1980) propuso un método de comparación y puntaje por pares tal que se obtenga una matriz cuadrada n x n, donde n es el número de criterios (en nuestro caso los indicadores son los criterios pues se desea construir el índice según su importancia). Se debe recordar que todas las comparaciones deben tener el mismo orden de magnitud. Igualmente se debe tomar en cuenta una propiedad del PJA sobre “juicios recíprocos”, que requiere que en la matriz de comparaciones, donde es el valor de la comparación del criterio i respecto al j, y el correspondiente a la comparación del criterio j en relación al i. Posteriormente, se debe verificar que dicha comparación por pares sea válida, es decir, que las comparaciones no generen contradicciones; para esto se pueden establecer grados de consistencia, es decir, valores que indican si la matriz de comparaciones propuesta tiene puntajes lógicos o no.
En seguida se presenta la matriz de comparaciones entre los criterios (indicadores). Para las comparaciones por pares se hizo una modificación que asegurara la consistencia de las comparaciones.
La matriz de la Tabla 2 es consistente y los datos se pueden interpretar de la siguiente manera: Entrada (1,2), el IA es cinco veces más importante para el InSoc que el IID, entrada (1,3) el IA es 1.6 veces más importante para el InSoc que el IO, entrada (1,4) el IA es igualmente importante para el InSoc que el IOs, y así análogamente se llevan a cabo las comparaciones por pares.
Tabla 2 Representación matricial de las comparaciones establecidas mediante el PJA.
| Variable | IA | IID | IO | IOS | IBR | PE |
|---|---|---|---|---|---|---|
| IA | 1 | 5 | 5/3=1.6 | 1 | 1 | 5/2 |
| IID | 1/5 | 1 | 1/3 | 1/5 | 1/5 | 1/2 |
| IO | 3/5 | 3 | 1 | 3/5 | 3/5 | 3/2 |
| IOS | 1 | 5 | 5/3 | 1 | 1 | 5/2 |
| IBR | 1 | 5 | 5/3 | 1 | 1 | 5/2 |
| PE | 2/5 | 2 | 2/3 | 2/5 | 2/5 | 1 |
Fuente: elaboración propia.
Definida la matriz de comparaciones, se normalizó por columnas y se promedió por filas para obtener el vector de pesos por indicador, también conocido como eigenvector principal (Saaty, 2003), el cual está compuesto por el peso obtenido de cada indicador.
La Tabla 3 contiene los pesos, ya estandarizados de las variables, los cuales fueron usados para calificar a cada familia según sus indicadores. También contiene el valor de ponderación de las variables utilizadas para la construcción de cada indicador (llamadas sub-variables) tanto para 1930 como para 2010.
Tabla 3 Pesos de las variables.
| Variable | Indicador |
Peso indicador |
Sub-variable | Peso sub-variable | |
|---|---|---|---|---|---|
| 1930 | 2010 | ||||
| Alfabetismo | IA | 0.2381 | Valor de IA | 1 | 1 |
| Dependencia | IID | 0.0476 | Valor de IID | 1 | 1 |
| Ocupación productiva | IO | 0.1429 | Valor de IO | 1 | 1 |
| Sector productivo de la ocupación | IOs | 0.2381 | Sector primario | 0.191 | 0.0351 |
| Sector secundario | 0.272 | 0.3455 | |||
| Sector terciario | 0.537 | 0.6391 | |||
| Bienes raíces | IBR | 0.2381 | No tiene Bienes | 0.055 | 0.1429 |
| Raíces (BR) | |||||
| Tiene BR en el campo | 0.066 | 0.4286 | |||
| Tiene BR en la ciudad | 0.331 | 1 | |||
| Tiene BR en el campo y la ciudad | 1 | - | |||
| Promedio de edad | PE | 0.0952 | Valor de PE | 1 | 1 |
Fuente: elaboración propia.
2.3. Obtención del InSoc
El InSoc por familia se obtuvo multiplicando el vector de pesos de los indicadores de la Tabla 3 por el vector de valores de cada familia. El índice refleja la situación socioeconómica de una familia, cuando este tiende a cero hablamos de una familia con acceso a menores opciones de desarrollo, y cuando tiende a uno, de una familia con acceso a mayores opciones de desarrollo. Entonces, tener un índice alto implicará pertenecer a una situación socioeconómica más alta.
2.4. Estratificación con los microdatos del Censo General de Población y Vivienda 2010
Dado que para 2010 se cuenta con al menos dos estudios en cuanto a la composición de los estratos sociales y socioeconómicos de la población mexicana, se decidió obtener los estratos primeramente con los microdatos de 2010 y basado en éstos, obtener su equivalente en 1930.
Cabe mencionar que, al obtener el InSoc por familia, podemos decir que todos los integrantes de una misma familia tienen el mismo InSoc, por lo que a cada individuo le asignamos el mismo valor de su familia.
De esta manera todos los individuos de la base de datos fueron clasificados. Lo anterior representa una ventaja para la estratificación propuesta en este trabajo, ya que se pueden hacer las caracterizaciones de cualquier subpoblación de interés.
Mediante el paquete estadístico SAS se obtuvieron los valores del InSoc para cada familia con lo que podemos saber qué familias tienen características similares e incluso podemos ordenarlas.
Teniendo las familias clasificadas y ordenadas se procedió a realizar el agrupamiento en estratos. Dado que las calificaciones asignadas por el índice se encuentran entre cero y uno, se decidió partir el intervalo [0,1] en 20 grupos siguiendo la metodología de Dalenius y Hodges, de acuerdo con Conapo (2012a). Lo anterior se realizó con el fin de tener una categorización del índice manejable como lo hizo Conapo (2012a) para el cálculo del Índice de Marginación 2010, y posteriormente se aplicó el método de diferenciación de grupos que se utilizó para formar los estratos y que se describirá a continuación.
Para cada uno de los grupos se obtuvo el promedio por indicador (IA, IID, IO, IOS, PE, IBR) de tal forma que se pudieran comparar entre sí y definir qué grupos compartían valores promedio semejantes y en cuáles se notaba un cambio más significativo (esto es una adaptación del método utilizado por Inegi en el estudio titulado “Cuantificando la clase media en México: un ejercicio exploratorio” (Inegi, 2013). Cabe señalar que, para llevar a cabo el agrupamiento en cinco estratos una vez ordenadas las familias de acuerdo al InSoc, se llevaron a cabo pruebas con distintos métodos, por ejemplo, el método de Dalenius y Hodges (Conapo, 2012a), y un método de distancias estadísticas; sin embargo, el método planteado por Inegi, en el estudio arriba señalado, es heurísticamente razonable (Tabla 4) y se apega más a lo esperado una vez que se exploran descripciones de los grupos obtenidos. De esta estratificación se tomaron los valores mínimo y máximo del InSoc para cada uno de los cinco estratos.
Tabla 4 Estratificación socioeconómica basada en cinco estratos (2010).
| Grupo | Valores InSoc | # familias | Porcentaje | IA | IID | IO | IOs | PE | IBR | Estratos | Estratos (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [0,0.21] | 391,549 | 1.4 | 0.019 | 0.342 | 0.001 | 0.000 | 0.375 | 0.323 | BAJO-bajo | 5.88 |
| 2 | [0.21,0.3] | 542,551 | 1.9 | 0.430 | 0.314 | 0.022 | 0.024 | 0.413 | 0.456 | ||
| 3 | [0.3,0.37] | 753,003 | 2.6 | 0.652 | 0.646 | 0.060 | 0.065 | 0.537 | 0.389 | ||
| 4 | [0.37,0.43] | 967,105 | 3.4 | 0.754 | 0.868 | 0.100 | 0.100 | 0.738 | 0.321 | BAJO-alto | 51.64 |
| 5 | [0.43,0.47] | 1,262,550 | 4.4 | 0.855 | 0.907 | 0.153 | 0.127 | 0.792 | 0.341 | ||
| 6 | [0.47,0.5] | 1,985,283 | 6.9 | 0.929 | 0.776 | 0.208 | 0.192 | 0.750 | 0.356 | ||
| 7 | [0.5,0.53] | 1,730,706 | 6.0 | 0.932 | 0.762 | 0.252 | 0.237 | 0.737 | 0.417 | ||
| 8 | [0.53,0.56] | 1,743,387 | 6.1 | 0.946 | 0.921 | 0.281 | 0.258 | 0.767 | 0.440 | ||
| 9 | [0.56,0.58] | 1,559,740 | 5.4 | 0.941 | 0.949 | 0.267 | 0.260 | 0.723 | 0.567 | ||
| 10 | [0.58,0.61] | 1,960,877 | 6.8 | 0.940 | 0.944 | 0.303 | 0.301 | 0.811 | 0.584 | ||
| 11 | [0.61,0.64] | 1,262,277 | 4.4 | 0.923 | 0.947 | 0.402 | 0.339 | 0.718 | 0.687 | ||
| 12 | [0.64,0.67] | 2,347,527 | 8.2 | 0.974 | 0.939 | 0.361 | 0.288 | 0.795 | 0.803 | ||
| 13 | [0.67,0.7] | 2,285,291 | 8.0 | 0.984 | 0.930 | 0.298 | 0.272 | 0.805 | 0.955 | MEDIO-bajo | 32.92 |
| 14 | [0.7,0.72] | 1,698,094 | 5.9 | 0.971 | 0.955 | 0.401 | 0.351 | 0.767 | 0.932 | ||
| 15 | [0.72,0.74] | 1,825,332 | 6.4 | 0.987 | 0.951 | 0.459 | 0.385 | 0.791 | 0.935 | ||
| 16 | [0.74,0.77] | 2,075,302 | 7.2 | 0.988 | 0.967 | 0.573 | 0.546 | 0.730 | 0.839 | ||
| 17 | [0.77,0.8] | 1,561,934 | 5.4 | 0.994 | 0.969 | 0.574 | 0.550 | 0.791 | 0.923 | ||
| 18 | [0.8,0.85] | 1,102,552 | 3.8 | 0.990 | 0.984 | 0.699 | 0.655 | 0.708 | 0.938 | MEDIO-alto | 6.96 |
| 19 | [0.85,0.92] | 895,979 | 3.1 | 0.994 | 0.988 | 0.804 | 0.704 | 0.743 | 0.995 | ||
| 20 | [0.92,1] | 745,141 | 2.6 | 1.000 | 1.000 | 0.992 | 0.981 | 0.650 | 1.000 | ALTO | 2.60 |
Fuente: elaboración propia.
Se consideró adecuado realizar una estratificación de cinco grupos (BAJO-bajo, BAJO -alto, MEDIO -bajo, MEDIO -alto y ALTO) para tener una suficiente diferenciación sin dificultar la interpretación. Para facilitar la comparación con otros estudios al respecto, la estratificación propuesta también se presenta en una escala de tres (Bajo, Medio y Alto), para esto se unieron los estratos BAJO-bajo y BAJO-alto para formar el estrato Bajo, el estrato MEDIO-bajo y MEDIO-alto para obtener el Medio y se conserva el estrato ALTO.
2.4. Estratificación con los microdatos del Censo de Población 1930
Es claro que en nuestro objetivo de comparar las estratificaciones de la población mexicana en 1930 y 2010, la estratificación inducida para 2010 es la misma que se utilizó para 1930, es decir, el rango del InSoc que pertenece a cada estrato en 2010 se usó igualmente en 1930.
Entonces, de acuerdo con los valores obtenidos, el estrato BAJO-bajo de 1930 estuvo formado por todas aquellas familias cuyo valor del InSoc estuvo en el intervalo de valores del InSoc del estrato BAJO-bajo para 2010, y así sucesivamente.
3. Resultados
Diversos estudios han caracterizado a la población de 2010 en estratos sociales y socioeconómicos, cada uno de estos estudios tiene un propósito diferente (estudios de mercado, cuantificaciones de clases medias, ubicación de poblaciones vulnerables, etcétera); sin embargo, nada se tiene con respecto a 1930 (debido a la reciente obtención de los microdatos). Por este motivo, los resultados que se presentarán en seguida toman relevancia, pues están basados en estimaciones de los microdatos de 1930.
Además, el índice construido para 1930 posteriormente se utilizó para calcularlo con los datos del 2010 y se realizó una comparación tomando como base 2010. Además, los resultados de la caracterización de la población de 2010 con el índice aquí construido, es similar con los obtenidos con la caracterización correspondiente realizada por el Inegi como veremos más adelante.
3.1. Estratificación con los microdatos del Censo de Población y Vivienda 2010
A continuación, se muestran los resultados obtenidos mediante el proceso de estratificación socioeconómica propuesto. En la Tabla 4 se presentan los 20 grupos formados al particionar el rango del InSoc, las primeras cuatro columnas son informativas de la situación de cada grupo, las siguientes seis columnas muestran los valores medios de cada indicador en ese grupo, las dos últimas columnas muestran la estratificación de cinco grupos realizada según los cambios observados en cada indicador. El degradado de colores es un apoyo visual para observar la separación de grupos. Por ejemplo, al menos cuatro de las medias por indicador de los primeros tres grupos están por debajo de 0.6 (color rojo), por lo que conforman el estrato BAJO-Bajo, sin embargo, a partir del grupo cuatro se nota una mejoría ya que sólo las medias de tres indicadores están por debajo de 0.6 y por esta razón se indica un corte o cambio de estrato. De acuerdo con la lógica anterior existiría una división entre los grupos 10 y 11, otra entre los grupos 12 y 13, una más entre los grupos 17 y 18 y la última entre los grupos 19 y 20. Lo anterior resultó en seis estratos y la escala que se planteó presentar es de cinco estratos por lo que fue necesario no tomar en cuenta una división correspondiente entre los grupos 10 y 11 basada en que la variable IBR, que es la que provoca los cortes 10 y 11 y 12 y 13, indica que hay mayor diferencia entre los grupos 12 y 13 (por lo tanto, más justificable el corte) que entre el 10 y el 11.
Una vez obtenida la gradación en cinco estratos, se obtuvo una de tres estratos útil para comparaciones con trabajos realizados anteriormente. En la Tabla 5 se presenta el resultado de la estratificación en el formato de tres estratos (Bajo, Medio y Alto).
Tabla 5 Estratificación socioeconómica basada en tres estratos (2010).
| InSoc | Estratificación | |||||
|---|---|---|---|---|---|---|
| Grupos | Intervalo | Estrato | Familias |
Porcentaje familias |
Personas |
Porcentaje personas |
| G1 - G12 | [0, 0.67] | BAJO | 16,506,555 | 57.52 | 64,885,150 | 57.95 |
| G13 - G19 | [0.67, 0.92] | MEDIO | 11,444,484 | 39.88 | 45,740,792 | 40.85 |
| G20 | [0.92, 1] | ALTO | 745,141 | 2.60 | 1,334,197 | 1.19 |
Fuente: elaboración propia.
3.2. Estratificación con los microdatos del Censo de Población 1930
Como se mencionó anteriormente, para 1930 se trasladaron las particiones establecidas en 2010, es decir, en 2010 el estrato BAJO-Bajo comprende el intervalo [0, 0.37) del InSoc, entonces en 1930 se abarcó ese mismo intervalo para formar el estrato BAJO-Bajo. La Tabla 6 muestra la estratificación de 1930 comparable con 2010.
Tabla 6 Estratificación socioeconómica basada en cinco y tres estratos (1930).
| Valores InSoc | Cinco Estratos | # familias |
Tres Estratos |
Estratos () | Personas | ||
|---|---|---|---|---|---|---|---|
| Número | |||||||
| [0,0.37] | BAJO-bajo | 2,022,515 | 75.13 | BAJO | 98.73 | 12,423,271 | 98.95 |
| [0.37,0.67] | BAJO-alto | 635,433 | 23.60 | ||||
| [0.67,0.8] | MEDIO-bajo | 30,868 | 1.15 | MEDIO | 1.25 | 129,440 | 1.03 |
| [0.8,0.92] | MEDIO-alto | 2,671 | 0.10 | ||||
| [0.92,1] | ALTO | 679 | 0.02 | ALTO | 0.02 | 2,210 | 0.02 |
Fuente: elaboración propia.
La Tabla 7 muestra los resultados (por familia) obtenidos para 1930 y para 2010 en el formato de tres estratos; asimismo, se muestra una comparación con la medición de la clase media realizada por Inegi (2013), obtenida por una vía completamente distinta.
Tabla 7 Comparación de los estratos socioeconómicos de 1930 contra 2010 a nivel familia.
| Microdatos 1930 | Microdatos 2010 | ||
|---|---|---|---|
| Estrato | Estrat. InSoc () | Estrat. InSoc () | Estrat. Inegi () |
| Bajo | 98.7 | 57.52 | 55.08 |
| Medio | 1.25 | 39.88 | 42.42 |
| Alto | 0.03 | 2.6 | 2.5 |
Fuente: elaboración propia.
Así pues, para 1930 el estrato alto representaba 0.03 de las familias, para 2010 este porcentaje aumentó a 2.6. Sin embargo, el cambio más sobresaliente se presentó en los estratos Medio y Bajo, en 1930 el estrato Bajo era de 98.7 y el Medio de 1.25, mientras que en 2010 el estrato Bajo constituía 57.52 y el estrato Medio incrementó a 39.88 por ciento.
Respecto a la comparación contra la estratificación propuesta por Inegi para 2010, el estrato alto se diferencia en 0.1, el estrato medio en 2.54 y el estrato bajo en 2.44 por ciento.
Utilizando como punto de referencia los resultados de la estratificación propuesta por Inegi, que a su vez son semejantes a los obtenidos por el Banco Mundial en 2013 (Inegi, 2013), se puede ver que tanto la metodología, como la estratificación propuesta, generan resultados congruentes. Así pues, dado que las variables seleccionadas para la construcción del índice pueden ser obtenidas tanto de los datos de 1930 como de 2010, es razonable (y válido) utilizar la metodología sobre los datos de 1930 y obtener una comparación legítima.
3.3. Índice de estratificación socioeconómica a nivel estatal
Se presenta una comparación a nivel estatal utilizando el InSoc. Se muestra primeramente el mapa de 1930 (Mapa 1), la escala de colores es un degradado basado sólo en los valores de ese año. En este caso el valor mayor es 0.36 (Sonora) al que se le asignó el color verde y el menor valor es de 0.22 (Guerrero) al que se le asignó el color rojo. Los mayores valores estatales del InSoc se concentraban en el norte del país mientras que los valores más bajos estaban en la región sur-sureste (Chiapas, Guerrero y Oaxaca).
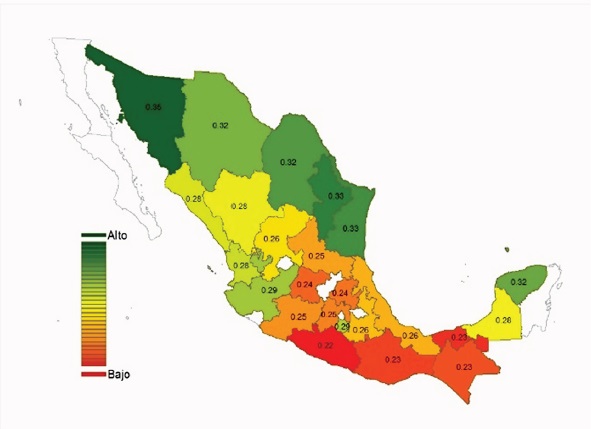
Fuente: elaboración propia.
Nota: Los estados que aparecen en blanco no cuentan con suficiente muestra para ser estimados.
Para mayores referencias consultar a Zamudio-Sánchez et al. (2015).
Mapa 1 Índice de estratificación socioeconómica a nivel estatal para 1930.
De igual manera se presenta el Mapa 2 con los datos de 2010, en el que podemos observar cambios tanto en el ordenamiento de los estados como en el aumento del InSoc en cada uno de ellos. Al comparar ambos mapas se pueden observar ambos cambios mencionados, por ejemplo, el estado de Zacatecas, en 1930 es de color amarillo y en 2010 su color tiende al rojo, esto no quiere decir que las condiciones de Zacatecas hayan empeorado respecto a sí mismo, de hecho, el InSoc de este estado en 1930 fue de 0.26 y en 2010 de 0.56; no obstante que su color se torne a rojo quiere decir que en 1930 el estado de Zacatecas tenía mejor condición socioeconómica con respecto a los demás estados que en 2010.
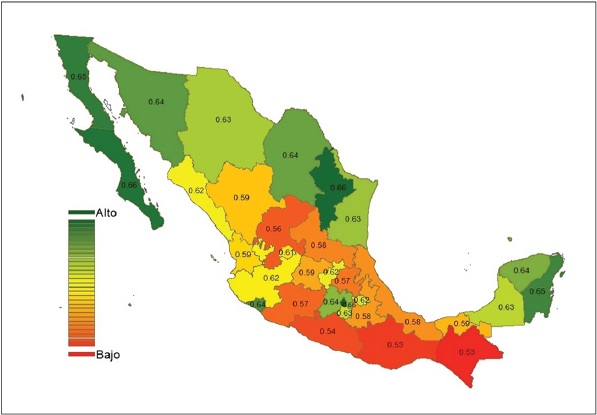
Fuente: elaboración propia.
Mapa 2 Índice de estratificación socioeconómica a nivel estatal para 2010.
Por otro lado, es notorio que los estados de la región sur-sureste se mantienen con los índices más bajos después de 80 años, mientras que los estados del norte continúan con los índices más altos.
Conclusiones
A partir de los diversos estudios revisados sobre el tema y haciendo uso del Proceso Jerárquico Analítico, se construyó un Índice de Estratificación Socioeconómica (InSoc), involucrando aspectos como la ocupación, la educación, los ingresos y el capital social (los últimos dos de cierta manera), que hace posible comparar la situación socioeconómica de 1930 con la de 2010.
De acuerdo con el estudio aquí realizado, desde 1930 hasta 2010 la población mexicana registró un avance sustancial en la composición de sus estratos socioeconómicos (principalmente un aumento del estrato medio), esto significa que ha mejorado la calidad de vida de un gran sector de la población. Aun así, más de la mitad de la población mexicana en 2010 se ubica dentro del estrato bajo, lo que representa un reto para mejorar las condiciones socioeconómicas de dicha población.
De igual manera, utilizando la escala de cinco estratos, podemos darnos cuenta de las precarias condiciones de las familias en 1930, producto de los conflictos sociales y del desarrollo de esa época, pues más de 75 de las familias mexicanas se encontraban en el estrato más bajo. Sin embargo, esto también nos habla de un problema más profundo, pues en 2010 seguía existiendo un porcentaje de la población (5.88) que vivía en condiciones similares a las peores condiciones del periodo posrevolucionario.
Con respecto a la metodología basada en el Proceso Jerárquico Analítico, utilizada para llevar a cabo la estratificación socioeconómica tanto de 1930 como de 2010, ésta permitió una adecuada clasificación, con grupos bien diferenciados entre sí (estrato Bajo 57.5, Medio 39.9 y Alto 2.6), respecto a sus características sociales y demográficas. Lo anterior se manifiesta dado que, al validar los resultados obtenidos en 2010 con el trabajo realizado por Inegi para este mismo año (que utilizando el método de conglomerados obtuvo para el estrato Bajo 55.1, el Medio 42.4 y el Alto 2.5), se observa una congruencia significativa.
De igual manera, mediante una descripción de los estratos obtenidos para 2010 con base en características que no fueron incluidas en el InSoc (Anexo 1), se corrobora su eficacia ya que cada estrato guarda una estrecha relación con lo que se esperaría encontrar (respecto a los otros estratos). Esto se observa claramente en la evaluación del porcentaje de personas que reciben apoyo de algún programa gubernamental, en donde la población beneficiada es porcentualmente mayor conforme el estrato es más bajo y disminuye conforme el estrato es más alto, lo cual pone de manifiesto que la clasificación obtenida tiene concordancia con los diversos estudios utilizados para crear las políticas públicas que generan dichos apoyos.
Otra comparación para validar los resultados del InSoc se realizó contra los resultados del Índice de Marginación de Conapo a nivel estatal (Anexo 2). Considerando que los ordenamientos se hicieron de modo que la posición 1 es la peor condición y la posición 32 es la mejor condición (lo cual es congruente con marginación, pero no con desarrollo socioeconómico), y que se tiene una asociación positiva entre la marginación y el InSoc (en una regresión lineal simple entre ambas se tiene una pendiente positiva y una R 2 = 0.6918), se tiene que a mayor marginación está asociado un menor desarrollo socioeconómico, como heurísticamente es esperado. De los 32 estados, 25 guardan una relación muy estrecha con la relación antes descrita y sólo siete escapan a ella.
De un análisis más detallado se puede apreciar que la variable Residencias en Condiciones Inadecuadas, que considera el Índice de Marginación pero que no encuentra correspondencia con las usadas en el InSoc, es la que ocasiona las disparidades en las clasificaciones, por marginación o por el InSoc, de estos siete estados. Dadas las restricciones impuestas por la información recopilada en 1930, esta aproximación en la relación del InSoc con el Índice de Marginación puede considerarse aceptable.
Si bien es cierto que no deja de haber cierta subjetividad en las ponderaciones que se obtienen utilizando el Proceso Jerárquico Analítico, los resultados aquí obtenidos muestran una congruencia significativa. Además, dado el carácter básico de las variables utilizadas para la construcción del índice, éste es idóneo para calcularse con datos de 1930 y llevar a cabo comparaciones válidas, ya que otras estratificaciones (como los Niveles Socioeconómicos AMAI, el estratificador Inegi, etcétera) utilizan datos más específicos con los que no se cuentan o inclusive no fueron colectados en esa época (como el ingreso, la infraestructura del hogar, los servicios, etcétera). Cabe resaltar que el presente trabajo es el primero realizado sobre estratificación socioeconómica con datos de 1930, lo que representa un avance no sólo en el acervo de estudios sociales en México, sino también en estudios de carácter histórico.
Otra de las bondades de la metodología propuesta es la posibilidad de desarrollar otras estratificaciones sociales y socioeconómicas mediante el ajuste de las ponderaciones del índice e incluso introduciendo variables distintas a las utilizadas (justificadamente), de lo que se sigue que la estratificación presentada en este trabajo es pertinente más no es única. Se debe tomar en cuenta que cualquier modificación que pretenda ser comparable con 1930 debe tomar como base las variables con las que se cuentan para ese año.
Este trabajo puede ser un punto de partida interesante y válido para medir y cuantificar el avance que se ha tenido en cuanto a la estructura social en México. Incluso se puede pensar en utilizar las bases de microdatos con las que cuenta el Inegi (sólo se cuenta con microdatos a partir de 1990) para estructurar una serie histórica reciente (1990-2010) que proporcione información acerca de los tiempos donde se tuvieron los mayores cambios y determinar buenas o malas políticas con mayor certeza.

