











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Introducción
En la actualidad, en el área de los negocios así como en la industria y el gobierno, se ven obligados a contar con procesos productivos eficientes para generar productos de alta calidad, entregados a tiempo y al menor costo posible para mantenerse en el mercado competitivo. Para lograr lo anterior, existen diferentes alternativas en donde una de ellas es experimentar directamente en el sistema real, lo cual genera costos muy elevados (Ortíz et al., 2006). Pero existe otra alternativa en la cual se reemplaza el sistema real por otro sistema, que en la mayoría de los casos es una versión simplificada del mismo, este proceso de experimentar con un modelo se denomina simulación, mientras que el proceso de diseñar el plan de experimentación para adoptar la mejor decisión se denomina optimización, pero si el plan de experimentación se lleva a cabo con el solo objeto de aprender a conducir el sistema, entonces se denomina entrenamiento o capacitación (Tarifa, 2005).
Según Gottfried la simulación se considera como una actividad mediante la cual se pueden extraer conclusiones acerca del comportamiento de un sistema, estudiando el comportamiento de un modelo, cuyas relaciones de causa y efecto son las mismas (o similares) a las del sistema original (Inzunsa, 2013), esta técnica se ha implementado en la combinación de la estrategia Lean & Green aplicada a un sistema de producción de piezas en el sector automotriz (Diaz et al., 2013), también para mejorar la productividad, logrando identificar y disminuir los cuellos de botella en las líneas de producción de una fábrica de pintura (Zahraee et al., 2014), entre otros.
En este trabajo se utilizó la simulación, logrando diseñar un modelo del sistema real de una empresa de manufactura que incluye parámetros configurables, permitiendo realizar experimentos para analizar y evaluar diferentes estrategias referentes al problema del incumplimiento de la demanda (Ingalls, 2011; Shannon, 2003; Carson II, 2005).
Definición del problema
Se analizó un sistema de ensamblaje en una empresa localizada en Escobedo, N.L., que se dedica al ensamble de ejes para vehículos de transporte pesado (Figura 1) para el ensamblaje de los ejes traseros, se tienen dos líneas en las cuales hay tres estaciones; para cada estación se cuenta con dos personas para el ensamblaje, una de lado derecho y la otra de lado izquierdo, una vez que el eje de cualquiera de las dos líneas sea liberado, se coloca en un rack o caja para su embarque, después se transportan a un almacén para su entrega.
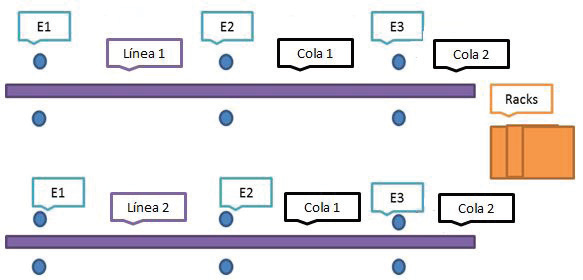
Cuando la producción se encuentra en proceso, en algunas ocasiones se detiene generando tiempo muerto o de ocio entre estaciones, tanto de la línea uno como de la línea dos, si las cajas se acaban o tardan en empaquetar, el proceso de producción se detiene y se generará tiempo muerto en la última estación, al igual que si hay cinco ejes esperando dicha estación, se detiene la producción para la estación anterior, generando en consecuencia un tiempo de entrega no satisfactorio para el cliente.
El alcance de esta investigación es generar un modelo de simulación que abarque la determinación del número de cajas óptimo para cumplir con la demanda requerida por parte de la empresa, sin incluir el inventario de las piezas debido a que no se tuvo disponible dicha información.
Objetivos
Los objetivos específicos de este trabajo son los siguientes:
Construir un modelo que represente al sistema real con el objetivo de experimentar con él.
Desarrollar un simulador computacional del modelo.
Experimentar con el simulador para lograr una adecuada toma de decisiones en la optimización del proceso de la empresa.
En la siguiente sección se describe la metodología que se llevó a cabo para generar diversas simulaciones sobre el modelo desarrollado, logrando realizar un análisis de los resultados a partir de los cuales sea posible generar una propuesta que optimice la producción de ejes en la empresa.
Metodología
Las metodología aplicada en el desarrollo de investigación está dividida en siete fases, en la primera se realiza la formulación del problema al que se enfrenta la empresa de manufactura, la segunda consiste en la definición de los parámetros y variables para generar un modelo de simulación del proceso llevado a cabo por dicha empresa, la tercera es el proceso de la recopilación y análisis de los datos para identificar una distribución que se ajuste a dichos datos, la cuarta consiste en formular el modelo de simulación, la quinta fase consiste en trasladar el modelo a un lenguaje de programación, la sexta es la simulación del modelo para obtener resultados y observar su comportamiento y por último la validación del modelo para comprobar si se ajusta a sistema real.
Formulación de problema
Uno de los mayores problemas de la empresa de manufactura, es el incumplimiento de las entregas de los racks, y para mejorar esto, se tiene que el propósito de esta investigación es estimar la cantidad adecuada de racks que debe existir para satisfacer la demanda requerida por semana, logrando reducir pérdidas por la entrega fuera de tiempo.
Definición de elementos del modelo
Componentes y parámetros
En este punto se definen los componentes que consisten en los racks o cajas y los ejes armados, líneas de ensamblaje de las cuales hay 2 estaciones donde cuentan con dos operadores, los ejes llegan de manera constante; los parámetros que consisten en los tiempos límites a simular, el tiempo estimado para que llegue un nuevo lote de cajas y el máximo valor a tomar de los valores aleatorios con una distribución definida.
Variables
Se definen las variables del sistema, en las cuales las unidades de tiempo están caracterizadas en minutos para las dos líneas de ensamblaje i = 1, 2 con cada una de sus estaciones j = 2, 3:
Variables exógenas: conocidas también como variables de entrada (Shannon, 2003), en donde LCajas = número de cajas iniciales y Ts(ij) = tiempos de servicio en cada línea con sus estaciones.
Variables de estado: son variables que solamente cambian con el tiempo (Flores, 2011), están compuestas por un Reloj = contador de tiempo de la simulación, Delta = intervalo de revisión de la simulación, TC = contador de tiempo para la llegada de un nuevo lote de cajas, Ret = booleano que cambia cuando ya no hay cajas disponibles, NumRet = número de veces que el proceso se retuvo por falta de cajas, Fn(i) = número de ejes terminados y empaquetados en cada una de las líneas, Na(ij) = número de ejes atendidos en cada línea con sus estaciones, To(ij) = tiempo de ocio en cada línea con sus estaciones y Cola(i) = número de ejes que se armaron en la segunda estación y están en espera de la siguiente en cada línea de ensamblaje.
Variables endógenas: conocidas también como variables de salida y son útiles en la toma de decisiones (Tarifa, 2005), que comprenden NTa(ij) = número total de ejes atendidos en cada línea con sus estaciones, TTo(ij) = tiempo total de ocio en cada línea con sus estaciones, FTn(i) = número total de ejes terminados y empaquetados en cada una de las líneas y NumRet = número total de veces que el proceso se retuvo por falta de cajas.
Recopilación y análisis de datos
Recopilación
La información fue recopilada de datos históricos proporcionados por la empresa en un documento con formato de tabla (Excel), en el que se incluía la información acerca de la hora de inicio y fin del proceso en cada estación, logrando así obtener la cantidad de minutos que tardó una estación en ensamblar una parte del eje, generando una lista de 200 valores para cada una de las estaciones.
Análisis de datos
Una vez que se obtienen las listas de los tiempos con base en los datos históricos, se utilizó una prueba conocida como “Test de Kolmogorov-Smirnov” para comparar 2 distribuciones empíricas (Arriaza et al., 2008) y obtener la distribución que mejor se ajusta a las listas de datos, donde se tiene
Sea Sm(x) la distribución acumulativa de una muestra de tamaño “m” y Sn(x) la distribución acumulativa de otra muestra de tamaño “n”, entonces se tiene representado el test de Kolmogorov-Smirnov como (Pei et al., 2010):
Con base en el cálculo del p-valor considerada una prueba de bondad y ajuste que permite declarar que tan significativa es una prueba (Romero, 2012):
Si el p - valor < 0.001, significa que la hipótesis nula no es creíble y por lo tanto se descarta.
Si 0.001 < p-valor < 0.05, significa que hay grandes motivos en contra de la hipótesis nula, por lo que se rechaza o no depende del valor de α que le hayamos asignado.
Si el p - valor > 0.05, significa que no existen motivos suficientes para descartar la hipótesis nula, por ende se toma como cierta.
Para este trabajo, se utilizó una interfaz gráfica para acceder a las características de un paquete estadístico conocido como “R” (Dodero et al., 2014), en el cual se compararon las distribuciones de Poisson, Normal, Uniforme, Exponencial, Geométrica con la lista de datos de las estaciones y de las cajas.
Se llegó a la conclusión, de acuerdo con el análisis de los resultados, que la distribución que mejor se ajusta a la lista de datos de la estación dos es la distribución de Poisson (Figura 2) en donde su p - valor= 0.4653 > 0.05, de la misma manera para la estación 3 (Figura 3) en donde su



Formulación de modelo
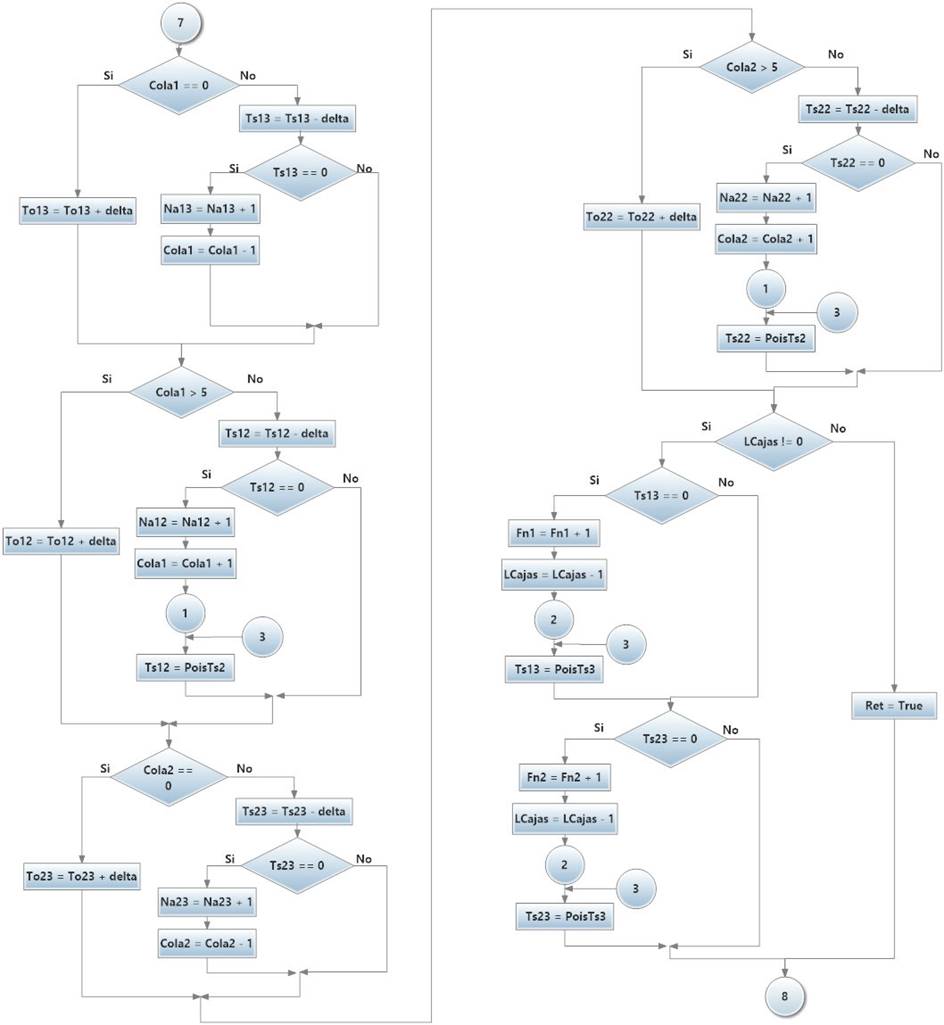
Se generó un modelo representado en un diagrama de flujo, el cual se dividió en 3 secciones: en la primera, se incluyen los generadores de valores de variables aleatorias con distribución de Poisson y Gaussiana Rectificada, en la segunda se declaran las variables a partir de las cuales se solicitan los valores de las variables aleatorias, donde se muestran los procesos que se generan cuando se termina el tiempo estimado para la próxima entrega de cajas, o si las cajas ya no se encuentran disponibles, así como el proceso de finalización de la solución cuando el tiempo estimado de producción termina, mostrando las variables requeridas para su observación, comparación y análisis. En la tercera sección (Figura 5) se muestran los procesos de producción para la estación dos cuando el tiempo de ensamblaje termina y se lleva a la fila de espera de la siguiente estación; si todavía hay espacio disponible y, lo que pasaría si no hay espacio en dicha fila, finalmente para la estación tres se muestra el proceso cuando hay cajas disponibles y se empaqueta el eje terminado y qué pasaría si dichas cajas ya no se encuentran disponibles, para ambas estaciones.
Traslación y simulación del modelo
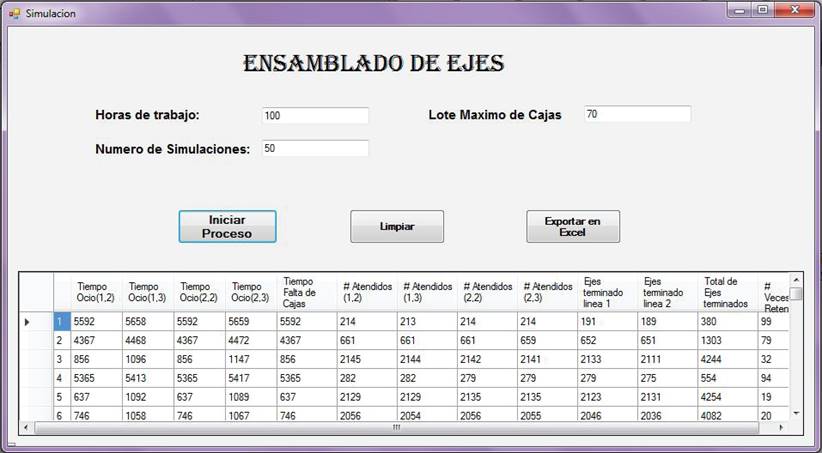
Se decidió desarrollar un programa de simulación en lugar de utilizar un software existente, ya que se tiene la ventaja de adecuarse al problema y no viceversa, es decir, no generar cambios o limitar a las variables y parámetros para que la herramienta funcione; el modelo formulado se trasladó a un lenguaje de programación simple, moderno y orientado a objetos denominado C# (ECMA, 2006), se generó el diseño de una interfaz (Figura 6), en el cual sus valores de entrada son el número de horas de trabajo que se realizan, el número de iteraciones que se desean analizar y el número máximo de cajas cuando llega un nuevo lote y se obtiene como resultado el tiempo total de ocio y la cantidad de veces que se retuvo el proceso por falta de cajas, los tiempos totales de ocio y el número de ejes atendidos en las líneas con sus respectivas estaciones, así como el número de ejes terminados y empaquetados en cada línea.
Validación del modelo de simulación
Una vez trasladado el modelo, se generó un análisis estadístico para determinar el número de réplicas necesarias usando el método de estimación de la media de población, para diferentes llegadas de cajas, como se muestra en la Tabla 1, en donde se estableció un error deseado 90 cajas, es decir, un porcentaje de 2.5% para un máximo de 70, 3.2% para 60, 3.4% para 55, 3.5% para 50 y 4.7% para 40, con un nivel de confianza de 95%:
Tabla 1 Determinación del número de réplicas para cada máximo de cajas
| Max. Cajas | 70 | 60 | 55 | 50 | 40 |
|---|---|---|---|---|---|
| S (n´) | 567.00 | 649.95 | 479.91 | 390.87 | 669.41 |
| n | 121 | 138 | 99 | 86 | 167 |
Asimismo, para validar el modelo se realizaron corridas con los parámetros originales del modelo, generando una lista de 100 datos y comparándolas con la misma cantidad de datos de la producción generada semanalmente por la empresa, usando el contraste T de Student para dos muestras independientes con un intervalo de confianza de 95%, en R (Figura 7), permitiendo validar el modelo debido a que su p - valor = 0.483 > 0.05.

Resultados de cinco días laborales
La Tabla 2 muestra las medias de doscientos resultados para una semana laboral, en los cuales, se toman en cuenta la hora de comida y una aproximación de veinte minutos de preparación antes de iniciar el turno laboral, las variables endógenas que se muestran son:
To(ij), tiempo total de ocio de la línea i de la estación j.
ToCajas, tiempo total de ocio por falta de cajas.
Na(ij), número total de ejes atendidos en la línea i de la estación j.
Fn(x), número total de ejes liberados y colocados en un rack o caja para su embarque de la línea x.
Total Ejes, total de los ejes liberados y colocados en un rack o caja para su embarque.
Retenidos, Número total de veces que se retiene por falta de Cajas.
Tabla 2 Resultados de la experimentación en el simulador para una semana laboral
| Max. Cajas | 40 | 50 | 55 | 60 | 70 |
|---|---|---|---|---|---|
| To12 | 3795 | 2913 | 2516 | 2233 | 1532 |
| To13 | 3969 | 3118 | 2729 | 2480 | 1786 |
| To22 | 3795 | 2913 | 2516 | 2233 | 1532 |
| To23 | 4015 | 3164 | 2767 | 2514 | 1810 |
| ToCajas | 3795 | 2913 | 2516 | 2233 | 1532 |
| Na12 | 873 | 1226 | 1387 | 1508 | 1784 |
| Na13 | 873 | 1225 | 1386 | 1507 | 1782 |
| Na22 | 874 | 1227 | 1388 | 1508 | 1785 |
| Na23 | 873 | 1226 | 1387 | 1507 | 1783 |
| Fn1 | 841 | 1199 | 1363 | 1487 | 1768 |
| Fn2 | 818 | 1177 | 1343 | 1469 | 1755 |
| Total Ejes | 1659 | 2375 | 2706 | 2956 | 3522 |
| Retenidos | 89 | 74 | 65 | 58 | 40 |
En la Tabla 3 se exponen las medias de las diferencias entre los tiempos de ocio por falta de cajas con los tiempos de ocio de cada una de las estaciones, es decir, los tiempos de ocio por cada estación, aun habiendo cajas disponibles.
Comparación de los resultados con la demanda total
En la Tabla 4 se generó una comparación para obtener las diferencias entre la suma total de la lista de los resultados obtenidos en la simulación y la lista de la demanda requerida para doscientas semanas laborales, en donde la suma total de la demanda requerida es de 540,176 racks.
Tabla 4: Suma total de las 200 simulaciones y la diferencia entre la suma total de los resultados obtenidos y la demanda total requerida
| Máximo de cajas | 70 | 60 | 55 | 50 | 40 |
|---|---|---|---|---|---|
| Total de ejes | 704454 | 591117 | 541238 | 475090 | 331829 |
| Dif. entre la producción-demanda requerida | 164278 | 50941 | 1062 | -65086 | -208347 |
Cuando los valores de las “diferencias entre la producción-demanda requerida” son positivos, significa que el número de ejes terminados y colocados en racks sobran y para el caso contrario, es decir cuando es negativo, faltan.
Se observó que para el caso donde el parámetro es de un máximo de 55 cajas la suma total para la demanda cumplida es de 541238, generando una diferencia total de mil sesenta y dos (1062) de racks extras, es decir, en promedio se generan aproximadamente entre cinco o seis racks adicionales para cada semana laboral, también se muestra que entre más cajas lleguen por hora, los tiempos de ocio y la retención de las máquinas disminuye considerablemente, cuando se encuentran cajas disponibles (Figura 8) o cuando no hay cajas disponibles (Figura 9), de la misma manera se ensamblan y liberan más ejes para ser empaquetados y colocados en racks (Figura 10), ayudando a la toma de decisiones para pedidos específicos.
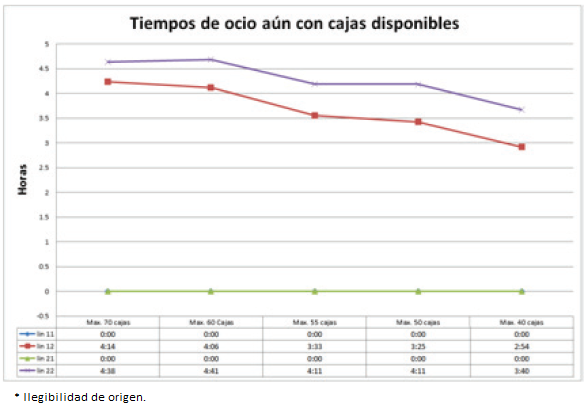
Figura 8 Media de los tiempos de ocio aun con cajas disponibles para las diferentes estaciones con su máximo número de cajas
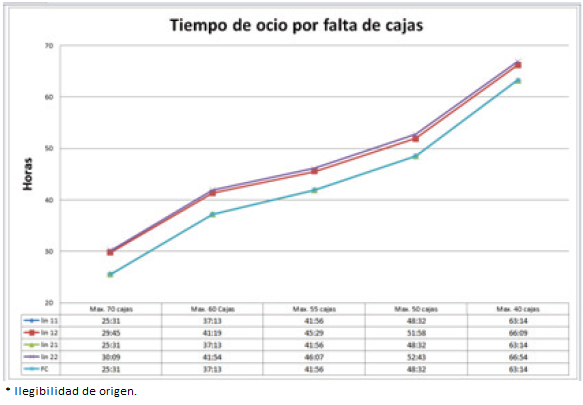
Figura 9 Media de los tiempos de ocio sin cajas disponibles para las diferentes estaciones con su máximo número de cajas
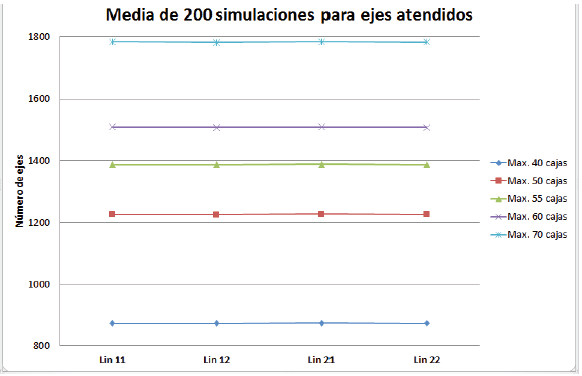
Conclusiones
Con la información proporcionada por parte de la empresa, la cual se integró por: las listas de tiempos de ejecuciones para cada una de las estaciones, los tiempos de llegada de un nuevo lote de cajas, la organización de las líneas de ensamblaje y el historial de pedidos, fue posible definir los componentes, variables (endógenas, exógenas y de estado) y parámetros del modelo, así como identificar a qué distribución se ajustan los datos, estos elementos en conjunto contribuyeron a la creación de un modelo que representa adecuadamente al sistema real; posteriormente se trasladó a un lenguaje de programación para experimentar con este simulador y generar resultados para el estudio.
Con base en los resultados de las soluciones de simulación, fue posible determinar los casos en donde es conveniente solicitar un cierto número de cajas para un tiempo específico, generando mejores resultados y más eficiencia por parte de la empresa, por lo que se concluye que la simulación es útil para optimizar el proceso de manufactura de la empresa, ya que en el caso de la lista de datos de la demanda requerida semanalmente, esta se cumple cuando llegan un máximo de 55 cajas por hora, generando un exceso de producción mínimo (Tabla 4).
Por otra parte, se espera que la información de los inventarios sobre las piezas para armar los ejes sea proporcionada, ya que con base en la observación y comentarios por parte de la empresa de manufactura, la problemática abarcaba mucho más que solo la falta de cajas, por lo que se deben estudiar otros casos, uno de ellos es cuando las piezas se terminan y se tiene que esperar un tiempo para solicitar más, lo cual genera retrasos en los pedidos. Al definir un modelo de simulación para los inventarios, se posibilitaría estimar un tiempo aproximado de solicitud para nuevas piezas, al complementar el modelo de este estudio con el nuevo modelo, se estima disminuir los tiempos de ocio para las estaciones, lo que genera simulaciones más detalladas y cercanas al sistema real, planteando una nueva pregunta de investigación: ¿Es posible eliminar un turno, agregando unas horas extras a los otros dos turnos, disminuyendo así considerablemente los costos de producción?

