










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería, investigación y tecnología
versión On-line ISSN 2594-0732versión impresa ISSN 1405-7743
Ing. invest. y tecnol. vol.16 no.4 Ciudad de México oct./dic. 2015
Aplicación de la distribución de probabilidades no acotada del Sistema Johnson para estimación de crecientes
Application of the Unbounded Probability Distribution of the Johnson System for Floods Estimation
Campos-Aranda Daniel Francisco
Profesor Jubilado de la Universidad Autónoma de San Luis Potosí. Correo: campos_aranda@hotmail.com
Recibido: mayo de 2014.
Aceptado: julio de 2014.
Resumen
Las crecientes de diseño son una estimación fundamental en el dimensionamiento de las nuevas obras hidráulicas, así como en la revisión de su seguridad hidrológica en las ya existentes. El método más confiable para su obtención consiste en ajustar un modelo probabilístico al registro disponible de gastos máximos anuales, para estimar sus magnitudes asociadas a ciertos periodos de retorno. Como tal modelo no es conocido, se prueban varios y se selecciona el más adecuado según un índice estadístico, comúnmente el error estándar de ajuste. Varias distribuciones de probabilidad han demostrado versatilidad y consistencia de resultados al procesar registros de crecientes y por ello, su aplicación se ha establecido como norma o precepto. El Sistema Johnson tiene tres familias de distribuciones, una de ellas es el modelo Log–Normal de tres parámetros de ajuste, que además es la frontera entre las distribuciones acotadas y aquéllas sin límite superior. Estas familias de distribuciones tienen cuatro parámetros de ajuste y convergen a la distribución Normal estándar, de manera que sus predicciones se obtienen con tal modelo. Habiéndose contrastado las tres distribuciones de probabilidad establecidas bajo precepto, en 31 registros históricos de eventos hidrológicos, se aplica ahora el Sistema Johnson a tales datos. Se comparan los resultados de la distribución no acotada del Sistema Johnson (SJU), con los óptimos procedentes de las tres distribuciones. Se encontró que las predicciones de la distribución SJU son similares a las obtenidas con los otros modelos, en los periodos de retorno bajos (< 50 años) y en general resultan del mismo orden de magnitud en los intervalos de recurrencia elevados (> 1000 años). Debido a su respaldo teórico, el modelo SJU se recomienda en la estimación de crecientes.
Descriptores: distribuciones Log–Pearson tipo III, general de valores extremos y logística generalizada, percentiles, error estándar de ajuste, algoritmo de Rosenbrock.
Abstract
Floods designs constitute a key to estimate the sizing of new water works and to review the hydrological security of existing ones. The most reliable method for estimating their magnitudes associated with certain return periods is to fit a probabilistic model to available records of maximum annual flows. Since such model is at first unknown, several models need to be tested in order to select the most appropriate one according to an arbitrary statistical index, commonly the standard error of fit. Several probability distributions have shown versatility and consistency of results when processing floods records and therefore, its application has been established as a norm or precept. The Johnson System has three families of distributions, one of which is the Log–Normal model with three parameters of fit, which is also the border between the bounded distributions and those with no upper limit. These families of distributions have four adjustment parameters and converge to the standard normal distribution, so that their predictions are obtained with such a model. Having contrasted the three probability distributions established by precept in 31 historical records of hydrological events, the Johnson system is applied to such data. The results of the unbounded distribution of the Johnson system (SJU) are compared to the optimal results from the three distributions. It was found that the predictions of the SJU distribution are similar to those obtained with the other models in the low return periods (< 50 years) and in general are of the same order of magnitude in higher recurrence intervals (> 1000 years). Because of its theoretical support, the SJU model is recommended in flood estimation.
Keywords: distributions Log–Pearson type III, General Extreme Values, Generalized Logistic, percentiles, standard error of fit, Rosenbrock algorithm.
Introducción
El cambio climático y sus consecuencias
El cambio climático (CC) inminente está generando condiciones meteorológicas más extremas: tormentas severas, periodos lluviosos con mayor duración y contrariamente, sequías más prolongadas. Tales condiciones producirán, por una parte, crecientes o gastos máximos más grandes y repentinos y por la otra, mayor erosión de los suelos, debido al poder erosivo de la lluvia y a la menor densidad de cobertura vegetal (Martínez y Aguilar, 2008; Madsen et al., 2013).
Debido a que las crecientes o gastos de diseño son la estimación fundamental de todo estudio hidrológico tendiente a dimensionar la infraestructura hidráulica o a revisar su seguridad, para que no se encuentre en peligro ante los eventos extremos de la naturaleza, surge entonces esta pregunta básica: ¿Cómo mejorar la estimación del gasto de diseño de una obra hidráulica frente al CC?
Acciones necesarias ante cambio climático En términos generales, ante el CC deben realizarse las siguientes tres acciones:
Primera: por ningún motivo suspender las mediciones hidrométricas y climatológicas, pues si estas eran importantes en el pasado para contar con registros cada vez mayores y con ello incrementar la confiabilidad de los resultados de su procesamiento estadístico, ahora resulta vital incorporar en estos los valores extremos recientes, de manera que las actualizaciones de los estudios hidrológicos reflejen realmente las nuevas condiciones o tendencias climáticas.
Segunda: debido a que las condiciones meteorológicas están cambiando y por consecuencia las climáticas, actualmente es más imperativo ampliar los puntos de medición para disponer de valores de apoyo reales en el transporte de información de sitios con registros amplios a estas nuevas localidades con escasez de datos, así como para poder realizar en el futuro análisis regionales más confiables.
Las dos acciones anteriores conciernen a la disponibilidad de datos y esta tercera está asociada con su manejo o procesamiento, integrando tres vertientes principales:
1) Con la idea de contrarrestar los efectos del CC, se sugiere aumentar el grado de confiabilidad de las estimaciones hidrológicas, con base en el incremento del intervalo promedio de recurrencia de los eventos, denominado periodo de retorno en años.
2) Estimar con mayor precisión los eventos de diseño, a través de diversos modelos probabilísticos, por ejemplo, los establecidos bajo precepto y otros nuevos que tienen bases teóricas sólidas.
3) Análisis probabilísticos avanzados (El-Adlouni et al., 2007), que consideran que los datos no constituyen un proceso estocástico estacionario, debido a los efectos del CC.
Estimación probabilística de crecientes
Actualmente, el método más confiable para estimar los gastos de diseño en una determinada localidad de un río, consiste en procesar el registro disponible de gastos máximos anuales ajustándole un modelo probabilístico o distribución de probabilidades y con base en esta obtener estimaciones o predicciones asociadas a ciertas probabilidades de excedencia.
Una ventaja importante de la serie anual de máximos al estar integrada por eventos extremos anuales, se presenta al aplicar el concepto básico de probabilidad del evento A, definida como el cociente entre el número de casos favorables (ncf) a un evento y el número de casos posibles (ncp), por lo tanto, es un número en el intervalo de cero a uno; o bien, entre cero y 100 cuando se expresa en porcentaje. Entonces, si un evento hidrológico, igual o mayor que un cierto límite, ocurre una vez en promedio en un lapso de Tr años, el cociente 1/Tr corresponderá a su probabilidad de excedencia, ya que es el cociente entre el ncf y el ncp. Lo anterior define el concepto de período de retorno (Tr) o intervalo promedio de recurrencia en años, como el inverso de la probabilidad de excedencia.
El periodo de retorno (Tr) es una forma de expresar la probabilidad de excedencia, por ello se dice: el gasto de diseño de Tr = 20 años o de Tr = 1,000 años, en lugar de decir, los eventos cuyas probabilidades de excedencia son 5% y 0.1% en cada año. El periodo de retorno no significa que un evento de Tr años ocurrirá exactamente cada Tr años, sino que existe una probabilidad de 1/Tr para que tal evento ocurra por año.
Incertidumbre en el análisis probabilístico de crecientes
Este análisis es una estimación basada en información limitada. Por lo anterior, siempre existe incertidumbre en el gasto máximo calculado o en el periodo de retorno estimado. Las causas son la amplitud reducida de los registros de gasto máximo anual, lo cual origina errores de muestreo y los errores propios de su medición. Además, este análisis acepta que los datos siguen un determinado modelo probabilístico y si este no captura plenamente el comportamiento real de los datos, entonces un error de modelo también es fuente de incertidumbre (Kjeldsen et al., 2014).
Evolución del análisis probabilístico de datos hidrológicos
El análisis probabilístico de gastos máximos, lluvias extremas, niveles y vientos máximos comenzó a mediados del siglo pasado, utilizando distribuciones de probabilidad de dos y tres parámetros de ajuste. Al final de la década de los años setenta, ya existían tres modelos probabilísticos que se debían aplicar por norma: la distribución Log–Pearson tipo III (LP3) en USA, la distribución General de Valores Extremos (GVE) en Inglaterra y la distribución Pearson tipo III (P3) en China. A comienzos de este siglo, Inglaterra cambió su distribución establecida bajo precepto y ahora es la Logística Generalizada (LOG).
Es importante destacar que los modelos P3 y LP3 provienen del sistema más antiguo que incluye 12 familias de distribuciones de probabilidad, el cual fue creado por Karl Pearson a finales del siglo XIX (Kottegoda, 1980; Bobée y Ashkar, 1991). Shapiro (1998) indica que el sistema de la Lambda Generalizada es el más reciente que se ha propuesto (Ramberg et al., 1979) y aún está en desarrollo. Intermedios entre estos dos existen el sistema de Halphen generado a inicio de los años cuarenta (Perreault et al., 1999) y el sistema de Johnson creado por Johnson (1949), el cual se describe y contrasta en este trabajo.
Objetivo del trabajo
Habiéndose realizado contrastes de las distribuciones GVE, LP3 y LOG en un grupo de 31 registros históricos, se propone ahora describir con detalle el sistema Johnson (SJ) de tres familias de distribuciones de probabilidad y aplicarlas al mismo grupo de registros, para seleccionar la más adecuada a cada uno y comparar sus resultados con los mejores obtenidos con estos tres modelos probabilísticos, cuya aplicación se realiza bajo precepto. Este grupo de muestras de eventos máximos anuales de tipo hidrológico, la mayoría crecientes, tomados de textos y otros trabajos relevantes al análisis probabilístico en esta disciplina, tienen amplitudes que varían de 16 a 113 años; sus datos generales, parámetros estadísticos, momentos L y referencias se pueden obtener en Campos (2013).
Métodos aplicados
Conceptos teóricos del Sistema Johnson
El sistema tiene tres familias de distribuciones de probabilidad, las cuales se generan a través de una transformación específica a la variable normal estándar (z). Las familias se llamarán SJU, SJB y SJL; la última es la distribución Log-Normal de tres parámetros de ajuste, la cual ocupa un lugar central en el sistema Johnson y cuya variable (x) está definida en el intervalo de ε a ∞, siendo ε un parámetro de ubicación. Las otras dos distribuciones tienen cuatro parámetros de ajuste, la familia SJU no tiene intervalo o frontera, por ello su designación, la cual viene de unbounded range; en cambio, la familia SJB se define en el intervalo de ε a ε+η, siendo η un parámetro de escala y su designación deriva de bounded range. El sistema Johnson se genera con la ecuación general siguiente (Kottegoda, 1980; Slifker y Shapiro, 1980 ; Shapiro y Gross, 1981; Shapiro, 1998):

en donde, las funciones Ki se escogen para abarcar un gran número de formas posibles, las definidas por Johnson son las siguientes; para la familia SJU

para la familia SJB

y para la familia SJL

En la población de la variable original X , los parámetros ε y η rigen el extremo izquierdo y la escala, mientras que la forma de la distribución está gobernada por los parámetros δ y τ.
Selección de la familia Johnson a utilizar
El proceso de selección de la distribución de probabilidades que mejor se adapta o ajusta a los datos involucra la estimación de los percentiles correspondientes a 3z, z, –z y –3z, los cuales se designan como: X3z, Xz, X-z y X-3z. Después se evalúan los siguientes tres parámetros y el de selección PS (Slifker y Shapiro, 1980; Shapiro y Gross, 1981; Shapiro, 1998):




Si PS > 1 se escoge la distribución SJU, si PS < 1 se adopta la distribución SJB y si PS≅1 se selecciona la distribución SJL.
La estimación de los percentiles requiere la selección de un valor de z, la transformación de ±z y de ±3z a probabilidades Normales y de ahí a una estimación de la posición empírica (i) en la variable original X . En muestras de tamaño moderado, se utiliza comúnmente un valor de z menor de uno. Por ejemplo, adoptando un valor de z = 0.5483, se tiene que ±3 z = ±1.645, valores que definen los percentiles de 95% y 5% de probabilidad de no excedencia [F (·)] en la distribución Normal y las otras probabilidades relativas a ±z son 70.8% y 29.2%. Ahora, resolviendo la siguiente ecuación empírica se obtienen las posiciones buscadas (Shapiro, 1998)

en donde, nd es el tamaño de la muestra, con los datos ordenados de menor a mayor e i es el valor buscado del percentil X3z, Xz, X-z y X-3z. Lógicamente, habrá que interpolar entre la pareja de posiciones reales menor que i y mayor que esta. Usando z = 1.0 en muestras grandes (n > 1000), las probabilidades F(·) son 99.86%, 84.13%, 15.87% y 0.14% (Slifker y Shapiro, 1980). En muestras de tamaño moderado también se utilizó z = 0.524, generando las probabilidades siguientes: 94.2%, 70%, 30% y 5.8% ( Shapiro y Gross, 1981).
Cálculo de los parámetros de ajuste de la distribución SJU
En la distribución GVE cuando su parámetro de forma (k) resulta positivo se define como distribución de probabilidades más conveniente el modelo Weibull con límite superior y concavidad hacia abajo en el papel de probabilidad Gumbel-Powell. Lo anterior ocurrió únicamente en los registros números 16, 20, 24 y 29. Cuando k es positivo, pero cercano a cero, indica que el modelo más adecuado es la distribución Gumbel, que es una línea recta en el papel Gumbel-Powell.
Por otra parte, las distribuciones LP3 y LOG no resultan acotadas en registros de crecientes con datos dispersos (outliers) y por ello no es procedente utilizar en esta comparación del sistema Johnson , la familia SJB, que presenta un límite superior en ε+η. Tampoco se contrasta la familia SJL, pues la distribución Log-Normal se aplica de manera rutinaria en los análisis probabilísticos de crecientes (Kite, 1977; Stedinger et al., 1993; Rao y Hamed, 2000). Por lo anterior, únicamente se exponen las expresiones de cálculo de los cuatro parámetros de ajuste de la familia SJU (Slifker y Shapiro, 1980; Shapiro, 1998).
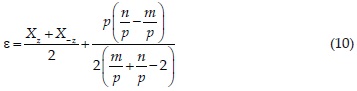
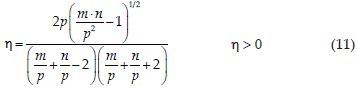

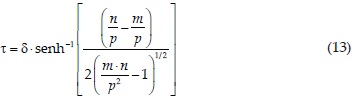
Las expresiones del arco coseno hiperbólico, del arco seno hiperbólico y del seno hiperbólico que será utilizada en la expresión de la solución inversa de la ecuación 1, son (Campos, 2003):
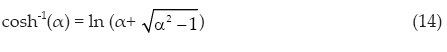
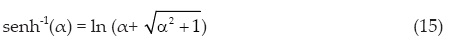

Cálculo del error estándar de ajuste
Este indicador de la calidad de ajuste que logra, con los datos del registro o muestra, la distribución que se prueba, se ha generalizado desde mediados de los años setenta y su expresión es la siguiente (Kite, 1977):

en donde, nd es el número de datos de la muestra, xi son los datos ordenados de menor a mayor  i, son los valores estimados con el modelo probabilístico que se prueba, para una probabilidad de no excedencia P(X < x) estimada con la fórmula de Weibull (Benson, 1962)
i, son los valores estimados con el modelo probabilístico que se prueba, para una probabilidad de no excedencia P(X < x) estimada con la fórmula de Weibull (Benson, 1962)

en la cual, m es el número de orden del dato, con 1 para el menor y nd para el mayor. Por último, np es el número de parámetros de ajuste, con tres para las distribuciones GVE, LP3 y LOG, y cuatro para la distribución SJU. La solución inversa de la ecuación 1 para la distribución SJU es la siguiente (Slifker y Shapiro, 1980)

La probabilidad (P) estimada con la ecuación 18 se toma en cuenta para el cálculo de la variable normal estándar (z), en cuya estimación se utilizó el algoritmo siguiente (Zelen y Severo, 1972)
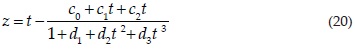
donde

c0 = 2.515517 c1 = 0.802853 c2 = 0.010328
d1 = 1.432788 d2 = 0.189269 d3 = 0.001308
La ecuación 20 se aplica cuando P varía de cero a 0.50 y entonces z será negativa, cuando P excede a 0.50 se emplea P = 1 – P.
Ajuste de la distribución SJU mediante optimización numérica
Durante los contrastes de las distribuciones GVE, LP3 y LOG con el grupo de 31 registros históricos hidrológicos, tales modelos se ajustaron mediante optimización numérica para minimizar el error cuadrático medio. Por lo anterior, también ahora se realizó el ajuste de la distribución SJU mediante optimización numérica utilizando como función objetivo (FO) el EEA (ecuación 17).
Nuevamente, este proceso se realizó con base en el algoritmo de múltiples variables no restringidas de Rosenbrock (Kuester y Mize, 1973 ; Campos 2003), considerando como variables a optimizar sus cuatro parámetros de ajuste (ε, η, δ, τ), cuyos valores iniciales se obtuvieron con las ecuaciones 10 a 13. El algoritmo citado, únicamente falló en los registros 1, 4, 11 y 19, excediendo el número máximo de evaluaciones de la FO de mil; o bien, no llegando a converger en el número máximo de etapas permitido, que fue de cincuenta. Ambos problemas se corrigieron limitando el número de etapas permitido a la última en que se tenían resultados consistentes.
Análisis de resultados
Registros que aceptan la distribución SJU
En la tabla 1 se concentraron los resultados de las ecuaciones 5 a 9, utilizando z = 0.5483, encontrado que únicamente en 13 registros de los 31 analizados, se aplica la familia de distribuciones SJU. Se observa que el procedimiento de selección trabaja correctamente, ya que detecta a la familia SJB como la más conveniente en los cuatro registros (16, 20, 24 y 29), que siguieron la distribución Weibull o modelo GVE con frontera superior.
Resultados óptimos de los contrastes previos
En la tabla 2 , para cada registro procesado se exponen ocho renglones de resultados, los dos primeros corresponden a los parámetros de ajuste (u, α, k), EEA y predicciones con periodos de retorno 10, 25, 50, 100, 500, 1 000 y 10 000 años, obtenidas con la distribución GVE. El primer renglón tiene los resultados de uno de los cuatro métodos de ajuste, el que condujo al EEA mínimo; el segundo renglón los resultados del ajuste mediante optimización numérica; por ello se indica en la columna 7 de la tabla 2 , el número de etapas y evaluaciones de la función objetivo (EEA) realizadas.
De manera similar, en los renglones 3 y 4 de cada registro se presentan idénticos resultados para la distribución LP3, pero utilizando alguno de sus seis métodos de ajuste y el de optimización numérica. En los renglones 5 y 6 de cada registro están los resultados de la distribución LOG, en este caso se ajusta solo con el método de momentos L y mediante optimización numérica. Los resultados de los seis renglones descritos proceden de Campos (2013).
Resultados de los ajustes de la distribución SJU
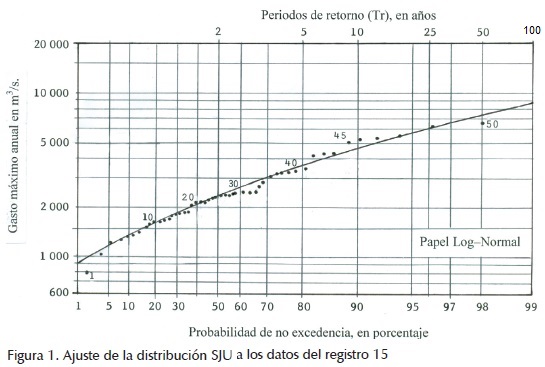
Finalmente, en los renglones 7 y 8 de cada registro de la tabla 2 se exponen los resultados del ajuste de la distribución SJU, con base en las ecuaciones 10 a 13 para estimar sus parámetros de ajuste y 17 a 21 para calcular su EEA . La estimación de las predicciones asociadas a los siete periodos de retorno contrastados, utiliza las ecuaciones 19 a 21, en las cuales P es la probabilidad de no excedencia relativa a cada intervalo de recurrencia. En la figura 1 se muestra uno de tales ajustes.
Apreciaciones generales en el contraste de la distribución SJU
Los cuatro modelos probabilísticos contrastados (GVE, LP3, LOG y SJU) conducen a predicciones casi idénticas en los periodos de retorno bajos (< de 50 años) e incluso en algunos registros hasta el de 100 años. Se observa una concordancia excelente en todas las predicciones de los seis registros con números: 1, 4, 6, 7, 15 y 23; ya que aún en los periodos de retorno de 1 000 y 10 000 años sus predicciones son del mismo orden de magnitud.
Las predicciones de la distribución SJU son menores en los periodos de retorno de 1 000 y 10 000 años en los registros 11, 17, 25 y 30. En el registro 25, reproduce los resultados del modelo LP3. Por el contrario, la distribución SJU aporta predicciones mayores en los periodos de retorno altos en los registros 19, 22 y 26.
Un aspecto muy importante asociado con la utilidad de la distribución SJU en los análisis probabilísticos de crecientes, es el hecho de resultar aplicable en registros que pueden catalogarse como "difíciles o complicados" de procesar por incluir valores dispersos o eventos extremos que se apartan del conjunto que integra la muestra. Tal es el caso de los registros con números 11, 17, 19 y 25, los cuales corresponden respectivamente a las hidrométricas de Jaina y Huites en la Región Hidrológica Núm. 10 (Sinaloa), Cerca del Moral en la Región Hidrológica Núm. 24-2 (Amistad-Falcón) y El Cuchillo de la Región Hidrológica Núm. 24-3 (Bajo Río Bravo).
Conclusiones
La aplicación de las cuatro distribuciones de probabilidad contrastadas (General de Valores Extremos, Log-Pearson tipo III, Logística Generalizada y Johnson con PS > 1) se recomienda en los análisis probabilísticos de crecientes y de otros datos hidrológicos extremos, debido a la consistencia o similitud numérica que presentan todas sus predicciones en los periodos de retorno reducidos (< 50 años), sin importar el método de ajuste.
El proceso de selección de la distribución de probabilidades del sistema Johnson que mejor se adapta o ajusta a los datos, se considera acertado, dada la similitud que mostraron las predicciones de los cuatro modelos contrastados (GVE, LP3, LOG y SJU) en los registros 1, 4, 6, 7, 15 y 23. En resumen, el modelo probabilístico descrito (SJU) es tan aproximado como los actualmente establecidos bajo precepto.
Además tal proceso define la aplicabilidad del modelo Johnson que no está acotado (PS>1) hacia registros que presentan valores dispersos. Lo anterior convierte a la distribución SJU en un modelo que siempre será conveniente probar al estimar crecientes, debido a sus bases teóricas que la respaldan y a la consistencia general observada en sus predicciones en el contraste realizado, en los 13 registros en que resultó aplicable.
Agradecimientos
Se agradecen las correcciones sugeridas y las observaciones realizadas por los dos árbitros anónimos, las cuales permitieron eliminar errores de redacción y destacar los alcances del trabajo.
Referencias
Benson M.A. Plotting positions and economics of engineering planning. Journal of Hydraulics Division, volumen 88 (HY6) 1962: 57-71. [ Links ]
Bobée B. y Ashkar F. The Gamma family and derived distributions applied in hydrology, Water Resources Publications, Littleton, Colorado, 1991, 203 p. [ Links ]
Campos-Aranda D.F. Introducción a los métodos numéricos: Software en Basic y aplicaciones en hidrología superficial, capítulo 9, Optimización numérica, pp. 172-211 y Apéndice A, pp. 212-217, editorial Universitaria Potosina, San Luis Potosí, 2003, 222 p. [ Links ]
Campos-Aranda D.F. Contraste de la distribución Logística Generalizada en 31 registros históricos de eventos máximos anuales. Ingeniería Investigación y Tecnología, volumen XIV (número 1), 2013: 113-123. [ Links ]
El Adlouni S., Ouarda T., Zhang X., Roy R., Bobée B. Generalized maximum likelihood estimators for the nonstationary Generalized Extreme Value model. Water Resources Research, volumen 43 (número W03410), 2007: 13. [ Links ]
Johnson N.L. Systems of frequency curves generated by methods of translation. Biometrika, volumen 36, 1949: 274-82. [ Links ]
Kite G.W. Frequency and risk analyses in hydrology, capítulo 7, three-parameter Log-Normal distribution, pp. 69-86 y capítulo 12, Comparison of frequency distributions, pp. 156-168, Water Resources Publications, Fort Collins, Colorado, 1977, 224 p. [ Links ]
Kjeldsen T.R., Lamb R., Blazkova S.D. Uncertainty in flood frequency analysis, capítulo 8, pp. 153-197 en: Applied Uncertainty Analysis for Flood Risk Management, editores Beven, K., Hall, J., Imperial College Press, Londres, 2014, 672 p. [ Links ]
Kottegoda N.T. Stochastic water resources technology, capítulo 3, Probability functions and their use, pp. 67-110, The MacMillan Press Ltd., Londres, 1980, 384 p. [ Links ]
Kuester J.L. y Mize J. H. Optimization techniques with fortran, ROSENB Algorithm, pp. 320-330, McGraw–Hill Inc., Nueva York, 1973, 500 p. [ Links ]
Madsen H., Lawrence D., Lang M., Martinkova M., Kjeldsen T.R. A review of applied methods in Europe for flood-frequency analysis in a changing environment, Centre for Ecology and Hydrology, Wallinford, Inglaterra, 2013, 180p. [ Links ]
Martínez-Austria P.F. y Aguilar-Chávez A. Efectos del cambio climático en los recursos hídricos de México, Volumen II, SEMARNAT-IMTA, México, 2008, 118 p. [ Links ]
Perreault L., Bobée B., Rasmussen P.F. Halphen distribution system. I: Mathematical and statistical properties. Journal of Hydrologic Engineering, volumen 4 (número 3), julio de 1999: 189-199. [ Links ]
Ramberg J.S., Tadikamalla P.R., Dudewicz E.J., Mykytka E.F. A probability distribution and its use in fitting data. Technometrics, volumen 21, 1979: 201-14. [ Links ]
Rao A.R. y Hamed K.H. Flood frequency analysis, capítulo 5, Normal and related distributions, pp. 83-125, CRC Press, Boca Raton, Florida, 2000, 350 p. [ Links ]
Shapiro S.S. y Gross A.J. Statistical modeling techniques, capítulo 5, Empirical models, pp. 161-224, Marcel Dekker, Inc., Nueva York, 1981, 367 p. [ Links ]
Shapiro S.S. Selection, fitting and testing statistical models, capítulo 6, pp. 6.1-6.35, en: Handbook of Statistical Methods for Engineers and Scientists, editor Harrison M. Wadsworth, 2a. ed., McGraw–Hill Inc., Nueva York, 1998. [ Links ]
Slifker J.F. y Shapiro S.S. The Johnson System: Selection and parameter estimation. Technometrics, volumen 22 (número 2), mayo de 1980: 239-246. [ Links ]
Stedinger J.R., Vogel R.M., Foufoula-Georgiou E. Frequency analysis of extreme events, capítulo 18, pp. 18.1-18.66, en: Handbook of Hydrology, editor David R. Maidment, McGraw–Hill, Inc., Nueva York, 1993. [ Links ]
Zelen M. y Severo N.C. Probability functions, capítulo 26, pp. 925-995, en: Handbook of Mathematical Functions, edited by Abramowitz M. y Stegun I.A., Dover Publications Inc., Nueva York, Ninth Printing, 1972. [ Links ]
Este artículo se cita:
Citación estilo Chicago
Campos-Aranda, Daniel Francisco. Aplicación de la distribución de probabilidades no acotada del Sistema Johnson para estimación de crecientes. Ingeniería Investigación y Tecnología , XVI, 04 (2015): 527-537.
Citación estilo ISO 690
Campos-Aranda D.F. Aplicación de la distribución de probabilidades no acotada del Sistema Johnson para estimación de crecientes. Ingeniería Investigación y Tecnología, volumen XVI (número 4), octubre-diciembre 2015: 527-537.
Semblanza del autor
Daniel Francisco Campos-Aranda. Obtuvo el título de ingeniero civil en diciembre de 1972, en la entonces Escuela de Ingeniería de la UASLP. Durante el primer semestre de 1977, realizó en Madrid, España un diplomado en hidrología general y aplicada. Posteriormente, durante 1980-1981 llevó a cabo estudios de maestría en ingeniería en la especialidad de hidráulica, en la División de Estudios de Posgrado de la Facultad de Ingeniería de la UNAM. En esta misma institución, inició (1984) y concluyó (1987) el doctorado en ingeniería con especialidad en aprovechamientos hidráulicos. Ha publicado artículos principalmente en revistas mexicanas de excelencia: 48 en Tecnología y Ciencias del Agua (antes Ingeniería Hidráulica en México), 18 en Agrociencia y 17 en Ingeniería. Investigación y Tecnología. Es profesor jubilado de la UASLP, desde el 1° de febrero del 2003. En noviembre de 1989 obtuvo la medalla Gabino Barreda de la UNAM y en 2008 le fue otorgado el Premio Nacional "Francisco Torres H." de la AMH. A partir de septiembre de 2013 vuelve a ser investigador nacional nivel I.

