










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería, investigación y tecnología
versión On-line ISSN 2594-0732versión impresa ISSN 1405-7743
Ing. invest. y tecnol. vol.13 no.2 Ciudad de México abr./jun. 2012
Sincronización de sistemas electrónicos en un mismo circuito integrado
Synchronization of Integrated Systems on a Chip
Linares–Aranda M.1, González–Díaz O.2 y Salim–Maza M.3
1 Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE) Puebla, Puebla, México. Correo: mlinares@inaoep.mx
2 Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE) Puebla, Puebla, México Correo: ogonzalez@susu.inaoep.mx
3 Freescale Semiconductor México. Correo: msalimm@freescale.mx
Información del artículo: recibido: agosto de 2008.
Reevaluado: septiembre de 2010.
Aceptado: marzo de 2011.
Resumen
En el presente artículo se propone la aproximación no convencional de osciladores de anillo interconectados y acoplados como redes de distribución de reloj para la sincronización de sistemas electrónicos en un solo circuito integrado. Se presentan resultados de simulación HSPICE de redes de reloj convencionales (globales) y no convencionales (locales) utilizando parámetros típicos de un proceso de fabricación de circuitos integrados CMOS (Complementary Metal–Oxide Semiconductor) de 0.35 μm pozo–N de Austria Micro Systems (AMS). Con base en resultados experimentales medidos en redes de distribución de señal de reloj, locales y globales, fabricadas mediante el citado proceso, se muestra que la aproximación propuesta es apropiada para sistemas en un solo circuito integrado, debido a su buen desempeño en frecuencia, consumo de potencia y alta robustez a variaciones del proceso de fabricación. Además, las redes de osciladores de anillo interconectados y acoplados poseen modularidad, regularidad y tolerancia a fallas.
Descriptores: redes de reloj, sincronización, sistemas en un chip, circuitos digitales, osciladores controlados por voltaje.
Abstract
In the present paper, the non–conventional interconnected and coupled ring oscillators approach working as clock distribution networks to synchronize electronic systems on a chip (SoC) is proposed. Typical CMOS (Complementary Metal–Oxide Semiconductor) N–well 0.35 μm Austria Micro Systems process parameters were used for conventional and non–conventional clock distribution nets design and simulation. Experimental results from local and global clock distribution networks fabricated using a CMOS 0.35 μm process show that the use of interconnected rings arrays, as globally asynchronous locally synchronous (GALS) clock distribution networks, represent an appropriate approach due to good performance regarding scalability, low clock–skew, high–speed, faults tolerant and robust under process variations, regularity, and modularity.
Keywords: clock networks, synchronization, systems on a chip, digital circuits, voltage controlled oscillators.
Introducción
Actualmente los circuitos integrados (CI), comúnmente conocidos como "chips" y utilizados en diferentes sistemas electrónicos, contienen millones de diminutos dispositivos semiconductores llamados transistores, ocupan áreas de varios milímetros cuadrados y operan a frecuencias del orden de Giga Herte (109 Hz). El manejo masivo de la información y su procesamiento en tiempo real, especialmente en aplicaciones de video y comunicaciones, exigen que estos sistemas sean cada vez más rápidos y consuman menos potencia (Bakoglu, 1990).
La mayoría de los sistemas electrónicos procesan la información en forma digital y realizan sus operaciones de forma síncrona (Bakoglu, 1990), esto es, requieren al menos una señal de reloj que active (temporice) y transfiera (sincronice) la información apropiadamente para su correcto funcionamiento. Típicamente esta señal de reloj se genera fuera del chip (oscilador y PLL: Phase–Lock Loop) y se introduce al CI a través de una terminal del mismo (figura 1). Posteriormente, esta señal se transmite mediante una red (red de distribución) en forma global a todos los elementos de carga (sumideros) que la necesiten, generalmente dispersos en todo el CI. Las redes de distribución de señal de reloj (RDSR) operan a la frecuencia más alta, manejan la mayor carga y ocupan el área más grande de un CI.
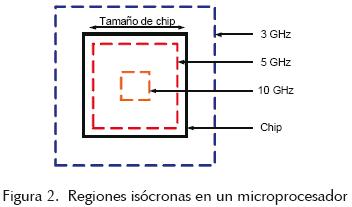
Todas las RDSR están constituidas por interconexiones (en mayor grado) y repetidores o buffers, y utilizan técnicas adicionales para asegurar el correcto funcionamiento de la red ante diversos efectos eléctricos y ambientales no deseados (ruidos) siempre presentes (Stefan, 2005). El diseño de estas redes es complejo y las exigencias actuales de desempeño hacen que su diseño sea cada vez más estricto. La tendencia a incorporar continuamente un mayor número de funciones está provocando que los sistemas electrónicos sean cada vez más complejos y de mayor tamaño (SoC: System on a Chip, y MCM: Multi–Chip Module), lo cual a su vez provoca que las RDSR abarquen más área y consuman más potencia (de 30 a 50% de la energía total del sistema). Sin embargo, un CI no puede crecer infinitamente, pues las limitaciones físicas de los materiales utilizados para su fabricación imponen una cobertura (tamaño) máxima a la cual una señal puede conmutar a una frecuencia dada (Dennis et al., 2005). Esta cobertura, denominada región isócrona, se reduce cuando la frecuencia crece (figura 2). Además, en tecnologías avanzadas de fabricación de CI, son las interconexiones las que tienden a dominar el retardo de los sistemas electrónicos integrados, y la evolución del desempeño de las interconexiones globales no es compatible con las velocidades de la señal de reloj global esperadas utilizando tecnologías avanzadas. Así, con el fin de seguir aplicando señales de reloj mediante redes globales, se ha modificado el escalamiento de las interconexiones de los últimos niveles en un CI (ITRS, 2004) y se dedican esfuerzos considerables en incorporar mejores y nuevos materiales en los procesos de fabricación, así como técnicas más eficientes de distribución de la señal de reloj. Estas tendencias y limitaciones plantean serios problemas en el diseño de redes que manejen señales de forma global, particularmente las RDSR. Con el fin de resolver algunos de los problemas que plantea el diseño de las RDSR globales en sistemas grandes y rápidos, en este trabajo se explora la filosofía local y se propone el uso de redes de distribución de reloj con base en osciladores de anillo interconectados y acoplados.
Redes de distribución de reloj convencionales
Los diseños actuales de RDSR diseminan una señal original en forma global a todos los nodos (sumideros) donde se requiera. Cada sumidero representa una carga que puede ser una simple compuerta digital o todo un elemento procesador complejo. Las RDSR de árbol H y Rejilla o una combinación de ambas (figura 3) son las topologías de RDSR más frecuentemente utilizadas en aplicaciones comerciales; sin embargo, para CI grandes, cada vez es más difícil cumplir con las figuras de mérito requeridas tales como: frecuencia, corrimiento de reloj (skew), temblor del reloj (jitter), consumo de potencia, etcétera.
Redes de distribución de reloj no–convencionales
Arreglos de osciladores de anillo interconectados y acoplados
Debido a los múltiples problemas que se presentan en las RDSR del tipo global (Salim et al, 2001), esta filosofía ha cambiado y han surgido las redes del tipo local, tales como las redes de arreglos de osciladores de anillo interconectados, bien del tipo resonante con base en líneas de transmisión y utilizando ondas estacionarias (O'Mahony et al, 2003), o bien del tipo no–resonante con base en líneas de transmisión utilizando ondas viajeras, entre las que se encuentran las de arreglos de osciladores de reloj rotatorio (Wood et al., 2001) y las de arreglos de osciladores de anillo interconectados y acoplados (Hall et al., 1997; O'Mahony et al, 2003, Salim et al., 2005). Estas últimas constituyen el tema de investigación del presente trabajo.
Las redes basadas en arreglos de osciladores de anillo interconectados y acoplados, son redes activas compuestas de cadenas en lazo cerrado de celdas de retardo sencillas. Estas redes son de fácil diseño, pues se reduce al de un solo oscilador y la repetición del mismo las veces necesarias hasta lograr un tamaño determinado. Además, son robustas a variaciones del proceso de fabricación, pues esas variaciones son absorbidas por todos los anillos minimizando su impacto en las diferentes figuras de mérito. Asimismo, son altamente regulares y escalables con los avances de la tecnología. En la figura 4 se presentan arreglos de 6, 8 y 16 osciladores de anillo interconectados y acoplados.
Oscilador de anillo básico
Un oscilador de anillo de ondas viajeras se construye mediante un número impar de etapas de retardo (inversor convencional, inversor diferencial, oscilador controlado por voltaje (VCO), etcétera) conectadas en lazo cerrado o anillo. Considere el oscilador de anillo de 3 inversores convencionales mostrado en la figura 5. En este oscilador, el periodo de oscilación T de la onda de voltaje a la salida de cualquier inversor puede expresarse como la suma de 6 tiempos de retardo de propagación (figura 5b). Considerando inversores idénticos, las capacitancias de carga en las salidas son iguales, por lo que es posible expresar el periodo de oscilación en términos del tiempo de retardo promedio τa, como (Rabaey et al., 2004):
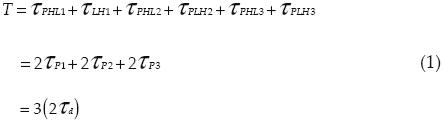
con

μn,p movilidad de portadores en transistores
εox permitividad del óxido de silicio,
Tox grosor del óxido de silicio,
L, W longitud, ancho de canal de los transistores, respectivamente.
CL carga en la salida del inversor,
Cox capacitancia de compuerta del transistor MOS,
Vd,d voltaje de alimentación.

Así, la frecuencia de oscilación es inversamente proporcional al número N de etapas inversoras y al tiempo de retardo promedio por etapa τd . Generalizando la expresión para un número impar N se tiene:

De la ecuación (3) se observa que la velocidad del oscilador puede aumentarse mediante la reducción del número N de etapas. Esta reducción de etapas resulta muy atractiva, ya que simultáneamente se disminuye el consumo de potencia y área. Así, es conveniente considerar osciladores de una y dos etapas. Sin embargo, a medida que N disminuye, es más difícil satisfacer simultáneamente los criterios de oscilación de Barkhausen (Pacheco et al, 2004): "la oscilación estable en un oscilador de anillo requiere un cambio de fase total de 360° a una frecuencia en la cual la ganancia del lazo en pequeña señal esté por encima de 0 dB. En un oscilador de anillo de N celdas, cada celda contribuye con un cambio de fase dependiente de la frecuencia de 180°/N y la inversión de fase en corriente directa provee los 180° restantes. Cuando N = 1 los problemas de baja ganancia y/o fase son más críticos, por lo que es necesario un diseño fino del oscilador lo que conlleva a un mayor tiempo de diseño". Debido a lo anterior, y dado que en circuitos integrados el tiempo de diseño es un factor de costo que siempre debe minimizarse, en este trabajo nos restringimos a osciladores de anillo de 2 y 3 etapas.
Arreglos de osciladores de anillo
Una vez obtenido el oscilador de anillo básico se pueden conectar múltiples osciladores en un arreglo de diferentes formas. Considere la versión de oscilador de anillo básico de forma triangular mostrado en la figura 5a. Compartiendo un inversor de cada lado del triángulo, éste puede extenderse a una red de 2 dimensiones, tal como se muestra en la figura 6a. De esta figura se puede observar que cualquier triángulo constituye una celda fractal (Fractal, 2007) en el sentido de que cualquier forma de triángulo interno tiene la misma forma de la red entera (figura 6b).
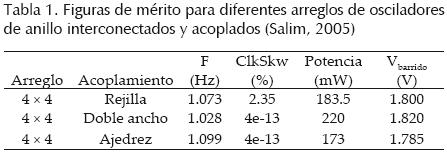
Las RDSRs de anillos interconectados presentadas en la figura 4 están acopladas en modo rejilla; este modo introduce efectos de borde que hemos denominado "efectos de superficie de cristal" por su semejanza con las impurezas en los cristales semiconductores. Con el fin de contrarrestar estos efectos, en Salim (2005) se presentan diferentes formas de acoplamiento de los arreglos con base en la duplicación del ancho de los segmentos compartidos entre celdas básicas. En la tabla 1 (Salim, 2005) se compara el desempeño de 3 arreglos alimentando el mismo número de sumideros (64), cubriendo la misma área (11 mm × 11 mm) y mismo arreglo matricial, pero con diferente modo de acoplamiento. De la tabla 1 se observa que el esquema de ajedrez presenta mayores ventajas, ya que consume menos potencia, oscila más rápido y posee corrimiento de reloj teóricamente de 0%.
Robustez de RDSR de anillos interconectados y acoplados
Tolerancia a fallas
Durante todo proceso de fabricación de un CI se presentan defectos en los dispositivos (transistores, diodos, capacitores, resistores, etcétera) e interconexiones que lo componen, debido a fallas en las diferentes etapas del proceso (malas difusiones e implantaciones, sobregrabados y falta de grabado de materiales, deficiente depósito de aluminio, polisilicio, cobre, etcétera). En particular, es de vital importancia el defecto de conductores abiertos (roturas), ya que en sistemas complejos actuales se ha encontrado que hay una alta probabilidad de que existan roturas en las líneas de interconexión. Esto es más crítico en CI con tecnologías avanzadas que utilizan varios niveles de interconexión de aluminio o de cobre. Las RDSR de anillos interconectados y acoplados (figura 7) han mostrado ser más robustas a fallas de circuito abierto que redes globales (figura 3) conservando prácticamente el mismo desempeño (Salim et al., 2007). Así por ejemplo, si se presentaran las siete fallas indicadas en las figuras 7a y 7b (los números en las interconexiones de estas figuras indican interconexiones abiertas) el arreglo seguiría funcionando, ya que la señal de reloj llegaría a todos los sumideros por otro camino diferente al de la falla, tal como se indica en la figura 7c. Por el contrario, en el caso de la red global de árbol H que alimenta 16 sumideros Si (figura 3a), puede verificarse que si sucediera una sola falla crítica (rotura) en la interconexión que lleva la señal de reloj al sumidero inicial de la red S0, entonces todos los sumideros finales de la red Si, i = 1,.2,..., N (N = 16), se quedarían sin señal de reloj y en consecuencia el sistema integrado no funcionaría.
Incertidumbre de la señal de reloj
El skew y el jitter de la señal de reloj (figura 8) son incertidumbres altamente importantes en la sincronización de sistemas digitales y de comunicaciones. El skew se refiere a variaciones en el tiempo de llegada de los flancos de la señal de reloj en diferentes sumideros finales, el jitter se refiere a la fluctuación alrededor de los bordes de elevación y caída de la señal de reloj. Ambas variaciones en la señal de reloj limitan la frecuencia de operación de los circuitos que la utilizan.
Con el fin de determinar la estabilidad de los arreglos de anillos interconectados y acoplados, se investigó el desempeño de 16, 64, 256 y 1024 anillos acoplados en forma de rejilla y ajedrez cubriendo 6, 12, 24 y 48 mm de lado, bajo variaciones del proceso de fabricación a través de análisis de MonteCarlo. Se consideró 10% de variación en la longitud mínima de canal del transistor; 30% de longitud mínima en el ancho del transistor e interconexiones; 8% en el ancho de óxido; 23% y 18% en los voltajes de encendido de los transistores tipo N y P, respectivamente; y 20% en la resistencia por cuadro y capacitancia por área de la interconexión. Los anillos fueron diseñados utilizando el modelo unificado propuesto en (Salim, 2005). En las figuras 9 y 10 se presentan gráficas de corrimiento de reloj, para el peor de 10 casos de redes locales y globales, respectivamente. La figura 9 muestra arreglos de osciladores de anillo que alimentan 1024 sumideros y ocupan un área de 48 mm × 48 mm. La figura 9a corresponde al arreglo de anillos interconectados en modo rejilla. Observe cómo los corrimientos más grandes ocurren en las esquinas del arreglo y la mayor parte del mismo presenta corrimiento menor a 5%. La figura 9b corresponde al arreglo de anillos interconectados en modo ajedrez y puede verse cómo el corrimiento más grande ocurre en una esquina del arreglo y los siguientes ocurren en tres regiones aisladas y ubicadas aleatoriamente. La mayor parte del arreglo presenta corrimiento menor a 7%. La figura 10 corresponde al peor de 30 casos de la red global árbol H, alimentando sólo 64 sumideros en un área máxima de 12 mm × 12 mm. Observe cómo los corrimientos más grandes y más pequeños ocurren en diferentes lados del arreglo; una mitad del arreglo presenta bajo corrimiento y la otra mitad presenta alto corrimiento. Esto muestra que el arreglo es muy sensible a las variaciones de proceso que afecten las primeras etapas del árbol H, y que se reflejan en etapas subsecuentes.
Circuitos integrados de prueba fabricados
Con el fin de verificar experimentalmente la funcionalidad de diferentes RDSR utilizando osciladores de anillo interconectados y acoplados, se fabricaron dos circuitos integrados utilizando una tecnología CMOS de 0.35 μm AMS.
a) El chip denominado RDR02 (figura 11) contiene estructuras no expandidas: un oscilador anillo de tres etapas de retardo, un oscilador de relajación, un arreglo 16 osciladores de anillo en modo rejilla y un arreglo de osciladores de relajación acoplados en modo rejilla. Mediante este chip se verificó el amarre de los arreglos de anillos interconectados y acoplados.

Cada etapa de retardo consiste en un inversor convencional con L = Lmin = 0.35 μm; WN = 3 μm y WP = 6 μm. Se utilizó metal nivel 2 con ancho de 0.9 μm para las líneas de interconexión y un ancho de 2 μm para las líneas de alimentación en nivel 5. Los arreglos de anillos ocupan un área de 190 μm × 190 μm, lo cual constituye una cobertura muy pequeña, por lo que estos arreglos se consideran no expandidos. En estos arreglos se tomaron los cuatro nodos cuaternarios como las salidas del arreglo (nodos A, B, C y D de la figura 4d), ya que presentan la misma fase y el menor efecto de superficie de cristal en el arreglo. Debido a la alta frecuencia de operación de los arreglos y a las limitaciones del equipo de medición, se utilizaron divisores de frecuencia entre 16 en las diferentes salidas (Salim et al, 2005; Pacheco et al, 2004).
b) El chip fabricado denominado RDR04 (figura 12) contiene tres RDSR: dos del tipo local y una del tipo global. Las RDSR usan serpentinas de 5 vueltas para extender la longitud de las interconexiones entre etapas de retardo. Cada RDSR tiene como sumidero final (carga) un convolucionador de señales de 4 × 4 bits. Se utilizaron terminales dedicadas para alimentar cada estructura de prueba (redes, divisores, convolucionador, etcétera).
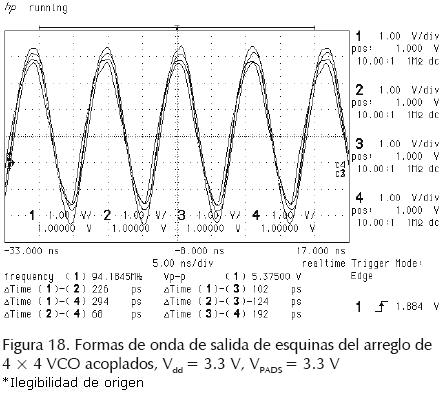
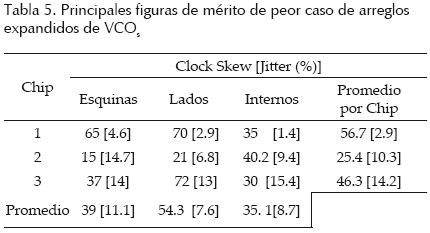
• Arreglo de 16 anillos interconectados y acoplados en modo rejilla (figura 13). En esta red cada anillo está compuesto por tres inversores convencionales sencillos. Los transistores MOS utilizados en cada inversor tienen una longitud de canal Lmin = 0.35 μm y ancho de Wn = 15 μm y Wp = 30 μm para tipo n y tipo p, respectivamente. El área del arreglo es de 1900 μm × 1900 μm. El perímetro de cada anillo con serpentinas es 11.1 mm. Con el fin de verificar las formas de onda en diferentes nodos del arreglo, se seleccionaron 12 salidas con la misma fase tal como se indica en la figura 13c. Las salidas se dividieron en grupos: esquinas (nodos 1–4), lados (nodos 5–8) e internos (nodos 9–12).
• Arreglo de VCO acoplados en modo rejilla (figura 14). Consiste en un arreglo matricial de 4 × 4 VCO acoplados en modo rejilla. Cada VCO está formado por dos celdas de retardo diferenciales (Linares et al., 2007). El arreglo tiene un área de 1900 μm × 1900 μm y utiliza serpentinas de tres dobleces. El perímetro de cada VCO con serpentinas es 2.5 mm. Se seleccionaron 12 salidas con la misma fase tal como se indica en la figura 14b (nodos 1–12).
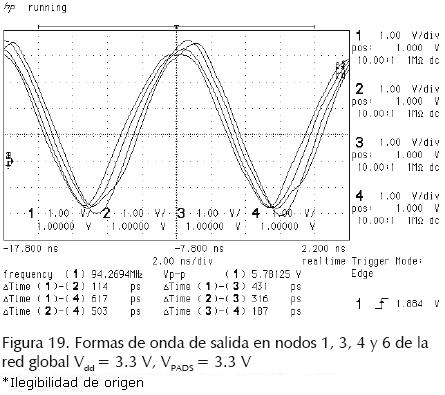
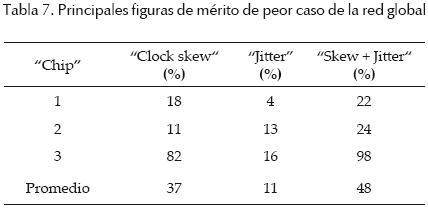
• Red global (figura 15). La red global disemina una señal generada por un VCO a 16 sumideros distribuidos en un área de 800 μm × 800 μm. Las ramas externas de la red se doblaron hacia adentro (figura 15a) y se usaron serpentinas (figura 15b) para incrementar la separación entre repetidores con el fin de verificar el comportamiento del arreglo con interconexiones de longitud grande. Se tomaron ocho salidas del arreglo tal como se indica en la figura 15b.
Resultados experimentales
Circuitos integrados fabricados
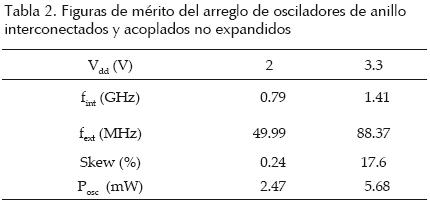
Chip RDR02. En la tabla 2 se resumen los valores de clock skew, consumo de potencia y la frecuencia interna (dividida entre 16) para diferentes valores de la fuente de alimentación. El comportamiento del consumo de potencia y la frecuencia se muestran en la figura 16. En esta figura, los valores se normalizaron con el máximo valor presentado en la tabla 2. Se observa una alta linealidad de estos parámetros con Vdd.

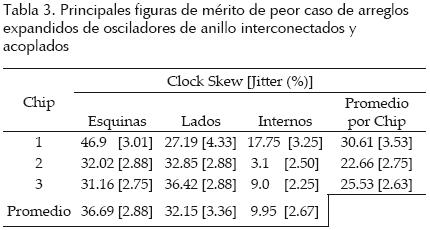
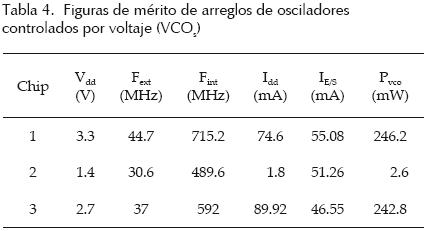
Chip RDR04. Las mediciones experimentales de diferentes figuras de mérito de las redes expandidas fabricadas fueron tomadas en 3 chips. En las figuras 17 a (18) 19 se muestran formas de onda de salida experimentales de los arreglos expandidos mostrando mediciones de frecuencia, voltaje pico a pico y corrimiento de reloj entre las salidas. Los diferentes arreglos se alimentaron con Vdd = 3.3 V. En las tablas 3 a (4–5–6) 7 se presentan figuras de mérito de las redes fabricadas. El skew y jitter del peor caso, se presentan como un porcentaje del periodo de reloj. Las mediciones se clasificaron por chip y por posición geométrica en el arreglo (esquina, lado o interno). En la tabla 7 se incluye la figura de mérito skew + jitter (S + J). Es válido agregarlos, ya que juntos reducen la porción útil del periodo de reloj dado.


Comparación de resultados
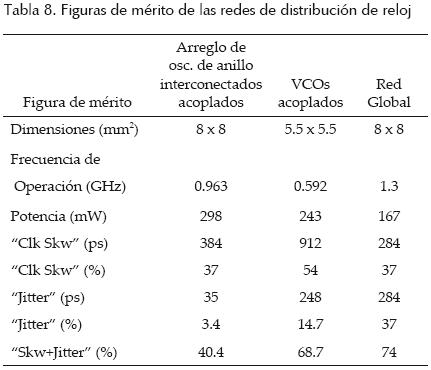
De los resultados experimentales presentados y el resumen de las principales figuras de mérito mostrados en la tabla 8, se puede ver que los arreglos de anillos interconectados y acoplados presentan el skew (37%), jitter (3.4%) y S + J (40.4%) más bajos; no obstante, tienen el mayor consumo de potencia (298 mW). Por su parte, los arreglos basados en VCO diferenciales acoplados presentan la peor degradación de señal debido al reducido barrido de voltaje de las señales. Los arreglos de VCO sólo trabajaron adecuadamente a 592MHz y tienen el peor skew (54%). Finalmente, la red global alcanza la frecuencia más alta (1.3 GHz) con el menor consumo de potencia (167 mW). Esto da lugar a un mejor compromiso potencia/frecuencia (0.128 mW/MHz); sin embargo, tiene el peor jitter (37%) y el peor S + J (74%).
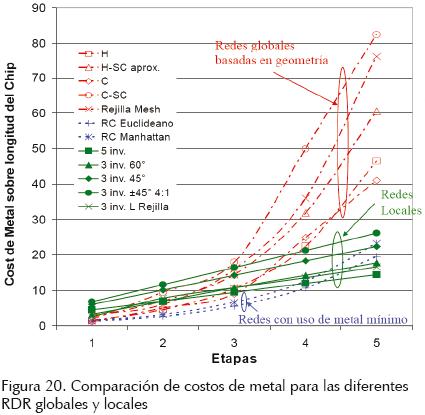
Se puede derivar de estos resultados que las redes de generación y distribución de señal de reloj con base en anillos interconectados y acoplados de etapas inversoras propuestas presentan características de desempeño (figuras de mérito) altamente deseables para sistemas de un solo chip, tales como temblor de la señal reducido y corrimiento de reloj relativamente bajo, alta robustez a fallas (principalmente de circuito abierto) y robustez a variaciones del proceso de fabricación. Si bien las redes de osciladores de anillo interconectados y acoplados presentan algunas características de desempeño relativamente aún inferiores a las de la red global utilizada para su comparación, estas figuras de mérito pueden mejorarse utilizando arreglos matriciales mayores a 4 × 4, tal como se ha podido verificar en las simulaciones. Asimismo, altamente atractivo es el consumo de potencia de arreglos de osciladores interconectados y acoplados (redes locales), pues éste crece linealmente conforme el tamaño de chip crece, como se observa en la figura 20 (Salim, 2005), comparado con el consumo exponencial que presentan las redes globales. El consumo de potencia disipada es función de la cantidad de metal (aluminio en este caso) utilizado por la RDSR.
Conclusiones
En este trabajo se han propuesto y verificado experimentalmente arreglos de osciladores de anillo interconectados y acoplados como una alternativa de redes de generación y distribución de reloj para sistemas en un solo chip (SoC). Las redes no resonantes propuestas presentan características altamente deseables para dar solución a los problemas de sincronización de grandes sistemas integrados, entre las que se encuentran: topología sencilla, alta regularidad, modularidad, altamente integrables y compatibles con la tecnología CMOS, generan frecuencias en el rango de los GHz, ocupan una área reducida, ya que no utilizan inductores y su diseño es sencillo y directo.
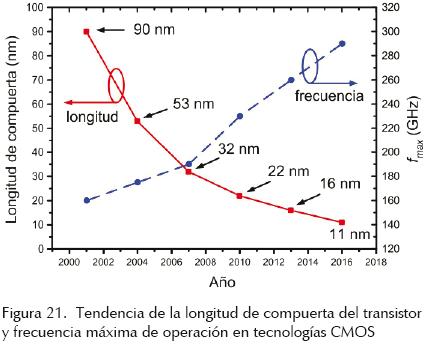
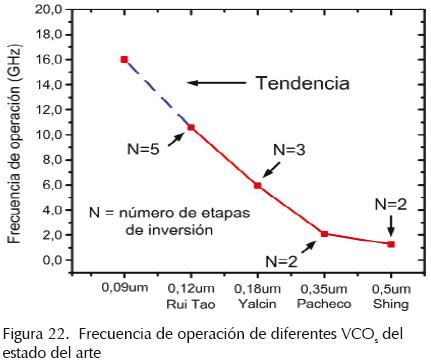
Las redes propuestas dependen altamente del oscilador de anillo básico por lo que su desempeño irá de la mano de los avances que se tengan del oscilador. En este aspecto, existe una amplia investigación de trabajos relacionados con el diseño de osciladores de anillo que generan señales con frecuencias en el rango de los GHz, y reducido consumo de potencia (Pacheco et al., 2004; Salim et al., 2004; Wei et al., 2004; Tao et al., 2004; Kim, 2006). Así, con el continuo escalamiento de las tecnologías (figura 21) y la constante propuesta de nuevas topologías para las etapas de retardo, la frecuencia y el consumo de potencia del oscilador de anillo básico podrán en un futuro hacer posible obtener redes de distribución de reloj con un desempeño mayor que el de redes del tipo global, incluso utilizando una mayor cantidad de etapas (figura 22).
Agradecimientos
Al Consejo Nacional de Ciencia y Tecnología (CONACYT–México) por el apoyo a través del proyecto 51511–Y.
Referencias
Bakoglu H.B. Circuits, Interconnections and Packaging for VLSI, 1a ed., Addison–Wesley, 1990. [ Links ]
Chen T., Huang L. World of Fractal [en línea] [Fecha de consulta 18 de Octubre de 2010]. Disponible en: http://www.math.nus.edu.sg/aslaksen/gemprojects/maa/World_of_Fractal.pdf [ Links ]
Dennis S., Keutzer K. Impact of Small Process Geometries on Microarchitectures in System on a Chip. Proceedings of the IEEE, 89(4):467–489, 2005. [ Links ]
Hall L., Clements M., Wentai L., Bilbro G. Clock Distribution Using Cooperative Ring Oscillators, en: Seventeenth Conference on Advanced Research in VLSI, 1997, pp. 62–75. [ Links ]
ITRS: International Technology Roadmap for Semiconductors, 2009 [en línea] [fecha de consulta 18 de Octubre de 2010], edition: Process, Integration, Devices, and Structures. Disponible en: http//www.itrs.net/Links/2009ITRS/2009Chapters_2009Tables/2009_PIDS.pdf [ Links ]
Kim K.H. U.S. Patent US 7,135,935 B2, November 14, 2006. [ Links ]
Linares A.M., Salim M.M., Pacheco B.D. An Experimental Comparison of Clock Distribution Networks for Systems on Chip, en: 4th International Conference on Electrical and Electronics Engineering, 2007, pp. 377–380. [ Links ]
O'Mahony F., Patrick–Yue C., Horowitz M.A., Simon W.S. A 10–GHz Global Clock Distribution Using Coupled Standing–Wave Oscillators. IEEE Journal of Solid–State Circuits, 38(11):1813–1820, 2003. [ Links ]
Pacheco B.D., Linares A.M. A Low Power and High Speed CMOS Voltage–Controlled Ring Oscillator, en: Proceedings of the IEEE International Symposium on Circuits and Systems, 2004, pp. 752–755. [ Links ]
Rabaey J., Chandrakasan A., Nikolic B.J. Digital Integrated Circuits: A Design Perspective, 2a ed., Pearson Prentice Hall, 2004. [ Links ]
Salim M., Linares M. Analysis and Verification of Clock Distribution Networks in Presence of Crosstalk and Grounbounce, en: 8th IEEE International Conference on Electronics, Circuits and Systems, 2001, pp. 773–776. [ Links ]
Salim M.M., Linares A.M. Interconnected Rings and Oscillators as Gigahertz Clock Distribution Nets, en: Proceedings of the ACM Great Lakes Symposium onVery Large Scale Integration, 2003, pp. 41–44. [ Links ]
Salim M.M., Linares A.M. Analysis and Verification of Interconnected Rings as Clock Distribution Networks, en: Proceedings of the ACM Greats Lakes Symposium on Very Large Scale Integration, 2004, pp. 312–315. [ Links ]
Salim M., Aguirre M., Linares M. Fused Timing Analytical Model for Repeater Insertion and Optimization, en: Proceedings of the IEEE 48th International Midwest Symposium on Circuits and Systems I, 2005, pp. 720–723. [ Links ]
Salim–Maza M. (tesis doctorado), México, INAOE, Junio de 2005. [ Links ]
Salim M.M., Linares A.M. Redes de distribución de señal de reloj con robustez a fallas del proceso de fabricación de CI. Proceedings Iberchip. XII. 2007. [ Links ]
Stefan–Rusu. Clock Generation and Distribution in High–Performance Processors, Enterprise Microprocessor Division, Intel Corporation, 2005 [en línea]. Disponible en: http://www.tkt.cs.tut.fi/kurssit/8404941/S04/chapter5.pdf [ Links ]
Tao R., Berroth M. Low Power 10 GHz Ring VCO Using Source Capacitively Coupled Current Amplifier in 0.12 |am CMOS Technology. Electronics Letters, 40(23):1484–1486, 2004. [ Links ]
Wei H.T., Jyh Y.Y., Hung C.T., Chong K.W. A 1.8V 2.5–5.2 GHz CMOS Dual–Input Two Stage Ring VCO, en: Proceedings of the IEEE Asia–Pacific Conference on Advanced System Integrated Circuits, 2004, pp. 134–137. [ Links ]
Wood J., Edwards T.C., Lipa S. Rotary Traveling–Wave Oscillator Arrays: A New Clock Technology. IEEE Journal of Solid–State Circuits, 36(11):1654–1665, 2001. [ Links ]
Yalcin A.E. A 5.9–GHz Voltage–Controlled Ring Oscillator in 0.18–μm CMOS. IEEE Journal of Solid–State Circuits, 39(1):230–233, 2004. [ Links ]
Semblanza de los autores
Mónico Linares–Aranda. Doctor en ciencias por el Centro de Investigaciones y de Estudios Avanzados del IPN, Departamento de Ingeniería Eléctrica, México DF en 1996. Desde 1986 es investigador/profesor titular en el Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE) en el área de electrónica. Actualmente responsable del Laboratorio de Pruebas y Caracterización de circuitos integrados del INAOE. Sus áreas de interés son el diseño, fabricación y pruebas de circuitos integrados, integridad de señal y el desarrollo de sistemas en un solo chip (SoC).
Manuel Salim–Maza. Doctor en ciencias en electrónica por el Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE), Puebla, México en 2005. Desde 2005 es ingeniero de diseño en Freescale Semiconductor, México y a partir de 2006 es líder técnico del equipo del transmisor y celdas especiales. Es profesor en la especialidad de diseño de CI en el Instituto Tecnológico de Estudios Superiores de Occidente (ITESO) desde 2006. Sus áreas de interés son diseño digital de alto desempeño, diseño automático y optimización.
Oscar González–Díaz. Obtuvo el grado de maestro en ciencias con especialidad en electrónica por el Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE) en 2006. Actualmente realiza estudios de doctorado desarrollando el proyecto "Metodología de sincronización eficiente para sistemas en un solo chip (SoC)". Sus áreas de interés son diseño VLSI y diseño robusto de sistemas a altas frecuencias.

