










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería, investigación y tecnología
versión On-line ISSN 2594-0732versión impresa ISSN 1405-7743
Ing. invest. y tecnol. vol.12 no.2 Ciudad de México abr./jun. 2011
Contraste de la distribución TERC en el Altiplano Potosino de México
Contrast of the Distribution SRET in the Potosi Highlands in Mexico
Campos–Aranda D.F.
Facultad de Ingeniería Universidad Autónoma de San Luis Potosí. E–mail. campos_aranda@hotmail.com
Información del artículo: recibido: julio de 2007.
Aceptado: julio de 2010.
Resumen
Inicialmente se destaca la importancia de las predicciones de lluvia máxima diaria como base para la estimación de las crecientes de diseño, cuando no existe información hidrométrica ni pluviográfica. Además, se citan las ventajas de los métodos regionales ante los valores dispersos en los datos y se formulan los dos objetivos del trabajo. Se continúa con la descripción de la información pluviométrica utilizada. Después se describen y aplican cuatro procedimientos de ajuste regional de la distribución General de Valores Extremos (GVE), a través del método de los momentos L, éstos son: (1) método de las estaciones–años, (2) ajuste por momentos de probabilidad pesada ponderados, (3) método de los valores estandarizados medianos y (4) ajuste con parámetro de forma regional. Posteriormente se aplican tres modelos probabilísticos a los registros pluviométricos, éstos son: las distribuciones GVE, Log–Pearson tipo III y la tipo exponencial de raíz cuadrada (TERC). Por último, se contrastan los resultados regionales con los obtenidos con los modelos locales y se formulan las conclusiones, las cuales destacan la sencillez y mayor aproximación de la función TERC.
Descriptores: precipitación máxima diaria anual, distribución GVE, métodos regionales, distribución TERC.
Abstract
First, the importance of maximum daily rainfall predictions as the base for designing flood estimation is pointed out, particularly when recording rain–gages and hydrometric information are not available. Besides, the advantages of regional methods when the data show outliers are cited and the two main objectives of this work are formulated. Next, the pluviometric information used is described. Late, four procedures of regional fit of the General Extreme Values (GEV) distribution are described and applied, based in the L moment technique, which are: (1) station–year method, (2) fit through averaging probability weighted moments, (3) median standardized values method and (4) fit through regional shape parameter. Three probabilistic models are applied to the pluviometric records: GVE, Log–Pearson type III and square–root exponential type (SRET). Finally, the predictions of probabilistic models and the regional results are contrasted; then several conclusions are formulated, which point out the simplicity and greater accuracy of the SRET function.
Keywords: annual maximum daily précipitation, GEV distribution, regional methods, SRET distribution.
Introducción
Cuando no existe información hidrométrica, la estimación de las crecientes se aborda a través del procesamiento de los registros pluviográficos para obtener las características de las tormentas de la zona y llegar a construir tormentas de diseño, las cuales se transforman en gastos máximos mediante una relación lluvia–escurrimiento; por ejemplo, el hidrograma unitario. Sin embargo, es frecuente que tampoco existan pluviógrafos cercanos y entonces, el análisis probabilístico de la precipitación máxima diaria anual es el punto de partida en la estimación de una tormenta de diseño.
Actualmente se reconoce que incluso un ajuste satisfactorio a un solo registro de crecientes o lluvias máximas no garantiza estimaciones confiables en los periodos de retorno superiores a 100 años, sino que son necesarios más datos para tratar de alcanzar una buena reproducción de la cola extrema de la distribución (Buishand, 1991).
Generalmente, la dificultad para modelar la cola derecha de la distribución aparece cuando se presentan valores dispersos o outliers. Esta necesidad de más datos se satisface usando los registros disponibles en la zona o región, lo cual constituye el enfoque de los métodos regionales.
Los objetivos fundamentales de este trabajo son los dos siguientes: el primero consiste en ajustar regionalmente la distribución de probabilidades General de Valores Extremos (GVE), a los 15 registros disponibles de precipitación máxima diaria anual en la zona conocida como Altiplano Potosino, con el propósito de obtener unas predicciones en cada sitio según este enfoque. El segundo objetivo establece el ajuste en cada estación pluviométrica de las distribuciones actualmente recomendadas para procesar este tipo de registros, con el objeto de contrastar sus resultados contra los del método regional adoptado y seleccionar la función que mejor los reproduce.
Desarrollo
Información pluviométrica utilizada
Corresponde a la disponible sobre precipitación máxima diaria anual (mm) en el sistema ERIC II (IMTA, 2000), para las estaciones pluviométricas del Altiplano Potosino o porción semiárida del estado de San Luis Potosí que pertenece a la Región Hidrológica No. 37 (El Salado), con más de 30 años de datos; con esta restricción se obtuvieron 15 registros, cuya localización geográfica se muestra en la figura 1; en la tabla 1 se presentan sus características generales y sus parámetros estadísticos insesgados (Campos, 2001).
Método de las estaciones–años
Los datos máximos anuales (gastos o lluvias) procedentes de varios sitios son conjuntados y tratados como un solo registro (Garros, 1994; Campos, 2006). Este enfoque acepta que los datos son variables aleatorias independientes, lo cual en el caso específico de la precipitación máxima no es estrictamente válido, debido a la dependencia espacial entre las lluvias observadas y a la relación que guarda ésta con la altitud. Para evitar lo anterior, una modificación importante consiste en estandarizar los datos, dividiéndolos entre su media aritmética o entre su mediana (Buishand, 1991).
Al dividir cada dato de un registro entre su valor medio y conjuntar las 15 series del Altiplano Potosino (tabla 1) se obtuvieron 625 valores, cuyo ajuste de la distribución GVE con el método de los momentos L (Stedinger et al., 1993; Campos, 2001), condujo a las predicciones estandarizadas mostradas en la tabla 2.

Al multiplicar estas magnitudes por la media aritmética ( ) de cada registro, se obtienen las predicciones respectivas del método de las estaciones–años; en la tabla 3 se muestran las correspondientes a las estaciones Cedral, San Luis Potosí y Villa de Arriaga.
) de cada registro, se obtienen las predicciones respectivas del método de las estaciones–años; en la tabla 3 se muestran las correspondientes a las estaciones Cedral, San Luis Potosí y Villa de Arriaga.
Método de los momentos de probabilidad pesada ponderados
La regionalización de los momentos de probabilidad pesada (br) comprende primeramente su estandarización, es decir, su división entre la media b0 y posteriormente su ponderación con base en la longitud de cada registro (nj), por lo cual:

donde ne es el número de estaciones pluviométricas utilizadas, en este caso 15. Los valores obtenidos fueron: be0 = 1.000, be1 = 0.62085 y be2 = 0.46492; a partir de los valores anteriores se ajusta la distribución GVE por medio del método de momentos L (Stedinger et al., 1993; Campos, 2001), para obtener las predicciones estandarizadas mostradas en la tabla 2. Al multiplicar estas magnitudes tabuladas por la media aritmética de cada registro se obtienen las predicciones respectivas de este método, las cuales también se presentan en la tabla 3 únicamente para las estaciones Cedral, San Luis Potosí y Villa de Arriaga.
Método de los valores estandarizados medianos
Este procedimiento es una adaptación del método tradicional de la avenida índice (Dalrymple, 1960; Cunnane, 1988; Campos, 2006) que utiliza un periodo común y por lo cual se visualiza aplicable a 14 de las 15 estaciones pluviométricas del Altiplano Potosino, utilizando registros de 35 años en el periodo de 1963 a 1997 (ver tabla 1); se excluye la estación Venado, cuyo registro no corresponde con tal periodo. Entonces, se ajusta por momentos L la distribución GVE (Stedinger et al., 1993; Campos, 2001), a cada registro de valores estandarizados con su media aritmética para obtener unas predicciones estandarizadas, cuyo valor mediano se indica en la tabla 2; al multiplicar tales valores por la media del registro se calculan las predicciones indicadas en la tabla 3 solamente para las estaciones Cedral, San Luis Potosí y Villa de Arriaga.
Método del parámetro de forma (k) regional
Consiste en ajustar una distribución GVE por momentos L con un procedimiento similar al de las estaciones–años pero utilizando como valores estandarizados los obtenidos con la expresión siguiente:

en la cual, u y α corresponden al parámetro de forma regional (k) de la distribución GVE, pero son los relativos a su registro. Entonces, cada vez que se calcula la función GVE de los datos conjuntados se obtiene un nuevo parámetro de forma k regional, el cual no se cambia y requiere un nuevo cálculo de parámetros u y α de cada registro. El proceso se repite hasta que el valor de k no varía de un tanteo a otro. En la tabla 4 se muestran los resultados de los tanteos y en la tabla 2 las predicciones estandarizadas (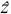 i). En cada estación pluviométrica, con base en sus valores finales de u y a (tabla 4) y la magnitud i se despeja la predicción buscada con la ecuación 2, por ejemplo para un periodo de retorno de 2 años en Cedral se tiene:
i). En cada estación pluviométrica, con base en sus valores finales de u y a (tabla 4) y la magnitud i se despeja la predicción buscada con la ecuación 2, por ejemplo para un periodo de retorno de 2 años en Cedral se tiene:
x2 = –0.295 · 19.699 + 50.411 = 44.6  45 mm
45 mm
en cambio, para un Tr = 10,000 años en Villa de Arriaga el cálculo es:
x10000 = 13.946 · 11.984 + 40.733 = 207.9 208 mm

En la tabla 3 se han concentrado el resto de las predicciones estimadas en tales estaciones y en San Luis Potosí.
Selección de valores regionales
Es importante destacar la semejanza extraordinaria de las predicciones obtenidas a través de los métodos de ajuste regional de la distribución GVE, concentradas una parte en la tabla 3, en los periodos de retorno pequeños (< 50 años) y aún en sus magnitudes más grandes (> 100 años).
Esto brinda gran confianza en tales resultados, dado que estas predicciones provienen de enfoques muy diferentes, como se ha descrito.
Por otra parte, un planteamiento simple y a la vez confiable para la selección de las predicciones regionales en cada estación pluviométrica, es adoptar las más grandes que fueron obtenidas. En las estaciones Cedral, Charcas, Santo Domingo, Soledad Diez Gtz. y Venado, el método del ajuste con parámetro de forma regional conduce a las mayores predicciones; en cambio, en el resto es el método del ajuste por momentos de probabilidad pesada ponderados.
Por lo anterior, en la tabla 5 de comparaciones, son los resultados de este procedimiento los que representan a métodos regionales.
Modelos probabilísticos a contrastar
Stedinger et al., (1993) recomiendan para procesar probabilísticamente lluvias máximas las distribuciones Log–Pearson tipo III (LP3) y la GVE. Para evitar subjetividades en este contraste, la función GVE se ajustará a los registros pluviométricos únicamente por medio del método de momentos L (Stedinger et al., 1993; Campos, 2001) y el modelo LP3 sólo a través del método de momentos en el dominio logarítmico (Bobée et al., 1991).
El tercer modelo probabilístico que se contrasta fue desarrollado por Etoh et al. (1987) para las lluvias diarias máximas anuales, fue designado SQRT–ET–max como abreviatura de square–root exponential type distribution of the maximun y por ello se denomina distribución tipo exponencial de raíz cuadrada (TERC), su expresión es la siguiente:
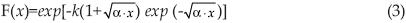
en la cual, F(x) es la probabilidad de no excedencia asociada a la variable x,k es el parámetro de frecuencia y α el de escala. Nanía y Gómez (2004) indican que la distribución TERC ha sido establecida en España como un modelo de referencia, debido principalmente a su origen específico para la modelación probabilística de lluvias máximas diarias anuales.
Para la estimación de los parámetros de ajuste (k,α) de la distribución TERC, se ha utilizado el método de las regresiones polinomiales del logaritmo natural del Cv y k, desarrollado por Zorraquino (2004) y aplicado por Nanía y Gómez (2004) y Campos (2008), el cual comienza por evaluar el coeficiente de variación (Cv), como el cociente entre la desviación estándar y la media; con base en tal valor se selecciona uno de los tres intervalos siguientes: 0.190 a 0.30, 0.30 a 0.70 y 0.70 a 0.999. El parámetro de frecuencia se estima con la fórmula siguiente:

para la cual los coeficientes ai están definidos en la tabla 6.
Como este método en realidad se basa en el de momentos (Zorraquino, 2004), entonces el parámetro de escala se calcula con la expresión siguiente:

donde la integral I1 se estima con la fórmula polinomial:
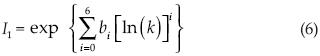
para la cual los coeficientes bi están definidos en la tabla 6.
Discusión de los resultados
Los resultados de los ajustes de las distribuciones GVE, LP3 y TERC a los 15 registros procesados del Altiplano Potosino, se han concentrado en la tabla 5. El análisis de contraste cualitativo de estas predicciones y las del método regional adoptado, indica que en las estaciones pluviométricas en que existe presencia de valores dispersos, las distribuciones GVE y LP3 conducen a predicciones muy elevadas con respecto a las estimaciones regionales, no así el modelo TERC. Lo anterior es notable en Cedral, pero ocurre en todas las estaciones con coeficiente de asimetría cercano o superior a 2.0 (tablas 5 y 1). Por el contrario, en los registros que pueden ser considerados normales debido a que sus coeficientes de asimetría y curtosis se aproximan a cero y 3.0, respectivamente (tabla 1), como lo son Los Pilares, Mexquitic, Reforma y San Luis Potosí, todos los modelos subestiman las predicciones, pero de manera más severa las distribuciones GVE y LP3. En términos generales, la distribución TERC conduce a los resultados más aproximados a los regionales, según se aprecia cualitativamente de la tabla 5 y numéricamente a través de los residuos en la tabla 7.
Conclusiones
Actualmente se considera que las predicciones obtenidas a través de los métodos regionales son más confiables y más estables; sin embargo estos procedimientos presentan el inconveniente de tener que recabar y procesar todos los registros disponibles en la zona o región estudiada. Además, algunas veces no son tan claras las similitudes estadísticas entre los registros, o no es tan evidente la definición geográfica de la región como en el caso aquí expuesto, teniéndose que recurrir previamente a la aplicación de pruebas de homogeneidad regional. Ante tales inconvenientes se sugiere aplicar el modelo TERC de manera individual al registro procesado para obtener las predicciones que serán las más aproximadas a los valores regionales, ante la dificultad para obtener éstos o cuando existe premura por los resultados. Lo anterior, basado en los resultados de las tablas 5 y 7.
Aunque el modelo TERC tiene el inconveniente de no presentar solución inversa, es decir una ecuación que permita el cálculo de una predicción asociada a una cierta probabilidad de no excedencia, el uso de la ecuación 3 es bastante simple y además la estimación de sus parámetros de ajuste es directa y muy sencilla.
En resumen, la distribución TERC es un modelo probabilístico que siempre se debe probar al procesar registros de precipitación diaria máxima anual, teniendo en mente que será menos sensible a los valores dispersos (outliers) y que debido a ello, probablemente conducirá a predicciones más apegadas a los valores regionales, como se ha demostrado para la zona del Altiplano Potosino.
Referencias
Bobée B. & Ashkar F. The Gamma Family and Derived Distribution–sApplied in Hydrology. Chapter 7: Log–Pearson type 3 distribution. Colorado, U.S.A. Water Resources Publications. Littleton, 1991. 203 p. pp. 76–120. [ Links ]
Buishand, T.A. Extreme Rainfall Estimation by Combining Data from Several Sites. Journal of Hydrological Sciences, Vol. 36, No. 4–8, pp. 345–365. 1991. [ Links ]
Campos–Aranda D.F. Contraste de cinco métodos de ajuste de la distribución GVE en 31 registros históricos de eventos máximos anuales. Ingeniería Hidráulica en México, 16(2):77–92, abril–junio, 2001. [ Links ]
Campos–Aranda, D.F. Análisis probabilístico univariado de datos hidrológicos. Capítulo 8: Análisis probabilístico con métodos regionales, páginas 133–161. Avances en Hidráulica 13. AMH–IMTA. México, DF. 2006. 172 p. [ Links ]
Campos–Aranda, D.F. Descripción y aplicación de la distribución TERC para obtener predicciones de precipitación máxima diaria. XX Congreso Nacional de Hidráulica. Tema 3: Hidrología Superficial y Subterránea, Ponencia 3. 15 al 18 de octubre de 2008. Toluca. Estado de México. [ Links ]
Cunnane C. Methods and Merits of Regional Flood Frequency Analysis. Journal of Hydrology, 100:269–290. 1988. [ Links ]
Dalrymple T. Flood–Frequency Analyses. Manual of Hydrology (Part 3): Flood–Flow Techniques, pp. 1–80. U.S. Geological Survey, Water–Supply Paper 1543–A. U.S.A. 1960. [ Links ]
Etoh T., Murota A., Nakanishi M. SQRT–Exponential Type Distribution of Maximum. Hydrologic Frequency Modeling, edited by V.P. Singh. D. Reidel Publishing Company. Dordrecht, Holland. 1987. Pp. 253–264. [ Links ]
Garros–Berthet H. Station–Year Approach: Tool for Estimation of Design Floods. Journal of Water Resources Planning and Management, 120(2):135–160. 1994. [ Links ]
Instituto Mexicano de Tecnología de Agua (IMTA). Eric II: Extractor rápido de información climatológica 1920–1998. Secretaría de Medio Ambiente y Recursos Naturales–IMTA. Jiutepec, Morelos. Mayo, 2000. [ Links ]
Nanía L.S. y Gómez V.M. Ingeniería hidrológica. Capítulo 7: Estadística Hidrológica, Grupo Editorial Universitario. Granada, España. 2004. 278 p. Pp. 205–232. [ Links ]
Stedinger J.R., Vogel R.M., Foufoula–Georgiou E. Chapter 18, theme 18.2: Probability Distributions for Extreme Events, 18.1018.22 and theme 18.8: Frequency Analysis of Storm Rainfall. Handbook of Hydrology, editor in chief David R. Maidment. McGraw–Hill, Inc. New York, USA. 1993. Pp. 18.48–18.53. [ Links ]
Zorraquino J.C. El modelo SQRT–ETMAX. Revista de Obras Públicas, (3,447):33–37. Madrid, España. Septiembre, 2004. [ Links ]
Semblanza del autor
Daniel Francisco Campos–Aranda. Obtuvo el título de ingeniero civil en diciembre de 1972 en la entonces Escuela de Ingeniería de la Universidad Autónoma de San Luis Potosí. Durante el primer semestre de 1977, realizó en Madrid, España un diplomado en hidrología general y aplicada. Posteriormente, durante 1980–1981, llevó a cabo estudios de maestría en ingeniería en la especialidad de hidráulica en la División de Estudios de Posgrado de la Facultad de Ingeniería de la UNAM. En esta misma institución, inició (1984) y concluyó (1987) el doctorado en ingeniería con especialidad en aprovechamientos hidráulicos. Ha publicado artículos principalmente en revistas mexicanas de excelencia: 35 en Ingeniería Hidráulica en México, 12 en Agrociencia y 7 en Ingeniería. Investigación y Tecnología. En congresos internacionales y nacionales ha presentado 24 y 73 ponencias, respectivamente. Fue investigador nacional (nivel I: expediente 7273) desde el 1° de julio de 1991 hasta el 31 de diciembre del 2007. Actualmente es profesor jubilado de la UASLP, desde el 1° de febrero del 2003. En 2008 la AMH le otorgó el premio nacional "Francisco Torres H." a la práctica profesional de la hidráulica.

