










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkIngeniería, investigación y tecnología
On-line version ISSN 2594-0732Print version ISSN 1405-7743
Ing. invest. y tecnol. vol.7 n.1 Ciudad de México Jan./Mar. 2006
Estudios e investigaciones recientes
Análisis bayesiano y fusión de datos para la clasificación de escenas urbanas del Distrito Federal
M. Rodríguez–Cruz y M. Moctezuma–Flores
Facultad de Ingeniería, UNAM
E–mails:
enerlam79@yahoo.com.mx
miguelm@verona.fi-p.unam.mx
Recibido: enero de 2005
Aceptado: junio de 2005
Resumen
En ciudades como México DF, existen crecientes dificultades de administración originadas por la falta de información de las estructuras urbanas y del dinamismo de su evolución. En este contexto, la fotografía aérea de alta resolución de regiones urbanas, puede facilitar tareas en la actualización de cartografía y planeación urbana mediante la segmentación y extracción automática de regiones de interés. En este artículo, se presenta un método para segmentar y clasificar imágenes de fotografía aérea, correspondientes a regiones urbanas de la Ciudad de México. Para lograrlo, primero se realiza una reducción en los niveles de gris de la imagen original, después se calcula su matriz de co–ocurrencia y a partir de ella se obtienen 10 descriptores estadísticos de textura. Posteriormente, se escoge a los descriptores que proporcionan la suficiente información para segmentar a la imagen en regiones características. Después, se realiza un proceso de homogeneización y finalmente, sobre las matrices de textura resultantes se aplica una fusión de datos. En está última etapa, se propone un método de fusión multiclases. El resultado final muestra la funcionalidad de esquema propuesto al mostrar escenas urbanas clasificadas en tres segmentos.
Descriptores: Matriz de co–ocurrencia, descriptores de textura, segmentación, clasificación, homogeneización y fusión multiclases.
Abstract
In cities like Mexico, D.F., there exists in creasing administration difficulties, orignated by the lack of information on the urban structures and the dynamism of their evolution; therefore, the acquisition of aerial high resolution photographs of urban regions, can facilitate tasks in the update of cartography and urban planning through the segmentation and automatic extraction of interest regions. In this article, we present a method to segment and classify aerial photographs of Mexico City. In order to obtain it, first a reduction in the gray levels of the original image is made. Later its matrix of co–occurrence is calculated and from this ten tex tural features are obtained. The textural features that provide the sufficient information to segment to the image are chosen. Later, a homogenization process is made, and finally, the resultant texture matrix is taken into a multiclasses fusion process. In this last stage, we propose a method to fuse several classes. The final result shows the performance of the proposed method, providing urban scenes classified in three different classes.
Keywords: Matrix of co–occurrence, textural features, segmentation, classification homogenization, multiclasses fusion.
Introducción
La textura puede definirse como la variación del contraste entre pixeles vecinos y puede utilizarse para detectar o distinguir los diferentes objetos o regiones de una imagen. Con base en estudios experimentales, Julesz (1971), sostiene que el sistema perceptivo humano puede distinguir texturas estadísticas de primer y segundo orden. La importancia de tal conjetura es que se verifica adecuadamente en el caso de las texturas naturales (Ecole Nationale Supérieure des Telecommunications, 2004). Diversos autores han discutido la interpretación estadística de los operadores textural GLCM (Geophys, 1991 y Cossu, 1998). Con independencia de las imágenes de prueba, Baraldi (1971), determinó la adecuada discriminación visual de patrones texturales al emplear matrices de co–ocurrencia (GLCM). Para el caso de datos pacromáticos y ante las limitantes que impone la mezcla de modos de probabilidad, nuestra propuesta es la extracción de regiones de interés vía caracterizaciones texturales y de su fusión. Así, en este artículo se realiza el análisis de fotografía aérea de alta resolución, correspondiente a una escena urbana del Distrito Federal. Después de explicar el método utilizado en la obtención de datos estadísticos texturales, vía la matriz de co–ocurrencia (GLCM), con base en representaciones matriciales se obtienen los descriptores de textura propuestos por Haralick et al. (1973). Ellos son necesarios para realizar la segmentación, clasificación y fusión de las imágenes. Después se explica el método de segmentación y clasificación que emplea un formalismo bayesiano. Enseguida, se describe un proceso de fusión de datos que implica casos binarios y se propone un método de fusión para el caso multiclases. Dicho método constituye una propuesta original. Posteriormente, se presentan los resultados obtenidos en cada etapa de procesamiento, así como de la fusión de las imágenes de textura.
En este trabajo se utiliza una imagen pacromática del Sur de la Ciudad de México, adquirida por el INEGI en 1992, con un tamaño de píxel de 40cm x 40cm. Los resultados obtenidos muestran el potencial de la fotografía aérea de alta resolución en la solución de problemas urbanos.
En la figura 1 se presenta el esquema del método propuesto.

Matriz de co–ocurrencia y descriptores de textura de Haralick
Para propósitos de segmentación, el empleo únicamente de niveles de gris presenta fuertes limitantes. Esto se debe a la alta semejanza en el rango radiométrico de los diversos elementos que componen una escena natural. Una alternativa es la incorporación de datos texturales que permitan distinguir en una escena urbana, por ejemplo, las regiones de bosques y áreas verdes de las zonas urbanas.
Para caracterizar la información contenida en la textura de una imagen, se utiliza la matriz de coocurrencia (Grey Level Co–occurence Matriz –GLCM–). La co–ocurrencia se interpreta como una medida matricial de la dependencia espacial de los niveles de gris. En esta representación cada elemento matricial representa la probabilidad de ocurrencia de dos valores en la escala de gris, separados por una distancia entre pares de pixeles y un ángulo  en una dirección determinada.
en una dirección determinada.
Para obtener la matriz de co–ocurrencia, se emplea una ventana deslizante. El algoritmo comienza con un barrido secuencial en la esquina superior izquierda de la imagen. Las probabilidades de co–ocurrencia se determinan y entonces se calculan los descriptores de esta matriz. Después, la ventana se desliza una columna hacia la derecha. En este punto, la mayoría de las probabilidades no cambian, excepto por las probabilidades que se forman con la nueva columna que ha sido incluida en la ventana y por la columna que ha salido de ella. Por lo tanto, a la matriz de co–ocurrencia original se le suman las probabilidades que se forman con la columna que ha sido incluida y se le restan las probabilidades que se formaban con la columna que ha salido de la ventana. La figura 2 muestra una representación del esquema de barrido simplificado.

Cuando se llega al extremo derecho de la matriz, la ventana se baja una sola fila. Para las filas pares, la ventana se mueve de izquierda a derecha y para las filas impares la ventana se mueve de derecha a izquierda. La ventana se mueve en un patrón de zig–zag hasta cubrir toda la imagen.
Cada vez que se calcula la matriz de coocurrencia para una ventana, también se calculan sus descriptores de textura. Estos descriptores señalan la dispersión de los elementos matriciales con respecto a la diagonal principal. Para calcular la matriz de co–ocurrencia se utilizaron ventanas de análisis de 5x5, un desplazamiento de un pixel y un ángulo de 0° y 180°. Tales parámetros fueron fijados con base a la resolución espacial y radiométrica de la imagen de prueba, acordes al tamaño de los elementos de la escena. A partir de la matriz de co–ocurrencia se calcularon los descriptores de textura de autocorrelación, contraste, correlación, cluster shade, cluster prominence, disimilaridad, entropía, máxima probabilidad y varianza. El algoritmo empleado es rápido y reduce hasta en un 90% el tiempo de cálculo, comparado con implementaciones de algoritmo original de Haralick et al. (1973).
Esquema de segmentación y clasificación bayesiana
La segmentación divide a una imagen en un conjunto de regiones. Para clasificar estas regiones, se divide el conjunto de pixeles que componen a la imagen en clases temáticas previamente definidas. En este trabajo, la segmentación y clasificación de las regiones se hace utilizando la función discriminante de Bayes, la cual está dada por la siguiente expresión:
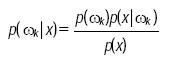
donde:
 es la probabilidad total de evento/pixel x
es la probabilidad total de evento/pixel x
p(ωk) es la probabilidad a priori de ocurrencia de la clase ωk
 es la probabilidad condicional del píxel x, dada la clase ωk
es la probabilidad condicional del píxel x, dada la clase ωk
M es el número de clases o regiones típicas
La expresión de probabilidad a posteriori señala una probabilidad de que ocurra un evento ωk dado que x ya ocurrió y que en una aproximación tipo Máximo a Posteriori constituye la etapa final del cálculo. Como p(x) es un término común se puede eliminar y la función discriminante resultante es:

Para aplicar la expresión anterior, se definió el proceso de segmentación en dos partes: la primera es la pre–clasificación bayesiana y la segunda es la clasificación.
Pre–clasificación bayesiana
Se define una etapa de pre–clasificación en virtud de desconocer las probabilidades a priori p(ωk) Esta etapa consta de dos partes de procesamiento:
Primera parte
1. Sobre la imagen de prueba se definen 3 ventanas de entrenamiento que identifican a tres clases típicas: la clase urbana con tonos de gris muy blancos, la clase urbana opaca y la clase no urbana.
2. Sobre cada ventana se calcula la media mk de la clase ωk.
3. Se aproximan las probabilidades conjuntas del numerador de la regla de Bayes mediante las funciones mostradas en la figura 3, las cuales indican la probabilidad condicional de que un píxel dado pertenezca a la clase ωk. Tales funciones identifican a cada clase y corresponden en el histograma a los datos en nivel de gris de la imagen a procesar. Como parámetros se emplean las medias y medidas de dispersión visibles en los traslapes de las funciones adjuntas.
Segunda parte: pre–clasificación
1. Se aplica la función discriminante de Bayes:
2. Como no se conoce la probabilidad de ocurrencia de clases p(ωk), inicialmente se suponen como equiprobables.
3. Se analiza cada uno de los pixeles de la imagen x, clasificando a cada pixel de acuerdo a los valores máximos de probabilidad a posteriori:
.
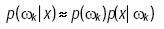
Clasificación bayesiana
En esta etapa se aplica nuevamente el proceso bayesiano anterior. En este caso, se actualizan las probabilidades a priori p(ωk). Esta actualización se lleva a cabo dividiendo el número de pixeles que pertenecen a cada clase entre el total de pixeles de la imagen, empleando los resultados de la preclasificación.
Después de realizar la actualización de probabilidades, se clasifica cada uno de los pixeles de la imagen utilizando la misma función bayesiana de probabilidad condicional (Figura 3). Durante el proceso de pre–clasificación y clasificación, el nivel de gris de cada píxel se proyecta sobre cada una de las funciones para determinar la probabilidad condicional de que el píxel pertenezca a la clase ωi. El número de funciones está determinado por el número de clases.
Como se puede observar en la figura 3, si el nivel de gris del píxel analizado está en el rango de 0 < W0 < m0, la probabilidad condicional para la clase ω0 es de 1. Para las demás clases, la probabilidad es cero, pero si el nivel de gris del píxel analizado está en el rango m0 + s/4 y m0 + 3*s/4, entonces existen 2 valores de probabilidad condicional para este píxel, ya que como se observa en la figura, éste puede pertenecer a la clase ω0 o a la clase ω1. Para obtener la probabilidad condicional de que el píxel analizado pertenezca a la clase ω0, se utiliza la siguiente función:

Donde
W0 es la probabilidad condicional de la clase W0
x es el nivel de gris del píxel analizado
m0 es la media de W0
S = m1 – m0
De igual forma, para obtener la probabilidad condicional de que el nivel de gris del píxel analizado pertenezca a la clase ω1, se utiliza la siguiente función:

Para la clase W1, si el nivel de gris del píxel a analizar es menor a m1 – 3*s/4 (lado izquierdo de la figura para la clase W1) y mayor a m1 + 3*s/4 (lado derecho de la figura para la clase W1) la probabilidad condicional para W1 es de cero. Si el nivel de gris del píxel analizado es mayor o igual a m1 + s/4 y menor o igual a m0 + s/4, entonces la probabilidad condicional será de 1.
Para el resto de las funciones se realiza un análisis similar. Después de obtener todos los términos condicionales:

se multiplica cada una de ellas por las probabilidades a pri ori, que en la primera etapa se consideran como equiprobables:

y en la segunda se actualizan. El píxel analizado pertenecerá a la clase con máxima probabilidad a posteriori.
Homogeneización
En virtud de la variabilidad que para un solo elemento de escena pueden tener los diversos operadores texturales, una vez realizada la segmentación y clasificación bayesiana, se realiza un proceso de homogeneización. En este proceso se igualan las etiquetas de clasificación, es decir, si en una imagen aparece la vegetación como negra y en otra como gris, hacemos que las dos pertenezcan a una misma clase, por lo que se procede a identificarlas con el mismo nivel de gris. Tal proceso se realiza mediante una tabla de equivalencias.
Esquema de fusión
Una imagen pancromática proporciona una información muy limitada del espectro electromagnético, por lo que un solo algoritmo de análisis puede resultar insuficiente para proporcionar resultados confiables y precisos. Por esta razón, Shan YU (1995), propone un método que consiste en aplicar varios algoritmos para analizar la misma imagen y fusionar resultados binarios de segmentación. En nuestro caso, la fusión tiene por propósito incorporar las detecciones parcialmente estimadas en cada resultado de textura. Una aportación del presente artículo es la de modificar el algoritmo de Shan YU a fin de realizar fusiones multiclases.
Para realizar la fusión de imágenes, primero se debe estimar la confiabilidad de los resultados obtenidos a través de los diferentes operadores texturales. Para ello, se utiliza un mapa burdo realizado sobre la imagen original y con base en él, se estima un error local. Para realizar la fusión de datos asumimos que:
s es un sitio o una región de la imagen.
S denota a la imagen completa.
L = {li, 1 < i < N} denota un conjunto de clases o de regiones a segmentar.
M(s) es la clase que pertenece a la región s de acuerdo al mapa.
I(s) es la clase de s obtenida por el resultado del análisis de imagen.
Cada una de las regiones de la imagen debe relacionarse con su vecindad. Supongamos que s' es una región en la vecindad de la región s, y d(s, s') la distancia euclidiana entre s y s' (Figura 4).

entonces se calculan las siguientes medidas

y

donde  es el indicador de función.
es el indicador de función.
El coeficiente a(s) es la suma de las regiones s' en el mapa, que pertenecen a la misma clase a la que corresponde la región que se está analizando. Cada una de estas regiones se divide entre la distancia s, s'. El coeficiente b(s) es la suma de las regiones s' en la imagen que pertenecen a la misma clase a la que corresponde la región que se está analizando en la imagen. Cada una de estas regiones se di vide entre la distancia s, s'.
Una vez obtenidos los coeficientes a(s) y b(s), se calcula el error local para cada región. Este error se de fine por la siguiente expresión:

donde Xl l es un error llamado de riesgo, que se obtiene cuando la región que se está analizando tanto en la imagen como en el mapa, pertenece a clases distintas. En caso de que la región analizada pertenezca a la misma clase, tanto en la imagen como en el mapa, este error es cero.
Los valores que puede tomar Xli,lj para el caso binario son los siguientes:
Xli,lj=20, si la región analizada en el mapa pertenece a la clase 1 y la región analizada en la imagen es de clase 2.
Xli,lj=0, si la región analizada en el mapa pertenece a la misma clase que la región analizada en la imagen.
Xli,lj=1, si la región analizada en el mapa pertenece a la clase 2 y la región analizada en la imagen es de clase 1.
r es una constante que para el caso binario es igual a 2, que indica que la información que brinda el mapa sobre la escena es más confiable que la información que proporciona la imagen.
Después de calcular el error local para cada región de la imagen se obtiene el coeficiente de confiabilidad, mediante la siguiente expresión:

Donde el denominador se obtiene sumando los valores que toma Xli,lj, y que son 20, 1 y 0, por lo tanto, el resultado es 21.
Una vez obtenidos los coeficientes de confiabilidad, se realiza el proceso de fusión, aplicando la siguiente expresión:

Donde p es el número de imágenes a fusionar. Esta ecuación nos dice que debemos analizar la pertenencia de cada región sobre el conjunto de clases.


Si una región de la imagen 1 pertenece a la clase 1, entonces su coeficiente de confiabilidad se acumulará en l1(s). Si para la misma región en la imagen 2 pertenece a la clase uno, entonces su coeficiente de confiabilidad se sumará al valor acumulado en l1(s). Pero si esta región pertenece a la clase 2, su coeficiente de confiabilidad se acumulará en l2(s).
Finalmente, la región analizada pertenecerá a la clase que tenga la mayor acumulación de los coeficientes de confiabilidad. De esta manera y repitiendo el proceso anterior se obtiene la fusión deseada.
Esquema propuesto: fusión multiclases
El método que se propone en este artículo realiza fusión multiclases. Los valores de las variables propuestas son los mismos que se utilizaron en el caso binario, es decir:
p = 3
r = 2,
Xli,lj=20, Xli,lj=1, Xli,lj=0
De acuerdo a una inspección visual, tres clases eran suficientes al propósito del presente artículo, ellas son: clase urbana con niveles de gris muy blancos o clase A, clase urbana opaca o clase B y clase no urbana o clase C. Con base en la fusión binaria se generan 3 pares de clases a analizar, que son: A y B, B y C, finalmente A y C.
La clase 1 siempre será el valor de nivel de gris más bajo. Con esta consideración se calculan las a(s) y b(s) correspondientes y después se obtiene Xli,lj, E(s), y el coeficiente de confiabilidad para cada imagen. Al igual que en el caso binario, la región analizada pertenecerá a la clase con mayor coeficiente de confiabilidad.
Resultados
Se muestran a continuación resultados del proceso descrito de segmentación y clasificación. Los descriptores de textura utilizados son autocorrelación, entropía y máxima probabilidad. Correspondiendo a una zona en la cercanía de la pirámide de Cuicuilco, la figura 5 muestra la imagen pancromática de prueba con un rango de 256 niveles de gris. Las figuras 6 a 8 (6, 7, 8) muestran resultados de los operadores texturales empleados. Las figuras 9 a 14 (9, 10, 11, 12, 13, 14) muestran los resultados de la segmentación bayesiana aplicada a las imágenes de textura, así como su homogeneización. La figura 15 muestra un mapa definido manualmente a partir de la imagen original que no debe ser preciso, pero que ayuda al proceso de fusión. La figura 16 muestra el resultado de la fusión y la figura 17 muestra ventanas de 100x100 pixeles que comparan la imagen original con los resultados de segmentación mediante un esquema clásico de k–medias y por el esquema propuesto de fusión.










Mapa brudo y fusión de los resultados previos de segmentación


Como se puede observar, los descriptores obtenidos utilizando operadores estadísticos de segundo orden ayudan a distinguir las diferencias de textura en regiones urbanas, tales como los contornos de calles y casas. Después de realizar el proceso de segmentación, clasificación y homogeneización, observamos que los descriptores de entropía y máxima probabilidad, nos brindan información más precisa sobre la distribución de la escena. La vegetación queda definida por la clase urbana opaca, los techos opacos urbanos y las calles quedan definidos dentro de la clase no urbana, y los techos blancos dentro de la clase urbana con niveles de gris muy blancos. Después, al realizar el proceso de fusión multiclases, podemos observar que la imagen resultante nos brinda información sobre tres elementos de la escena y señala con claridad los contornos de los techos y de las calles. Con este resultado se puede realizar un mapa temático de esa zona de la Ciudad de México.
Conclusiones
Los datos obtenidos por la percepción remota satelital dan la visión sinóptica requerida por la amplia escala de estudios de planificación para el desarrollo integrado. Los datos que se obtienen mediante la percepción remota aérea son útiles; por ejemplo, para la visualización y valoración de desastres naturales, enfocando áreas prioritarias y proporcionando información de datos a pequeña escala. En este trabajo, se implementó un esquema estadístico para la segmentación y clasificación de fotografía aérea de alta resolución. Para lograrlo, se utilizaron representaciones de funciones conjuntas de densidad orientadas al análisis de texturas. También se definieron etapas de segmentación y clasificación bayesiana máximo a posteriori, así como una técnica de fusión de datos. En esta última etapa se propuso un método de fusión multiclases, partiendo de un método de fusión binaria.
Con base en los resultados obtenidos, se puede decir que el método propuesto funciona adecuadamente, ya que la imagen resultante quedó divida en tres clases, dos de ellas urbanas y una tercera no urbana. Consideramos que este trabajo puede servir para derivar mayor información sobre elementos de escenas, y con esto lograr un mejor análisis y planificación de las zonas urbanas.
Etapas posteriores del presente trabajo consideran la realización más automática de mapas temáticos y la evaluación de la dinámica urbana.
Agradecimientos
El presente trabajo fue parcialmente financiado por el CONACYT, México.
Referencias
Clausi D.A. y Zhao Y. Rapid Extraction of Image Texture by Co–Occurrence Using a Hybrid Data Structure. Department of Systems Design Engineering, University of Waterloo, http://www.elsevier.com/gej–ng/10/13/38/73/57/30/abstract.html. [ Links ]
Cossu R. (1998). Segmentation by Means of Textural Analysis. Pixel, Vol. 1, No. 2, pp. 21–24. [ Links ]
Ecole Nationale Supérieure des Télécommunications (2004). Le Traitement des Images, Tome 2, Sep. [ Links ]
Evaluation of Second–Order Texture Parameters for Sea Ice Classification from Radar Images (1991). J. Geophys. Res, Vol. 96, No. 6, pp. 10625–10640. [ Links ]
Haralick R.M., Shanmugam K. and Dinstein I. (1973). Texture Features for image Classification. IEEE Trans on Syst. Man Cybern., Vol. 3, pp. 610–621, Nov. [ Links ]
Julesz B. (1971). Foundations of Cyclopean Perception. The University of Chicago Press, Chicago. [ Links ]
Shan–YU. (1995). Improving Satellite Image Analysis Quality by Data Fusion. IEEE IGARSS'95, Firenze, It., pp. 2164–2166. [ Links ]
Bibliografía sugerida
Baraldi A. and Parmiggiani F. (1995). An Investi gation of the Textural Characteristics Associated with Gray Level Cooccurrence Matrix Statistical Param e ters. IEEE Trans. Geosci. Remote Sensing, Vol. 33, No. 2, pp. 293–304, March.
Fernández–Aguirre E. (2002). Análisis y clasificación semi–automática de escenas urbanas del Distrito Federal. Facultad de Ingeniería, UNAM, México, DF.
http://www.teledet.com.uy/quees.htm
Morales D.I., Moctezuma M. and Parmiggiani F. (2004). Urban Edge Detection by Texture Analysis. IEEE International Geoscience and Remote Sensing, IGARSS 2004, Anchorage Alaska, Vol. 6, pp. 3826–3828, 20–24, Sept.
Semblanza de los autores
Marlene Rodríguez–Cruz. Se graduó como ingeniera en telecomunicaciones por la Facultad de Ingeniería de la UNAM en abril de 2004, con un estudio sobre el análisis bayesiano y la fusión de datos para la clasificación de imágenes de percepción remota. Actualmente es analista de ingeniería de tráfico y evaluación del desempeño de región 9 en TELCEL.
Miguel Moctezuma–Flores. Es ingeniero mecánico–electricista por la Facultad de Ingeniería de la UNAM, donde también realizó una maestría en ingeniería eléctrica. Asimismo, finalizó una maestría en procesamiento de señales e imágenes en la ENST–Telecom París, donde obtuvo también el doctorado en 1995. Ha dirigido diversos proyectos de investigación nacionales e internacionales y es autor de más de 20 artículos internacionales en el área. Actualmente se desempeña como profesor de tiempo completo en la DIE–FI, UNAM.

