










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkPapeles de población
versão On-line ISSN 2448-7147versão impressa ISSN 1405-7425
Pap. poblac vol.18 no.72 Toluca Abr./Jun. 2012
Alcances y límites de los métodos de análisis espacial para el estudio de la pobreza urbana
Scopes and limits of the analysis methods for the study of urban poverty
Landy L. Sánchez-Peña
El Colegio de México
Este artículo fue
recibido el 29 de septiembre de 2008
aprobado el 21 de marzo de 2012.
Resumen
Los estudios poblacionales en México han puesto poca atención a la dimensión espacial de los fenómenos sociales, pese a que preguntas sobre la difusión de comportamientos o sus diferencias territoriales han sido parte de su agenda de investigación. Este artículo es de corte metodológico y revisa tres aproximaciones para dar cuenta de la dependencia y la heterogeneidad espacial: análisis exploratorio de datos espaciales, modelos de regresión espacial autorregresivos y regresión geográficamente ponderada. El texto ejemplifica las preguntas y aplicaciones de estos métodos a partir de un análisis de la pobreza en Guadalajara a nivel de Área Geoestadística Básica (AGEB), Se sugiere que estos métodos pueden ser útiles para entender el grado de concentración espacial de la pobreza urbana, los posibles efectos de contagio o difusión y cómo los factores explicativos de la pobreza pueden tener efectos diferenciados en la ciudad.
Palabras clave: análisis espacial, dependencia y heterogeneidad espacial, geografía de la pobreza.
Abstract
Mexican population studies paid limited attention to the spatial dimension of social phenomena. even if questions regarding behaviors' diffusion or differences across space have been at the core of their research agenda. This paper has a methodological aim. It reviews three methods to account for spatial dependency and heterogeneity: exploratory spatial data analysis, autoregressive regression models, and geographically weighted regression. The paper exemplifies their questions and applications by examining urban poverty in Guadalajara, at the geostatistical basic area level. It suggests that spatial methods offer a useful way to understand issues such as poverty geographical concentration, contagion o diffusion effects, and variations on poverty explanatory factors across the city.
Key words: spatial analysis, spatial dependency and heterogeneity, poverty geography.
Introducción
En los estudios demográficos han sido recurrentes las preguntas acerca de cómo se distribuyen espacialmente los grupos poblacionales y qué factores explican dicha distribución. También ha existido interés por entender cómo ciertos procesos demográficos ocurren de manera distinta a través de las regiones y hasta qué punto localidades geográficamente cercanas se influyen entre sí en la adopción de prácticas sociales, por ejemplo, en el control de la fecundidad o los patrones de consumo. Este tipo de preguntas implican, sin embargo, retos metodológicos en la estimación de los llamados efectos espaciales: autocorrelación y heterogeneidad espacial.
Recientes desarrollos estadísticos y computacionales permiten no solo modelar dichos efectos espaciales, sino también plantearnos nuevas preguntas sobre la dimensión espacial de los procesos sociales. A lo largo de este trabajo se revisan los supuestos conceptuales y de estimación de tres familias de métodos que buscan dar cuenta de la autocorrelación y heterogeneidad: análisis exploratorio de datos espaciales, modelos de regresión espacial autorregresivos y la regresión geográficamente ponderada. Esto con el fin de mostrar su utilidad para analizar la distribución geográfica de los grupos poblacionales y sus determinantes. A lo largo del texto se ejemplifica la aplicación de estas técnicas, sus ventajas y limitaciones, a partir de examinar la pobreza urbana en Guadalajara, México. Con ello se busca mostrar cómo el análisis espacial puede contribuir a entender tres preguntas que han emergido con fuerza en los estudios de pobreza: cuán concentrada está la pobreza urbana, cuáles son los determinantes de la pobreza y si estos varían a lo largo del territorio.
Espacio y procesos sociodemográficos
En la abundante literatura sobre la pobreza han recobrado centralidad preguntas concernientes a la localización y distribución espacial de los hogares en condición de pobreza, con particular atención a su grado de concentración o dispersión. Por un lado, en contextos urbanos se acentúa la preocupación por identificar áreas donde se concentran los pobres, dados los efectos negativos que altos niveles de aglomeración geográfica pueden tener para el bienestar de los hogares de menor nivel socioeconómico (Wilson, 1998; Sampson, 2009; Hernández et al, 2002); por el contrario, la investigación en áreas rurales ha puesto atención en el grado de dispersión de las comunidades, característica que contribuye a su aislamiento y a las dificultades para brindarles servicios gubernamentales (Hernández, 2004). A estos estudios se añaden aquellos que examinan la distribución de la marginación a lo largo del territorio, así como aquellos que analizan las características geofísicas de las zonas de asentamiento de los hogares pobres a fin de medir su exposición a riesgos naturales (CONAPO, 2002; Salas, 2007).
Todos estos estudios se han beneficiado de la consolidación de los Sistemas de Información Geográfica (SIG) que permiten el rápido manejo cartográfico, proveen el despliegue visual de las variables y facilitan la comunicación de los hallazgos a un público amplio. Si bien los SIG han popularizado el análisis territorial entre investigadores y funcionarios públicos, la dimensión espacial de los fenómenos poblacionales sigue estando limitadamente atendida (Weeks, J. et al, 2004), ya que relativamente pocos trabajos consideran cómo el espacio influye el fenómeno bajo investigación y no se emplean metodologías que explícitamente consideren la estructura espacial del mismo (Anselin, 1989; Haining, 2003; Holt y Lo, 2008; Lobao et al, 2007). En buena medida lo anterior se explica tanto por la limitada disponibilidad de datos georreferenciados, como por los retos conceptuales y metodológicos que modelar dicha estructura supone.
Sobre la estructura de los datos y los efectos espaciales
Considerar la dimensión espacial de los procesos sociodemográficos implica preguntarse sobre dónde ocurren estos y de qué manera dicha distribución geográfica condiciona o influye dichos fenómenos. Esta dimensión espacial abarca cuestiones como la escala a la que los fenómenos ocurren, la difusión territorial de ciertos fenómenos o las características de la distribución espacial de ciertos grupos poblacionales. Es decir, hay que preguntarse sobre la ubicación de ciertos eventos, pero también sobre cómo estos lugares y sus atributos se interrelacionan entre sí. De ahí que los métodos de análisis espacial empleen la ubicación de los fenómenos de estudio tanto en términos absolutos (dónde ocurre), como en términos relativos (distribución, distancia entre las observaciones). Dicho en otras palabras, en el análisis espacial el arreglo geográfico de los objetos (v.gr. la configuración espacial de las unidades de observación) es en sí mismo objeto de investigación y provee información fundamental sobre el proceso social bajo análisis. Por ejemplo, desde la perspectiva del análisis espacial no solo interesarían las tasas de fecundidad municipales sino su distribución específica en el territorio, asumiéndose entonces que el fenómeno bajo estudio sería notablemente distinto si dicho arreglo espacial cambiase —aun cuando los valores de la variable no lo hiciesen (Haining, 2003).1
Al emplear la información completa sobre la ubicación de los fenómenos, el análisis espacial puede capturar mejor las interacciones entre las observaciones espaciales (Haining, 2003). Pero, ¿qué tiene de especial lo espacial? (Anselin, 1989). En términos generales, existen dos grandes efectos que estructuran las relaciones en el espacio. Por un lado, el efecto de heterogeneidad espacial, que indica la presencia de diferencias sistemáticas en la ocurrencia de un fenómeno en distintas regiones geográficas, de tal forma que habría diferencias en su distribución (media, varianza) en un subgrupo de los datos o, bien, simplemente cambiarían con la ubicación de las unidades (Anselin, 1992). Así, por ejemplo, cuando hablamos de diferencias entre los niveles de pobreza del sur y el norte mexicanos, o las diferencias intrametropolitanas entre el centro y el oriente de la Ciudad de México estaríamos hablando de heterogeneidad espacial. Es importante notar, sin embargo, que dichas diferencias deben ser significativas y suponen un proceso subyacente que da origen a los contrastes entre las regiones (Fotheringhamm et al, 1997). En el fondo, dicha heterogeneidad presumiría que las variables explicativas del fenómeno en cuestión podrían variar a lo largo del espacio, tanto en su significancia como en su peso.
El otro efecto espacial es la dependencia o autocorrelación espacial, que se presenta cuando una variable tiende a asumir valores similares en unidades geográficamente cercanas (Anselin, 1989), este efecto se expresa en la llamada Ley de Tobler (1970): "Todas las cosas se parecen a otros objetos, pero se parecen más a los objetos más cercanos". Este proceso de autocorrelación da cuenta del surgimiento de clústeres locales, por ejemplo, la aglomeración de zonas pobres dentro de las ciudades.
Considerar la presencia de efectos espaciales puede ser necesario tanto por motivos metodológicos como teóricos. Por un lado, la presencia de dependencia espacial violaría el supuesto de la independencia de las observaciones, generando problemas en la correcta estimación de modelos de regresión, específicamente los estimadores mínimos cuadrados serán sesgados e ineficientes (Anselin, 2006), con los sabidos problemas que ello implica para la estimación de los coeficientes, los intervalos de confianza y significancia de los coeficientes, así como problemas para la bondad de ajuste del modelo (Wooldridge, 2001). Por otro lado, la dependencia espacial puede ser de interés en sí misma, dado que puede expresar un proceso de "contagio" o influencia recíproca entre las unidades de observación o, bien, puede ser producto de fuerzas económicas, sociales o políticas que tienden a agrupar a poblaciones con rasgos comunes en ciertas áreas (Voss, et al, 2006).
Los modelos de regresión de mínimos cuadrados también asumen que los parámetros a ser estimados son los mismos a lo largo y ancho de la región analizada, es decir, se asume en los datos. La presencia de heterogeneidad espacial viola este supuesto, pues implica variaciones en la media y varianza dependiendo de la ubicación de las observaciones. Como es sabido, cuando este principio no se cumple, las estimaciones presentan problemas, particularmente de la varianza, en las regresiones de mínimos cuadrados. Esta variación puede, sin embargo, buscar modelarse a fin de comprender hasta dónde el proceso social bajo escrutinio ocurre no solo a distintas tasas sino también por distintas razones. En resumidas palabras, nuestro interés por los efectos espaciales puede ser metodológico en tanto buscamos evaluar la estabilidad y confiabilidad de nuestras estimaciones, o bien podemos hacer de esa distribución espacial parte de nuestra pregunta de investigación. En cualquiera de los casos, la presencia de efectos espaciales demanda el empleo de métodos que permitan diagnosticarlos, corregirlos y, en su caso, moldearlos. En el ejemplo de la pobreza urbana, estos métodos puedan contribuir a responder preguntas tales como: ¿cómo está distribuida la pobreza en el espacio urbano?, ¿existen clústeres de alta pobreza?, ¿qué factores contribuyen a explicar el patrón espacial observado?, ¿tienen las variables explicativas de la pobreza el mismo peso en la ciudad o es posible identificar variaciones a lo largo del territorio? En las siguientes secciones se presentan tres tipos de métodos espaciales, mostrando su utilidad para resolver problemas metodológicos y arrojar luz sobre dimensiones poco exploradas de la desigualdad en contextos urbanos.
Métodos y datos
Este trabajo explora la utilidad de los métodos espaciales en el estudio de la pobreza urbana en la Zona Metropolitana de Guadalajara, Jalisco. Los datos provienen del cuestionario básico del Censo de Población y Vivienda 2000 agregados por AGEB, que es la unidad geográfica censal más pequeña. Los datos empleados provienen de la base sobre bienestar de las regiones y, en esta, el área metropolitana de Guadalajara tenía en el año 2000 una población de 3.2 millones de personas, dividida en siete municipios y 1 146 AGEB.
Los datos por AGEB provienen del cuestionario básico y los ha publicado el Instituto Nacional de Estadística y Geografía (INEGI), incluyen diversas variables sociodemográficas, tales como escolaridad promedio, condición de empleo, estado marital, número de hogares, disponibilidad de servicios de salud y características de la vivienda. Las variables relacionadas al ingreso, sin embargo, son limitadas. La única variable que mide los niveles de pobreza a nivel AGEB considera solo pobreza extrema,2 ya que se define como pobres a aquellos cuyo ingreso per cápita del hogar es menor a dos dólares, la cantidad mínima necesaria para cubrir necesidades alimenticias de acuerdo al Banco Mundial. Bajo esta definición, 5.8 por ciento de población en Guadalajara es clasificada como pobre. Sin embargo, cuando analizamos sus valores por AGEB esta variable muestra una distribución muy dispersa: mientras su promedio es de 6.2 por ciento, existen áreas con cero porcentaje de pobres y otras donde alcanza 65.9 por ciento. Esta definición es claramente insuficiente para dar cuenta de la pobreza urbana, pero es la única disponible al público a nivel AGEB.
Para complementar el análisis, también se examina la distribución espacial de trabajadores de bajo ingreso, aquí definida como aquellos que ganan menos de dos salarios mínimos por día (aproximadamente 2 270 pesos en 2000). Ellos representan 31 por ciento de aquellos que reciben ingresos por trabajo, teniendo una media por AGEB de 32.5 por ciento y una desviación estándar de 13.2 por ciento. Un análisis a profundidad sin duda requiere mejores mediciones de pobreza, pero dado que el objetivo central de este trabajo es ilustrar el empleo de métodos espaciales, por ahora estas dos variables son suficientes.
Como variables explicativas se incluyen la escolaridad promedio, la relación de dependencia, la proporción de hogares con jefatura femenina, hogares ampliados; así como proporción de la población desempleada, trabajadores por cuenta propia, trabajadores laborando menos de 32 horas semanales y aquellos empleados en ocupaciones caracterizadas por su alta informalidad. Este conjunto de variables busca dar cuenta de las condiciones de ocupación, el nivel educativo y los arreglos familiares que otros estudios han encontrado asociados a la privación económica a nivel de los municipios o las AGEB.
Nuevos métodos y programas desarrollados en los últimos años facilitan esta tarea, permitiendo un análisis más completo de la dimensión espacial de los fenómenos sociales. En este trabajo presentamos las posibilidades que ofrece el Análisis Exploratorio de Datos Espaciales (AEDE), los modelos de regresión autoregresivos y las regresión geográficamente ponderada. Los dos primeros serán implementados en GeoDa, un software gratuito disponible en línea,3 y para el tercer método se empleará Gwr,4 un software diseñado por Stewart Fotheringham, Martin Charlton y Chris Brunsdon en la Universidad Nacional de Irlanda.
Análisis exploratorio de datos espaciales (AEDE)
El AEDE es una serie de técnicas para visualizar y estimar la autocorrelación espacial. El estudio AEDE permite "mapear" cómo se distribuye la pobreza en el ámbito urbano e identificar la presencia de clústeres de exclusión social, es decir, es posible identificar zonas de la ciudad donde se agrupan las AGEB con altos niveles de pobreza. En GeoDa, la cuantificación de dichos clústeres se realiza a través de dos medidas: I de Moran e Indicadores Locales de Asociación Espacial (LISA, por sus siglas en inglés).
Las figuras 1 y 2 presentan la proporción de pobres y trabajadores de bajos ingresos en las AGEB de Guadalajara. Estos primeros mapas muestran una fuerte heterogeneidad en la distribución de los grupos por ingreso en la ciudad: el patrón general muestra un grado importante de "mezcla" entre las AGEB caracterizadas por niveles medios y bajos de pobreza. Dicho panorama concuerda con estudios que sugieren que las ciudades mexicanas tienen mayores niveles de heterogeneidad de lo que hubiésemos podido predecir basados solo en sus niveles de ingreso (Sánchez-Peña, 2009; Roberts, 1995).
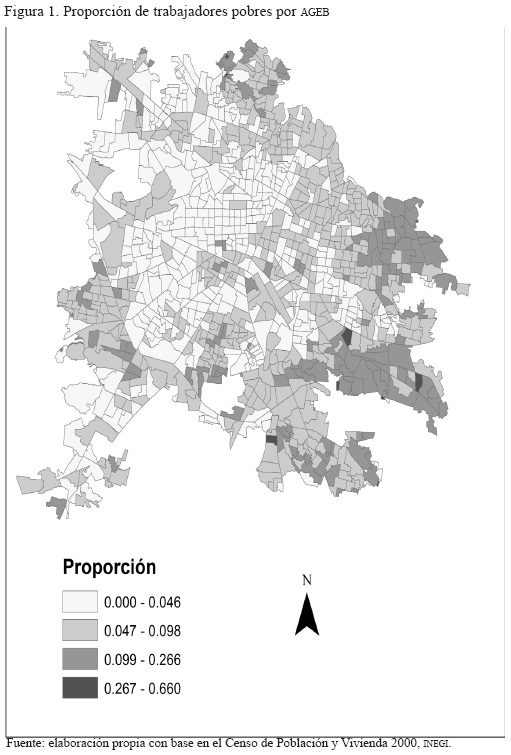

Aunque dicha heterogeneidad parece ser el rasgo fundamental de Guadalajara, también es clara la presencia de zonas de alta pobreza en las orillas de la ciudad (particularmente al este), mientras que una gran zona de baja pobreza se localiza en la zona centro y centro-occidente de la ciudad. Una imagen muy similar ofrece el mapa de trabajadores de bajo ingreso: las AGEB con altas proporciones de trabajadores de bajos ingresos tienden a ubicarse en la periferia y las unidades con bajas proporciones están localizadas en el medio-oeste, mientras que el medio-este está mucho más mezclado. Dicho de otra manera, ambos mapas (figuras 1 y 2) sugieren la presencia de clústeres donde la pobreza o el bienestar se concentran.
Una manera de cuantificar el grado de aglomeración es a través de la I de Moran, la cual mide la tendencia de valores similares a agruparse en el espacio, es decir, hasta qué punto áreas con altos niveles de pobreza están cerca de otras áreas de alta pobreza mientras que zonas de poca pobreza están rodeadas también de otras similares. Los valores de la I de Moran varían entre 0, 1 y -1, donde 0 implica la no existencia de un patrón definido, mientras valores tendientes a -1 indicarían autocorrelación negativa, y 1, el máximo de autocorrelación positiva:

Donde y es el valor de la variable en la unidad,  es su media y w representa la matriz de pesos geográficos la cual determina que observaciones son consideradas vecinas entre sí. En este caso usamos una estructura de "reina" de primer orden de contigüidad, la cual define como vecinas aquellas AGEB adyacentes entre sí que tienen puntos en común (fronteras o vértices).5
es su media y w representa la matriz de pesos geográficos la cual determina que observaciones son consideradas vecinas entre sí. En este caso usamos una estructura de "reina" de primer orden de contigüidad, la cual define como vecinas aquellas AGEB adyacentes entre sí que tienen puntos en común (fronteras o vértices).5
Las Figuras 3 y 4 muestran la gráfica y valores de I de Moran para nuestras dos variables de ingreso. En ambos casos hay evidencia significativa de autocorrelación espacial positiva,6 pero el agrupamiento de AGEB con niveles de pobreza alcanza 0.2764, mientras que el de trabajadores de bajo ingreso es de 0.4636. La gráfica de la I de Moran (Figura 3) muestra que las unidades con bajos niveles de pobreza contribuyen más a la auto-correlación espacial (cuadrante inferior izquierdo), mientras que las AGEB con bajos niveles de los trabajadores pobres tienden a concentrarse tanto como aquellas con altos niveles (cuadrante izquierdo inferior y cuadrante superior derecho).


La diferencia en el grado y la forma en que ambas variables se aglutinan puede reflejar los niveles de privación económica que cada una de ellas refleja: dado que una mide pobreza extrema es probable que ciertas colonias populares aparezcan como zonas de baja pobreza aunque sean zonas donde una alta proporción de los trabajadores gane menos de dos salarios mínimos.
Una imagen más intuitiva y específica de la presencia de clústeres de pobreza es proporcionada por Indicadores Locales de Asociación Espacial (LISA). La estimación de la I de Moran local es:

Estos indicadores miden la asociación espacial entre el valor que una variable asume en la unidad i y los valores que asume en las AGEB vecinas, vecindad definida también a través de la matriz de pesos geográficos. Por ello, LISA ofrece una manera de identificar clústeres locales y de observar no-estacionariedad a través del espacio (Logley y Tobon, 2004). Los mapas de LISA (Figuras 5 y 6, mapas de clústeres) señalan dónde es posible identificar la aglomeración de valores similares. En los mapas los clústeres de valores altos están representados con puntos y los de valores bajos con un gris claro, mientras que los agrupamientos de valores disímiles están marcados con negro (cluster bajo-alto) y rayas (alto/bajo). Este ejercicio permite también identificar si dichos clústeres son estadísticamente significativos a distintos niveles de valor de p, estos niveles están representados con distintas escalas de grises (Figuras 5 y 6, mapas de significancia).


Las AGEB con altos niveles de pobreza forman clústeres en diversas zonas periféricas de la ciudad (puntos en el mapa 5), mientras que las áreas gris claro representan clústeres de baja pobreza. Por otro lado, las áreas coloreadas con negro y a rayas representan zonas donde diversas AGEB con niveles disímiles de pobreza se agrupan (alto-bajo y bajo-alto, respectivamente). LISA, entonces, puede ayudarnos a identificar zonas de alta y baja marginalidad (clústeres de valores similares) y la presencia de casos extremos o atípicos (áreas disímiles) (Logley y Tobon, 2004). La Figura 5 ilustra una mayor concentración de la pobreza y el bienestar de lo que hubiésemos supuesto basados exclusivamente en la Figura 1. Mas, el mapa de LISA muestra la existencia de barrios altamente pobres junto a zonas de muy baja pobreza, ubicación que podría responder a una búsqueda de oportunidades de empleo de los pobres (Portes, 1989). De igual manera muestra la existencia de enclaves de bienestar en zonas altamente pobres, quizá mostrando el desarrollo de fraccionamientos cerrados, lo que ha sido documentado en el caso de Guadalajara (Cabrales, 2001).
El mapa de LISA de los trabajadores de bajo ingreso (Figura 6) ofrece una imagen muy similar. La localización de los clústeres de valores parecidos (puntos gris claro) es básicamente la misma que de los clústeres de pobreza, pero la extensión de los clústeres es mayor en el primer caso. De nuevo, esto podría reflejar las diferencias en el nivel de privación económica que estas variables miden: los bajos salarios están más extendidos que la pobreza extrema.
Por ello, el clúster de puntos (alto-alto) es más grande, mientras que el clúster gris claro mantiene proporciones similares. En suma, el análisis exploratorio con las medidas de I de Moran y LISA nos permiten analizar el grado de concentración geográfica de la pobreza y la riqueza, identificar clústeres dentro de la ciudad y analizar la heterogeneidad por ingreso que caracteriza a las AGEB de Guadalajara.
Modelos de regresión espacial autorregresivos
En el análisis exploratorio anterior, las I de Moran para las variables de pobreza y de bajos ingresos fueron positivas y altamente significativas, lo cual es indicativo de la presencia de autocorrelación espacial. Sin embargo, la I de Moran provee solo una mirada limitada de este fenómeno, ya que los clústeres de valores similares (bajo-bajo, alto-alto) podrían reflejar solo la distribución geográfica de las variables explicativas de la pobreza. Por ejemplo, los clústeres de trabajadores de bajos ingresos en una zona podrían reflejar la aglomeración de trabajadores subempleados.
Sin embargo, es posible que existan otros fenómenos que contribuyen a la formación de clústeres más allá de las características de la población que habita una determinada AGEB. Como se mencionó anteriormente, la dependencia espacial puede emerger como resultado de procesos económicos, sociales o institucionales que contribuyen a la interdependencia entre las unidades de observación. En el caso de la concentración de la pobreza urbana es posible pensar en la operación de los mercados de suelo y vivienda como un ejemplo de procesos que dan lugar a la autocorrelación espacial. Estudios recientes sugieren que las políticas de zonificación y la apertura de suelo estratificada por nivel socioeconómico pueden contribuir a la concentración geográfica de la pobreza y la riqueza (Canseco, 2011). Adicionalmente estudios sobre asentamientos populares muestran que el establecimiento original puede expandirse gracias a la migración de nuevos pobres a las zonas donde hay tierra disponible (Sánchez-Peña, 2009).
Muchas veces dicha expansión se genera por las redes sociales de los habitantes originales quienes informan a familiares y conocidos sobre las oportunidades de suelo en el área. En tales casos uno podría hablar de un efecto de contagio o de aprendizaje entre las unidades vecinas: la probabilidad de un asentamiento pobre en una zona aumentaría las posibilidades de que la AGEB vecina también sea pobre.
Con datos de sección cruzada no es posible dar cuenta de los procesos que llevan a la dependencia espacial entre unidades geográficas, pero es posible identificar la existencia de dicha interacción. Sustantivamente hay dos preguntas: ¿el nivel de pobreza en una AGEB dada refleja solo la composición social de dicha AGEB?, o ¿está influenciado ese nivel de pobreza por los niveles de pobreza en las unidades vecinas? Para examinar la dependencia espacial después de controlar otras características relevantes podemos implementar modelos multivariados de regresión espacial autorregresivo. Más importante aun, si las medidas exploratorias revelan la presencia de dependencia espacial, entonces debemos implementar dichos modelos, porque ignorarla podría comprometer la fiabilidad de nuestro análisis (Anselin, 1992a).
Anselin (1992a) distingue dos tipos de dependencia espacial: una es ruido o ajena para nuestro análisis y la otra es sustantivamente relevante. La primera está en el término del error y viola el supuesto de la no correlación entre los errores en la regresión de mínimos cuadrados. Si ignoramos la autocorrelación del error los estimadores de nuestra regresión serán ineficientes, aunque no sesgados (Anselin, 2002). Es considerada como ruido porque no afectará los coeficientes del modelo y porque solo nos interesa para mejorar nuestras estimaciones. La autocorrelación en el término del error puede ser manejada a través de un Modelo Espacial del Error, que supone que la dependencia espacial encontrada en la variable dependiente es resultado de la distribución geográfica de nuestras variables explicativas y de la autocorrelación del término del error (Anselin, 2002; Baller et al., 2001). Como se puede observar en la ecuación siguiente, el modelo es similar a un modelo de regresión estándar, pero se estima el parámetro λ que calcula el grado de autocorrelación de los errores, dada una matriz de pesos geográficos (W):

Por otro lado, la autocorrelación espacial substantiva se presenta cuando el valor que toma la variable dependiente en cada unidad geográfica está realmente determinado por el valor que dicha variable asume en las unidades vecinas. Es decir, la autocorrelación estará todavía presente después de controlar otras variables explicativas. Si ignoramos este tipo de dependencia espacial, los coeficientes estimados con la regresión de mínimos cuadrados estarán sesgados, con los consecuentes problemas de la estimación y el signo de los coeficientes, la significancia de los mismos y la bondad de ajuste del modelo. La alternativa para modelar este tipo de autocorrelación es el Modelo Espacial Lag, que considera la dependencia espacial introduciendo una variable espacial Lag. De acuerdo con Baller et al. (2001), un Modelo Espacial Lag representa la relación interactiva entre la variable dependiente y las variables independientes en las unidades vecinas. La ecuación siguiente permite entender como se estima un modelo de rezago espacial, donde p es el parámetro espacial de rezago que se estima, W es la matriz de pesos geográficos, Χ es la matriz de covarienates, y ε es el vector de errores no correlacionados:

GeoDa ofrece un camino para determinar qué modelo necesitamos implementar.7 Este software permite estimar una regresión estándar de mínimos cuadrados y una serie de diagnósticos espaciales, con los cuales podemos decidir qué tipo de autocorrelación espacial está presente en nuestros datos y, por tanto, el modelo a utilizar. El Cuadro 1 muestra los resultados para un modelo que estima el nivel de pobreza de las AGEB como una función de la inserción laboral, escolaridad y estructuras familiares, y relación de dependencia prevalente en cada área.8 El modelo aquí implementado no pretende ser exhaustivo sino solo ilustrativo del tipo de análisis a realizar con regresiones espaciales. Lo que buscamos es mostrar hasta dónde nuestros datos sugieren autocorrelación sustantiva o no y cuánto cambian nuestras estimaciones al implementar un modelo autorregresivo espacial.

En nuestro ejemplo, los resultados de la regresión de mínimos cuadrados sugieren que la proporción de trabajadores desempleados, los empleados menos de 32 horas a la semana y la proporción de hogares con jefatura femenina incrementan significativamente los niveles de pobreza por AGEB. Por el contrario, la escolaridad promedio, el trabajo en ocupaciones altamente informales y la relación de dependencia reducen dichos niveles. En general, los resultados se comportan como podría esperarse, aunque llama la atención que ni la proporción de ocupados por cuenta propia ni la proporción de hogares ampliados sean significativas pese a que trabajos previos sugieren que las estructuras familiares extensas están asociadas con la pobreza.
Los exámenes de diagnóstico confirman la presencia de autocorrelación espacial y sugieren que esta se encuentra en el término del error,9 sugiriendo la necesidad de especificar un Modelo Espacial del Error (MEE) que considera este tipo dependencia espacial y mejora la eficiencia de nuestra estimación. El Cuadro 1 compara los resultados del modelo de mínimos cuadrados y el MEE, estos dejan ver las diferencias en los coeficientes son mínimas, aunque la estimación del error estándar mejora tal y como se esperaría en la presencia de autocorrelación en los errores. En nuestros datos ello se traduce en un cambio en la significancia del coeficiente de hogares ampliados, el cual pasa a ser significativo en el MEE, resultado que confirma trabajos previos. Si bien parecería una diferencia menor entre los dos modelos, el MEE muestra una bondad de ajuste mejor, menores errores estándar, y logró identificar el efecto de los arreglos familiares.10 En síntesis, el análisis multivariado sugiere que los clústeres de pobreza encontrados en el análisis exploratorio responden a la distribución geográfica de las variables explicativas incluidas en el modelo y otras no consideradas. La evidencia no sugiere procesos de aprendizaje o contagio entre las unidades o fuerzas estructurales guiando la concentración de la pobreza per se. Sin embargo, esta conclusión debe ser considerada con cuidado. Un análisis completo requeriría observar la distribución de las variables a lo largo del tiempo, para confirmar o refutar la presencia de autocorrelación sustantiva. El análisis anterior muestra una limitación importante del AEDE y de la regresión lineal: incluso cuando es posible detectar dependencia espacial, estos métodos no permiten explicarla. Ambos métodos ofrecen una mirada indirecta a los procesos de interacción entre las unidades geográficas, pero tienen poca capacidad para discriminar qué mecanismos están detrás de ella.
Regresión geográficamente ponderada
Mientras los modelos autorregresivos centralmente modelan la autocorrelación espacial, la regresión geográficamente ponderada (Gwr, por sus siglas en inglés) busca analizar la no estacionariedad de los datos. Así, esta técnica permite explorar si la asociación entre pobreza y sus variables explicativas es constante en toda la ciudad o si se puede identificar variaciones por zonas.
Esto es posible porque una regresión geográficamente ponderada permite la estimación de parámetros locales y no solo globales (Fotheringhamm et al., 1997). Un parámetro local es estimado "tomando prestada" información de las unidades dentro de una distancia previamente establecida, donde las unidades más cercanas tienen mayor peso que las más lejanas (Fotheringham et al., 2001: 52). Como tal, esta técnica cuestiona el supuesto implícito en las regresiones estándar de que un modelo puede aplicarse por igual a toda el área geográfica analizada, cuando en realidad pueden presentarse importantes variaciones tanto en el modelo completo como en la relación específica entre la variable dependiente y algunas de sus variables explicativas (Charlton et al, 2003; Fotheringham et al., 2001). Así, nuestro modelo explicativo podría funcionar mejor en ciertas zonas de la ciudad y algunas variables cobrar mayor importancia en ciertas regiones que en otras o incluso tener efectos opuestos.
En este sentido, Gwr estima un modelo lineal del tipo:

Donde i es la localidad en la cual se miden y e x y para la cual se estiman los parámetros. Mientras que la estimación de los parámetros se obtiene de:

Donde W(I) es la matriz de pesos específicos para la ubicación i, de tal forma que las observaciones cercanas tienen más peso que las observaciones lejanas.
En esta sección se implementa el mismo modelo multivariado que en la sección anterior y se analiza con especial atención cómo cambia en la ciudad el efecto que las variables de inserción laboral tienen sobre los niveles de pobreza. Gwr provee tanto los resultados de la regresión estándar de mínimos cuadrados (aquí llamada global) y los resultados de los cálculos locales. El Cuadro 2 solo presenta los resultados de las estimaciones locales, mismas que muestran cuánto varían los coeficientes a través del espacio.11

Debido a lo grande que sería un archivo con 1 416 regresiones locales, una por cada AGEB, Gwr solo proporciona el resumen de cinco números de su distribución (valor mínimo, primer cuartil, mediana, tercer cuartil y valor máximo). De esta tabla podemos deducir que el valor que los coeficientes asumen en distintas áreas de la ciudad varía importantemente. Por ejemplo, el coeficiente para la variable trabajo por pocas horas llega a tener un valor de -0.085 en algunas zonas, mientras en otras tiene un efecto positivo sobre los niveles de pobreza de hasta 3.97. En cambio, el coeficiente del desempleo varía en su tamaño (entre 11.47 y 26.44), pero siempre tiende a aumentar los niveles de pobreza.
Gwr provee un test formal de Monte Carlo para estimar si la variabilidad espacial de los parámetros es estadísticamente significativa. En nuestro análisis, los resultados muestran que solo dos variables lo son: relación de dependencia y trabajo por cuenta propia. Dicha variabilidad puede ser más fácil de observar si mapeamos las parámetros locales calculados por Gwr. La Figura 7 muestra la variación que el parámetro relación de dependencia asume en Guadalajara. Las gradaciones de grises representan las variaciones en el tamaño del coeficiente de esta variable a lo largo del territorio. Aun cuando esta variable tiene un efecto negativo en todas las zonas de la ciudad, su efecto sobre la pobreza es mayor en el este y sudeste, así como en la zona periférica del extremo noroeste de la metrópoli, las mismas áreas donde fueron claramente identificados clústeres de pobreza.

Por su parte, la Figura 8 presenta los coeficientes locales para la variable de trabajo por cuenta propia, la cual muestra todavía mayor variación. Las gradaciones de grises en el mapa representan el tamaño del coeficiente en el modelo Gwr. Mientras esta variable se asocia con menores niveles de pobreza en las regiones oeste y centro-oeste, en la región este de la ciudad la proporción cuentapropistas se asocia con mayor pobreza.

Esto podría representar la variedad de ocupaciones que se clasifican como "por cuenta propia", reflejando puestos de mejor nivel en ciertas zonas y más precarios en las zonas más pobres.
Gwr también permite estimar cuan bien se ajusta nuestro modelo a los datos, calculando un R2 local. La Figura 9 muestra que nuestro modelo se desempeña mejor en la zona este que en el resto de la ciudad; es decir, que nuestras variables explicativas tienen menos poder predictivo en otras zonas de Guadalajara. Diagnósticos tales como el coeficiente de determinación y el Criterio de Información de Akaike (AIC) sugieren que el modelo local es mejor que el modelo global. Además de la idea de que las variables tienen efectos diferenciados a través de la ciudad, los mapas de Gwr permiten identificar la presencia de regiones geográficas donde se observan cambios discretos en la distribución de las variables (media, varianza) y donde un tipo distinto de relación parece establecerse entre las variables consideradas, diferencias regionales que son conocidas en la literatura como regímenes espaciales. En nuestro caso, la región este de Guadalajara parece constituir un régimen espacial, hipótesis que puede ser explorada con mayor detenimiento utilizando GeoDa y modelos de regresión lineal con regímenes espaciales, los cuales calculan coeficientes específicos para cada subgrupo de los datos (estos modelos pueden implementarse con SpaceStat o R).

Conclusión. Límites y posibles contribuciones del análisis espacial
Los métodos estadísticos que consideran la ubicación y distribución espacial de los procesos sociales están desarrollándose rápidamente, pero aún tienen limitaciones importantes tanto por el avance de los métodos mismos como por la disponibilidad de datos georreferenciados. Tres problemas son frecuentes en el análisis espacial. Primero, los datos georreferenciados disponibles tienden a ser de áreas geográficas administrativamente delimitadas (estados, municipios, localidades, AGEB) que pueden o no ser las más adecuadas para el fenómeno en cuestión. Es probable, por ejemplo, que los mercados de trabajo no sean bien capturados con estas fronteras administrativas, pero sí lo sean las políticas públicas de empleo que utilizan dichas unidades como referencia de planeación (Messner y Anselin, 2002).
De cualquier manera, existe el riesgo de que el fenómeno poblacional estudiado no se ajuste a las unidades geográficas en las cuales la información esté disponible o no ocurra en la escala para la cual tenemos datos. Ello limita las conclusiones que podemos obtener con los métodos anteriormente expuestos. Por ejemplo, es común que el Modelo Espacial del Error sea favorecido por los datos cuando existe dicho desajuste entre los datos disponibles y la "verdadera" dimensión espacial en la que un fenómeno ocurre.
Un segundo problema surge del hecho de que la mayor parte de los métodos se han abocado a modelar datos agregados (por área o polígono) y se corre el riesgo de la "falacia ecológica", es decir de tratar de inferir los comportamientos de los individuos a partir de las características del área en la que viven. Claramente, esto no puede hacerse. Los modelos solo tienen sentido para entender que pasa en el nivel agregado y tratar de inferir comportamientos colectivos (Messner y Anselin, 2002). Es posible, sin embargo, mezclar métodos de análisis espacial con otros que pueden descomponer ambos niveles, por ejemplo, los modelos multinivel (Sampson et al, 1997).
En tercer lugar está el problema sobre la interpretación sustantiva de la autocorrelación o heterogeneidad espacial, particularmente cuando solo tenemos información para un punto en el tiempo. En el caso de la dependencia espacial, solo tendremos mayores certezas con datos longitudinales, ya que con un solo momento en el tiempo no es posible distinguir un efecto espacial aparente de un efecto real de contagio, aprendizaje o spillover (Messner y Anselin, 2002). El análisis de la heterogeneidad es un poco más permisivo al respecto, en este caso el mayor reto es identificar el tipo de variación en el espacio que se observa (continua o discreta) y desarrollar explicaciones de por qué dicha heterogeneidad está presente.
A pesar de estas limitaciones, los métodos de análisis espacial pueden ser de gran utilidad para los estudios de población. Múltiples políticas sociales, como las de combate a la pobreza o mejoras del hábitat urbano, son focalizadas geográficamente, y para ello se hacen supuestos sobre la distribución espacial de su población objetivo, su grado de concentración, intensidad de la pobreza en ciertas regiones o incluso cercanía respecto de los proveedores de servicios educativos o de salud. El análisis espacial exploratorio permite medir dónde y cuán aglomeradas se encuentran las áreas de pobreza, lo que podría mejorar la cobertura de los programas. Idealmente ello podría contribuir en el mediano plazo a disminuir la concentración geográfica de la pobreza, un objetivo deseable dado los estudios que documentan que dicha concentración puede favorecer la estigmatización de sus habitantes y un deterioro mayor de sus condiciones de vida.
Adicionalmente, comprender cómo se interrelacionan los espacios sociales mediante el modelaje de la dependencia espacial puede mejorar nuestro entendimiento de fenómenos clave como en la dinámica demográfica, tal como son los efectos de contagio, difusión o imitación. Por otro lado, los modelos que buscan dar cuenta de la heterogeneidad espacial permiten probar estadísticamente argumentos que han estado presentes en los estudios sociodemográficos a través del tiempo, respecto a las variaciones en las relaciones sociales a lo largo del territorio, por ejemplo, la idea que la pobreza en el sur del país no solo es más alta sino que también refleja condiciones estructurales distintas que las imperantes en el norte del país. Además, ya que pudiésemos identificar que variables influyen más en los niveles de pobreza de cada zona sería, posible desarrollar políticas de pobreza más sensibles y, quizás, más eficientes.
Bibliografía
ANSELIN, L., 1989, What is special about spatial data? Alternative perspectives on spatial data analysis, en Symposium on Spatial Statistics. Past, present and future, Universidad de Siracusa. Siracusa. [ Links ]
ANSELIN, L., 1992, Spatial data analysis with GIS: an introduction to application in the social science, informe de investigación 90-10, University of California, Santa Bárbara. [ Links ]
ANSELIN, L., 1995, Exploring spatial data with Geoda: a workbook, Internet, recuperado de: https://geoda.uiuc.edu/pdf/geodaworkbook.pdf. [ Links ]
ANSELIN, L., 2002, "Under the hood: Issues in the specification and interpretation of spatial regression models", en Agricultural Economics, vol. 27, núm. 3. [ Links ]
ANSELIN, L., 2006, "How (not) to lie with spatial statistics", en American journal of preventive medicine, vol. 30, núm. 25, recuperado de: http://www.ncbi.nlm.nih.gov/pubmed/16458788. [ Links ]
BALLER, R, L. ANSELIN, S. MESSNER, G. DEANE, y D. HAWKINS, 2001, "Structural covariates of U.S. county homicide rates: incorporating spatial effects", en Criminology, vol. 39, núm. 3. [ Links ]
CABRALES, L., 2001, Latinoamerica, paises abiertos, ciudades cerradas, Universidad de Guadalajara/Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura (UNESCO), Guadalajara, México. [ Links ]
CANSECO, B., 2011, Desintegrando la metrópoli: segregación residencial en la periferia de la Zona Metropolitana de la Ciudad de México, tesis de maestría, El Colegio de México (COLMEX), México. [ Links ]
CHARLTON, M., S. FOTHERINGHAM y C. BRUNSDON, 2003, Geographically weighted regression and associated statistics workbook, SummerWorkshop, Santa Bárbara. [ Links ]
CONAPO 2002, Índice de marginación urbana, Consejo Nacional de Población (CONAPO), México. [ Links ]
FOTHERINGHAM, S., Martin CHARLTON y C. BRUNDSDON, 2001, "Spatial variations in school performace: a local analysis using geographically weighted regression", en Geographical & Environmental Modelling, vol. 5, núm. 1. [ Links ]
FOTHERINGHAMM, S., C. MARTIN, y B. CHRIS, 1997, "Measuring spatial variations in relationships with geographically weighted regression", en M. FISCHER y A. GETIS (eds.), Recent developments in spatial analysis: spatial statistics, behaviouralmodelling, and computational intelligence, Berlín. [ Links ]
GARCIA B y O. OLIVEIRA, 2003, "Trabajo e ingreso de los miembros de las familias en el México Metropolitano", en E. DE LA GARZA y C. SALAS (eds.), La situación del trabajo en México 2003, Universidad Autónoma Metropolitana (UAM), Plaza y Valdéz, México. [ Links ]
HAINING, R., 2003, Spatial data analysis: theory and practice, Cambridge University Pres, Londres. [ Links ]
HERNÁNDEZ, D., M. OROZCO, J. CAMACHO, H. LLAMAS, C. CAMACHO, y V. TELLEZ, 2002, "Concentración de hogares en condición de pobreza en el medio urbano", en Cuadernos de Desarrollo Humano núm. 3, Secretaría de Desarrollo Social (SEDESOL), México. [ Links ]
HERNÁNDEZ, J., 2004, "La distribución territorial de la población rural urbanización", en La situación demográfica de México 2003, CONAPO, México. [ Links ]
HOLT, J. y C. LO, 2008, The geography of mortality in the Atlanta metropolitan area, en Computers, Environment and Urban Systems, recuperado de: http://linkinghub.elsevier.com/retrieve/pii/S0198971507000518. [ Links ]
LOBAO, L., G. HOOKS y A. TICKAMYER, 2007, "Introduction. Advancing the sociology of spatial inequality", en The sociology of spatial inequality, State University New York Press, Nueva York. [ Links ]
LOGLEY, P. y C. TOBON, 2004, "Spatial dependence and heterogeneity in patterns of hardship: an intraurban analysis", en Annals of the Association of American Geographers, vol. 94, núm. 3, Londres. [ Links ]
MESSNER y L. ANSELIN, 2002, Spatial analisis of homicida with areal data, Internet, recuperado de: http://sal.uiuc.edu/users/anselin/papers/smla.pdf. [ Links ]
ORD, J. K., 1975, "Estimation methods for models of spatial interaction", en Journal of the American Statistical Association, vol. 70, núm. 349. [ Links ]
PERRET, 2011, A proposal for an alternative spatial weight matrix under consideration of the distribution of economic activity, en Bergische Universitat Wuppertal Schumpeter School of Business and Economics, Wuppertal, Germany. [ Links ]
PORTES, A. , C. DORE-CABRAL y P. LANDOLT, 1997, The urban Caribbean. transition to the new global economy, The John Hopkins University Press, Baltimore. [ Links ]
PORTES, A. y B. ROBERTS, 2005, "The free market city: Latin American urbanization in the years of the neoliberal experiment", en Studies in Comparitiv International Developmet, vol. núm. 1. [ Links ]
PORTES, A., 1989, "Latin American urbanization during years of the crisis", en Latin American Research Review, vol. 24, núm. 3. [ Links ]
ROBERTS, B. R., 1995, The making of citizens, Edward Arnold, Londres. [ Links ]
SALAS, J. 2007, "Vulnerabilidad, pobreza y desastres 'socionaturales' en Centroamérica y el Caribe", en Informes de la Construcción, vol. 59, núm. 508, octubre-diciembre. [ Links ]
SAMPSON R. J., S. RAUDENBUSH y F. EARLS, 1997, "Neighborhoods and violent crime: a multilevel study of collective efficacy", en Science, vol. 277, núm. 5328. [ Links ]
SAMPSON, R., 2009, "Racial stratification and the durable tangle of neighborhood inequality", en The annals of the American Academy of Political and Social Science, vol. 621, núm. 1. [ Links ]
SÁNCHEZ-PEÑA, L., 2009, Segregación residencial, redes y trayectorias laborales en la Ciudad de México, ponencia presentada en Diálogos y Reflexiones en Población, Ciudad y Medio Ambiente 2009, COLMEX, México. [ Links ]
TOBLER W., 1970, "A computer movie simulating urban growth in the Detroit region", en Economic Geography, vol. 46, núm. 2. [ Links ]
VOSS, P., D. LONG, R HAMMER y S FRIEDMAN, 2006, "County child poverty rates in the US: a spatial regression approach", en Population Research and Policy Review, vol. 25, núm. 4. [ Links ]
WEEKS, J. A. GETIS, A. HILL, S. GADALLA y T. RASHED, 2004, "The fertility transition in Egypt: intraurban patterns in Cairo", en Annals of the Association of American Geographers, vol. 94, núm. 1. [ Links ]
WILSON, F., 1987, The truly disadvantaged: the inner city, the underclass, and public policy, University of Chicago Press, Chicago. [ Links ]
WOOLDRIDGE, J., 2001, Econometric analysis of cross section and panel data, The Instituto Tecnológico de Massachusetts (MIT) Press, Boston. [ Links ]
1 Imaginemos, por ejemplo, que el patrón espacial de las tasas de fecundidad municipal fuese distinto, de tal forma que los municipios de las zonas metropolitanas no tuviesen valores bajos similares —como ocurre hoy en día— sino que estos valores estuvieran aleatoriamente distribuidos a través de México. En ese caso la media y la varianza de las tasas de fecundidad serían las mismas, pero las conclusiones a las que llegaríamos sobre la relación entre urbanización, metropolización y fecundidad serían notablemente distintas.
2 Dicha variable está incluida en la base de datos Regiones Socioeconómicas de México, disponible en línea http://www.inegi.gob.mx/est/contenidos/espanol/sistemas/regsoc/default.asp?
3 Programa disponible en http://geodacenter.asu.edu/ (último acceso por la autora 6 de noviembre 2011).
4 Geographically Weighted Regression por su nombre en inglés. Información sobre el software se puede obtener en http://ncg.nuim.ie/ncg/GWR/index.htm (último acceso por la autora en 5 Diciembre 2011).
5 Es posible establecer distintas matrices de pesos geográficos donde la conectividad entre las unidades de observación puede estar dada por la continuidad o adyacencia y en otras está definida por la distancia entre las unidades. Más recientemente se ha propuesto generar matrices de pesos geográficos en función de su conectividad social (flujos migratorios, intercambios comerciales, etcétera) (Perret, 2011).
6 Ambos serían significativos con un valor de p 0.0001. El test de significancia se realiza contra la hipótesis de distribución espacial aleatoria de las unidades, una hipótesis no muy restrictiva en el caso de los fenómenos sociales.
7 GeoDa también ofrece otra serie de diagnósticos sobre la presencia de heteroscedasticidad, sin embargo no tiene capacidad para modelar este efecto espacial de manera directa. Una posibilidad es hacerlo con SpaceStat, software comercial que también fue desarrollado por Luc Anselin, creador de GeoDa. En nuestro modelo se detectó la presencia de heteroscedasticidad lo que implica que la autocorrelación espacial detectada podría estar contaminada por ella.
8 Los modelos espaciales fueron calculados con la matriz de pesos geográficos tipo reina, de primer orden de contigüidad, la misma utilizada para el cálculo de LISA e I de Moran. La variable dependiente fue transformada a Logit (p/1/p) con el fin de asegurar que los valores predichos cayeran dentro del rango 0 y 1 y asegurar la confiabilidad del modelo.
9 La regla es escoger el modelo con el valor del multiplicador de Lagrange más grande y significativo.
10 A pesar de que la serie de diagnósticos espaciales sugiere que el MEE es el modelo más adecuado, el Cuadro 1 muestra los resultados para el Modelo Lag, solo con propósitos ilustrativos. El tamaño, signo y significancia de los coeficientes en este último modelo no son muy distintos de la regresión de mínimos cuadrados, lo que es de esperarse, ya que nuestros datos no muestran la presencia de autocorrelación sustantiva.
11 Los resultados de la regresión estándar de mínimos cuadrados generados por Gwr son los mismos que los de GeoDa y están reportados en el Cuadro 1.
Información sobre la autora:
Landy Sánchez Peña. Es doctora en Sociología por la Universidad de Wisconsin-Madison. Actualmente es profesora e investigadora del Centro de Estudios Demográficos, Urbanos y Ambientales de El Colegio de México, así como coordinadora de la Maestría en Demografía de dicha institución. Ha trabajado y publicado sobre ajuste estructural, mercados de trabajo y desigualdad urbana. Entre sus trabajos recientes se encuentra Rural population trends in México: demographic and labor changes en coautoria con Edith Pachecho y publicado en Katherine Curtis y Laszlo Kulcsar (eds.) International Handbook of Rural Demography, Springer; así como el artículo "¿Viviendo cada vez más separados? Una aproximación multigrupo a la segregación residencial en la Ciudad de México 1990-2005" publicado por Estudios Demográficos y Urbanos, 2012. Sus líneas de investigación actuales son cambio demográfico y patrones de consumo de los hogares urbanos, así como el análisis espacial de la desigualdad. Dirección electrónica: lsanchez@colmex.mx

