











 nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introducción
La simulación, el modelo y el sistema son conceptos interrelacionados que se utilizan en diversas disciplinas para entender, analizar y predecir el comportamiento de sistemas complejos en el mundo real.
El concepto de simulación se refiere al proceso de imitar el comportamiento de un sistema en tiempo real utilizando un modelo computacional. La simulación se utiliza para predecir el comportamiento de un sistema en situaciones en las que no es posible realizar experimentos prácticos debido a limitaciones de tiempo, costo o éticas.
Por ejemplo, se pueden simular escenarios de terremotos para predecir el daño potencial en edificios, o se pueden simular sistemas de transporte para evaluar el impacto de cambios en la infraestructura. Las simulaciones pueden variar desde simples modelos matemáticos hasta modelos complejos que incorporan múltiples variables y factores ambientales.
El concepto de modelo se refiere a una representación simplificada y abstracta de un sistema real que se utiliza para comprender y predecir su comportamiento. Los modelos pueden ser matemáticos, físicos o conceptuales, y se utilizan en una amplia variedad de disciplinas para representar sistemas complejos.
Por ejemplo, los modelos de árboles se utilizan en ecología para entender cómo los diferentes factores ambientales afectan el crecimiento de los árboles. Los modelos también se utilizan en la economía para predecir el comportamiento de los mercados financieros y en la ingeniería para diseñar sistemas de control y de producción.
El concepto de sistema se refiere a un conjunto de elementos interrelacionados que interactúan entre sí para lograr un objetivo común. Los sistemas pueden ser físicos, biológicos, sociales o tecnológicos, y se pueden estudiar a diferentes escalas, desde sistemas moleculares hasta sistemas planetarios.
Los sistemas se caracterizan por tener entradas, procesos internos y salidas. Por ejemplo, un sistema de producción de automóviles puede tener entradas como materias primas y energía, procesos internos como ensamblaje y pruebas, y salidas como automóviles completos.
Las relaciones entre la simulación, el modelo y el sistema son complejas y multifacéticas. La simulación es una herramienta que se utiliza para evaluar la precisión de un modelo al comparar las predicciones de la simulación con los datos reales del sistema.
Los modelos se utilizan para representar y simplificar los sistemas complejos, lo que permite una comprensión más profunda de su comportamiento. La simulación y el modelo también pueden utilizarse juntos para probar diferentes escenarios y variables, lo que permite la evaluación de diferentes estrategias y decisiones.
En conclusión, la simulación, el modelo y el sistema son conceptos interrelacionados que se utilizan para entender y predecir el comportamiento de sistemas complejos en el mundo real.
La simulación es una herramienta valiosa para evaluar la precisión de un modelo, mientras que el modelo se utiliza para simplificar y representar el comportamiento de un sistema.
La comprensión de estas relaciones puede ayudar a los investigadores a desarrollar modelos y simulaciones más precisos y útiles para una amplia variedad de disciplinas.
Experimentar con un sistema real implica trabajar con un objeto o proceso físico en el mundo real, mientras que experimentar con un modelo de un sistema implica trabajar con una representación matemática o simulación computarizada del objeto o proceso. A continuación, se presentan algunas diferencias entre experimentar con un sistema real y experimentar con un modelo de un sistema:
Control: Al trabajar con un modelo de un sistema, es posible controlar y manipular las variables de entrada con mayor precisión y facilidad que en un sistema real. En un sistema real, las variables pueden ser más difíciles de medir y controlar debido a la complejidad del entorno y la naturaleza impredecible de algunas variables.
Costo: Experimentar con un modelo de un sistema suele ser más económico que experimentar con un sistema real. En el caso de los sistemas físicos, pueden requerirse grandes cantidades de recursos, materiales y mano de obra para llevar a cabo experimentos, mientras que en los modelos se requieren recursos de computación y software.
Tiempo: El tiempo necesario para realizar experimentos con sistemas reales puede ser mucho mayor que el necesario para experimentar con modelos de sistemas. En el caso de los modelos, se pueden realizar simulaciones en paralelo y experimentar con diferentes configuraciones de variables de entrada en cuestión de minutos u horas, mientras que los sistemas reales pueden tardar días o incluso semanas en realizar una sola prueba.
Precisión: Los modelos de sistemas pueden ser más precisos que los sistemas reales en ciertos casos, ya que es posible ajustar las variables y los parámetros para obtener resultados más precisos. Además, los modelos pueden proporcionar resultados consistentes y repetibles que pueden ser difíciles de lograr en un sistema real debido a la variabilidad inherente.
Limitaciones: Los modelos de sistemas pueden ser limitados por la calidad y la precisión de los datos de entrada y por la complejidad del sistema en sí. Además, los modelos no siempre pueden capturar todas las interacciones y complejidades de un sistema real, lo que puede llevar a resultados inexactos. En el caso de los sistemas reales, puede haber limitaciones en cuanto a lo que es posible medir y controlar, lo que puede afectar la precisión y la validez de los resultados.
En resumen, experimentar con un modelo de un sistema puede ser más económico, rápido y controlable que experimentar con un sistema real, aunque los modelos pueden tener limitaciones y no siempre pueden capturar todas las complejidades de un sistema real.
Por otro lado, experimentar con sistemas reales puede proporcionar resultados más precisos y representativos del mundo real, aunque puede ser más costoso y requerir más tiempo.
Experimentar con un modelo físico y un modelo matemático son dos formas de realizar experimentos en ingeniería y ciencias físicas, y aunque ambas tienen como objetivo estudiar sistemas, hay algunas diferencias importantes entre ellas:
Naturaleza del modelo: Un modelo físico es una representación tangible de un sistema, que se construye utilizando materiales físicos y herramientas de fabricación. Por otro lado, un modelo matemático es una representación abstracta de un sistema que se construye utilizando ecuaciones y fórmulas matemáticas.
Flexibilidad: Un modelo matemático es más flexible que un modelo físico, ya que se pueden realizar cambios rápidamente y modificar la representación matemática según se necesite. En cambio, los modelos físicos pueden requerir más tiempo y recursos para hacer cambios en la construcción y en la configuración del sistema.
Costo: Los modelos físicos pueden ser más costosos de construir y mantener que los modelos matemáticos, ya que requieren materiales, herramientas y espacio físico para su construcción y pruebas. En cambio, los modelos matemáticos pueden ser más económicos de construir y pueden ser ejecutados en cualquier computadora.
Precisión: Los modelos físicos pueden proporcionar mediciones precisas de un sistema real, ya que utilizan sensores físicos y herramientas de medición para recopilar datos. Por otro lado, los modelos matemáticos pueden proporcionar una alta precisión si se conocen con exactitud los parámetros de entrada del modelo, aunque pueden estar sujetos a errores de aproximación.
Alcance: Los modelos matemáticos son más fáciles de escalar que los modelos físicos. Por ejemplo, un modelo matemático de un sistema hidráulico se puede utilizar para predecir el comportamiento de sistemas a gran escala, mientras que un modelo físico tendría que ser construido específicamente para la escala deseada.
En resumen, tanto los modelos físicos como los modelos matemáticos tienen sus ventajas y desventajas, y la elección del modelo dependerá de los objetivos del experimento y del sistema que se esté estudiando.
Los modelos físicos son más adecuados cuando se requiere una alta precisión en la medición, y los modelos matemáticos son más adecuados cuando se requiere una mayor flexibilidad en la configuración del sistema y una mayor capacidad de escalar el modelo.
Una solución analítica y una simulación son dos herramientas importantes en la ingeniería y las ciencias físicas. A continuación, se presentan algunas diferencias entre una solución analítica y una simulación:
Naturaleza de la solución: Una solución analítica es una solución matemática cerrada que se puede obtener a partir de ecuaciones y fórmulas matemáticas. Por otro lado, una simulación es una representación numérica del sistema que se obtiene mediante el uso de herramientas de simulación computacional.
Precisión: Una solución analítica puede ser más precisa que una simulación, ya que se puede obtener una solución exacta si se conocen todas las variables y parámetros del sistema. Sin embargo, en la práctica, esto no siempre es posible, y las soluciones analíticas pueden estar sujetas a errores de aproximación y suposiciones simplificadoras. Las simulaciones, por otro lado, pueden proporcionar resultados más precisos si se conocen con precisión los parámetros de entrada y se han validado las suposiciones utilizadas en el modelo.
Flexibilidad: Una solución analítica puede ser menos flexible que una simulación, ya que las ecuaciones y las fórmulas matemáticas pueden ser complicadas y difíciles de modificar. En cambio, una simulación puede ser más flexible, ya que los parámetros del modelo se pueden modificar y ajustar para ver cómo afectan al comportamiento del sistema.
Escalabilidad: Las soluciones analíticas pueden ser más difíciles de escalar que las simulaciones, ya que las ecuaciones matemáticas pueden volverse más complejas a medida que se aumenta la complejidad del sistema. Las simulaciones pueden ser más fáciles de escalar, ya que se pueden ejecutar en diferentes configuraciones de hardware y software para manejar sistemas más grandes y complejos.
Costo: En general, una solución analítica puede ser más económica que una simulación, ya que se requiere menos recursos computacionales y menos tiempo de desarrollo. Sin embargo, esto depende del problema que se esté resolviendo y de la complejidad de las ecuaciones y los modelos matemáticos involucrados.
En resumen, tanto las soluciones analíticas como las simulaciones tienen ventajas y desventajas, y la elección de una herramienta dependerá de los objetivos del problema y de la naturaleza del sistema que se esté estudiando.
Las soluciones analíticas son útiles cuando se puede obtener una solución exacta o se necesitan resultados rápidos y simples. Las simulaciones son útiles cuando se necesita una mayor flexibilidad y precisión en la modelización del sistema, especialmente cuando la complejidad del sistema es alta y la solución analítica no es factible.
2. Diseño de un modelo de simulación
Para el estudio de cualquier sistema, vemos que el diseño de un modelo de simulación puede ser un proceso complejo, que requiere de conocimientos en distintas áreas, como la modelación matemática, la programación y la ingeniería de sistemas. A continuación, se presentan algunas etapas clave en el diseño de un modelo de simulación:
Identificación del sistema: Se debe definir claramente qué sistema se quiere modelar y cuáles son los objetivos de la simulación. Se debe considerar cuál es el alcance de la simulación y qué aspectos del sistema se quieren analizar.
Recopilación de datos: Se deben recopilar datos relevantes sobre el sistema, como tiempos de procesamiento, capacidades de los equipos, demandas de los clientes, entre otros. Estos datos pueden ser obtenidos a través de mediciones en el sistema real o a través de información de fuentes secundarias.
Diseño del modelo: Se debe definir un modelo matemático del sistema, que permita representar los procesos y comportamientos del sistema en cuestión. Esto implica la selección de las variables relevantes, las relaciones entre ellas y las reglas que gobiernan su comportamiento.
Validación del modelo: Una vez que se ha definido el modelo, se debe verificar que es adecuado para representar el sistema real. Esto se puede hacer comparando los resultados de la simulación con los datos del sistema real, o a través de la validación cruzada con otros modelos similares.
Implementación del modelo: El modelo debe ser implementado en un software de simulación, que permita su ejecución y la obtención de resultados. En esta etapa se deben definir los parámetros y las condiciones iniciales del modelo.
Ejecución de la simulación: Se deben ejecutar múltiples simulaciones, variando los parámetros de entrada del modelo y analizando los resultados obtenidos. Se pueden utilizar técnicas de análisis estadístico para obtener conclusiones más robustas.
Validación de los resultados: Los resultados de la simulación deben ser validados en base a los objetivos establecidos previamente. Se debe analizar si el modelo es adecuado para realizar predicciones y si las conclusiones obtenidas son coherentes con el sistema real.
Comunicación de los resultados: Finalmente, se deben comunicar los resultados de la simulación, a través de informes técnicos, gráficos o presentaciones. Es importante que los resultados sean comprensibles para los distintos actores involucrados en el sistema, como gerentes, operarios o especialistas técnicos.
Un modelo de simulación se puede clasificar en discreto o continuo. En el primer caso es cuando se tienen variables de tipo discreto, en donde se manejan números enteros como por ejemplo líneas de espera. En el segundo caso es cuando se tienen las variables de tipo continuo, en donde se manejan números reales como estudio de fluidos, intercambio de calor.
Adicionalmente un modelo de simulación se puede clasificar en determinista cuando en el modelo se utilizan variables cuyos valores no se ven afectados por variaciones aleatorias y se conocen con exactitud. Por ejemplo, el modelo de inventarios conocido como lote económico.
En caso contrario se clasifica como aleatorio o estocástico, que es cuando en el modelo se utilizan variables cuyos valores sufren modificaciones aleatorias con respecto a un valor promedio; dichas variaciones pueden ser manejadas mediante distribuciones de probabilidad.
Un buen número de estos modelos se pueden encontrar en la teoría de líneas de espera. En este caso es necesario crear un modelo de simulación que imite el comportamiento de las variables.
3. Simulación con variables aleatorias
Las variables aleatorias de entrada son aquellas que representan las incertidumbres en un modelo de simulación. Estas variables pueden incluir factores como la variabilidad en los tiempos de llegada de clientes, la variabilidad en la duración de los procesos, la variabilidad en las tasas de fallas de los equipos, entre otros.
La importancia de las variables aleatorias de entrada radica en que su inclusión adecuada en el modelo es esencial para que la simulación se aproxime a la realidad. Si se ignoran o se subestiman las incertidumbres en el modelo, se corre el riesgo de generar resultados poco realistas y poco confiables.
Por ejemplo, si se está simulando el tiempo de espera de los clientes en una tienda, es importante considerar la variabilidad en los tiempos de llegada de los clientes, la variabilidad en el tiempo que cada cliente tarda en hacer sus compras, y la variabilidad en el tiempo que los cajeros tardan en procesar las transacciones.
Si se ignora la variabilidad en alguna de estas variables, los resultados simulados podrían ser muy diferentes a los observados en la realidad.
En resumen, para que un modelo de simulación se aproxime a la realidad, es crucial identificar y modelar adecuadamente las variables aleatorias de entrada que representan las incertidumbres en el sistema o proceso que se está simulando.
Cómo determinar el tipo de distribución que tienen los datos de entrada de un sistema
Para determinar el tipo de distribución que tienen un conjunto de datos, se pueden utilizar diversas técnicas estadísticas y gráficas. Las más comunes son: histograma, gráfico de probabilidad normal, gráfico de caja y bigotes, prueba de bondad de ajuste y análisis de momentos. La prueba de bondad de ajuste es más utilizada y consiste en determinar si los datos se ajustan a una distribución teórica. Si el valor p de la prueba es mayor que el nivel de significancia elegido (generalmente 0.05), se puede concluir que los datos se ajustan a la distribución teórica.
Prueba de Bondad de Ajuste
La prueba de bondad de ajuste es una técnica estadística utilizada para evaluar si una muestra de datos proviene de una distribución de probabilidad específica o no. En otras palabras, se utiliza para determinar si una muestra de datos se ajusta adecuadamente a una distribución teórica conocida.
El objetivo de la prueba de bondad de ajuste es determinar si la muestra de datos se ajusta a la distribución teórica de interés. Si la muestra de datos no se ajusta a la distribución teórica, esto puede indicar que la distribución teórica no es la más adecuada para modelar los datos o que los datos son insuficientes para hacer una conclusión definitiva.
Existen diferentes métodos para realizar una prueba de bondad de ajuste, que varían en su complejidad y en los supuestos subyacentes. Algunos de los métodos más comunes son la prueba de chi-cuadrado, la prueba de Kolmogórov-Smirnov, la prueba de Anderson-Darling y la prueba de Shapiro-Wilk.
Es importante destacar que la prueba de bondad de ajuste no garantiza que la distribución teórica sea la más adecuada para modelar los datos, pero puede proporcionar evidencia para apoyar o refutar la hipótesis de que la muestra de datos proviene de una distribución teórica específica. Además, la prueba de bondad de ajuste se utiliza a menudo en la validación de modelos estadísticos y de simulación, donde es necesario comprobar si los datos simulados se ajustan adecuadamente a la distribución teórica asumida.
Prueba de Anderson-Darling
La prueba de Anderson-Darling es una prueba de bondad de ajuste que se utiliza para determinar si un conjunto de datos proviene de una distribución teórica específica, como la distribución normal, exponencial o uniforme, entre otras. Es una prueba más poderosa que la prueba de Kolmogórov-Smirnov para muestras grandes y puede detectar diferencias más sutiles entre la distribución teórica y los datos observados.
La prueba de Anderson-Darling se basa en el cálculo de una estadística de prueba que mide la discrepancia entre la función de distribución empírica de los datos y la función de distribución acumulada de la distribución teórica. Cuanto mayor sea el valor de la estadística de prueba, mayor será la evidencia en contra de la hipótesis nula de que los datos provienen de la distribución teórica.
El resultado de la prueba de Anderson-Darling es un valor de estadística de prueba y un valor p asociado que indica la probabilidad de que los datos provengan de la distribución teórica. Si el valor p es menor que un nivel de significancia previamente elegido (por ejemplo, 0.05), se rechaza la hipótesis nula y se concluye que los datos no siguen la distribución teórica.
Si el valor p es mayor que el nivel de significancia, no se puede rechazar la hipótesis nula y se concluye que los datos siguen la distribución teórica.
Es importante tener en cuenta que la prueba de Anderson-Darling requiere que los datos sean independientes e idénticamente distribuidos (IID) y que la distribución teórica se especifique de antemano. Además, la prueba puede ser sensible a la elección de los parámetros de la distribución teórica y a la presencia de valores atípicos en los datos.
Por lo tanto, se recomienda utilizar la prueba de Anderson-Darling en combinación con otras técnicas para evaluar la distribución de los datos y tener en cuenta el contexto y conocimiento del problema para interpretar los resultados. El procedimiento general de la prueba es:
Obtener n datos de la variable aleatoria a analizar.
Calcular la media y la varianza de los datos.
Ordenar los datos en forma ascendente Yi para i=1, 2,…, n.
Ordenar los datos en forma descendente Yn+1-i para i=1, 2,…. N.
Establecer de manera explícita la hipótesis nula, al proponer una distribución de probabilidad.
Calcular la probabilidad esperada acumulada para cada número Yi PEA(Yi) y la probabilidad esperada acumulada para cada número Yn+1-i PEA(Yn+1-i) a partir de la función de probabilidad propuesta.
Calcular el estadístico de prueba
Ajustar el estadístico de prueba de acuerdo con la distribución de probabilidad propuesta
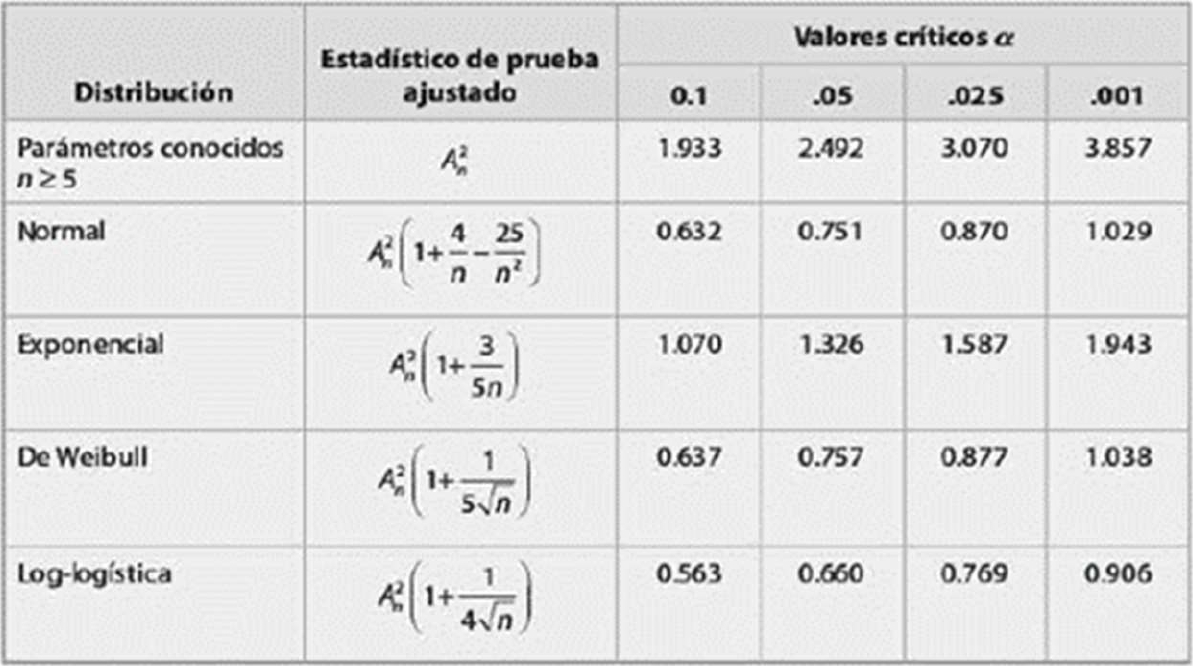
Definir el nivel de significancia de la prueba αi y determinar su valor crítico αn según tabla anexa.
Comparar el estadístico de prueba con el valor crítico. Si el estadístico de prueba es menor que el valor critico no se puede rechazar la hipótesis nula.
Prueba de Kolmogórov-Smirnov
La prueba de Kolmogórov-Smirnov es una técnica estadística utilizada para evaluar si una muestra de datos proviene de una distribución de probabilidad específica. En otras palabras, se utiliza para determinar si una muestra de datos se ajusta adecuadamente a una distribución teórica conocida.
La prueba de Kolmogórov-Smirnov se basa en la comparación de la función de distribución empírica (FDE) de los datos con la función de distribución teórica (FDT) correspondiente. La FDE es una estimación de la FDT a partir de los datos observados, mientras que la FDT se conoce a priori.
La prueba de Kolmogórov-Smirnov calcula la distancia máxima (D) entre la FDE y la FDT, y se utiliza para determinar si los datos se ajustan adecuadamente a la distribución teórica. Si la distancia máxima es pequeña, entonces los datos se ajustan bien a la distribución teórica. Por el contrario, si la distancia máxima es grande, entonces los datos no se ajustan bien a la distribución teórica.
La prueba de Kolmogórov-Smirnov se utiliza comúnmente en la estadística para evaluar la bondad de ajuste de una distribución teórica a los datos observados. También se utiliza en la validación de modelos estadísticos y de simulación para determinar si los datos simulados se ajustan adecuadamente a la distribución teórica asumida.
Es importante tener en cuenta que la prueba de Kolmogórov-Smirnov asume que los datos son independientes e idénticamente distribuidos (IID) y que la distribución teórica es continua. Si los datos no cumplen con estos supuestos, entonces la prueba puede no ser adecuada y se deben considerar otras pruebas de bondad de ajuste. El procedimiento general de la prueba es:
Obtener al menos 30 datos de la variable aleatoria a analizar.
Calcular la media y la varianza de los datos
Crear un histograma de m = √n intervalos, y obtener la frecuencia observada en cada intervalo Oi.
Calcular la probabilidad observada en cada intervalo POi = Oi/n, esto es, dividir la frecuencia observada Oi entre el número total de datos n.
Acumular las probabilidades POi para obtener la probabilidad observada hasta el i-ésimo intervalo, POAi.
Establecer de manera explícita la hipótesis nula, para esto se propone una distribución de probabilidad que se ajuste a la forma del histograma.
Calcular la probabilidad acumulada para cada intervalo, PEAi, a partir de la fusión de probabilidad propuesta.
Calcular el estadístico de prueba c = max |PEAi – POAi| para i=1,2,3…k,…m.
Definir el nivel de significancia de la prueba α, y determinar el valor crítico de la prueba Dα,n, como muestra la gráfica.
Comparar el estadístico de prueba con el valor crítico. Si el estadístico de prueba es menor que el valor crítico no se puede rechazar la hipótesis nula.
Prueba de Kolmogórov-Smirnov vs Anderson Darling
Tanto la prueba de Kolmogórov-Smirnov como la prueba de Anderson-Darling son pruebas de bondad de ajuste utilizadas para evaluar si una muestra de datos proviene de una distribución de probabilidad específica.
La principal diferencia entre estas dos pruebas es que la prueba de Anderson-Darling es más sensible a las desviaciones en la cola de la distribución, mientras que la prueba de Kolmogórov-Smirnov es más sensible a las desviaciones en el centro de la distribución.
La prueba de Anderson-Darling utiliza una medida de distancia basada en la función de distribución empírica (FDE), al igual que la prueba de Kolmogórov-Smirnov, pero utiliza pesos diferentes para cada punto de datos, lo que hace que sea más sensible a las desviaciones en la cola de la distribución. La prueba de Kolmogórov-Smirnov, por otro lado, se basa en la distancia máxima entre la FDE y la función de distribución teórica (FDT) y es más adecuada para detectar desviaciones en el centro de la distribución. En resumen, la elección entre la prueba de Kolmogórov-Smirnov y la prueba de Anderson-Darling dependerá de la forma de la distribución de los datos y de la ubicación de las desviaciones en relación con la distribución teórica.
Es recomendable realizar ambas pruebas para tener una evaluación más completa de la bondad de ajuste de la distribución teórica a los datos observados.
Aplicaciones para hacer las pruebas de bondad de ajuste de un conjunto de datos
Stat Fit es una herramienta de ProModel, un software de simulación empresarial utilizado para modelar, analizar y optimizar sistemas complejos. Stat Fit es una función dentro de ProModel que se utiliza para ajustar modelos de distribución de probabilidad a los datos históricos o a los datos de entrada de un modelo de simulación.
Con Stat Fit, los usuarios pueden seleccionar una distribución de probabilidad de una amplia variedad de opciones, incluyendo distribuciones continuas y discretas, y luego ajustar los parámetros de la distribución a los datos observados.
La herramienta utiliza varios métodos de ajuste, como el método de máxima verosimilitud y el método de los momentos, para encontrar los parámetros óptimos de la distribución.
Una vez que se ha ajustado la distribución, los usuarios pueden utilizarla para generar datos aleatorios que se ajusten a la distribución ajustada.
Estos datos se pueden utilizar para realizar análisis de sensibilidad y simulaciones en ProModel, lo que permite a los usuarios evaluar diferentes escenarios y tomar decisiones informadas. La herramienta Stat Fit de ProModel es una herramienta útil para ajustar modelos de distribución de probabilidad a los datos y generar datos aleatorios que se ajusten a la distribución.
Esto permite a los usuarios modelar sistemas complejos y tomar decisiones informadas basadas en los resultados de la simulación. Esta herramienta utiliza la Prueba de Kolmogórov-Smirnov y la prueba de Anderson Darling.
Generadores de variables aleatorias
Una vez que se ha determinado el tipo de distribución que tienen los datos de entrada, es necesario generar datos aleatorios de entrada con la distribución que tienen los datos, como se presenta en Fig. 4 y Fig. 5.




Generadores de variables aleatorias muestra una tabla con los generadores más comunes.
4. Análisis de resultados
La validación y la verificación son procesos críticos en el desarrollo de modelos de simulación porque garantizan que el modelo se ajuste a su propósito y sea confiable para su uso.
Estos procesos también ayudan a identificar errores y deficiencias en el modelo, lo que permite corregirlos y mejorar la precisión y la calidad de los resultados.
La validación se refiere al proceso de asegurarse de que el modelo simula de manera precisa el comportamiento del sistema real. Esto se logra mediante la comparación de los resultados del modelo con los datos reales, los resultados de otros modelos similares y los resultados esperados de la teoría. La validación es importante porque un modelo no validado puede generar resultados inexactos y llevar a decisiones equivocadas.
La verificación, por otro lado, se refiere al proceso de asegurarse de que el modelo se haya construido correctamente y que sea confiable para su uso. Esto se logra mediante la revisión y la prueba del modelo para detectar y corregir errores, y garantizar que el modelo esté diseñado de manera coherente con los requisitos y especificaciones del usuario. La verificación es importante porque un modelo no verificado puede contener errores y ser inadecuado para su propósito.
La validación y la verificación son procesos críticos para garantizar la precisión y la calidad de los resultados de un modelo de simulación. La validación asegura que el modelo simule de manera precisa el comportamiento del sistema real, mientras que la verificación asegura que el modelo se haya construido correctamente y sea confiable para su uso. Un modelo validado y verificado puede ayudar a tomar decisiones informadas y lograr resultados positivos.
Algunos de los aspectos que es necesario tomar en cuenta en la validación son: recopilar datos reales, definir los criterios de validación para comparar con los datos reales como error absoluto medio o error cuadrático o correlación, ejecutar la simulación y comparar los datos simulados con los datos reales, realizar un análisis de sensibilidad para determinar si al realizar cambios en el modelo los resultados se comportan como en la realidad y finalmente ajustar el modelo de simulación en caso de que sea necesario.
Análisis de sensibilidad
El análisis de sensibilidad ayuda a identificar qué variables o parámetros tienen el mayor impacto en los resultados de la simulación, lo que permite enfocar los esfuerzos en la mejora de la precisión de esos parámetros. También puede ayudar a identificar las incertidumbres y las limitaciones en el modelo de simulación.
Existen diferentes técnicas de análisis de sensibilidad, como el análisis de varianza (ANOVA), el análisis de sensibilidad univariante y multivariante, y la simulación de Monte Carlo. En general, estas técnicas implican la ejecución de la simulación con diferentes valores de los parámetros de entrada y la comparación de los resultados para evaluar cómo cambian los resultados a medida que cambian los parámetros de entrada.
El análisis de sensibilidad puede ser útil para tomar decisiones informadas en áreas como la planificación, el diseño y la toma de decisiones. Por ejemplo, en un modelo de simulación de gestión de inventario, el análisis de sensibilidad puede ayudar a determinar cuál es el nivel óptimo de inventario que minimiza los costos y maximiza los beneficios, y cuál es la sensibilidad de los resultados a los cambios en los costos de los materiales o los plazos de entrega.
Los resultados de una simulación dependen de la distribución de probabilidad de las variables aleatorias. Los intervalos de confianza en una simulación nos permiten evaluar la precisión y la incertidumbre asociadas con nuestras estimaciones y predicciones, lo que puede ser útil para tomar decisiones informadas basadas en los resultados de la simulación.
El intervalo de confianza cuando la variable aleatoria sigue una distribución normal es calculado con la siguiente formula:
En el caso de que la variable aleatoria siga otro tipo de distribución el intervalo de confianza es relativamente más amplio y se calcula como:
en donde:
r= número de réplicas,
α= nivel de rechazo,
s =
Para que el resultado de una variable aleatoria llegue al estado estable en una simulación no terminal o de estado estable, es decir, que los resultados de la simulación se estabilizan y la longitud de las réplicas ya no tiene un impacto significativo en los resultados.
En una simulación, la longitud de las réplicas se refiere a la duración de cada ejecución independiente de la simulación. Una réplica se ejecuta para generar un conjunto de datos de salida que se utiliza para analizar el comportamiento del sistema simulado.
La longitud de las réplicas debe ser determinada con cuidado, ya que puede tener un impacto significativo en los resultados de la simulación. Si las réplicas son demasiado cortas, puede que no se capturen adecuadamente los efectos estocásticos o aleatorios del sistema y los resultados pueden ser poco confiables.
Si las réplicas son demasiado largas, la simulación puede requerir un tiempo de computación excesivo y puede ser difícil de manejar en términos de almacenamiento de datos y análisis.
La longitud óptima de las réplicas depende del sistema que se está simulando, de los objetivos de la simulación y de la precisión deseada en los resultados. En general, se recomienda que la longitud de las réplicas sea lo suficientemente larga como para capturar los efectos estocásticos importantes del sistema, pero lo suficientemente corta como para no requerir un tiempo de computación excesivo.
Una forma común de determinar la longitud óptima de las réplicas es realizar un análisis de sensibilidad para evaluar cómo varían los resultados de la simulación en función de la longitud de las réplicas.
Esto permite determinar el punto en el que los resultados de la simulación se estabilizan y la longitud de las réplicas ya no tiene un impacto significativo en los resultados.
En el caso de que los datos tengan una distribución normal, el tamaño de la corrida de la simulación se calcula con la siguiente formula:
Cuando la suposición de normalidad en los datos no existe, la longitud de la réplica se calcula así:
5. Caso práctico
En una empresa zacatecana de manufactura se realizó un estudio de líneas de espera en el área de inspección. Se tomó el tiempo entre llegadas de las piezas y el tiempo que transcurría durante la inspección de cada una. Considerando una muestra de 50 piezas se tienen los siguientes datos:
Luego de la prueba de bondad de ajuste tenemos los siguientes resultados para el tiempo entre llegadas. Es importante señalar que los datos se redondearon a 4 dígitos después del punto decimal para mostrarlos, sin embargo, en la realidad no se muestran así en ambos casos.
La prueba de bondad de ajuste para el tiempo durante la inspección: Generamos el modelo de simulación, en donde el tiempo entre llegadas tiene una distribución exponencial con una media de 4.52 minutos y el tiempo durante la inspección con una distribución normal con una media de 3.99 minutos y una desviación estándar de 0.617 minutos.
Aunque tiene un 100% la distribución Lognormal, no haremos con la distribución normal con un 99.6% de aceptación.
Aquí se muestran solamente las primeras 10 piezas, pero continua hasta las corridas necesarias según la formula.
Graficamos la columna con la variable de interés, en este caso los minutos que está la pieza en el sistema. Como observamos el valor de p < 0.05, por lo anterior, los datos no siguen una distribución normal.
Utilizamos entonces la fórmula de abajo con una desviación estándar de 4.958 y un error de 2 minutos (definido por analista) y una alfa de 0.05. n=(1/0.05)*(4.958/2)^2=122.91 corridas para llegar a la estabilidad, sin embargo, en la prueba piloto se realizó con 500 corridas, por lo que se sugiere dejarlo así.
Posteriormente se realizan las réplicas para calcular el intervalo de confianza, se sugiere manejar al menos 30 réplicas para tener un mejor desempeño.
Para efecto de la presentación se hizo un corte. Se calcula el promedio de todos los promedios de las 30 réplicas.
El valor de p < 0.05 por lo que los datos no siguen una distribución normal y calculamos el intervalo de confianza con la fórmula de la Fig. 20.
Límite superior = 12.55+(3.12/RAIZ(30*0.05/2)) = 16.1526.
Límite inferior =12.55-(3.12/RAIZ(30*0.05/2)) = 8.9473.
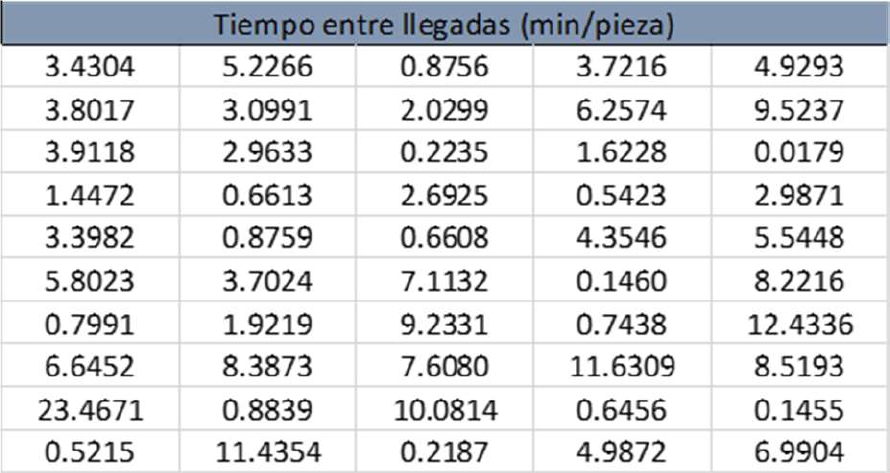

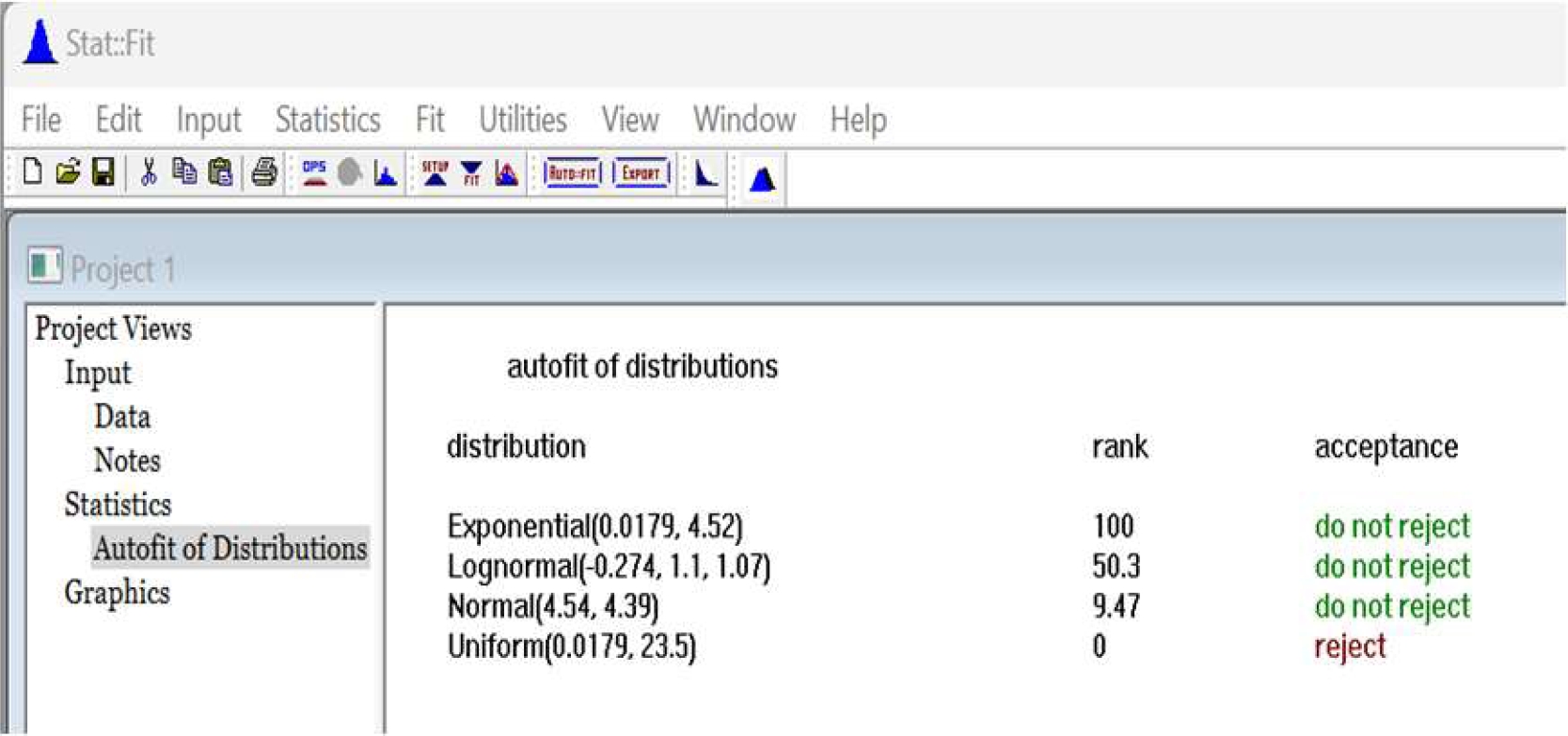
Fig. 8 Comparativo de las distribuciones analizadas. Prueba de bondad de ajuste con el software Promodel, módulo stat-fit. No se rechaza la hipótesis de que los datos tengan una distribución exponencial con un 100%

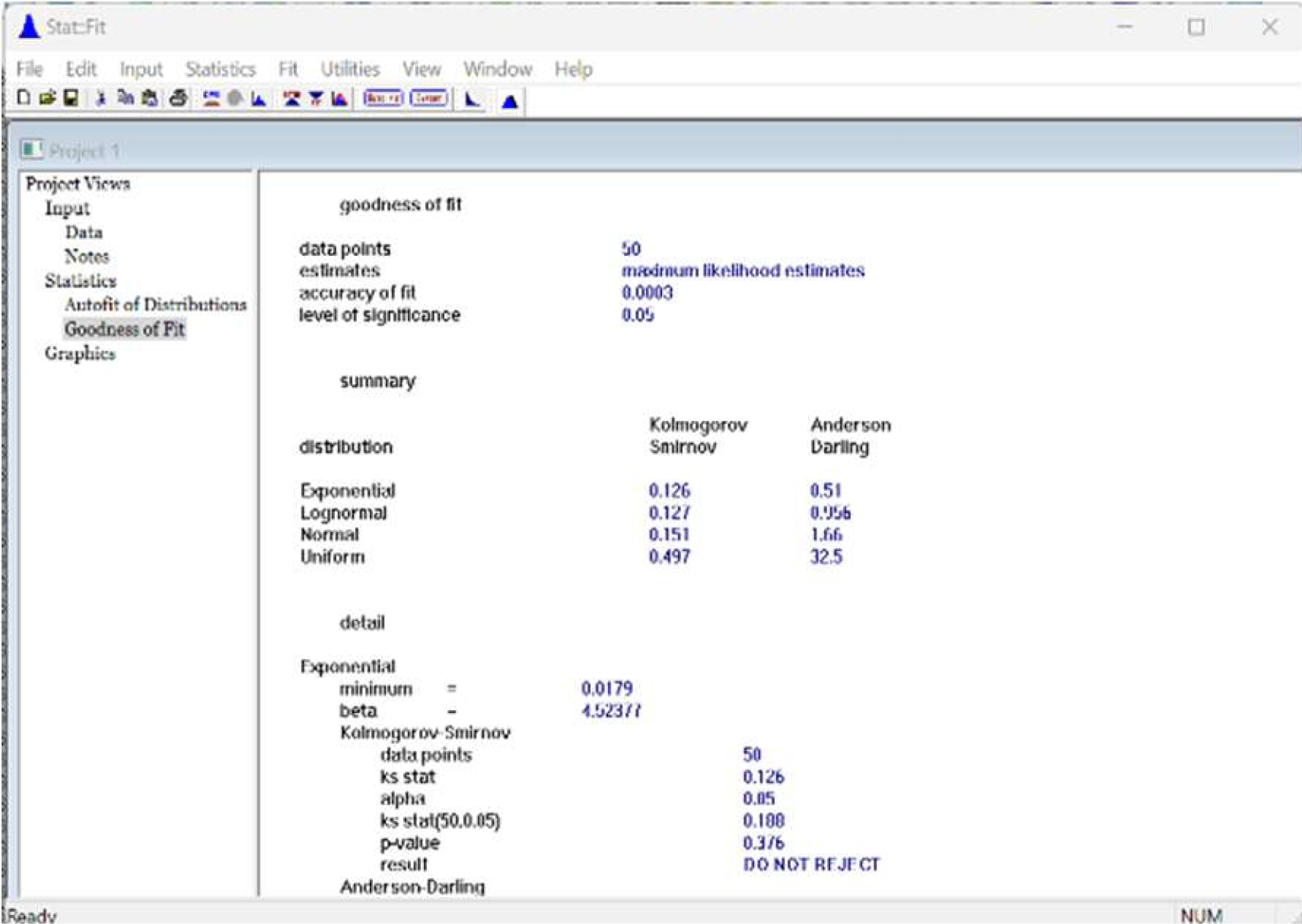
Fig. 10 Resultado de las pruebas de bondad de ajuste de los 50 datos con un nivel de significancia de 0.05, muestra ambas Kolmogórov-Smirnov y Anderson- Darling
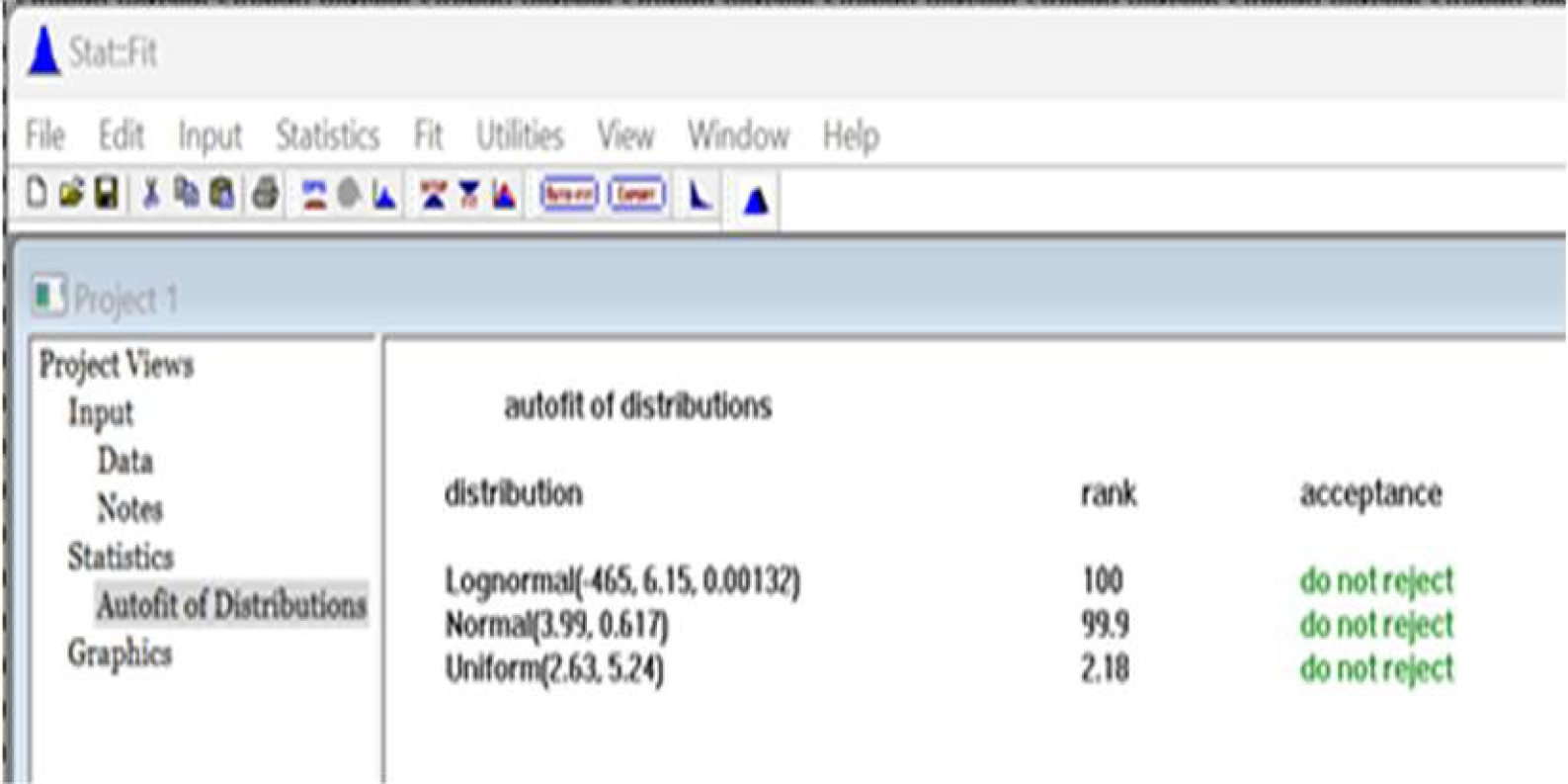
Fig. 11 Comparativo de las distribuciones analizadas. Prueba de bondad de ajuste con el software Promodel, módulo stat-fit. No se rechaza la hipótesis de que los datos tengan una distribución lognormal con un 100%, ni tampoco se rechaza la hipótesis de que los datos tengan una distribución normal con un 99.9%

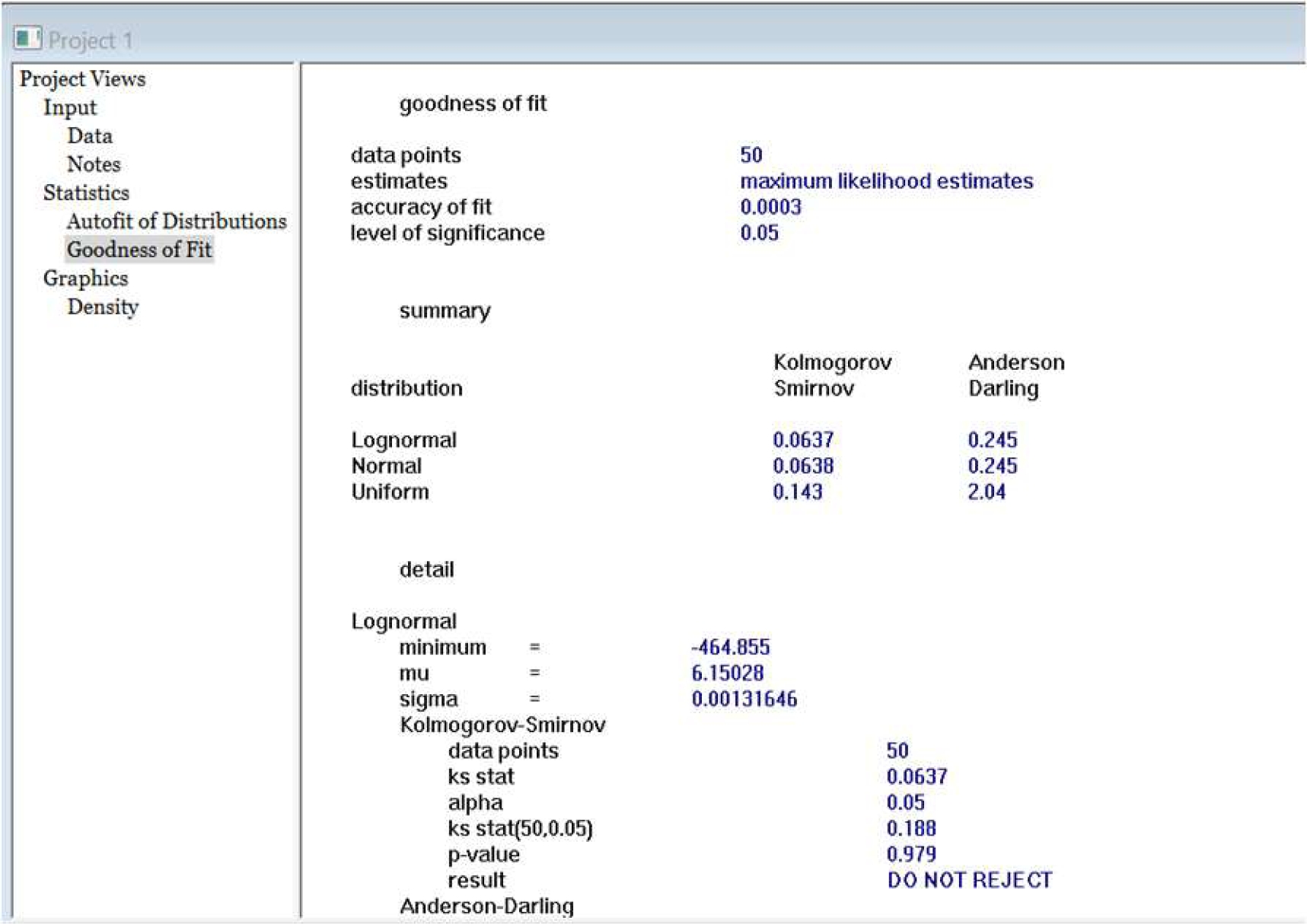
Fig. 13 Resultado de las pruebas de bondad de ajuste de los 50 datos con un nivel de significancia de 0.05, muestra ambas Kolmogórov-Smirnov y Anderson- Darling
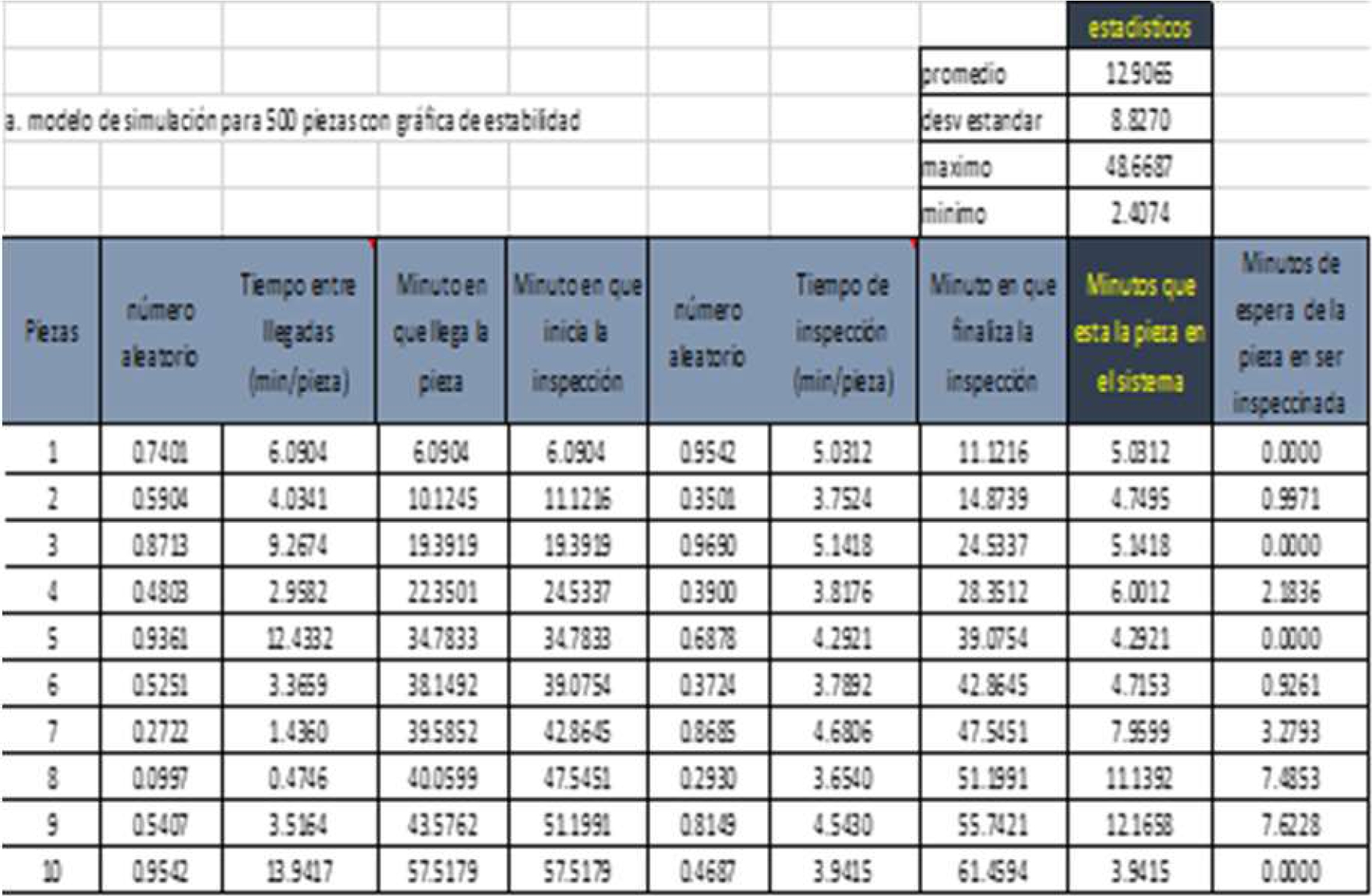


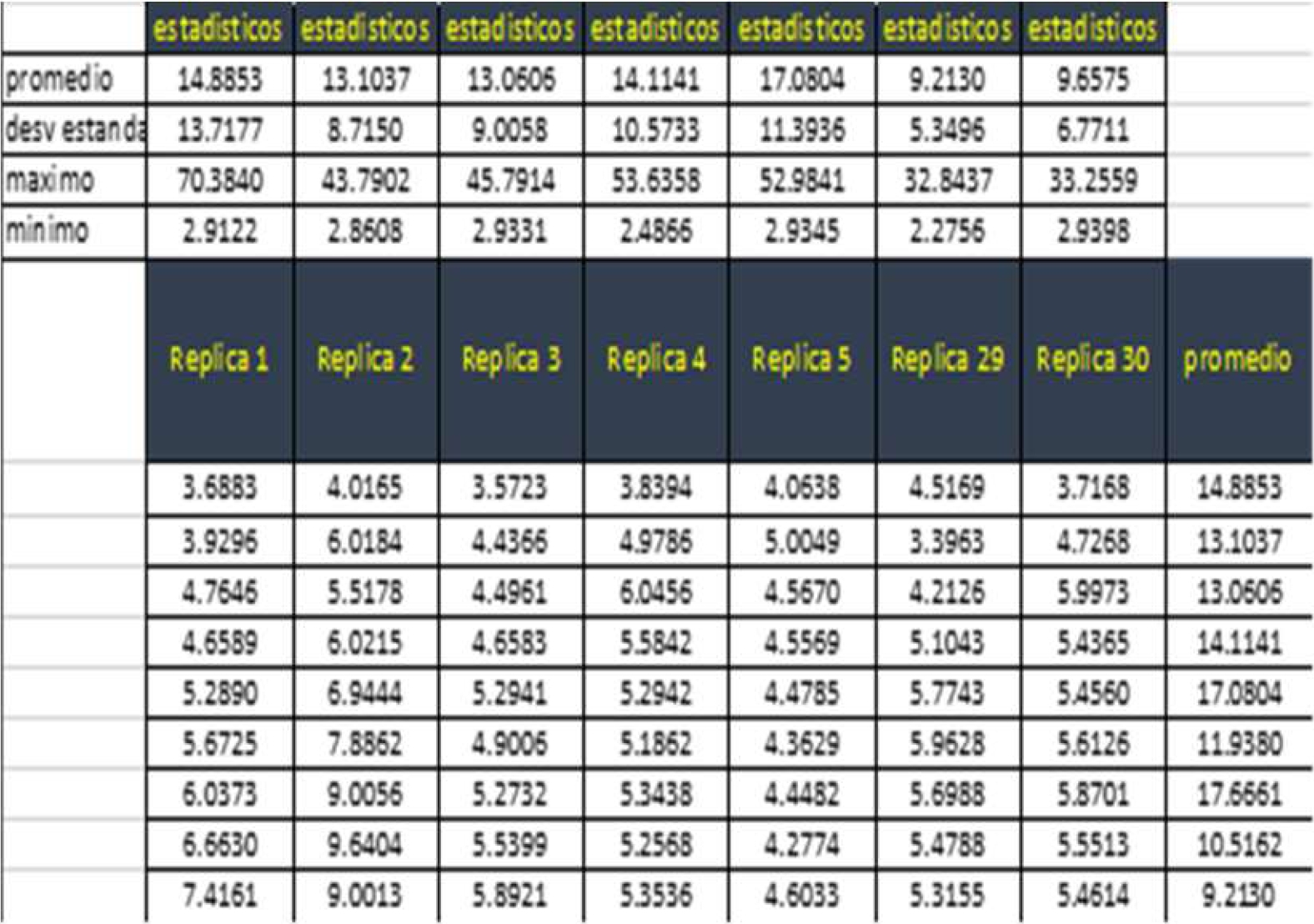
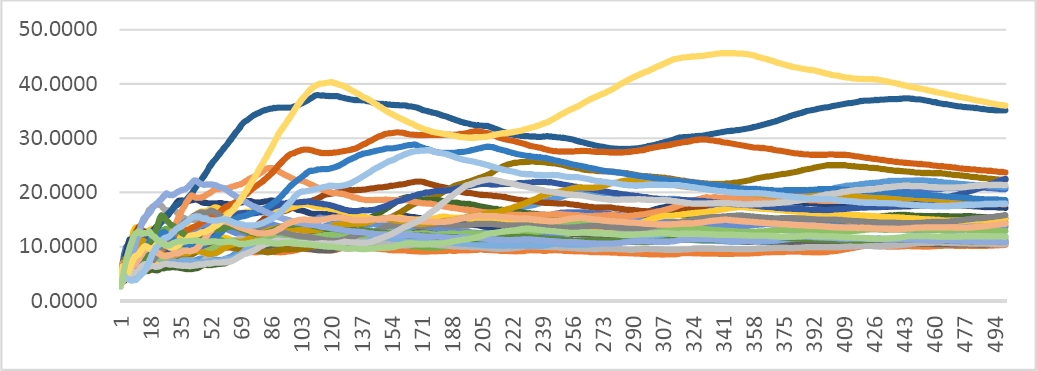
Fig. 18 Gráfica de probabilidad de la variable de interés “minutos que esta la pieza en el sistema” de las 30 réplicas
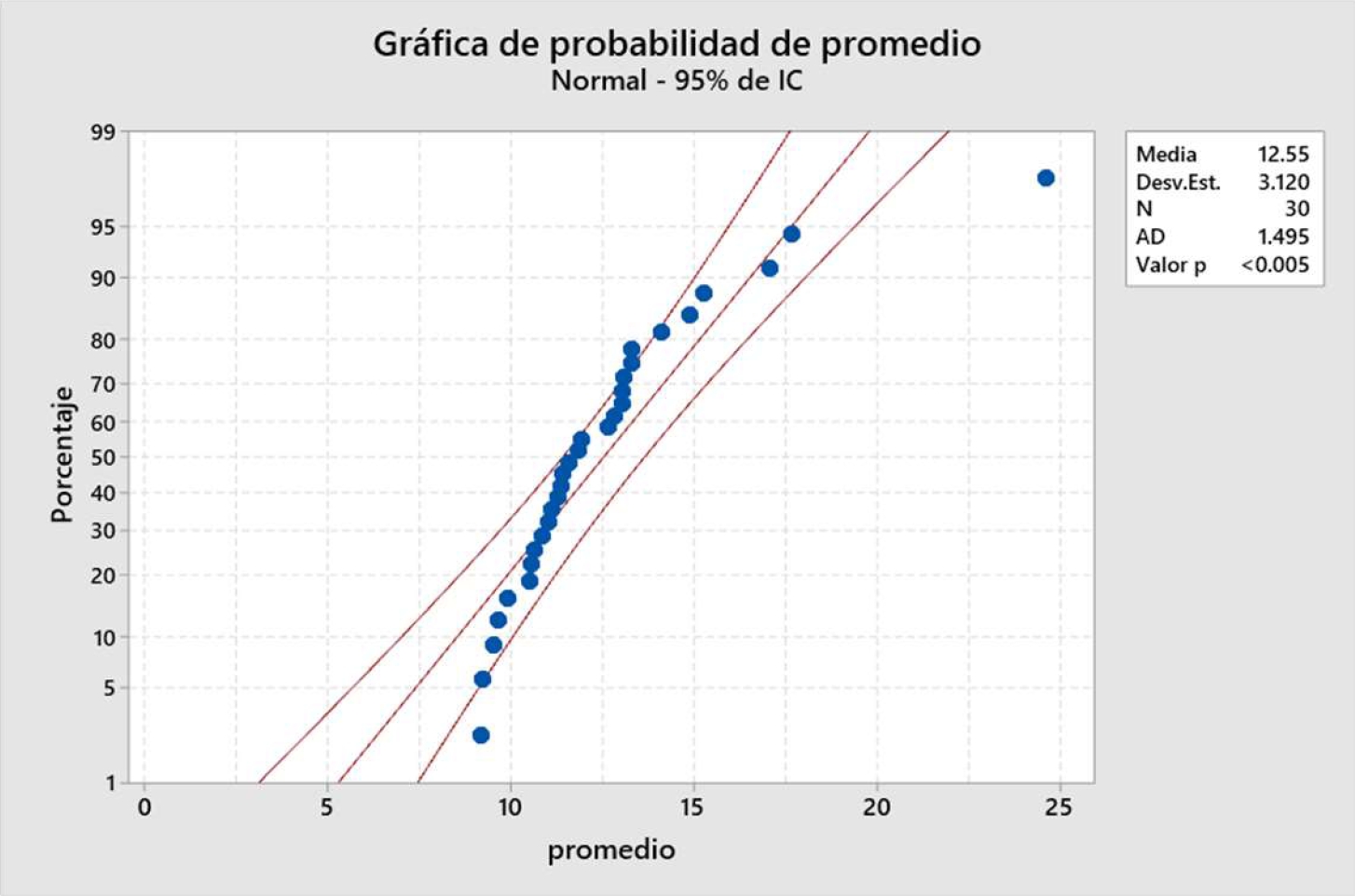
Fig. 19 Gráfica de probabilidad los 30 promedios de las réplicas referentes a la variable de interés “minutos que la pieza está en el sistema”

La simulación nos concluye que el promedio de una pieza en el sistema de inspección (línea de espera + tiempo de inspección es de 12.55 minutos con una desviación estándar de 3.12 minutos. El intervalo de confianza con un 95% de seguridad está entre 8.9473 y 16.1526 minutos.
6. Conclusiones
Las conclusiones que se pueden obtener después de una simulación dependen del propósito y del alcance de la simulación en sí.
Algunas de las conclusiones generales que se pueden obtener son las siguientes: Comportamiento del sistema: La simulación permite analizar el comportamiento del sistema en diferentes condiciones y escenarios.
Se pueden identificar patrones, tendencias y relaciones entre las variables de interés, lo que permite entender mejor el funcionamiento del sistema.
Identificación de cuellos de botella: La simulación puede ayudar a identificar cuellos de botella y puntos críticos del sistema, que pueden afectar el rendimiento, la eficiencia y la productividad.
Al conocer estos puntos, se pueden tomar medidas para optimizar el sistema y mejorar su desempeño.
Evaluación de alternativas: La simulación puede utilizarse para evaluar diferentes alternativas o estrategias de operación.
Esto permite tomar decisiones informadas y basadas en evidencia, lo que puede reducir el riesgo y mejorar los resultados.
Análisis de riesgo: La simulación puede ayudar a analizar el riesgo asociado con diferentes eventos y situaciones. Esto permite identificar los riesgos potenciales y tomar medidas para minimizar su impacto.
Validación y verificación del modelo: La simulación permite validar y verificar el modelo utilizado para representar el sistema. Esto ayuda a asegurar la precisión y confiabilidad de los resultados obtenidos.
En resumen, las conclusiones que se pueden obtener después de una simulación son importantes para entender el comportamiento del sistema, identificar puntos críticos, evaluar alternativas y tomar decisiones informadas basadas en evidencia.

