











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
Los Sistemas Operativos de Tiempo Real (SOTR) son un tipo especial de sistema operativo que debe contar con características adicionales a las ofrecidas por un sistema operativo de tiempo compartido, ya que en general, interactúan con procesos del mundo real y deben respetar sus restricciones temporales [5].
Este tipo de sistemas operativos, de acuerdo a su diseño, pueden ser propietarios o extensiones de tiempo real; estas últimas pueden estar basadas en el kernel de Linux, y permiten tener un SOTR a disposicion, sin tener que pagar una licencia o utilizar hardware específico.
Por ello, en este trabajo se usa RT-Linux, que ofrece características de tiempo real a través del parche PREEMPT_RT, este parche proporciona la capacidad de ejecutar tareas de tiempo real y manejador de interrupciones en la misma máquina que Linux estándar [22, 13].
Todas las tareas computacionales generan tiempos de respuesta que dependen del hardware y el software del ordenador. Los tiempos de respuesta de las tareas ejecutadas en sistemas operativos en tiempo real como RT-Linux pueden variar a medida que evolucionan sus instancias aunque siempre ejecuten el mismo algoritmo.
El modelado de tiempos de respuesta, permite representar matemáticamente el comportamiento del sistema para conocer cómo podría comportarse en diferentes escenarios y conocer los peores.
En el caso de los sistemas de tiempo real, es bastante significativo hacerlos a medida para aplicaciones específicas y saber cómo se comportarían en situaciones de estrés con algoritmos que generen alta carga computacional y con prioridades del nivel más alto.
2. Trabajos relacionados
Los trabajos que a continuación se describen soportan y sugieren el uso de RT-Linux. Los autores del artículo [31] establecen que el parche PREEMPT_RT tiene el objetivo de aumentar la predictibilidad y reducir la latencia del kernel.
Además, afirmaron que Linux no puede ser considerado un sistema de tiempo real estrictamente, al menos no para escenarios de seguridad crítica.
En [24], los autores muestran que el parche RT es adecuado para las unidades que hacen hincapié en el procesamiento de datos, que dependen en gran medida de IPC (comunicación entre procesos).
En el artículo de [37] se muestran sorprendentes experimentos usando Linux y RT-Linux y los resultados destacan que el kernel optimizado por el parche RT-Linux generaba menos retraso que el kernel en la programación multihilo.
En la tesis de maestría de [13], se probó y comparó el rendimiento de dos parches de tiempo real Xenomai y PREEMPT_RT.
Para el análisis de los tiempos medidos se utilizó el primer y segundo momento de probabilidad, que mostró el mejor rendimiento con el parche PREEMPT_RT y tuvo menores varianzas y redujo el tiempo de respuesta.
Todos estos trabajos muestran algunas ventajas del uso de RT-Linux frente a Linux estándar y otros parches de tiempo real.
Por lo tanto, los tiempos de respuesta de las tareas ejecutadas en sistemas operativos de tiempo real como RT-Linux pueden variar a medida que evolucionan sus instancias, aunque siempre ejecuten el mismo algoritmo; esto se debe a diversas causas como los tiempos de operación, los tiempos de espera, el ruido de las mediciones, el jitter, la programación, el paso de mensajes, las interrupciones de hardware y software, entre otras [34].
Esta variación disminuye a medida que aumenta la prioridad de las tareas; sin embargo, los tiempos de respuesta mínimos y máximos siguen estando presentes en la misma tarea y esto complica su seguimiento, disminuyendo su nivel de predictibilidad en caso de contingencia o sobrecarga, y además, dificultando el dimensionamiento de los recursos.
En el trabajo de los autores [23] se describen los tiempos de ejecución de las tareas periódicas; estos tiempos se utilizan para calcular la utilización alcanzable del procesador, y este concepto fue la base de futuras investigaciones.
[20] explican que los tiempos de respuesta de un sistema en tiempo real
Además, mostraron una ecuación del tiempo de respuesta mediante la suma del bloqueo máximo de los procesos de menor prioridad, el jitter máximo, el peor tiempo, el tiempo de computación, el periodo de las tareas y el plazo.
En este sentido, [4] presentaron una sencilla ecuación recursiva para determinar los tiempos de respuesta del mejor caso de las tareas periódicas bajo una programación preventiva de prioridad fija y un escalonamiento arbitrario. Los autores [30] siguieron el mismo sentido de los trabajos anteriores; presentaron una ecuación de recurrencia para calcular los tiempos de respuesta del mejor caso de un conjunto de tareas periódicas con prioridades fijas.
La solución se basa en la identificación de la fase del mejor caso de una tarea de baja prioridad en comparación con las tareas de mayor prioridad.
Este escalonamiento se produce cuando la tarea de baja prioridad se libera de forma que termina simultáneamente con las liberaciones de todas las tareas de mayor prioridad cuando éstas han experimentado su máxima fluctuación de liberación.
Hasta ahora, las cinco referencias revisadas tienen algo en común. Los autores proponen algún tipo de modelo teórico de tiempos de respuesta. Todos ellos se basan en un modelo de tiempos de respuesta en diferentes escenarios.
En [2], los autores presentan un modelo para estimar el tiempo de respuesta en el peor de los casos de tareas esporádicas con prioridades fijas en un uniprocesador preventivo, especifican que dependiendo del nivel de prioridad, las tareas pueden tener mayor o menor tiempo de respuesta, considerando que la respuesta para el peor caso no deba exceder el plazo máximo.
De igual manera influye la complejidad computacional del algoritmo, otro factor es la continuidad en el algoritmo procesado, cuando el incremento de tiempo es muy pequeño se tendrán que hacer más operaciones por periodo; además, si se busca una buena aproximación a un sistema continuo se deben considerar tiempos de muestreo muy pequeños.
Identifican tres propiedades deseables: continuidad, computabilidad eficiente y aproximabilidad. Otros trabajos que siguieron esta idea son los de [3, 9, 15, 1].
Los autores [26, 25] presentan un enfoque estadístico para el análisis del tiempo de respuesta de los sistemas embebidos en tiempo real, y su trabajo se basa en la teoría del valor extremo, las simulaciones de Monte Carlo y otros métodos estadísticos para obtener una estimación probabilística; los autores aseveran que el análisis de tiempos de respuesta debe hacerse con un enfoque estadístico (no es suficiente un enfoque determinístico) para calcular los peores tiempos de respuesta; una característica de este trabajo son sus resultados experimentales basados en el análisis de datos.
En [28], los autores proponen una estimación probabilística del tiempo de respuesta en el peor de los casos orientada a sistemas multinúcleo en tiempo real.
Su trabajo implica la generación de datos con clasificación de muestras e igualación del tamaño de las mismas, y la estimación se basa en un modelo de distribución de valores extremos y un método de ajuste del modelo de distribución de Pareto generalizado.
También se presenta la detección de umbrales y la estimación de parámetros.
Por último, [32] presentaron y demostraron un novedoso análisis del mejor caso exacto de tiempo de respuesta para tareas periódicas independientes en tiempo real con plazos arbitrarios programadas utilizando una programación de prioridad fija con umbrales de anticipación, los autores presentaron un desarrollo teórico completo y diferentes escenarios para probar el modelo.
3. Desarrollo
3.1. Banco de pruebas
El banco de pruebas se conforma por (figura 1) una Computadora de Placa Reducida (SBC) Raspberry Pi, un Sistema Operativo Real-Time Linux, como objeto de prueba se utiliza un proceso que genera alta carga computacional temporal basado en inversión de matrices por el método de Gauss-Jordan, se implementa mecanismo de planificación de tiempo real y se asigna la prioridad más alta al proceso; se miden los tiempos de respuesta y se almacenan en un vector de datos para realizar la caracterización estadística; una vez analizado el comportamiento de los tiempos se propone un modelo matemático que permita representar y replicar su dinámica bajo diferentes condiciones de operación.

3.2. Algoritmo de inversión de matrices
Para fundamentar este trabajo experimental, se tomó como objeto de prueba el proceso de inversión de matrices apoyado en [16, 8, 13].
En la Figura 2 se muestra el pseudocódigo del algoritmo, puede observarse también que se realiza la medición del tiempo antes de llamar a la función

Las funciones que integra la biblioteca
El algoritmo tiene el propósito de generar un proceso de alta carga computacional temporal en el sistema operativo, su complejidad es O(n3) y se emplea para hacer la medición de los tiempos de respuesta, la inversión de matrices se efectúa con las siguientes dimensiones: 32×32, 64×64 y 128×128, para cada dimensión se realizan 1000 inversiones, con el objetivo de observar el comportamiento de los tiempos de respuesta como métrica cuantitativa.
Es importante mencionar que la matriz se llena con valores pseudoaleatorios de punto flotante, se genera el llenado una sola vez y esa matriz se invierte 1000 veces.
La razón de utilizar este algoritmo, es debido a la complejidad computacional temporal y número de operaciones que involucra a medida que se incrementan las dimensiones de la matriz a invertir; Por otra parte, cabe señalar que las matrices tienen muchas aplicaciones en áreas como control, filtrado, imágenes, robótica, videojuegos, inteligencia artificial, etc.
La medición de los tiempos de respuesta se realiza dentro del algoritmo, para efectuar las mediciones, existe una serie de funciones dentro de la biblioteca

Los tiempos de respuesta medidos se guardan en un archivo de texto, para ser graficados fuera de línea en el software MATLAB.
3.3. Asignación de planificador y prioridad de tiempo real
De acuerdo con el trabajo de [13], para implementar mecanismo de planificación de tiempo real se utiliza
Pid es el ID de proceso al que se asignará la prioridad, puede establecerse con valor 0 para indicar que la prioridad se asignará al proceso actual.
Policy es la política de planificación, con base en [29]
Finalmente, param es un puntero a la estructura
En este trabajo se utiliza el planificador
Por lo tanto, el recurso del procesador está enfocado en darle atención al proceso en ejecución, de tal manera que evita que sea desalojado por otras tareas hasta que termine su ejecución.
La asignación de prioridad y planificador se muestra en el fragmento de código de la figura 4.

3.4. Caracterización estadística de tiempos de respuesta
La caracterización estadística permite conocer la dinámica del sistema o fenómeno que se esté analizando, por ello el primer paso para caracterizar es calcular los momentos de probabilidad, que corresponden a la media y varianza, los cuales para este caso se calcularán de manera recursiva, pues es de interés conocer la dinámica de los tiempos de respuesta a medida que evoluciona el experimento, si se realizara el calculo aplicando directamente las ecuaciones se obtendría un valor general, lo cual no permitiría indagar en el comportamiento de los tiempos de respuesta [14].
Los momentos de probabilidad indican la dinámica de los tiempos de respuesta conforme a la evolución del experimento y la dispersión que existe de los datos alrededor de la media recursiva.
También, proporciona información sobre la naturaleza de los tiempos, es decir, si son homogéneos (estacionarios) o heterogéneos (No estacionarios), dando pauta a su análisis con un mejor enfoque para elegir una técnica de modelado y reconstrucción adecuadas.
La Función de Densidad de Probabilidad (FDP) junto con los momentos de probabilidad presentan información de la estacionariedad del proceso; se espera que sea gaussiana y simétrica para aplicar técnicas de reconstrucción como mínimos cuadrados o filtro de Kalman, de otra manera deberá normalizarse [14].
3.5. Primer momento de probabilidad o esperanza matemática
El primer momento de probabilidad es la media o valor esperado de una variable aleatoria
Para calcular la media recursiva se parte de la ecuación (1) y se aplica diferencias finitas para obtener la ecuación de la media recursiva, como se representa en (2):
3.6. Segundo momento de probabilidad o varianza
El segundo momento de probabilidad o varianza de una variable aleatoria
El cálculo de la varianza recursiva se realiza a partir de la ecuación (3) y de igual forma se aplica diferencias finitas, quedando finalmente la ecuación (4):
4. Propuesta de modelo ab initio para reconstrucción de tiempos de respuesta
De acuerdo con la caracterización de la dinámica de los tiempos de respuesta, se tiene que es un sistema lineal, estacionario e invariante en el tiempo. Por ello con base en el trabajo [7], se propone el siguiente modelo fundamental para tiempos de respuesta tipo SISO, lineal y de primer orden, presentado en la figura 5 y descrito en la ecuación (5):
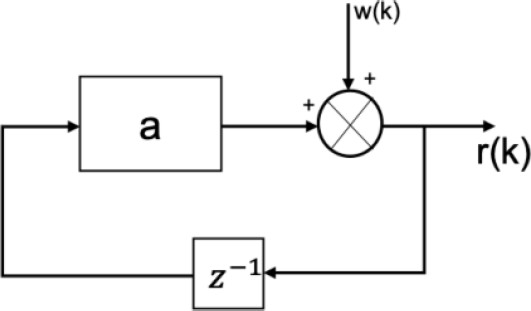
Se procede a despejar el parámetro
Con el procedimiento anterior, se tiene el modelo fundamental para reconstrucción de tiempos de respuesta:
Para validar el modelo de reconstrucción, se calcula el error de reconstrucción mediante la siguiente ecuación:
Finalmente, se calcula el error de convergencia del modelo propuesto, calculado a través de la ecuación (10):
5. Propuesta de modelo basado en CEM (cociente de esperanzas matemáticas)
En el modelo ab initio se tuvo un primer acercamiento en el cual se considero un ruido externo
Sin embargo, al ser una primera aproximación no se logra una adecuada convergencia a los valores reales.
Para mejorar el nivel y velocidad de convergencia, a continuación se presenta el desarrollo de una nueva versión del modelo de tiempos de respuesta, a través de un modelo autorregresivo de media móvil, considerando los resultados de la caracterización estadística de las mediciones experimentales de los tiempos de respuesta generados por una tarea de alta prioridad sobre RT-Linux.
El algoritmo reconstructor se basa en un modelo probabilístico basado en el primer momento de probabilidad para estimar el estado del parámetro.
Mediante el uso de un modelo de tiempos de respuesta y el algoritmo reconstructor es posible calcular el error de reconstrucción para determinar la calidad de la reconstrucción [12].
Para el procedimiento de reconstrucción, se propone un conjunto
–
–
–
–
–
En términos formales, el conjunto

Fig. 6 Diagrama de estados R para reconstrucción de la dinámica de los tiempos de respuesta de una tarea con alta prioridad sobre RT-Linux [12]
El primer estado es
El estado
El estado
Por último, el estado
Obsérvese que los estados
Siguiendo este contexto, para cada estado se propone un diagrama de estados de segundo nivel para representar los procedimientos internos a fin de obtener el respectivo resultado.
5.1.
En el estado
En el algoritmo, se utiliza la función
Para la medición de los tiempos, se utiliza la función
Utilizando estas funciones, se obtienen los tiempos de respuesta de cada instancia
–
–
–

Fig. 7 Diagrama de estados
Para cada instancia
5.2.
En esta parte, se propone un conjunto de definiciones necesarias, un lema y un teorema para desarrollar el modelo de reconstrucción como se muestra en la Figura 8 con los siguientes estados:
–
–
–
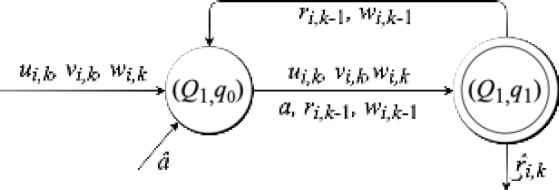
Fig. 8 Diagrama de estados
Para obtener el diagrama de estados
Definición 1 (Tiempo de respuesta
Con
La hipótesis de partida es la siguiente: la dinámica de los tiempos de respuesta de una tarea puede reconstruirse a partir de un modelo matemático, un parámetro estimado y la medición y caracterización de un conjunto de tiempos de respuesta de una tarea con prioridad alta fija [12].
Definición 2 (Tiempo de operación
El tiempo de operación
Definición 3 (Tiempo de ejecución
El tiempo de ejecución
Definición 4 (Tiempo de desalojo
El tiempo de desalojo
Observe que una instancia
Lo que implica que:
Las restricciones temporales, la notación y sus relaciones se basan en [6]. En este sentido, se presenta la figura 9, la tabla 1 y todo el desarrollo matemático [12].

Fig. 9 Esquema de restricciones temporales para una instancia
Tabla 1 Lista de variables [12]
| Variable | Descripción |
| Conjunto de tareas | |
| Tarea | |
| Instancia | |
| Tiempo de arribo | |
| Tiempo de operación | |
| Tiempo de inicio | |
| Tiempo de ejecución | |
| Tiempo de desalojo | |
| Tiempo de finalizado | |
| Tiempo de respuesta | |
| Entrada del sistema | |
| Ruido interno | |
| Ruido externo | |
| Error de reconstrucción | |
| Tiempo de respuesta reconstruído | |
| Índice de tarea | |
| Índice de instancia | |
| Número total de tareas | |
| Número total de instancias | |
| Número total de segmentos de tiempo | |
| Parámetro del sistema | |
| Parámetro estimado del sistema | |
| Error cuadrático medio |
Lema 1. El tiempo de respuesta
Prueba. Teniendo en cuenta (13) y sustituyendo en la ecuación (14):
Considerando
Con las ecuaciones (14) y (11) es posible proponer un modelo dinámico recursivo [18, 17, 19]. Por consiguiente, se obtiene:
Teorema 1. (Dinámica de los tiempos de respuesta
Considerando
La ecuación (20) es un sistema lineal, invariante en el tiempo porque la caracterización dinámica de los tiempos de respuesta de una tarea en tiempo real con alta prioridad es un modelo recursivo, los niveles de ruido están acotados por la desviación estándar respecto a la esperanza matemática de los tiempos de respuesta, y
Prueba. Considerando la ecuación (14)
Entonces, esas son variables aleatorias de procesos estocásticos y se pueden sumar para obtener [12]:
Tal que:
Por otro lado,
Siguiendo los párrafos anteriores, se tiene que representar
Aplicando un retardo a la ecuación (24) se obtiene:
Sustituyendo la igualdad de las ecuaciones (24) y (25) en la ecuación (23), se obtiene:
Despejando
5.3.
Una cuestión importante sobre la estimación de parámetros es cómo calcular el parámetro
Entonces, para este estado se necesita estimar un parámetro
Nótese que la estimación de
–
–
–
–
–
–
Con las condiciones anteriores se propone el siguiente lema.
Lema 2. (Estimador de Parámetro
Prueba. Debido a que el sistema es lineal, estacionario y de primer orden, se propone construir un estimador basado en CEM, partiendo de la ecuación(26), se aplica esperanza matemática en ambos lados de la igualdad [12]:
Y despejando el parámetro
En la figura 10, se presentan los estados

La ecuación (29) está calculada de forma recursiva y permite observar la dinámica de
5.4.
Esta etapa es muy importante, se valida la calidad del modelo de reconstrucción propuesto mediante el error de reconstrucción y el error cuadrático medio. Para ello, se presenta el tercer estado como se muestra en la figura 11:
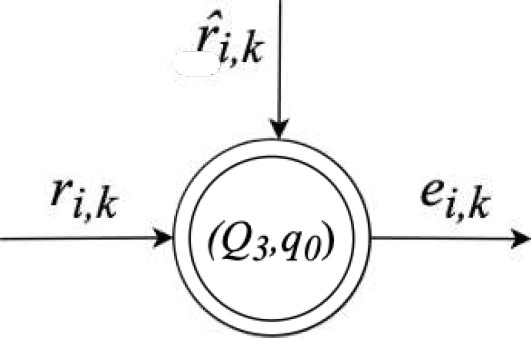
Fig. 11 Diagrama de estados
donde:
De acuerdo con [11], el error cuadrático medio mide la amplitud de la variación del estimador con respecto al propio estimado, se esperan estimadores con menor error cuadrático medio y más cercanos al valor medido que se busca estimar:
6. Resultados
Esta sección presenta un compendio de gráficas que ilustran los tiempos de respuesta medidos y reconstruidos a través de los modelos propuestos en la sección de desarrollo.
Los experimentos se realizaron sobre un banco de trabajo configurado por una computadora de placa reducida con sistema operativo RT-Linux y una tarea que ejecuta el algoritmo de inversión matricial programado en lenguaje C.
Es importante resaltar que se llevaron a cabo experimentos para inversión de matrices de dimensión 32×32, 64×64 y 128×128. Sin embargo, para este apartado, se presentan las figuras del experimento de inversión de matrices de 128 × 128.
6.1. Especificación de elementos del banco de pruebas
La tabla 2 especifica los elementos del banco de pruebas y sus características para realizar estos experimentos. Es muy importante mencionar que se considera la ejecución de una tarea en los experimentos realizados.
Tabla 2 Elementos del banco de pruebas
| Elemento | Característica |
| SBC | Raspberry Pi 3 modelo B |
| Sistema operativo | RT-Linux con parche PREEMPT RT |
| Planificador | Round Robin (SCHED RR) |
| Prioridad | Alta prioridad (99) |
| Algoritmo | Inversión de matrices |
Es importante mencionar que previamente en el estudio de [13], se probaron los planificadores FIFO y Round-Robin, el mecanismo de planificación se implementó con la función
Se observó que con el planificador Round-Robin hubo variaciones menores en comparación con FIFO, debido a que Round-Robin asigna timeslices a cada tarea garantizando que los tiempos de respuesta se comporten de manera uniforme en RT-Linux.
6.2. Resultados de caracterización de tiempos de respuesta
A continuación se muestran las gráficas obtenidas del experimento de inversión de matrices de 128×128 al aplicar las ecuaciones (2 y 4) presentadas en la sección de desarrollo, correspondientes al primer y segundo momentos de probabilidad, se grafica también su desviación estándar superior e inferior lo cual es de importancia ya que permite tener una region acotada en donde se tiene mayor concentración de tiempos de respuesta, lo que se encuentra fuera de esa región podría considerarse jitter.
Aunado a esto se grafica su función de densidad de probabilidad, estas herramientas permiten conocer el comportamiento de los tiempos de respuesta, visualizar si son estacionarios o no, y tomarlo como punto de partida para proponer un modelo.
En la Figura 13 se muestran las gráficas de los tiempos de respuesta normalizados, considerando su medida máxima 1 para posteriormente definir un espacio de probabilidad con el objetivo de reconstruir la dinámica de tiempos de respuesta y elegir la mejor técnica a través de estimadores e identificadores estocásticos.

Fig. 12 Gráfica de primer y segundo momentos de probabilidad y desviación estándar de tiempos de respuesta, para experimento de inversión de matrices de

Fig. 13 Gráfica de tiempos de respuesta normalizados y función de densidad de probabilidad, para experimento de inversión de matrices de
En la Figura 12 se observan los tiempos de respuesta en un espacio estadístico para inversión de matrices de
En la misma gráfica se muestra la desviación estándar superior e inferior, donde se representa una región acotada de la mayor concentración de tiempos de respuesta, en la cota superior el tiempo es alrededor de
En la varianza recursiva se observan fluctuaciones durante las primeras 400 instancias, pero en el progreso del experimento se mantiene casi constante manteniendo un valor aproximado de
En los tres experimentos realizados, la media recursiva tuvo un comportamiento similar durante las primeras 100 instancias y después los tiempos se mantuvieron constantes.
De acuerdo a las gráficas de varianza recursiva se observa de manera general que difícilmente llega a converger a un valor, los datos son fluctuantes parcialmente en la evolución de los experimentos.
En suma, el comportamiento de los tiempos de respuesta se describe como un sistema estocástico estacionario e invariante en el tiempo con estabilidad en media [36], este es un dato muy importante ya que con este antecedente se pasa a la siguiente etapa que consiste en la propuesta de un modelo ARMA y un estimador de parámetros basado en el CEM.
6.3. Resultados del modelo ab initio para reconstrucción de tiempos de respuesta
A partir del análisis estadístico presentado en la sección anterior y con base en la dinámica de los tiempos de respuesta observada, se determinó que el sistema es lineal, estacionario e invariante en el tiempo.
En este apartado, se presentan los resultados del modelo presentado en la sección de desarrollo.
En la figura 14, se muestra un conjunto de gráficas que presentan el parámetro estimado

Fig. 14 Gráfica de parámetro estimado
Esto se confirma al observar en la tercera gráfica que no se tiene un adecuado seguimiento de los tiempos reconstruidos respecto a la dinámica de los tiempos de respuesta medidos, si bien es un comportamiento esperado ya que al ser un modelo ab initio que sólo considera un ruido externo, se necesitan m+as elementos a considerar para que la reconstrucción tenga un mejor seguimiento.
6.4. Validación de modelo ab initio
De acuerdo con los resultados del modelo de reconstrucción, se calcula el error de reconstrucción, que es la diferencia entre el tiempo de respuesta reconstruido y el tiempo de respuesta medido; además se realiza el cálculo del error cuadrático medio y se presentan las gráficas resultantes.
En la figura 15, se observa que el error de reconstrucción tiene un comportamiento fluctuante; si bien tiene valores cercanos a cero, la reconstrucción inexacta causa estas fluctuaciones; el error cuadrático medio tiene una respuesta aceptable, se observa que en el transcurso de los eventos se aproxima asintóticamente a cero en los tres experimentos.

6.5. Resultados del modelo de tiempos de respuesta basado en CEM
Esta etapa de resultados se apoya en la caracterización estadística previamente realizada.
De acuerdo con el Teorema 1 en la sección de desarrollo, el comportamiento de los tiempos de respuesta se describe como un sistema estocástico estacionario e invariante en el tiempo.
Se considera un modelo invariante en el tiempo porque de acuerdo con la caracterización de los tiempos de respuesta medidos, no se observan grandes variaciones en sus magnitudes, por lo que se estima un parámetro constante
Por lo tanto, se presenta el modelo de reconstrucción de los tiempos de respuesta basado en las medidas y la caracterización del sistema. Se considera que el sistema es lineal ya que el comportamiento de la dinámica de los tiempos de respuesta permanece constante dentro de un rango acotado; si el tamaño de la matriz aumenta, entonces la magnitud de los tiempos de respuesta crece exponencialmente, por su complejidad
A continuación, se presentan las gráficas resultantes del modelo de reconstrucción para el experimento de 128×128: En la Figura 16 se observan tres gráficas. La primera representa el parámetro estimado

Fig. 16 Gráfica del parámetro estimado
Posteriormente, en la figura 18 se muestran el primer y segundo momentos de probabilidad. Estas figuras son muy importantes porque se puede ver que tiene convergencia en casi todos los puntos, lo que valida el modelo propuesto basado en CEM.

Fig. 17 Gráfica del error de reconstrucción y del error cuadrático medio del experimento de inversión de matrices de 128×128

6.6. Validacion del modelo basado en CEM
Para validar el modelo de reconstrucción propuesto, la figura 17 muestra el error de reconstrucción y el error cuadrático medio, donde se observa en todos los experimentos que los errores son cercanos a cero.
Con respecto a esto, se confirma que el modelo propuesto tiene una buena convergencia. Para explicar detalladamente los resultados, se presenta una breve discusión de los valores de los últimos datos de cada experimento en la Tabla 3.
Tabla 3 Últimos valores del primer y segundo momento de probabilidad, error de reconstrucción y error cuadrático medio de los tiempos de respuesta medidos y generados por los modelos ab initio y CEM, para cada experimento
| Últimos valores |
32 |
64 |
128 |
|
| Mediciones | ||||
| Modelo ab initio | ||||
| Modelo de CEM | ||||
6.7. Discusión resultados de los modelos respecto a los valores reales
Para mostrar con mejor detalle los resultados del modelo ab initio y el modelo basado en CEM, este trabajo se sintetiza en la tabla 3, donde se presentan los valores representativos que indican: primer y segundo momentos de probabilidad, valor del parámetro estimado, error de reconstrucción, y error cuadrático medio para cada experimento.
A continuación se muestra una colección de figuras que representan gráficas de error de reconstrucción y error cuadrático medio, de los modelos ab initio (color azul) y CEM (color rojo).
Por último, para el experimento de

Fig. 19 Comparativa de error de reconstrucción y error cuadrático medio con los modelos ab initio y CEM para el experimento de inversión de matrices de 128×128
Obsérvese que el valor del parámetro estimado
En comparación con el modelo de CEM, el parámetro estimado para los tres experimentos fue de 0.9990, pues de acuerdo con la dinámica de la reconstrucción de los tiempos, hay un seguimiento adecuado respecto a los valores medidos, se tiene una mejor aproximación ya que en el modelo se consideran la entrada del sistema, ruido interno y ruido externo.
7. Conclusiones y trabajo futuro
Se construyó un banco de pruebas en una computadora de placa reducida Raspberry Pi, el kernel Linux PREEMPT_RT que conforma al sistema operativo RT-Linux, y una tarea de inversión de matrices programada en lenguaje C. Se destacan las siguientes contribuciones:
– Se desarrolló la teoría necesaria para presentar la dinámica de los tiempos de respuesta.
– Se llevó a cabo el desarrollo de dos modelos para la reconstrucción de tiempos de respuesta de una tarea de alta prioridad sobre RT-Linux.
– Se desarrollaron estimadores de parámetros para cada modelo propuesto.
– Se realizó la validacion experimental de los modelos propuestos a través de una tarea real ejecutada con alta prioridad sobre RT-Linux.
– El modelo basado en CEM, tiene una mejor aproximación a los valores reales de acuerdo con la respuesta del error de reconstrucción.
Se realizaron dos propuestas de modelo, la primera a través de un modelo ab initio, donde se consideró al sistema lineal, de primer orden, con una entrada y una salida, y un parámetro
La reconstrucción se llevó a cabo a partir de la estimación del parámetro
Para mejorar el modelo ab initio, se consideraron dos elementos más: una entrada
El escenario propuesto para el modelado es estable computacionalmente, aplicable a tareas de alta prioridad en un sistema operativo de tiempo real no propietario como RT-Linux.
El uso del modelo y la reconstrucción se puede centrar en aplicaciones que requieran implementar tareas periódicas, algoritmos iterativos, o modelos que utilicen operaciones matriciales de forma exhaustiva, donde exista la necesidad de mejorar el rendimiento computacional y la eficiencia algorítmica con RT-Linux en una SBC como Raspberry Pi; por ejemplo, en [10].
Los modelos que son referencia en la sección de trabajos relacionados son un precedente para el desarrollo de este trabajo, sin embargo, no realizan análisis experimental. Es muy importante enfatizar el desarrollo de modelos dinámicos, capaces de describir el comportamiento de los tiempos de respuesta del conjunto de instancias de una tarea con alta prioridad en un sistema RT-Linux, totalmente diferente a una descripcion cualitativa a través de un análisis estadístico, ya que el objetivo de esos trabajos no era reconstruir el sistema, sino describirlo estadísticamente según sus cualidades. El modelo para reconstruir la dinámica de los tiempos de respuesta tiene dos usos principales para futuras aplicaciones:
En primer lugar, dimensionar el sistema computacional para hacer uso adecuado de sus recursos de memoria y del uso de la CPU, y en segundo lugar, proponer esquemas de tolerancia a fallos, ya que cuando la magnitud de los tiempos de respuesta comienza a aumentar o se observa una alta variación del primer y segundo momento de probabilidad el sistema computacional podría fallar.
Los resultados obtenidos son satisfactorios; sin embargo, se puede proponer otra técnica para estimación de la reconstrucción que podría tener una mejor aproximación. Para futuros trabajos, sería interesante proponer un modelo multivariable que implique la ejecución simultánea de más de una tarea con diferentes niveles de prioridad. Además, proponer otras técnicas de estimación y modelado, basadas en: filtro de Kalman, variable instrumental, lógica difusa, factor de olvido exponencial, aprendizaje automático, entre otras.

