











 nova página do texto(beta)
nova página do texto(beta) Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1 Introduction
In natural language processing (NLP), WSD is the problem of identifying the meaning of a word by taking into account its context of use. WSD is one of the oldest challenges in the field of NLP.
Indeed, disambiguation of word senses in context is easy for humans, but is a major challenge for automatic approaches.
Arabic is a challenging language due not only to the presence of ambiguous words with diverse meanings, but also to their semantic changes and their evolution over time. In fact, multiple contributions have enriched the Arabic language throughout history.
Thus, some words disappear, while others appear. But, some changes in word meanings may lead to the appearance of more updated words that correspond to contemporary reality. Indeed, the changes of word meanings produced by the modifications imposed by social life are frequent.
For instance, the word “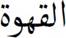 ” refers now to the “coffee” rather than the “wine” which was its original meaning. Thus, numerous works were developed in the literature to disambiguate Arabic words ([9, 7, 6]).
” refers now to the “coffee” rather than the “wine” which was its original meaning. Thus, numerous works were developed in the literature to disambiguate Arabic words ([9, 7, 6]).
All these works are concerned with identifying the meanings of modern Arabic words. However, the Arabic language can be classified into three main historical periods, namely old Arabic, middle-age Arabic and contemporary Arabic.
In light of this, it is obvious that the senses of words are not fixed. In fact, they are constantly changing and evolving due to time and events.
Therefore, it is crucial for a contemporary reader exploring texts from an earlier era to give relevant meanings to certain words depending not only on the historical situation in which these words were produced in their original texts, but also on contexts and conditions.
In this work, we propose a simple, yet effective, word sense disambiguation method that uses a combination of a lexical knowledge-base and contextualized embeddings.
In fact, we have investigated in this study the efficiency of contextual word embeddings, more precisely, stacked embeddings in order to disambiguate Arabic words.
Our method aims to train a neural embedding model based on the Flair architecture [2] to be able to identify the meaning of an ambiguous word with reference to the context of its occurrence in a particular text. Therefore, the major contributions of this paper are as follows:
– Pre-train the FLAIR model specifically for the Arabic language based on the Historical Arabic Dictionary Corpus (HADC) [5],
– Put forward a method, which helps to automatically extract the meaning of a given term that occurred in a particular context.
The main purpose of this method is not only to disambiguate the given word according to its context of use but also according to the era in which it occurred,
– Study different strategies in order to build context vectors and sense vectors,
– Show that the stacked embedding [2] technique achieves the best disambiguation performance.
The remainder of the paper is structured as follows: in section 2, we present a survey on the main approaches to word sense disambiguation that have been widely proposed.
We also give an overview of the related works, which focused on Arabic word sense disambiguation based on contextualized embeddings.
In Section 3, we illustrate our proposed method for Arabic word sense disambiguation. Section 4 presents our experiments and results. We finally draw a conclusion and future work directions in Section 5.
2 Related Works
Two different categories of machine learning and knowledge-based methods have been explored over the years to tackle the WSD problem [27]. On the one hand, knowledge based methods use a myriad of lexical-semantic resources, such as dictionaries, ontologies or thesaurus.
An example of such a method is the Lesk algorithm [19] that aims to disambiguate a word by choosing the sense with the greatest number of overlapping words between the definitions of each of the meanings of the target word, and those of the context words.
On the other hand, however, machine learning based methods exploit annotated and unannotated corpora to disambiguate words. These methods can be divided into supervised, semi-supervised and unsupervised learning approaches.
Supervised methods use large quantities of examples from sense-annotated corpora. The trained model is then used to assign the correct sense to each word in a given context.
Yet, unsupervised methods exploit a large amount of unlabeled data rather than manually sense-tagged corpora in order to disambiguate a word in a particular context. Semi-supervised methods use some annotated data to create a large semantically annotated corpus.
Among various approaches to the WSD task used over the past two decades, a supervised learning approach has been the most successful.
However, it is quite expensive in both time and cost to annotate a large amount of data because supervised WSD requires a large amount of manually labeled training examples to achieve good performance.
Unsupervised learning approaches, however, require neither labeled examples nor diverse resources. Thus, these approaches are typically less accurate than supervised algorithms because examples may not be assigned the correct sense.
During recent years, the use of contextualized embeddings that produce different representations for the same word depending on its contextual usage [11, 24, 3], has contributed to a series of significant advances in a range of NLP tasks, such as Named Entity Recognition [29], Sentiment Analysis [21] and WSD [26]. In fact, contextualized word embeddings are reported to be highly powerful as they represent words as vectors varying across linguistic contexts. This permits them to capture more complex characteristics of word meaning, including polysemy [14].
The established English success makes contextualized embeddings an attractive option for Arabic consideration. In this concern, many contextual embedding models have been developed, like BERT [11], RoBERTa [20], ALBERT [18], hULMonA [13] and AraBERT [8].
Accordingly, many works have investigated contextualized embeddings to solve WSD problems. However, works focusing on Arabic word sense disambiguation based on contextualized embeddings are relatively limited compared with other languages.
Some studies have recently implemented different embedding models for Arabic word sense disambiguation. [4] evaluated the performance of using word2vec and Lemma2Vec models for modern Arabic word disambiguation.
They constructed different models based on two different corpora, and they tuned different types of parameters. The final results show that Lemma2Vec models are slightly better than Word2Vec models for Arabic word disambiguation. [12] presented an Arabic gloss-based WSD technique.
They utilized the Bidirectional Encoder Representation from Transformers (BERT) to build two different models that can efficiently perform Arabic WSD. The authors used the models proposed in [8, 1] to build two gloss-based WSD models. The first model uses the pre-trained BERT models as a feature extractor without fine-tuning BERT layers to generate a contextual word embedding of the target word in its context. They also used it to generate a sentence vector representation of the definition sentence.
These representations’ vectors were then fed to a trainable dense layer to perform supervised WSD. In the second model, they fine-tuned BERT layers by training them with a sentence pair classification objective.
[16] trained a neural language model for Arabic language based on the Flair embeddings technique [3]. The main idea of their work is to study the role of different training parameters of the neural network in WSD performance.
Then, they developed a method that helps to automatically extract the meaning of a given Arabic term. Their proposed method consists in building a recurrent neural network model in order to calculate a distributed representation of both the contexts of use of the ambiguous term and its corresponding definitions.
It should be noted that all the previous methods that focused on Arabic Word Sense Disambiguation were just concerned with identifying the meaning of terms in modern Arabic. Only [16] focused on disambiguation of Arabic terms according to the distinct historical period in which they occurred.
However, they were limited to evaluate the Flair technique during the disambiguation process. Hence, the idea of disambiguating old and middle-age Arabic items by combining multiple embeddings is by no means original.
3 Arabic WSD Method Using Stacked Embeddings
This study is conducted based on two major motivating factors. First, the success of contextualized embeddings in English encourages us to perform a similar work in Arabic for further validation. Second, the power of contextualized embeddings, especially stacked embeddings, should be used to solve the Arabic WSD problem and disambiguate words according to both their contextual appearance in a source text and the era in which they emerged.
In this section, we describe the details of the proposed WSD method using stacked embeddings. The rationale behind this method is to embed the contextual uses and meanings of an ambiguous word taken from Arabic dictionaries.
Alongside, we applied the cosine similarity distance to determine which of the possible word senses for the target item is closer to the context representation.
The strong point of this method is that it only requires an external knowledge source and large unlabeled corpus and does not rely on labeled training data.
The aforementioned steps of the proposed method are illustrated in Figure 1. We describe each step of our method in the next sections.

3.1 Arabic Word Embedding Model
In this step, our primary objective is to train our own contextualized word embeddings based on the Flair framework [2]. In fact, Flair is an NLP library implemented by Zalando Researchfn.
It is built on top of PyTorchfn that provides access to many other state-of-the-art language models, such as FastText [10], GloVe [23], Elmo [24], and BERT [11].
Moreover, this technique essentially aims to learn character-level representations of a word in order to obtain dynamic vector representations for this word depending on its contexts of use.
To build a Flair Embedding model for Arabic, we have chosen the Historical Arabic Dictionary Corpus (HADC) [5]. It is originally designed to create a historical Arabic dictionary.
Indeed, this corpus contains texts at various periods, and in different domains and geographical distributions. The main characteristics of the HADC corpus are shown in Table 1.
Table 1 Main characteristics of the HADC corpus
| Historical period | Number of text |
| Pre-Islamic era | 100 |
| Islamic era | 101 |
| Abbasid era | 383 |
| Middle era | 147 |
| Modern era | 138 |
| Total | 869 |
Before training the Flair model, several normalization and preprocessing steps were performed. Infact, all diacritics, punctuations, Madda character, digits (Hindi and Arabic), Latin characters (including accented letters) were removed. Thereafter, we are going to use an LSTM with 1024 hidden states and one layer.
3.2 Context Representation
The goal behind this is to represent the context of the ambiguous word with the help of a vector. To attain this purpose, we employed two different methods, namely Document Pool Embeddings and Stacked Embeddings [2].
The first method aims to do a pooling operation over all word embeddings in a sentence to obtain an embedding for the whole sentence. In our case, the sentence represents the context in which the ambiguous word is used.
The second method aims to embed the ambiguous word in its context of use based on stacked embeddings. In fact, stacked embeddings are one of the most important concepts of the Flair library that aims at concatenating together language models in order to achieve better results.
Indeed, according to [2] stacking the embeddings can provide a powerful embedding to represent words. In this respect, we have stacked different embeddings in order to create a context vector of the ambiguous word. In the first place, we have combined Flair embedding with GloVe [23] and in the second place Flair with word2vec [22].
3.3 Sense Representation
To extract the senses of an ambiguous word, we have relied on well-defined resources, namely four Arabic dictionaries that describe the different historical periods of the Arabic language.
– For Old Arabic Dictionaries: we adopted Tahdhib Allougha Dictionaryfn by Abou Mansour Azhari.
– For Intermediate Arabic Dictionaries: we used Tej Alarous Dictionaryfn by Murtadha Zbidi.
– Concerning Modern and contemporary Arabic Dictionaries: we employed Contemporary Arabic Language Dictionaryfn.
So, one of the most important parts of our method consists in building the intended lexical dictionary. In fact, for old Arabic, we have used Tahdhib Alougha3 Dictionary.
Moreover, we have semi-automatically developed a structured electronic dictionary with an XML format containing the glosses of 100 ambiguous old Arabic words.
Likewise, we have developed a dictionary that contains the glosses of 100 ambiguous words extracted from Tej-Alarouss4.
Still, the last two dictionaries, Tahdhib Alougha and Tej-Alarous, are manually structured because they have complex structures which vary from one entry to another and they are characterized by a quasi-absence of markers.
For words in modern Arabic, we have relied on Contemporary Arabic Language5 dictionary. Indeed, we have an HTML version of this dictionary. The latter is distinguished by a set of markers facilitating the transformation of its raw content to a structured version in XML.
Then, we automatically converted it to a structured electronic XML format. For example, Table 2 describes the structures of Contemporary Arabic Language dictionary before and after the structuring step.
Table 2 Extract from the Contemporary Arabic Language dictionary before and after before and after the structuring stage
| TXT Dictionary | XML Dictionary |
 |
 |
Thus, our primary objective is to identify the different meanings of an ambiguous word based on the appropriate dictionary by taking into account the historical period in which this term appeared in the document.
Moreover, it is essential to know the historical period during which this word was used before constructing the appropriate vector for each definition of the ambiguous word.
In order to carry out this sub-step, we focused on the title of the document which takes the following form: The date of death followed by the name of the work.
The latter will be used, in this sense, to determine the historical period during which the document, containing the word to be disambiguated, was created.
It is important to note that the date of the author’s death is of considerable importance in our work as it can embody the most precise history of the author’s productions. In fact, we have not relied on the author’s date of birth due to two major reasons.
First, this date is sometimes unknown especially for old authors. Second, the date of birth does not reflect the author’s notoriety that most often begins after his death leaving his imprints behind him as a whole archive to be consulted.
Therefore, the historical period in which the document was produced is reflected in the most logical and objective way through the date of death.
Then, after obtaining all the sense definitions of the word to be disambiguated in the last step, we will represent each sense as a vector by using Document pool embedding and Stacked embedding methods previously introduced.
3.4 Similarity Using Cosine Distance
To attribute for each ambiguous word its appropriate sense, we chose the meaning with the closest semantic similarity to the context representation. The context vectors can then be compared to the possible word sense vectors for the abstruse item.
To measure the similarity between context vectors and sense vectors, we used a cosine distance metric. In fact, the similarity measure between two vectors,
4 Evaluation and Discussion
4.1 Code and Data
Our test corpus comprises 183 texts belonging to different historical periods. These texts have been extracted from the Historical Arab Dictionary Corpus (HADC) [5] and the Open Source Arabic Corpora (OSAC) [25].
Indeed, the Historical Arab Dictionary Corpus is divided into two main parts: one for learning and the other for testing. About 149 texts in old and medieval Arabic were specified and used for the test.
As for Modern Arabic, along with the texts extracted from the HADC, we have extracted some texts from the OSAC[25]. Moreover, we have trained the Flair embeddings model and executed the designed algorithms using the ”Google Colaboratoryfn” platform.
The hyperparameters used to train the model are as follows:
Indeed, this configuration allows us to obtain, after several experiments, the best embedding model that leads to better performance on the Arabic word disambiguation task in different historical periods.
Moreover, we have used Word2vecfn toolkit to learn vectors and Gensimfn to implement the model. As for GloVe we have taken the model proposed by Zalando Researchfn.
4.2 Results and Discussion
In order to measure the performance of our method, we have used the precisión metric. In our case, for any ambiguous word, this metric measures the number of contexts correctly divided by the total number of annotated contexts.
During the evaluation process, we relatively consider the historical period in which an ambiguous term emerged. The major purpose of our experiment consists in evaluating different stacks of word embeddings and testing their usefulness for disambiguating Arabic terms with reference to the historical period in which they turned out.
The results of our first experiment, in which Flair contextual embeddings and pooling techniques were used, are presented in the Table 3. Then, we studied the effect of stacking different embeddings. Table 3 shows the results of combining Flair embeddings with GloVe and word2vec.
Table 3 The average precisión obtained with Flair contextual embeddings and Stacked embeddings techniques
| Method | Old Arabic | Middle age Arabic | Modern Arabic |
| Document Pool Embedding (Flair) | 43.40% | 42.54% | 46.34% |
| Stack embeddings (Flair + GloVe) | 49.53% | 50.43% | 66,18% |
| Stack embeddings (Flair + word2vec) | 52.2% | 55.34% | 70.86% |
Therefore, combining word2vec [22] with Flair embeddings seems particularly beneficial for each historical period of the Arabic Language.
It should be noted, however, that combining GloVe [23] and Flair embeddings is better than the FLAIR embeddings alone.
Indeed, Table 3 illustrates that the stacked embedding method gives a better representation of the context containing the ambiguous word, and therefore performs better disambiguation results.
Consequently, using contextual embeddings, more particularly stacked embeddings, improved the results of disambiguating Arabic words according to each historical period during which these terms were used.
In summary, based on the aforementioned results, stacked embeddings represent an effective way to solve the Arabic word sense disambiguation problem. Moreover, the best results were obtained using stacked embeddings, more precisely by combinig Flair with word2vec.
This is because the latter allow a better representation of the corpus terms using vectors, and subsequently a better representation of the context containing the ambiguous word with its different definitions. Therefore, improving context vectors and definition vectors leads to better results yielded by our proposed method.
Finally, we have compared the results obtained by the proposed method with the method developed by [16] and the approach proposed by [12] (Table 4).
The attained precisión, which noticeably outperforms [16], is still less than the method proposed by [12]. We think that this difference might be due to the nature of ambiguous words and its complex contexts of use taken for the test. Thus, this contexts that appeared in a modern documents may have old meanings.
Recalling that we have based our comparison on the same test data, our method has given better results compared to that proposed by [16] and [17]. This result can confirm the good choice and performance of using stacked word embeddings in the Arabic Word Sense Disambiguation field.
5 Conclusion
This work evaluated the use of contextualized embeddings for disambiguating Arabic words. The main purpose of this study is to extract the meaning of a given word that appeared in the document.
More importantly, our method focuses equally on disambiguating not only words in Modern Arabic, but also words that emerged in ancient and middle-age Arabic periods.
We tested several embeddings including stacked embeddings in order to identify the perfect combination to achieve the best results.
The experiments show that combining word2vec and Flair word embeddings reaches a precisión of 70.86% for Modern Arabic, 52.2% for Old Arabic and 55.34% for Middle-age Arabic.
During our experimentation, we have noticed that some words have meanings that existed in the corpus rather than in the dictionary. As a future work, we will try to overcome this problem by proposing an unsupervised Arabic Word Sense Disambiguation based on contextualized embeddings.
Furthermore, we will intend to look into the induction of the different senses of a given Arabic word based on the HADC corpus.

