











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Many optimization problems, especially in the field of engineering, have variables that cannot take every value in a continuous space. Instead, such variables can only take integer values, or discrete values in the general sense. Integer variables are commonly used to define elements of the same class, e.g., worker assignment, car control with gear change, multi-stage mill design, selection of standardized elements, etc. Nonlinear problems where continuous, integer, and discrete variables coexist are known as Mixed-Integer Nonlinear Programming (MINLPs) problems [10]. In general, a MINLP problem can be defined by (1) – (6):
where
In a MINLP problem, the integer restrictions divide the feasible region into discontinuous feasible parts with different sizes. Fig. 1 shows a MINLP problem, where
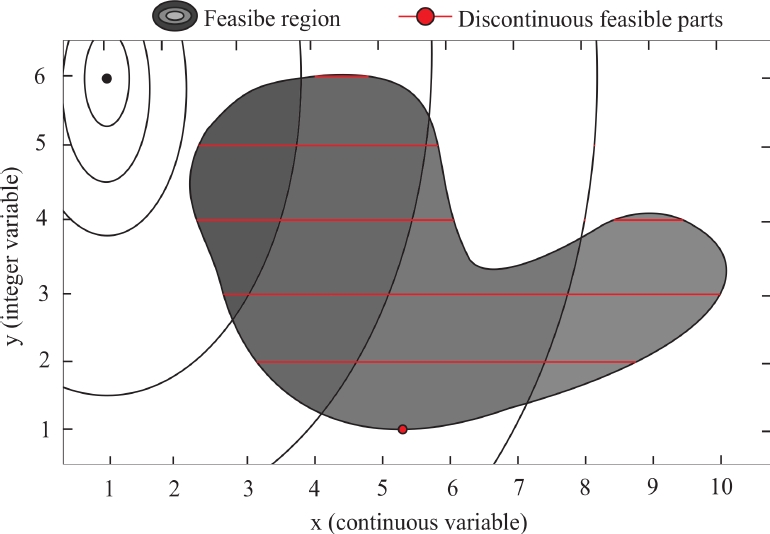
Fig. 1 MINLP problem example, where the shaded area represents the feasible region defined by the constraints, and the red lines are the discontinuous feasible parts that also satisfy the integer restrictions
The shaded area is the feasible region defined by the constraints, and the red lines are the discontinuous feasible parts that also satisfy the integer restrictions.
In recent years, meta-heuristic optimization algorithm have gained popularity over classical MINLP techniques.
Different extensions of genetic algorithms [2], particle swarm optimization [4, 16], differential evolution [1, 5], ant colony optimization [13], harmony search [3], estimation of distribution algorithm [15], aimed at solving MINLP problems have been proposed.
The most significant advantage of these algorithms is their robustness regarding the function properties, such as non-convexity or discontinuities [12].
The classical MINLP techniques (like branch and bound, cutting planes, outer approximation) generally require prior convexification and relaxation operations, which are not always possible [11].
On the other side, when the population of meta-heuristic optimization algorithm converges to a discontinuous feasible part, it quickly loses diversity, and the exploration is reduced, with no possibility of jumping out to another discontinuous feasible part. Compared to larger discontinuous parts, it is difficult to find feasible solutions in the smaller parts. If the best solutions are located in small parts, then the population might converge to the wrong solutions.
Only a few recent works focused on MINLP problems consider the drawbacks described above. In [7], a multiobjective differential evolution is proposed.
This strategy gives equal priority to integer conditions and quality of the solution, and the population converges to good regions regarding both criteria.
In [6], the authors propose a cutting strategy that penalizes non-promising solutions, which means that non-promising parts are progressively discarded.
In addition, they propose a repulsion strategy that penalizes the discontinuous parts where the population is trapped, in order to search better solutions in other regions.
More recently, in [9] the Estimation of Distribution Algorithm for Mixed-Variable Newsvendor problem (
The new proposal (
In this work, we propose an algorithm,
The first modification consists in establishing the exploration and exploitation components for the histogram of discrete variables, using the balance between both terms to improve the performance of the algorithm during the evolution.
The second modification is a repulsion operator to overcome the population stagnation in discontinuous parts, and continue the search for possible solutions in other regions.
Through a comparative analysis, the individual contribution of each modification to the algorithm performance was verified. The performance of
2 Estimation of Distribution Algorithm
New variable values are generated from statistical sampling. In the case of continuous variables, statistical sampling is hybridized with a mutation operator.
The replacement mechanism to get the next population is carried out through parent-offspring competition using the
2.1 Adaptive-width Histogram Model
The AWH model promotes promising regions by assigning them high probabilities, while in the other regions very low probabilities are assigned. One AWH is developed for each decision variable independently.
The search space
Points

The total number of bins is (
By assuming that
The
Let
However, a small value will be assigned through the parameter
The first case in (10) is the count of bins of promising regions
The third case assigns zero to the end bins with empty range. The probability of the
2.2 Learning-based Histogram Model Linked with
The LBH
The aim is to maintain an equal probability for all available integer values until

Fig. 3 LBH
When
If the
Therefore, if the histogram begins the learning process at that point, it has a better chance of converging to good solutions.
Considering that the variable
where
Let
Therefore, as the number of generations advances,
2.3 Sampling
After the histograms have been developed, the offspring is obtained by sampling the models.
In case of a continuous variable
For a discrete variable
2.4 Hybridization with a Mutation Operator
The mutation operation is added to generate the real variables. The vector of real variables
where
In the new proposal the values of
2.5 Constraint Handling
The replacement mechanism to get the next population is carried out through parent-offspring competition using the
The
Given two function values
where
This means that the candidates with a violation sum lower than
In the case of
The
where
3 Proposed Method
Two modifications for
The first proposed modification focuses on establishing a new balance between exploration and exploitation of the LBH
The second modification is based on the repulsion of discontinuous parts that stagnate the population, with the aim of seeking better solutions in other discontinuous parts.
3.1 LBH
As described in (12),
However, when certain admissible values begin to prevail statistically over others, the histograms and the populations begin to be similar, so the terms of the equation (12), instead of combining different information, emphasize the same search direction and cause accelerated (and often premature) convergence.
In this work, the following LBHε model is proposed:
where
In this model,
As can be seen in Fig. 4, now for very low values of

Fig. 4 LBH
As the value of
3.2 Repulsion
The repulsion strategy proposed in [6] consists of two steps: (i) judge whether the population is trapped into a solution, and (ii) apply a repulsion operator to the discontinuous feasible part containing the solution, and restart the population. Eq. (21) is the fail consideration to find a better solution:
where
If (21) is satisfied, it means that the algorithm fails to find a better solution, then the counter is incremented (
If
4 Experimentation and Results
4.1 Benchmark Problems
Sixteen MINLP problems (F1-F16) were used to evaluate the performance of
The maximum number of objective function evaluations was set at 200,000, and 25 independent runs were executed for each problem. The tolerance value for the equality constraints was set at 1.0E-04.
A run was considered as successful if:
4.2 Algorithms and Parameter Settings
To prove the individual contribution of each modification proposed, the instance with only
–
–
–
–
4.3 Analysis of Results
Table 1 summarizes the results of
Table 1
| Problem | Status | PSOmv | EDAmv | EDAmv(I) | EDAIImv |
| F1 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 100 | 0 | 100 | |
| Ave ± Std Desv | 17.000±0.000 + |
13.000±0.000 |
17.000±0.000 | + 13.000±0.000 | |
| F2 | FR | 100 | 100 | 100 | 100 |
| SR | 100 | 100 | 100 | 100 | |
| Ave ± Std Desv |
1.000±0.000 |
1.000±0.000 |
1.000±0.000 |
1.000±0.000 | |
| F3 | FR | 100 | 100 | 100 | 100 |
| SR | 24 | 100 | 76 | 100 | |
| Ave ± Std Desv | -3.879±0.217 + |
-4.000±0.000 |
-3.880±0.218 + | -4.000±0.000 | |
| F4 | FR | 100 | 100 | 100 | 100 |
| SR | 100 | 100 | 100 | 100 | |
| Ave ± Std Desv |
-6.000±0.000 |
-6.000±0.000 |
-6.000±0.000 |
-6.000±0.000 | |
| F5 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 100 | 76 | 100 | |
| Ave ± Std Desv | 1.240±0.000 + |
0.250±0.000 |
0.488±0.432 + | 0.250±0.000 | |
| F6 | FR | 100 | 100 | 100 | 100 |
| SR | 100 | 100 | 100 | 100 | |
| Ave ± Std Desv |
-6,783.582±0.000 |
-6,783.582±0.000 |
-6,783.582±0.000 |
-6,783.582±0.000 | |
| F7 | FR | 96 | 100 | 100 | 100 |
| SR | 0 | 24 | 28 | 36 | |
| Ave ± Std Desv | NA + | 0.895±0.235 + | 0.725±0.361 + | 0.642±0.359 | |
| FR | 100 | 92 | 100 | 100 | |
| SR | 0 | 0 | 0 | 0 | |
| Ave ± Std Desv | 7,222.847±94.800 | -NA + | 7,971.856±518.086 |
7,986.723±906.139 | |
| F9 | FR | 100 | 88 | 100 | 100 |
| SR | 16 | 0 | 0 | 0 | |
| Ave ± Std Desv | 7,284.444±283.224 | -NA | + 8,305.496±742.746 |
8,391.061±854.267 | |
| F10 | FR | 100 | 64 | 96 | 100 |
| SR | 64 | 0 | 0 | 0 | |
| Ave ± Std Desv | 7,337.332±277.610 | -NA + | NA + | 8,086.671±641.101 | |
| F11 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 0 | 0 | 0 | |
| Ave ± Std Desv | 46.280±6.601 + | 40.785±5.484 + | 38.119±5.378 |
37.822±5.334 | |
| F12 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 0 | 0 | 4 | |
| Ave ± Std Desv | 90.048±17.975 + | 74.500±30.941 + |
51.976±20.146 |
56.201±23.594 | |
| F13 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 0 | 0 | 4 | |
| Ave ± Std Desv | 8,956.649±7.448 |
8,943.236±29.864 |
8,955.137±31.467 |
8,949.792±35.701 | |
| F14 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 48 | 60 | 76 | |
| Ave ± Std Desv | 8,977.707±66.813 + | 8,963.673±41.007 |
8,954.966±10.181 |
8,958.233±41.392 | |
| F15 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 0 | 0 | 0 | |
| Ave ± Std Desv | 30.899±1.203- | 34.997±3.938 + | 30.580±1.827 |
31.639±2.105 | |
| F16 | FR | 100 | 100 | 100 | 100 |
| SR | 0 | 0 | 0 | 0 | |
| Ave ± Std Desv | 31.086±0.001 | -51.652±23.202 + | 31.598±1.353 ≈ | 31.636±1.365 | |
| [7/4/5] | [8/8/0] | [5/11/0] | —– |
These results are assessed considering the terms Feasible Rate (FR), Successful Rate (SR), Average (Ave), and Standard Deviation (Std Dev), over 25 independent runs. “NA” means that an algorithm cannot achieve 100% FR.
As mentioned above, the
However, for problems F1, F3, and F5, where the solutions are in small feasible parts, a slower convergence of
The repulsion strategy is very useful for this situation, since restarts the exploration in the remaining unexplored parts.
As can be seen, the implementation of repulsion strategy in
A Wilcoxon’s rank-sum test at a 0.05 significance level was carried out between
In Table 1,
As shown in the final part of Table 1, the results of
It is clear that
Regarding
Although in general
Therefore, it is recommended in future works to focus on promoting greater diversity in
5 Conclusion and Future Work
The first modification establishes a better balance between the exploration and exploitation terms in LBH
The second modification is a repulsion operator to overcome the population stagnation in discontinuous parts, and continue the search for good solutions in other regions.
Through a comparative analysis on sixteen test problems, the individual contribution of each modification to the algorithm performance was verified.
According to the Wilcoxon’s rank-sum,
The benchmark was also used to compare the performance of the improved proposal against
However,
First and third authors acknowledge support from SIP-IPN through project No. 20221928.
Fourth author acknowledges support from SIP-IPN through project No. 20221960.

