











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Nowadays, due to the continuous exponential growth of information produced in the medical domain, and due to the important impact of such information upon research and upon real world applications, there is a particularly great and growing demand for Question Answering (QA) systems that can effectively and efficiently aid users in their medical information search [1].
QA system takes a question posted in natural language instead of a set of key-words, analyzes and understands the meaning of the question, and then provides the exact answer from a set of knowledge resources [2]. The QA system consists of three main processing modules, namely, question processing, passages retrieval processing, and answer processing. A question processing is the primary and basic source through which a search process is directed for answer. Therefore, an accurate and careful analysis to the question is required. Thus, question processing is the most fundamental module in any QA system, and the performance of its results significantly impacts on the following modules of information retrieval and answer extraction.
To our knowledge, proposed Arabic medical QA systems are so limited either in terms of their performance as well as in terms of the types of questions they are designed to answer. Moreover, the most attention in Arabic has been paid to answering factoid questions, in which the answer is a single word or a short phrase [3].
Ambiguity is a common phenomenon in human natural language. In QA, ambiguity is a critical challenge in extracting what the user looking for in his question. Therefore, ambiguity can cause confusion in interpretation of the question, and then impacts negatively the performance of the QA system.
In this paper, we propose a new approach to handle medical questions (factoid and complex questions) for the Arabic language. Moreover, our approach overcomes the ambiguity in the question processing module, an issue that has not been appropriately addressed in the field of Arabic QA.
The remainder of this paper is structured as follows. Section 2 presents the related works. Ambiguity problems are presented in section 3. Section 4 describes our approach. Section 5 deals with the experimentation carried out to evaluate the efficiency of our question analysis module. Finally, section 6 draws the main contributions and proposes further perspectives.
2 Related Works
The problem of answering questions formulated in natural language has been studied in the field of Information Retrieval (IR) since the mid-1990s [4]. However, unlike IR, the QA system returns simple and precise answer to a natural language question instead of a large number of documents [5, 6] . As we mentioned, the QA system is composed of three modules: question analysis, passage or document retrieval and answer extraction. Different QA systems may use different implementation for each module [7, 8]. In this section, we focus on some studies for the question analysis module.
Until now, very little effort was directed toward the development of QA system for the medical domain in the Arabic language, compared to other languages such as French and English. This is mainly attributed to the particularities of the medical domain and the language (see Section 3). The situation is further aggravated by the lack of linguistic resources and Natural Language Processing (NLP) tools that is available for Arabic [9, 10].
In an effort to achieve a better question analysis, [2] analyzed the question to extract type and category of desired answer whether it is a place, a quantity, a name or a date, which makes the answer extraction easier.
[10] analyzed Arabic questions by formulating the query, extracting the expected answer type, the question focus and the question keywords. The focus is the noun phrase of the question which the user wants to ask about. For instance, if the user’s question is “What is the capital of Canada?” then the question focus is “Canada” and the keyword is “capital” and the expected answer type is a named entity for a location.
[11] analyzed the question by:
— Tokenization and normalization.
— Determining answer type by question words (When, What...)
— Named entity recognition.
— Focus determination by extracting the main named entity.
— Keywords extraction.
— Removing stop words using the Khoja stop list.
— Query expansion using the Arabic dictionary of synonyms. Named entities are not expanded to avoid ambiguity.
— Stemming by Khoja’s Stemmer and named entities are not stemmed.
— Query generation of keywords into a boolean formula.
[3] made six steps to process Why-questions. They tokenized the question, then normalized it, then removed stop words (optional step). After that, they applied khoja’s stemmer to obtain the root of each non-stop word in the question. Then, they used the extracted keywords to formulate and generate the query. Finally, they extended the list of keywords by including synonyms and words that share the same root.
The systems of [12] and [13] are developed for the medical domain in Arabic language. These systems analyze only factoid questions by extracting the topic and the focus of the question, and extracting named entities. The system of [12] classifies the questions into organization, location, person, viruses, diseases, treatment.
We can confirm, from literature reviews, that most Arabic QA systems ensure analysis of factoid questions. Nevertheless, there are few studies that have addressed the problem of answering complex questions. In addition, there are few works that have integrated semantic analysis and treated the medical field in the Arabic language, which makes the development of a new Arabic QA system is crucial.
3 Ambiguity
A study of different questions showed us the existence of several linguistic phenomena which can cause ambiguities in the question processing. Indeed, if we solve these problems, the errors will be so minimal and our system will be more relevant compared to existing Arabic QA systems.
3.1 Specific Arabic Difficulties
Arabic specific difficulties consist in its richness that needs special processing, which makes regular NLP systems, designed for other languages, unable to process it. One of the Arabic-specific difficulties is the lack of diacritics (i.e. kasra, fatha, damma), which leads to more ambiguous situations than any other language. This issue can be explained through the question  (Who was killed in Uganda?).
(Who was killed in Uganda?).
The lack of diacritics in verb  (to kill) presents at least two cases for the question processing:
(to kill) presents at least two cases for the question processing:
—
 qutila which means that the question is “Who was killed in Uganda?”, so
qutila which means that the question is “Who was killed in Uganda?”, so  in this question means (was killed).
in this question means (was killed).—
 qatala which means that the question is “Who did kill in Uganda?”, so
qatala which means that the question is “Who did kill in Uganda?”, so  in this question means (kill).
in this question means (kill).
Arabic language morphology is challenging when compared to other languages. This is because Arabic is a highly agglutinative and derivational language where a word token can replace a whole sentence in other languages. For example, for the question  (Do we can prevent the clot?), the sentence “Do we can” can be expressed in one Arabic word
(Do we can prevent the clot?), the sentence “Do we can” can be expressed in one Arabic word  which includes the verb
which includes the verb  (can), the prefix
(can), the prefix 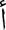 (do) and the pronoun
(do) and the pronoun  (we). Therefore, extracting keywords from an Arabic question will be more complex than any other language. Furthermore, in a question like
(we). Therefore, extracting keywords from an Arabic question will be more complex than any other language. Furthermore, in a question like  (Who are the two scientists who won the Nobel Prize in medicine for cancer treatment?), the user looks for the name of two persons (i.e. James P. Allison and Tasuku Honjo). In English, the system catches this user require through the word “two”. In Arabic QA, this keyword is embedded in the word
(Who are the two scientists who won the Nobel Prize in medicine for cancer treatment?), the user looks for the name of two persons (i.e. James P. Allison and Tasuku Honjo). In English, the system catches this user require through the word “two”. In Arabic QA, this keyword is embedded in the word 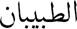 Alt abiybaAni (two scientists) thanks to the suffix
Alt abiybaAni (two scientists) thanks to the suffix  Ani. Actually, the question above is just an example; the morphology of an Arabic word may contain multiple information (basic POS, number, gender, etc.) which are important for each module of Arabic QA. Unlike English and most Latin-based languages, Arabic does not have capital letters which makes Named Entity Recognition (NER) harder [14].
Ani. Actually, the question above is just an example; the morphology of an Arabic word may contain multiple information (basic POS, number, gender, etc.) which are important for each module of Arabic QA. Unlike English and most Latin-based languages, Arabic does not have capital letters which makes Named Entity Recognition (NER) harder [14].
3.2 Specific Difficulties of Medical Domain
Apart from ambiguity in Arabic language, ambiguity also appears in medical terms. We observed that the more ambiguous terms are diseases names. For example, the term  means both an insect and a dermatological disease. This issue can be explained through the question
means both an insect and a dermatological disease. This issue can be explained through the question  (What is a louse?); such system can extract the following answers:
(What is a louse?); such system can extract the following answers:


In fact, to extract the right answer, the system must understand the context. For example, in (2), the keyword  (disease) indicate that it is a definition of the disease
(disease) indicate that it is a definition of the disease  (Louse). Furthermore, in open-domain, the nature of the expected answer is known from the interrogative pronouns. For instance, in a When-question
(Louse). Furthermore, in open-domain, the nature of the expected answer is known from the interrogative pronouns. For instance, in a When-question  (When America discovered?), the nature of the expected answer is a time. Nevertheless, in medical-domain, a When-question can indicate an age, a condition or a time. Table 1 gives an example. To extract the correct answer, we must define a sequence of keywords which define the question and disambiguate it in the sense that it indicates what the question is looking for.
(When America discovered?), the nature of the expected answer is a time. Nevertheless, in medical-domain, a When-question can indicate an age, a condition or a time. Table 1 gives an example. To extract the correct answer, we must define a sequence of keywords which define the question and disambiguate it in the sense that it indicates what the question is looking for.




4 Proposed Method
The challenges discussed in the previous section make clear the need for new method to deal with Arabic medical QA. In addition, the most of previous studies are based on a superficial analysis of factoid questions (i.e. where, when, how much/many, who and what).
The originality of our approach lies in the disambiguation and the semantic analysis of factoid and complex questions (i.e. why and how to). In our proposal, the question analysis module is based on five steps as illustrated in Fig 1: Corpus study, Named Entity Recognition (NER), Stop word removal, Disambiguation, and Question Expansion (QE). In the first step, questions are gathered and studied to define the disambiguation patterns.

These patterns are transformed into transducers to process any type of medical question in Arabic language. Questions will be processed by the parallel steps (NER, Stop word removal, and disambiguation) using dictionaries, syntactic grammars, and morphological grammar in order to get some useful information. Finally, the last step will extend the extracted keywords.
4.1 Corpus Study
The need to have an Arabic corpus is a necessity for processing Arabic QA systems. Indeed, the questions are gathered from several sources, namely, discussion forums, frequently asked questions (FAQ) and some questions translated from Text REtrieval Conference (TREC). Currently, we collected 350 questions which contain seven categories (see Table 2). The questions are then subjected to an analysis step.
Table 2 Collected questions
| Question type | What | When | Where | Who | How many/much | How | Why |
| Number | 85 | 53 | 42 | 38 | 45 | 39 | 48 |
According to our study, we identify 158 question disambiguation patterns. Table 3 shows some patterns of the question  (When). These patterns will be transformed into transducers to parse the questions.
(When). These patterns will be transformed into transducers to parse the questions.

4.2 Named Entity Recognition (NER)
The previous studies emphasize that the NER is important for all the QA system components. Indeed, the integration of a NER step will definitely boost our system performance because the answer of a factoid question is a named entity.
In our case, we developed our own NER tool especially formulated for our proposal. This step is based on dictionaries and transducers. We have considered five categories:
4.3 Stop Words Removal
This step removes the conjunctions, prepositions and interrogative pronouns. After removing the stop words, the important terms in the question will be remaining. In our proposal, the stop words are eliminated from the outputs of the syntactic transducers (see Fig 3).


4.4 Disambiguation
Our system is based on dictionaries and transducers. These resources allow us to disambiguate ambiguous words and the nature of the expected answer (Problems mentioned in the previous section).
4.4.1 Word Sense Disambiguation (WSD)
WSD process is required in application such as a QA application [15]. Some ambiguous words which have a different sense influence negatively the extraction of the correct answer. Let’s take the following questions as an example:


As shown above, the verb  have the sense of “generate” in the question (1) and the sense of “born” in the question (2). To resolve this problem, as shown in our dictionary in Fig 2, each ambiguous word is associated with semantic feature to identify the sense of the entry (sens-generer, sens-naitre). This feature is used in the syntactic transducers (see Fig 3).
have the sense of “generate” in the question (1) and the sense of “born” in the question (2). To resolve this problem, as shown in our dictionary in Fig 2, each ambiguous word is associated with semantic feature to identify the sense of the entry (sens-generer, sens-naitre). This feature is used in the syntactic transducers (see Fig 3).
The WSD process allows also our system to define the correct stem. For instance, the stem of  ywld in question (1) is
ywld in question (1) is  wal ada and in the question (2) is
wal ada and in the question (2) is  >awolada.
>awolada.
4.4.2 Disambiguation of the Nature of the Expected Answer
For a reliable disambiguation, each defined pattern in the corpus study step is transformed into transducers. The identification of the nature of the expected answer is related to the focus of the question. For example, the transducer of Fig 3 describes the paths of the pattern ”When<Verb>Fetus| Child |Infant?” (see Table 3). This transducer can analyze a question like  (When the child crawls?). The focus in this example is
(When the child crawls?). The focus in this example is  (child), so the nature of the expected answer is “Age”.
(child), so the nature of the expected answer is “Age”.
4.5 Question Expansion
Extraction only original question keyword is proved to have some limitations. To get rid of these limitations, we need to define the meaning the user looking for.
Therefore, in question expansion (QE), we extend the list of the exact words of the user’s question by adding new words that connect semantically to those in the question. Since the documents may not contain the terms that the user used in his question, expanding question will increase the chance of getting the answer [16].
In the previous works, QE is achieved using Arabic WordNetfn. In our dictionaries, the feature Syno (for synonyms) is used to expand questions. This feature is called in the QE transducer as shown in Fig 4.

After processing the question  (What is the appropriate use of sunscreen for a baby?) with the previous steps, the transducer of Fig 4 can extract the synonym of
(What is the appropriate use of sunscreen for a baby?) with the previous steps, the transducer of Fig 4 can extract the synonym of  <isotixdaAm which is
<isotixdaAm which is  <isotiEomaAl, the synonym of
<isotiEomaAl, the synonym of 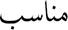 munaAsib which is
munaAsib which is  mulaAim and the synonym of
mulaAim and the synonym of  raDiyEo which is
raDiyEo which is  Tifl.
Tifl.
Expanding question can be applied also in order to overcome the situations where the Passage Retrieval (PR) module eliminates relevant passages containing other forms of the question keywords. The idea now is adding other forms of the keywords that share the same root (see Fig 5).

Let’s continue with the same question  .
.
Thanks to QE process, the PR module can extract not only the passages that contain the keyword  raDiyEo but also its broken plural form
raDiyEo but also its broken plural form  ruDãEo. This process is applied also to extracted synonyms. Therefore, we consider each keyword with its synonym and its different forms since the QE would theoretically generate all these terms.
ruDãEo. This process is applied also to extracted synonyms. Therefore, we consider each keyword with its synonym and its different forms since the QE would theoretically generate all these terms.
The expanded list of terms extracted from the question will be sent to the PR module to extract the passages that may contain the answer.
5 Experimentation and Evaluation
In our proposal, linguistic resources are built with the linguistic platform NooJ [17]. We conduct a set of experimentation to evaluate the performance of our question analysis module. Therefore, we exploit a test corpus which contains 399 questions. For each question type ( “What”,
“What”,  “When”,
“When”,  “Where”,
“Where”,  “Who”,
“Who”,  “How many/much”,
“How many/much”,  “How”,
“How”,  “Why”) a set of 57 questions is used.
“Why”) a set of 57 questions is used.
The results of applying the transducer that extracts the type of the expected answer and keywords are illustrated in Fig 6. This transducer allows the NER, stop words removal, and disambiguation. Then, the keywords are expended by the QE transducers.

After applying the analysis on the test corpus using our linguistic resources, we obtain the results illustrated in Table 4.
Table 4 Summarizing the measure values
| Method | Without disambiguation | With disambiguation |
| Precision | 66% | 93% |
| Recall | 58% | 87% |
| F-Measure | 61% | 89% |
Table 4 shows that the disambiguation process enhances the F-Measure by 28%. It is then concluded that by reducing ambiguity, especially when processing the medical domain in the Arabic language, the obtained results will be increased.
Errors are often due to the problem in writing some Arabic letters such as the letter  “A” which can also be writing like
“A” which can also be writing like  > or
> or  | or
| or  <. For example, in some question, we can find the word “inflammation” written like
<. For example, in some question, we can find the word “inflammation” written like 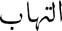 AlotihaAbo or
AlotihaAbo or  <ilotihaAbo. To resolve this problem, we need to rewrite the question by unifying all variants of a letter into a single form. Furthermore, the presented errors in the question analysis are due to dictionaries’ coverage that must be improved and the complexity of some questions that requires special handling techniques.
<ilotihaAbo. To resolve this problem, we need to rewrite the question by unifying all variants of a letter into a single form. Furthermore, the presented errors in the question analysis are due to dictionaries’ coverage that must be improved and the complexity of some questions that requires special handling techniques.
6 Conclusion
In the present paper, we have developed a question analysis module (QAM) for our system to analyze an Arabic medical question.
Our QAM is mainly concerned with the identification of four factors, namely, keywords extraction, disambiguation, question expansion, and nature of the expected answer extraction. This analysis of question allows extracting all the necessary information that will be used as inputs for the other QA components. Our proposed method achieves satisfactory results.
In the future work, we seek to add a pre-processing to normalize the question. We also seek to improve our linguistic resources by adding new terms in the dictionaries.

