











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Nowadays, recommender systems represent a high economic, social and technological impact at international level due to the main technological companies as Google, Facebook, Twitter, LinkedIn, Netflix, Amazon, Microsoft, Yahoo!, eBay, Pandora, Spotify and others more have been used these systems in their leading services [1]. Further, these systems have been contributed on information overload problem, user experience, user decision making, and companies sales [2].
A recommender system is a software tool that suggests items as products, films, jobs, friends, web sites, songs and other more items based on the tastes users [3]. Besides, their performance can be optimized with hybrid approaches that combined two or more recommender algorithms to complement their disadvantages with advantages of other algorithms. For this reason, big money amounts are inverted to optimize algorithms and to develop new research on hybrid approach.
This research presents a systematic literature review on the hybrid approaches for recommender systems that is designed with an Okoli and Schram’s information systems guide [4]. Systematic literature review is a systematic, explicit, and reproducible method for identifying, evaluating, and synthesizing the completed and recorded research produced by researchers, scholars, and practitioners. Additionally, other related works used a software engineering guide, however, information systems are more related to recommender systems than software engineering. The guide contains eight steps that are showed in Figure 1.
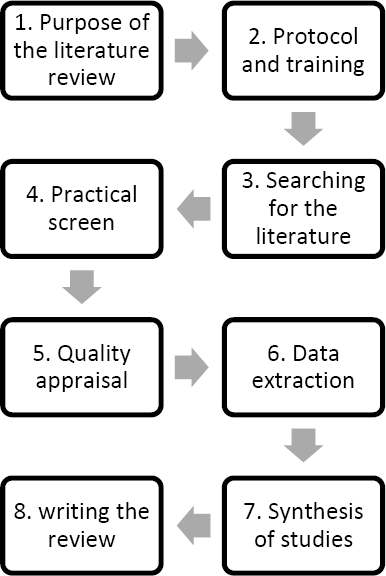
These steps are developed in the body of this work for generated a recent art state from 2016 to 2020 on hybrid recommender systems.
2 Related Works
The Ҫano y Morisio’s quantitative research [3] is a principal related work because they developed an art state from 2005 to 2015 on hybrid recommender systems. Furthermore, they used a software engineering guide to analyze challenges and solutions with data mining and machine learning techniques. The most important challenges identified were cold-start and data sparsity. The new problems identified was recommendations on multi domains, context variation and evolution of tastes users. The foremost application domain was the movies. Accuracy metrics for evaluation were the more used. Finality, the new opportunities identified were context recommendations, parallel hybrid algorithms and processing of biggest datasets.
Other recent related works are the following. In [2] is introduced a systematic study on recommender systems in the e-commerce, this study used a software engineering guide for developed an art state from 2008 to 2019. In [5] is presented a systematic literature review on trust-based recommender systems in Internet of Things (IoT), this work used a software engineering guide for developed an art state from 2008 to 2018. However, these related works are not specifically addressed to hybrid approaches.
For this reason, this study generates an art state from 2016 to 2020 on hybrid approaches for recommender systems to fill the knowledge gap from Ҫano y Morisio’s research [3]. Unlike the related works, this research uses a more recent guide, and it is addressed for information systems.
3 Purpose of the Literature Review
The general purpose is to analyze recommender hybrid approaches progress and to identify opportunity areas for further research. The goals are to analyze the recent trends about challenges, methodologies, datasets, application domains and evaluation metrics on hybrid approach.
4 Protocol and Training
Research questions are defined in this section to develop the rest steps of information systems guide.
| RQ1. | Which recent and relevant studies are addressed on recommender hybrid approaches? |
| RQ2. | Which problems are tackled with recommender hybrid approaches? |
| RQ3. | What experimental solutions are generated with recommender hybrid approaches? |
| RQ4. | What techniques and algorithms are used for recommender hybrid approaches? |
| RQ5. | Which evaluation metrics are used for recommender hybrid approaches? |
| RQ6. | Which datasets are used for recommender hybrid approaches? |
| RQ7. | Which application domains are used for recommender hybrid approaches? |
| RQ8. | Which future works and opportunity areas exist for recommender hybrid approaches? |
5 Searching for the Literature
Information sources selected are five important scientific databases, these databases have been used by other related works of indexed journals in Journal Citation Report (JCR) [3, 2]. These datasets are:
Query structure is based on six keywords and synonyms set for each keyword. The first three keywords are gotten of Ҫano y Morisio’s related work [3], other three keywords are proposed by this work to include challenges, datasets and evaluations on recommender hybrid approaches. The Table 1 describes the keywords with their synonyms to generate the query terms.
Table 1 Keyword and synonyms for the query
| # | Keyword | Synonyms |
| 1 | Hybrid | Hybridization, Mixed |
| 2 | Recommender | Recommendation |
| 3 | System | Systems, Software, Technique, Techniques, Technology, Approach, Engine |
| 4 | Challenge | Challenges, Problem, Problems, Issue, Trouble |
| 5 | Dataset | Corpus |
| 6 | Evaluation | Assessment, Metrics |
AND/OR Boolean operators are used to define the query with the previous terms. Two subqueries are joined, the first subquery represents the general searching on hybrid recommender systems, and the second subquery represents the specific searching about challenges, datasets, and evaluations on recommender hybrid approaches. The Table 2 shows the query developed with the terms previously defined.
Table 2 Query for scientific databases
| Query |
| ((Hybrid OR Hybridization OR Mixed) AND (Recommender OR Recommendation) AND (System OR Systems OR Software OR Technique, OR Techniques OR Technology OR Approach OR Engine)) OR ((Hybrid OR Hybridization OR Mixed) AND (Recommender OR Recommendation) AND (System OR Systems OR Software OR Technique, OR Techniques OR Technology OR Approach OR Engine) AND (Challenge OR Challenges OR Problem OR Problems OR Issue OR Trouble OR Dataset OR Corpus OR Evaluation OR Assessment OR Metrics)) |
Searching for the literature is realized with five scientific databases previously selected and a query previously defined. The general results are 383,937 publications retrieved of which, Spring Link retrieves 319,124 publications, ACM Digital Library retrieves 37,349 publications, Scopus retrieves 12,921 publications, Web of Science retrieves 12,717 publications and IEEE Xplore retrieves 1,826 publications. Springer Link retrieved the most publications amount, and IEEE Xplore retrieved the least publications amount. However, practical screen and quality appraisal steps will select the valid publications to generate the art state.
6 Practical Screen
The inclusion and exclusion criteria are defined to select publications, also the publications will be reviewed for the first time of the 382,937 retrieved publications in the searching for the literature.
6.1 Inclusion Criteria
Inclusion criteria are defined to include retrieved publications material of the scientific databases. Inclusion criteria are the following.
6.2 Exclusion Criteria
Exclusion criteria are defined to exclude retrieved publications material of the scientific databases. Exclusion criteria are the following.
– Papers’ title and abstract not addressing on recommender hybrid approaches.
– Gray literature.
– Papers published before 2016 and after 2020.
– Papers not written in English.
The first literature review identifies 70 papers, these papers satisfy to inclusion and exclusion criteria. Besides, 25 Web of Science papers are selected, 19 Springer Link papers are selected, 15 ACM Digital Library papers are selected, 6 Scopus papers are selected, and 5 IEEE Xplore papers are selected.
7 Quality Appraisal
Quality appraisal is evaluated with a weighted questionnaire [3]. Questions are weighted with coefficients of 0.5 for low importance, 1 for medium importance and 1.5 for high importance. Answers are valuated with score values of 0 for “no” answer, 0.5 for “partly” answer and 1 for “yes” answer. Table 3 explains quality criteria based on seven weighted questions.
Table 3 Weighted questionnaire for quality appraisal
| # | Question | Wt. |
| 1 | Did the study clearly present the problem that is addressing? | 1 |
| 2 | Did the study clearly develop an experimental solution? | 1.5 |
| 3 | Did the study clearly describe recommender techniques or algorithms? | 1 |
| 4 | Did the study clearly use metrics evaluation for recommender systems? | 1.5 |
| 5 | Did the study clearly describe the dataset that is using? | 1 |
| 6 | Did the study clearly introduce the application domain? | 0.5 |
| 7 | Did the study clearly describe their further works? | 0.5 |
The evaluation for each paper is explain with follow formula:
This formula realizes a product operation between the question weight (wt) and the answer score value (sv), then the average is computed for the seven questions with their answers correspondingly. The quality threshold to accept papers should be than 0.81.
A second literature review is realized based on quality criteria to select 36 papers of the 70 papers selected in the first literature review. This second literature review realizes a detailed review on 36 papers through complete readings. Furthermore, 12 papers’ ACM Digital Library are selected, 12 papers’ Web of Science are selected, 5 papers’ Springer Link are selected, 4 papers’ IEEE Xplore are selected, and 3 papers’ Scopus are selected. The Table 4 presents the papers retrieved amount in scientific databases and the papers selected in the first and second literature review.
8 Data Extraction
Data extraction is realized on 36 papers selected in the second literature review, moreover a form [3] is generated in Table 5 for the extraction of 18 data, these data are used for answer to the research questions, for this reason the third column contains a research question number.
Table 5 Form for data extraction
| Extracted data | Explanation | RQ |
| ID | Identification number. | - |
| Title | - | RQ1 |
| Authors | - | - |
| Year publication | - | RQ1 |
| Name | Journal or conference name. | - |
| Volume | Journal volume. | - |
| Issue | Journal issue. | - |
| Location | Publication location. | - |
| Source | Database from which was retrieved. | - |
| Problem | Research problem. | QR2 |
| Experiment | Experimental description. | QR3 |
| Methods | Methods and algorithms applied. | QR4 |
| Techniques | Recommender individual techniques applied. | QR4 |
| Hybrid approach | Recommender hybrid approaches applied. | QR4 |
| Evaluation | Evaluation metrics and forms. | QR5 |
| Dataset | Dataset used. | QR6 |
| Domain | Application domain used. | QR7 |
| Future work | Future work suggestions. | QR8 |
9 Results
This section develops the synthesis of studies step and writing the review step. In Figure 2, it is introduced the distribution of 36 papers revised, including 20 conference papers and 16 journal papers. The papers amount for each year are classified on chronological order, this classification proves that these papers included in the present systematic literature review are recent and current. Furthermore, the journal papers amount and conference papers amount have a minima difference due to journal paper generally are more extensive than the conference papers.

The journal papers are present the best quality results than the conference papers, in Figure 3 is showed the quality average for both publication types, journal papers quality average is 0.97 and conference papers quality average is 0.88, however, both comply with the quality criteria established. Additionally, this classification of papers’ quality level servers to develop an art state more solid.

The problems distribution of the 36 studies analyzed on recommender hybrid approaches are introduced in Figure 4. The principal challenges identified are cold start, accuracy, sparsity, data source integration, scalability, and other problems as lack of personalization, aspect-based recommendations, location-based recommendations, lack of novelty, explanations for recommendations, transparency and interpretability, session-based recommendations, and recommender parallel algorithms. In total, 13 research problems are identified, and 6 principal trends are classified.
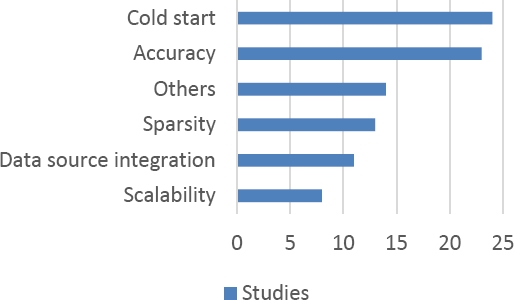
The studies that tackle the problems identified on recommender hybrid approaches are showed in Table 6. Moreover, 3 studies tackle an only research problem, nevertheless, the most studies tackle 2 or more research problems due to the algorithms combinations, for example the studies [6, 7] tackle up to 5 problems.
Table 6 Studies that tackle problems identified on recommender hybrid approaches
| ID | Study | Cold start | Accuracy | Other | Sparsity | Data source integration | Scalability |
| 1 | [8] | x | x | x | |||
| 2 | [9] | x | x | ||||
| 3 | [10] | x | x | ||||
| 4 | [11] | x | x | ||||
| 5 | [12] | x | x | ||||
| 6 | [13] | x | x | x | x | ||
| 7 | [14] | x | x | x | |||
| 8 | [15] | x | x | x | |||
| 9 | [16] | x | x | ||||
| 10 | [17] | x | |||||
| 11 | [18] | x | x | x | |||
| 12 | [19] | x | x | ||||
| 13 | [20] | x | x | x | |||
| 14 | [21] | x | |||||
| 15 | [22] | x | |||||
| 16 | [23] | x | x | x | |||
| 17 | [24] | x | x | x | |||
| 18 | [25] | x | x | ||||
| 19 | [26] | x | x | ||||
| 20 | [27] | x | x | ||||
| 21 | [28] | x | x | x | |||
| 22 | [29] | x | x | x | |||
| 23 | [30] | x | x | ||||
| 24 | [31] | x | x | x | x | ||
| 25 | [32] | x | x | ||||
| 26 | [33] | x | x | x | |||
| 27 | [34] | x | x | ||||
| 28 | [35] | x | x | ||||
| 29 | [36] | x | x | ||||
| 30 | [37] | x | x | ||||
| 31 | [38] | x | x | x | |||
| 32 | [39] | x | x | x | |||
| 33 | [40] | x | x | x | |||
| 34 | [6] | x | x | x | x | x | |
| 35 | [41] | x | x | x | |||
| 36 | [7] | x | x | x | x | x |
9.1 Problems and Challenges
9.1.1. Cold Star
Cold start is a traditional problem in recommender systems, and it is the principal trend in this art state. This challenge happens when a new user or new item have no ratings history in the system. For this reason, predicting user interest is a hard task since no personalized data can be used as reference [9]. [6] tackled cold start problem with a novel recommender systems called Capsmf that used a deep learning based text analysis model. In [24], it is proposed a personalized reranking of paper recommendations using paper content and user behavior. In [12], it is developed a hybrid recommender system based on profile expansion technique to alleviate cold start problem. In total, 24 studies tackle this problem.
9.1.2. Accuracy
The second trend is accuracy problem that represents quality and efficiency of the recommendations, a high accuracy in the results means a better recommendations quality and a low errors rate in the system [2]. [8] tackled this problem with the generation and understanding personalized explanations in hybrid recommender systems. In [18], it is proposed a hybrid recommender system for sequential recommendations combining similarity modes with Markov Chains. In [20], it is generated a comparative analysis of recommender systems based on item aspect opinions extracted from user reviews. In total, 23 studies tackle this problem.
9.1.3. Sparsity
The third trend is sparsity problem that is a similar problem to cold start, this problem arises when the users rate a very limited number of item and the items catalog is very large, in consequence a sparse user-item rating matrix is generated with insufficient data for identifying similar users or items, this cause a negative impact on the recommendations quality [3]. [39] tackled this problem with a hybrid location-based recommender system for mobility and travel planning.
In [27], it is proposed an efficient algorithm for recommender system using kernel mapping techniques. In [13], it is introduced a novel model for hospital recommender system using hybrid filtering and big data techniques. In total, 13 studies tackle this problem.
9.1.4. Data Source Integration
The fourth trend is data source integration problem to enrich the recommender system data input, so it will improve its performance [8]. [40] tackled this problem with a neural explainable recommender model based on attributes and reviews. In [30], it is proposed an automatic playlist continuation using a hybrid recommender system combining features from text and audio. In [14], it is introduced a cross-platform app recommendation by jointly modeling ratings and texts. In total, 11 studies tackle this problem.
9.1.5. Scalability
The fifth trend is scalability problem that is a difficult characteristic to achieve due to scalability represents the number of users and items that a system can bear. A system designed to recommend few items to some hundreds of users will probably fail to recommend hundreds of items to millions of people, unless it is designed to be highly scalable [3]. [29] tackled this problem combining aspects of genetic algorithms with weighted recommender hybridization. In [41], it is proposed a recommender system based on collaborative filtering using ontology and dimensionality reduction techniques. In [25], it is introduced an enhancing recommendation stability of collaborative filtering recommender system through bio-inspired clustering ensemble method. In total, 8 studies tackle this problem.
9.1.6. Other Problems
Lack of personalization in recommendations limits the systems efficiency because users have several tastes. This problem is tackled in [38] with personalized hybrid recommendation for group of users in a multimedia domain. In total, 6 studies tackle this problem.
Aspect-based recommendations use textual reviews like a rich information source for users’ preferences because these reviews contain users’ opinions on items aspects. In [20], techniques of natural language processing (NLP), data mining and sentiment analysis for aspects extraction and recommendations are used. In total, 3 studies tackle this problem.
Location-based recommendations utilize social networks information to suggest interesting locations. In [39], it is proposed a hybrid location-based recommender system for mobility and travel planning. In total, 2 studies tackle this problem.
Problems tackled for an only study are lack of novelty, explanations for recommendations, transparency and interpretability, session-based recommendations, and recommender parallel algorithms.
In total, 14 studies tackle other problems on recommender hybrid approaches.
9.2 Recommender Techniques
Recommender individual techniques distribution on hybrid approaches is presented in Figure 5. This figure presents 7 trends on recommender techniques. These trends are collaborative filtering (CF), content-based filtering (CBF), knowledge-based filtering (KBF), sequence-based (SB), demographic filtering (DF), context-aware (CA) and other techniques (OTs) as utility-based, location-based, popularity-based, social networks-based, behavior-based, session-based, aspect-based, trust-based, bots-based, and cross-domain recommendations. In total, 16 recommender techniques are identified, and 7 principal trends are classified.

9.2.1. Collaborative Filtering
Collaborative filtering is a traditional recommender technique, and it is a principal trend in this art state. Basic idea is that people who had similar tastes in the past will also have similar tastes in the future [3]. Besides, a user-item rating matrix is used generally to generate recommendations by this technique. CF is classified in memory-based and model-based techniques [12, 41], memory-based techniques use similitude functions to search users or items similarities to predict users’ ratings, and model-based techniques use machine learning techniques to generate predictive models. Other CF classification is introduced by [14], where CF is classified in neighborhood methods and latent factor methods. Neighborhood methods look for users or items similarities called neighborhoods, then these methods predict users’ ratings.
Latent factor methods focus on fitting the user-item rating matrix using low-rank approximations and applying the matrix to identify new user-item associations. In total, 30 studies use the collaborative filtering.
9.2.2. Content-based Filtering
The second trend is content-based filtering that recommend items similarities [38], this technique use a user profile that contents attributes of user’s favorite items, then items similarities to user profile are recommended [19]. CBF is utilized generally for text recourses in fields of NLP, information retrieval (IR) and data mining. In total, 21 studies use the content-based filtering.
9.2.3. Knowledge-based Filtering
The third trend is knowledge-based filtering that depend on patterns and rules extracted from deep knowledge of the interesting items for users. It is realized through deep understanding of market and application context, or through capturing users’ preferences via dialogs or questions, then a discrimination tree of item attributes is built with these preferences [22]. KBF uses semantic information, for example, item semantic information includes the attributes, the relationships among the items, and relationships between meta-information and items [41]. In total, 9 studies use knowledge-based filtering.
9.2.4. Sequence-based
The fourth trend is sequence-based technique that models sequential dependencies over the user-item interactions in a sequence. User-item interactions may be when a user views or buys items on an e-commerce. Unlike CF and CBF, SB techniques handle interactions like a dynamic sequence, then actual and recent user’s preferences are got by an analysis of sequence dependencies to get recommendations more precise. SB techniques are classified in traditionality sequence models, latent representation models and deep neural network models [42]. In total, 7 studies use sequence-based techniques.
9.2.5. Demographic Filtering
The fifth trend is demographic filtering that uses a user’s demographic profile with specific information as age, gender, country and other user data. Then user similarities are grouped, and recommendations are performed based on user groups [34]. In total, 6 studies use demographic filtering.
9.2.6. Context-Aware
The sixth trend is context-aware techniques that uses context information as time and user’s behavior aspects as views, clicks, shopping, etc., this context information is utilized to enrich other conventional recommender techniques for improve their performance [7]. CA techniques are classified in prefiltering, postfiltering, and context modeling [14]. In prefiltering, context drives data selection. In postfiltering, context is used to filter recommendations after traditional method. In context modeling, context is integrated directly into the model. In total, 3 studies use context-aware techniques.
9.3 Recommender Hybrid Approaches
Recommender hybrid approaches distribution is introduced in Figure 6, this figure presents 7 trends on recommender hybrid approaches. These hybrid approaches are weighted, mixed, switching, feature combination, feature augmentation, cascade and other approaches that combining multidisciplinary algorithms. In total, 7 recommender hybrid approaches are identified and classified like principal trends.

9.3.1. Weighted
The first trend is weighted approach that combines several recommender techniques’ score with a linear combination or a voting scheme for produce a single recommendation [10]. In total, 14 studies use weighted approach.
9.3.2. Mixed
The second trend is mixed approach that utilizes a basic algorithm for merge recommendations lists of several techniques into a single list [11]. On the other hand, a challenge is to include rankings in lists combined, however, the combination generally is based on ratings prediction [27]. In total, 5 studies use mixed approach.
9.3.3. Switching
The third trend is switching approach that selects one of several recommendation techniques depending on the situation [11]. In total, 3 studies use switching approach.
9.3.4. Feature Combination
The fourth trend is feature combination approach that allows data from the different techniques to be combined and transmitted to a single recommendation algorithm [11]. A study uses feature combination approach.
9.3.5. Feature Augmentation
The fifth trend is feature augmentation approach that allows the result of one technique to be used as the input of the other one [11]. A study uses feature augmentation approach.
9.3.6. Cascade
The sixth trend is cascade approach that ranks recommender techniques to refine results of each technique. The first technique is principal because other techniques only refine its results [11]. A study uses cascade approach.
9.3.7. Other Hybrid Approaches
A hybrid recommender system based on hypergraph topologic structure for social networks is proposed in [23], this work develops a hybrid matrix factorization model, and combines CF and CBF. A personalized reranking of paper recommendations using paper content and user behavior is generated in [24], moreover this work combines CBF, SB and behavior-based recommendations. A neural explainable recommender model based on attributes and reviews is developed in [40]. A hybrid recommender system using deep learning based text analysis model is introduced in [6]. In total, 16 studies use other hybrid approaches. Besides, deep learning is a principal alternative to generate hybrid approaches.
9.4 Methods and Algorithms
Methods and algorithms distribution is presented in Figure 7, this figure presents 10 principal trends on methods and algorithms for recommender hybrid approaches. These trends are clustering, cosine similarity, matrix factorization, natural language processing, optimization algorithms, k-nearest neighbors (KNN) algorithms, neural networks, information retrieval, Euclidean distance, and other methods and algorithms as rule-based systems, user’s profile expansion technique, parallel algorithms, feedback rating, semantics algorithms, demographic similarity, Pearson correlation similarity, haversine formula, Markov chains, association rules, ontologies, ensemble methods, kernel mapping methods, fuzzy logic, intelligent agents, decision trees and analytic hierarchy process method. In total, 26 algorithms and methods are identified, and 10 principal trends are classified.

The first trend are clustering methods that cluster users or items similarities with unsupervised learning. K-modes algorithm is utilized to clusters sets of users and items based on context information in [23]. Users’ ratings on films are clustered with an expectation maximization algorithm in [41]. A bio-inspired clustering ensemble method is used for the collaborative filtering in [25]. In total, 11 studies use clustering methods.
The second trend is cosine similarity that looks for similar users or items with its computations. In [24], cosine similarity is utilized with TF-IDF (Term frequency–Inverse document frequency) technique to compare vectors that contain research papers’ content. In [20], cosine similarity is employed in several ways for CBF based on user profile and item aspect opinions extracted. In [10], the adjusted cosine is applied to search similar items with CF. In total, 11 studies use cosine similarity.
The third trend are matrix factorization methods that derive latent factors for characterize to users and items like vectors that contain these latent factors, then vectors’ items more similarities to user’s vector are the recommendations. In [14], a latent factor model that maps users and items in a latent space of k dimensions for model multi-domain rankings is developed. In [23], a matrix factorization method is employed to obtain the optimal latent features for users and items using the stochastic gradient decent (SGD) algorithm. In [6], a probabilistic matrix factorization is integrated to a text analysis model of a deep neural network. In total, 8 studies use matrix factorization methods.
The fourth trend is natural language processing that understands and generates natural language between humans and computers [43]. In [14], reviews and descriptions of cross-platform apps are represented like documents, then non-English words and stop words are removed, as well verbs and adjectives are normalized with the help of the Porter stemmer algorithm, and a LDA method is run to extract topics. In [20], opinions of items aspects are extracted on users’ textual reviews, then opinions’ polarity is identified with sentiments analysis methods, furthermore methods based on vocabulary, word frequency, syntactic relationships and topics models are applied. In total, 8 studies use NLP.
The fifth trend are optimization algorithms that design a system that optimizes a set of metrics subject to constraints [44], furthermore these algorithms identify inputs to maximize or to minimize to a function. In [18], a learning model is generated with a loss function called sequential Bayesian personalized ranking (S-BPR) using hyper parameter, then the hyper parameter is optimized by maximum a posteriori (MAP) estimation, and SGD algorithm is used for estimation of the optimal hyper parameter. In [39], three swarm intelligence algorithms are used to cluster to users, these algorithms are ant colony optimization (ACO), cuckoo search algorithm (CSA) and mussels wandering optimization (MWO). In total, 7 studies use optimization algorithms.
The sixth trend are k-nearest neighbors’ algorithms that generally employ a user-item rating matrix as information source, as well a function similarity is applied to identify similar users or similar items called neighbors. Then users’ ratings are predicted based on k-nearest neighbors identified. In [20], collaborative patterns in aspects opinions data are exploited using a KNN algorithm with the combination of CF and Pazzani’s CBF. In [10], baseline CF is generated with KNN algorithm using adjusted cosine similarity. In total, 6 studies use KNN algorithms.
The seventh trend are artificial neural networks that imitate the humans’ biological neurons behavior, besides these methods are very important for the deep learning.
In [24], a two-layer feedforward neural network is used as the scoring function, where the input layer takes features from each candidate item, and the output layer contains one node that yields the score. In [40], a convolutional neural network (CNN) is utilized to process items reviews and to get items semantic characteristics. In total, 6 studies use artificial neural networks.
The eighth trend is information retrieval that look for text documents in large documents collections based on an information need [45]. In [24], a research paper is represents in a word space with TF-IDF vectors, these vectors content values for words and bigrams in the article title, abstract and keywords, then cosine similarity is used to compare TF-IDF vectors. In [18], TF-IDF method and cosine similarity are used for the content-based filtering. In total, 5 studies use information retrieval.
The ninth trend is Euclidian distance that compute the distance between two points in a Euclidian space, and Pythagorean theorem is utilized. In [24], a loss function is utilized, and Euclidean distance is applied to preserve paper-paper similarities from the browsing history. In [34], Euclidean distance is employed to compute the distance between characteristics vectors for the CBF. In total, 4 studies use Euclidean distance.
Other methods and algorithms as rule-based systems, user’s profile expansion technique, parallel algorithms, etc., are identified. In total, 22 studies use other methods and algorithms.
9.5 Application Domains
Application domains distribution is presented in Figure 8, this figure presents 7 principal trends on application domains for recommender hybrid approaches. These trends are movies, multi-domains, music, products, tourism, social networks, location, apps and other domains as hospitals, session actions, jobs, research papers, personal names, smartphones, medicos, and books. In total, 16 application domains are identified, and 9 principal trends are classified.

The first trend is movies domain that it is used by principal companies like Netflix, Amazon, GroupLens and IMDb. In total, 16 studies use movies domain.
The second trend are multi-domains that combine multiple information sources to enrich the recommendations, however these domains represent a big challenge. In total, 8 studies use multi-domains.
The third, fourth, fifth and sixth trend are domains of music, products, tourism, and social networks. In total, each domain is used for 4 studies. The seventh and eighth trend are domains of location and apps. Other domains as hospitals, session actions, jobs, etc., are employed in 9 studies.
9.6 Datasets
Datasets distribution is presented in Figure 9, this figure presents 7 principal trends on datasets for recommender hybrid approaches. In total, 17 datasets are identified, and 7 principal trends are classified. These trends are MovieLens, independent datasets, Amazon, TripAdvisor, Yelp, Last.FM and other datasets as IMDB, RecSys, Kaggle, Epiones, Douban, ScienceDirect, FilmTrust, Nameling Discovery, Million playlist, Yahoo! and Book crossing.

The first trend is MovieLens dataset that is used widely for some research due to it contains movies metadata, movies tags and users’ ratings, besides this dataset has multiple versions for several research types. In total, 13 studies use MovieLens dataset.
The second trend are independent datasets, these datasets are developed in their own research. In total, 9 studies use independent datasets.
The third trend is Amazon dataset that it is a multi-domain dataset because has several types of commercial products as clothes, movies, jewelry, books, etc., further it contains metadata items, users’ ratings, and users’ text reviews. In total, 4 studies use Amazon dataset.
The fourth trend is TripAvisor dataset that it is utilize widely in tourism domain. In total, 3 studies use TripAvisor dataset.
The fifth and sixth trends are Yelp dataset (multi-domain) and Last.FM dataset (music domain). In total, each dataset is used by 2 studies.
Other datasets as IMDB, RecSys, Kaggle, etc. are used by 10 studies.
9.6 Evaluation Metrics
Evaluation metrics distribution is presented in Figure 10, this figure presents 11 principal trends on evaluation metrics for recommender hybrid approaches. In total, 26 evaluation metrics are identified, and 11 principal trends are classified. These trends are recall, precision, root mean squared error (RMSE), normalized discounted cumulative gain (NDCG), F1, mean absolute error (MAE), accuracy, user tests, coverage, mean average precision (MAP), and other metrics as novelty, crowd-sourced, receiver operating characteristics (ROC) curve, silhouette technique, rate coverage, similarity, mean reciprocal rank, mean squared error (MSE), user space coverage (USC), aggregate diversity (AD), expected popularity complement (EPC), clicks rate, root mean squared shift (RMSS), R-precision, cold start and normalized version of the MAE (NMAE).

The first trend is recall metric with 16 studies, the second trend is precision with 15 studies, the third trend is RMSE with 11 studies, the fourth trend is NDCG with 8 studies, the fifth trend is F1 with 7 studies, the sixth trend is MAE with 7 studies, the seventh trend is accuracy with 5 studies, the eighth trend is user tests, the ninth trend is coverage, and the tenth trend is MAP. Other metrics as novelty, crowd-sourced, ROC curve, etc. are used by 17 studies.
There is a classification for several evaluation types, these evaluation types are online evaluations and offline evaluations. Online evaluations are realized to real users in real time so that these evaluations are a big challenge. Further, these evaluations are generated with crowdsourcing as Mechanical Turk (MTurk) [8]. Offline evaluations are realized with datasets, these datasets are divided in training dataset and test datasets, the 80% of data are generality for training and 20% of data are for testing, besides 5-fold cross-validation is used mainly.
10 Conclusions
At present, recommender systems represent a high economic, social and technological impact at international level due to the main technological companies have been used these systems in their leading services because recommender systems have been contributed on information overload problem, user experience, user decision making and companies sales. Furthermore, hybrid approaches are used widely to optimize recommender systems.
A systematic literature review on the hybrid approaches for recommender systems is generated for develop an art state from 2016 to 2020 considering a knowledge gap from a principal relate work. Besides, unlike other works, this research uses a more recent guide that is addressed to information systems that it is a principal area related to recommender systems.
The principal findings identified on recommender hybrid approaches are presented next. The problems trends are cold start, accuracy, sparsity, data source integration, scalability, and other problems. The recommender techniques trends are collaborative filtering, content-based filtering, knowledge-based filtering, sequence-based, demographic filtering, context-aware and other techniques. The hybrid approaches trends are weighted, mixed, switching, feature combination, feature augmentation, cascade, and other hybrid approaches. The methods and algorithms trends are clustering, cosine similarity, matrix factorization, natural language processing, optimization algorithms, k-nearest neighbors algorithms, neural networks, information retrieval, Euclidean distance, and other methods and algorithms. The application domains trends are movies, multi-domains, music, products, tourism, social networks, location, apps and other domains. The datasets trends are MovieLens, independent datasets, Amazon, TripAdvisor, Yelp, Last.FM and other datasets. The evaluation metrics trends are recall, precision, RMSE, NDCG, F1, MAE, accuracy, user tests, coverage, MAP, and other evaluation metrics.
These findings about challenges, methodologies, datasets, application domains and evaluation metrics on hybrid approaches will benefit to recommender systems community to generate new research and to identify new opportunities areas on recommender hybrid approaches.
The future works are to expand art state with other years after 2020, to refine query terms, to include other scientific databases, to refine practical screen and quality appraisal steps, to search a more recent guide addressing to recommender systems, and to select a application domain.

