











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Identifying the reduplications from the text corpora is a specific string matching or a pattern matching problem based on the morphological [1] as well as a phonological [2] criterion. Whereas string matching or pattern matching is a fundamental operation in computer science. It plays an essential role in various real-world applications, including Natural Language Processing (NLP). Various string matching algorithms have been developed like Rabin-Karp’s algorithm [4], Knuth-Morris-Pratt's (KMP) algorithm [5], automata-based algorithm [6]. The fuzzy-based approximate string matching algorithms are also used in various applications like spellcheckers, search engines, Bioinformatics, etc. But none of these are suitable for partial reduplication detection in the run of text [3] in the context of NLP applications. Reduplication detection in a text is a common problem in NLP. None of the conventional string matching algorithms are suitable for partial reduplication detection. Researchers tried to address such a problem using the ruled-based heuristic approach, but the rules are very much language-dependent and have low coverage. This situation motivated us to develop a fuzzy rule-based system to capture the partial reduplication from the corpus.
2 Types of Reduplications
Based on the morphological construction the reduplications are of two types [7], total and partial reduplication. The total reduplication is the repetition of the whole word such as “bye-bye”, “quack-quack” etc. in English. On the other hand, partial reduplication is defined as the repetition of part of the word such as "flip-flop", “criss-cross” in English.
The reduplication is relatively less frequent in English-like languages and their morphological construction is also simple.
But the languages of African, South-Asian, etc. are complex and difficult to identify from the text corpus. There is complex morphological construction on partial reduplication.
It may be with suffixes, prefixes, sub-string, etc. Sometimes it co-occurs with the eco-word, synonyms, antonyms, etc. [8]. From the computational point of view, handling the total reduplication is relatively simple. However, the main concern is in partial reduplication, which has been addressed in this paper.
3 Importance of Reduplications
Reduplication is a morphological operation of repetitions. Sometimes it affixing reflects certain phonological characteristics of the language. It is also used in inflection to convey the grammatical dimension like the number and sometimes derived a new word. Furthermore, reduplication is often used when a speaker adopts a tone that is more expressive or figurative speech and it is also often but not exclusively iconic in meaning. Sometimes reduplication is used in echoing and found in onomatopoeia. In some cases, it is used to emphasize e.g. no-no in English. Quite a few reduplications can be found in child language, such as bobo, dada, etc.
What exactly the syntax or semantic changes depends on a particular language [9]. It has been identified that there are forty-five functions in 108 languages [10]. For example, it is used to express augmentation, intensification, diminution, attenuation, etc [11].
Augmentation implies the increase of quantities, activity, or greatness. Augmented through reduplication adds to the semantic value of a word in various languages. In the Indonesian language, the reduplication of buku (book) is buku-buku (plural form of a book). In Bengali  / ke means who and its reduplicated
/ ke means who and its reduplicated  -
-  / ke-ke impels plural form of who.
/ ke-ke impels plural form of who.
In the intensification increase the degree e.g. in the Indonesian language the reduplication of mue ko (book) is mue-mue ko (big book). In Bengali  / jore means fast and its reduplicated
/ jore means fast and its reduplicated  -
-  / jore-jore impels very fast.
/ jore-jore impels very fast.
Diminution says the decrease of quantity, e.g. In Indonesian anak means child where reduplicated anak-anak means adopted child.
The above examples show that Several semantic and syntactic properties are connected with reduplication amongst the languages [12]. All such features of the reduplications are not encapsulated in the various NLP applications. In order to achieve the high precision result, it needs a special treatment of reduplication in various applications. Consider an example i.e. S1 and S2 in Bengali:
S1: 

 / ghare bekar yubaka (Unemployed youth at home).
/ ghare bekar yubaka (Unemployed youth at home).
S2: 
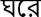

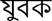 / ghare ghare bekar yubaka (Unemployed youth at every house).
/ ghare ghare bekar yubaka (Unemployed youth at every house).
In sentence S1, there is a word  / ghare, which means in house, but its reduplicated forms appear in sentence S2,
/ ghare, which means in house, but its reduplicated forms appear in sentence S2, 
 / ghare ghare, which means every house. It clearly shows that how reduplication changes the semantics. Figure 1 shows that the Bengali-English google machine translation system fails to capture the reduplicated meaning. It is just an instance but it happens in most cases. These examples show the importance of reduplication in language processing applications.
/ ghare ghare, which means every house. It clearly shows that how reduplication changes the semantics. Figure 1 shows that the Bengali-English google machine translation system fails to capture the reduplicated meaning. It is just an instance but it happens in most cases. These examples show the importance of reduplication in language processing applications.

4 Reduplications in Bengali
The Bengali language belongs to the Indo-Aryan language spoken most widely spoken language of Bangladesh and the second most widely spoken of the 22 scheduled languages of India [13]. It is one of the state languages of the Indian states of Tripura, West Bengal as well as some parts of Assam it is the second most spoken language in the Indian subcontinent. The Bengali-speaking population is more than 250 million native and more than 300 million speakers in total, making Bangla the sixth language [14] after English, Chinese, Hindi, Spanish, Arabic.
4.1 Existing Work and Frequency of Reduplication in Bengali
The literature shows that most of the existing works on reduplication are found in the domain of linguistic. It can be found in various Indic languages like Bengali [3], Sanskrit, Tamil [15], Kannada [16], Manipuri, or other South Asian languages [17]. Some of the researchers tried to address the issue in computational aspects [18]. But it is hardly found that tried to explore its quantization or addressed all forms and aspects. Senapati et. al. [3] tried to develop a heuristic-based generic approach, but that does not cover all types of partial reduplications.
Reduplication is a common feature in Bengali and is frequently used in spoken and written text.
A corpus-based study shows that [3] there is 0.71% of the word in a corpus are reduplicated and 9.4% of the sentences contain reduplicated words in the TDIL corpus [19]. These statistics show the importance of the reduplicated feature and it cannot be ignored in any NLP applications. The rich morphology of the language makes it more productive and complex.
4.2 Peculiarities of Bengali Reduplication
Based on the morphological construction there are different types of reduplication like total or partial as mentioned earlier. But in the case of Bengali, the partial reduplication is more complex and lots of peculiarities are there. The morphology of reduplication is of the form X X (or X-X or XX) i.e. repetition of a word or token. In the case of partial it is of the form X Y (or X-Y or XY), where X is part of Y or Y is a part of X. Sometimes X is the prefixing or suffixing Y. Sometimes X, Y have the opposite meaning of each other but X Y together forms a reduplication. Some of such peculiarities are explained below with examples.
When X is a prefix of Y: in another word it can be expressed as Y is the inflection form of X. Example, 
 / dhab dhabe (pure white color).
/ dhab dhabe (pure white color). 
 / tak take (pure red color). Here each individual word is not a valid term, but the reduplicated expressions give a significant meaning.
/ tak take (pure red color). Here each individual word is not a valid term, but the reduplicated expressions give a significant meaning.
When X is a suffix of Y: in this case, X appears as a suffix of Y. Example, 
 / nayai onayai (justice or injustice).
/ nayai onayai (justice or injustice). 
 / dhataba adhataba (metallic or non-metallic).
/ dhataba adhataba (metallic or non-metallic). 
 / gayene agayene (consciously or unconsciously). Here the meaning each pair of words are opposite to each other and together they give a separate meaning. In such cases, the reduplicated gives the meaning completeness i.e. meaning gives a whole concept.
/ gayene agayene (consciously or unconsciously). Here the meaning each pair of words are opposite to each other and together they give a separate meaning. In such cases, the reduplicated gives the meaning completeness i.e. meaning gives a whole concept.
When X Synonym Y: when two words X, Y are lexically different but their meaning is same or almost similar together form a reduplication. For example, 
 / churi chamari (robbery) where the meaning of
/ churi chamari (robbery) where the meaning of  / churi is theft,
/ churi is theft,  / chamari means illegal work.
/ chamari means illegal work. 
 / chal chulo (economically poor) where the meaning of
/ chal chulo (economically poor) where the meaning of  / chal is rice and
/ chal is rice and  / chulo means cooking burner.
/ chulo means cooking burner.
When X Antonym Y: when two words X, Y are lexically different, but their meaning is opposite to each other that forms a reduplication. For example, 
 / aagu pichu (back and forth),
/ aagu pichu (back and forth), 
 / kachhe dure (near and far),
/ kachhe dure (near and far), 
 / dena pawna (loan and owing), etc.
/ dena pawna (loan and owing), etc.
When Y is the eco word in X: An echo word is a word or phrase that does not have any meaning and does not exist separately. It co-occurs with another word to form a reduplication. Generally, it imitates the same sound as the associate word and has the same morphological construction. The eco word changes its meaning as the like duplications, etc. Example, 
 / khabar dabar (varieties food etc.) where the meaning of
/ khabar dabar (varieties food etc.) where the meaning of  / khabar is food and
/ khabar is food and  / dabar is eco-word. Similarly,
/ dabar is eco-word. Similarly, 
 / jal tal (water, beverage etc.) where the meaning of
/ jal tal (water, beverage etc.) where the meaning of  / jal is water and
/ jal is water and  / tal is an eco-word. In this case, the first token has a specific meaning, and when it scans with the eco-word it changes its meaning.
/ tal is an eco-word. In this case, the first token has a specific meaning, and when it scans with the eco-word it changes its meaning.
The above examples show that just using the string matching algorithm it is difficult to identify such reduplication from the corpus. Some researchers tried to identify such pairs using the heuristic approaches. But such an approach does not give high precision accuracy. Not even fuzzy-based string matching algorithms retrieve all such partial reduplications but it gives many false positive instances.
For example, the in-build Python-based fuzzy string matching library Fuzzywuzzy returns the matching score of 67 in both the cases  / ehat' (this hand),
/ ehat' (this hand),  / ohat’ (that hand)) and (
/ ohat’ (that hand)) and ( / ehat’ (this hand),
/ ehat’ (this hand),  / khat’ (how many hands)). But in first case is a valid partial reduplication but not in the second case. So, this matching score cannot be used to identify partial reduplications.
/ khat’ (how many hands)). But in first case is a valid partial reduplication but not in the second case. So, this matching score cannot be used to identify partial reduplications.
In our approach, we have considered the other morpho-linguistic features in the matching criterion like the length of characters, the length of characters in the vowel modifiers, ordered sequence of the characters, ordered sequence of the vowel modifiers, position of mismatches, rhythmic similarity, eco words, antonym words. Each feature is described in brief with examples.
Length of characters: length of characters is an important feature in reduplication. In the case of English reduplication (XY) in almost all cases the length (X) = length (Y). But in case of Bengali reduplication it follows either length (X) = length (Y) or length (X) = length (Y) + 1. For example, 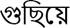
 / guchhiye gachhiye (well-organized way) where it is length (X) = length (Y). And
/ guchhiye gachhiye (well-organized way) where it is length (X) = length (Y). And 
 / karone okarone (all the time) where it is length (X) = length (Y) + 1.
/ karone okarone (all the time) where it is length (X) = length (Y) + 1.
Length of vowel modifier: in Bengali, 10 vowels appear as signs act as a modifier is known as vowel modifier. These are 

 ,
, 

 ,
, 

 ,
, 

 ,
, 
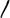
 ,
, 

 ,
, 

 ,
, 

 ,
, 

 ,
, 

 . These vowel modifiers play an important role in the morphology and construction of the reduplications. Our observation is that the length of the vowel modifier is an important feature in identifying the partial reduplicated word.
. These vowel modifiers play an important role in the morphology and construction of the reduplications. Our observation is that the length of the vowel modifier is an important feature in identifying the partial reduplicated word.
It is observed that in most of the cases the mismatched character is either in an alphabet or in a vowel modifier but not in both cases.
Example, in 
 / malis talis (message etc.) the alphabet set are <
/ malis talis (message etc.) the alphabet set are < 
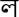
 > and <
> and < 

 > and their vowel modifier sets are <
> and their vowel modifier sets are < 
 > and <
> and < 
 >. In this case, there is a mismatch in an alphabet.
>. In this case, there is a mismatch in an alphabet. 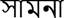
 / samna samni (nearby), here the alphabet set <
/ samna samni (nearby), here the alphabet set < 

 > and <
> and < 

 > but their vowel modifier sets are <
> but their vowel modifier sets are < 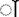
 > and <
> and < 
 >. In this case, the mismatch is in the vowel modifier.
>. In this case, the mismatch is in the vowel modifier.
Position of mismatches: in partial reduplication, the repetitive word has a partial match or in other words, we can say there is a mismatch. The position of mismatch is an important feather in partial reduplication.
For example, 
 / guchhiye gachhiye (well organized), the mismatch is at the very beginning of the characters.
/ guchhiye gachhiye (well organized), the mismatch is at the very beginning of the characters. 
 / khorach khoracha (expanses), the mismatch is at the end position. It is noted that in most of the cases the mismatch is at either beginning or at the end position.
/ khorach khoracha (expanses), the mismatch is at the end position. It is noted that in most of the cases the mismatch is at either beginning or at the end position.
5 Fuzzy Inference System Architecture
A Fuzzy Inference System (FIS) is a technique that is used for mapping from an input space to an output space using fuzzy logic.
A FIS tries to formalize the reasoning of a set of rules of human language employing fuzzy logic [20-21]. The architecture of the FIS includes four components, these are Fuzzification, Knowledge base, Inference engine, and Defuzzification.
The architecture of the FIS is illustrated in Figure 2. Each component is illustrated below. The fuzzification [22-23], choosing of membership function [24-25], fuzzy knowledge base [26-27], aggregation rules [28], defuzzification [29] are the important components of the fuzzy inference system.

6. Rule-Base for Identifying for Partial Reduplication
The rule-base of identifying the partial reduplication of Bengali is comprised of the features that are described in section 4. We described them in two sets, the crisp rule base and fuzzy rule base are described next.
6.1 Crisp Rule Base
This set consists of three rules. Rules are defined as a crisp rule because rules are hard decisions like yes or no. That means, if it satisfied a predefined condition then it is considered as a reduplicated form otherwise not.
Rule 1:
IF X is synonym of Y THEN (X Y) is reduplicated
Rule 2:
IF X is antonym of Y THEN (X Y) is reduplicated
Rule 3:
IF Y is a eco word THEN (X Y) is reduplicated
In the implementation point of view, to find the synonym and antonym a Bengali WordNet has been used that build with a similar scheme of BanglaNet [30]. On the other hand, to check the eco-word find the entry of the word in the Bengali WordNet. If the entry is not found, then it is considered an eco-word. Because the eco word is invalid or it does not have any meaning.
6.2 Fuzzy Rule Base
This set also consists of nine fuzzy rules. These rules are dealing with morpho-linguistic features like the number of mismatch characters (i.e. length comparison of characters), the number of mismatches of vowel modifiers (i.e. length comparison of vowel modifiers), the position of mismatch.
Before we formulate the actual fuzzy rules, define the fuzzy linguistic variables of similarity score and some terminologies used in the rules:
Score = {high, medium, low}
charMismatch(X, Y) returns the number of mismatch characters of the strings X and Y.
vmMismatch(X, Y) returns the number of mismatches of vowel modifiers in the strings X and Y.
Rule 1:
IF charMismatch(X, Y) = 0 THEN Score = high
Rule 2:
IF charMismatch(X, Y) = 1 THEN Score = medium
Rule 3:
IF charMismatch(X, Y) ≥ 2 THEN Score = low
Rule 4:
IF vmMismatch(X, Y) = 0 THEN Score = high
Rule 5:
IF vnMismatch(X, Y) = 1 THEN Score = medium
Rule 6:
IF vmMismatch(X, Y) ≥ 2 THEN Score = low
Rule 7:
IF misPosition (X, Y) = first THEN Score = high
Rule 8:
IF misPosition (X, Y) = mid THEN Score = low
Rule 9:
IF misPosition (X, Y) = last THEN Score = high
A summarization of the rules is given in Table 1.
7 System Architecture
Figure 3 shows the system architecture of our sys-tem of identifying the partial reduplication from the corpus.

As described above, our rule base is consisting of two sets of rules, the crisp rule-base, and the fuzzy rule-base. The crisp rule base consists of three crisp rules which are treated as a separate component in our architecture (Fig. 3).
The fuzzy rule-base consists of the nine fuzzy rules and a fuzzy inference system is used for this rule-base (Fig. 3). So, our system is a hybrid architecture that consists of a crisp rule-base along with a fuzzy inference system (Fig. 3). Its execution process is in parallel mode, i.e. for a pair of a token (X Y), it is considered input for both, the fuzzy inference system as well as a crisp rule base. And it is considered a reduplicated pair if any one of the rule-base outputs as a reduplicated pair.
7.1 Fuzzification in our System
The fuzzification is the method of transforming a crisp value into a fuzzy value. Here it is described the exact implementation in our system.
This fuzzification is also defined in two ways. For the fuzzy Rule 1 – Rule 6, the linguistic variables are considered as low, medium, and high.
But for the fuzzy Rule 7 – Rule 9 and hence the fuzzification is done for Rule 1 – Rule 6, in one way and for Rule 7 – Rule 9 in different ways.
The fuzzification function for Rule 1 – Rule 6, is like the trapezoidal function is shown in Fig. 4.

The value along the x-axis is considered as the similarity measured in percentage. The 0-50% matching is considered as low, 40-80% matching is considered as medium and 50-100% matching is considered as high.
These values are set from the concept domain study of various literature. Now for a pair (X Y) if their matching percentage is x1, and the membership value corresponding to the high and medium is μ1(x1) and μ2(x1) then its resultant value is considered as max{μ1(x1), μ2(x1)} (shown in Fig. 8). A similar concept is used for Rule 7 – Rule 9 is shown in Fig. 5.

7.2 Aggregation and Defuzzification in our System
In the fuzzy rule base, all rules are executed parallelly. In order to make a final decision, the fuzzy sets that represent the outputs of all rules are needed to aggregate into a single output that is also a fuzzy set (Fig. 6). There are various methods are for aggregation, but we have considered the max-min method in our system [31].

7.3 Defuzzification
Now the final step is defuzzification. Here it needs to convert the output of aggregated fuzzy member-ship value (Fig. 6) to the crisp value. This is done by the max-membership method i.e. it considered maximum x value corresponding to that fuzzy membership value. The x-value represents the similarity measured (described in section 7.1) of two strings (X Y) in percentage. In our cases, a threshold value is defined and the crisp output exceeds that threshold value it is considered as reduplication and in our experiment, it is set as 75.
8 Experiment and Result
8.1 Test Data Set
The system is tested on the Technology Development for Indian Languages (TDIL) Bengali corpus [19]. The corpus is created under the Department of Electronics, Govt. of India for various Indian languages including Bengali. This corpus content is with texts from diverse areas like Fine Arts (5%), Literature (20%), Social Sciences (15%), Commerce (10%), Natural Sciences (15%), Mass media (30%), etc. The corpus content 3,34,260 sentences and 44,29,574 words.
8.2 Results
Though the system is mainly focused only on partial reduplication, it is capable capture the total reduplication too. Hence the result is described in three following ways shown in Table 2.
9 Error Analysis
The error analysis is not done in fuzzy implementation and fuzzy rule-bases. It is primarily tried to focus only to investigate source of false-positive errors. In cases of total reduplication, the output is 100% accurate with respect to the lexical level but there is an error in 40 cases in the semantic level.
For example, the system identified “2-2” as a total reduplication, which is lexically correct but semantically it is not correct. So all the 40 false-positive cases the source of errors are similar. Some of other instances are  / didi (elder sister),
/ didi (elder sister),  / sisi (glass bottle),
/ sisi (glass bottle),  / kaka (uncle), etc.
/ kaka (uncle), etc.
In the case of partial reduplication, there are 169 false-positive cases. There are some words (word pair) used in Bengali, their morphological structure looks like a reduplication but it is not and these are the sources of this error. For example, 
 / coca cola,
/ coca cola, 
 / mayer gayer, etc.
/ mayer gayer, etc.
10 Conclusion
The primary focus of this paper is a successful implementation of a FUZZY-NLP system for partial reduplication identification from the text corpus. Earlier researchers tried to address this issue by heuristic approaches on the basis of string matching. In this context, it is one of the pioneering attempts that concretize a fuzzy-based or fuzzy string matching system. This approach incorporated some morphological features like an ordered sequence of characters’/vowel modifiers, lengths, the position of mismatch, etc.
Some of these features are not considered earlier. The system is easily imported to identify the reduplications for other morphological-rich languages. Similar concepts can be used for other similar problems like morphological analysis, spell checker, etc.
The system can be fitted in any language just replacing the rule base module. This system also introduced three crisp rules, those rules address the exceptional reduplications in the Bengali languages. The yield of these rules is high precessions on the availability of rich language resources like a digital dictionary, WordNet, etc.

