











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Similarity searching consists in retrieving the most similar objects to a given query from a database. This task has become essential in different areas such as, pattern recognition, artificial intelligence, etc. Actually, it can be applied to any field with a set of objects and a similarity measure between any two objects of the set is defined.
Dissimilarity is a measure of how different two objects are and is preferably computed with a distance function. This measure is normally defined by an expert in the specific application domain and can be used as a black box. A distance function is frequently very expensive to compute, therefore our goal is to reduce the number of distance computations needed to solve each query.
Many important databases are huge and lack of structure. Perfect examples are the multimedia databases. These are challenging and should not be handled with traditional database manipulation systems but rather with metric-space indices. A metric space is defined by a collection of objects and a distance function, we describe it in Section 2.1. An important challenge is to keep the index in main memory, thus, as the size of the database increases more efficient techniques in terms of memory space are needed.
In general, the complete process is split in two parts: building an index, which is an offline process, and querying the index. The performance of a proximity index depends on the intrinsic dimensionality (IDim) of the data; in practice, when the IDim is too high the index performance might collapse [8, 19]. In this paper, we are proposing a novel improvement to one of the best algorithms in high dimension, with a very small index, that can be kept in main memory.
This paper is organized as follows. Section 2 gives details about the related work. Section 3 describes our proposal, some definitions about permutants, classes, etc.; its experimental evaluation is shown in Section 4. Section 5 provides some conclusions and future work. An early version of this work appeared in [13]. The main changes are We propose to use a recent metric between permutations, a new way for selecting the elements per class, and new distances from elements to classes..
2 Related Work
2.1 Basic Concepts
Let
Formally, a metric space is a pair
Basically, there are two kind of queries: Range queries and K-Nearest Neighbor queries. A Range query
2.2 Metric Space Indices
A complete survey of metric space searching can be seen in [8, 23, 21]. Metric spaces indices are classified in three categories: pivot-based indices, partition-based indices, and permutation-based indices.
A pivot-based index (PiBI) chooses a small set of elements called pivots, and every pivot computes and stores all the distances to the rest of the elements, these computed distances are stored as an index. There are several proposals about storing these distances in a data structure using PiBI ([2, 8, 15, 19] to mention a few).
At querying time, first query
The second family is a partition-based index (PaBI), which splits the space using some reference objects, called centers. Centers define partitions (by several criteria: closer ones, whithin a radio, etc), and the set of objects is partitioned. At query time, subsets that do not intersect with the query are discarded [17, 23, 7, 16, 9]. PaBIs work reasonable well in high dimension, but usually need
2.2.1 Permutation-Based Indices
In [5, 6, 1], the authors introduced the permutation-based index (PeBI) as follows: Let
Ties are broken using any consistent order. The hypothesis is Similar objects are expected to have similar permutations. To find relevant objects to a given query, permutations similar to the query permutation should be reviewed. The new problem is to find these similar permutations.
There are many similarity measures between permutations and in [6] the authors showed the performance of some. The simplest one (and with a competitive performance) was Spearman Footrule
where
For example,
Note that permutant
PeBIs have an excellent performance in high dimension and large permutations work better than short ones. Authors in [10, 20] did no use all but just a few permutants (the prefix of the closest ones to the object for each permutation). The prefixes are structured in an index in RAM. This way the authors achieved better compression, saving the space used by the index at the expense of loosing precision in the retrieval stage [11, 18]. There is another kind of PeBI using nSimplex projected vectors, however, not all databases can be processed with this technique [22].
An exact answer for a similarity query retrieves all the objects that satisfy it. As the IDim of the dataset increases the cost of computing the answer exponentially grows, phenomenon known as the curse of dimensionality. In some cases we can trade precision in the results for computing time. This is known as approximate retrieval, and is very useful in metric spaces of high IDim.
PiBIs work well for exact retrieval in low IDim, while PaBIs perform reasonable well for exact and approximated retrieval in high IDim. Finally, PeBIs work very well in high IDim for approximated retrieval.
On the other hand, in [14] the authors introduced another metric to measure similarity between permutations. The authors considered penalizing harder when in two permutations one specific permutant appears in different positions. This metric takes advantage of the fact that at solving queries near positions of a specific permutant in two permutations gives you more valuable information than the oposite. The metric proposed in [14] was defined as follows:
and the new metric is:
where
3 Our Proposal
The main problem of PeBIs, causing loss of accuracy in retrieval stage, is depicted in Fig. 1.
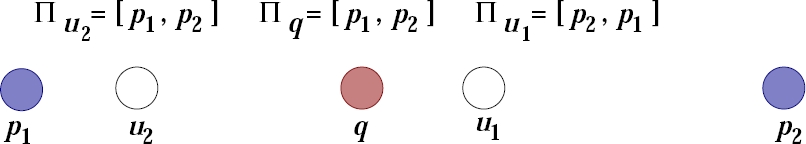
Fig. 1 The Main problem of the PeBI. In the example shown here
Notice that query
In this paper, we extend [13], which is a novel way to reduce the permutation size as compared to that needed for standard PeBI, without reducing the retrieval precision. Our proposal consists in having permutations of classes of permutants
Formally, let
We compute
In the next sections, we discuss criteria for selecting elements for each class and computing
3.1 Criteria to Select Groups of Permutants
In order to explore this technique, we use several criteria to form classes of permutants:
Rand This criterion consists of choosing each class randomly.
C1e selects the first element of each class randomly and adds its
F1e selects the first element of each class randomly and adds its
C2e selects, for each class, a pair of mutual nearest neighbors and the
SSS selects
Let



3.2 Distance to a Class
Since we have
In order to illustrate our ideas, in Fig. 2 all classes were selected in random way. For object

Fig. 2 Classes 1, 2 and 3 in blue, green and red respectively. We show the permutations by classes according to the four options of distances. That is, using
Our proposal is to use a new metric for evaluating how similar classes of permutations are instead of using Spearman’s metric.
4 Experimental Results
We ran the experiments in synthetic and real world datasets. Synthetic ones allow us to assess the strength of our technique while varying some parameters, such as dimensionality, dataset size, number of permutants and classes, distance to classes and the way to conform the classes.
On the other hand, real world datasets show the performance of our technique in practical situations.
The performance of our proposed technique is measured in terms of distance computations.
4.1 Synthetic Databases
Our proposal was tested using a synthetic database composed by vectors uniformly dis-tributed in the unitary cube. Our dataset consists of 100,000 points in
In Figure 3 the performance of our technique as the dimension increases is showed. As we expected, the number of distances rises as the dimension increases. Notice that the PeBI idea has a good performance when we use just 16 permutants, however, for

Fig. 3 Computed distances for solving
It is important to notice that we have two phases of distance computations: when a query
The internal distances are unavoidable, and external distances allow us to answer the queries quickly. All images reported are the total distances (internal + external distances).
4.2 Real Databases
In this section we show the performance of our similarity searching method in real-world metric spaces using the benchmark set for similarity searching community [12].
In this case, we have a non-uniform database, we can use the technique proposed in this paper:
4.2.1 NASA Images
This dataset consists of 40,150 feature vectors in
We used the Euclidean distance to compare the feature vectors of this collection of images. We chose 500 histograms randomly as test set, for querying, and the rest as our database to be indexed.
In Figure 4, we are using two different size of classes

4.2.2 Colors
This database consists of 112,682 color histograms, represented as 112-dimensional feature vectors. This dataset was obtained from the SISAP project’s metric space benchmark set [12]. We chose 500 histograms randomly as test set, for querying, and the rest as our database to be indexed.
In Figure 5 we show that our proposals have excellent results.

Fig. 5 Total distances computed for finding nearest neighbors as the number of nearest neighbors increase for the COLORS database. The number of permutans is
Notice that PeBIs technique (red line, using
However, our new proposal is better, in particular notice that using
Finally, using
4.2.3 CoPhIR
This database consists of 10 million objects selected from the CoPhIR project [3]. Each object is a 208-dimensional vector and we use the
Each vector was created in a linear combination of five different MPEG7 vectors as described in [3]. We chose the first 500 vectors from the database as queries. Each query consisted of searching for twenty nearest neighbors.
In Figure 6 we show two images, the top plot considers all computed distances (internal + external, where internal is

5 Conclusion and Future Work
In this paper, we presented an extended version of [13]. The original idea of to use classes of permutants instead of single ones in the permutation based algorithm [6]. In this paper, we introduced a new distance between classes and experimented with different ways of selecting elements inside classes.
Our experimental results showed that we can improve the permutation based algorithm up to 90% in real databases.
As a future work, we would like to test how this technique works using different size of classes. Also, another interesting idea is to mix different criteria to choose a class, in this paper, all classes are selected using exactly the same criterion.

