











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
At present, the number of digital documents has exponentially grown due to the constant use of the computer, resulting in the need for information, which has become a primary activity for any aspect of life. However, not all the information is important, so it is necessary to identify it. This activity is difficult for a user to perform, since in each search for information an endless number of documents appear that must be reviewed, hence the importance of having a summarized form of the document.
One way to solve this problem is through keyphrases, words, or terms [4, 6, 19, 31], which provide a brief way to describe the main content of the document and thus help the user to decide if that information is adequate for him [2, 3, 15, 24]. In this paper, we will refer to them as keyphrases.
Most of the contents of the web do not have phrases that represent the web. However, it is common to see them in scientific articles and news pages, where authors are requested to provide a list of phrases for representation [36]. The low use of these is because it is a time-consuming activity; in some cases, it is necessary to have experts with knowledge in a specific domain. Therefore, efforts have been made to find keyphrases that represent the main content of a document [6, 29, 36]. This activity is called keyphrase extraction, which is a process related to human cognition, so that the field of computational sciences has seen the need to carry out investigations that can model this process, through techniques thus creating the task of automatic extraction of keyphrases. This task generates phrases from a source document, instead of using thesauri as a resource (keyphrase assignment) [22, 29, 32].
Usually, the task is divided into two phases: identification of phrases that can serve as candidates and selection, where the importance of the phrase is determined by scoring [22, 40].
The extracted phrases are not only used to represent the content of a document [10]. Furthermore, they are useful for other tasks such as indexing [21], grouping [4], classification [20], abstract generation [33], and opinion mining [7].
One of the characteristics that years ago was considered relevant for the keyphrase extraction task was frequency [29]. However, this criterion is not the main one, since, in a text, there can be very repetitive phrases, but it does not mean that they are keys [37].
In [11], a method based on the generation of lexical patterns is described, making use of frequent maximal sequences [14] that allow obtaining keyphrases from a text, regardless of their frequency, resulting in a list of candidate phrases, which will later be selected through a ranking, considering the ones with the highest weight as the best.
2 Related Works
Most of the papers that study the extraction of keyphrases use data sets, mostly in English [3, 4, 22, 40], also in French [3, 9], Croatian [2] and Chinese [41]. There are corpus for different domains such as scientific [16, 18, 22, 40], emails [17], social networks [1, 40], among others.
However, they are used to test and evaluate supervised and unsupervised automatic keyphrase extraction methods. One of the most important supervised works within the keyphrase extraction study is that carried out by Turney [35], who implements a machine learning system consisting of two sections; a genetic algorithm called Genex and the extractor, which consists of twelve parameters, which are adjusted by the genetic algorithm, to later generate a list of keyphrases.
In addition, other methods use external resources that are dependent on the language, such as the system called SEERLAB [34] that integrates three components for the identification of candidate phrases; parser, extractor, and candidate classifier, where it trains a Random Forestar classifier for keyphrase selection.
Phrases can be identified using sequential patterns, which calculate the semantic relationship between the words in a document [39].
On the other hand, there are unsupervised methods; one of the most basic is TF [28], which is used as a baseline to determine the acceptable value that a system can have the task [16].
It is considered a characteristic in some works, where the task is considered as classification problem [5, 17, 30].
Although there are unsupervised methods such as TF, there are also more robust ones, such as SemCluster [4]. First, n-grams and named entities are obtained to use knowledge bases and identify semantic relationships with other terms. Additionally, it uses a grouping model to systematically identify and filter unimportant groups of phrases, allowing only those representing the document to be scored as candidate keyphrases.
In [25], two techniques are used to extract keyphrases: maximal frequent sequences and PageRank. These are used to obtain a limited number of text fragments called n-grams (uni-grams, bi-grams, and tri-grams). Subsequently, a weight is assigned to the sequences using PageRank, and the ones with the highest value are chosen as candidates.
Maximal Frequent Sequences (MFS) are essential in pattern mining, and these are not a subsequence of any other frequent sequence but rather a compact representation of the entire set of frequent sequences [14]. They have been applied to different works as in [11], where a method for detecting text fragments as a candidate for hyperlinking is presented. First, a set of lexical patterns is obtained, called that way because they work at the lexical level without considering syntactic or semantic aspects. The text should be normalized from examples of human-generated candidate fragments (seeds). These are tagged as <Link>. They must also contain right and left context, limited to 20 words that help to delimit the beginning and the end of a text fragment that contains a hyperlink.
The text then serves as input to the MFS algorithm that derives the lexical patterns. Sequences are essential since the sequential order of the word is essential to obtain a good pattern. These patterns become search patterns that are applied to a set of plain text to obtain those candidates.
The patterns have been useful in this task, and in [13], he applies this same technique and process to answer definition questions.
However, in [26], he also uses this technique for the information extraction task. These three works have been tested with the Spanish language.
In this paper, we propose an unsupervised method for automatic keyphrase extraction, which consists of two essential sections; the first is the discovery of lexical patterns, and the second is the selection of keyphrases through a series of weighing derived from the evaluation of each pattern.
Our method is compared to the following novel unsupervised approaches: Yake [12], Topic Rank [9], Single Rank [38], and Text Rank [23], which are implemented using the PKE library [8].
Yake is a method based on the extraction of statistical characteristics from the text, such as term co-occurrence; an important aspect is that not based on the frequency of terms, which means that conditions are not established for the minimum of frequency that a keyword must have to be a candidate, as is the case with our proposed method [12].
TopicRank [9] is a graph-based method based on the grouping of sentences as topics, calculating weights as a function of the distances between positions. This method relies on identifying noun phrases, while in our method this is not a determiner. SingleRank [38] is graph-based, which builds a local graph for each unique document. Also, it calculates based on the co-occurrence relationship between two words that express cohesion relationships.
For our method, the co-occurrence in the MFS and the generation of lexical patterns, is important. Finally, TextRank [23] is a graph-based model, where the units to be classified are sequences of one or more lexical units extracted from the text, and these represent the vertices added to the graph. In this way, we can say that both this method and the proposed one take words as lexical units. The rest of the document is organized as follows: Section 3 describes the proposed method for obtaining the keyphrases. Section 4 is dedicated to experimentation and the description of obtained results. Finally, in section 5, we give the conclusion of the work.
3 Proposed Method
In general, the proposed method is based on six important phases for the Automatic Keyphrase Extraction task, where MFSs are used for the lexical pattern discovery process, which will assist in generating a candidate keyphrase list.
3.1 Pre-Processing
The first phase of this method is cleaning, restructuring, and coding of the data. This step is carried out because the MFS module does not accept special characters. Therefore, all symbols other than punctuation marks and numbers are eliminated since they do not provide relevant information.
Afterward, the accepted symbols are normalized, transforming them into labels using regular expressions, which allow their identification; URLs, emails, and dates were labeled. Finally, the sentences' lemmatization is applied using Porter's stemming algorithm [27] for each data set document.
Table 1 shows some examples of the normalization of special characters.
3.2 Data Construction and Preparation
In this phase, from a set of data
Whereas for
Furthermore, for each
This set will be required for the lexical pattern discovery phase
Table 2 shows some examples of the normalization of
3.3 Lexical Pattern Discovery
In this phase, the extraction of MFS [14] is applied in
From this phase, a series of patterns is obtained, whose discovery depends on a threshold
For example, if the amount of
3.4 Identification of Candidate Keyphrases
The
It is important to note that
Table 3 Examples of lexical patterns according to their length
| Lexical Patterns | |
| 𝑂𝑓 < 𝐾𝑃 >. | |
| 𝑂𝑓 < 𝐾𝑃 >< 𝐾𝑃 >, | |
| 𝑇ℎ𝑒 < 𝐾𝑃 >< 𝐾𝑃 >< 𝐾𝑃 >. | |
| 𝐴 < 𝐾𝑃 >< 𝐾𝑃 >< 𝐾𝑃 >< 𝐾𝑃 >, |
3.5 Lexical Pattern Evaluation
To evaluate the performance of
3.6 Selection and Evaluation of Keyphrases
The selection is made from
In addition to the previous weights, a Boolean weight was added, where the value of 1, always corresponds to
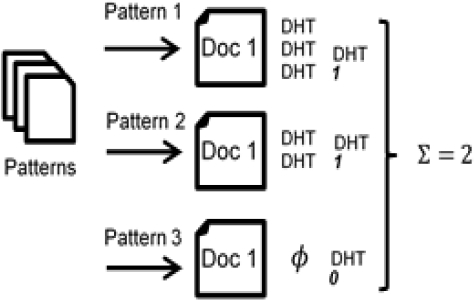
where:
After assigning the weights, if the
Figure 2 shows the process for assigning precision weighing of

As mentioned in the boolean weighting, if
In such a way that to identify the keyphrases, it does not depend on the frequency that
From this phase, we obtain
Table 5 Combinations of n-grams
| Combination (C) | n-gramas |
| Combination 1 (C1) | |
| Combination 2 (C2) | |
| Combination 3 (C3) | |
| Combination 4 (C4) | |
| Combination 5 (C5) | |
| Combination 6 (C6) | |
| Combination 7 (C7) |
Finally,
4 Experimentation
4.1 Data
This article uses the SemEval-2010 dataset for task # 5. It has 284 scientific articles, of which 100 are for tests, 144 for training, and 40 for validation. It also contains a set of gold standard keyphrases, assigned by author, reader, and combined (assigned by author and reader) for each article. The reader phrases were generated by 50 student annotators from the University of Singapore, where the main objective was to obtain keyphrases from any section of the document. However, the indication was not fully considered, thus having 15% of keyphrases assigned by the reader and 19% assigned by author that do not appear in the document; due to this, the maximum memory that the participating systems could have reached it was 81% and 85% [16].
4.2 Results
Our method was tested with eight thresholds, of which
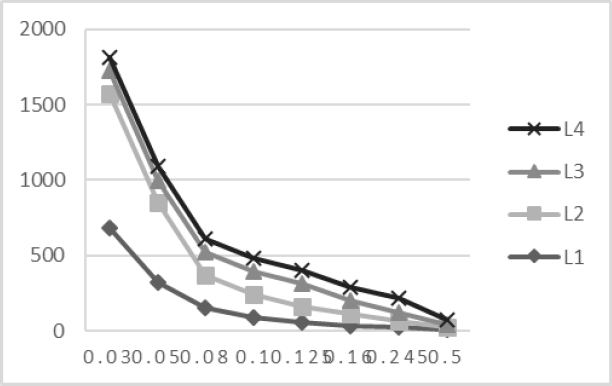
As can be seen in the figure, the lower the threshold, the greater the number of patterns that can be obtained. However, these patterns are already beginning to depend on the context and domain of the documents, which is why it was considered that the best threshold is not the one with the greatest number of patterns, but the one with the greatest number. The best was
Table 6 Performance of the proposed method for different thresholds, combinations, and weights
| Proposed Method | Top 15 | ||||||||
| Threshold | Author | Reader | Combined | ||||||
| P | R | F-M | P | R | F-M | P | R | F-M | |
|
|
6.00% | 23.26% | 9.54% | 14.67% | 18.27% | 16.27% | 17.27% | 17.67% | 17.47% |
|
|
6.07% | 23.51% | 9.65% | 14.00% | 17.44% | 15.53% | 16.73% | 17.12% | 16.92% |
|
|
6.07% | 23.51% | 9.65% | 13.80% | 17.19% | 15.31% | 16.60% | 16.98% | 16.79% |
|
|
6.00% | 23.26% | 9.54% | 13.67% | 17.03% | 15.17% | 16.47% | 16.85% | 16.66% |
|
|
5.80% | 22.48% | 9.22% | 13.33% | 16.61% | 14.79% | 16.00% | 16.37% | 16.18% |
|
|
5.47% | 21.19% | 8.70% | 12.07% | 15.03% | 13.39% | 14.60% | 14.94% | 14.77% |
|
|
5.67% | 21.96% | 9.01% | 11.80% | 14.70% | 13.09% | 14.53% | 14.87% | 14.70% |
|
|
4.67% | 18.09% | 7.42% | 11.20% | 13.95% | 12.42% | 13.27% | 13.57% | 13.42% |
The results show that the best keyphrases are obtained from weighing
This is because the patterns are sequences of characters with a percentage of the frequency with respect to β, as shown in section 3.3. That is why in some
Table 7 Patterns that appear in different β for the identification of keyphrases of l^1
| Patron | ||||||||
| 0.1 | 0.08 | 0.03 | 0.254 | 0.05 | 0.08 | 0.16 | 0.125 | |
| Of < KP > . | X | X | X | X | X | |||
| The < KP > is | X | X | X | X | X | |||
| Of < KP > , | X | X | X | X | ||||
| The < KP > of the | X | X | X | X | X | |||
| Of < KP > and | X | X | X | X | X | X | ||
| ( < KP > ) | X | X | X | X | X | X | X | |
| And < KP > . | X | X | X | X | X | |||
| The < KP > of a | X | X | X | X | X | X | X | |
| Of < KP > is | X | X | X | X | X | X | X | X |
| The < KP > to | X | X | X | X | X | X | ||
Table 8 shows the results obtained from our method for the top 5 of the sets, author, reader, and combined, and we compare them with four unsupervised methods.
Table 8 Performance of the proposed method, considering the 5 best keyphrases of the author, reader, and combined sets
| Proposed method | Top 5 | ||||||||
| Threshold | Author | Reader | Combined | ||||||
| P | R | F-M | P | R | F-M | P | R | F-M | |
|
|
8.00% | 10.34% | 9.02% | 16.00% | 6.64% | 9.39% | 19.60% | 6.68% | 9.96% |
| Yake [12] | 9.40% | 12.14% | 10.60% | 14.40% | 5.98% | 8.45% | 19.00% | 6.48% | 9.66% |
| Topic Rank [9] | 8.00% | 10.34% | 9.02% | 5.60% | 6.48% | 9.16% | 18.40% | 6.28% | 9.36% |
| Single Rank [38] | 0.80% | 1.03% | 0.90% | 2.00% | 0.83% | 1.17% | 2.60% | 0.89% | 1.33% |
| Text Rank [23] | 0.20% | 0.26% | 0.23% | 0.80% | 0.33% | 0.47% | 0.80% | 0.27% | 0.40% |
It can be seen that the proposed method has an F-M value of 9.96% for the top 5 in the set of combined phrases, which places us in the first position of this ranking.
The methods with which we compare were implemented from the PKE toolkit [8], which is developed in Python for the automatic extraction of keyphrases, each of the methods consists of different parameters. For Yake, stoplist = 'english', selection n = 3, window = 2, threshold = 0.8 and extraction n = 15 were used. Topic Rank; pos = {'NOUN', 'PROPN', 'ADJ'}, stoplist = 'english', method = 'average', threshold = 0.7 and extraction n = 15. Single Rank; pos = {'NOUN', 'PROPN', 'ADJ'}, window = 10, normalization = "stemming" and extraction n = 15. Lastly, TextRank; pos = {'NOUN', 'PROPN', 'ADJ'}, window = 2, normalization = "stemming", top_percent = 0.33 and extraction n = 15.
Tables 9 and 10 show the top 10 and 15, where our method continues to retain the first position.
Table 9 Performance of the proposed method, considering the 10 best keyphrases of the author, reader, and combined sets
| Proposed method | Top 10 | ||||||||
| Threshold | Author | Reader | Combined | ||||||
| P | R | F-M | P | R | F-M | P | R | F-M | |
|
|
8.00% | 20.67% | 11.54% | 17.60% | 14.62% | 15.97% | 20.90% | 14.26% | 16.95% |
| Yake [12] | 7.40% | 19.12% | 10.67% | 13.50% | 11.21% | 12.25% | 17.00% | 11.60% | 13.79% |
| Topic Rank [9] | 5.90% | 15.25% | 8.51% | 12.50% | 10.38% | 11.34% | 14.70% | 10.03% | 11.92% |
| Single Rank [38] | 0.80% | 2.07% | 1.15% | 2.80% | 2.33% | 2.54% | 0.20% | 2.18% | 2.59% |
| Text Rank [23] | 0.70% | 1.81% | 1.01% | 1.70% | 1.41% | 1.54% | 2.00% | 1.36% | 1.62% |
Table 10 Performance of the proposed method, considering the 15 best keyphrases of the author, reader, and combined sets
| Proposed method | Top 15 | ||||||||
| Threshold | Author | Reader | Combined | ||||||
| P | R | F-M | P | R | F-M | P | R | F-M | |
|
|
6.00% | 23.26% | 9.54% | 14.67% | 18.27% | 16.27% | 17.27% | 17.67% | 17.47% |
| Yake [12] | 6.40% | 24.81% | 10.18% | 11.47% | 14.29% | 12.73% | 14.67% | 15.01% | 14.84% |
| Topic Rank [9] | 5.20% | 20.16% | 8.27% | 10.53% | 13.12% | 11.68% | 12.80% | 13.10% | 12.95% |
| Single Rank [38] | 1.07% | 4.13% | 1.70% | 2.87% | 3.57% | 3.18% | 3.47% | 3.55% | 3.51% |
| Text Rank [23] | 0.73% | 2.84% | 1.16% | 1.80% | 2.24% | 2.00% | 2.20% | 2.25% | 2.22% |
5 Conclusions
This paper presents a method for extracting keyphrases using lexical patterns. The results prove that this proposed method and the weights used to identify keyphrases are useful for the task. We can also see that the best weighting was boolean, which considers a positive or negative value when the phrase is or is not detected by a certain search pattern.
However, the importance of the threshold with which the patterns are extracted must be considered, since the lower
In addition, in the same way, it can be considered that the keyphrases identified by our proposed method do not depend on the frequency of the word, but on the search pattern that identifies it, therefore we can conclude that a keyphrase should not only be a frequent word in the text, but it can also appear only once and be considered highly relevant.
Finally, through our method, we discover that a pattern can appear in more than one threshold, which we consider important since we can mention that the pattern's lexical structure is constant, and it is more likely that a keyword can be contained in these contexts lexicons.
As a future work, we test lexical functions [42] and content-based characteristics [43].

