











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Sentiment analysis has received special attention in the fields of advertising, marketing and production. Indeed, the emergence of several social media platforms, such as Facebook, Instagram, LinkedIn and Twitter has encouraged individuals to express their opinions and feelings towards various subjects, products, ideas, people, etc. Therefore, automatic sentiment analysis has become one of the most dynamic research areas in the NLP field.
In this respect, our work is part of the automatic analysis of Internet users’ comments that are posted on the official pages of supermarkets in Tunisia on Facebook social networks. To do this, We have gathered comments from the official Facebook pages of Tunisian supermarkets.
To conclude, the main objective of this research is to propose an automatic sentiment analysis of Internet users’ comments that are posted on the official pages of Tunisian supermarkets and on Facebook social networks. We began by studying the issues related to the term ‘opinion’ and the existing solutions. At the end of this study, we proposed a method for the analysis of feelings.
The primary contributions of this paper are as follows:
— We gather comments from the official Facebook pages of Tunisian supermarkets, namely Aziza, Carrefour, Magasin Genéral, Géant and Monoprix. This corpus is made up of comments written in the Tunisian Dialect by taking into account two main scripts; Latin script and Arabic script.
— We annotate our corpus for sentiment analysis based on five sentiment classes (very positive/positive/neutral/negative/very negative) and twenty aspect categories.
— We present our proposed method with the different steps of the automatic sentiment analysis.
— We eventually disclose our elaborate experiments and the obtained outcomes.
The remaining of this paper is structured as follows. Section 2 surveys the literature on sentiment analysis. In Section 3, we deal with the Tunisian Dialect dataset that were collected and used in our experiments. Section 4 is dedicated to a detailed presentation of our proposed method for opinion analysis in the Tunisian dialect. In this context, we propose two different approaches: The first allows to classify the collected comments into five sentiment classes at the sentence level, while the second aims to introduce the aspect-based sentiment analysis of the Tunisian dialect by implementing two models, namely the aspect category model and the sentiment model. Section 5 provides a discussion that demonstrates the efficiency and accuracy of both RNN and CNN-based features. We finally draw some conclusions and future work directions in Section 6.
2 The Main Approaches of Sentiment Analysis
Sentiment analysis is one of the most vigorous research areas in NLP research field that focuses on analyzing people’s opinions, sentiments, attitudes, and emotions towards several entities such as products, services, organizations, issues, events, and topics [34]. A large number of research works on sentiment analysis have been recently published in different languages. Hence, to achieve this, we first laid the foundation for research on the sentiment analysis by reviewing relevant literature on past studies conducted in this field. According to this study, sentiment analysis works fall into three major approaches, namely a machine learning based approach, a knowledge based approach and a hybrid approach.
The next subsection highlights the related works of Arabic and Arabic dialects sentiment analysis.
2.1 Machine Learning Based Approach
Machine learning helps data analysts build a model with a large amount of pre-labeled words or sentences in order to tackle the classification problem. [54] examined opinion analysis of the Tunisian dialect. Their corpus was made up of 17k comments.
Three main classifiers were adopted for the classification task, namely Support vector machines, Bernoulli naïve Bayes and Multilayer perceptron. Their obtained error rates were 0.23, 0.22, and 0.42 for support vector machine, multilayer perceptron and Bernoulli naïve Bayes, respectively.
Deep learning is a crucial part of machine learning that refers to the deep neural network suggested by G.E. Hinton [56]. It includes five main networks or architectures: CNN (convolutional neural networks), RNN (recursive neural networks), RNN (recurrent neural networks), DBN (deep belief networks), and DNN (neural networks deep).
2.2 Knowledge-Based Approach
The knowledge-based approach also known as lexicon-based approach consists in building lexicons of classified words. In this respect, [55] relied on a lexicon-based approach to be able to construct and assess a very large sentiment lexicon including about 120k Arabic terms.
They put forward an approach that enables them to utilize an available English sentiment lexicon. To evaluate their lexicon, the authors made use of a pretreated and labeled dataset of 300 tweets and reached an accuracy rate of 87%.
In their attempt to construct a new Arabic lexicon, [59] proposed a subjectivity and sentiment analysis system for Egyptian tweets. They built an Arabic lexicon by merging two modern standard Arabic lexicons (called MPQA and ArabSenti) with two Egyptian Arabic lexicons. The new lexicon is composed of 300 positive tweets, 300 negative tweets and 300 neutral tweets, for a total of 900 tweets achieving an accuracy of 87%.
2.3 Hybrid Approach
The Hybrid approach is a combination of the two approaches already mentioned above. [60] developed a semantic model called ATSA (Arabic Twitter Sentiment Analysis) based on supervised machine learning approaches, namely Naïve Bayes, support vector machine and semantic analysis. They also created a lexicon by relying on available resources, such as Arabic WordNet. The model’s performance has been improved compared to the basic bag-of-words representation with 4.48% for the support vector machine classifier and 5.78% for the classifier NB. In another study conducted by [61], a hybrid approach combining supervised learning and rules-based methods was applied for sentiment intensity prediction. In addition, the authors utilized not only well-defined linear regression models to generate scores for the tweets, but also a set of rules from the pre-existing sentiment lexicons to adjust the resulting scores using Kendall’s score of about 53%.
3 Tunisian Dialect Corpus Description
The existence of a corpus is mandatory for a precise analysis of sentiments, because it is used to train and evaluate the models developed. In our case, we need a corpus in Tunisian dialect for the opinions analysis in the field of supermarkets. Due to the lack of available public datasets of this field, in this research project, we built our dataset.
During the data collection phase, two types of corpus are utilized. The comments in the first type are written based on a Latin script (also called Arabizi). The comments in the second type of corpus, however, are written by using an Arabic script. As mentioned above, this is due to the habit and ease of writing in Latin, especially that Tunisians often introduce French words into their writings and conversations. Based on these characteristics, we decided to divide the corpus into two different parts, namely Arabizi corpus and Arabic corpus. This section deals with a breakdown of the datasets used in our work and gives an overview of the corpus statistics.
3.1 Arabizi Corpus
Arabizi in general refers to Arabic written using the Roman script [8]. In particular, Tunisian Arabizi appeared especially in social media, such as Facebook, Instagram, SMS and chat applications. Arabizi corpus comprises numbers instead of some letters.
For example, the sentence 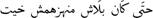 [even if they are free, I will not take them]] can be converted to Arabizi to become: ”7ata blech manhezhomch 5iit”, here the author used the numbers ”7” and ”5” which successively replaced the Arabic letters
[even if they are free, I will not take them]] can be converted to Arabizi to become: ”7ata blech manhezhomch 5iit”, here the author used the numbers ”7” and ”5” which successively replaced the Arabic letters  and
and  .
.
Moreover, our Arabizi corpus is characterized by the phenomenon of code switching which is defined in [36] as “the mixing, by bilinguals (or multilinguals), of two or more languages in speech, often without changing the speaker or subject”. This phenomenon is the passage from one language to another in the same conversation. For example, ”solde waktech youfa” / [When will the promotion expire?]]. This phenomenon appeared in our Arabizi corpus which includes foreign words of French origin, such as ”promotion” [promotion]], ”bonjour” [hello]], ”caissiere” [cashier]], etc.
One of the major characteristics of Arabizi corpus is the presence of abbreviated of foreign words. Using abbreviated foreign words is one of the major characteristics of our Arabizi corpus. Taking the example of the word ”qqles” instead of ”quelques” [a few]]. Apart from abbreviations, some spelling mistakes can be detected from the internet users’ performances of some foreign words. These mistakes are due to the users’ low French language proficiency. Take the example of the word ”winou el cataloug” instead of ”winou el catalogue” [where is the catalog?]]. Here, we notice that Facebook users get used to writing words as they listen to them.
3.2 Arabic Corpus
Our Arabic script corpus is made up of words and expressions extracted from the Tunisian Dialect, like  [stop lying]]. We noticed a case in which a specific comment contains foreign words which are written using Arabic alphabets. For example, the french word ”climatisseur” becomes
[stop lying]]. We noticed a case in which a specific comment contains foreign words which are written using Arabic alphabets. For example, the french word ”climatisseur” becomes  /klymAtyzwr/. Table 1 reports the most salient characteristics of our Tunisian Dialect corpus in terms of the number of sentences and words.
/klymAtyzwr/. Table 1 reports the most salient characteristics of our Tunisian Dialect corpus in terms of the number of sentences and words.
4 Method Overview
Recall that in our work, we are interested in the sentiment analysis of Facebook comments published in the Tunisian Dialect in the field of Tunisian supermarket services. Our sentiment analysis was performed at two levels, sentence level and aspect level. The purpose of sentence based sentiment analysis is to determine the general opinion. For aspect level, the primary goal is to present and discover sentiments on entities and their distinct aspects. Thereafter, we will describe the main tasks of each step of our method.
4.1 Steps of the Proposed Method
As we have conducted two methods for the analysis of opinions, namely, the analysis of opinions at the aspect level and the analysis of opinions at the sentence level, we will follow six steps in our proposed method. We begin by presenting common steps for both levels of analysis. First of all, we collect comments from Facebook. Then we divide our corpus constructed into two parts: Latin corpus, which contains Latin writing and Arabic corpus, which contains Arabic writing. In the following, the corpus used will be stored in a HDFS (Hadoop Distributed File System), which aims to store large volumes of data on the disks of many computers.
4.1.1 Sentiment Analysis at Sentence Level
At this level of analysis, we will exploit the two corpus, corpus Arabic and Arabizi. Thereafter, we will apply pre-treatment steps of these corpus in order to eliminate the noises that include, initial pre-treatment steps for each corpus, followed by a tokenization step. We will also go through a step of normalization and a step of racinisation for the Arabic corpus. Then we make the manual annotation of two corpus in five classes, very negative, negative, neutral, positive and very positive. Then we move on to a main stage which is the construction of the text representation model, which takes tokens as input, where each token presents a word.
In order to perform the classification task, we will choose the three deep learning algorithms, CNN, LSTM and Bi-LSTM. For example, following this level of analysis, the classification of the comment “hh 7asilou allah la traba7kom or latfar7kom”  highlights the “very negative” result that results in disappointment. Figure 1 shows the method we propose for sentiment analysis at the sentence level.
highlights the “very negative” result that results in disappointment. Figure 1 shows the method we propose for sentiment analysis at the sentence level.
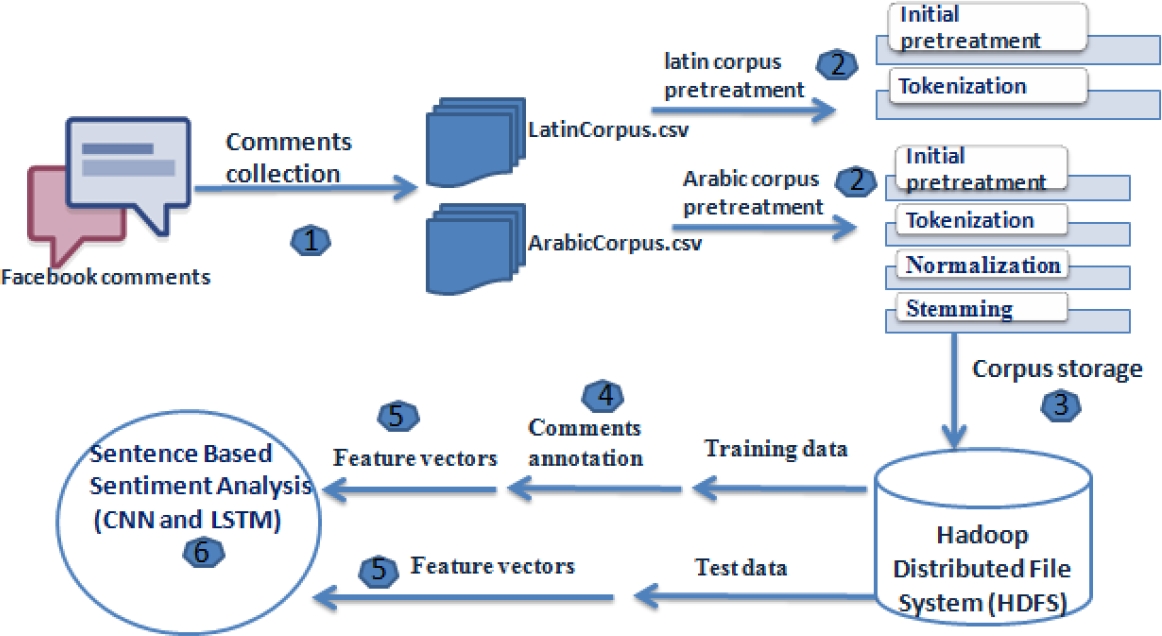
4.2 Collection of Dataset
We selected the social network “Facebook” by concentrating on the supermarket field in Tunisia in order to gather suitable comments. We have identified five official pages of supermarkets (Carrefour, Magasin general, Monoprix, Aziza and Geant). This corpus construction is based on two important tools: ”Facepager”fn and ”Export Comments”fn.
4.3 Processing of the Dataset
Once the corpus is collected, the available resources must go through a preprocessing stage in order to create a usable corpus.
4.3.1 Repeated Comments
A comment sometimes appears several times in the corpus. Repeated comments don’t add anything to the sentiment analysis. Therefore, we have kept only one occurrence of each comment.
4.3.2 Normalization
The Tunisian Dialect is characterized by the use of informal writing that does not respect precise orthographic rules. This fact makes their automatic processing difficult. Indeed, some words in the corpus have more than one form. Thus, a special pre-processing step was implemented in order to alleviate these problems and to obtain consistent data. This step consists in normalizing Arabic words by converting the multiple forms of a given word into a single orthographic representation. In our work, we used the CODA-TUN (Conventional Orthography for Tunisian Arabic) tool [51].
4.3.3 Light Stemming
Words written in the Tunisian Dialect are often made up of more than one word; hence the importance of the root word task. Light rooting aims at removing all prefixes and suffixes from the word and keeping its root. For example, the word 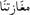 mgAztnA / [our supermarket]] is changed to
mgAztnA / [our supermarket]] is changed to 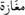 [supermarket]] by removing the suffix
[supermarket]] by removing the suffix  .
.
4.4 Corpus Annotation
Since the primary goal of supervised learning is to determine the polarity of opinions in advance, we move forward to another crucial step, known as the annotation of the corpus after pretreating the two corpora. Manual annotation is therefore necessary to build a learning corpus for sentiment analysis. Indeed, our corpus was annotated by native Tunisian Dialect speakers who were asked to classify the comments according to already well-defined categories and sentiment classes.
4.4.1 Annotation for Sentiment Analysis at the Aspect Level
the annotation of the aspect-based sentiment analysis depends only on the Arabic script corpus, in which we first labeled our collected comments with five distinct classes. The first class is ”very positive”. It’s used when the comment contains words that express total satisfaction with a service or a product. For example, 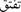 [very nice]]. The second class ”positive” is used if the comment expresses a positive feeling, such as satisfaction, enthusiasm, etc. For example,
[very nice]]. The second class ”positive” is used if the comment expresses a positive feeling, such as satisfaction, enthusiasm, etc. For example,  [delicious]].
[delicious]].
The third class ”neutral” is performed if the comment is informative or expressing no sentiment. For example, the comment  [do you work during Eid]] is informative with no word of sentiment. Negative means if the comment expresses a negative feeling, such as dissatisfaction, regret or any other negative feelings. For example,
[do you work during Eid]] is informative with no word of sentiment. Negative means if the comment expresses a negative feeling, such as dissatisfaction, regret or any other negative feelings. For example,  [they are not beautiful]], etc. Finally, very negative means when the comment expresses a very negative feeling, such as annoyance, disappointment or any other very negative feelings. For example, the word
[they are not beautiful]], etc. Finally, very negative means when the comment expresses a very negative feeling, such as annoyance, disappointment or any other very negative feelings. For example, the word 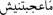 [very bad]].
[very bad]].
Then, we annotated our Arabic corpus with 20 already well-defined categories. Each category comprises two major parts that form the tuple ”E#A”, namely the aspect entity (E) and the attribute of aspect entity (A). The list of aspect entities is composed of 9 aspects, namely, “drinks”, “aliments”, “services”,” locations”, “cleaners”, “electronics”, “utensils” and “others”. However, the list of attributes of aspect entities is, namely, “general”, “quality and “price”. These attribute are defined for each entity, except for the two entities; “locations” and “services”. Thus, we fixed a single entity attribute “general” for these last two entities. Table 2 reports aspect categories with examples of topics discussed in each category.
Table 2 Aspect categories with the topics discussed in each category
| Aspects | Topics discussed |
| Drinks | Coffee / tea, juice, soda, water. |
| Aliments | Bakery, canned products, dairy products, dry food, frozen food, vegetables, individual meals, ice cream, meat, etc. |
| Cleaners | Laundry detergent, dishwashing liquid detergent, etc. |
| Electronics | Laptops, telephones, televisions, etc. |
| Services | Complaints and suggestions from the customer. |
| Locations | Concerning one of the supermarkets location |
| Utensils | Kitchen utensils |
| Others | Baby items, pet items, batteries, greeting cards, games, gifts, vouchers, catalogs, recipes, etc. |
Aspect entity attributes corresponding to entity labels are shown as follows:
— Price: this attribute includes promotions and payment facilities. For example, the words
 [how much?]],
[how much?]],  [Please reduce the price]],
[Please reduce the price]], 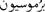 [promotion]], etc.
[promotion]], etc.— Quality: This refers to an advice via a product or a service. For example:
 [it’s disgusting]],
[it’s disgusting]],  [that’s wonderful]], etc.
[that’s wonderful]], etc.— General: The user does not express his opinion clearly. It is difficult to understand whether his opinion is related to either the price of the product or the quality of the product.
4.4.2 Annotation for Sentiment Analysis at the Sentence Level
As regards the method of analyzing opinions at the sentence level, the two corpus have been labelled into five classes which are shown in table 3.
Table 3 Sentiment classes with examples of comments from the two corpus
| Examples of comments written in Arabic | Examples of comments written in latin | |
| Positive |
 |
7lou 3jebni ha9 |
| Negative |
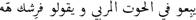 |
les caissiere hala yahkyou m3ana bkelet tourbya |
| very positive |
 |
a7ssen afar wahsen kadya w service fi mg |
| very negative |
 |
7asilou allah latraba7kom ou latfar7kom |
| Neutral |
 |
famech rakadha on promotion svp |
4.5 Feature Vectors
Our method applied two main feature vectors, namely word embedding vectors and the morpho-syntactic analysis. Although the preprocessing step was performed in the two corpora, the comments are not ready to be used by two neural network algorithms because they require a representation of the words that were considered as feature vectors. Our classifiers, CNN, LSTM and Bi-LSTM deep learning networks, take as input the vector representations of each word.
Indeed, it is necessary to go through the creation of a characteristic vector for each word in a comment. Consequently, we implemented the Gensimfn of the Word2Vec model. This model plays a key role as it uses a deep neural network, manipulates sentences in a given document, and generates output vectors. The Word2Vec model was developed by Google researchers led by [37]. The word2vec algorithms include two different models: skip-gram and the Continuous Bag-of-Words (CBOW) model. In the first model, the distributed representations of the input word are used to predict the context. In the second model, however,the representations of the context are combined to predict the word in the middle.
For the morpho-syntactic analysis, we employed the tool developed by [52], who proposed a method to remove the ambiguity in the output of the morphological analyzer from the Tunisian Dialect. They disambiguated results of the Al-Khalil-TUN Tunisian Dialect morphological analyzer [53] Their suggested method achieved an accuracy of 87%. For our work, entity names are identified by words which are labeled with ”noun” and ”prop-noun”. about sentiment words, they are recognized by words labeled with the words ”adj” and ”verb”.
4.6 Classification
For the implementation of these methods, we selected three algorithms, namely CNN, LSTM and Bi-LSTM by relaying the deep learning methods in order to implement the two tasks, namely, sentence-based sentiment analysis and aspect-based sentiment analysis.
We applied the Word2vec algorithm as input for both neural networks. The general architecture of neural networks is illustrated in figure 2.
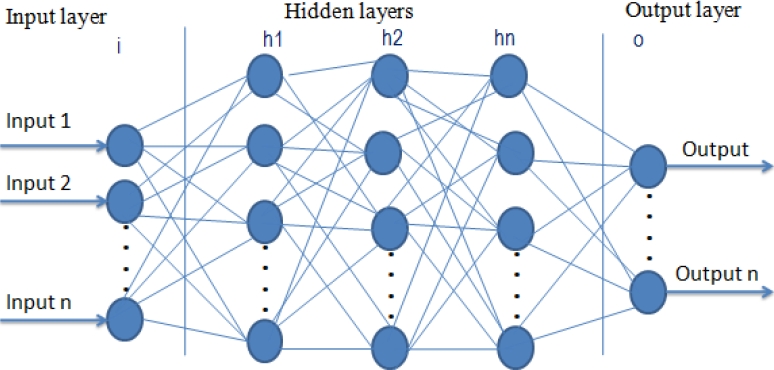
The neural network is defined by determining the number of input layers, the number of hidden layers and the number of output layers. As illustrated in Figure 2, the neural network architecture can be expressed in this way:
In the input layer, the inputs (1 · · · n) indicate a sequence of words. Then, i = (i1 · · · in) present the vector representations of entries entered. The neural network consists of h = (h1 · · · hn) hidden layers that aim to map the vectors i to hidden layers h. The last layer, the output layer, receiving the last hidden layer output to merge and produce the final result o.
4.6.1 Convolution Neural Network model (CNN)
CNN is also called Convnets or Cnns, it is one of the models of deep learning that marks impressive results in the field of TALN in general, and in the analysis of feelings.
Our CNN model consists of an input and an output layer, along with numerous hidden layers. Conventionally, the layers of a neural network are fully connected. This explains the fact that the output of each layer is the input of the next layer. The hidden layers consist of convolution layers, pooling layers, two fully connected layers, and activation functions. The pooling layer is applied to the output of the convolution layer. The fully connected layer aims to concatenate all the vectors into one single vector. The activation function introduces non-linearity into the neural network through a softmax classification layer. The output layer generates the polarity of each input comment.
To summarize, to train our CNN model, we adopted the Word2vec algorithm for the representation of words with a size of 300. This representation presents the input of the convolution layer. The convolution results are grouped or aggregated to a representative number via the pooling layer. This number is sent to a fully connected neural structure in which the classification decision is based on the weights assigned to each entity in the text.
Indeed, the main purpose of the fully connected layer is the reduction or compression of the dimensional representation of input data generated by the convolution layer. The output from the pooling layer is passed to a fully connected softmax layer. As a multi-class classification was adopted in our work, we used a Softmax classification layer which predicts the probabilities for each class.
The figure 3 summarizes how the CNN model works for sentiment analysis at the two levels.For the aspect level, for the aspect category model, the input is a vector representation of each sentence with its aspect words, while, for the sentiment model, is a vector representation of each sentence with its sentiment words. Concerning the output, for the aspect category model, the output is a list of 20 categories classes, and, for the sentiment model, it’s a list of 5 classes. While, for the sentence level, the input of the model is a vector representation of each sentence. The output is a list of 5 classes.

4.6.2 Long Short-Term Memory Model (LSTM)
The RNN Model is characterized by the sequential aspect of an entry in which the word order is of a significant importance. In addition, the RNN gives the possibility of processing variable length entries.
In this work, long short-term memory (LSTM) is a particular type of neural network that is used to learn sequence data. As a type of RNN, LSTM reads the input sequence from left to right. It is also capable of learning long-term relationships. That is why the prediction of an input depends on the anteposed or postposed context. So, RNN is designed to capture long distance dependencies.
The entry into the LSTM model is a sequence of word representations using the Word2vec algorithm. Then, those representations are passed to an LSTM layer. The output of this layer is also passed to a softmax activation layer which produces predictions on the whole vocabulary words.
The figure 4 summarizes how the LSTM model works for sentiment analysis at the two levels. As mentioned above in the CNN model, For the aspect level, the input is a vector representation of each sentence with its aspect words and sentiment words. The output of this level is a list of 20 categories classes and other 5 sentiment classes. For the sentence level, the input of the model is a vector representation of each sentence. While, the output is a list of 5 classes.

4.6.3 Bidirectional Long Short-Term Memory Model (Bi-LSTM)
The LSTM network reads the input sequence from left to right, while Bi-LSTM which is variant of LSTM, it relies on the connection of two LSTMs layers of reverse directions (forward and backward) on the input sequence. The first layer is the input sequence and the second layers is the reversed copy of the input sequence The output layer combines the outputs of the forward layer and backward layer by receiving both status information from the previous sequence (backward) and the next sequence (forward). Bi-LSTM is therefore very useful where the context of the entry is necessary, for example when the word negation appears before a positive term.
In our work, we used a one-layer bi-LSTM where the entry of the model is a sequence of words M represented using the Word2vec algorithm. Then, M is passed to a Bi-LSTM layer, the output of this layer is passed to a softmax activation layer which produces predictions on the whole vocabulary, for each step of the sequence. Each method of CNN and RNNs in general has its characteristics and differs from the other.
RNNs process entries sequentially, while CNNs process information in parallel. In addition, CNN models are limited to a fixed length entry, while RNN models have no such limitation. The major disadvantage of RNNs is that they train slowly compared to CNNs.
The architecture of the Bi-LSTM model for the two levels, sentence and aspect level is shown in Figure 5. As mentioned above in the CNN and LSTM models, the input of the aspect level is a vector representation of each sentence with its aspect words and sentiment words. The output of this level is a list of 20 categories classes and other 5 sentiment classes.
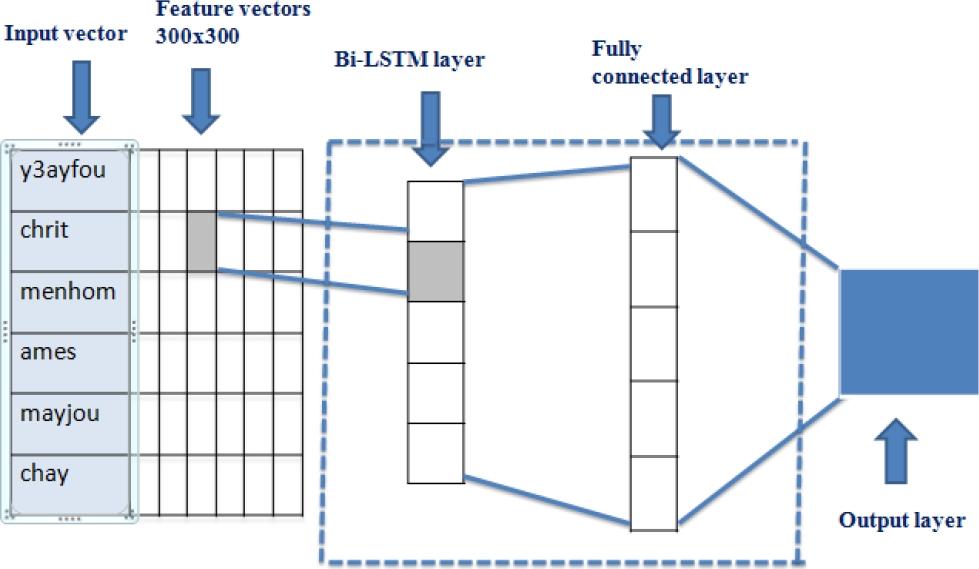
For the sentence level, the input of the model is a vector representation of each sentence. The output generating is a list of 5 classes.
5 Experiments
In this experiment, three deep Learning methods (CNN, LSTM and Bi-LSTM) were used.
In order to evaluate the two systems. Due to the informal nature of the Tunisian Dialect, we are required to convert all the different forms of a given word into a single orthographic representation. This explains our choice of the CODA-TUN tool (Conventional Orthography for Tunisian Arabic) that is introduced by [51].
One of the major features used in our work is word embedding technique that was described in section 6.6 as input features for our models. In our method, each word of a comment was replaced by a 1D vector representation of dimension d, with d is the length of the vector that equals to 300.
The sentiment analysis at aspect level requires not only the extraction of entity names for the formation of category aspect models, but also the use of sentiment words in order to construct the sentiment model. For this reason, we made use of Al-Khalil-TUN Tunisian Dialect morphological analyzer developed by [52] to remove the output ambiguity.
5.1 Dataset
In order to present our corpus used for sentiment analysis at the two levels, we have classified our collected data into two parts. The first part is the training corpus which represents around 80% of the total size while the second part constitutes 20% of the corpus used for the test. In what follows, we will present the training corpus size and the test corpus size at each level of analysis in terms of the number of comments and the vocabulary size.
For the sentiment analysis at the sentence level, we used the two corpus. On the contrary, for the analysis at the level of aspect, we used the Arabic corpus only because of the absence of a morphosyntactic analyzer for Latin writing. For the sentiment analysis at sentence level, table 4 reports the corpus size followed by the vocabulary size for the training and test corpus. For sentiment analysis at aspect level, table 5 presents the corpus size followed by the vocabulary size for the category model and the sentiment model for the training and test corpus. The figure 6 presents the 20 aspect category classes of our Arabic corpus according to the estimated number of occurrences.
Table 4 The corpus size followed by the vocabulary size for sentence-based sentiment analysis
| # of comments | vocabulary size | |
| Training corpus | 35k | 77k |
| Test corpus | 9k | 38k |
Table 5 The corpus size followed by the vocabulary size for aspect-based sentiment analysis
| # of comments | Vocabulary size for category model | Vocabulary size for sentiment model | |
| Training corpus | 14k | 4k | 4k |
| Test corpus | 3k | 2K | 2k |
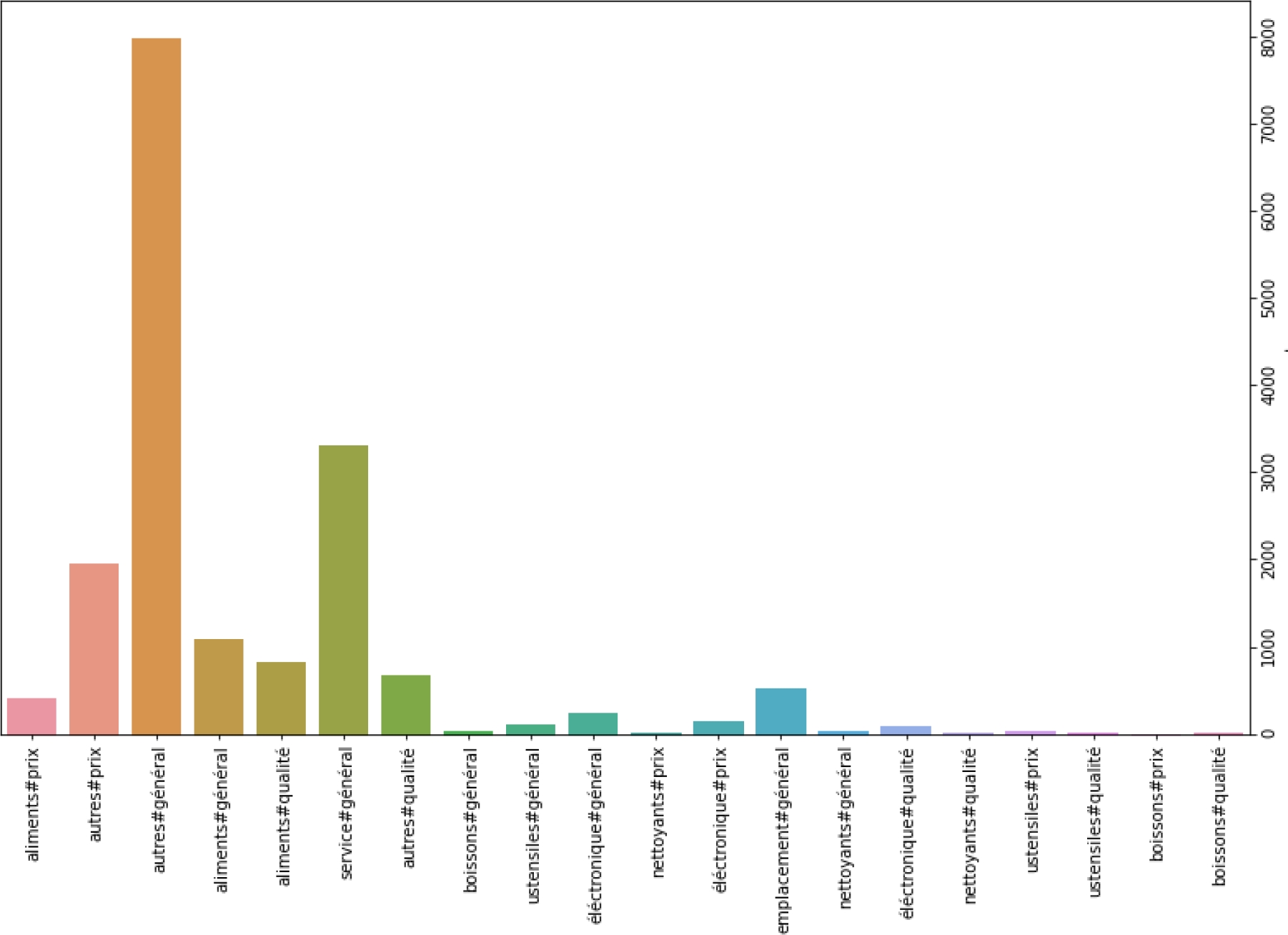
The axis refers to the aspect categories in our dataset. x shows the estimated number of occurrences. The number of comments classified as (others-general) is the largest part of the dataset.
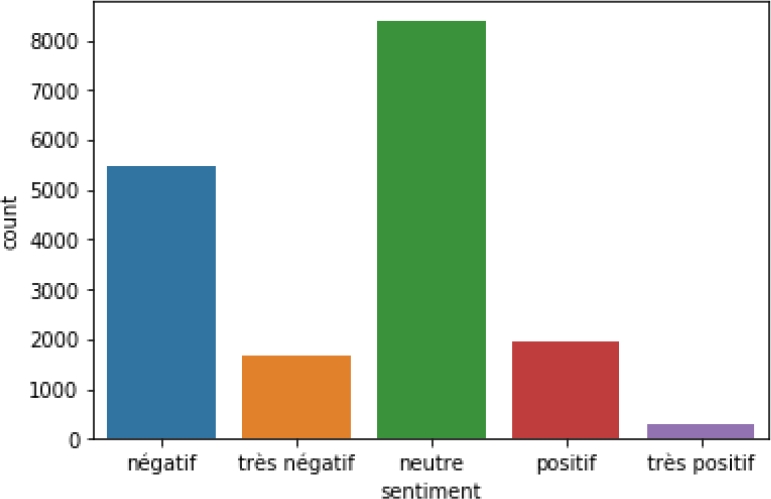
The figures 7 and 8 presents some statistics of sentiment classes for both, Arabic corpus and Arabizi corpus.

5.2 Evaluation Metrics
In order to assess the performance of the two levels, at sentence level and aspect level. Concerning the aspect level,for the aspect category model and the sentiment model, we calculated the F-Measure 1 of each model by combining both precision and recall measures. The F-Measure also called F-score is computed as the harmonic mean of the precision and recall with values ranging between 0 (representing the worst score) and 1 (representing the best score). Therefore, the F-Measure is calculated as follows:
5.3 Evaluation Results and Discussion
In this part we will present the outcomes of the evaluations carried out for the deep learning models (CNN, LSTM and Bi-LSTM). The performances of those models are represented by using F-Measure measurement. At aspect level, we present the F-Measure of each model depending on the stop words and stemming used in the pretreatment phase.
Table 6 shows F-Measure values of both the aspect category model and the sentiment model. According to table 6, we noticed that the use of stop word removal and stemming had almost no improvements for the three models. For this reason, we decided to carry out the other experiments by ignoring stemming and stop-word removal.
Table 6 F-Measures of aspect category model and sentiment model
| Aspect category model | Sentiment model | |||||
| CNN | LSTM | Bi-LSTM | CNN | LSTM | Bi-LSTM | |
| Without stop words and stemming removals | 46% | 46% | 48% | 51% | 47% | 50% |
| With stop words and stemming removals | 47% | 46% | 49% | 51% | 47% | 50% |
To achieve better results, we will test the performance of our models by classifying our experiences into 8 distinct groups. We will try to modify the number of aspect categories and sentiment classes. To do this, we changed the number of sentiment classes (5, 4, 3 and 2) without modifying the number of aspect categories presented in table 7. For a four-way classification, we ignored the neutral class. Fora three-way classification, we made some modifications. In this vein, the “very positive” class is replaced by the “positive” class, and the “very negative” class is changed to the “negative” class. Finally, for a binary classification, we went through the same steps of the three-way classification by eliminating the neutral class.
Table 7 F-Measures of the aspect category model and sentiment model with 20 aspect categories and different sentiment classes
| Aspect category model | Sentiment model | |||||
| CNN | LSTM | Bi-LSTM | CNN | LSTM | Bi-LSTM | |
| with 20 categories and 5 sentiments | 47% | 46% | 49% | 51% | 47% | 50% |
| with 20 categories and 4 sentiments | 42% | 33% | 40% | 65% | 58% | 60% |
| With 20 categories and 3 sentiments | 48% | 46% | 47% | 58% | 47% | 55% |
| with 20 categories and 2 sentiments | 42% | 28% | 41% | 77% | 75% | 78% |
According to table 7, the best F-Measure reached 49% with 20 categories and 5 sentiment classes for the aspect category model using Bi-LSTM model. However, the highest F-measure was 78% for the sentiment model using Bi-LSTM model.
In the table 8, we will focus on the modified number of aspect categories. We will also evaluate our models based on each sentiment class (5, 4, 3 and 2). Indeed, we modified the aspect categories by removing the list of attributes of aspect entities (“general”, “quality and “price”).
Table 8 F-Measure of aspect category model and sentiment model with different sentiment classes and 8 aspect categories
| Aspect category model | Sentiment model | |||||
| CNN | LSTM | Bi-LSTM | CNN | LSTM | Bi-LSTM | |
| with 8 categories and 5 sentiment | 61% | 61% | 62% | 48% | 46% | 50% |
| with 8 categories and 4 sentiment | 54% | 49% | 55% | 60% | 58% | 60% |
| With 8 categories and 3 sentiment | 62% | 61% | 62% | 54% | 47% | 49% |
| with 8 categories and 2 sentiment | 56% | 49% | 55% | 78% | 75% | 77% |
Based on the outcomes displayed in table 8, the CNN-based classification and Bi-LSTM-based classification achieved best F-Measures values with 62% for the aspect category model. For the sentiment model, the best F-Measure value obtained was 78% using CNN model.
The result obtained by the two models was not good for several reasons. First, deep learning methods need a large dataset for best performance. However, this is not the case for our work as our corpus size is only 17k. Second, morpho-syntactic analyzer that produces many empty lines was not able to extract all sentiment words and aspects.
Moreover, the training corpus utilized to train the morpho-syntactic analyzer [52] was a spoken a corpus that consists of not only radio and TV broadcasts but also conversations recorded in railway stations. Our constructed corpus, however, was gathered from the official supermarket pages. Hence, all these causes have a negative impact on the performance of our developed classifiers.
At sentence level, table 8 shows F-Measure values for the three deep learning models.
In order to achieve better results, we will test the performance of our models by classifying our experiences into 4 distinct groups by changed the number of sentiment classes (5, 4, 3 and 2). For a four-way classification, we ignored the neutral class. For a three-way classification, we made some modifications. In this vein, the “very positive” class is replaced by the “positive” class, and the “very negative” class is changed to the “negative” class. Finally, for a binary classification, we went through the same steps of the three-way classification by eliminating the neutral class.
According to table 9, the highest F-Measure reached was 87% with LSTM and Bi-LSTM with three-way and two-way classification using 5 sentiment classes.
5.4 Discussion
In this section, for the sentence level, we will compare the results obtained by our classifiers with the work [69] and of [70].
Table 10 presents, in detail, a comparison between our classifiers and those of others. We cannot compare the two levels of analysis, at the level of sentence and at the level of aspects, because they do not have the same size of corpus nor the same characteristics.
Table 10 Comparison of CNN, LSTM and Bi-LSTM results for sentiment analysis at sentence level
| Corpus Analyzer | Training corpus | Test corpus | Language | Accuracy |
| Sentiment analysis at sentence level | 35k | 7k | Tunisian dialect | For the binary classification:LSTM=87% CNN=86%Bi-LSTM =87%For the three-way classification:LSTM=87% CNN=69%Bi-LSTM =72% |
| [70] | 1k | 359 | MSA and dialect tweets | For the binary classification:LSTM=84%, CNN=77 % |
| [69] | 8k | 2k | MSA and dialects | For the three-way classification:CNN=64% LSTM=64% |
| [58] | 13k | 4k | Tunisian dialect | For the binary classification:LSTM =67% Bi-LSTM =70% |
According to table 10, our classifiers compared to that of [70] surpass the performance of the latter with F-Measure value using CNN model. [70] obtained an accuracy of 85% using CNN, while our classifier recorded an F-Measure of 68% using CNN for a binary-classification.
On the other hand, by comparing our system with that of [69], our classifiers were able to obtain better F-Measure with 87% for LSTM and 68% for CNN with respect to 64% and 64% respectively for the classifiers from [69].
Regarding aspect-based sentiment analysis, the main challenge is the lack of tools available to deal with Arabic content and especially dialects. In this fact, there is not much work that has focused on this level of analysis for the Arabic language using deep learning.
Indeed, based on the outcomes displayed in table 10, the performance of [73] classifier has surpassed our classifier in terms of precision, which obtained an accuracy of 82%, while our classifier recorded an accuracy of 61% for the category appearance model and 75% for the sentiment model.
6 Conclusion and Future Work
This research focuses on the domain of sentiment analysis at two levels for the Tunisian Dialect, the sentence level and aspect level. We chose to work in the field of supermarkets. We selected the comments from the official Facebook pages of Tunisian supermarkets, namely Aziza, Carrefour, Magasin General, Geant and Monoprix. To the best of our knowledge.
At the aspect level, this is the first work that deals with the sentiment analysis problem in the Tunisian Dialect. In order to perform the sentiment analysis task, we utilized a machine learning approach, called deep learning. Indeed, we have developed three deep learning algorithms called, CNN, LSTM and Bi-LSTM. At sentence level, our system achieved a best performance with an F-Measure value of 87% using LSTM and Bi-LSTM. At aspect level, our system achieved a best performance with an F-Measure value of 62% for the aspect category model and 78% for sentiment model using Bi-LSTM and CNN.
Five universal problems for processing Tunisian Dialect affect the performance of the sentiment analysis task. First, the Tunisian Dialect, representing a mosaic of languages, is strongly influenced by other languages, like Turkish, Italian and French. Second, Tunisian people write and comment based on two type of scripts, namely Latin script and Arabic script. Third, due to the absence of a standard orthography, people use a spontaneous orthography based on phonological criteria. Fourth, the Tunisian Dialect is usually written without diacritical signs. One of the major functions of these signs is to determine and facilitate the meaning of words, phrases or sentences.
Our future works will focus, first, on improve and develop our models to be more precise in detecting negation and to deal with both the sarcasm problem and spam detection. In addition, we will try to increase the dataset size by transliterating the Arabizi corpus into Arabic.
Finally, in order to ameliorate the outcomes of our models (CNN, LSTM and Bi-LSTM), we will try to test other deep learning techniques, like DNN (deep neural networks) and DBN (deep belief networks).

