











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Dictionaries are language compendiums that include carefully selected information to provide linguistic information about the lexical units they contain. There are different types of dictionaries, which vary in their content as well as their purpose. In this paper we will deal with the analysis and processing of those that are addressed to the native speakers of a language (called monolingual), that try to cover the whole lexicon of a language (general) and whose information provides the semantic-pragmatic definition of the words they define (explanatory).
These types of dictionaries exist in practically any language, so their processing can contribute to the digital enrichment of languages low on computer-readable resources. The most widely used and recognized explanatory dictionary in Spanish-speaking countries is the Diccionario de la Lengua Española (Dictionary of the Spanish Language), issued by the Real Academia Española (Royal Spanish Academy). It is often used by other dictionaries as a basis for its preparation and consultation. This work will be based on a version of this dictionary to analyze its content and propose methods to extract semantic information.
We will focus on verbs processing and the implementation of three computational methods to generate machine-readable semantic resources will be presented. Previous works have implemented different kind of methods and algorithms to identify semantic relationships from dictionaries, for example [11] uses rule matching method to extract automatically emotional lexical semantic relationship based on general dictionary. In [14] a semantic network for Turkish was developed using structural and string patterns in a dictionary.
Relation between lemmas and definiens in a Spanish dictionary are used in [17] to identify semantic characteristics of combinations; they focused on verb in the definition of another verb, a noun in the definition of another verb, a noun marked in the outline of a verb, and a noun in the outline of an adjective. [8] applied several methods of extraction of hyponym/hypernym relations based on morphosyntactic templates, simple heuristics, and word embeddings, extracting 40K unique hypernym candidates for 22K word entries. The paper is organized as follows: section 2 deals with the explanation of the structure of a Dictionary and the components that made up the Dictionary that we used; section 3 presents the method we proposed to identify simple Collocations and in section 4 we explain two methods to obtain synonyms. Finally, we share our conclusions in section 5.
2 Dictionary Structure
Dictionaries are structured by ordered sections named Lexicographical Articles, which are composed of an entry called Lexical Unit (LU) and the information that defines or describes it.
The entries are known as simple entries if they are made up of a single word, and as complex entries if they are made up of more than one word. These entries are ordered alphabetically in their base form, also called lemmatized form [7, 21].
Since dictionaries concentrate the lexicon of a language, it is possible to find in them information regarding words of all grammatical existing categories in that language, such as nouns, verbs, adjectives, adverbs, pronouns, conjunctions, etc.
The total elements that make up the dictionary that we processed are shown in table 1.
Table 1 Elements that make up the dictionary
| Element | Frequency |
| Lexical Units | 89, 799 |
| Definitions | 162, 362 |
| Defined verbs | 12, 008 |
| Definitions of verbs | 27, 668 |
| Defined adjectives | 21, 788 |
| Definitions of adjectives | 33, 106 |
| Defined nouns | 44, 316 |
| Definitions of nouns | 87, 076 |
| Defined adverbs | 2, 146 |
| Definitions of adverbs | 2, 887 |
Table 2 Components of the Lexicographic Units
| Line | Lexicographic units |
| 1 2 3 |
Militar1 Del lat. militāre. 1. intr. Servir en la guerra. 2. … |
| 1 2 3 |
Militar2 Del lat. militāris. 1. adj. Perteneciente o relativo a la milicia o a la guerra, por contraposición a civil. 2. … |
When there are two or more entries that are homonymous but have a different etymological origin, a superscript is placed on them to distinguish them.
After the lexical unit, usage marks are added, that is, information regarding its restrictions and conditions of use, which allows us to know if it has a colloquial use or in some specific social stratum, if it is exclusive to some geographical area or if it belongs to some domain of specialized knowledge. Finally, the semantic information is placed, which constitutes the basic content of the lexicographical article. Below are two lexicographical articles that include the above-mentioned elements.
Line 1 indicates the lexical unit that is defined, accompanied by a superordinate that differentiates it from a homonym. Line 2 indicates its etymology, and from line 3 onward, its definitions are placed.
2.1 Definition
One way to classify lexical units is as lexical content words, which refers to nouns, adjectives, verbs and adverbs, and functional words, which contain prepositions, pronouns, etc. The lexical definition that defines the first class of words is known as the proper or peripheral definition and the definition that accompanies the second class is called the improper or functional definition.
The proper definition expresses a lexical-semantic type of meaning, while the improper definition is used to describe or explain the way functional words work and how they are used, due to their lack of real lexical meaning.
Proper definitions are generally structured under the rule of the Aristotelian definition, which consists of placing a generic term or immediate hypernym at the beginning of the definition, and later the specific difference, which uses a set of features and characteristics that differentiate the defined term from others that are grouped under the same hypernym.
Each definition is numbered according to its frequency of use, that is, the most used variant will be placed at the beginning.
Verbs are ordered by stating their definitions with a transitive mark first, followed by the intransitives, and the pronouns at the end.
2.2 General Data Cleaning
For our purpose, we apply a cleaning process to eliminate the unnecessary information from the definitions. As shown above, definitions consist of sentences, which include different kinds of information, such as sense number, etymology, grammatical marks, examples, and so on. Consider the next example:
Avivar. 1. tr. Dar viveza, excitar, animar. Avivó el paso. U. t. c. prnl. La polémica se avivó con la publicación del artículo.
The definition is made up by the next elements:
(i) Lexical Unit: Avivar (revive),
(ii) Sense number: 1,
(iii) Grammatical mark: tr. (transitive),
(iv) Definition: Dar viveza, excitar, animar, (To give vivacity, to excite, to encourage),
(v) Example: Avivó el paso (He/She sped up the pace),
(vi) Grammatical mark: U. t. c. prnl, (Used also as pronominal),
(vii) Example: La polémica se avivó con la publicación del artículo, (The polemic was fueled by the publication of the report).
Our interest was to maintain only the element (iv), that is, the definition, removing all other elements.
3 Extraction of Simple Collocations
There is not a single accepted definition for Collocations in spite of terms having been widely studied from different approaches [1, 3, 4, 5, 9, 17].
In general, collocations are two (or more) lexical units that are commonly used together. According to [4], they are in a syntactic relationship and are combined considering some restrictions with a semantic basis. They reflect the linguistic competence of the speakers, which is why they are useful in second language learning, machine translation and automatic terminology extraction.
Some of the criteria used to distinguish collocations from free word combinations are lexical criteria (a word is used in a fixed position with respect to a given word), statistical criteria (frequency of word co-occurrence), functional criteria (collocations are classified according to the function of collocational elements), etc. [10].
Examples of a free word combination, a collocation and a fixed combination are presented in the next table.
Table 3 Examples of lexical combinability in Spanish and their equivalent in English
| Free word combination | Collocation | Fixed word combination |
| Vender dulces (Sell candies) | Tener progreso (To make progress) | Tomar el pelo (To pull someone’s leg) |
| Comer fruta (Eat fruit) | Tomar un baño (To have a bath) | Llover a cántaros (To rain cats and dogs) |
Collocations are present among free word combinations and fixed word combinations. The first one is a group of two or more words that can be combined only following certain semantic restrictions. On the other hand, fixed word combinations are lexical combinations whose overall meaning cannot be derived or understood from the meanings of its parts.
The structure of collocations is formed by the so-called base and the so-called collocator. The first one provides all or almost all the meaning and choices in the second word, considering one sense, usually with an abstract or figurative character [1]. This is the reason why the collocator often varies from one language to another. Base and collocator are placed as it is shown below:
Collocations can be organized in two classes considering their components: simple, which are made up of two lexical units, and compound, made up by a lexical unit and a complex phraseological unit [5]. According to the typology in [9], possible categorical combinations, which form collocations, are pointed out in the next table:
Table 4 Categorial combinations of the lexical units in collocations
| Type of collocation | Categorial combination |
| Simple | Noun + Verb Noun + Adjective Noun + Preposition + Noun Verb + Adjective Adverb + Adjective Verb + Adjective (VA) |
| Compound | Verb + Nominal idiom Verbal idiom + Noun: Noun + Adjective idiom Verbo + Adverbial idiom Adjetive + Adverbial idiom |
Because collocations are unambiguous, they are usually used in lexicographical definitions, especially those formed by the combination Noun + Verb, taking the initial position as if it were the genus or immediate hypernym. They are also used to perform other functions in the definition, as explanatory or content notes, examples and introductory formulas [12, 19].
The lexicographical definitions of verbs in the RSAD use three different types of elements. First, the incorporation of a verb in the position of genus, as can be seen in (1). The second type makes use of verbal periphrases, exemplified in (2).
Finally, the use of collocations, as shown in (3). All of these elements are underlined in the examples:
-
(1) With verbs:
a. Using a single verb: Spell. To say the letters of each syllable separately, the syllables of each word and then the whole word. (Deletrear. Decir separadamente las letras de cada sílaba, las sílabas de cada palabra y luego la palabra entera).
b. Using two or more verbs:
Corrupt. To alter and disrupt the shape of something.
(Corromper. Alterar y trastrocar la forma de algo).
-
(2) With verbal periphrasis:
(3) With Collocations: Amenizar: Hacer ameno algo (To entertain: Make something enjoyable).
3.1 Methodology
For this task, we used an approach focused on automatically identifying word combinations following two restrictions: (i) combinations are used at the beginning of verb definitions and (ii) words are grouped under the following combinations of categories:
Pattern 1: verb + noun (VN).
Pattern 2: verb + preposition + noun (VPN).
Pattern 3: verb + adverb (VR).
Pattern 4: verb + adjective (VA).
Considering the restrictions, our hypothesis states that a word combination can be considered a collocation, if its base belongs to the lexical family of the defined verb.
Some examples of the above combinations can be seen in the following table. The process we followed to solve this task, consists of three phases, which are mentioned below:
(i) Preprocessing. Definitions are cleaned and tagged with a Part of Speech (PoS) tagger.
(ii) Processing. Definitions are selected if they fulfill the hypothesis and restrictions that were previously mentioned.
(iii) Evaluation. Possible collocations were evaluated with the criteria established by [9,22] (lexical combination restrictions and semantic, syntactic and behavioral testing at the syntagmatic and paradigmatic levels).
Table 5 Spanish collocations under our restrictions and proposed hypothesis
| Dictionary entry | Definition | Collocation |
|
Desposar (Marry) |
Contraer matrimonio (To get married) |
Contraer matrimonio (To get married) |
|
Enderezar (Straighten) |
Poner derecho o verticalmente lo que está inclinado o tendido (To set upright or vertically what is tilted or lying) |
Poner derecho (To set upright) |
3.1.1 Preprocessing
The cleaning of definitions consisted of two tasks:
a) Removing the contour formulated as Dicho de as we can see in the next example:
Dicho de una planta: formar copa.
(Said of a plant: to take on a cupped shape)
b) Removing all the selection restrictions that were incorporated between the base and the collocator of the possible collocations. In the next definition, selection restriction is underlined.
Santificar: hacer a alguien santo por medio de la gracia.
(Sanctify: to make someone holy through grace).
The removed elements were “someone”, “something”, “thing”, “person” and “place”, because they are usually used as selection restrictions in Spanish [19] and they are not useful for identifying collocations.
Then, we use the PoS tagger named Freeling to tag all the definitions, which helped us to know the grammatical category and to obtain the lemmatized form of the words.
3.1.2 Processing
The first step in this phase was to develop a heuristic to obtain the roots of the lemmatized forms of the words by eliminating the affixes that were taken from a previously created list in order to select the definitions where the base of the possible collocations belonged to the lexical family of the defined verb.
Then, combinations of words whose grammatical categories were of our interest were selected. Finally, all words out of these combinations were removed from the definitions.
3.1.3 Evaluation and Results
There were 1,347 possible collocations obtained with our method. Frequency of possible collocations grouped by category combination is shown in the next table.
Table 6 Frequency of Collocations by type of combination
| Combination | Freq | Possible Collocation |
| VN | 823 |
Dar albergue (To give shelter) |
| VA | 76 |
Causar alegría (To cause to feel happier) |
| VR | 10 |
Dejar seguro (To make sure) |
| VPN | 438 |
Adornar con alhajas (To decorate with jewelry) |
A 75% sample was taken (just over 1,000 possible collocations) to be manually evaluated. The criteria for the evaluation were taken from [9, 22]. They propose the characteristics of collocations on (i) syntactic, (ii) semantic, (iii) syntagmatic, and (iv) paradigmatic levels:
(i) Some collocations allow changes in their elements or even in their structure.
(ii) There is a semantic relationship among the elements of the collocations, which can be due to a semantic specialization or a semantic neutralization.
(iii) Collocations can present different combinations.
(iv) Collocations can be of the derivative collocation type (their elements can change their grammatical category because of the lexical meaning of their elements) or non-derivative collocation type (the previous behavior is not presented).
We found that 63% of the possible collocation candidates were really a collocation. Distribution of the rest of combinations of words is as follows: 2.8% (28) are locutions and 35.9% (363) are free word combinations.
The result was compared with a baseline obtained considering that all combinations of words with which a definition begins is a collocation.
Two thousand combinations of words were evaluated using this approach. They were also evaluated manually, and it was found that only 316 were collocations, which represents a precision of 15,8%. This result is far below that of the obtained by the proposed method.
Finally, the obtained collocations were searched in Google to verify that they were in use and not that they were an artificial construction.
4 Synonyms Extraction
We implemented two simple methods to extract synonyms from the dictionary. The first one took advantage of the synonymic and cross-reference type definitions and the second one did so through the construction of a graph based on the hyponym-hypernym relationships between the LU and its genus.
4.1 Approach Based on Synonymic and Cross-References Definitions
The solution was implemented in three phases: the first one was about cleaning data, the second one consisted of identifying the different ways in which genus are used. The third one consisted of processing definitions to get synonyms, and in the last one, results were evaluated comparing them with a dictionary of synonyms.
4.1.1 Definition Processing
Synonyms are included in definitions through different ways:
(i) Using the synonymic definition.
(ii) Using the cross-reference definition.
(iii) Using synonymic and Aristotelian definitions.
The synonymic definition consists of using synonymous words to define the meaning of an LU. It has been criticized by theoretical lexicography, since, as is commented in [23]: “from the point of view of the formal structure of the definitive statement, its content lacks syntax and, therefore, does not offer an explanation of the lexical unit being defined”.
Even so, this kind of definition is widely used. An example of a synonymic definition is presented below.
Reprimir: Contener, refrenar, templar o moderar.
(Repress: To contain, to restrain, to temper or to moderate.),
where the words contener (to contain), refrenar (to restrain), templar (to temper) and moderar (to moderate) are presented as synonyms of reprimir (to repress).
The cross-reference definition is that where one of the word’s meanings is used to define another. The next example shows this type of definition:
Iniciar, comenzar (|| dar principio a algo),
(Start: to begin (|| to set something into motion)).
The cross-reference is introduced using a double vertical bar within brackets, where the words next to the vertical bars (set something into motion) refers to the content of the specific sense of the word used as definition (begin). Finally, the combination of a synonymic and Aristotelian definition can be seen below:
Hundir: sumir, meter en lo hondo,
Sink: to dent, to shove far into something.
The first word in the definition refers to a synonym and the second one follows the Aristotelian definition. For an automatic extraction of these synonyms, a PoS tagging is not necessary because verbs in Spanish have the endings ar, er or ir, so it is possible to use only regular expressions.
4.1.2 Results
4,402 verbs presented synonymic or cross-reference definitions.
The maximum number of synonyms that was possible to identify in only one sense was five, as is shown below:
Acalorar: fomentar, promover, avivar, excitar, enardecer.
(Heat up: to encourage, to promote, to enliven, to excite, to inflame).
Afincar: arraigar, fijar, establecer, asegurar, apoyar.
(Anchor: to root, to fix, to establish, to secure, to support).
It is important to mention that all of these synonyms are valid for a specific sense of the lexical unit, that is, one single LU may have different synonyms in different senses. For example, the verb bloquear (to block) with different synonyms (which are underlined) depending on its senses is shown in the next table.
Table 7 LU synonyms depending on its senses
| Num. of sense | Definitions with synonyms |
| 1 |
Interceptar, obstruir, cerrar el paso. (To intercept, to obstruct, to close the passage). |
| 3 |
Dificultar, entorpecer la realización de un proceso. (To hinder, to obstruct the performance of a process). |
| 4 |
Entorpecer, paralizar las facultades mentales. (To numb, to paralyze the mental faculties). |
6,222 definitions were identified containing synonyms. This information was saved in a plain text file, separating each element with double sign # for an easy automatic extraction. A fragment of this file is shown below.
Ejemplificar##1##demostrar
Ejercitar##2##ejercer
Electrizar##2##exaltar, avivar, entusiasmar
Elegir##1##escoger
…
(…
Exemplify##1##demonstrate
Exercise##2##exercise
Electrify##2##exalt, enliven, excite
Choose##1##select
…)
The first element corresponds to the defined LU, the second one to the sense number and the third one to the synonym or synonyms found in the corresponding sense.
4.1.3 Approach Based on Hyponym–Hypernym Relationships
Monolingual Dictionaries organize their content following very well-known rules: every entry or lexical unit (LU) is accompanied by a sentence which define it or describe it. In case of defining a content word, the sentence is headed by a generic term or hypernym (genus) followed by information that differentiate the LU from other items grouped under the same hypernym (differentia).
For this task, we consider pairs of LU – genus as nodes of a directed graph and propose that elementary cycles are made up by groups of synonyms. There exist previous works that built a graph from dictionaries to identify synonyms following different approaches. For example [2] considers edges from the LU to each of the words in its definition, in [13] the graph is assumed to be a Markov chain where states are the graph nodes and transitions are the edges, valuated with probabilities.
Our method is based on the typical organization of definitions of words with lexical content, which is represented by a genus + differentia.
4.1.4 Genus Structure
It is important to know how genus can be structured in the definitions. All of these possibilities are shown in the next examples.
(i) When it corresponds to a verb:
Egresar: salir de alguna parte.
(Egress: to go out of somewhere).
(ii) When it corresponds to chain of verbs linked by conjunctions or disjunctions:
Importunar: incomodar o molestar con una pretensión o solicitud.
(Importune: to annoy or to bother with a pretension or request).
(iii) When it corresponds to a subordinate clause in infinitive carrying out the function of direct complement:
Gallear. Pretender sobresalir entre otros con presunción o jactancia.
Swang. Pretending to stand out from the crowd with presumption or brag
(iv) When it corresponds to a verbal periphrasis:
Reorganizar: volver a organizar algo.
Reorganize: to organize something again.
(v) When it corresponds to a combination of all previous possibilities:
Repasar: volver a mirar, examinar o registrar algo.
Review: to look over, examine or register something again.
4.1.5 Graph Construction
The approach we followed was to link the defined LU with the genus in each of its senses. If we recursively take each genus as a LU and we link it to its genus in their senses, we can create a graph. An example is shown in figure 1.
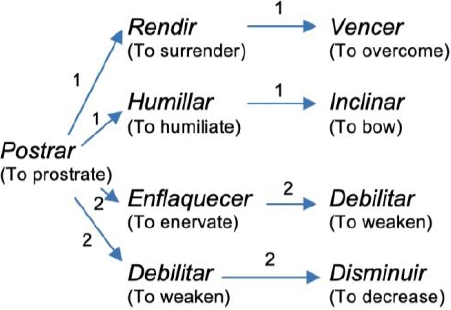
Each word represents a node, the arrow shows the hyponym-hypernym relations (left and right side in the row) and the number in the arrow shows the sense number where genus was obtained.
We can assume that a graph created from hyponym-hypernym relations cannot contain cycles, that is, paths in which the first and the last vertices are identical, but cycles are an inevitable feature of a human-oriented dictionary that tries to define all words existing in the given language [6, 15, 16]. Our assumption is that the cycles suggest a semantic relation than a hyponym/ hypernym relation.
4.1.6 Evaluation
This consideration allowed us to identify 84 cycles, which group 225 verbs. We used Spanish Espasa’s Dictionary of Synonyms and Antonyms to evaluate these results. We obtained a precision of 92% and a recall of 17%. In addition, 5% of verbs that were not found in the dictionary, were real synonyms.
The synonyms were saved in a plain text file to provide an easy automatic processing. Each row corresponds to a group of synonyms, which are separated by double slash.
contar##numerar
despojar##privar
ocultar##esconder##encubrir
…
(…
count##number
deprive##private
hide##conceal##cover
…)
5 Conclusion
Three different methods were presented to process semantic relations from a monolingual dictionary. It was shown that this kind of dictionaries are useful to identify simple collocations with a good precision result. We obtained 1,347 possible collocations with 63% of precision.
On the other hand, more than 6,000 synonyms were obtained using different approaches; in this paper, the synonym and cross-reference definitions as well as hyponym-hyperonyn relations to create a graph were used to solve this task.
This work's contribution does not rely on the implemented computational methods per se, but in the strategies to analyze the information contained in the dictionary to create different semantic resources. Our approach can be useful, for example, for less-resourced languages.

