











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The main objective of steganography is to establish forms of secret communication between two points by hiding a message on a carrier medium, in order to prevent an intermediary from detecting the existence of such communication [1]. The steganographic techniques can be applied on the spatial or frequency domain however, the spatial domain techniques are fragile against to compression or noise contamination attacks, among others. On the other hand, frequency domain techniques, such as discrete cosine transform (DCT) or discrete wavelet transform (DWT) offer better robustness against various intentional and unintentional common attacks [2]. In addition, it is possible to perform a hybrid steganography method that uses more than one frequency domain as shown in [3].
However, the data hiding methods implemented in the frequency domain, even though they are robust to different manipulation attacks on the carrier medium, still present low embedding capacity, low quality in the modified carrier medium, and/or low quality in the recovered secret message.
Digital images are the most preferred medium to apply steganography, as they contain large amount of redundant data. Image steganography embeds the secret message into the image by modifying pixel intensities in a manner that alterations are hardly noticeable to human eye [4].
Nevertheless, the type of digital content (text, image, audio) to hide into the carrier image can produce different effects on the three main characteristics of steganography: imperceptibility, robustness and embedding capacity. This means that each steganographic method must be designed taking into account the three main characteristics mentioned above in order to obtain the best performance.
On the other hand, digital speech signals and digital images are not commonly employed together in steganography schemes due to the existing difficulties regarding their sizes.
For example, just a 5-second speech signal with a sampling rate of 8 kHz can hold up to 40,000 samples and, if it is necessary to represent the information as a binary sequence, there would be 640,000 bits for 16-bit resolution per sample. Thus, it is necessary to develop steganography techniques that allow embed a large amount of binary data, maintaining a high trade-off between the three characteristics mentioned above, and ensuring that the extracted speech signal from the stego-image (carrier image with embedded secret message) is intelligible.
In this paper, a digital image steganography scheme for speech signals is designed. This new steganographic framework appears to demonstrate high embedding capacity of speech signals and robustness against JPEG compression. The embedding process is implemented in the DWT domain of the luminance channel using the YCbCr color space, additionally, a chaotic map method is implemented to encrypt the speech signal and spread it throughout the whole image.
2 Related Work
Previously proposed steganographic schemes that embed speech signals into digital images are discussed below.
Talbi et al. [5], proposed a scheme that embeds and extracts a speech signal using digital color images as a carrier. The embedding process is performed in the frequency domain using the DCT. The speech signal is amplitude modulated before to be embedded into the DCT coefficients of the red color channel. For extraction process, the original carrier image is required to correctly extract the secret signal from the stego-image, however, the maximum SNR value for the recovered speech signal is 16 dB.
In [6], a steganographic method based on the singular value decomposition (SVD) for speech signals is presented. Firstly, the speech signal is transformed into a gray-scale image, then, the singular value decomposition (SVD) is applied to the speech gray-scale image; also, the SVD is applied to the HH1 subband of the first level of the lifting wavelet transform (LWT) of the color carrier image.
Data hiding is performed by replacing the singular values of HH1 with the singular values of the speech gray-scale image; then, SVD is applied to obtain the modified HH1 band. Finally, an 8-bit signature is generated using the U and V matrices of the speech gray-scale image to embed it into the LL4 and HH4 subbands of the fourth level decomposition of the LWT. For the extraction process, the embedded original 8-bit signature is compared with the extracted from the stego-image and, if the signatures match, the secret speech signal is reconstructed applying SVD to the modified subband, extracting the SVs and using the Uw and Vw orthogonal matrices.
Talbi [7] presents a steganographic method based on [6], which additionally uses an encryption technique to increase the security of the hidden speech signal. Experimental results obtained in [6, 7] have demonstrated low embedding capacity, and regular performance in the quality of the stego-image (PSNR ≈ 40 dB) and the quality of the extracted speech signal (SNR of 25 dB) for maximum 8-second recording speech signals using 512×512 carrier color images.
Punidha et al. [8], described a scheme based on the integer wavelet transform (IWT) and the YCbCr color space. For the embedding process, the secret message is generated using the approximation coefficients of the first level IWT of the speech signal and it is embedded into the LL1 subband of the first level IWT decomposition of the Cb channel. During the extraction process, only the stego-image is required, however, only the Cb channel is used for hiding in order to maintain the visual quality of the stego-image, resulting in limited embedding capacity of this method.
In summary, steganographic systems that embed speech signals into digital images mainly have the disadvantage of low embedding capacity; thus, when a speech signal is embedded, too much pixels in the carrier image are modified, degrading the visual quality of the stego-image.
3 Methodology
The proposed scheme allows to embed digital speech signals in color images with a semi-blind steganographic approach.
The embedding and extraction processes are developed in the DWT domain (Haar wavelet) and a sine chaotic map is used to increase the security of the hidden message and spread it throughout the whole image avoiding its direct accessibility. The designed scheme is mainly divided in two process. The first one consists of the embedding stage, which is presented in figure 1, and the second process forms the extraction stage, which can be observed in figure 3.
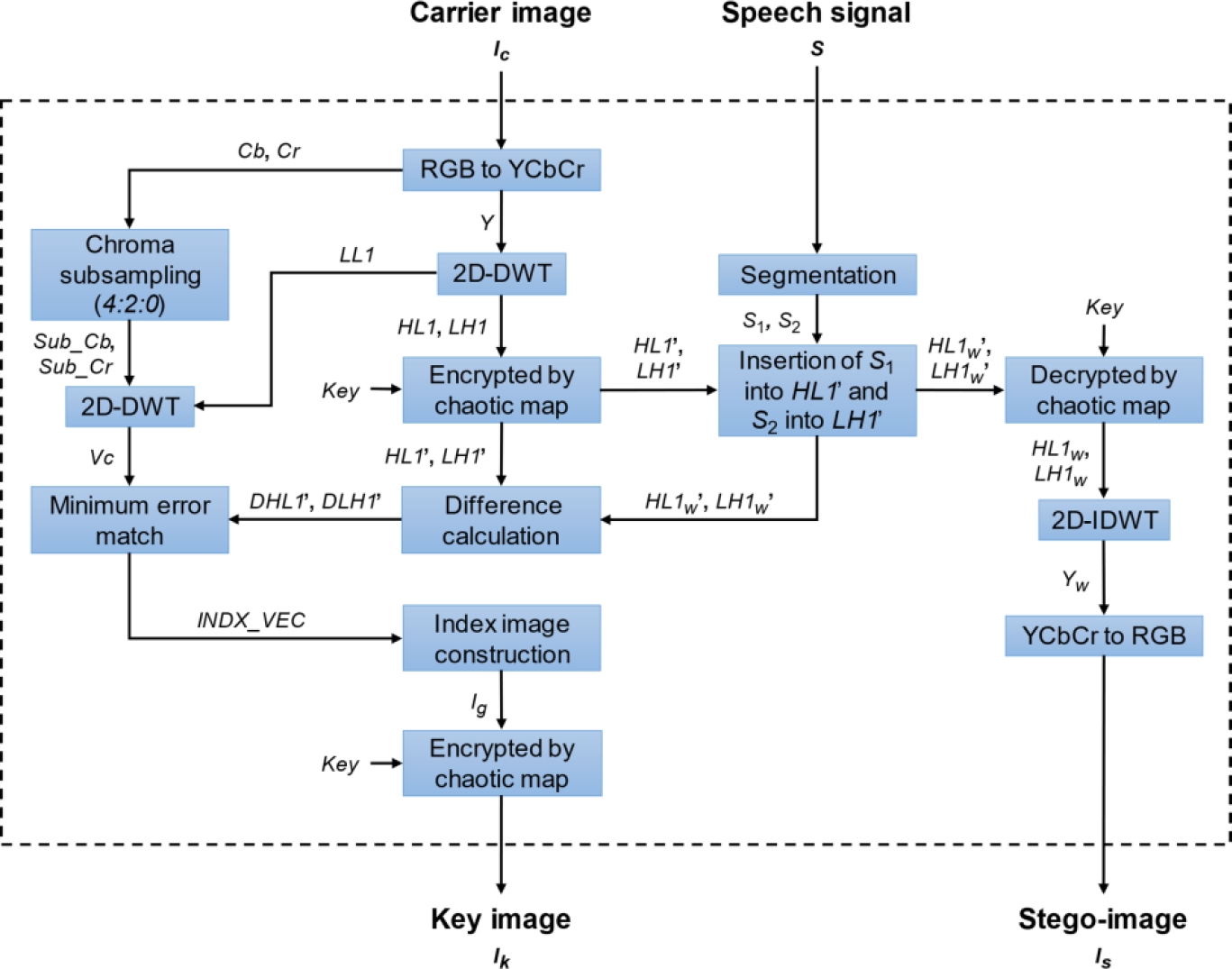

3.1 Speech Signal Embedding
Figure 1 shows the detailed block diagram for the speech signal embedding process.
Firstly, the carrier image is transformed from the RGB color space to the YCbCr color space [9]:
Then, the Y channel is transformed to the first-level DWT decomposition in order to obtain the LL1, HL1, LH1 and HH1 subbands, where HL1 and LH1 are encrypted by the sine chaotic map [10] using the equation (4), obtaining the chaotic subbands HL1’ and LH1’.
where
The digital speech signal is divided in two segments of the same size (S1 and S2), which are embedded into the HL1’ and LH1’ coefficients according to following equation:
where A is the carrier coefficient,
In this way, the chaotic subbands with the secret signal HL1w’ and LH1w’ are obtained and decrypted using the sine chaotic maps system. Then, the modified luminance channel Yw is calculated by applying the inverse DWT (IDWT) to the LL1, HL1w, LH1w and HH1 subbands. The stego-image Is is obtained by the YCbCr to RGB conversion as follows:
After the stego-image is obtained, the differences between the subbands HL1’, LH1’ and HL1w’, LH1w’ respectively, are calculated as follows:
Additionally, the Cb and Cr channels are resampled using the 4:2:0 chroma subsampling format, obtaining Sub_Cb and Sub_Cr. Then, a vector Vc is performed from the coefficients in the HL2, LH2, and HH2 subbands of the second-level DWT decomposition of LL1, and the coefficients of the Sub_Cb and Sub_Cr transformed to the first-level DWT decomposition.
In this way, each value in DHL1’ and DLH1’ is used in (11) to calculate the absolute difference with each element in Vc. Subsequently, is necessary to locate and store the index of the coefficient in Vc where the absolute difference has the smallest value (minimum error) obtaining INDX_VEC:
where a ∈ {DHL1’, DLH1’} and b ∈ Vc.
The obtained indexes INDX_VEC are normalized to a range of values between 0 and 255 to construct a grayscale image, which is encrypted using the sine chaotic map. Figure 2 shows the normalization process of the indexes. As can be seen, a matrix is performed from the normalized indexes vector. The dimensions of this matrix are established from the maximum information capacity that can be embedded and the necessary number of bits to represent the largest index of Vc. For example, for a 512×512 image, it is possible to hide up to 131,072 audio samples and 18 bits are required to represent the largest index of Vc; therefore, there are 294,912 normalized values in the range of 0 to 255. Thus, the matrix should be dimensioned using the following equation:
where M is the vertical dimension (height), N is the horizontal dimension (width) and INs is the normalized value vector size. So, for INs = 294,912, the dimensions of the matrix should be 543×544, obtaining the gray-scale image Ig. Finally, the key image Ik is obtained by applying the sine chaotic map to Ig.
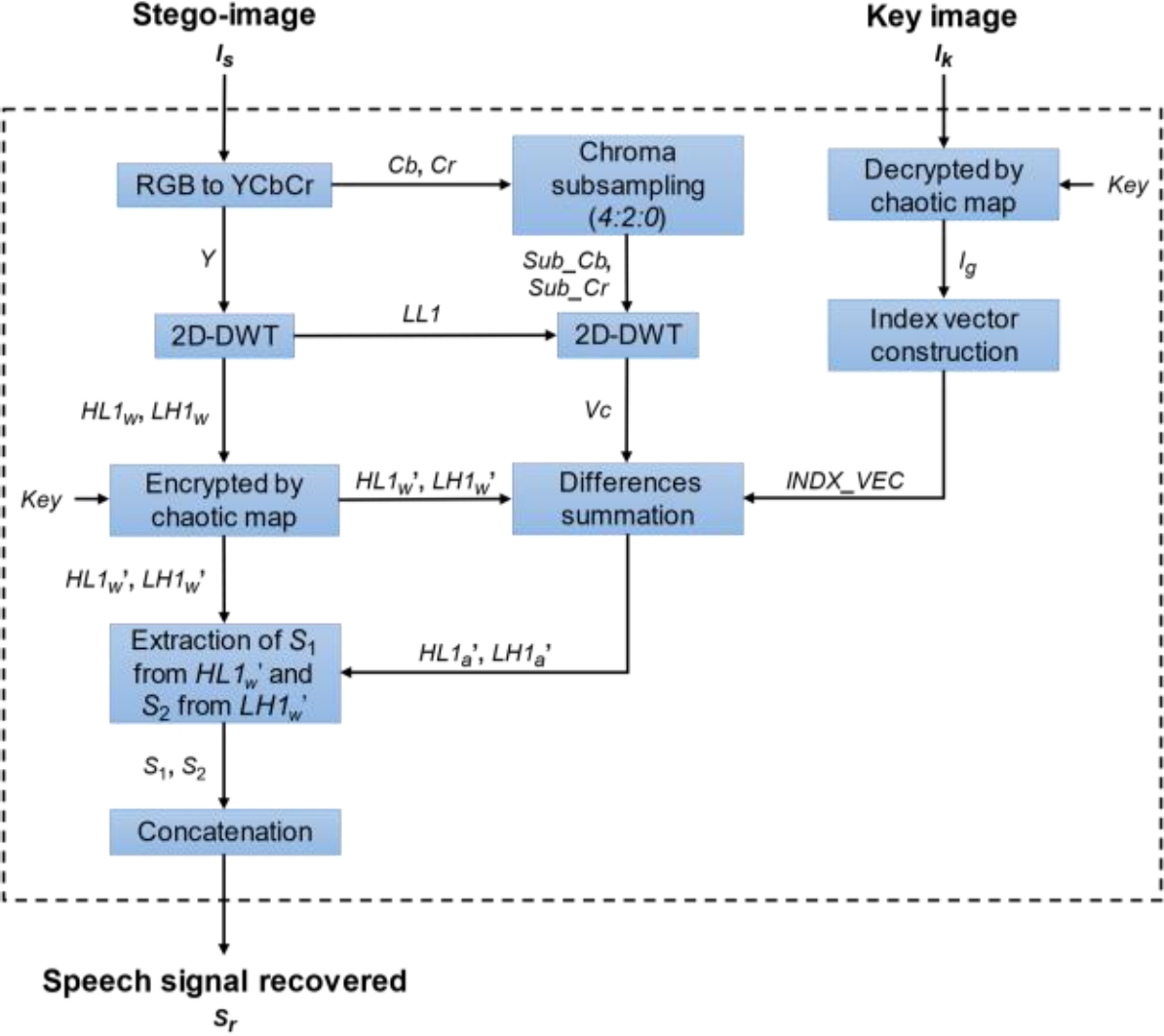
3.2 Speech Signal Extraction Process
The speech signal recovery process requires the stego-image and the key image. Figure 3 explains the procedures required to extract and reconstruct the speech signal. Firstly, the stego-image is transformed to the YCbCr color space using (1)-(3); then, the Y channel is divided into the LL1, HL1w, LH1w and HH1 subbands derived from the first-level DWT decomposition. HL1w and LH1w contain the secret message, however, it is necessary to encrypt this subbands by the sine chaotic map before starting extraction.
As shown in figure 3, the vector Vc is constructed in the same way as in the embedding process but with the stego-image. On the other hand, the key image is decrypted using the sine chaotic map in order to convert each pixel to a binary sequence and, knowing the number of bits necessary to represent the largest index of Vc, binary blocks are generated, which are converted to decimal values. The new normalized values are used as indexes to locate the coefficients in Vc that are closer to the differences DHL1’ and DLH1’ calculated at the embedding stage.
The “Differences summation” block shown in figure 3 consists of computing the approximations of the original chaotic subbands HL1’ and LH1’ using following equations:
where DHL1a’ and DLH1a’ are the approximations of the differences DHL1’ and DLH1’, respectively.
Therefore, the difference between HL1w’ and HL1a’ allows the first S1 segment extraction of the secret message, and the difference between LH1w’ and LH1a’ permits the second S2 segment extraction using equation (15). The secret message extracted from both segments are concatenated to obtain the recovered speech signal Sr.:
where Aw are the values obtained from HL1w’ or LH1w’, and Ax are the approximate values obtained from HL1a’ or LH1a’.
4 Experimental Results
To evaluate the performance of the proposed system, different tests have been carried
out on RGB images with dimensions of 512×512 pixels. The main characteristics of the
digital speech signals used as the secret message to perform the tests are: sampling
frequency Fs = 8000 Hz, bits of quantization
bQ = 16, monoaural in.wav format, from 2 to 16.384 seconds of
recording time values, and the embedding strength has been adjusted to
Figure 4 shows some color images used as carriers in the proposed scheme.

Figure 5 shows two speech signals with different recording times used as secret messages. It is important to mention that the speech signal shown in figure 5(b) allows to embed the maximum possible information capacity into the carrier images.

Figure 6 shows the stego-images and the key images obtained from the embedded process for two different speech signals.

Fig. 6 Stego-images and key images obtained from the embedded process for two different speech signals: (a1, a2) Stego-images and (b1, b2) Key images with 8 sec embedded speech signal; (c1, c2) Stego-images and (d1, d2) Key images with 16.384 sec embedded speech signal
Table 1 shows the experimental results comparison between the proposed scheme and state-of-the-art schemes for the imperceptibility of the secret message and the final visual quality of the stego-image, when the objective evaluation criteria were the PSNR and SSIM values between the original carrier images and the stego-images. Additionally, the audio quality of the recovered speech signal has been evaluated using the signal-to-noise ratio (SNR) values between the original speech signal and the reconstructed one.
Table 1 Objective evaluation comparison of the stego-images and recovered speech signals for the proposed scheme and the state-of-the-art methods. (NS – Not supported)
| Carrier image | Scheme | Stego-image | Recovered speech signal | ||||
| PSNR (dB) | SSIM | SNR (dB) | |||||
| 8 sec | 16.38 sec | 8 sec | 16.38 sec | 8 sec | 16.38 sec | ||
| Airplane | Proposed | 34.42 | 31.85 | 0.87 | 0.82 | 42.72 | 40.58 |
| [5] | 31.70 | 30.69 | 0.89 | 0.81 | 13.82 | 12.74 | |
| [6] | 41.16 | NS | 0.99 | NS | 27.0 | NS | |
| [7] | 43.48 | NS | 0.99 | NS | 14.24 | NS | |
| [8] | NS | NS | NS | NS | NS | NS | |
| House | Proposed | 34.43 | 31.87 | 0.95 | 0.92 | 43.29 | 40.62 |
| [5] | 30.55 | 29.51 | 0.94 | 0.91 | 13.82 | 12.90 | |
| [6] | 37.84 | NS | 0.99 | NS | 11.31 | NS | |
| [7] | 41.01 | NS | 0.99 | NS | 18.23 | NS | |
| [8] | NS | NS | NS | NS | NS | NS | |
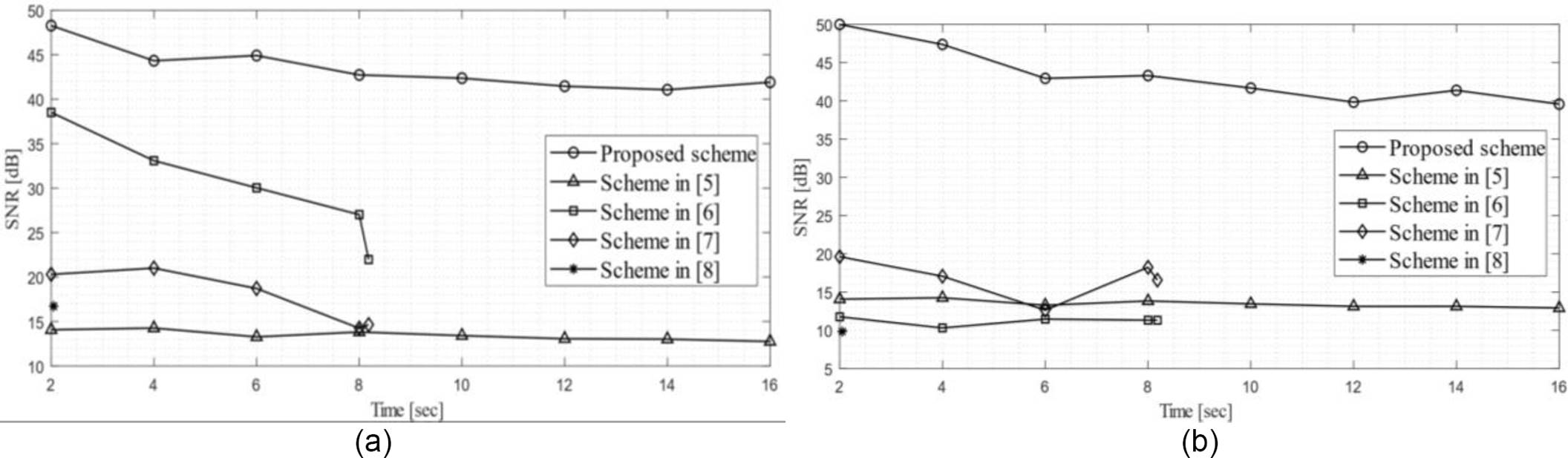
Figures 7 and 8 show the objective audio measure SNR for the recovered speech signals against JPEG compression, applied to the stego-images Airplane and House respectively, with different quality factors, in order to evaluate the robustness of the proposed scheme and the state-of-the-art methods. As we can be seen in figure 7 and figure 8, the method presented in [8] cannot embed speech signals larger than 2.048 seconds of recording time into color images of 512×512 pixels. The same conclusion can be achieved for schemes presented in [6] and [7] (see figures 7(b) and 8(b)), because they can only embed speech signals with a maximum recording time of 8.192 seconds.

Fig. 7 Robustness evaluation comparison of recovered speech signals against JPEG compression at different quality factors for the stego-image Airplane using: (a) 8 sec speech signal, (b) 16.384 sec speech signal

Fig. 8 Robustness evaluation comparison of recovered speech signals against JPEG compression at different quality factors for the stego-image House using: (a) 8 sec speech signal, (b) 16.384 sec speech signal
Figure 9 shows a performance comparison between the proposed scheme and state-of-the-art methods, regarding to the recovered speech signals audio quality for different recording times from 2 to 16 seconds. As it can be noticed in experimental results, the proposed scheme appears to demonstrate an outstanding performance compared with state-of-the-art schemes in terms of imperceptibility for the secret message, excellent visual quality of the stego-image, improved embedding capacity, higher robustness against JPEG compression and superior audio quality of the recovered speech signal.
5 Conclusions
In this paper, a new steganographic scheme that hides a digital speech signal into a color image is presented. The proposed scheme has been evaluated with several speech signals with different recording times, demonstrating higher embedding capacity, better robustness and imperceptibility of the secret message, excellent visual quality of the stego-image and superior audio quality of the recovered speech signal in comparison with state-of-the-art schemes.
The designed scheme shows a non-visual perceptible difference between the original carrier image and stego-image, even if the maximum embedding capacity of the proposed scheme is used, obtaining an average values of 32 dB and 0.92 in PSNR and SSIM, respectively.
The main advantage of the proposed steganographic scheme is the robustness against JPEG compression at different quality factors (from 75 to 100), allowing to embed a speech signal up to 16.384 seconds of recording time into a carrier color image with 512×512 pixels, without any degradation of the audio quality of the recovered speech signal (up to 41 dB of SNR), even if the stego-image is JPEG compressed (up to 30 dB of SNR).

