











 nova página do texto(beta)
nova página do texto(beta) Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1 Introduction
Advertising aggregation into web pages is a common strategy for monetization. Too many web sites deliver free content and get income using advertising payment. This kind of monetization allows them to operate and to keep information production. Sometimes advertising causes displeasure for diverse reasons, for instance, when the amount of publicity is excessive and others when the commercial message is discordant for the information read.
Advertising aggregation is an important issue that must be analyzed from different points of view. On one side, commercial information is necessary for guaranteeing the economic survival of web sites. On the other hand, users read information about their interest, i.e., they browse and consume web content according to a specific motivation. We consider that methods that preserve the thematic sense between web content and an advertising message can reduce the reader’s displeasure when publicity is shown.
In this work, we consider the thematic sense as a set of topics which are correlated. For instance, a football match, which is transmitted by TV, regularly is related to the consuming of snacks and beer and, perhaps, within a friend’s meeting. They are different facts, a football match, snacks, and beer drinking and friends meeting. However, they are correlated. A formal approach that is useful to find out correlations into data is the technique of Latent Semantic Analysis (LSA [4]).
Here we can state the proposal for this work. We think that a gentle introduction to the publicity can be reached if the sense of the web content concerning the advertising message can be assured. For this reason, we introduce a formal method, to measure the level of correlation among both messages, expressed within text fragments.
Our proposal is motivated, too, by the behavior of new styles of inRead advertising, which dynamically presents commercial information when a user browses a web page. In this way, web page fragments could be semantically compared with the advertising message, and then, the more similar web page fragment could be determined for the publicity location.
Now an important issue must be faced, which web page fragments should be considered for the analysis?
We could treat the text source as plain documents. However, web text is formatted using (X)HTML, i.e., the information is organized in formatting nodes which frequently provide certain implicit unity (all the information in a node is related) imposed by the web designer.
In this way, the main path for this work is going to be established in the context of approaches that exploit the text fragments within a web page and written in natural language. For instance„ those devoted to web filtering such as [1, 10, 17]. Regardless of this focus, formulas here presented for calculus of semantic similarity among text fragments can be applied in a seamless way to any pair of text fragments, and thereby we could analyze sentences of paragraphs instead of web page text fragments.
We consider that methods preserving the unity of (X)HTML nodes are more acceptable. Some works following this approach are [1, 5, 14, 16]. For instance, in [1], a method for information extraction from web pages considering the distance between (X)HTML nodes as measurement of analysis is introduced. However, standard tests of similarity, in the setting of natural language processing, as a basis for producing text measurements, are not employed. We believe that it is necessary to test classical techniques of natural language processing to establish an adequate comparison framework.
In this work, we present a formal method for automatic measuring of semantic similarity among an advertising text and a web page node, based on techniques of similarity employed in natural language processing and inspired on the notion of latent semantic analysis. Our formal method requires only once the calculations of LSA, and then it returns the more relevant web page node for advertising placement.
One of the main contributions of this paper is the definition of one formula to determine the semantic similarity of one text excerpt w.r.t. an advertising text. The formula is not affected by the size of text fragments.
The rest of the paper is organized as follows. In Section 2, Theoretical foundations of our work. In Section 3, we introduce a formal technique for relevance calculation based on semantic similarity and tree-like structure of web pages. Then, in Section 5, we describe a prototype and a set of experiments. Finally, we present related work and conclusions in Section 6.
2 Theoretical Foundations
In this section standard theoretical basis of our work are introduced.
Salton et al. originally introduced the vector space model for automatic indexing in
[15] and it is considered a
standard representation technique in information retrieval setting where stored
entities (documents) are compared with each other. Given a text document
In a vectorial representation, typographic symbols such as "," or "-" are ignored. The well-known stop words are treated in the same way. For web pages, formatting labels are removed.
2.1 Latent Semantic Analysis
Latent Semantic Analysis (LSA) is a theory and technical method for extracting and representing the contextual-usage meaning of words by means of statistical computations applied to a large corpus of text [7]. Hence, the underlying idea is that the aggregate of all the word contexts in which a given word does and does not appear provide a set of mutual constraints that largely determines the similarity of meaning of words and sets of words to each other [8].
The first step of LSA consists of the construction of a matrix representation of
text, i.e., the matrix
Next, LSA performs the Singular Value Decomposition process
(SVD) on the matrix
Finally,
After SVD decomposition, the original matrix
Example 1 Let us consider the documents:
The dictionary of the document collection is {computer,
software, branded, PC, hardware, generic}. According to
previous speech, the first row in
Considering
If the similarity between vectors representing the rows 0 and 3
of
3 Calculating the More Relevant Web Page Node for Advertising
Now, we describe the main contribution of this work, i.e., a formal technique for calculating the more relevant web page node for advertising.
The goal of the technique is to find out the web page node (of a specific URL) that presents the best semantic similarity w.r.t. a given advertising text. An advertising text is a fragment of text in natural language, which is regularly inserted in a web page to be exposed.
3.1 Semantic Similarity based on LSA
Measuring the similarity of meanings between two blocks of text, on the one hand, the text of a fragment on a web page and the other, the advertising text, can be defined as an act of measuring the semantic similarity between texts.
LSA is fully documented for comparison of similarity among documents of terms. However, advertising placement requires being determined by analyzing several text pieces from a web page. In this setting, a procedure for calculation of similarity among text excerpts (of variable size) instead of documents is needed.
Our approach for application of LSA through
We require to incorporate the semantic LSA information towards distinct sized texts and also, for the aggregation of the LSA semantic information upon the similarity calculation.
In this way, our first definition for semantic similarity measurement is called
relative similarity: If a text fragment
For instance, the vector for the text fragment
Let us remember that we are computing similarities among text fragments of
several sizes, this is the reason why we apply a mapping of values from the
document in
We must consider that LSA gathers contextual information w.r.t. the terms in a collection. A certain kind of measurement of correlations should be conveniently incorporated into a new scheme of comparisons among text fragments. This is going to be examined in the following.
Definition 2 (Mutual similarity matrix
Intuitively speaking
Example 3
Let us consider the Example 1, the mutual similarity matrix of
Here
In the matrix of mutual similarities the information that shows explicitly the
numerical similarities among terms in a collection of documents is located. Now,
it is necessary to exploit such measures from
For this, we apply a simple idea: if a term
Definition 4 (threshold, meaningful relation)
Let the real number
The threshold defines the least numerical limit of similarity measure for
considering a relation between terms as important. Each row in
To incorporate main correlations in the vectors of text fragments, we define the concept of augmented vector.
Definition 5 (augmented vector)
Let
where
When a vector is augmented, not only appears the weight of those terms present in a fragment of text; also, the threshold value is incorporated in the position corresponding for terms which are not present in the fragment but, they maintain a correlation (meaningful relation) with some other terms present in the fragment. Roughly speaking, in an augmented vector, there are values for its terms and their correlated terms. Now, for computing similarity we overload standard cosine similarity.
Definition 6 (augmented similarity)
The augmented similarity between fragments of text
where the numerator represents the dot product of the augmented
vectors
Here, augmented similarity returns the similarity calculus of two vectors, which were augmented from correlations among terms.
Finally, intending to harvest the best properties of relative similarity and augmented similarity, we define semantic similarity.
Definition 7 (semantic similarity)
Given
be the semantic similarity between text fragments
Fundamentally we apply the product of relative similarity with augmented
similarity, which we call
In this way, semantic similarity combines the properties of both measurements. Relative similarity is more affected by the coincidence of terms in the ad text w.r.t. the analyzed fragment, while augmented similarity, offers greater values when a text fragment brings more relationships with its terms. In other words, it privileges the number of correlations of its terms.
At this point, a useful formal scheme for computing semantic similarity between text fragments has been completely defined. Next, a set of rules for text fragmentation to determine the more relevant text from a web page is required.
4 Extraction of Text Fragments from a Web Page
To define a strategy to extract text fragments from a web page, we could suggest many criteria. However, there is the standard scheme DOM, which organizes the content of a web page in hierarchical nodes.
Example 8 Let us consider the following web page:
DOM model is an adequate scheme. It stands for Document Object Model, which is a W3C standard platform—and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure, and style of documents [9].
Its corresponding DOM representation is visualized in a graphical mode in Figure 1. We can see a web page as a tree-like data structure where each node is an (X)HTML element, i.e., a (X)HTML tag with its contained text and its attributes, furthermore, its children are the embedded (X)HTML labels.
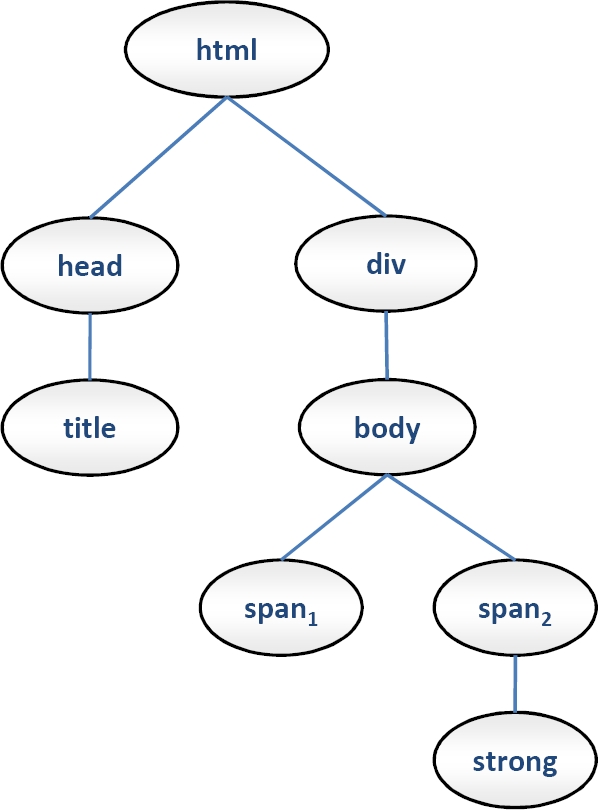
In a DOM data structure, if a node contains nested (X)HTML labels, there is a
relation of embedding between the node and its children. For
instance in Example 8,
Definition 9 (web page tree)
A web page tree
Given a web page tree
Now we define candidate branch of a web page tree in order to compute semantic similarity tests w.r.t. the web user query.
Definition 10 (candidate branch)
Let
Hence, each node (except the root) of a web page tree and its children is a candidate branch.
Definition 11 (web text)
Let
Web text is necessary to get text excerpts for applying semantic similarity calculations.
Example 12 Let us consider the web page tree of Example 8, then there are 7 candidate branches, i.e., those which are compound by the following (X)HTML elements:
Their contained texts were not drawn. Hence, the set of candidate branches is
Definition 13 (semantically relevant nodes)
Given
Example 14
Here the shape of the semantically relevant nodes is basically an ordered
list composed by candidate branches and their corresponding semantic similarity
w.r.t. an ad text, for instance:
Once semantically relevant nodes of a web page were computed, we are able to offer the most significant text excerpts as a result of an ad text.
Next, we present a definition of relevant web page node for
advertising placement. For this reason, we require some auxiliary functions:
Definition 15 (relevant web page node)
Given a web page
In Figure 2 we present an algorithm to determine the more relevant web page node for advertising location from a given web page.

Fig. 2 An algorithm for computing the more semantically related web page node for advertising location
The first step of the algorithm prepares a collection from contextual documents.
Then, it constructs the matrix
The last part of the algorithm extracts the highest semantically related web page node w.r.t. the advertising text and returns it. In other words, the algorithm determines which web page node has more semantic similarity w.r.t. an advertising text.
5 Prototype and Experiments
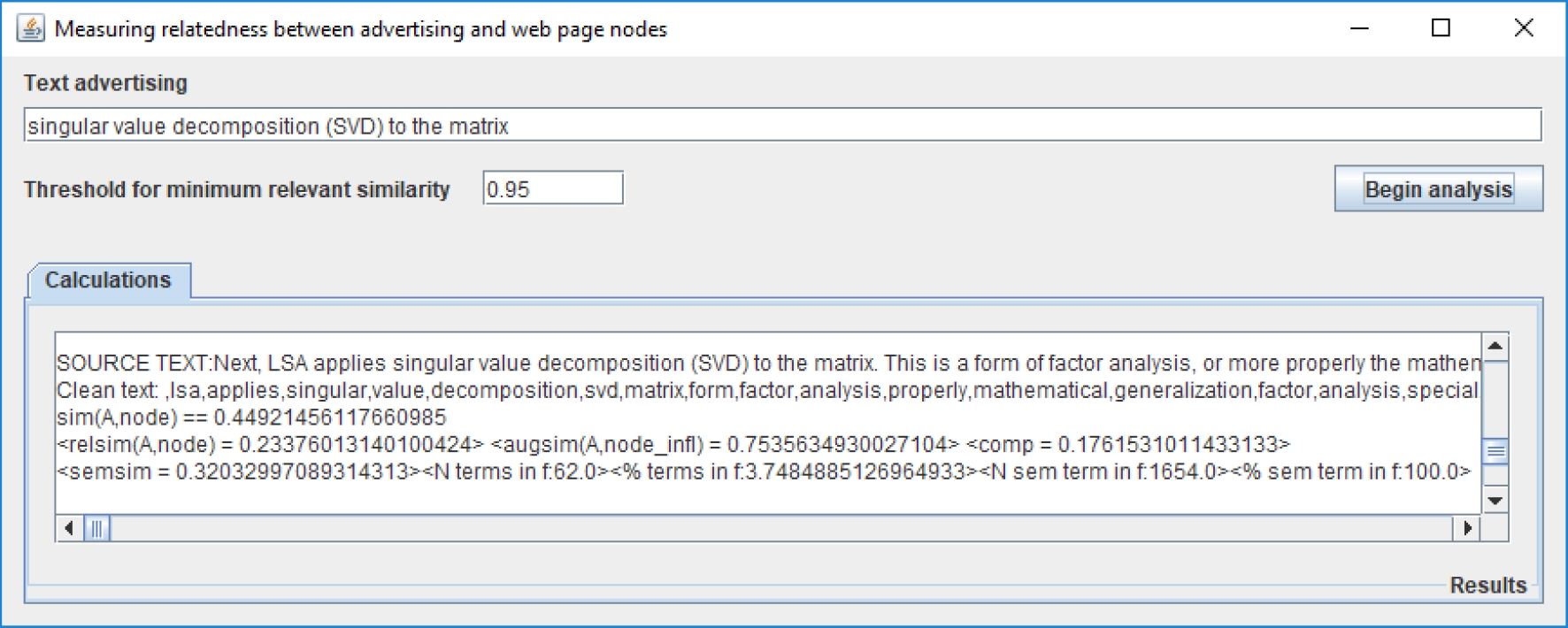
In this section, some aspects of the practical approach for web page node relevance calculation are presented, a relevant node is the more semantically related w.r.t. a text advertising. The computational tool is shown in Figure 3.

Once the target web page is defined, the web page is downloaded, for this, a parser is employed. Jericho [6] allows us to retrieve and to filter web pages and their text. Inclusive, it is possible to walk through their tree structures, visiting each node, and recovering their text. DOM node tree is visited to take one node, each time, for analysis. Then, DOM node and advertising text are augmented, and finally, a value of semantic similarity is computed. The node that presents the highest semantic similarity is chosen as the more appropriate place for particular commercial information.
Figure 4 is devoted to the natural language processing phase explanation. The first step refers to text preparation. Naturally, the tool requires a set of documents whose content must be in the same context as text advertising. It is crucial because LSA will calculate correlations between terms, which is useful for measuring semantically related texts, and to be exploited in our relevance analysis.
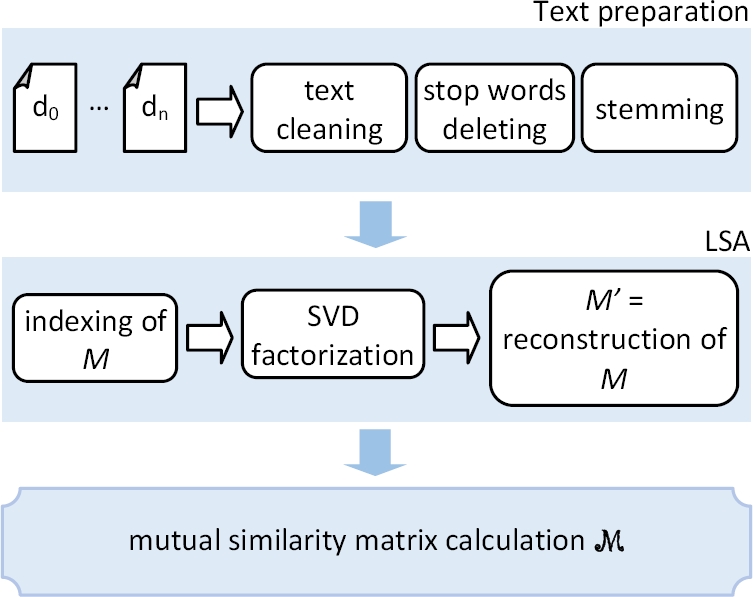
Then, the standard actions of natural language processing are shown: text cleaning,
stop words deleting, and so on. For that phase, a proper library has been developed.
Each document is treated, next, matrix
5.1 Experiments
In this section, we describe an experiment performed upon the prototype, and correspondingly upon the formal technique. The collection was composed of text documents from a set of web pages whose links are the following.
In this experiment, all web pages compose the collection of documents for LSA feeding. Next, we employ a little paragraph of text advertising to determine the more semantically related web page node (in each URL), i.e., the more relevant node for advertising placement.
Each web page was downloaded, and their DOM nodes were extracted by means of our DOM parser (based on Jericho [6]), then a text file with the set of nodes from each URL was prepared. Next, the whole process of the formal technique introduced in Section 3 was computed to determine the semantic similarity of every node and as a consequence, the best adequate place for commercial information.
The advertising text is:
In the Table 1 a set of measurements are
presented, there, a series of 26 nodes
Table 1 Measurements for
| semsim | terms | % terms | text of |
|||||
| 1 | 0.14 | 0.137 | 0.336 | 0.046 | 0.2090 | 508 | 30.71 | What is LSA? What is ... |
| 2 | 0 | 0 | 0.091 | 0 | 0.0173 | 1 | 0.06 | What is LSA? |
| 3 | 0 | 0 | 0.862 | 0 | 0.0446 | 17 | 1.02 | Note: If you linked ... |
| 4 | 0 | 0 | 0.892 | 0 | 0.0452 | 9 | 0.54 | click here to open ... |
| 5 | 0 | 0 | 0.997 | 0 | 0.0473 | 3 | 0.18 | The information on this page is based |
| 6 | 0 | 0 | 0.867 | 0 | 0.0447 | 9 | 0.54 | Landauer, T. K., Foltz, ... |
| 7 | 0 | 0 | 0.888 | 0 | 0.0451 | 4 | 0.24 | which is available for ... |
| 8 | 0 | 0 | 0.780 | 0 | 0.0428 | 68 | 4.11 | Latent Semantic Analysis (LSA) is a ... |
| 9 | 0 | 0 | 0.995 | 0 | 0.0473 | 3 | 0.18 | Latent Semantic Analysis |
| 10 | 0 | 0 | 0.091 | 0 | 0.0174 | 1 | 0.06 | (LSA) |
| 11 | 0.21 | 0.154 | 0.804 | 0.124 | 0.2882 | 70 | 4.23 | Research reported in, and ... |
| 12 | 0 | 0 | 0.997 | 0 | 0.0474 | 2 | 0.12 | semantic space |
| 13 | 0 | 0 | 0.833 | 0 | 0.0440 | 33 | 1.99 | LSA can be construed ... |
| 14 | 0 | 0 | 0.753 | 0 | 0.0422 | 72 | 4.35 | As a practical method ... |
| 15 | 0 | 0 | 0.735 | 0 | 0.0417 | 76 | 4.59 | Of course, LSA, as ... |
| 16 | 0 | 0 | 0.853 | 0 | 0.0444 | 24 | 1.45 | However, LSA as currently... |
| 17 | 0 | 0 | 0.750 | 0 | 0.0421 | 98 | 5.92 | LSA differs from other... |
| 18 | 0 | 0 | 0.729 | 0 | 0.0416 | 105 | 6.34 | However, as stated above... |
| 19 | 0 | 0 | 0.874 | 0 | 0.0449 | 6 | 0.36 | Preliminary Details about ... |
| 20 | 0 | 0 | 0.842 | 0 | 0.0442 | 47 | 2.84 | Latent Semantic Analysis is ... |
| 21 | 0.05 | 0.163 | 0.822 | 0.134 | 0.2955 | 29 | 1.75 | The first step is to ... |
| 22 | 0.45 | 0.234 | 0.754 | 0.176 | 0.3204 | 62 | 3.74 | Next, LSA applies singular ... |
| 23 | 0 | 0 | 0.859 | 0 | 0.0445 | 17 | 1.02 | Landauer, T. K., ... |
| 24 | 0 | 0 | 0.867 | 0 | 0.0447 | 4 | 0.24 | Basic and applied memory... |
| 25 | 0 | 0 | 0.863 | 0 | 0.0446 | 15 | 0.90 | Landauer, T. K., & Dumais... |
| 26 | 0 | 0 | 0.182 | 0 | 0.0232 | 2 | 0.12 | Psychological Review, ... |
The first calculus shown is
Now let us focus in a series of properties of the technique and let us observe its behavior through the results in the Table 1.
The technique is independent of the size of the text node analyzed.
Initially, it is more straightforward computing calculations in simple documents
than complete documents (or web pages). DOM nodes present the phenomenon of
embedding. For instance, node body embeds all the paragraphs on a web page.
Fragment 1 constitutes the biggest node in
The technique offers maximum qualification for keyword coincidences.
In column
The technique exploits LSA results.
6 Related Work and Conclusions
To the best of our knowledge, there are many research works focused on measuring the success of advertising campaigns [2, 3]. However, there are not for measuring the best place for publicity location on a web page. It may be that this concern is more attractive for companies and, the solutions they reach are implemented instead of being published. However, from an academic point of view, it is interesting to measure the meaning of advertising w.r.t. the meaning of the web content which a user reads. In this work, we proposed a method for the numerical comparison. Other future work will be devoted to analyzing the success of this criterion for publicity location.
In summary, we have introduced a formal technique for semantic similarity between web page nodes and advertising messages, which presents several advantages: always returns a value, is independent of the size of text fragments, privileges (numerically) the existence of common words in text node and ad text, outperforms results of cosine similarity, only once calculation of LSA is required to produce any number of comparisons from an ad text.
The exposed formula of semantic similarity is based on that presented in [13], some formalizations are included here. And finally, the technique is described in a technological style (fully procedural), which is convenient to replicate the tool.
We have developed a pair of tools, one for web page (Jericho [6] based) parsing and other for text fragment ranking (Figure 5).
For future work, we are testing deep methods based on word embedding, to produce a parametric framework for web filtering and web indexing.
The potential applications of the technique are the following: analysis of similarity among content and advertising, filtering of web pages (since we rank DOM nodes with semantic similarity), the transformation of web pages, determining of hot sections in a web page, production of industrial tools, and other more.

