











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Knowledge graphs model information in the form of entities and relationships between them [1]. This kind of relational knowledge representation has a long history in logic and artificial intelligence [2], for example, in semantic networks [3] and frames [4]. It has been used in the Semantic Web community with the purpose of creating a "web of data" that is readable by machines [5]. Knowledge graph is a powerful tool for supporting a large spectrum of search applications including ranking, recommendation, exploratory search, and web search [6,7]. A knowledge graph aggregates information around entities across multiple content sources and links these entities together.
There is a growing interest in automatically constructing knowledge graphs [8,9,10]. However, automatically constructing such graphs from noisy extractions presents numerous challenges [11,12]. There are many literatures related to this topic. From the early information extraction [13,14,15] to special data extraction, e.g. the web table extraction [16,17], and further, the relation extraction [18,19,20]. The methods range from rule based methods [21,22] to supervised methods and semi-supervised methods [23-31].
In this study, we focus on extracting the special information from structured web and building a knowledge graph. A sample web page is shown in Fig. 1. We extract the structure information shown in the red rectangle and build a knowledge graph about the enterprises. Each page on this kind of websites contains one or more facts about a particular entity (defined as topic entity, which is the subject for all relations in this page). For example, the sample web page in Fig. 1 gives information such as "Date of Establishment", "Head Office" and "Capitalization" about a company.
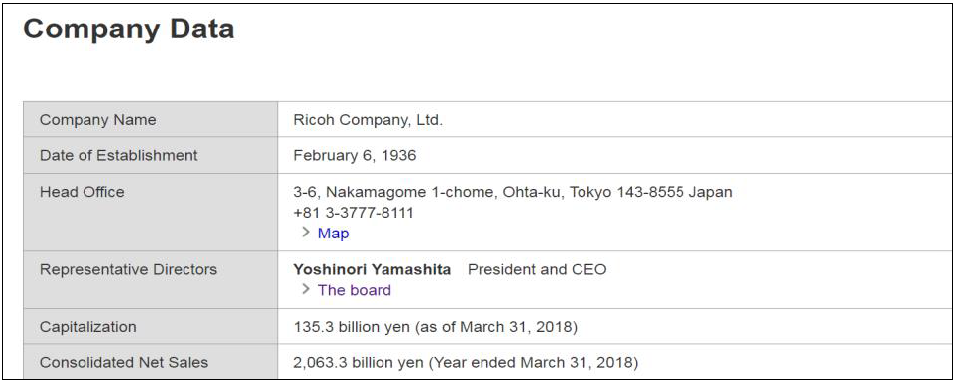
The company entity will be the subject of all the relations and can be omitted, in this case, the relations can be represented as (relation, object). Take Fig. 1 for example, there will be some relations such as (Date of Establishment, "February 6, 1936"), (Representative Director, "Yoshinori Yamashita") and (Capitalization, "135.3 billion yen").
However, building knowledge graph from webpages is not easy.
However, building knowledge graph from webpages is not easy. There are two main problems:
There are always various representations for one relation. For example, the relation "Date of Establishment" on a company website may be presented as "Date of Establishment", "establishment date", "establishment day", "Date of Company Established" and "Found date". It is hard to find all the possible descriptions.
There are always various templates to generate relation (relation, object) among different websites thus makes the structure or layout, differ from website to website. Take the "Required Education" of the company jobs for example, the XPath On the website (www.careerbuilder.com) is: "/html/body/table/tbody/tr/td/table/tbody/tr[2]/td/table/tbody/tr[8]/td[1]”. While it is “/html/body/div[1]/div[2]/div[1]/div[4]/div[1]/div/dl/dt”on another website (www.monster.com).
Furthermore, the templates will change due to website revisions. Even in the webpages generated from the same template, the pages may differ due to the missing fields, varying numbers of instances and conditional formatting. All these problems make the relation extraction much difficult.
The conversional relation extraction methods learn extraction patterns from manual annotations [6,24,26,27,32,33]. The manual annotation is an expensive and time-consuming step.
The CERES system [24] uses an entity-linking step in the annotation process to identify detailed page topic entities, followed by a clustering process to identify the areas of pages corresponding to each relation.
This method can compete with annotation-based techniques in the literature. This paper presents a novel semi-automatic knowledge graph construction method with relation pattern extraction using similarity learning. The knowledge graph is building from structured web page. Each web page is presented as a DOM Tree [34], the sample (relation, object) is presented as tag sequence of the XPath. The vector of the (relation, object) pair is gotten from the embedding method and feed to the Siamese network to learn a similarity metric. The relation pattern is built from the seed instance and be continually optimized by iterative steps.
The knowledge graph can be built in a semiautomatic way. Given some instances of the relations for an entity, the system build the relation patterns and find more relation instances by the similarity metric. The new relation instances are also used to refine the existing relation patterns. The system can also find new relations by clustering method using the learned similarity metric. For example, to build a knowledge graph for enterprise, the system only need some instances for the existing relations ("Date of Establishment", "Capitalization", "address", "website" and so on), the system builds pattern for each relation and extracts information from web pages. The system find more relation instances from web pages and refine the relation patterns.
By using the similarity metric learnt from relation instances and the clustering approach, the system can find new relations such as "slogan" and build pattern for it.
The main contributions of this paper are listed as following:
A method is proposed that using tag sequence and its embedding to build the relation patterns.
The relation extraction pattern similarity is learnt from the tag sequence of seed instances by using a Siamese network. The relation patterns can achieve self-improvement by finding more and more instances using the similarity metric.
The proposed method can also be used to detect the new relations and build the extraction patterns for the new relations.
The rest of this paper is organized as follows. Section 2 presents the knowledge graph building method using pattern similarity based relation extraction. Section 3 shows the experimental results. Section 4 gives several conclusions and future works.
2 Method Introduction
There are several steps in our system:
Make the representation for the relation instances.
Learn the similarity between tag sequences.
Build extraction patterns from seed instances.
Refine the extraction patterns with new instances.
2.1 Representation of the Input Relation Instances
The inputs of this system are two relation instances from the webpages. The relation (R) and object (O) of each relation instance (R, O) will be embedded in a tag sequence of XPath like this:
<tagR1> <tagR2> … … <tagRm> R <tagO1> <tagO2> ... <tagOn> O
This tag sequence will be used to present the relation instance.
Take the "Capitalization' relation as example, the relation instance is (Capitalization, 135.3 billion yen) and the XPath for these two nodes are:
/html/body/table/tbody/tr/td/table/tbody/tr[2]/td/table/tbody/tr[8]/td[1] Capitalization
/html/body/table/tbody/tr/td/table/tbody/tr[2]/td/table/tbody/tr[8]/td[2] 135.3 billion yen
This relation instance is represented as a tag sequence:
( <html> <body> <table> <tbody> <tr> <td>
<table> <tbody> <tr[2]> <td> <table> <tbody>
<tr[8]> <td[1]> Capitalization <html> <body>
<table> <tbody> <tr> <td> <table> <tbody> <tr[2]>
<td> <table> <tbody> <tr[8]> <td[2]> 135.3
billion yen)
This tag sequence presents the layout information on the web page.
The idea of this paper is to learn the similarity between relation instances and build the relation pattern using the similarity. It is hard to give the similarity of the relation instances pair, but it is easy to give the label that whether these two relation instances belong to the same relation or not. In our system, we use '0' to indicate the same relation and '1' for different relations.
For example, if we have another relation instance (capital fund, $202.5 billion) and the tag sequence:
( <html> <body> <div[1]> <div[2]> <div[1]>
<div[4] > <div[1]> <div> <dl> <dt[6] capital fund
<html> <body> <div[1]> <div[2]> <div[1]> <div[4]>
<div[1]> <div> <dl> <dd[7]> $202.5 billion)
When we put these two tag sequences to the system, we also should give the label '0' (same relation). It is a training instance for the system.
2.2 The Siamese Network for Sequence Similarity Calculation
The first step of this method is the tag sequence embedding. That is to make a vector for the input tag sequence so that similar tag sequences or tag sequence used in a similar context are close to each other in the vector space. In the free text analysis field, the word embedding is widely used, particularly in deep learning applications.
The word embeddings are a set of feature engineering techniques that transform sparse vector representations of words into a dense, continuous vector space, enabling system to identify similarities between words and phrases based on their context.
In this paper, we adopt the word embedding approach [35,36] and trained a Skip-Gram word2vec model from the intermediate result of DOM tree parsing. In Fig. 2, the X11, X12, … , and X1n are tags for the first tag sequence and the X21 , X22, … , and X2n for the second tag sequence. They will be convert into vectors through the embedding component. After that, these tag embeddings are combined into one vector as the embedding of the tag sequence. There are several ways to combine the tag embeddings. In this paper, we chose the concatenation operation due to experimental results. The concatenation operation is to concatenate the vectors of each tag one by one to make a big vector. Say, if we have 10 tag vectors and each vector has the dimension 128, then the concatenation vector will has the dimension 1280.
The vectors of the tag sequence are put into the feature map layers. The feature maps layer converts the tag sequence into a target space such that a simple distance in the target space approximates the "semantic" distance in the input space. Since the two feature maps layer share the same parameter W, this can be consider as the Siamese architecture [37,38]. This network is suitable for recognition or verification applications where the number of categories is very large and not known during training.
Given a family of functions Gw(x) parameterized by W, the method seeks to find a W such that the similarity metric
In the training stage, let Y be a binary label of the pair, Y=0 if the X1 and X2 belong to the same relation (genuine pair) and Y=1 otherwise (impostor pair). Let W be the shared parameter vector that is subject to learning, and let Gw(X1) and Gw(X2) be the two points in the low-dimensional space that are generated by mapping and X1 and X2. Then our system use the Ew(X1, X2) to measures the similarity between X1 and X2.
It is defined as
where (Y, X1, X2)i is the i-th sample, which is composed of a pair of samples and a label, LG is the partial loss function for a genuine pair, LI the partial loss function for an impostor pair, and P the number of training samples. LG and LI should be designed in such a way that minimization of L will decrease the energy of genuine pairs and increase the energy of impostor pairs. A simple way to achieve that is to make LG monotonically increasing, and LI monotonically decreasing. In this paper, the LG and LI are:
Here the Q is a constant and is set to the upper bound of Ew. The Ew is the similarity metric which learned by the Siamese network, it is in the range [0, 1].
2.3 Relation Patterns Building and Refining
Once we have learnt the similarity metric, we can use it to calculate the similarity of two input tag sequences. The tag sequence pair with similarity bigger than a given threshold can be used to build the same relation pattern. That means that, if we have some seed instances, we can use them and the similarity metric to find more similar instances. And build the relation patterns from these instances.
How to build the relation pattern using the instances? There are several ways to do this. In the rule scenario, we can deduce the regular expression from the detected relation instances and use it as the relation pattern. In this paper, we use the centroid point as the relation pattern.
The key technique of this system is the similarity learning method. With the similarity metric, we can collect more and more relation instances and then build better extraction pattern. Iteratively, the extraction pattern is used to find more relation instances.
The experimental results in Session 3 shows the performance of our similarity learning method. For example, in the "Capitalization" scenario, we have the instance:
(<html> <body> <table> <tbody> <tr> <td>
<table> <tbody> <tr[2]> <td> <table> <tbody>
<tr[8]> <td[1]> Capitalization <html> <body>
<table> <tbody> <tr> <td> <table> <tbody> <tr[2]>
<td> <table> <tbody> <tr[8]> <td[2]> 135.3
billion yen)
and
(<html> <body> <div[1]> <div[2]> <div[1]>
<div[4] > <div[1]> <div> <dl> <dt[6] capital fund
<html> <body> <div[1]> <div[2]> <div[1]> <div[4]>
<div[1]> <div> <dl> <dd[7]> $202.5 billion).
After some iterations, we find some new tag sequence belong to the "Capitalization" relation, say:
(<html> <body> <div[1]> <div[3]> <div[2]>
<div> <div[7]> <div[1]> capital amount <html>
<body> <div[1]> <div[3]> <div[2]> <div> <div[7]>
<div[2] US$65,000,000).
These new tag sequences are put into the collection of the "Capitalization" relation and used to update the relation pattern. Then the updated relation pattern is used to collect new relation instances. This method can also be used to detect the patterns for new relations. For example, if we already have some relations about the job such as the "Date of Establishment", "Capitalization", "address" and "website". The proposed system may get some relation instances clusters using clustering method. There may be cluster for a new relation, say, "Number of Employees". Here are the relation instances for this new relation:
( <html> <body> <div[1]> <div> <div> <div[2]>
<div[2]> <div[1]> <div[1]> <dl[4]> <dt> Number of
Employees <html> <body> <div[1]> <div> <div>
<div[2]> <div[2]> <div[1]> <div[1]> <dl[4]>
<dd> 98,868).
(<html> <body> <div[2]> <div> <dl[10]> <dt>
Staff number <html> <body> <div[2]> <div>
<dl[10]> <dd> 1,678).
The relation name is different ("Number of Employees" and "Staff number') and the format of the object is different also. They should be put into one cluster using the clustering method.
3 Experiments
3.1 Data Set
We built a knowledge graph for enterprise using the proposed method. Firstly, we got a collection of websites about Japanese companies by search engine. Start from some manually labeled instances, we built a knowledge graph which contains 2,717,653 company entities and 22,257,276 triples. To show the performance of our method. We conducted a set of experiments, which use part of the data. We selected 10 relations to train the pattern similarity learning model. The instance number of each relation are shown in the Table 1.
3.2 Experimental Results
The evaluation metric for similarity are:
— FA (False Accept Rate, the percentage of impostor pairs accepted),
— FR (False Reject Rate, the percentage of genuine pairs rejected),
— EER (Equal Error Rate, the point where FA equals FR).
To train and evaluate the similarity module, we need to build a set of tag sequence pairs, including genuine pairs and impostor pairs. There are 10 relations and total 286,276 instances. If we random select 1000 instances from each relation, we can build 9,999,000 genuine pairs and 90,000,000 impostor pairs.
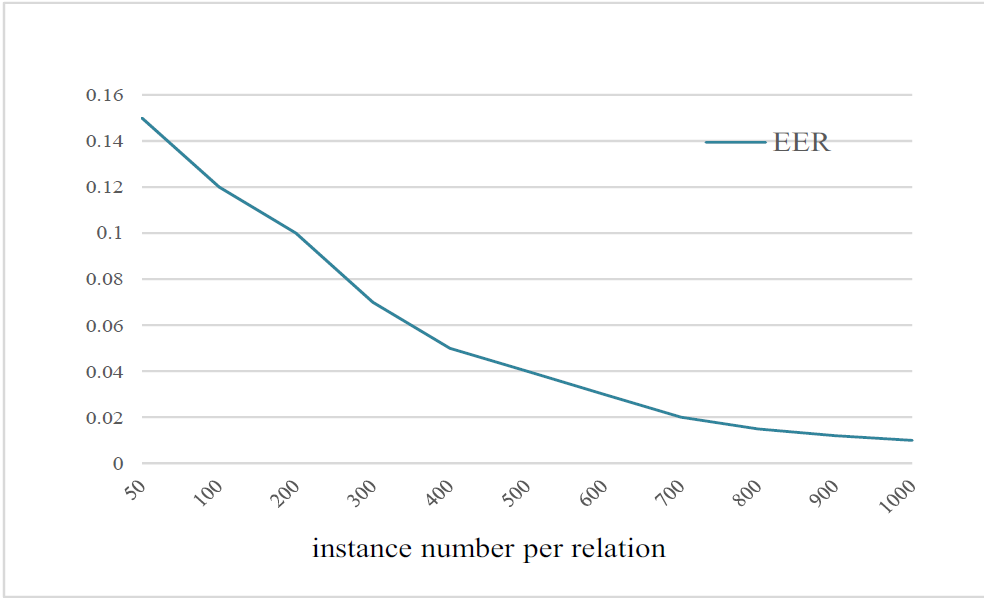
Table 2 shows the experimental results of similarity learning, the system get EER 0.01 using the 10,000 instances (1,000 instances per relation). The iteration steps is about 500 to get the performance. The Fig. 3 shows the EER at different instance number. We can see that the more instances, the better performance. It trends to convergence when the instances number of each relation is about 1000.
Table 2 Experimental Results of Similarity Learning
| Instance number |
Iteration steps |
EER |
|---|---|---|
| 10,000 | 100 | 0.04 |
| 10,000 | 500 | 0.01 |
The main scenario for the proposed method is to find new patterns and new relations. To evaluate the performance, we conduct experiments on unseen dataset. The unseen dataset means the test data are separated from the training data. In the enterprise knowledge graph case, we train the model on the some relations and test on the dataset with other relations.
More concretely, we train the model on the previous 10 relations (name, address, person, homepage, phone number, rel-org, finance, size, date, and product). Then we test this model on the dataset with different relations (say, fax, email, Permission, Introduction, domain, office) shown on table 3. We find the optimal threshold on the valid dataset and use the threshold to get the FA and FR on test dataset. The EER is gotten from test dataset. The system got EER 0.05 on the unseen datasets. This enable the new patterns and relations find procedure.
Table 3 The unseen dataset
| Relation | Number of instance |
|---|---|
| Fax | 5,911 |
| 3,586 | |
| permission | 2,645 |
| introduction | 4,436 |
| domains | 13,347 |
| offices | 11,145 |
In the scenarios that finding the new relations and getting the patterns, the clustering approach is adopted to put the similar instances into same group. To evaluate the new relation detection performance. We adopt the following steps and use the precision and recall metrics:
Input test data of k (for example, k=6) categories.
Clustering, output k clusters.
Assign label for data in each cluster.
Compare the assigned labels with the true labels.
-
Using precision and recall (by Table 4) to evaluate the performance:
Precision = TP/(TP+FP),
Recall = TP /(TP+FN).
Table 4 The metric for evaluated the clustering results
| Clustering labels | |||
|---|---|---|---|
| Y | N | ||
| True Label | P | True Positives (TP) | False Negatives (FN) |
| N | False Positives (FP) | True Negatives (TN) | |
Two clustering methods (Hierarchy and K-Means) are evaluated. The experiments results shown in Table 5. From this table, we can see that K-Means got better results than hierarchy clustering method. It can be used to find the new relations.
Table 5 The clustering experimental results
| Precision | Recall | ||
|---|---|---|---|
| Hierarchy Clustering |
Fax | 0.6976 | 0.775 |
| 0.7847 | 0.758 | ||
| Permission | 0.733 | 0.675 | |
| Introduction | 0.9973 | 0.366 | |
| Domains | 0.5903 | 1.00 | |
| Office | 0.9915 | 0.931 | |
| K-Means Clustering |
Fax | 0.7284 | 0.912 |
| 0.9134 | 0.77 | ||
| Permission | 0.7414 | 0.671 | |
| Introduction | 0.9989 | 0.882 | |
| Domains | 0.8503 | 1.00 | |
| Office | 0.9883 | 0.93 | |
4 Conclusion
This paper presents a new semi-automatic knowledge graph construction method by relation pattern extraction. The proposed method uses tag sequence to build the relation pattern.
A Siamese network is adopted to learn the similarity metric from the tag sequences. The proposed method builds the relation patterns and continually refines those patterns by finding more and more samples using the similarity metric.
It can also be used to detect patterns for the new relations. The future work includes finding new representation of the relation patterns and give the labels for new relations automatically.

