











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Human-machine communication is in full progress, thus facilitating the accessibility to information and its treatments by introducing new faster methods to access information like voice commands. Nonetheless, the dialectal variability can prevent much understanding of the vocal command. In order to assist interactive systems in the comprehension of transmitted messages, several studies addressing the Arabic dialect identification have been established.
The Arabic dialect identification has become the central task for most applications of Arabic speech processing, such as machine translation, speech recognition or social media analysis. In accordance with Zaidan et al. [1], dialect identification can be seen as an application of language identification applied to a group of closely related languages.
The literature contains recent work that has proposed statistical approaches for Arabic dialect identification. However, current methods are often based on linguistic resources (corpora, lexicon, dictionaries), which does not always exist, especially for Maghrebi Arabic. For this reason, we propose a combination between linguistic and numerical methods to identify the dialectal origin for each input audio signal. The sample of dialects covers Tunisian, Algerian, Moroccan, Syrian, Palestinian and Egyptian.
This paper is structured as follows. The different dialects of spoken Arabic language are briefly described in section 2. In section 3, we expose some work from the literature addressing the Arabic dialect identification. The proposed methodology is detailed in section 4. The details about the experiments are described in section 5. The concluding remarks and future work are mentioned in section 6.
2 Dialectical Variability
The speakers of the Arabic language use in their daily discourses various dialects that can be considered as alternatives of the Modern Standard Arabic (MSA). Tunisian, Algerian and Moroccan dialects share several phonological traits among themselves thanks to their common history. Their lexicon contains several pronunciations inherited from other languages like Berber, French, Turkish, Italian and Spanish. Also, Syrian, Palestinian and Egyptian dialects share a lot of phonological features. In the following sub-sections, we briefly describe these dialects.
2.1 Tunisian Dialect
Similar to other Maghrebi dialects, Tunisian vocabulary is generally Arabic, with some Berber words. However, it is morphologically and phonologically different from the MSA. The Tunisian dialect is very agglutinative: Speakers use often very few words where just one expresses a whole sentence. It differs from the MSA especially in its negation form where the markers are always agglutinated to other words as affixes or suffixes. Moreover, in the Tunisian dialect, several Arabic words are used with significant changes in their stem formation.
2.2 Algerian Dialect
The Algerian dialect is an informal spoken language, not used in official speech. Its vocabulary is roughly similar throughout Algeria. Nevertheless, in the east of the country, the dialect is closer to the Tunisian one whereas in the west it is closer to the Moroccan one. Most of the words of Algerian dialect come from the MSA [2], but there is a significant variation in vocalization in most cases, and some omission of some sounds in other cases. Contrary to the MSA, few sounds are not used in Algerian discourses like ظ and ذ, where most of the time they are respectively pronounced as ض and د. Furthermore, the Algerian dialect uses some non-Arabic sounds like ڤ and پ.
2.3 Moroccan Dialect
The Moroccan dialect or the Moroccan Darija is a member of the Maghrebi Arabic language continuum spoken in Morocco.
It is mutually intelligible to some extent with the Algerian dialect and to a lesser extent with Tunisian one. It has been significantly influenced by other vocabulary like Berber, Latin, French and Spanish.
2.4 Egyptian Dialect
The Egyptian Arabic is a North African dialect of the Arabic language, which is a branch of the Afro-Asiatic language. It originated in the Nile in Lower Egypt around the capital Cairo. Egyptian Arabic evolved from the Quranic Arabic, which was brought to Egypt during the seventh-century Muslim conquest that aimed to spread the Islamic faith among the Egyptians. The Egyptian dialect was very highly influenced by the Coptic language, which was the native language of the Egyptians prior to the Arab conquest [3], and later it was significantly influenced by other languages such as French, Italian, Turkish and English.
2.5 Syrian and Palestinian Dialects
The Syrian and Palestinian dialects are part of Levantine Spoken Arabic, which covers also Lebanese and Jordanian dialects. Phonologically, structurally and lexically, we can mention several common features between Levantine Arabic and other varieties of Arabic. On the other hand, there are significant differences among Levantine dialects based on geographical areas and urban/rural division. The Syrian dialect is highly influenced by the Syrian language, a Semitic language of the Middle East, which belongs to the Aramaean language group and contains a large vocabulary inherited from Turkish and French languages. The Palestinian dialect presents phonetically slightly different compared to north Levantine dialects. It can follow two main varieties: urban and countryside. It can be also classified geographically into north and south.
3 State of the Art
The literature has presented multiple studies addressing dialect identification. In such work, researchers have tried to develop new platforms whose goal has been to associate the adequate dialect to each input acoustic signal. We can mention the following:
- In the objective of identifying Arabic and Chinese dialects, Zhang et al. recommended a novel study based on the frequency of common n-grams. The main idea is to classify the input acoustic signal in the class, which maximizes the number of n-grams compared to a reference acoustic base. It is the target of the work in [5]. Compared to the existing systems, the obtained results showed a strong correlation between dialect-salience and the frequency of occurrences in n-grams.
- To identify Jordanian and Egyptian dialects, Al-Ayyoub et al. invented in [6] a novel methodology based on the combination between different numerical and linguistic audio techniques. Through this study, the authors put forward a new solution to the problem of dialect identification and determined as well the combination of features/classifiers that would generate the best results. Based on a large corpus of Jordanian and Egyptian dialects, the suggested system showed a good performance.
- In [7], Guellil et al. proposed an unsupervised approach to identify the Algerian dialect within social media. In order to do so, the authors used a large Algerian dialectal lexicon. The proposition was based on the improved Levenshtein distance [11, 12]. Supporting a corpus of 100 messages that were collected using the Facebook API, the authors obtained an identification rate exceeding 60%.
- Based on the naive Bayesian algorithm and a transfer system, Hamada et al. put forward in [4] a novel study addressing the identification of the Egyptian dialect from text messages that circulated on social networks and generated the corresponding MSA representation. Using 3,000 words presenting the Egyptian dialect, the authors attained an identification rate, which exceeded 92%.
In spite of the richness of the literature with studies addressing Arabic dialect identification, the intra-dialect variability presents a motivation to propose new robust features and new measures of similarity. Our contribution consists, for each input acoustic signal, in introducing a new methodology whose target is to calculate its similarity compared to referenced dialectal bases.
4 Methodology
The goal of this paper is to assign each input acoustic signal to an adequate Arabic dialect. The main idea consists in comparing between the phonetic model representing the input acoustic signal and the referenced models of different Arabic dialects. In accordance with the results of this comparison, we assign the input acoustic signal to the class which minimizes the cosine similarity. Figure 1 describes the operation of the proposed system:

4.1 Acoustic Modeling
The generation of phonetic models referenced to Arabic dialects requires an acoustic model trained to different spoken Arabic varieties and a large base of dialectical speeches. The speech base must be recorded by native speakers and cover all dialectical variabilities. The following table (Table 1) summarizes the corpora used to train our acoustic model.
Table 1 Summary of base of speeches used to train the acoustic model
| Objective | Speech bases and sizes | ||
|---|---|---|---|
| 77 minutes of dialectical Tunisian speeches | 388 minutes | ||
| 57 minutes of dialectical Algerian speeches | |||
| Training an acoustic model for dialectical Arabic language | 66 minutes of dialectical Moroccan speeches | ||
| 62 minutes of dialectical Syrian speeches | |||
| 70 minutes of dialectical Palestinian speeches | |||
| 56 minutes of dialectical Egyptian speeches | |||
4.2 Forced Alignment
Supporting the Sphinx_align tool, we make the forced alignment procedure that allows generating for each speech signal the suitable phonetic transcription. For this treatment, it is sufficient to give this tool the paths to the necessary data, which are the voiced signals in the MFCC format, the suitable phonetic transcriptions, the pronunciation dictionary and the acoustic model. The obtained phonetic transcription (previous sub-section) will be decomposed by bi-phonemes and the probability of occurrence for each bi-phoneme will be calculated. The vector arranging all these probabilities forms the phonetic model referenced to the dialect covered by the input speeches.
Table 2 gives details about the base of speeches used to generate dialectic phonetic models.
Table 2 Summary of base of speeches used to calculate dialectical phonetic models
| Objective | Speech bases and sizes | |
|---|---|---|
| Calculating dialectical phonetic models | 88 minutes of dialectical Tunisian speeches | 413 minutes |
| 67 minutes of dialectical Algerian speeches | ||
| 78 minutes of dialectical Moroccan speeches | ||
| 51 minutes of dialectical Syrian speeches | ||
| 58 minutes of dialectical Palestinian speeches | ||
| 71 minutes of dialectical Egyptian speeches | ||
We must guarantee a correlation between all phonetic models in the presentation and in the order of bi-phonemes. For example, the Algerian dialect includes the phonemes “ڤ” and “پ”, which is not the case for other Arabic dialects, so all models must comprise bi-phonemes containing these phonemes in the same order compared to the phonetic model referenced to the Algerian dialect.
Figure 3 illustrates an extract from the phonetic model referenced to the Tunisian dialect.


For each new speech (S), to be associated to a suitable dialect, we transform this acoustic signal to its phonetic form (phonetic model), following the same procedure in section 4.2. We calculate, thereafter, all angles θS,i (i=1, …, 6) which separate this model for each one of the dialectical sample studied in this paper (Tn: Tunisian, Al: Algerian, Mr: Moroccan, Sy: Syrian, Pl: Palestinian and Eg: Egyptian). Finally, the input speech will be assigned to the dialect that minimizes the angle of similarity.
For example, a speech sequence S is associated to an appropriate dialectical class as follows:
- We calculate Ɵ = {θS,Tn, θS,Al, θS,Mr, θS,Sy, θS,Pl, θS,Eg} is the set of all phonetic similarity distances between the input speech sequence and all other spoken Arabic varieties.
- We suppose Min(Ɵ) is the minimum of the set Ɵ.
- The dialect which verifies the Min(Ɵ) is the most adequate to the input speech sequence.
The calculation of the set Ɵ is based on the following scalar product formulas:
where
5 Tests and Results
5.1 Test Conditions
The test is done under the following conditions:
- We prepare an acoustic model trained to dialectical Arabic speeches. For this objective we utilize a voice corpus of 388 minutes of Arabic speech which covers Tunisian, Algerian, Moroccan, Syrian, Palestinian and Egyptian dialects ( on *.wav format and in mono speaker mode).
- We calculate six phonetic models, one for each Arabic dialect covered by this study. We use, for this goal, an acoustic base containing 413 minutes of Arabic dialectical speeches (on *.wav format and in mono speaker mode).
- We test the performance of the suggested method based on 117 speech sequences recorded by native speakers, which covers all the studied Arabic spoken varieties in this paper. All records follow the *.wav format and the mono speaker mode. The repartition of the test base is as follows:
5.2 Experimental Results
In this section, we are interested in measuring the similarity between each pair of Arabic dialects through phonetic models that reference different Arabic spoken varieties. For this purpose, we choose to use the cosine similarity [8, 9], a measure of correlation between documents. It quantifies the similarity between two phonetic models. The choice of this metric is justified by its performance guaranteed in the document comparison [10].
The following table (Table 4) illustrates the results of dialectical speech classification and describes the confusion rate inter-dialects. Figure 4 details the performance of our proposed approach for each Arabic dialect.
Table 3 Summary of base of speeches used to evaluate proposed methodology
| Objective | Utilized test base | |
|---|---|---|
| Testing proposed methodology | 26 sequences of dialectical Tunisian speeches | 117 sequences |
| 21 sequences of dialectical Algerian speeches | ||
| 15 sequences of dialectical Moroccan speeches | ||
| 17 sequences of dialectical Syrian speeches | ||
| 22 sequences of dialectical Palestinian speeches | ||
| 16 sequences of dialectical Egyptian speeches | ||
Table 4 Classification results using proposed method
| Test bases | Classification results | |||||
|---|---|---|---|---|---|---|
| Tn | Al | Mr | Sy | Pl | Eg | |
| Tn | 92.30% | 0% | 7.69% | 0% | 0% | 0% |
| Al | 0% | 95.23% | 4.76% | 0% | 0% | 0% |
| Mr | 0% | 6.66% | 93.33% | 0% | 0% | 0% |
| Sy | 0% | 0% | 0% | 94.11% | 5.88% | 0% |
| Pl | 0% | 0% | 0% | 9.09% | 90.90% | 0% |
| Eg | 0% | 0% | 0% | 0% | 6.25% | 93.75% |
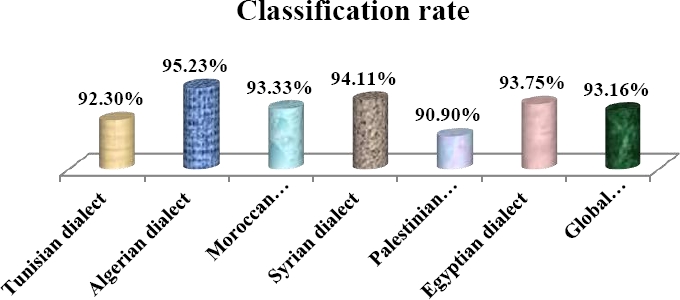
5.3 Discussion
Table 4 draws some confusions between Arabic dialects. It is clearly shown that the highest confusion rates are those between Algerian and Moroccan and between Palestinian and Syrian dialects. This confusion is justified by the closeness between these pairs of dialects; e.g., Palestinian and Syrian dialects share significant vocabulary.
Some misclassification speech sequences can be justified by the shortness of the acoustic signal. Indeed, the dialectical speech sequence to be classified is short. Probably, the phonetic model does not cover all possible bi-phonemes, so the similarity with the referenced phonetic model will be falsified. Pathological speech may also result in misclassification [15, 16, 17].
6 Conclusions and Future Work
To conclude, we can mention that the comparison between phonetic models presents a deciding factor to classify Arabic dialectical speeches. In this paper, we have put forward a probabilistic-phonetic methodology to assign each input acoustic signal to a suitable Arabic dialect. For this purpose, a corpus of 413 minutes of Arabic dialectical speeches has been prepared to calculate the phonetic models referring to the different spoken Arabic dialects. Another corpus containing 388 minutes of Arabic speeches covering six Arabic dialects has been recorded to train the acoustic model.
Based on 117 speech sequences, our proposed method has presented a high performance. Indeed, we have had 93% as a classification rate of Arabic dialects and we have extracted some confusion inter-dialects that confirm the closeness between these dialects.
To the best of our knowledge, this work presents the widest dialectical coverage. We are satisfied with the obtained results, and our suggested approach can present an important reference for work focalizing on the classification of dialectical speeches.
As future work, we can extend this study to elaborate a new platform whose goal is to transform an input acoustic signal from the dialectical form to its adequate one in MSA [13, 14]. Indexing the spoken content can also benefit from our methodology [18].

