











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
In Community Question and Answering (CQA) services (Yahoo Answers1, StackOverflow2), users can post new questions and answer existing questions. Four main problems in CQA are [10]: (1) finding similar questions given a new question, (2) finding answers given a new question, (3) measuring answer quality and its effect on question retrieval, and (4) finding experts in a community. Our task of summarizing answers posits in the third problem.
Among the answers, question owner selects one or several ones as best answer(s). 48% questions have a unique answer [10]. Best answers could be incomplete, particularly for complex questions or non-factoid questions (against factoid questions which requires concise facts). This raises the need for answer summarization in CQA. Researchers have been using text summarization techniques for summarizing factoid, non-factoid, as well as multi-sentence and complex questions [19, 17, 2].
This work focuses on using unsupervised sentence representation to tackle answer summarization in non-factoid CQA. Two neural models including deep Auto-Encoder (AE) and Long-short-term-memory Auto-Encoder (LSTM-AE) [5, 8] are explored to capture semantic and syntactic information and generate low-dimensional vectors, which are later used for measuring sentence similarity.
We aim at tackling three main challenges: sparsity, diversity, and genre adaptation. Neural embeddings help overcome sparsity of short texts (i.e. questions and answer sentences in this work). The Maximal Marginal Relevance (MMR) algorithm [1] balances question relevance and summary diversity. Last but not least, representations based on Yahoo-Webscope are expected to be more suitable for CQA.
The rest of the paper is organized as follows. Related works are discussed in Section 2. Section 3 is dedicated to our method for answer summarization. Experiments are presented in Section 4. Finally, Section 5 concludes the paper.
2 Related Work
Techniques in text summarization have been applied to answer summarization in question-answering [19]. Liu applied clustering on open questions and opinion questions [10]. Tomasoni exploited metadata and proposed concept scoring functions based on semantic overlap [18]. Other approaches aimed at solving the optimization problem for selecting a subset of sentences that maximizes an objective function under length constraint.
Integer linear programming was successfully applied to summarize answers in CQA [18]. Chan proposed using Conditional Random Fields to deal with the incomplete answer problem and complex multi-sentence questions. The author showed a systematic way to model semantic contextual interactions between answer sentences, based on question segmentation; Both textual and non-textual features were explored [2].
Researchers have been developing techniques to learn neural text embeddings [5, 11, 7, 4, 13, 16]. Auto-encoder was applied to query-oriented single-document summarization [20]. In another direction, sequence-to-sequence architecture was applied to abstractive summarization [12, 15, 3]. The most related works to ours on answer summarization in non-factoid CQA were presented in [14, 17], using sentence vectors generated from Paragraph Vector [7] and Convolutional Neural Network (CNN), in that order.
3 Sentence Embeddings for Answer Summarization
The proposed answer summarization framework is demonstrated in Fig. 1. Given a pair of question q and its answers {Ai}, answer sentences are first extracted to generate of a set of sentences {Si}. The sentence representation block uses Yahoo-Webscope to learn models and to generate low-dimensional vectors q′ and {xi} for q and {Si}, respectively. MMR algorithm takes q′ and {xi} as inputs and generates an answer summary.
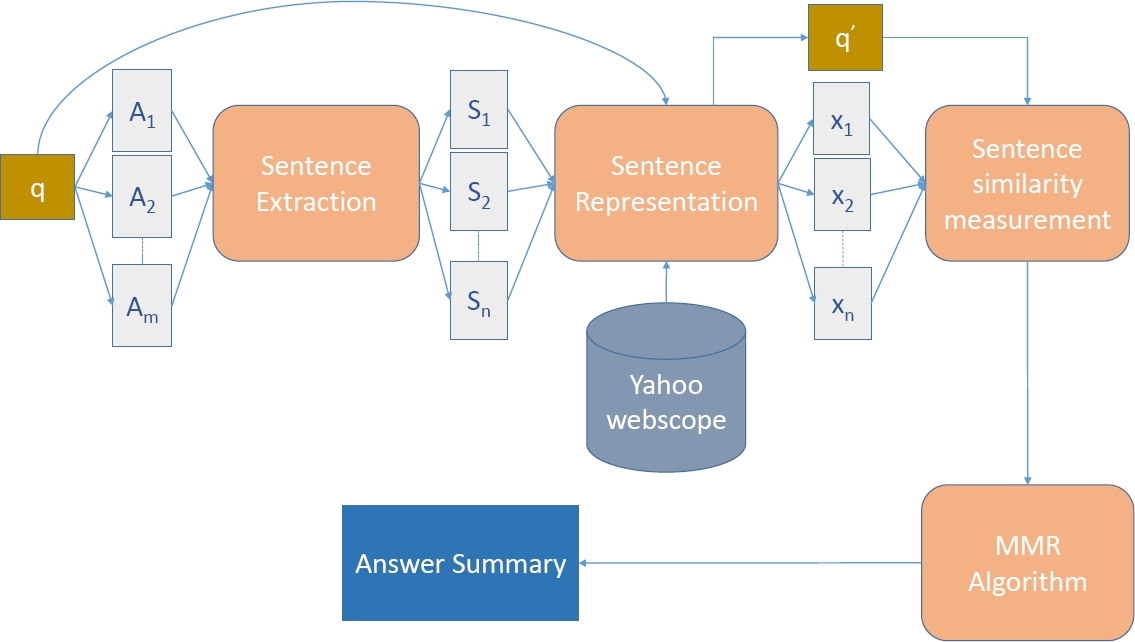
3.1 Sentence Representation
Neural networks are effective in representing semantic and syntactic information of sentences in low-dimensional vectors. This paper investigates two unsupervised neural models, i.e. Deep Auto-Encoder and Long Short-Term Memory (LSTM) Auto-Encoder [8] for sentence representation.
3.1.1 Deep Auto-Encoder
An Auto-Encoder neural network is a generative model that aims at reconstructing its own inputs. Our deep Auto-Encoder model is introduced in Fig. 2. It has four encoding layers:
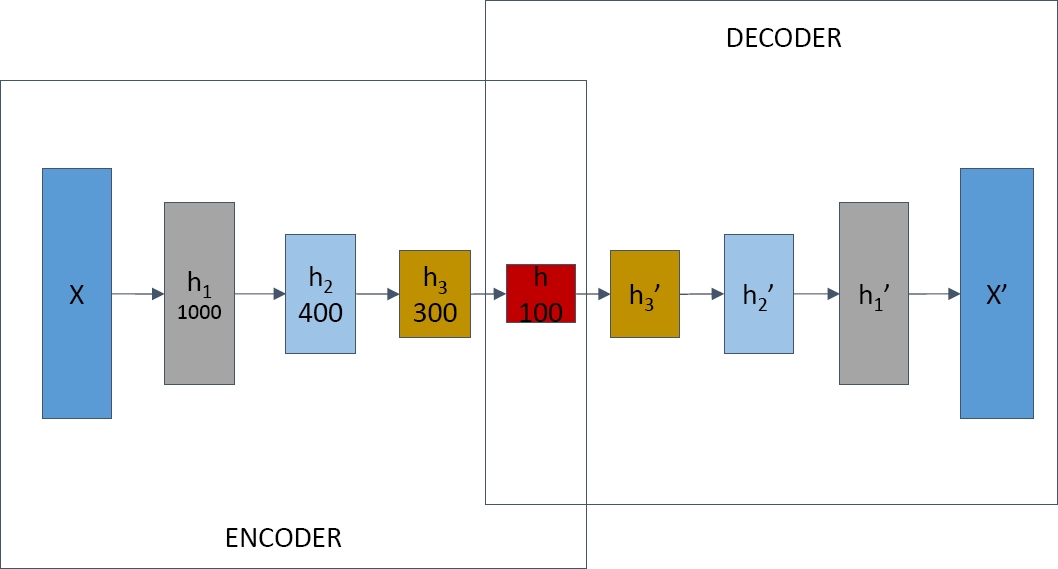
A sentence X is put into the network with tf-idf weights. X is very sparse because it only contains a small number of words while its dimension is the size of vocabulary. The Auto-Encoder can learn a distributed semantic representation with low dimension. The layer h is used for sentence representation. Decoding layers are:
where sigmoid function is:
The squared error loss is:
where V is vocabulary size.
3.1.2 LSTM Auto-Encoder
Deep Auto-Encoder doesn’t capture syntactic information in word order. We propose using LSTM Auto-encoder (Fig. 3), which was first introduced in [8]. This model learns sentence in an unsupervised manner and captures both syntactic information in word order and semantic information in word embeddings:
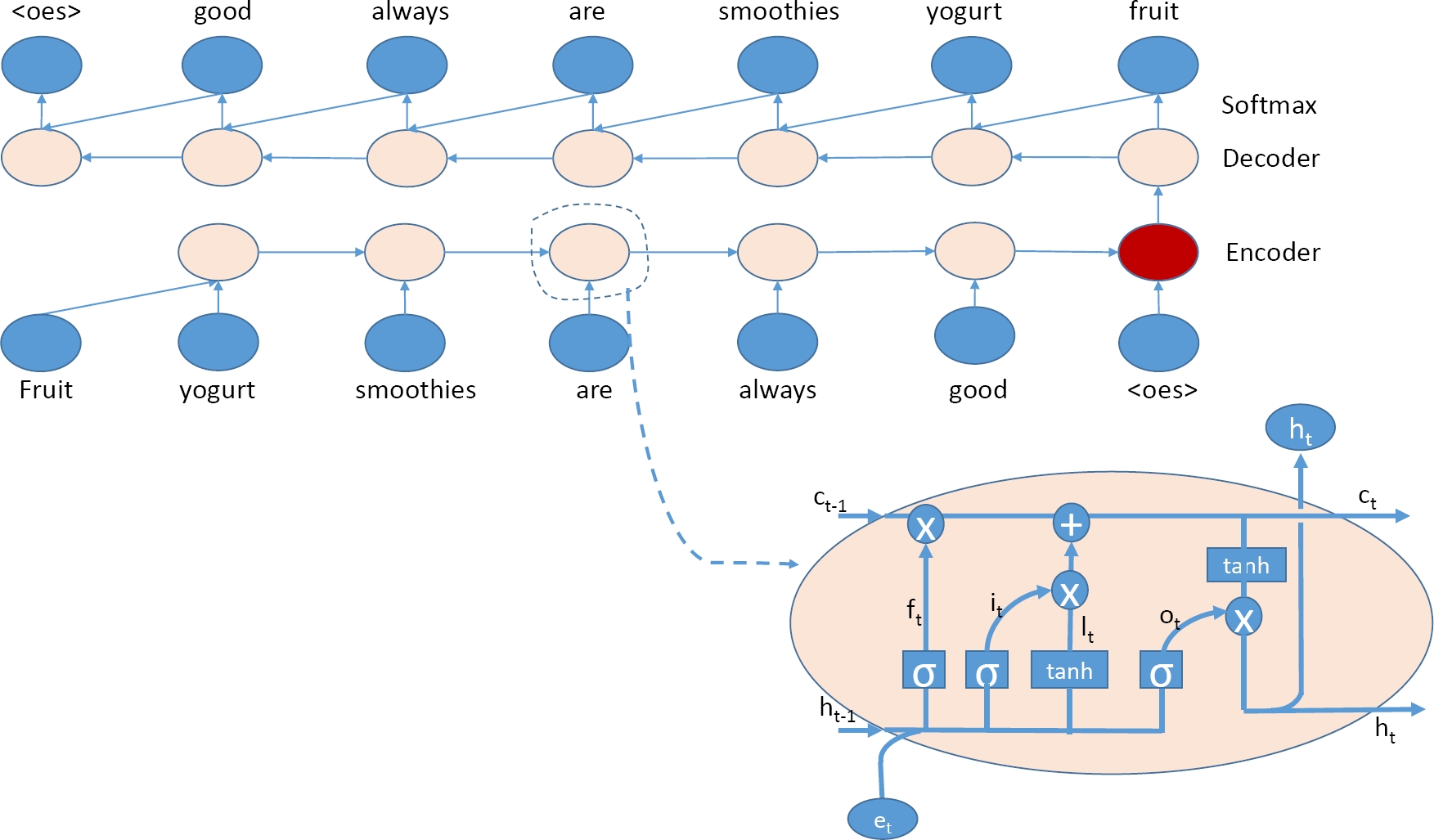
Fig. 3 Long-short-term-memory Auto-Encoder: The last encoding LSTM cell (the red node) is used for sentence representation
hends is used to present the input sentence
The decoder sequentially predicts sentence words using a softmax function:
et is an embedding for word at position t and generated by the LSTMdecode. The encoder and decoder use two different LSTMs with two different sets of parameters.
Our loss function:
where H is the Cross-entropy error function. The LSTM model at time t is defined as follows:
3.2 Extractive Summarization
MMR is applied to generative extractive summaries (Algorithm 1). It is a greedy algorithm which incrementally selects a sentence by maximizing a linear combination of query relevance and summary diversity (line 3). Here the hyper-parameter κ takes a value in [0, 1]. Sim(s, q) and sim(s, s′) are sentence similarity. q is the question. S is the set of all sentences in the answers. L is the limit length of a summary. R is the set of summary sentences.

Sentence similarity is computed by cosine similarity:
4 Evaluation
4.1 Datasets
L6 - Yahoo! Answers Comprehensive Questions and Answers corpus3 from Yahoo Webscope was used for unsupervised learning of sentence representation (Table 1).
Table 1 Yahoo Webscope corpus
| Statistics | Size |
|---|---|
| Questions | 87,390 |
| Answers | 314,446 |
| Answer sentences | 1,662,497 |
We used the test dataset in [17] for evaluation4. The dataset contains manual summaries with the limited length of 250 words. In our experiments, limited summary length was selected accordingly (L = 250 in MMR).
4.2 Experimental Setup
Each input sentence vector put into AE is represented using tf-idf. The vocabulary was created by lowercasing, removing the stopwords, rare words (below 10 times), stemming, and normalizing number. The auto-encoder has four layers for encoding, and four layers for decoding. Layer h with 100 dimensions is used to present sentence. Learning parameters for back propagation and Adam algorithm[6] were: learning rate η = 0.001; batch size = 128 sentences; 20 epochs. The model was trained on Yahoo-webscope in eight hours with a machine of 20 CPUs.
Word embeddings from word2vec5 on Google news of size 300 were fed into LSTM-AE. When a word was not in the vocabulary of pre-trained word embeddings, its embedding was sampled from a normal distribution. Commas, colons were converted to <dot>.
Periods, end marks were converted to <eos>. Learning parameters were: batch size of 128 sentences, 20 epochs, learning rate η = 0.001. It took three weeks with a machine of 20 CPUs to train this model on Yahoo-webscope. Both AE and LSTM-AE were implemented on Tensorflow.
4.3 Experimental Results
ROUGE metric [9] was used to evaluate text summarization. At first, the results of two baselines, tfidf and tf-idf weighted average word embeddings, are shown in Table 3. AE, LSTM-AE and a combination of AE and LSTM-AE by concatenating the two sentence embeddings (mentioned as CONCAT) are compared. The results are in Figure 4.
Table 2 Test dataset
| Statistics | Size |
|---|---|
| Non-factoid questions | 100 |
| Answers | 361 |
| Answer sentences | 2,793 |
| Words | 59,321 |
| Manual summaries | 275 |
| Avg. summaries per question | 2.75 |
Table 3 Evaluating two baselines
| Word2Vec | Tfidf | |||||
|---|---|---|---|---|---|---|
| κ | Rouge-1 | Rouge-2 | Rouge-L | Rouge-1 | Rouge-2 | Rouge-L |
| 0.1 | 0.621 | 0.529 | 0.607 | 0.532 | 0.282 | 0.464 |
| 0.2 | 0.619 | 0.524 | 0.606 | 0.531 | 0.282 | 0.463 |
| 0.3 | 0.618 | 0.523 | 0.605 | 0.532 | 0.281 | 0.464 |
| 0.4 | 0.615 | 0.518 | 0.600 | 0.530 | 0.279 | 0.467 |
| 0.5 | 0.622 | 0.525 | 0.604 | 0.529 | 0.279 | 0.464 |
| 0.6 | 0.614 | 0.513 | 0.605 | 0.528 | 0.278 | 0.467 |
| 0.7 | 0.610 | 0.507 | 0.607 | 0.529 | 0.280 | 0.489 |
| 0.8 | 0.609 | 0.504 | 0.610 | 0.530 | 0.285 | 0.488 |
| 0.9 | 0.611 | 0.505 | 0.603 | 0.532 | 0.288 | 0.488 |
| 1.0 | 0.608 | 0.501 | 0.601 | 0.532 | 0.289 | 0.489 |

As we only have the test dataset, experiments with different values of κ as the only hyper-parameter (of MMR) were conducted. LSTM-AE with κ = 0.3 was selected as our representative to compare with related works. Last but not least, with κ = 0.3, linear combination of AE and LSTM-AE similarities was investigated (Table 5):
where α is hyper-parameter.
Table 4 Comparison to state-of-the-art methods
| Method | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| BestAns | 0.473 | 0.390 | 0.463 |
| DOC2VEC + sparse coding | 0.753 | 0.678 | 0.750 |
| CNN + document expansion + sparse coding + MMR | 0.766 | 0.646 | 0.753 |
| LSTM-AE | 0.766 | 0.653 | 0.759 |
Table 5 Evaluating linear combination of AE similarity and LSTM-AE similarity
| α | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| 0.1 | 0.771 | 0.661 | 0.761 |
| 0.2 | 0.771 | 0.661 | 0.760 |
| 0.3 | 0.771 | 0.661 | 0.760 |
| 0.4 | 0.770 | 0.660 | 0.759 |
| 0.5 | 0.770 | 0.659 | 0.759 |
| 0.6 | 0.771 | 0.658 | 0.759 |
| 0.7 | 0.772 | 0.662 | 0.763 |
| 0.8 | 0.772 | 0.662 | 0.763 |
| 0.9 | 0.771 | 0.660 | 0.759 |
As expected, Word2vec outperforms tfidf by large margin (Table 3) thanks to low dimensional vectors and semantic information. However, Word2vec is not on par with AE and LSTM-AE (Figure 4). This is because the former straightforwardly derives sentence embeddings from word embeddings by weighted average; while sentence vectors are parameters of the two latter models that need to be learned from data. With κ < 0.5, LSTM-AE beats AE on all the metrics. When κ > 0.5, AE performs better on ROUGE-1 and ROUGE-2. This is possible because a large value of κ prefer diversity to relevance. Overall, LSTM-AE is a better choice. It is worth noting that concatenating the two models doesn’t bring significant improvement (Figure 4).
LSTM-AE with κ = 0.3 was compaired to state-of-the-art methods. DOC2VEC [14] uses Paragraph Vector [7] to generate sentence representation and sparse coding to detect salient sentences. However, it is not clear on which data Paragraph Vector was learned and how sentences were represented. CNN learns sentence embeddings from annotated answer sentences, i.e. sentences with labels as summary or non-summary. Relevant sentences from Wikipedia are also retrieved to overcome sparsity. Low-dimensional sentence vectors are first put into sparse coding and then MMR to generate summaries. Here, the baseline BestAns selects the best answers as summaries.
Interestingly, our unsupervised sentence representation performs slightly better than supervised one without annotated data (Table 4). LSTM-AE outperforms DOC2VEC. The reason could be two-fold: i) Paragraph Vector introduces paragraph (i.e. sentence in this case) context via so-called paragraph id additional token in the input layer, and sampling several windows through the sentence. Meanwhile, LSTM-AE captures semantic and syntactic of the sentence in the last encoding LSTM cell and uses it for sentence representation. ii) LSTM-AE was trained on Yahoo-Webscope, a large corpus of questions and answers from communities.
This could make sentence representation more suitable to CQA tasks. On the other hand, we have no clue on which data Paragraph Vector is trained in DOC2VEC; and why ROUGE-2 reported in [14] is higher than both CNN and our method. In the future, we are going to reimplement DOC2VEC, with Yahoo-Webscope as training data for Paragraph Vector, to investigate in more details.
Table 5 shows that linear combination of sentence similarities is more effective than concatenating the representations of sentence pairs (Figure 4).
5 Conclusions and Discussions
The paper presents an approach to summarizing answers for non-factoid questions in CQA using unsupervised neural sentence embeddings. Semantic and syntactic information, as well as genre and domain knowledge are incorporated in low-dimensional vectors. Empirical results demonstrated the effectiveness of these representations, particularly ones generated by LSTM-AE. Our method outperforms other methods and is on par with a method based on supervised sentence representation. In the future, we are going to apply drop-out in learning neural models, and use Restricted Boltzmann Machines to initialize Auto-Encoder to enhance their output representation. Moreover, encouraging by results on CQA answer summarization, we are going to investigate LSTM-AE on extractive text summarization and CQA problems.

