











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
Information Retrieval, an application area of Natural Language Processing (NLP), intends to content information needs of the end users. Information needs vary from individual to individual, which poses challenge to the design of search engines. Though the conventional search engines come equipped with text and multimedia content searching abilities, they often lack the interface and the requisite competence to search math formulae present inside scientific documents.
Effective retrieval of the scientific documents is challenged by abundance and complexity of the math formulae contained therein. Presence of these formulae significantly demarcates scientific documents from normal text documents, and mandates modification in conventional retrieval mechanisms to ease their retrieval. Intelligence of scientific documents search engine is manifested in its ability to comprehend crux of math formula query prior to searching. Relevant search results should be substantially influenced and guided by the semantics of query formula rather than its syntactic constructs.
For example, given query formula to be
Distinctive stipulations, laid out by math formula search, necessitate revamping conventional techniques to successfully meet the expectations of end users of math search engine. To this end, document indexing and formulae search techniques have been subjected to numerous modifications, which exhibit promising performance under normal as well as eccentric situations. In particular, indexing of canonicalized, tokenized and structurally unified variants of raw formulae have been found to engender relevant search results [16, 13, 14].
Canonicalization tackles representational non-uniformity of math formulae whereby equivalent formulae, with minor representational difference, are homogenized. In addition, tokenization and structural unification help retrieve sub-formulae and similar formulae, respectively. Weights assigned to tokenized and structurally unified formulae characterize extent of their similarity with original formulae, which eventually help in ranking the retrieved documents. Although the approach splendidly caters to the need of math information seekers, it can be fascinating to prospect other competent techniques, which may depict similar traits with relatively lesser effort.
In this paper, we present our formulae embedding approach to math information retrieval, and a comprehensive analysis of the obtained system results to infer strengths and weaknesses of the proposed approach. Formulae embedding envisions math formulae inside documents and the mathematical user query as binary vectors, wherein each bit position designates absence or presence of a specific mathematical entity ( such as single character variable, superscript, subscript, fraction, special symbol, and so on).
After having preprocessed the scientific documents and the math formulae contained therein, each formula is transformed into a fairly large-sized vector, which encompasses nearly all the information content of the corresponding formula.
Eventually, the multitude of formula vector to corresponding document mapping are indexed to assist the searcher module in its hunt for relevant documents. Count of matching set bits (set bits at same positions) of indexed formula vector and query vector constitutes the crucial criterion for assessing relevance of the retrieved documents.
Although there are some pitfalls associated with the proposed approach, it predominantly lives up to the expectations of the end users as a baseline approach.
Efficiency of the proposed approach is tested using a corpus containing 212 documents of the NII Testbeds and Community for Information Access Research (NTCIR)-12 MathIR task1, and a queryset containing 19 Wikipedia Main Task queries and 4 Wikipedia Browsing Task queries. Well known trec_eval2 tool is employed to evaluate the system’s effectiveness on the grounds of Precision at 5 (P_5), Precision at 10 (P_10), mean average precision (map) and binary preference-based measure (bpref) measures. The tool compares system results against a Gold Dataset containing judged entries for each query of the queryset.
Considerably high values of the evaluation measures serve as testament to the distinguished abilities of the proposed approach. Furthermore, the system results are also compared with the search results produced by a conventional text-based search engine. Vast gaps in the corresponding evaluation measures of the two systems are indicative of the conceptual difference between the conventional text-based search and the math formulae search.
Rest of the paper is structured as follows: Section 2 reviews some closely related works; Section 3 describes system architecture and its working description; Section 4 discusses experimental framework used for testing effectiveness of the system; Section 5 presents system results and their comprehensive analysis; Section 6 points direction for future research; Section 7 concludes the paper.
2 Related Works
Information rich contents of the scientific documents serve as crucial input to many scientific and technical research. However, scientific documents being primarily rich in math formulae, conventional text-based indexing and search techniques often fail to retrieve information from such documents.
Although a number of past works have addressed the issue of information retrieval from scientific documents, the formulae embedding approach, in particular, is still in its infancy. A relevant work in this regard is the document retrieval system [17] of NTCIR-12 MathIR task, which uses Document To Vector (Doc2Vec) and Latent Dirichlet Allocation (LDA) for retrieving similar formulae and sub-formulae. More specifically, the Distributed Bag of Words (PV-DBOW) model, a special variant of the Doc2Vec algorithm, is exploited and extended to represent math expressions in terms of the real valued vectors.
Furthermore, the preliminary exploration of formulae embedding has shown promising results in context of math information retrieval [4]. Initially a symbol2vec method transforms formulae symbols into vector representation, and the cosine distance of symbol vectors of closely related symbols turn out to be minimum. Symbol vectors and Distributed Memory Model of Paragraph Vectors (PV-DM) are then used to embed formulae. Well known cosine similarity measure computes similarity of formulae vectors, and suitable scores are assigned to the retrieved search results. However, the insufficient system description and analysis of results barely convey strengths and weaknesses of the approach.
The necessity of math formulae search led to the introduction of a new math pilot task in NTCIR-10 conference [1, 6], and the task has continued to be part of subsequent NTCIR conferences, namely NTCIR-11 [2, 5] and NTCIR-12 [18, 7]. The Math Indexer and Searcher (MIaS) system of NTCIR-10 conference employs preprocessing of scientific documents followed by canonicalization and linearization of mathematical expressions to ease their retrieval [8]. An enhanced version of MIaS [13] uses better preprocessing, canonicalization, math representation and query expansion strategies. Furthermore, combining text keywords with math query using different querying strategies has furthered the effectiveness of retrieval [9]. MIaS at NTCIR-12 conference was characterized by an additional structural unification component, which helped retrieve semantically similar formulae [14]. Tangent-3 math retrieval system [3] at NTCIR-12 uses inverted indexing to store mathematical entities extracted from Symbol Layout Tree (SLT). This is followed by a 2 stage retrieval process. While the first stage primarily concerns retrieval of relevant expressions using iterator trees and trivial ranking, the second stage concerns strict re-ranking of top-k best candidates.
Modifications in conventional indexing and search techniques have also contributed notably to the domain of math formulae search. In particular, substitution tree based indexing techniques [15, 12] index math formulae along nodes and leaves of a substitution tree and, hence, minimize the memory requirement. Nodes of the tree correspond to substitutions whereas the leaves correspond to mathematical entities. Depth first traversal of the substitution tree yields an indexed formula. An improved and intelligent boolean model [11] modifies conventional AND search mechanism, and performs ORing and stemming of the user query for effective retrieval of the scientific documents.
An architecture for scientific document retrieval, containing 3 different Text-Text, Text-Math and Math-Math entailment modules, is proposed in [10]. Architecture supports search for user query containing text as well as mathematical contents. Text Entailment (TE) module matches text part of the query to the indexed text contents, Math Entailment (ME) module matches mathematical part of query to the indexed math formulae and Text Math Entailment (TME) module matches text part of the query to standard names of the indexed math formulae.
3 System Description
This section provides details of the corpus used for experimentation, and the crucial components of the system architecture which collaboratively function to output relevant search results for each user query. Figure 1 shows the system architecture and workflow of the proposed system.
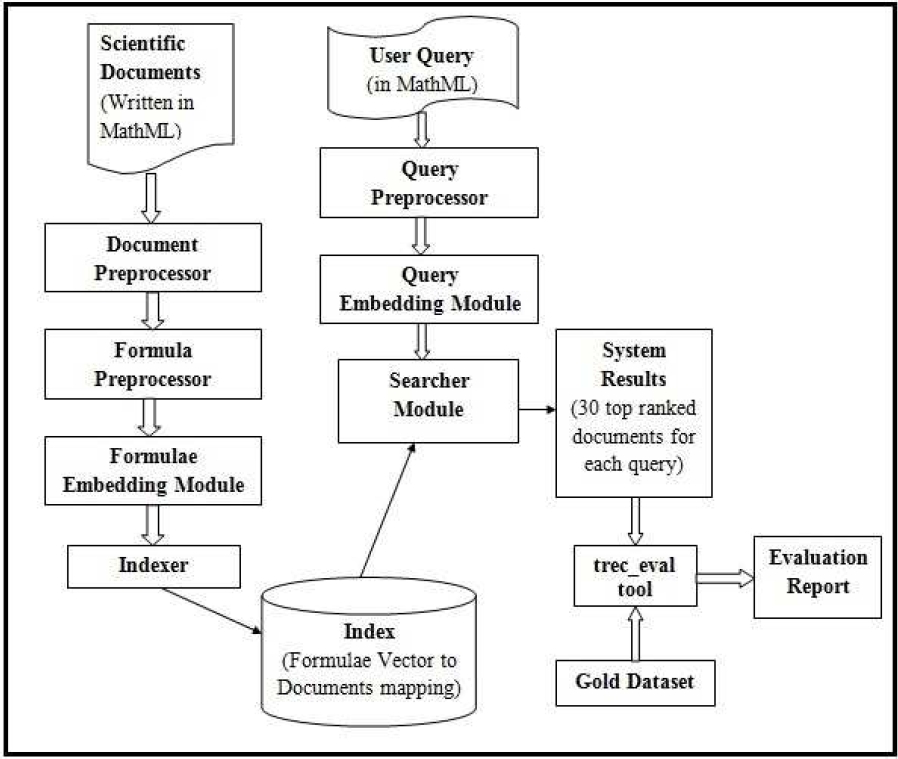
3.1 Corpus Description
Proposed system has been experimented with a corpus containing 212 documents chosen from vast arXiv and Wikipedia corpora of NTCIR-12 MathIR task. Total size of the corpus is 22.6 MB, with majority of the documents being formulae rich and considerably large in size. The documents are in XHTML format, with formulae encoded using MathML.
arXiv corpus The arXiv corpus of NTCIR-12 MathIR task comprises of 105,120 scientific documents chosen from the following arXiv categories: math, cs, physics:math-ph, stat, physics:hepth and physics:nlin [18]. Documents contain roughly 60 million math formulae written using MathML. arXiv corpus is intended for technical users.
Wikipedia corpus The Wikipedia corpus of NTCIR-12 MathIR task comprises of 319,689 articles in XHTML format, which contain 590,000 formulae encoded using LATEX, Presentation MathML and Content MathML. Unlike arXiv corpus, Wikipedia corpus is intended for non-technical users.
While selecting the documents for experimentation, adequate care has been taken to ensure that:
a reasonable proportion of the documents are common to different queries of the query set.
some documents contain exact formula query, whereas some contain similar formulae, sub-formulae and parent formulae.
Table 1 summarizes the corpus information.
3.2 Document Preprocessor
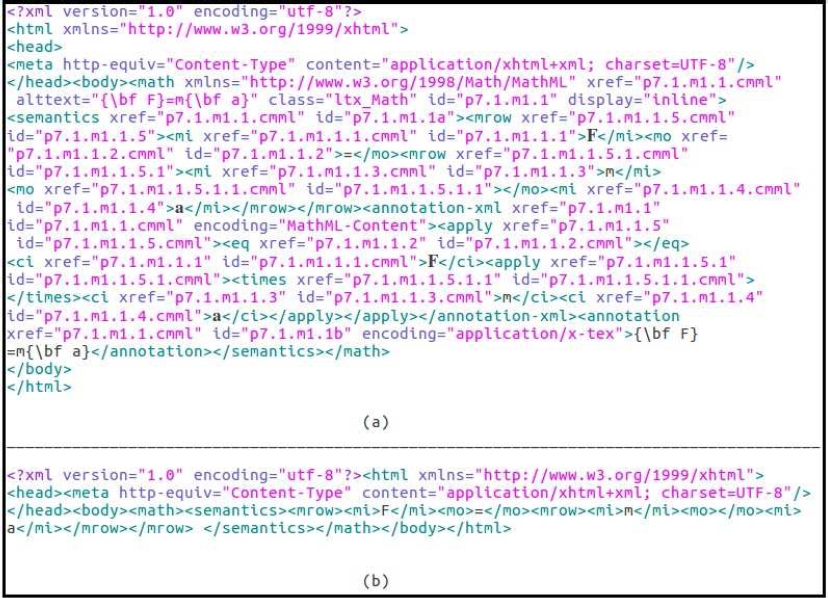
Core focus of the proposed approach being formulae retrieval and formulae matching, the document preprocessor extracts only MathML formulae from the documents containing text as well as math contents. Figure 2 shows a sample XHTML document containing text as well as math contents. Figure 3(a) shows the output of document preprocessor, wherein the text contents have been removed.

3.3 Formula Preprocessor
Primary job of the formula preprocessor is to filter out unnecessary MathML elements and attributes, which barely contribute to the information content of the formula. Table 2 shows some examples of preprocessing done by the formula preprocessor. Also, Figure 3(b) shows a complete output of the formula preprocessor, wherein only relevant information of the raw formula have been preserved.
Table 2 Preprocessing done by Formula Preprocessor
| Original | Processed |
|---|---|
| <mi xref =“p7.1.m1.1.1.cmml” id=“p7.1.m1.1.1”> | <mi> |
| <mo xref =“p7.1.m1.1.2.cmml” id=“p7.1.m1.1.2”> | <mo> |
| <math xmlns =“http://www.w3.org/1998/Math/MathML”> | <math> |
| <semantics xref =“p7.1.m1.1.1.cmml” id=“p7.1.m1.1.1”> | <semantics> |
| <annotation-xml>...</annotation-xml> | Contents between the two elements are removed |
| <annotation>...</annotation> | Contents between the two elements are removed |
3.4 Formula Embedding Module
The formula embedding module takes processed formula as input and outputs a corresponding binary vector. Careful observation of the Presentation MathML formulae guides us to the fact that <mi> and <mo> elements form the key constituents of nearly all formulae. Thus, the module parses processed MathML formula to fetch contents from all occurrences of <mi> and <mo> elements. Besides, the module also accounts for all other MathML elements, such as <msqrt>, <msub>, <msup> and so on, present in the formula. Eventually, the module uses fetched information contents and the bit position information table to set respective bits of the corresponding formula vector, which has a fixed length of 150 bits.
A bit position information table (see Table 3) depicts bit positions assigned to different mathematical entities. A vector of length 150 suffices to encode mathematical contents of all the documents in our corpus. However, the module offers flexibility to vary (increase or decrease) length of formula vector, if required.
Table 3 Bit Position Information Table
| Entity | Position | Entity | Position | Entity | Position | Entity | Position |
|---|---|---|---|---|---|---|---|
| a/A to z/Z | 0-25 | <msqrt> | 56 | log, ln | 88 | ± | 120 |
| exp | 4 | ℤ | 57 | ! | 89 | ⎰ | 121 |
| = | 26 | ℕ | 58 | Trigo. Ratios | 90 | ○ | 122 |
| Product | 27 | ℚ | 59 | ℝ | 91 | ′ | 123 |
| - | 28 | ⌝ | 60 | θ | 92 | ∧ | 124 |
| , | 29 | α | 61 | gcd | 93 | ∃ | 125 |
| + | 30 | γ | 62 | xor | 94 | ¬ | 126 |
| ∇ | 31 | ω | 63 | τ | 95 | lim | 127 |
| ∂ | 32 | ϑ | 64 | η | 96 | <,〈 | 128 |
| → | 33 | Var. Name | 65 | σ | 97 | >,〉 | 129 |
| . | 34 | Null | 66 | Ω | 98 | ⊗ | 130 |
| ( | 35 | † | 67 | # | 99 | ⊢ | 131 |
| ) | 36 | : | 68 | ⌜ | 100 | ⊓ | 132 |
| ≡ | 37 | dist | 69 | ≠ | 101 | ⊔ | 133 |
| ≫ | 38 | ∓ | 70 | { | 102 | ∥ | 134 |
| ∝ | 39 | φ, ϕ, Φ | 71 | } | 103 | ∪ | 135 |
| ≈ | 40 | ħ | 72 | ⊙ | 104 | ∩ | 136 |
| / | 41 | π | 73 | ≤ | 105 | ↦ | 137 |
| ⊆ | 42 | Δ | 74 | ∈ | 106 | ⊂ | 138 |
| ⊕ | 43 | µ | 75 | [ | 107 | det | 139 |
| ∼ | 44 | Σ | 76 | ] | 108 | Π | 140 |
| | | 45 | ∈ | 77 | *,x | 109 | mod | 141 |
| <mfrac> | 46 | ... | 78 | ∉ | 110 | sup | 142 |
| <mn> | 47 | δ | 79 | ^ | 111 | ≥,⩾,≳ | 143 |
| <msub> | 48 | ψ,Ψ | 80 | Σ | 112 | dim | 144 |
| <msup> | 49 | Γ | 81 | ; | 113 | := | 145 |
| <msubsup> | 50 | ∞ | 82 | ¯ | 114 | ≅ | 146 |
| <mover> | 51 | ρ | 83 | ⇐⇒, ⇔ | 115 | max | 147 |
| <munderover> | 52 | β | 84 | ⇒ | 116 | inf | 148 |
| <munder> | 53 | λ | 85 | ⌈ | 117 | min | 149 |
| <mtable> | 54 | ξ | 86 | ⌉ | 118 | ||
| <mmultiscripts> | 55 | ◻ | 87 | ∀ | 119 |
Figure 4 shows typeset representation and formula vector of a processed MathML formula.

The following points are worth noting about bit position information table and formula vector:
Bit positions 0-25, 57-65 and 71-100 correspond to the content of <mi> tag, bit positions 26-45, 66-70 and 101-149 refer to the contents of <mo> tag, and bit positions 46-56 refer to essential MathML tags which contribute to the semantics of formula.
The list of entities is by no means exhaustive, but it accounts for nearly all the entities contained in our corpus. In future version of the proposed system, the length of formula vector will be extended to account for more math symbols and their semantics.
In order to retrieve specific results ahead of non-specific ones, distinction is maintained between single alphabet variables, by assigning them different bit positions ranging from 0-25. However, the table makes no distinction between the cases of variables, and the different cases of same variable are assigned same bit position. For example, ‘a’ and ‘A’ are assigned same bit position equal to 0. Furthermore, since the entities “exp” and ‘e’ are interchangeably used, they have been assigned same bit position equal to 4. For the same reason, “log” and “ln” are assigned same bit position.
Proposed system seeks generalized results for the query term involving trigonometric ratios, such as “sin”, “cos”, “tan”, “cot”, and so on. Thus, all such ratios are assigned same bit position equal to 90.
An entity which can be part of <mi> as well as <mo> tags, i.e. the one which can act as variable as well as operator, is assigned two distinct bit positions. One such entity is Σ, which is assigned bit positions 76 and 112, designating variable and operator, respectively.
Bit position 65 designates a multi character variable, whose name is not a standard variable name (such as, lim, log, gcd, and so on).
The formula vector does not account for multiple occurrences of the entities. Even though an entity occurs more than once in the formula, only one corresponding bit of the formula vector is set. This limitation, however, causes inability to retrieve relevant search results, if the user query contains repetition of an entity.
However, none of the above constraints incurs loss of generality, and the approach is scalable.
3.5 Indexer
Indexer stores formula vector to corresponding document mapping in an index. System indexes a total of 5,969 processed formulae, derived from 212 documents of the corpus.
Moreover, the index size is 1 MB, which is 4.42% of the corpus size. Corpus size and the size of formula vector are the primary factors, which affect size of the index. Indexer indexes formulae in document-wise fashion, meaning thereby that only after having indexed all the formulae of a document, it goes for indexing next document of the corpus.
However, it is observed that ‘0’ bits of a formula vector, which designate absence of mathematical entities, unnecessarily increase the size of index. Our primary concern being presence of an entity, future modification will refrain from storing ‘0’ bit information in the index.
3.6 Query Preprocessor
The task of query preprocessor resembles that of document and formula preprocessors. It extracts math formula from the user query (text+math) and processes it to remove unnecessary MathML elements and attributes.
3.7 Query Embedding Module
Similar to the formula embedding module, the query embedding module transforms processed user query into a binary query vector. An important observation is that some NTCIR queries comprise of query variable (qvar), which may designate a variable name, numeric value or complex expression. As of now, the module assumes “qvar” to be numeric value and sets the bit position 47, corresponding to element <mn>, equal to 1 if “qvar” is encountered.
3.8 Searcher Module
Given a user query in vector form, primary objective of the searcher module is to retrieve relevant search results. Module uses number of matching set bits of query vector and formula vector as the criterion to judge relevance of formula vector and, hence, the search results. Although the criterion is not foolproof, it works effectively well for majority of user queries. Probable errors and associated problems of the selected criterion are comprehensively analyzed, with suitable examples, in subsection 5.4.
The module retrieves 30 most similar top ranked documents corresponding to each user query. It should be noted that a query vector may match different formulae of the same document with different scores, and if such a document succeeds to find place in the result list, the module reports highest of all the scores. In any case, the module refrains from reporting redundant results, which may hamper the evaluation process.
Eventually, the system results are fed to trec_eval evaluation tool, which compares them with the Gold dataset entries and outputs an evaluation report, which summarizes effectiveness of the system in terms of a number of parameters.
4 Experimental Design
This section details queryset, gold dataset and evaluation parameters used to evaluate performance of the system.
4.1 Queryset Description
Our queryset comprises of 23 MathML queries, derived from NTCIR-12 MathIR Wikipedia Main Task and Wikipedia Formula Browsing Task querysets. The queryset is a mix of simple and complex queries, and each query has an associated QueryID. While selecting documents for the corpus, it is ensured that the documents contain either exact form or similar form or sub-formula form of the query formulae in the queryset. Each of the queries in the queryset is transformed into a query vector by the query embedding module.
4.2 Gold Dataset
Gold Dataset (also known as qrel file) strictly adheres to the Text REtrieval Conference (TREC) qrel format3, and contains a set of human assessed documents for each query in the queryset. Gold dataset has the format:
QueryID Iteration Document# Relevance
where, QueryID designates specific query, Iteration is an irrelevant field usually set to 0 and ignored by the trec eval tool, Document# specifies document number of the retrieved document and Relevance designates binary judgment (1 for relevant and 0 for irrelevant). A document is judged relevant even if it contains small content of the query formula. Our Gold Dataset contains 690 entries, wherein 77 entries are judged irrelevant. Figure 5 shows snapshot of the Gold Dataset.

4.3 Evaluation Parameters
System results are evaluated on the grounds of P_5, P_10, map and bpref. All these measures are computed for each query, and individual measures are then averaged over all the queries in the queryset. P_k, with k being equal to 5 and 10, refers to the count of relevant documents out of first k retrieved documents. In order to compute map, precision score is computed whenever a relevant document is retrieved.
The precision scores are then averaged over all the relevant documents, corresponding to a query, to get average precision. Average precision scores are averaged over all the queries to get map. Furthermore, bpref measures ability of the system to retrieve relevant documents ahead of irrelevant ones. Besides, we have also computed fraction of the relevant documents which are retrieved (denoted as frac_ret). Count of retrieved relevant documents (num_rel_ret) divided by the count of relevant documents (num_rel) gives the measure of frac_ret. Values of num_rel and num_rel_ret, used to compute frac_ret, are obtained from the evaluation report. All the five parameters range from 0 to 1, with larger signifying the better.
5 Results and Analysis
5.1 Format of Result Set
The Result Set containing system results adheres to the result file format of TREC. Each tuple of the result set is of the form:
QueryID Iteration Document# Rank Similarity Run_ID
Although Iteration (iter) and Rank fields are mandatory, the two are ignored by the evaluation tool. Similarity (sim) is usually float in nature and attains larger value for the documents which are retrieved first. In our case, the count of matching set bits refers to the Similarity score. Run_ID, a trivial field, is a string which characterizes system run and gets printed on the evaluation report. The three trivial fields, namely Iteration, Rank and Run_ID, have been set to dummy values “Q0”, “20” and “demo”, respectively. Figure 6 shows snapshot of the Result Set.

5.2 Evaluation Report
Evaluation report generated by the trec_eval contains values of a number of parameters, which summarize effectiveness of the proposed system. However, only 5 parameters, discussed in the subsection 4.3, are used to infer the system’s effectiveness. Labeled bar chart, shown in Figure 7, depicts values of the evaluation parameters for the proposed system. Fairly high values of the parameters substantiate effectiveness of the proposed approach. Out of a total of 613 relevant documents, system succeeds in retrieving 535 documents, which equates to 87.27% (frac_ret=0.8727) of the total relevant documents.

5.3 Comparison with Conventional Text Search Engine
The same experimental framework (Corpus, Gold Dataset and Query Set) is used to retrieve results from Apache Nutch4 based conventional text search engine. Labeled bar chart, shown in Figure 8, depicts comparison of evaluation parameters for the two systems. Significant differences in corresponding evaluation measures are attributed to the fact that math search is way different than conventional text search in terms of retrieval needs of the end users, and the way query term is matched to the indexed terms. In particular, the incompetence of conventional text search engine is reflected in its ability to retrieve only 54 out of 613 relevant documents, which equates to 8.81% (frac_ret=0.0881) of the total relevant documents.

5.4 Results Analysis
In this subsection, we have comprehensively analyzed strengths and possible limitations of proposed method from different perspectives. Following observations and system outcomes are worth considering:
First observation is that given a query formula, system flawlessly retrieves all search results, wherein the query term is either present in its exact form or present as sub-formula of a larger parent formula. This actually happens because similarity score (number of matching set bits of query vector and the search result) for such results will be maximum. For example, Table 4 shows some of the search results for the user query a ⊕ b. In first and second search results, the query term appears in its exact form whereas in third and fourth search results, it appears as sub-formula of its parent formula. Moreover, the maximum similarity score is 3 as the query formula comprises of three distinct entities, namely a, ⊕ and b.
Second observation is that even the complex formulae, which share semantic relatedness with the user query and contain all its entities, are successfully retrieved. For example, the fifth and sixth search results (see Table 4) neither contain exact query formula nor its parent form, but they are retrieved by our system, as they semantically resemble the query formula and contain all its entities.
-
Third observation is that the proposed system successfully retrieves sub-formulae and similar formulae of a given user query. Consider, for example, the search results for user query O(mn log m), shown in Table 5.
Snippets shown in first four search results depict sub-formulae of the user query. Also, the fifth search result is semantically similar to the user query.
-
Fourth observation is that although the decision of correlating relevance with high similarity score predominantly works well, it does incur failure in certain cases. Consider, for example, the search results for the user query 2F1(a, b; c; z), shown in Table 6.
Though the first three search results are ap-preciable, the last search result is absolutely irrelevant. Such an irrelevant result succeeds in finding place in the result list, because it contains majority of the query formula entities, namely ‘A’, ‘B’, ‘C’, ‘(’, ‘)’ and ‘1’.
Fifth observation is that for the user query F = ma, system retrieves an irrelevant search result
Table 4 Search results for the user query a ⊕ b
| Search Results | Documents | Similarity Score |
|---|---|---|
| a ⊕ b | hep-th0005087_1_93 | 3 |
| b ⊕ a | 1310.4652_1_21 | 3 |
| a ⊕ b = b | 1209.1718_1_16 | 3 |
| (a, b) ∈ A ⊕ B | math0011063_1_119 | 3 |
| M(B) = M(A) ⊕ M(A−1B) | math0102078_1_5 | 3 |
| WPk = APk ⊕ BPk | math0206213_1_24 | 3 |
Table 5 Search results for the user query O(mn log m)
| Search Results | Documents | Similarity Score |
|---|---|---|
|
|
0805.1348_1_4 | 5 |
|
|
quant-ph0205083_1_82 | 5 |
|
|
quant-ph0211179_1_57 | 5 |
| O(log n) | 0805.1348_1_32 | 5 |
| O(nt log n) | 1308.3898_1_18 | 5 |
Table 6 Search results for the user query 2F1(a, b; c; z)
| Search Results | Documents | Similarity Score |
|---|---|---|
| 2F1(a + 1, 1; 2; z) | math-ph0203052_1_8 | 10 |
| 2F1(k + 1, k + 1; 1; λ) | quant-ph0212072_1_20 | 7 |
| 2F1(−n, b; γ; y) | math-ph0203052_1_21 | 7 |
|
|
hep-th0108170_1_12 | 7 |
Our fourth and fifth observations guide us to the fact that using number of matching set bits of the formula vector and the query vector as similarity measure criterion is not foolproof. A search result with low similarity score might prove to be more relevant than the one with better score. Thus, even though the proposed system lives up to our expectations as a baseline system, a future extension necessitates revision in similarity measure criterion to overpower existing inabilities.
6 Future Directions
As the system is baseline and first of its kind, the list of possible future directions goes long. Some salient future directions are undermentioned:
Proposed system currently refrains from indexing and searching text contents. Thus, augmenting baseline system with text indexing and searching ability can further the system’s performance, and possibly invalidate some of the irrelevant search results.
Formula and Query vectors need to be lengthened to accommodate new symbols and semantic information. For example, some bit positions may account for count of occurrences of an entity or co-occurrence of two or more entities, which will eventually let the searcher module prefer relevant results over irrelevant ones.
Similarity measure criterion can be modified to assign weightage to certain bit positions. It is a well-established fact that the end users may compromise the variable names but not the operators. For example, given user query to be a ⊕ b, the end user will be more content with c ⊕ d than a + b, even though the similarity score for the latter will be more than the former. Thus, assigning more weightage to operator bit positions, while computing similarity score, can do wonders.
It can be fascinating to prompt the end users for key entities in their queries. Search results not containing such entities should not be retrieved. This can be ensured by dynamically assigning more weightage to the bit positions of key entities while computing the similarity score.
7 Conclusion
In this paper, we describe an unconventional formula embedding approach, which can ease retrieval of math formulae present inside scientific documents. Uncommonly used formula embedding approach opens door to the new horizons and helps combat underlying challenges of the scientific document retrieval. Having transformed the processed document formulae and the user query into vectors of fixed size, the proposed system uses number of matching set bits of the document formula and the query vector as similarity measure to retrieve and rank the indexed formulae. Comprehensive analysis of the system results affirms underlying strengths and weaknesses of the system. Although the approach has associated limitations, it shows competence in retrieving exact query formula, parent formulae, sub-formulae and similar formulae. Modifying similarity measure criterion, and incorporating support for indexing and searching of textual terms are some of the notable future modifications, which can further the effectiveness of retrieval.

