











 nova página do texto(beta)
nova página do texto(beta) Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1 Introduction
Authorship Analysis aims at extracting information about the authorship of documents from features within these documents. It is based on combining three different techniques, namely Authorship Profiling, Authorship attribution or Identification and Plagiarism Detection. Author profiling is the task of determining the writers’ features, such as native language, education, gender, age and personality traits, by understanding their writing styles.
In recent years, author profiling has been a promising field of research in the world of human-machine interaction systems as it presents important opportunities and challenges in various fields such as marketing, analysis of social networks and social computing [40, 8, 31].
For instance, author profiling helps, in crime investigation, identify the perpetrator of a crime by considering the characteristics of his/her writing styles. However, it does also allow studying the behavior of potential terrorists or groups advocating racial segregation [11].
Author profiling is also employed in marketing to detect, for example, the profiles of potential consumers of a website for online sale to help decision makers choose their marketing strategies [24]. Besides, author profiling is applied in e-learning. It allows understanding and detecting the users’ behavior in this educational environment and thus permits architects of learning sites and designers of educational tools and materials to create and organize the content of learning according to the learners’ needs.
With the development of social networks, Facebook has recently become an interesting target for research providing rich information to study and model user's behavior. Indeed, user's contributions and activities constitutes a valuable insight about individual behavior, opinions, experiences and interests, which makes it an important and rich source for the extraction of corpus serving as the basis for several research works. [31] employed users data on Facebook to explore the feasibility of predictive personality modeling in order to support future intelligent systems. Other studies, such as [37] and [21] utilized Facebook data for sentiment classification, authorship identification [17] and speech recognition [20].
In our approach, we applied deep learning approaches to learn the abstract and higher level features of the document and identify author characteristics. We explored extension of the recursive neural network that employs a variant of the Gated Recurrent Units (GRUs) architecture to tackle the problem of gender detection.
2 State of the Art
The writing style of the words reflects the authors’ mental, social and even the physical as well as the psychological states. Indeed, statistical studies exploring the stylistic features of a text have begun one century ago with T. Mendenhall. Afterwards, several probabilistic machine learning and deep learning approaches were introduced.
The studies of stylometric demonstrated also that individuals can have a footprint linked to their writing style. Indeed, [25] defined an author profile as “a set of length L of the most frequent n-grams with their normalized frequencies”. Thus, the profile of an author can be considered as the ordered set of pairs {(x1; f1); (x2; f2)… (xL; fL)} Of the L most frequent n-grams xi and their normalized frequencies fi.
[27] represented 604 documents from the British National Corpus (BNC) in the form of trees whose roots are words sets or POS. They obtained 80 % accuracy to infer the gender of the author.
Researchers in 2002, [12] investigated authorship gender attribution mining from e-mail text documents based on the structural characteristics and gender preferential language features. They obtained 70.2 % precision rate for gender detection.
Different researchers used a variety of powerful machine learning and statistical algorithms to build a classification model by employing these features vectors.
[28] analyzed a corpus of 71,000 blogs incorporating almost 300 million words. They utilized a learning algorithm, called Multi-Class Real Winnow (MCRW), to learn models that classify blogs according to the author’s gender and age. They got 43.8% and 86% for age and gender accuracy prediction, respectively.
The authors, in 2016, built a Cross genre Author Profiling System (CAPS) which considered parts of speech, collocations, connective words and various other stylometric features to differentiate between the writing styles of male and female authors as well as between different age groups. Their system attained 74.36% accuracy for gender identification [7].
For age and gender profiling, in 2013 [29] employed (SVM) Classifiers together with Principal Component Analysis (PCA). They concluded that content-based features are more discriminative than other features (style based and content based features). SVM classifiers allowed obtaining 82.6% gender prediction accuracy.
In 2016, [36] approached the task of gender detection with combinations of stylistic features such as function words, parts of speech, emoticons and punctuations signs. They trained their models with SVM and obtained 55.75 accuracy for gender identification in English data PAN 2016 competition.
Liblinear classifier combined with Concise Semantic Analysis (CSA) was used by [4]. It achieved a best accuracy of 65.72 for the age prediction in English blogs data PAN 2013 competition [4].
To predict the author gender, [19] reached a good accuracy equal to 0.8283 by using REP Tree (a fast decision tree learning algorithm) as a classifier and the sentence based, character, syntactic and Word features.
[38] relying on a corpus of 3524 Vietnamese Weblog pages of 73 bloggers and exploiting 298 features, they obtained an accuracy of 82.12 for occupation and 78.00 for location dimension by employing IBK.
[2] used the gensim Python library for LDA topic extraction with SVM classifiers. Their result proved that the topic models are useful in developing author-profiling systems. [10] predicted the gender, age and personality traits of Twitter users in four different languages (Spanish, English, Italian and Dutch). They accounted stylistic features represented by character Ngrams and POS N-grams to classify tweets. They applied Support Vector Machine (SVM) with a linear kernel called LinearSVC and obtained 83.46% for gender detection.
In [13], researchers applied SVM classifier and neural network on TF-IDF and verbosity features. Results showed that SVM classifiers are better for English datasets.
They proved that neural networks performed better for Dutch and Spanish datasets. For English, the best findings were obtained using a TF-IDF at character level combined with the verbosity feature. Their results are almost similar to those provided by [6]. They got 61.5 gender accuracy and 41.03 age accuracy.
Based on the corpus collected from Twitter for four different languages (Arabic, English, Portuguese and Spanish), [3] obtained 85.99 for gender identification accuracy by combining character n-grams (with n between 3 and 5) TF-IDF word n-grams (with n between 1 and 2).
[33] obtained 70.02 by using logistic regression with combinations of character, word and POS n-grams, emojis, sentiments, character flooding, and lists of words per variety in PAN 2017 competition [41].
Deep learning based approaches have recently dominated the state of the art in well-studied problem among NLP researchers. New approaches have also emerged to improve authorship analysis which involves many layers of nonlinear information processing in deep neural networks [22, 49]. Subsequently, deep learning-based approaches have demonstrated remarkable results for text classification and have performed well for phrase level and message level sentiment classification [26, 46].
In 2016 and for the first time, [30] have employed deep learning techniques for author profiling. They described a big gap between traditional machine learning models and deep learning models in the participant teams evaluated in the VarDial2016 workshop. They attempt to narrow this gap using convolutional neural networks (CNN) as a first approach for author profiling.
In 2017, many researches applied deep learning approaches: Recurrent Neural Networks, Convolutional Neural Networks as well as word and character embeddings. However, [17] generated embeddings of the authors’ text based on sub word character n-grams. These representations were classified using deep averaging networks. They got 79.19 for gender identification in PAN 2017 competition [41].
[45] used TF-IDF and a Deep Learning model based on Convolutional Neural Networks.
As features, he used a matrix of 2-grams of letters with punctuation marks, beginning and ending with 2-grams. They obtained 72.07 as precision of gender identification in PAN 2017. The same model based on Convolutional Neural Networks was used by [47] who explored parameters such as the size of the input of the network, the size of the convolutional kernels, the number of kernels and the type of input. They found experimentally that sequences of words performed better than sequences of characters as input for the CNN. They obtained 76% of accuracy in the test partition in PAN 2017 competition.
Experiments on automatic classification of users according to latent attributes, such as gender and age, were performed on a wide range of resources including Facebook, telephone conversations [42], blogs [44] and Twitter [16, 51]. The problem that always arises, in this context, is how to label user’s profiles to obtain their age and gender. To solve this problem, two techniques were proposed. The first one is based on applying a manual labeling. For instance, [35] constructed manually a dataset by means of a fine-grained annotation effort of more than 3000 Dutch Twitter users.
To determine the author’s gender, [9] sampled users from the Twitter stream and used links to blogging sites indicated in their profile. Some approaches used, for example, lists of male and female names by analyzing Facebook texts [15].
The second manner of construction corpora consists in taking into account information provided by the authors themselves. For instance, in blog platforms, [28] studied the effect of age and gender on the style of writing in 71,000 blogs, while [38] used the corpus of 3524 Vietnamese Weblog pages of 73 bloggers or e-mail messages [14].
Though Arabic is spoken by almost 400 million people, research works of authorship analysis performed on Arabic texts are not numerous. For example, the study of [1] focused on author identification. The researchers constructed a corpus written by 20 authors and 20 messages written by each one.
The second work investigating the multilingual messages was carried out by [14].
In their research, authors collected Arabic and English e-mails written by 1033 English people and other e-mails written by 1030 Egyptian Arabic speakers. They studied several demographic and psychometric features for author profiling [48].
In [5], authors construct an Arabic corpus taken from Facebook for age and gender detection. They used different techniques for classification combined with linguistic, stylistic and structural features to determine the gender and age of author. They obtained 71.52 accuracy to infer the gender of the author and 53.08% for age detection.
3 Data
Our study was performed on two varieties of corpus. The first corpus consists of short texts (one comment per author that does not exceed 15 words at the average) proposed by [5]; whereas the second corpus presented by the conference PAN @ CLEF 2017 contains long texts (100 tweet per author) [41].
The first corpus is based on the Web texts, especially Facebook. In fact, they labeled manually gender with the help of a dictionary of proper nouns (ambiguous nouns have been discarded) and by visiting each profile and looking at the photo, description, etc. This first corpus composed of 4444 validated profiles contains 70121 words with an average of 15.77 words per profile. Approximately, 50% of the texts have a text length shorter than 10 words. The corpus was balanced in terms of gender, while it was imbalanced in terms of age.
The second dataset used to train the proposed models is the official PAN@CLEF 2017 Author Profiling Training Corpus. It was collected from Twitter. For each tweet collections, the texts, taken from the Arabic language, are composed of tweets, 100 tweets per authors. In this work, we concatenate the user tweets to have a unique instance. For the Arabic language, four varieties were used in this corpus: Egypt, Gulf, Levantine and Maghrebi.
4 Proposed Approach
The standard recurring networks obtain their strength from their memory capacity for sequence processing thanks to recurrent connections, bringing the context of the preceding element into the sequence, and their ability to be trained through back propagation through time. But, learning long term dependencies using simple recurrent neurons may provoke problems like exploding or vanishing gradients [23].
To solve such issues, recent approaches have modified the simple neuron structure in order to learn more efficiently dependencies over longer intervals. In this study, we evaluate the performance of such neural networks, namely Gated Recurrent Units (GRUs). The latter (GRUs) is a specific recurrent neural network (RNN) architecture that is well employed to learn from experience to predict unknown author’s gender.
Gated Recurrent Units (GRUs) use both past and future information stored by both the forward and backward networks, regardless of the type of network.
Indeed, this bi-directional model employs the activation functions of Softmax to calculate its output.
It first computes the hidden state forward by applying the function and the hidden state backwards of an entity in the sequence:
The transition from hidden a state to another is based on using the Gated recurrent units. Although RNNs can theoretically capture long-term dependencies, they are very hard to actually train. [23] showed that learning long term dependencies in recurrent neural networks through gradient decent is a difficult task. Gated recurrent units are designed to provide more persistent memory, making it easier for RNNs to capture long term dependencies.
In this paper, we apply a bi-directional gated RNN (GRUs) as an optimization algorithm Adam. In the following section, we will present our system of determining the author’s gender from Arabic corpus, as shown in Figure 1.
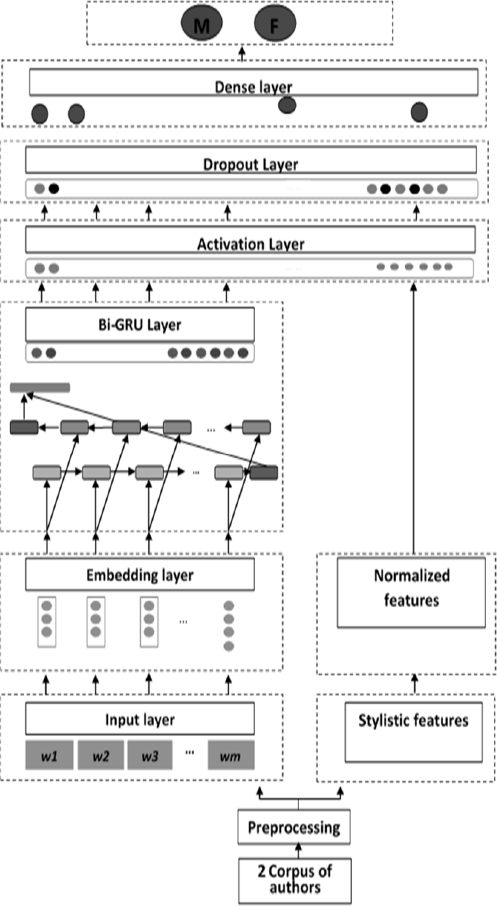
4.1 Preprocessing
To model statistically the language, we pre-processed the comments in the extracted corpus utilizing five regular expressions. The first expression permitted identifying Arabic texts and omitting those written in foreign languages. However, in the second expression, we deleted duplicated letters (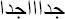 ). The third expression omitted diacritization; whereas the fourth deleted comments in form of hypertexts (advertisements links, images...). At final two or more successive spaces, resulting from the application of the rules already mentioned or they are founded in the original texts, were replaced by one space.
). The third expression omitted diacritization; whereas the fourth deleted comments in form of hypertexts (advertisements links, images...). At final two or more successive spaces, resulting from the application of the rules already mentioned or they are founded in the original texts, were replaced by one space.
4.2 Input Layer
In this layer, each unit of the input layer passes its assigned value directly to the Embedding layer.
4.3 Stylistic Features
We considered the comments as a vector in a multi-feature space. Then, we used the obtained labeled vectors to construct our classification model. In fact, six types of style related features were determined [5].
− Arabic Lexical features:
These features were obtained by frequency calculations. We distinguished the number of words appearing once and those appearing twice, the average length of sentences, the number of sentences, the number of verbal sentences as well as the number of negative sentences starting with negation. (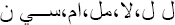 ).
).
− Arabic n-grams:
We used bigrams and trigrams to detect Arabic authors’ profiles.
− Arabic syntax features:
It consists in labeling comments and giving each word, in the extracted corpus, its syntactic category (proper name, common noun, verb, adjective, etc).
− Arabic character frequencies:
We calculated the frequency of letters, punctuation marks (number of colons, exclamation marks, question marks and commas), uppercase characters, lowercase characters, numerical characters, alphabetical characters, numbers and symbols like (@, #, and, %, *).
− Bag of smileys:
We listed 57 manually created emoticons (:- ),, : (, ; - ), ; ), ;-P, ;P, :P, :-p, :p...) which express different sentiments (happiness, sadness, anger, etc.)
− Arabic stop words:
We defined 4 groups of stop words, such as personal pronouns ("he", هو),("she", هي ),("they", هم ), demonstratives (this هذا, these هؤلاء, there أولئك), prepositions (from من, toإلى, in في, about عن ) and interrogatives ("where", أين,"who", من).
4.4 Normalized Features
To remove the impact of different scales, we normalized the value of each feature using AMZD normalization [39]:
4.5 Embedding Layer
We employed the default continuous bag of words embedding strained through a shallow neural network, as shown by [51] to initialize the embedding layer of the RNN. This bag represents essentially words by a vector to identify the similarity between words. In fact, the search for similarity is based on the word 2vec techniques. Indeed, word2vec is a combination of two methods (CBOW (Continuous bag of words) and Skip-gram model) which learn weights acting as word vector representations [51].
The Word2Vec model was formed by the corpus of Arabic Wikipedia with 4 million tweets extracted in order to enrich the vocabulary list with words that do not exist in Wikipedia. For training, we used the skip-gram neural network model with a window of size 5 (1 center word + 2 words before and 2 words after), a minimum frequency of 15 and a dimension equal to 300.
4.6 BI-GRU Layer
The GRU cell has two gates: an update gate (z) and a reset gate (r). It reduces the three gates defined in the LSTM networks (the input, forget and output gates).
The following equations represent the gating mechanism in a GRU:
4.7 Activation Layer
Most recent deep learning networks have used rectified linear units (ReLUs) for the hidden layers. Most frameworks, like Tensor Flow and TF Learn, simplify the use of ReLUs on the the hidden layers [31].
It computes the following function:
4.8 Drop Out Layer
As the size of our model is relatively big and to avoid overfitting problem, we applied Dropout to control the size of the network and to change the number of the hidden features in the recurrent layers [34]. In fact, dropout involves randomly removing some hidden units in a neural network during the training step while keeping all of them during the testing step. We employed dropout on our softmax layer with p = 0.5.
5 Experimentation and Results
To evaluate the prediction accuracy of our method we used the best results of [42] obtained in PAN@CLEF2017 as a baseline method to assess our technique and show its efficiency. Basile and al [41] obtained the best accuracy result as showing in Table 3.
Table 1 The distribution of comments according to different gender and age categories
| Gender | |||
|---|---|---|---|
| Female | Male | Total | |
| 18-24 | 214 | 369 | 583 |
| 25-34 | 339 | 415 | 854 |
| 35-49 | 686 | 235 | 921 |
| 50-64 | 468 | 633 | 1101 |
| >65 | 496 | 489 | 985 |
| Total | 2203 | 2241 | 4444 |
Table 2 PAN CLEF 2017 training corpus statistic for gender detection
| Authors | Tweets | Language varieties | Genders |
|---|---|---|---|
| 2400 | 240k | Gulf, Levantine, Maghrebi, Egypt | 1200 M; 1200 F |
Table 3 Gender accuracy for PAN and Facebook corpus
| Facebook Corpus | Pan Corpus | |
|---|---|---|
| Basile et al., 2017 [42] | -- | 80.06 % |
| Our system | 62.1% | 79% |
In our method, we used10-fold cross validation. The dataset, for both corpus, was divided at the note level. We separated out 10 % of the training set to form the validation set. This validation set was used to evaluate our bi-directional RNN model. We also employed a maximum of 20 epochs to train our model. The training was performed on an Intel core i7 machine with 16 GB memory.
To choose the optimization algorithm, we trained our model with 20% of randomly dataset from PAN corpus, in 10 epochs. Then we selected the algorithm which achieving the highest accuracy on the development set. We tested seven algorithms: SGD, Adam, RMSprop, Adagrad, Adadelta, Adamax and Nadam. Experiments shows that our model performed with Adam optimizer and it converges to 80 % of accuracy.
Table 3 shows the performance results of our system in the two test datasets used for gender identification. For PAN corpus, we compared our method with the best accuracy obtained in PAN 2017.
Comparing our result with that achieved by the best participant in PAN@CLEF2017, based on the same corpus, we obtain a very encouraging result that shows the effectiveness of deep learning models. By taking the GRUs model on a large amount of data, it reaches 79% for the age identification task.
To show the relationship between GRUs model and the amount of training data, we changed the training corpus, we based on the second corpus extracted from Facebook, which is a corpus very small compared to PAN corpus, GRUs did not show the same performance and obtained an accuracy of 62.1%.
In general, using stylistic models with word embeddings in a GRUs architecture allowed obtaining the best results and proved that bi-directional deep networks is crucial in author profiling task, especially when it’s trained on a huge amount of data.
6 Conclusion
This paper proposes a combination of stylistic models with words embeddings and Deep-Learning (GRUs) Neural Network to predict the gender of Twitter and Facebook Arabic authors.
Our bi-directional recurrent neural networks model shows a good performance on gender identification. The obtained results were encouraging, especially for Facebook corpus. This result not so surprising since neural network models had shown efficiency adapting to natural language processing problems (sentiment analysis, text classification…).
As future works of this study, we plan to extend our detection tool to other attributes for Arabic authors like language variety and personality features.

