











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The main objective of Automatic Theorem Proving is that given an expression of some logical system, a computer program can decide if that expression follows from a set of axioms and inference rules.
There are many procedures to reach this goal, for example, Resolution, Semantic Tableaux, Hilber Systems, Natural Deduction, Davis-Putnam, and Sequent Calculus.
This work is in the line of Sequent Calculus, in the sense that after applying an inference rule the size of the original expression decreases, which is called subformula property.
Intuitively, it means that the truth of an expression depends only on its constituent elements. Of course, the type of axioms and inference rules change from one system to another.
For example, in AB grammars, the words of an expression in English can be considered as axioms, if after applying modus ponens to them we get an expression of type
A collateral objective in Automatic Theorem Proving is to say why an expression does not follow from the axioms. This is called, the explanatory power of the Automatic Theorem Prover. We are going to use this kind of tools to develop an automatic theorem prover for Natural Logic with emphasis on textual entailment.
Recognizing Textual Entailment is essential for other Natural Language Processing tasks such as: Semantic Search, Question Answering, Text Summarization, and Information Extraction. Different methods have been used to solve the RTE problem [7], those methods are based on machine learning, linear programming, probabilistic calculus, optimization, and logic.
The logical methods used in RTE, although they use an inference mechanism, decide on the entailment through machine learning algorithms or some kind of optimization. In such a situation, it is not possible to know what relationships, among the subexpressions of the text and the hypothesis, are avoiding the entailment.
Natural Logic was developed to reason in natural language without having to use some kind of logical form [22, 18]. Natural Logic only uses lexical, syntactic, and basic semantic information of a language. Natural Logic can be viewed as the joint of some kind of Categorial Grammar, with modus ponens as the unique inference rule, and reasoning with polarity.
In this paper, we are going to present an Automatic Theorem Prover for Natural Logic. Its main features are: it can make entailments on more than one subexpression, and it finds precisely the subexpressions that do not permit the entailment.
We explain briefly in section 2 four approaches to RTE that use some kind of inference mechanism, and one that is based on Natural Logic. We deal with Natural Logic in section 3, section 4 is devoted to construct the algorithms needed for the proof theory of an extension of AB grammars. Section 5 contains an adaptation of the algorithm of van Benthem to compute polarity in AB grammars, and an Automatic Theorem Prover for Natural Logic is developed. Later, section 6 shows some examples of the Automatic Theorem Prover. Finally, section 7 gives our conclusions, and future work directions.
2 Approaches based on an Inference Mechanism
The methods discussed in this section use some kind of inference mechanism to recognize textual entailment, excepting for the one of MacCartney and Manning, which is included because it is based on Natural Logic.
2.1 COGEX
The system of Hodges et al. [9] transforms the input text and hypothesis into logical forms. The transformation process includes part-of-speech tagging, parse tree generation, word sense disambiguation and semantic relations detection.
In order to use the logic prover COGEX, a list of clauses called ”set of support” is required, this is used to begin the search for inferences. Another list, called the usable list, contains clauses used by COGEX to produce inferences. The axioms are about knowledge of the world, linguistic rewriting rules, and synsets of WordNet.
The clauses in the set of support are weighted, a clause with a lesser weight is prefered to participate in the search. The negated hypothesis (COGEX proves by refutation) is added to the set of support with the largest weight, this guarantees that the hypothesis will be the last clause used in the search.
If a refutation is found the prover ends, if there is not a refutation the predicate arguments are relaxed. If despite arguments relaxation a refutation is not found, predicates are dropped from the negated hypothesis until a refutation is found.
When a refutation is found, a score for it is computed, beginning with a perfect score and subtracting points for axioms used, arguments relaxed, and predicates dropped.
If the score for a refutatiion is greater than a threshold, then it is considered that the entailment is true, otherwise it is considered false.
2.2 OTTER
In the proposal of Akhmatova [2] the meaning of a sentence is represented by the set of atomic propositions contained in it, then the sentences are compared by means of their associated propositions.
A syntax-driven semantic analysis is used to get the atomic propositions associated with a sentence. The output of the parser is used as input for the semantic analyser; from the output of the analyser, the representation of the sentence in first order logic, which is called the logic formula, can be derived.
For Akhmatova, there are many ways to describe meaning through logical form, but they are rigid and hard to produce. Because of that, a simplified representation is proposed.
The simplified representation is build from: three types of objects
Later, usign WordNet, a relatedness score between words is computed from the paths between the senses of the words, the longer the path, the lesser is the relatedness. This score together with knowledge rules are given to the automatic theorem prover OTTER.
If for every proposition in the hypothesis sentence
2.3 Abduction
Raina et al. [17] begin constructing a syntactic dependency graph using a parser, hand written rules are used to find the heads of all nodes in the parse tree. The relations represented in the dependency graph are translated into a logical formula representation. Each node in the graph is converted into a logical term and it is assigned a unique constant.
Later, abductive theorem proving is realized by the resolution method, where each abductive assumption, and its degree of plausabilty is quantified as a nonnegative cost using the assumption cost model. The objective is to find the proof of minimun cost, which is chosen automatically by a machine learning algorithm.
2.4 Vampire and Paradox
The approach of Bos and Markert [4, 5] is based on what they call shallow semantic analysis and deep semantic analysis.
Four features are obtained from the shallow semantic analysis, the overlap between words in text and hypothesis, the length of text, the length of hypothesis, and the relative length of hypothesis with respect to the text.
To achieve the deep semantic analysis, they use a robust wide-coverage parser, which produces proof trees of Combinatory Categorial Grammar [19]. Afterwards, the proof trees are used to build discourse representation structures, these are the semantic representations from Discourse Representation Theory. Later, the semantic representations are translated into first order logic expressions.
The model checker Paradox and the automatic theorem prover Vampire are used to prove wheter or not the text implies the hypothesis. Bos and Markert take two features from the automatic theorem prover, and six from the model checker.
A decision tree is trained with the twelve features, and it is used to decide if the text implies the hypothesis.
2.5 Natural Logic
MacCartney and Manning [13, 12] use Natural Logic to avoid logical forms, their system is called NatLog. They begin with a linguistic pre-processing, the text and the hypothesis are parsed with the Stanford parser, the main purpose of this step is monotonicity marking; nevertheless, they do not use polarity (see section 3) as an inference mechanism.
The second step consists of an alignment between the text and the hypothesis, alignments are represented by sequences of atomic edits over words.
Finally, taking as features the monotonicity infromation and the sequences of edits, a decision tree is trained.
2.6 Brief Analysis of the Methods
As it can be seen in Table 1, the methods based on some inference mechanism use first-order logic (FOL) as a form to represent the text and the hypothesis.
Table 1 Summary of the main characteristics of some logical approaches
| First author | Inference Mechanism | Logic | BK | Challenge | Decide by |
|---|---|---|---|---|---|
| Hodges | COGEX | FOL | WordNet | RTE-2 | Optimization |
| Akhmatova | OTTER | FOL | WordNet | RTE-1 | Unclear |
| Raina | Abduction | FOL | RTE-1 | Machine Learning | |
| Bos | Vampire and Paradox | FOL | WordNet | RTE-1 | Machine Learning |
| MacCartney | WordNet | RTE-3 | Machine Learning |
For us, it is unclear the decision mechanism that follows the system of Akhmatova, a relatedness score is computed, but its role in the decision process is never mentioned.
The other methods use a decision process different to the inference mechanism, as it has been explained, hiding why the entailment was not carried out.
3 Natural Logic
Sánchez in his Ph. D. dissertation [18] formalizes the ideas of van Benthem about Natural Logic and monotonic reasoning [20, 21]. Even though the origins of Natural Logic go back to Aristotle [22, 11]; the central idea, in the program of Natural Logic of van Benthem et al., is that natural language, besides communicating ideas, serves to reason without having to use formal systems, as predicate calculus or high order logics. The idea is to use the syntactic structure of a sentence, semantic properties of their lexical constituents, and a functor constructor.
According to Icard and Moss [10], van Benthem [20] and Sánchez [18] define proof systems to reason about entailment using monotonicity in high order languages.
Both van Benthem and Sánchez use, for the syntactic analysis of a sentence, a version of categorial grammars called calculus of Ajdukiewicz [1, 3, 14]. This is based on basic types
Definition 3.1. The calculus of Ajdukiewicz. The categorial language of the calculus of Ajdukiewicz ℒℒ is given by:
The unique inference rule in the calculus of Ajdukiewicz takes the form:
and it does not matter if the type
It is assumed that each word in the lexicon has a type, for example: common nouns have type
Hence to know whether a sentence is well formed, the inference rule (1) is used to build a proof tree, if its root is
Nevertheless, as there are words that play different roles (for example, white could either be an adjective, or a noun, or a verb), if a sentence contains words of this kind, the algorithm that constructs the proof tree for such a sentence would have to try with the different types of each word until the type
We have a proof tree in Figure 1 for the sentence Dobie didn’t bring every ball. In this figure, it is worth noting that: the type of every has its first argument on the right; the type of every ball has its argument on the left; the type of Dobie has its argument on the right, and the type

The first semantic element of Natural Logic is that each type denotes a set, hence
Definition 3.2. Partial order relations. Partial order relations on the denotations of types can be defined in the following way:
If
If
If
The second semantic element of Natural Logic is that working with a proof system based on functors, and taking into account a partial order relation on each type, it is possible to define static characteristics on functors, namely a functor can be either upward monotone, or downward monotone; obviously a functor can also be non-monotone, according to the following terms [8]:
Definition 3.3. Monotonicity. A function
for all
for all
As it has been stated, the inference rule (1) must be applied to construct a proof tree, therefore a functor node and an argument node are required. The resulting node will serve as either the functor node, or the argument node to construct the following level of the proof tree. In this way, the construction of a proof tree is done by composing functors: if an upward (downward) monotone functor
Table 2 Result of the composition of upward monotone
| ○ | + | − | · | |
| + | + | − | · | |
| − | − | + | · | |
| · | · | · | · |
From Table 2 we can infer that the composition of
In terms of the proof tree of a sentence, a functor node that is upward monotone will have positive polarity if it is the argument of a composition where an even number of downward monotone functors are involved, otherwise it will have negative polarity.
On the same terms, a functor node that is downward monotone will have positive polarity if it is the argument of a composition where an odd number of downward monotone functors are involved, else it will have negative polarity.
Once the polarity of a node
In order to compute the polarity of the elements of a sentence, the following clause is added to definition 3.1.
If
This clause does not belong to the calculus of Ajdukiewicz, it has been included to mark either the upward monotonicity of a functor from
So that, it is supposed that the lexicon contains the information of monotonicity that some functors require, as shown below:
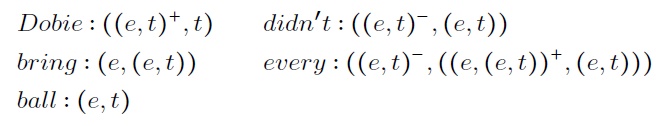
As an example, we have the proof tree in Figure 2a with lexical monotonicity marking for the sentence Dobie didn’t bring every ball.

Fig. 2 The two steps to compute polarity with the algorithm of van Benthem, for the sentence Dobie didn’t bring every ball
Once the proof tree has lexical monotonicity marks, the algorithm of van Benthem begins marking the root of the proof tree with polarity +, then if the functor in turn is upward monotone, the polarity mark is propagated. In case that the functor is downward monotone, then the polarity mark of the argument is reversed, because a downward monotone functor reverses the order relation of the elements of its domain. Figure 2b exemplifies Algorithm 3.1 for the sentence Dobie didn’t bring every ball.
Algorithm 3.1. van Benthem polarity algorithm
Label the root with +.
Propagate notations up the tree.
If a node of type
If a node of type
To know when a sentence
Definition 3.4. Subexpression. Let
Example 3.1. Let
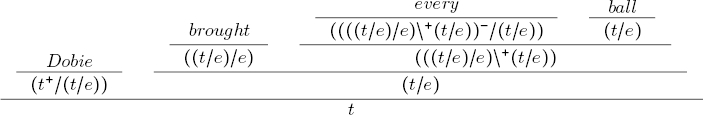
When we say that
Definition 3.5. Entailment on the same subexpression. Let
4 Automatic Theorem Proving for an Extension of AB Grammars
We are going to extend a version of categorial grammars called AB grammars [14]; in this extension, types are constructed by
As it has been stated, to prove that a natural language expression is well formed (it is a sentence), a proof tree with root
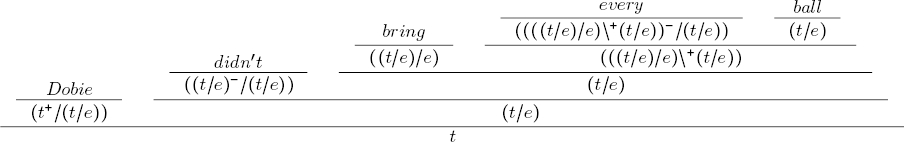
A natural language expression
As it is known, there are natural language expressions that admit more than one syntactic analysis. Evenmore, sometimes it is possible to use the inference rules in more than one pair of adjacent words.
Hence, we need to look for those pairs of words that may conform the initial subtrees of possible proof trees. Also, for each initial subtree we need to know the list of pairs
For example, for the proof tree in Figure 4 its unique initial subtree is

The algorithm BFSTL has three input parameters:
In general (line 10), if some inference rule can be applied to
If no rule can be applied (lines 15 and 16), a recursive call is made indicating that a word has been processed, and leaving
If no environment was found (lines 2 and 6) then the
The algorithm BAWPT builds a proof tree from a list of environments. If the list of environments is not empty (lines 4 and 5), then the algorithm BAPT is called with the elements of the first environment in the list, and the type of the root of the first subtree (line 6).

If the algorithm BAPT could not build a proof tree, then a recursive call is performed with the rest of the list of environments (lines 8 and 9). If the algorithm BAPT built a proof tree, this is returned (line 10). If the environment list is empty, then it was not possible to build a proof tree and the exception
The algorithm EXTRACTYPE merely returns the root of a unary tree (lines 2 and 3), or the root of a binary tree (lines 4 and 5). This is used in line 6 of the algorithm BAWPT.

The purpose of the algorithm BAPT is to build a proof tree. It takes four arguments: the list
If
If

If it was not possible to build a new proof subtree, then the tree
If
If
Finally, the algorithm BUILDPROOFTREE passes the appropriate initial values to BFSTL in order to get a list of environments, this list is passed to BAWPT, which constructs a proof tree.

5 Automatic Theorem Proving for Natural Logic
To compute polarity in our extension to AB grammars, the algorithm of van Benthem is adapted as follows.
Algorithm 5.1. van Benthem’s polarity algorithm adapted to an extension of AB grammars.
Label the root with +.
Propagate notations up the tree.
(a) If a node of type
(b) If a node of type
As an example with have the proof tree of Figure 5a.

Fig. 5 Proof trees with polarity marks using the adapted algorithm of van Benthem in an extension of AB grammars
The algorithm POLALG encodes the algorithm of van Benthem more precisely. It returns a proof tree with polarity marks. Its arguments are: the polarity label

If the current tree is a unary tree, then it returns a unary tree marking the root with
If the current tree is a binary tree and the functor is the left subtree, then it recursively propagates the polarity
If the current tree is a binary tree and the functor is the right subtree, then it recursively propagates the polarity
The algorithm POLARITY returns a proof tree with polarity marks, it receives as argument the representation of a natural language expression

Example 5.1. A proof tree with polarity marks for the natural language expression An elk ran is shown in Figure 5b.
If
Example 5.2. If
Finally, we want to define an automatic theorem prover, to get this it is needed to chain entailments on more than one subexpression, this is done in the following way:
Definition 5.1. Entailment. Let
Now, we define the algorithms ENTAILS, ENTAILSALL, and ENTAILSONE.
The algorithm ENTAILS has as input the natural language expressions

ENTAILSALL tries to find counterexamples to the entailment of two natural language expressions. The algorithm ENTAILSALL codes Definition 5.1, it takes two parameters as input:
As it is implicit in Definition 3.5, a natural language expression

Hence, the main purpose of ENTAILSALL is to process a pair
If ENTAILSONE does not fail, then a recursive call is performed (line 16) removing the pair
If subexpressions
When each pair of DifSub has been processed, the result of ENTAILSALL has to do with whether or not counterexamples have been found (lines 1 and 2).
The algorithm ENTAILSONE codes almost directly Definition 3.5, it takes subexpressions

To implement an automatic theorem prover, lexicons having pairs
The C & C tools [6] have a POS tagger, but it uses the inference rules of Combinatory Categorial Grammars, and there is not an algorithm to compute polarity for these kind of grammars, actually the known algorithms to compute polarity only work with Categorial Grammars which have the inference rules
There are no domains partially ordered as it is supposed in section 3, therefore it is not possible to check if
6 Examples
At this time, we have a prototype that constructs possible counterexamples for the pair text-hypothesis of natural language expressions. It is implemented in Moscow ML version 2.10, for what has been discussed previously, the prototype asks the user for the veracity of the constructed relationships in the entailment process.
Example 6.1. An elk ran ⊢ An animal moved

This exemplifies that a very specific statement can be generalized at the extreme that it loses information. Nevertheless, the entailment is true.
Example 6.2. Dobie brought every ball ⊢ Dobie brought every black ball

In this case we have the role of ”every” that is downward monotone on its first argument, therefore it sets the polarity of ball to negative. Hence it can be replaced with black ball that is a lesser expression. The entailment is true.
Example 6.3. Dobie didn’t bring every ball ⊢ Dobie didn’t bring every black ball

In this case the verb is negated, therefore it changes the polarity of the following constituents. Hence, the prototype asks if ball is a kind of black ball, i.e, if ball is lesser than black ball. Thence the entailment is false.
Example 6.4. Don’t dig your grave with your own knife ⊢ Don’t trench your grave with your own penknife. For this example, refer to Figure 6.

Fig. 6 Proof tree with polarity marks for the sentence Don’t dig your grave with your own knife, in this tree

If WordNet is consulted we find that trench is a direct troponym of dig. Also, that penknife is a hyponym of knife. The entailment is true.
Example 6.5. Don’t dig your grave with your own knife ⊢ Don’t trench your hole with your own penknife

penknife is a hyponym of knife, trench is a direct troponym of dig, but hole is an hypernym of grave, it is not an hyponym. The entailment is false.
7 Conclusions and Future Work
We have developed an Automatic Theorem Prover for Natural Logic to Recognize Textual Entailment; this includes algorithms to: construct proof trees as the syntactic part of Natural Logic; compute polarity as the base of reasoning in Natural Logic; and look for subexpressions that falsify the entailment process.
The main advantage of the Automatic Theorem Prover is that it provides the list of counterexamples (pairs of subexpressions of the same type) that do not allow the entailment between two natural language expressions. As a consequence, the scope of Natural Logic in Recognizing Textual Entailment is restricted to pairs of expressions having the same syntactic structure.
As future work, in order to widen the scope of Natural Logic to Recognize Textual Entailment, it is desirable to be able to compare subexpressions of similar types; for example, the type of nouns is similar to the type of noun phrases.
Other points on the agenda for future work are: to construct lexicons where the words are associated with their types, to define an algorithm to compute polarity for Combinatory Categorial Grammars, and to build interfaces to take advantage of resources such as WordNet, and BabelNet.
We wish to thank anonymous reviewers for their comments, which helped improve the present manuscript.

