











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
In sentiment analysis, aspect extraction aims to extract attributes of entities called aspects that people express in their opinions [15]. In social media context, users actively communicate in a mix of multiple languages, thereby generating large content of code-mixed data [7]. Since such data occurs as random mix of words in different languages, context is spread across languages and therefore semantic interpretation gets difficult and can be resolved only by explicit language identification systems [4, 28]. However, it is computationally intensive and practically infeasible to find or build translation tools and parallel corpora for each language pair in the code-mixed data. Therefore, we are interested in designing an automatic process for language independent retrieval of aspects from code-mixed data, without an aid from parallel corpora or translation resources. Also, the useful topics of information are highly dispersed in the high dimensional code-mixed social media content.
Therefore there are two key challenges:
Extraction of useful aspects from code-mixed social media data across the language barrier.
Making the aspect extraction fault tolerant and coherent by addressing semantics while grouping them.
In the existing literature, two models have been highly recommended - Probabilistic Latent Semantic Analysis (PLSA), [10] and Latent Dirichlet Allocation (LDA), [5]. Both the models infer latent ‘topics ’from ‘document ’and ‘word’. In [2], the authors proposed code-mixed PLSA which is based on co-occurrence matrix for representation of code-mixed words from chat messages and is modeled on PLSA for aspect discovery. However, the work carried out by using PLSA and LDA in monolingual context, resulted in extraction of some incoherent aspects [6]. Considering the code-mixed content, [2] attributed the issue of inclusion of incoherent aspects (aspects placed in incorrect topic clusters), in the output to the noisy, un-normalized and out of context words. In this paper we handled this issue in two steps: first, use of shallow parser [27], to obtain normalized output at the pre-processing stage and second, associating semantics to language independent word distributions in Latent Dirichlet Allocation (LDA) algorithm [5], for retrieval of coherent latent aspects. Therefore, the need for improvement in coherence of aspect clusters has been addressed using multilingual synsets.
In our system multilingual synsets are extracted from freely available lexicographic dictionary called BabelNet [21]. The multilingual synsets for two sample words, one in English and the other in Hindi is shown in Fig. 1, and these are coherently related in lcms-LDA based on semantic similarity.

In summary, our work makes the following contributions:
— Automatic extraction of useful aspects from code-mixed data by learning from language independent monolingual word distributions.
— Improvement in coherence of clusters by shifting from merely statistical based co-occurrence grouping to semantic similarity between words.
The structure of the paper is as follows: Section 2 illustrates related work in aspect extraction and related issues; Section 3 describes the proposed model; Section 4 presents experimental results with explanation on how aspects are extracted from code-mixed text and comparative evaluation of lcms-LDA with the state-of-the-art techniques for code-mixed aspect extraction; finally, Section 5 presents concludes the paper.
2 Related Work
Social media is a source of huge amount of opinion data on the web. In multilingual countries, people on social networking forums, often communicate in multiple languages, both at conversation level and at message level [14]. Majority of such conversational data is informal and occurs in random mix of languages [7]. When this code alternation occurs at or above the utterance level, the phenomenon is referred to as code-switching; when the alternation is utterance internal, the term ‘code-mixing’is common [4, 8] constructed social media content code-mixed in three languages Bengali(BN)-English(EN)-Hindi(HI), from Facebook comprising of 2335 posts and 9813 comments.
Annotation at different levels of code-mixing were provided which included sentence-level, fragment-level and word-level tagging. Dictionary based methods of classification were compared with supervised classification methods namely Support Vector Machine (SVM) and sequence labeling using Conditional Random Field (CRF), with and without context information [4], concluded that word-level classifier with contextual clues perform better than unsupervised dictionary based methods. The large volume of code-mixed data on the web has introduced several new challenges and opportunities in tasks like capturing opinions of general public.
Today, sentiment analysis has become a specialized research area finding increasing importance in commercial applications and mining business processes, by virtue of its task of processing opinion data. In the process, aspect extraction plays a fundamental role which aims at extracting the aspects of an entity in a domain on which opinions have been expressed [11, 15, 22, 25]. Traditionally opinions can be expressed at document level, sentence level and aspect level [15]. To maximize the value from the opinions we need to process opinions at the fine grained level of granularity. So we chose to work at the aspect level. Fundamentally, the task of aspect based opinion analysis comprises of identifying and extracting aspects of an entity in a domain in which opinions have been expressed [15].
With very large volume of noisy code-mixed social media data, we find that useful information is highly dispersed and therefore is to be conveyed through latent semantic aspects. Researchers have successfully used topic models for the purpose of latent aspect extraction and grouping in the form of soft clusters [19,20,29]. Probabilistic Latent Semantic Analysis (PLSA) [10] and Latent Dirichlet Allocation (LDA) [5], are recommended unsupervised topic modeling methods for aspect extraction and grouping in multilingual context [30]. Each topic is distribution over words with their associated probabilities and each document is distribution over topics.
[30] put forth that an improved topic representation with language independent word distribution works better on text representations that contain synonymous words. Topic models have showed success in tasks like sentiment analysis [17, 29], word sense disambiguation [13] and modeling similarity of terms [5, 13]. However, all this work has addressed monolingual data and at the most parallel bilingual data. We specifically followed the use of probabilistic topic models in multilingual context since most of the social media content consists of random occurrences of words in code-mixed form.
[23] proposed code-switched LDA (cs-LDA), which is used for topic alignment and to find correlations across languages from code-switched corpora with datasets in English-Chinese and English-Spanish. cs-LDA learns semantically coherent topics over LDA as judged by human annotators. However, content analysis in social media like Twitter pose unique challenges as posts are short and written using multiple languages [26]. They used topic modeling for predicting popular Twitter messages and classifying twitter users and corresponding messages into topical categories. In addition, code-mixed chat data has non-standard terminology which makes the semantic interpretation of aspect clusters challenging.
[3] introduced a method for extracting paraphrases that used bilingual parallel corpora. Using automatic alignment techniques from phrase based statistical machine translation, they show how paraphrase in one language like English can be identified using a phrase in another language as a pivot, conveying the same information. They evaluated the quality of obtained paraphrases and concluded that automatic alignment of context contributes to it.
To address the issue of coherence in topic based aspect extraction, [16] proposed a knowledge based method called Automated Knowledge Learning (AKL), using a three step process: first, LDA was run on the domain corpus, then clustering was performed on the obtained topics and finally in step 3, frequent patterns were mined from the topics in each cluster. Besides human evaluation they used topic coherence to show the improvement in precision over the baselines.
In this paper, we propose a novel LDA based algorithm for clustering code-mixed aspect terms semantically. This method termed lcms-LDA, utilizes information from large multilingual semantic knowledge base called BabelNet [21], as mentioned in [1], for monolingual representation of code-mixed words. The key aspect of our proposed framework is that it leverages augmented synsets across languages, and proposes topic distribution based on semantic similarity between the words. This knowledge is used for clustering and inference in lcms-LDA. As a consequence the proposed method results in automatic retrieval of coherent monolingual clusters from code-mixed input.
3 Proposed Model
The structure of our proposed lcms-LDA model is described here. Let V be the vocabulary with
Fig. 2, shows graphical representation of our proposed lcms-LDA model. Each circle node indicates a random variable and the shaded node indicates w, which is the only observed variable.
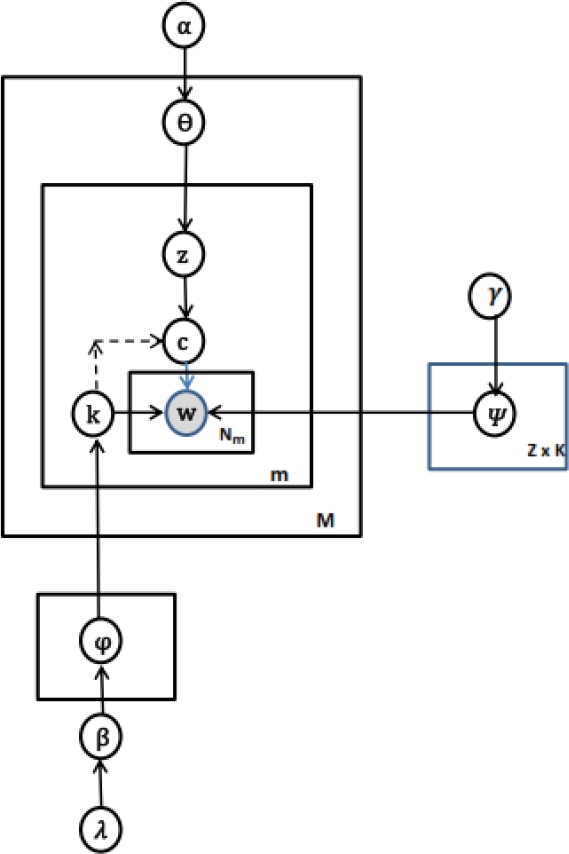
In code mixed text, input words occur in random mix of different languages due to which semantics is spread across languages. In order to automatically deal with this, λ enables augmentation of multilingual synsets as proposed in [1]. This updates values of
We performed approximate inference in lcms-LDA model using the block Gibbs sampler for the estimation of the posterior distribution of P(z|w ;
The conditional distribution of sampling posterior is given in Equation 1:
We have presented the generative process in Algorithm 1. The core aspect behind the proposed lcms-LDA algorithm is that multilingual synset knowledge from the lexical resource adds semantic similarity while word co-occurrence frequencies typically in topic models only grasp syntactic level similarity by statistical means.

Also, since multilingual synsets provide synonyms across languages, monolingual representation of aspects aids in improving the coherence of aspect clusters. Therefore, semantic similarity between words is computed by determining the quantity and quality of overlap across the multilingual synonym lists. We have presented the method in Algorithm 2.

ComputeSemSim
4 Experimental Results
In this section we first present the implementation details of lcms-LDA and then show the performance of the lcms-LDA aspect extraction framework.
4.1 Dataset Used
For the evaluation of the proposed lcms-LDA model we used FIRE 20141 (Forum for IR Evaluation), for shared task on transliterated search. This dataset comprises of social media posts in English mixed with six other Indian languages.The English-Hindi corpora from FIRE 2014 was introduced by [7]. It consists of 700 messages with the total of 23,967 words which were taken from Facebook chat group for Indian University students. The data contained 63.33% of tokens in Hindi. The overall code-mixing percentage for English-Hindi corpus was as high as 80% due to the frequent slang used in two languages randomly during the chat [7].
As stated in [29], topic models are applied to documents to generate topics from them. The key step in our method is clustering similar code-mixed words co-occurring in the same context. According to [9], the words occurring in the same context tend to be semantically similar.
The key step in our method is introduction of cluster variable c in lcms-LDA model which groups code-mixed words semantically i.e words co-occurring in the same context. Such words across the languages with similar probabilities belong to the same topic and words with different probabilities are distributed across topics. Since implicitly context is closely shared with a message, we treat each code-mixed message independently. This representation is suitable for us as the word semantic similarity first resolves context at the message level.
In Fig. 3, we demonstrate an example of two topic clusters to show the effect of c. The two sets of words in Fig. 3, show two sample topic clusters formed by top aspects based on the probability of occurrence. The first cluster in Fig. 3, shows a topic cluster with c disabled and the second cluster indicates the aspects clustered with c enabled. In Fig. 3, each aspect is separated by a semi-colon followed by the respective probability of occurrence shown in italic font.

Fig. 4 shows the sample clusters generated by lcms-LDA.

4.2 Data Pre-Processing
In our proposed lcms-LDA model, our objective is to address coherence of aspects, which basically clusters words that are semantically related irrespective of the language in which they are written. At the pre-processing stage we address this need by employing shallow parser [27] and obtain the normalized output. We then used POS tagger by [24], to obtain POS tag of each word. Since our data has random mix of words in different languages, we tagged such words based on the context of the neighboring words. We addressed noise words by eliminating stop words2 for Hindi and English.
4.3 Results
To evaluate the proposed lcms-LDA model on the said dataset, we consider the comparison with the two baselines PLSA [10] and LDA [5]. Also, we tested the performance comparing lcms-LDA with the aspect topic distributions obtained from LDA using augmented monolingual words proposed by [1]. We refer to this output as Aug-Mono-LDA. The language independent code-mixed semantically coherent aspect topics across the chat collection is given as
First, lcms-LDA was employed on the dataset described in Section 4.1. Then each message of the said code-mixed chat corpus, after pre-processing was computed as aspect topic distribution based on semantic coherence. It should be noted that work in [1] only described the discovery of language independent aspects and did not include semantics for coherence improvement of aspect clusters. To the best of our knowledge this is the first work addressing extraction of language independent aspects from code-mixed input.
We compare the proposed method with the language independent aspect [1], based LDA. Thus obtained aspect clusters called Aug-Mono clusters indicate augmented monolingual clusters in English or Hindi language of bilingual Hindi-English code-mixed corpus. Their topic distributions are computed on monolingual words based on co-occurrences. We used this method for comparison as we are interested in evaluating coherence by comparing aspect clusters based on semantics against statistically obtained clusters. We evaluate our approach over this system in terms of both aspect cluster interpretibility as well as distinctiveness. Both these measures contribute towards evaluation of the quality of topic aspect semantic coherence [18].
The Kullback Leibler (KL) divergence measure [12] offers symmetrical KL-Divergence score for comparing distributions. We compared distinctiveness of the aspects clustered in topic distributions produced by [2] and we referred to the same as Code-Mixed PLSA (CM-PLSA). We computed KL-Divergence score for all symmetric combinations and averaged it across all the clusters in a topic. We recorded the scores for different values of
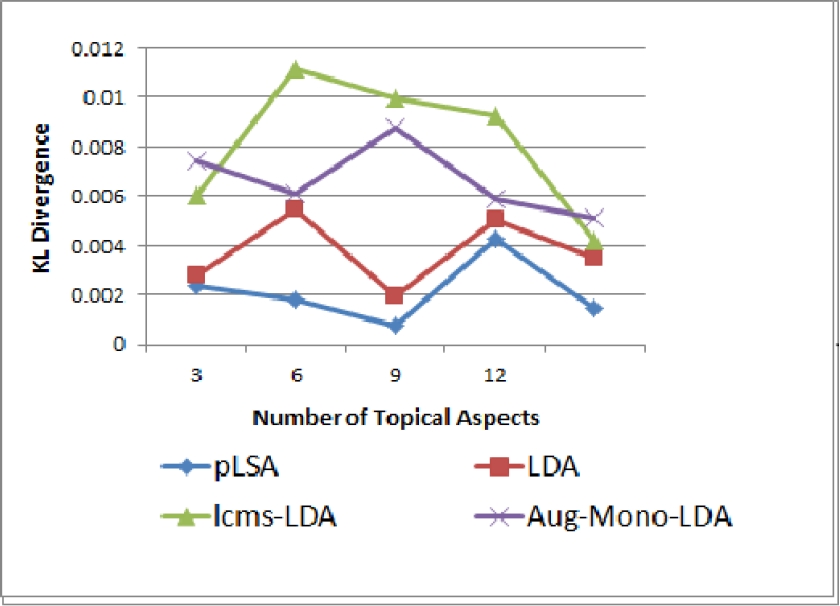
From Fig. 5, we observe that the KL-divergence for lcms-LDA is maximum at
However, as compared to all the models lcms-LDA generates higher distinctiveness and therefore semantics helps in improvement of coherence of aspects resulting in better topic association. The drop in distinctiveness for higher values of
We evaluate the coherence of aspect clusters by yet another standard measure called UMass score. The UMass coherence score is computed by pairwise score function measuring empirical probability of common words [18].
Fig. 6 shows testing for topic interpretibility of topics in each topic cluster. It is maximum at

On the semantic evaluation of the words participating in a cluster, we observed that the chat data resulted in inclusion of many ungrammatical words and words which were not nouns. Therefore, with increasing size of the cluster the topic interpretibility is observed to have decreased.
5 Conclusion
Active interaction of people on the web through social networks and online text forums is increasingly becoming popular as it encourages communication in random mix of languages. As a consequence, tremendous amount of code-mixed data having interesting patterns of interest hidden in it is generated. Sentiment analysis tools generally working on opinion data is always hungry for extraction of useful aspects which are indicators of sentiments and opinions that are implicitly expressed.
In this work, we presented a novel model, termed lcms-LDA, which automatically integrates semantics in the computation of language independent representations of code-mixed words in the LDA algorithm, thus enabling semantics in code-mixed aspect extraction.
Thus, proposed language independent semantic approach to code-mixed aspect extraction, leverages knowledge from freely available in external multilingual resource, thereby introducing automatic clustering of coherent aspect clusters. Therefore, in the perspective of its application, this could be a very useful aid for code-mixed aspect based sentiment analysis.

