











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
It has long been a major goal of the natural language processing (NLP) community to enable computers to understand text as humans do. A lot of NLP tasks have been tensely studied towards this goal. Among them, questions answering carries great importance and has been a huge challenge. A question answering (QA) task is to predict an answer for a given question with regard to related information. It can be formulated as a map f : {related_text, question} → {answer} [9]. To predict the correct answer, computers are required to have a understanding of the text.
Almost all problems in NLP can be formulated as QA tasks. Some tasks, like information retrieval and dialog system, are by nature question answering tasks. Other problems, like machine translation, pos tagging, co-reference resolution and so on, can also be formulated as question answering tasks. Take the co-reference resolution for example, given a piece of text, we raise questions like “What does XX refer to?” and expect the system to give correct answers. Similarly, we can model pos tagging as a question answering task by asking “What are the parts of speech?” for each sentence.
These NLP tasks can be regarded as a special form of question answering, the closed-domain question answering, which only accepts a certain type of questions. On the other hand, open-domain question answering accepts various kinds of questions. Obviously the latter is much more closer to complete text comprehension and much more difficult to resolve than the former.
Existing work on NLP tasks that can be formulated as closed-domain question answering are highly differentiated, each designed for an (or a class of) unique task(s) with unique features and unique architectures. It is almost impossible to develop a comprehensive system which can conduct several different tasks without damaging the performance, let alone the open-domain question answering.
Though challenging, it is important and meaningful to pay attention to comprehensive systems. Resolving several different tasks under a unified scheme is to some extent, closer to how humans process languages. It differs from previous work in that comprehension of text is needed to serve as the basis for answering various questions.
As we know, the work employing machine learning models for natural language processing normally involves two steps: feature representation and modelling. Feature representation converts text into features which can be easily computed by the model. Models are then designed accordingly to process the input features and generate the desired output. Developing a comprehensive system with a unified scheme faces challenges in both aspects: we have to develop a kind of feature representations which is capable of representing all the information contained in text as different tasks may need different information, and develop a model which is capable of paying attention to different aspects of the information carried by features with regard to the problems raised and generating the desired results. The two challenges are to be met and overcome towards a comprehensive system.
Now with the deep neural networks, it becomes not only possible, but also probable to develop such a multi-purpose system in a unified scheme. All deep learning models rely on distributed representations representing various features as vectors. These vectors are believed to have encoded all the semantic and syntactic information in themselves. By replacing the various features used in traditional models with vector representations, we can solve the problem of feature representations. But existing deep neural network models are often developed for a certain problem or a certain class of problems. In other words, they are in no sense different from traditional methods in being highly differentiated. To fully explore the potential of distributed representations and the neural networks, we introduce a novel model named the entity-based memory network. Entities refer to anything that exist in reality or are purely hypothetical. We assume that text can be projected to a world of entities. The key of conducting comprehension and reasoning over text is to identify its containing entities and analyse the states of these entities and the relations between them. The entity-based memory network we proposed is capable of keeping a memory of entities conducting selection when answering questions.
The proposed model is tested on several datasets, including the bAbI dataset [22], large movie review dataset [11] and the machine comprehension test dataset [14]. Results show we have achieved satisfying results using the entity-based memory network. The rest of the paper is organized as follows: Section 2 describes our approaches and elaborates the details. Section 3 reviews previous work that uses memories. Section 4 presents the experiments and the analysis. Section 5 concludes the paper.
2 Approaches
2.1 Overview
Firstly we use an example to illustrate the model. Table 1 shows a piece of text.

This piece of text contains 4 sentences and 2 questions. There are 7 entities in total, all of them underlined. This text is elaborated around the 7 entities. It describes how their states change (i.e., the change of a character’s location) when the story goes on. Note that here all the entities are concrete concepts that exist in reality. It is also possible to talk about abstract concepts.
The core of the proposed model are entities. Take the text shown in Table 1 for example. We take Sentence 1
(S1) as input and extract the entities it
contains {Mary, bathroom}. Vectors representing the states of these entities are
initialized using some pre-learnt word embeddings 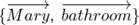 and stored in a memory pool.
Meanwhile, we turn S1 into a vector
and stored in a memory pool.
Meanwhile, we turn S1 into a vector  using an autoencoder model
or other models depending on your preference. Then we use the sentence vector
using an autoencoder model
or other models depending on your preference. Then we use the sentence vector
 to update
the entities’ states
to update
the entities’ states  . The goal is to reconstruct
solely from
. In the same
way, we process the following text (S2) and its
containing entities (John, hallway) until encounter a question (S3). S3 is
converted into a vector
. The goal is to reconstruct
solely from
. In the same
way, we process the following text (S2) and its
containing entities (John, hallway) until encounter a question (S3). S3 is
converted into a vector  following the same method
that processes previous input text. Then taking
following the same method
that processes previous input text. Then taking  as input, we retrieve
related entities from the memory which now stores all the entities (Mary,
bathroom, John, hallway) that appear before S3. The
related entities’ states are then used to produce a feature vector. In this
case, (Mary and bathroom) are related to the question and their states are used
for constructing the feature vector. Note the states of these entities now are
different from their initial values due to S1. Based
on the feature vector, we then use another neural network model to predict the
answer to S3.
as input, we retrieve
related entities from the memory which now stores all the entities (Mary,
bathroom, John, hallway) that appear before S3. The
related entities’ states are then used to produce a feature vector. In this
case, (Mary and bathroom) are related to the question and their states are used
for constructing the feature vector. Note the states of these entities now are
different from their initial values due to S1. Based
on the feature vector, we then use another neural network model to predict the
answer to S3.
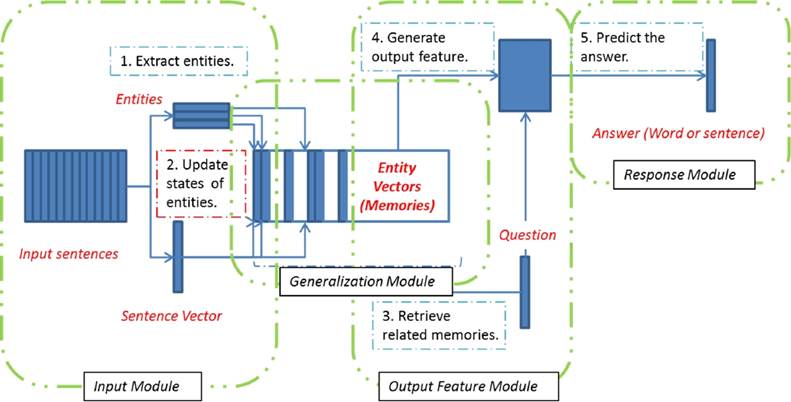
The model monitors the entities involved in text and keeps updating their states according to the input. Whenever we have a question with regard to the text, we check the states of entities and predict an answer accordingly. The proposed model comprises of 4 modules, as is shown in Fig. 1. Each module is designed for a unique purpose and together they construct the entity-based memory network model.
I: Input module. Take as input a sentence and turn it into a vector. Meanwhile, extract all the entities it contains. The question is also processed using this module.
G: Generalization module. Update the states of related entities according to the input. Create a new memory slot for entities that are not contained in the memory pool.
O: Output feature module. It is triggered whenever a question arrives. Retrieve related entities according to the input question and then compose an output feature vector accordingly.
R: Response module. Generate the response according to the output feature vector.
2.2 Entity-based Memory Network Model
Here we present a formal description of the proposed model. Assume we have text S1, S2, ...Sn whose entities are annotated in advance as e1, e2, ..., em.
Input Module We firstly turn each sentence Si into its vector representation:
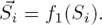 (1)
(1)
Generalization Module For a sentence Si, we collect all the entities it contains
 . These
entities’ states
. These
entities’ states  are simultaneously updated according to
are simultaneously updated according to 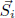 as follows:
as follows:
 (2)
(2)
f2 is to reconstruct only using the states of
Si’s containing entities . are updated to minimize the
difference between 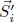 and . Recall
that is
generated using f1 with the whole sentence
Si as input. We compress the information
carried by Si into a vector and then unfold it into
.
and . Recall
that is
generated using f1 with the whole sentence
Si as input. We compress the information
carried by Si into a vector and then unfold it into
.
After processing the sentences, we construct a memory pool which consists of entities whose states are regarded as capable of representing the information carried by the input text.
Output Feature Module Question q is turned into a vector  and then
and then 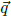 is used to retrieve related
entities from the memory pool.
is used to retrieve related
entities from the memory pool.
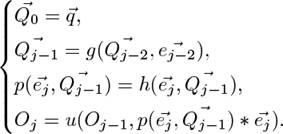 (3)
(3)
 is the
probability (or score) of ei being selected to
compose the feature vector for answering q. In
is the
probability (or score) of ei being selected to
compose the feature vector for answering q. In 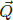 , we consider the entity
selected in the previous iteration. is kept updated using
, we consider the entity
selected in the previous iteration. is kept updated using
 and
p. O* is the output feature
vector.
and
p. O* is the output feature
vector.
After several iterations, we use the final Om as the output feature vector O. Note that if the O* does not change much between iterations, we will omit the remaining entities. This early-stop strategy helps reduce the time cost.
Response Module Then we decide the answer which is usually one word using a(q) = v(O). a(q) produces a vector whose each item corresponds to one word in the vocabulary. a(q)i indicates the probability of wordi being used as the correct answer. We choose the one with the highest probability. As stated, models like recurrent neural network can be used to output a sentence.
2.3 Implementation
This is a supervised model and requires annotated data for the training. The annotated data contains the input text, questions and answers. Also we need all the entities and entities that are related to the answer labeled.
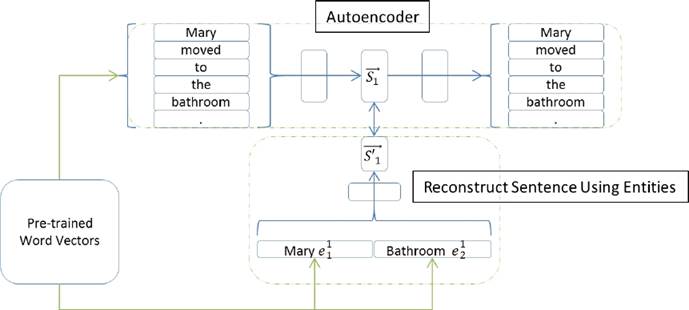
Fig. 2 The Generalization Module: Using S1 as an example, the autoencoder is used to convert the sentence into a vector and the entities contained in S1 are used to reconstruct the sentence vector
We define the function form for training as follows: As for f1, many models, like the recurrent neural network, recursive neural network and so on [12, 17, 8], can be used to convert a sentence into a vector. Here we use an Long Short-Term Memory (LSTM) autoencoder [10] which takes a word sequence as input and outputs the same sequence.
f2 takes a list of entity states as input and tries to
reconstruct . We
use the Gated Recurrent Unit (GRU) [2]:
 (4)
(4)
a GRU can be represented as the follows:
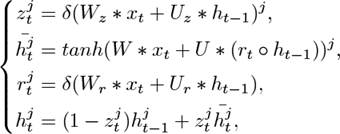 (5)
(5)
◦ represents an element-wise multiplication. z and r are two gates controlling the impact of historical h on the current h. The GRU takes x as input and updates the state of the neuron h. Compared with LSTM, it simplifies the computation while still keeps a memory of previous states. Therefore it takes less time to train.
Our goal is to minimize the loss  . Using the stochastic
gradient descent, we are able to train f2 and also
update . The
input module and the generalization module do not interact with the remaining.
Thus they can be trained in advance.
. Using the stochastic
gradient descent, we are able to train f2 and also
update . The
input module and the generalization module do not interact with the remaining.
Thus they can be trained in advance.
The output feature module checks the memory pool repeatedly to select entities to form a feature vector:
 (6)
(6)
To generate the final answer, we use a simple neural network which takes the feature vector O as input and predict a word as output. pw = v(O) = softmax(tanh(W' * O + b)). The word with the highest probability is selected. Suppose a sentence is to be generated, we use the GRU to update O and then generate the sentence {w*} as follows:
 (7)
(7)
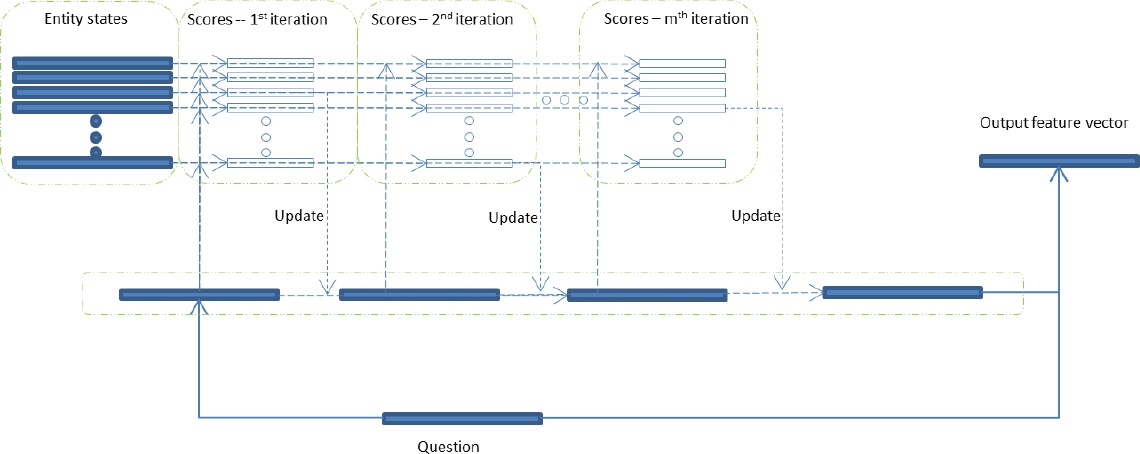
Fig. 3 The Output Feature Module: In each iteration, entities are assigned different scores which indicate their importance in constructing the output feature vector
Similar to [23], we use the stochastic gradient descent algorithm to minimize the loss function shown in Equation 2.3 over parameters. For an input Si and a given question q annotated with the correct answer wordk and related entities {ecj}, the loss function is as follows:
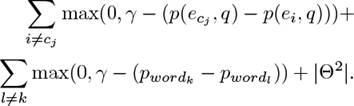
Here γ is the margin and |Θ2| is the squared sum of all parameters which is used for regularization. Note that Θ does not include parameters of f1 and f2. Their parameters and states of entities are learnt as described in Section 2.2. Word vectors used to initialize entity states and words in autoencoder come from GloVe [13]. The dimension is set to be 50.
2.4 Data Annotation
The model requires entities to be annotated in advance. In this work, we treat each noun and pronoun as an entity. Different words are regarded as different entities. This strategy saves us the effort of entity resolution which is a challenge for many languages. It also makes possible the application of the proposed model towards the task of entity resolution.
For datasets with related entities annotated, we can use the loss function described above. But annotating the related entities is time and labour costing. Most datasets available are not annotated. The weakly supervised learning can be applied to such data by trimming the loss function to 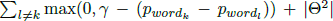 . For unannotated data, a fully supervised training is also possible if we regard entities contained in questions as related entities or if we can use other methods to identify entities that are believed to be related.
. For unannotated data, a fully supervised training is also possible if we regard entities contained in questions as related entities or if we can use other methods to identify entities that are believed to be related.
3 Memories in Deep Neural Networks
The model presented above is novel in considering historical entities. Taking more information to consideration for a task generally leads to better results. For example, RNN takes a sequence, instead of just separate words, as input, and hence is able to produce better representations for sentences. The modified version of RNN, LSTM, capable of keeping a memory of historical input, is proven more effective in handling long-distance dependency than RNN.
3.1 Memory at Neuron Level (LSTM & GRU)
The long short-term memory network (LSTM) is regarded as an improvement of the traditional recurrent neural networks (RNN). LSTM provides us with an efficient method to process information over extended time interval.
In the back-propagation of a recurrent neural network, the gradient is multiplied a large number of times (as many as the number of time steps) by the weight matrix which connects neighbouring layers in the model. This means that, the magnitude of weights in the transition matrix can have a strong impact on the learning process. If the weights in this matrix are small, it can lead to the gradient vanishing problem, making more difficult the task of learning long-term dependencies in the data. On the other hand, if the weights in this matrix are large, it can lead to a situation where the gradient signal is so large that it can cause learning to diverge. This is often referred to as exploding gradients.
To address this problem, researchers introduce the long short-term memory cells in neural network models [4]. A long short-term memory cell is composed of four main elements: an input gate, a neuron with a self-recurrent connection, a forget gate and an output gate. The input gate controls the impact of the input value on the state of the memory cell and the output gate controls the impact of the state of the memory cell on the output. The self-recurrent connection controls the evolution of the state of the memory cell and the forget gate decides whether to keep or reset the histories of the memory cell’s states. These elements serve different purposes and work together to make LSTM cells much more powerful than traditional neural cells. LSTM is widely used in various tasks in NLP and other machine learning fields [16, 19, 20, 3].
LSTM, as is shown in Fig. 4 [2], uses additional memory units to control the gates. It increases the complexity of the neural networks. The Gated Recurrent Unit (GRU) simplifies the structure and reports performance on par with LSTM but costs less time to train. An empirical analysis of GRU and LSTM model shows that they have similar performance on sequence modeling [2]. In our model, we use the GRUs as an effective method to deal with information over time series. We have a formal and elaborated description about how to use them in our work in Section 2.
3.2 Memory at Layer Level (Memory Network)
In LSTM, the neuron looks at the input in a relatively small scale. Normally the neuron takes one word vector as input each time thus it cannot look beyond the level of words. Layer-level memory networks are designed to keep memories of sentence vectors.
The Memory Network (MNN) [23] puts historical input in a memory pool and then select related memories to answer questions. The core component is the memory pool that stores all the input sentences so that they can be retrieved later to answer questions. This model contains several neural networks which are jointly optimized according to the task. Experiments on a toy dataset show that this model is able to answer simple questions according to the input text.
Later [7] propose the Dynamic Memory Network (DMNN) which introduces the attention mechanism into the memory network model. When retrieving memories, the location of the next related sentence is predicted according to the related sentences identified in the previous iterations. Using the attention mechanism, they obtain further improvements. Some other work [18, 1] follow the work of MNN by introducing additional memory network modules. These work focus on storing sentence vectors for later retrieval with no exceptions. Most of them have been tested on the toy dataset bAbI [22] and are reported to have achieved satisfying results. When further tested on some practical tasks, these models also show the ability to produce results as good as existing state-of-the-art systems or even better results.
Compared with LSTM, memory networks which store sentence vectors as memories have the superiority of processing information from a large scale. Experiment results they reported on a series of tasks are concrete proofs. But there is also a problem with the memory networks. Taking sentence vectors as input means that it is difficult to further analyze and take advantages of relations between smaller text units, such as entities. For example, when an entity ea of sentence A interacts with another entity eb of sentence B, we have to take the whole sentences A and B into consideration rather than just focus on ea and eb. This inevitably brings about noise and damages the comprehension of text. The failure of obtaining fine-grained information prevents further improvements. That is the reason why we propose the entity-based memory network.
4 Experiments
4.1 bAbI
To verify the effectiveness of the proposed model, we conduct experiments on several datasets. Firstly, we try the proposed model on the bAbI dataset [22].
bAbI is a toy data set developed for comprehension-based question answering. The example shown in Table 1 is extracted from the bAbI dataset. It contains 20 topics, each of which contains short stories, simple questions with regard to the stories and answers. The data is generated with a simulation which behaves like a classic text adventure game. According to some pre-set rules, text is generated in a controlled context.

Previous work reports extremely satisfying results using memory networks for most topics (around 90% for most of them). However, we notice an interesting thing that all of them with no exception fail on the problem of path-finding which is to predict a simple path like ”north, west” given the locations of several subjects. Another one is the positional reasoning. The Memory Network [22] reports accuracies of 36% and 65% for the two topics. The Dynamic Memory Network [7] reports accuracies of 35% and 60%. The proposed model (Entity-MNN) reports accuracies of 53% and 67% respectively. It is still far from satisfying but the improvements on the two tasks indicates the superiority of the entity-based memory network.
Despite this, results on the toy dataset is not as convincing as that on practical tasks. Given how the bAbI data is generated, it should be very easy to achieve a 100% accuracy if we do simple reverse engineering to identify the entities and rules. The good results of memory networks, including our model, can not be solely attributed to their ability of comprehension. It may be partly due to their ability of identifying the entities and rules from text.
4.2 Large Movie Review Dataset
We further tested our model on the Large Movie Review Dataset [11], which is a collection of 50,000 reviews from IMDB, about 30 reviews per movie. Each review is assigned a score from 1 (very negative) to 10 (very positive). The ratio of positive samples to negative samples is 50:50. Following the previous work [11], we only consider polarized samples with scores no greater than 4 or no smaller than 7.
For each review, we present it as a short story and then add a question “what is the opinion?”. The answer is either “negative” or “positive”. In this way we turn this task into a question answering problem. Note that although here the answer to a question is either “negative” or “positive”, we do not put any constraints on the output.
It is treated in the same way as open domain question answering and the system is expected to learn to predict the output by itself.
We do not use the full dataset as the training takes a long time. We randomly select 10K samples (5K negative samples and 5K positive samples) for training and another 10K for test. We obtain an accuracy of 97.2% on the subset which is higher than the 89% reported by [11], 93.4% by [5] and 95% by [6] which use the same dataset though different sizes.
4.3 Machine Comprehension Test
The machine comprehension test (MCTest) dataset [14] has 500 stories and 2000 questions (MC500). All of them are multiple choice reading comprehension questions. The stories are for children so limited world knowledge is required. An additional smaller dataset with 160 stories and 640 questions (MC160) is also included in the MCtest data and used in our work.
Since the proposed model does not consider the form of multiple choice questions, we need to convert MCTest data into suitable formats firstly. When answering a multiple choice question, one is provided with several alternatives of which at least one is correct. These alternatives can be regarded as information known.
For a question, we replace the “Wh-” words using each alternative and generate new declarative sentences. These sentences are generally understandable though may not be grammatically correct. Then we use the proposed system to decide whether the generated sentences are correct or wrong. Information carried by alternatives are encoded in the newly generated sentences. However, we do not distinguish between questions with only one answer and those with more than one answers as these newly generated sentences are treated separately. In other words, all questions are treated as having multiple answers.
The MCTest contains only hundreds of stories and is usually used for test only as statistical models normally require a large amount of training data. However, we still obtain satisfying results using this dataset. Table 3 demonstrates the effectiveness of the entity-based model on the open-domain question answering dataset. We outperform the previous state-of-the-art [21, 15] on both MC160 and MC500. Note our model does not employ rich semantic features as others do, and hence is easy to be migrated to languages aside from English.

4.4 Analysis
The proposed model is designed based on the assumption that entities are the core of text. By updating the states of entities, information carried by text is encoded into entities. Thus all questions which are related to the text can be answered based on entities solely. Entities enable us to break a sentence into smaller text units and analyse text from a smaller scale. Therefore the entity-based model is more sophisticated and powerful than those based on sentences as has been proven in our experiments.
A shortcoming with such a model is that, it cannot handle text that contains very few entities. Also hidden entities are not considered. As we know, pro-drop languages, like Japanese and Chinese, tend to omit certain classes of pronouns when they are inferable. This is referred to as zero or null anaphora. The proposed model will encounter problems when dealing with such text.
5 Conclusion
This work presents the entity-based memory network model for text comprehension. All the information conveyed by text is encoded into the states of its containing entities and questions regarded to the text are answered using these entities. Experiments on several tasks have proven the effectiveness of the proposed model.
The proposed model is based on the assumption that entities can express all the information of text. In future research, we will further explore its ability by considering more components in text. not merely entities.

