











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
In many Southeast Asian countries, the literary works were mostly recorded on dried and treated palm leaves (Figure 1). The palm leaf manuscripts record many important knowledges about world civilization histories. It attracts the historians, philologists, and archaeologists to discover more about the ancient ways of life. Although the existence of ancient palm leaf manuscripts in Southeast Asia is very important both in term of quantity and variety of historical contents, unfortunately the access to their content is limited, because of the linguistic difficulties and the fragility of the documents.

In order to make the manuscripts more accessible, readable and understandable to a wider audience, an optical character recognition (OCR) system and also an automatic transliteration system are urgently needed for this kind of ancient manuscript collection. In the domain of document image analysis, the handwritten character recognition has been the subject of intensive research during the last three decades. Some methods have already reached a satisfactory performance especially for Latin, Chinese and Japanese script. However, the development of handwritten character recognition methods for other various Asian script, such as Balinese script [1], Devanagari script [2], Gurmukhi script [3], Bangla script [4], and Malayalam script [5], always presents many issues.
Moreover, to give more access to the important information and knowledge in palm leaf manuscript only with an OCR system is not enough, because normally in Southeast Asian script the speech sound of the syllable change related to some certain phonological rules. Therefore, using an OCR system which is completed by an automatic transliteration system will help to transcribe these ancient documents, and to develop the automatic analysis and indexing system of the manuscripts. By definition, transliteration is defined as the process of obtaining the phonetic translation of names across languages [6].
Transliteration involves rendering a language from one writing system to another1. In [6], the problem is stated formally as a sequence labeling problem from one language alphabet to other. A transliteration engine for transliterating the Balinese script of palm leaf manuscript to the Latin-based script is one of the most demanding systems which has to be developed for the collection of palm leaf manuscript images. It will help to index and to access quickly and efficiently to the content of the manuscripts.
For this purpose, we present in this paper an implementation of knowledge representation and phonological rules for the automatic transliteration of Balinese script on palm leaf manuscript. Many transliteration model have been proposed [6]–[9]. In this system, a rule-based engine [9] for performing transliterations is proposed. Our model is based on phonetics which is based on traditional linguistic study of Balinese transliteration.
This paper is organized as follow: section 2 gives a brief description about Balinese palm leaf manuscripts in Bali and the Balinese script. Section 3 presents the detail description of knowledge representation for the glyph segment image collection in the experimental study. The phonological rules for Balinese script transliteration is formally described in section 4. The result and evaluation of the experimental results are presented in Section 5. Finally, conclusions with some prospects for the future works are given in Section 6.
2 Balinese Palm Leaf Manuscript and Balinese Script
2.1 Balinese Palm Leaf Manuscript
In Bali, Indonesia, the palm leaf manuscripts were called Lontar. The epic of lontar varies from ordinary texts to Bali’s most sacred writings. Apart from the collection at the museum (Museum Gedong Kertya Singaraja and Museum Bali Denpasar), it was estimated that there are more than 50,000 lontar collections which are owned by the private families.
Unfortunately, many discovered lontars, part of the collections of some museums or belonging to private families, are in a state of disrepair due to age and due to inadequate storage conditions. Lontars were written and inscribed with a small knife-like pen (a special tool called Pengerupak). It is made of iron, with its tip sharpened in a triangular shape so it can make both thick and thin inscriptions. The writings were incised in one (and/or both) sides of the leaf. The manuscripts were then scrubbed by the natural dyes to leave a black color on the scratched part as text.
2.2 Balinese Script
The Balinese palm leaf manuscripts were written in Balinese script and in Balinese language, composed in the old Javanese language of Kawi and Sanskrit. Balinese language is a Malayo-Polynesian language spoken by about more than 3 million people mainly in Bali, Indonesia2. Balinese script (Aksara Bali) is a descendant of Brahmi script, and is considered to be one of the more complex scripts from Southeast Asia. The type of writing system is syllabic alphabet. The alphabet and numeral of Balinese script is composed of ±100 character classes including consonants, vowels, and some other special compound characters. Some characters are written on upper baseline (Ascender) or under the baseline of text line (Descender). Writing in Balinese script, there is no spaces between words from left to right in a horizontal text line. According to the Unicode Standard 9.03, Balinese script has actually the Unicode table from 1B00 to 1B7F. In general, in Balinese script4:
- The vowel “A” is implicit after all consonants and consonant clusters and should be supplied in transliteration, unless: (a) another vowel is indicated by the appropriate sign; or (b) the absence of any vowel is indicated by the use of an “ADEG-ADEG” sign.
- Vowels are almost always indicated by one of a class of agglutinating signs (pangangge-suara) added above, below, before, or after the consonant or consonant cluster which they affect.
To initialize the work on document image analysis of palm leaf manuscripts, Kesiman et al. [10] have already built the AMADI_LontarSet5, the first handwritten Balinese palm leaf manuscript dataset. It includes three components of dataset as follows: binarized images ground truth dataset, word annotated images dataset, and isolated character annotated images dataset. In the isolated character annotated images dataset, there are 133 glyph classes which were collected as the glyph segment image collection. The study of isolated Balinese character recognition on palm leaf manuscript was also already done by Kesiman et al. [1].
The transliteration engine which is developed in this work is based on the need of a transliteration system to complete the OCR process of the palm leaf manuscript.
3 Knowledge Representation
3.1 Glyph Segment Image Collection
As already explained in the previous section, the transliteration engine which is proposed for this work is based on and is developed for the glyph segment image collection of the AMADI_LontarSet [10]. From the 133 classes of glyph segment image collection which were used in the isolated Balinese character recognition task [1], [10], some of them represent the consonant of the basic character of Balinese alphabet. In their base form, they will produce a speech sound of a syllable which will be ended with a vowel “A”.
For example, glyph “NA”, glyph “CA”, glyph “RA” .etc. Each of those consonant basic character glyph has their associate second glyph form (conjunct form6) which is normally called Gantungan or Gempelan, or with another specific glyph name. For example, glyph “GANTUNGAN NA” for glyph “NA”, glyph “GUWUNG” for glyph “RA”, glyph “GEMPELAN SA” for glyph “SA”. The Gantungan will be written under other consonant glyph, and the Gempelan will be written aside other consonant glyph. The conjunct form will be used when one consonant follows another without a vowel in between7.
These Gantungan and Gempelan will be used to annihilate the vowel “A” (the nucleus of the syllable) of their previous (upside or left side) written consonant glyph (Figure 2). For the reason of limited number of pages, Table 1 listed only 5 examples of the consonant of the basic character glyphs, their associate second glyph forms (conjunct form), speech sound, and their component of syllable (onset and nucleus) which were found in the glyph segment image collection. Interested reader can contact the authors of this paper to get the complete table. In some cases, it was found in the collection, the consonant of the basic character glyphs which were written in their cursive form (optional ligatures) with a glyph called “TEDONG”. For example, glyph “KA TEDONG” for glyph “KA”, glyph “MA TEDONG” for glyph “MA”, glyph “NA TEDONG” for glyph “NA” .etc.

Fig. 2 Consonant basic glyphs (from left to right: glyph “Na”, “NA TEDONG”, “GANTUNGAN NA”, “TA”, “TA TEDONG”, and “GANTUNGAN TA”)

But the speech sound of the consonant will not be changed. In addition to the basic glyphs, in the glyph segment image collection, there are also the compound glyphs. A compound glyph is actually a glyph segment which is composed by more than one basic glyph, but the glyph segmentation process cannot separate them. The collection of compound glyph can facilitate the OCR process to deal with the improper segmentation task. The compound glyphs produce a speech sound of a syllable which will be ended with a different vowel than vowel “A” or will be combined with other consonant (Figure 3). For the reason of limited number of pages, Table 2 listed only 5 examples of the consonant of the compound glyphs, their glyph components, and their component of syllable (onset, nucleus and coda) which were found in the glyph segment image collection. Interested reader can contact the authors of this paper to get the complete table.


The rest of the glyphs consist of the numeral glyphs, punctuation glyphs, the vowel glyphs and special consonant glyph which can be used to change the speech of sound of other basic or compound glyphs (see the examples in Figure 4 and Table 3).

Fig. 4 Vowel glyphs (from left to right: glyph “TALENG”, “TEDONG”, “ULU”, “SUKU”, “CECEK”, “PEPET”, “SURANG”)

3.2 Glyph Properties and Categorizations
Seven properties to categorize the glyphs were specifically defined based on the existing glyph segment image collection. Property “Id” defined the identity number of the glyphs. The value of “Id” ranges from 1 to 133. Property “Level1” defined the name of the glyphs. The name of the glyphs normally represents their speech sound. But for some glyphs, the name is totally different. Property “Level2” is categorized in six groups: CON for consonant, VOC for vocal, GAN for gantungan, GEM for gempelan, NUM for numeral, and PUN for punctuation. GAN groups all second glyph form (conjunct form) of consonant basic glyphs (see Table 1) which should be written as a descender of other glyph (below other glyph).
GEM groups all second glyph form (conjunct form) of consonant basic glyphs (see Table 1) which should be written aside (right side) of other glyph. A special consonant called “ADEG-ADEG” is also categorized as GEM because, if it is needed, it can also annihilate the vowel “A” (the nucleus of the syllable) of their previous glyph. VOC groups not only the vowel glyph on the Table 3. The special consonant glyphs were also categorized as VOC because they can change the speech sound of other consonant glyph. One special case is glyph “CECEK”. It has two functions, as a special consonant and as a punctuation. In this system, glyph “CECEK” is considered as special consonant so it has the property of VOC.
All other basic and compound consonant glyphs are considered as CON. Property “Level3” defined the spatial position of the glyphs related to the medial text line on the manuscript. It will be used to construct the phonological rules for all glyphs from OCR results. Six categories of spatial position for the glyph were defined (Figure 5). ASC (ascender) glyphs and DESC (descender) glyphs do not intersect the medial text line, ASC glyphs are written above the medial text line, and DESC glyphs are written below the medial text line. BASE glyphs are normally the basic glyph segments written exactly on the medial text line, while ASC-BASE glyphs and BASE-DESC glyphs are normally the compound glyph segments between a BASE glyph with an ASC glyph or with a DESC glyph. In the glyph collection, there is only one ASC-BASE-DESC glyph class which is called glyph “ADEG-ADEG”.

Property “StartSyllable” keeps the information of the onset of syllable for the consonant basic glyphs or the speech sound for the consonant compound glyphs, numeral, punctuation, and special consonant glyphs. Property “EndSyllable” keeps the information of the nucleus of syllable for the consonant basic glyphs (see Table 1).
Property “SplitSyllable” keeps the information of the onset, nucleus, and coda of syllable for the consonant compound glyphs (see Table 2). All information about glyph properties and categorizations are saved in a XML file and will be loaded on a list of glyph with a linked list pointer data structure.
4 Phonological Rules
The method of transliteration depends on the characteristics of the source and target languages [7]. Our model is based on phonetics which is based on traditional linguistic study of Balinese transliteration. Based on the glyph segment image collection, the glyph properties and categorizations, the conditional scheme of phonological rules for the transliteration of Balinese script were finally identified and formally defined.
The phonological rules defining the transliteration are provided and and are applied in sequential conditional checking order. The engine check all conditional phonological rules that might be applied to the given sequential glyph position and apply them in sequential order one by one. The OCR module for Balinese glyph recognition feeds the transliteration module with a sequential glyph data structure which is presented in Figure 6.
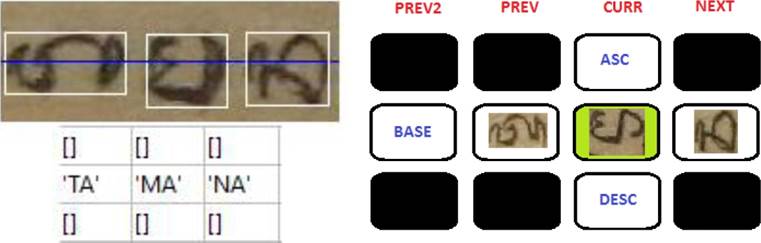
In Balinese script, the final speech sound for a syllable of a current (CURR) base (BASE) glyph will be determined by the ascender (ASC) of current glyph, the descender (DESC) of current glyph, the BASE of the NEXT glyph, the BASE of the previous (PREV) glyph, or even in some certain phonological rules, it can also be influenced by the BASE of the two previous (PREV2) glyphs.
The phonological rules for Balinese script transliteration should be finally built and be formally defined based on that OCR output data structure. Only a few examples of the phonological rules are described in this paper. Interested reader can contact the authors of this paper to get the complete rules.

For the example in Figure 6, when the transliteration engine proceeds the gylph “MA” as the CURR BASE glyph, RULE1 will be applied first, because glyph “MA” is a CON BASE type glyph. In this case, the transliteration engine will take first the STARTSYLLABLE of glyph “MA” as the speech sound output, which is “M”. The second rule which can be applied of this sequentiel glyph position for glyph “MA” is the RULE8.
RULE8 describes the concatenation of speech sound “A” with the last speech sound output, because the CURR BASE glyph does not have an ASC glyph and/or a DESC glyph. The PREV BASE glyph is not a glyph “TALENG” and the NEXT BASE glyph is not a glyph “ADEG-ADEG” or GEM type glyph. The final speech sound output will be “MA”. If all the same sequentiel rules can be applied to glyph “TA” on the left and glyph “NA” on the right of glyph “MA”, the final transliteration output will be “TAMANA”.
5 Experimental Results
To evaluate the correctness of phonological rules, the experiments of transliteration process for sample word segments of Balinese palm leaf manuscript were performed for all rules (see some examples in Table 4). Before the transliteration process, the OCR for Balinese script was performed.

6 Conclusions and Future Works
The knowledge representation and phonological rules for Balinese script which were presented in this paper already perform an effective and correct transliteration process. To improve the accuracy of OCR for Balinese script on palm leaf manuscripts, a lexicon-based statistical approach is needed. It should be useful to integrate the phonological rules in the OCR post correction step when the physical feature description is failed to do the recognition process. Our future interests are to build an optimal lexicon dataset for our system, in term of quantity and completeness of the dataset and to define an appropriate lexicon information (characters, syllables and words level) for Balinese script.

