











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
In recent years, there has been much work in machine translation keeping in mind the need of automatic tools to translate text in one language to the equivalent text in another language. As existing systems for Machine translation are not competent to the human translators, there is huge scope for improvement. Evaluating the performance of these systems is of key concern to their development.
One of the major issues in the performance evaluation of machine translation systems is that of measuring the quality of translated text. The problem of Machine Translation Evaluation is therefore central to the Machine translation systems.
The problem of machine translation evaluation is stated as the problem of evaluating how close the machine translation is to the human translations. Evaluating machine translations by humans is inherently slow and costly process. Considering the growth of machine translation research, tools for automatic MT evaluation are of prime concern to NLP and specifically to MT research.
There have been several attempts to design a metric for automatic MT Evaluation. The proposed metrics try to measure the similarity or semantic closeness between candidate machine translation and the actual reference translation. In (Papineni et al., 2002), a metric, BiLingual Evaluation Understudy (BLEU) based on n-gram matching is proposed. However, it does not take into account recall i.e. what fraction of reference translation the candidate translation covers. A variation of BLEU with frequency weights is proposed in (Babych and Hartley, 2004). It tries to improve BLEU by giving appropriate weights to different n-grams in the sentence which BLEU treats equally.
In (Culy and Riehemann, 2003) limitations of n-gram matching based methods are pointed out in general. The limitations apply to BLEU as well. Another metric, METEOR, proposed in (Banerjee and Lavie, 2005), tries to overcome some of the limitations of BLEU by taking into account precision and recall. It also uses fragmentation penalty to account for wrong word-order. It also incorporates three levels of matching n-grams viz. Exact, stem and WN Synonymy match. In (Lavie and Agarwal, 2007), the performance of METEOR is improved by refining the parameters for specific languages. (Lavie and Denkowski, 2009) discusses the development of METEOR.
MAXSIM proposed in (Chan and Ng, 2008), also uses POS information along with lemma and synonym information. It introduces the concept of Bipartite graph match to find the maximum matching based on Synonym match scores. It also suggests the use of dependency relations to improve the performance.
Most of the work with respect to MT Evaluation is done for Western languages. However, very little work is attempted for Indian languages. In (Aanthkrishnan et al., 2007), the author has pointed out the problems with BLEU in the evaluation of English- Hindi indicative translations. The paper also describes the divergences between English and Hindi causing BLEU to fail.
In (Chatterjee et al., 2007), the authors suggest the use of Word-Group Identification and word-group matching instead of n-gram matching as the way to improve the performance of BLEU in case of Hindi. The word-group refers to the sequence of words with fixed internal order. This takes care of free word order among the word-groups to some extent. However, they calculate the final score in the same way as does the METEOR.
Considering all these issues with the use of BLEU, METEOR in Hindi translation evaluations, we attempt to design the new metric for MT Evaluation especially for Hindi which we describe in the next section.
2 Framework of Evaluation Metric
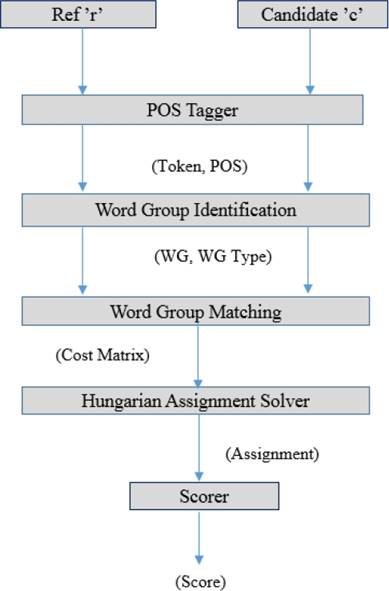
In the proposed metric, we attempt to make use of linguistic knowledge of Hindi at various levels. First, we tokenize both the reference and test sentences into words. The POS tags are obtained using standard Hindi POS tagger (IITB). Using this POS information we identify the word-groups as discussed in subsection 2.1.
We formulate the problem of evaluation as the minimum cost assignment on a bipartite graph where the two sets of nodes represent the word groups in reference and test translations.
The weights are assigned to edges between each node in one set to every other node in the other set of this bipartite graph so as to represent the semantic dissimilarity between the reference word group and the test word group.
Special nodes are added to make the no. of nodes in the two sets equal and the weights of edges associated with such nodes are set to 1. The weights are assigned as described in subsection 2b and 2c. The overall framework is described in Section 2 (this section). Each of the component of the framework is described in detail in the following sections.
2.1 Identification of Word Groups
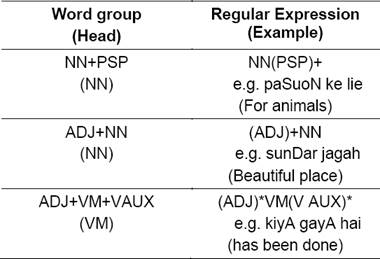
Our notion of word group is limited to the group of words having strict internal order.
This notion of word groups is described in (Chatterjee et al., 2007). In the current work, we identify the word groups based on the POS information. Specifically, we consider three different types of word groups viz. Noun-Post-positions, Adjective- Noun and Verb groups. Verb group includes just verbs, verbs with auxiliary verbs and verbs with associated adjectives. In the recent work (Gupta et al., 2010), METEOR is modified to handle Noun & Post-position group. However, we are dealing with a richer set of word groups. We use a simple FSM detecting simple regular expressions describing these word groups. Table 1 summarizes the different types of word groups along with their matching regular expressions, head part and representative example.
a. Matching Words
During word matching, we try to match the two given words at three different levels: Exact match, Lemma match, Synonym match and each such match receives a score depending on the type of match.
For finding Lemma and Synonym match we make use of Hindi WordNet (Jha et al., 2001). The two words are considered to be matched as synonyms if they have at least one common sense in the word net. For each of these levels we consider two sublevels: one where POS tags match and the other where they don’t match. The Table 2 shows the scores for each type of match.
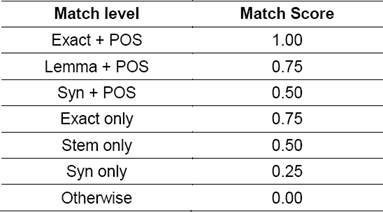
As shown in Table 2, we give increasing penalty as the level of match goes down. We give highest preference to exact match, then to Lemma match and then to Synonym match. Only POS matching doesn’t make sense when the words do not have exact, lemma or synonym match. However, there may be changes in POS tags of a word depending on its usage. So, we consider the three types of match without POS match by giving a little penalty (0.25).
b. Word Group Matching
To match word groups, we try to match each word of the word group with each word in the other group. We match the word group only if the head part of the word groups match at least at some level of word matching.
Also, the matching of head part carries more weight in the overall score assigned to word group.
Let wgr be the reference word group and wgt be a test word group. Let, wgr(i) be the ith word of wgr and wgr(j), be jth word of wgt Let, wgr(h) and wgt(h) be the head words of the two word groups. Then the match score of the two word groups is calculated as follows:
1. Each word in wgt , wgt(i) is matched with every word wgr(j) of wgr and a score (w(wgt(i); wgr(j)) is obtained. The word score for wgt(i) w.r.t wgr is given as:
 (1)
(1)
 (2)
(2)
where nt the no. of words in the word group W gt and α is decides the importance of head part in the word-group matching. Otherwise, Swg(wgt; wgr) is regarded as 0.
Swg(wgt; wgr) takes care of additive errors whereas Swg(wgt; wgr) takes care of deletion errors. The former will have smaller value when there are elements in wgt which don’t match with any of the elements in wgr, whereas the later one will have smaller value if there are elements in wgr which do not match with any of the elements in wgt.
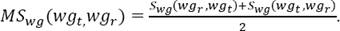 (3)
(3)
Averaging the two gives equal weight to the types of errors captured by each of them.
Note that Swg is asymmetric whereas MSwg is symmetric.
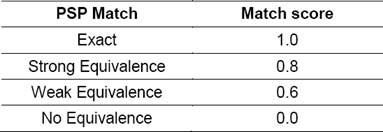
c. PSP Equivalence
Post-Positions play an important semantic role in Hindi. Some Post-positions are almost replaceable by each other. We call such post-positions as strongly equivalent. Similarly, some postpositions can sometimes be replaced by some other positions. These are called as weakly equivalent. So, a post-position Pi is either strongly equivalent, weakly equivalent or non-equivalent to other postposition Pj. This equivalence is not symmetric. We make use of this PSP equivalence information to add one more level of matching for NN+PSP word groups. The following Table 3 shows the scoring scheme for PSP matching.
To account for the PSP equivalence, we modify the step 2 in word-group matching as follows:
 (4)
(4)
Here Spsp(wgt(psp), wgr)is given according to Table 3 depending on whether wgr contains strongly equivalent, weakly equivalent or nonequivalent PSP for wgr(psp).
Table 4 shows the strongly equivalent and weakly equivalent Post positions for some of Hindi post positions. In Hindi, the postposition ke kAraN (meaning “because of”) is almost always replaceable by another postposition kI vajah se without affecting the meaning. However, it can be replaced by another postposition ke falswarup (meaning “as a result of”) in some of the situations but not all. Similarly, ko doesn’t have any strongly equivalent postposition but is weakly replaceable by ke lie.

d. MT Evaluation as Minimum Cost Assignment
As described in the beginning of section 2, we formulate the problem of MT Evaluation as the minimum cost assignment problem on a bipartite graph. The two sets of nodes represent the word groups in the reference and test sentences respectively. The weight assigned to the edge joining the reference word group wgr to the test word group wgt is given as:
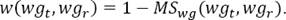 (5)
(5)
We solve the problem using Hungarian Assignment Solver. The final evaluation score of reference sentence t is obtained as:
 (6)
(6)
where
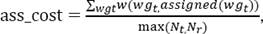 (7)
(7)
where assigned(wgr) represents the referenceword group wgr to which wgt is assigned in the minimum cost assignment by Hungarian solver and Nt, and Nr are the no. of nodes in the two sets of bipartite graph G(t, r) defined over.
e. Overall Penalty Factors
It is observed that whenever PSP part of Noun+PSP group in reference sentence is replaced by other non-equivalent PSP or is missing in the test sentence, the meaning of the sentence is affected and hence such sentences receive very low scores during human judgment even though the rest of the sentence considerably matches with the reference. To address this issue, we additionally penalize such test sentence by multiplying its evaluation score by overall penalty factor between 0 to 1. Currently, the overall penalty factor is set to 0.75.
3 Results
To understand how our metric evaluates a sentence, consider the cost matrix shown in Table 5 for a given pair of reference and test translations.
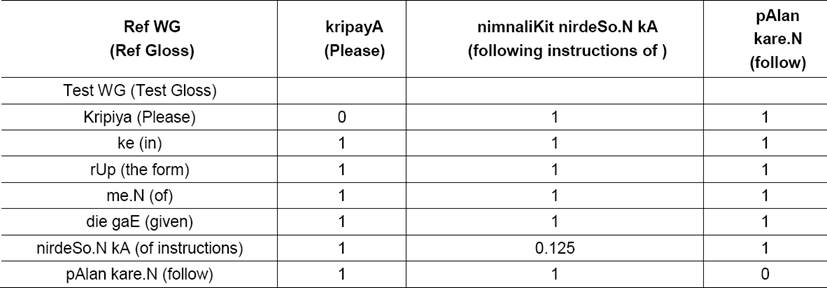
For the sake of simplicity, dummy nodes (added to make cardinality of two sets equal) are not included in the cost matrix as all entries corresponding to these nodes are 1. In Table 5, the columns correspond to Word-groups in reference translations whereas rows correspond to Word-groups in test translations. Note that, the entry for kripaya in ref WG and kripaya in testWG is 0 as they two match exactly. Similarly, the entry 0.125 captures the penalty for missing element nimnaliKit in the reference translation.
To test the performance of our metric, we arranged some English sentences, their test translations and reference human translations. We also obtained human evaluations for the gathered test translations. Subsection 3.1 describes the process of human evaluation in detail.
We test our metric through three different experiments. In the first experiment we use around 50 simple English sentences and their Hindi translations. The sentences were not pertaining to any specific domain. We obtained evaluation from three different native Hindi speakers. We also obtained the Hindi translations of these English sentences from a native Hindi speaker other than the three involved in the evaluation. These translations are treated as reference translations.
For the second experiment, we collected around 150 English sentences from various domains such as Parliament, Agriculture, Insurance, and Government along with their standard Hindi reference translations.
In both these experiments, we use test translations, Hindi translations of English sentences obtained from freely available Google Translate (Google, https://translate.google.com) English-Hindi translation engine. We use human translations of English sentences as reference translations for both of these experiments.
In the third experiment, we take some of the reference translations from second experiment and generate some test translations per reference translations. The sentences are generated by making certain kinds of changes in the reference translations. These changes include addition of words, deletion of words, replacement of a word by its morphological variation, replacement of a word by its synonymous word, valid word-reordering, invalid reordering, replacing PSP’s by its strongly equivalent, weakly equivalent and non-equivalent PSPs. We use these artificially generated sentences as test sentences. This experiment was aimed at analyzing the ability of the proposed metric to capture the typical errors in the machine translation systems.
3.1 Human Evaluation
We presented English sentence and their corresponding Hindi translation to human subjects and asked them to evaluate it on 5-point scale (0-4) as shown in Table 6. The reference translations used for automatic evaluation were kept hidden from the subjects. This ensures that the human judgment is not biased towards a single reference. We gathered such evaluations from three different subjects who are the native Hindi speakers.

The average score given by the subjects is considered as the overall human judgment.
a. Evaluation Results
We correlate the scores of the proposed metric with human scores. We also compare the results with METEOR with only exact match. Table 7, 8 displaying correlations1 and correlations2 with the summary of system level scores and correlations of the metric scores with human judgment for the two experiments we conducted.
Table 7 Exp. 1 Correlation Results: System level scores and Correlation with Human judgments for different metrics for Experiment 1
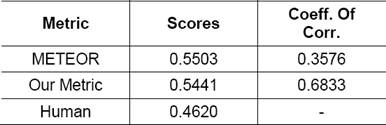
Table 8 Exp. 2 Correlation Results: System level scores and Correlation with Human judgments for different metrics
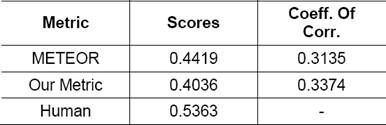
As shown by Table 7, the proposed new metric performs extremely Good. The correlation of this metric with human judgment is almost double the correlation of METEOR. However, as shown in Table 8, we get only marginal improvement over METEOR for complex set of sentences. As our metric is based on other sources of information like Hindi WordNet and POS Tagger, the success of metric largely depends on accuracy of these sources. Also, set of complex sentences include many technical terms which are transliterated during automatic translation but have appropriate Hindi translations in reference translation. Also, the sentences being complex their translations were not so good and mostly received low scores during Human judgments.
The results of the third experiment are shown in Table 9. The analysis of these results shows that the proposed metric is capable of differentiating between valid and invalid word orders in Hindi. METEOR penalizes both of them equally considering that both are equally invalid. However, the proposed metric penalizes only invalid reorder but favors the valid reorder by performing matching at word-group level. Also, our metric favors the translation when a post-position is substituted by another equivalent post-position. METEOR doesn’t take into account such equivalence at all though paraphrase matching is proposed (Lavie and Denkowski, 2010).
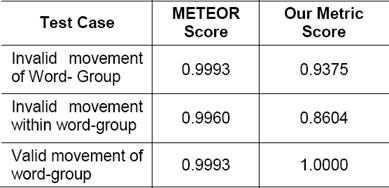
4 Conclusion and Future Work
We have attempted here to make use of linguistic knowledge at various levels for MT Evaluation with Hindi as target language. Specifically, the proposed metric uses the knowledge about Hindi through POS and Synonymy information, word group identification and PSP equivalence. We claim that use of such linguistic information in addition to statistical one helps in evaluating translations better by showing higher correlation of our metric with human judgments. Though the approach makes the metric language specific, the use of similar linguistic knowledge in other languages is expected to help the evaluating translations in that language. However, the form of knowledge that can be used may differ from language to language e.g. PSP equivalence which is useful for Hindi may not be useful for other languages. Though framing the problem of evaluation as minimum cost assignment problem makes it computationally slower, the complexity can be reduced by making use of some heuristics.
In the current work, we have not experimented with various parameters such as specific scores to be assigned and the specific weight to be given for matching head of the word-group. Also, the weight of the head is likely to change from word group to word-group. The weight for NN in NN+PSP may be different for weight for NN in ADJ+NN. As these scoring functions are crucial to the performance of our metric, experimenting with these parameters is the main focus of future work.
It would be nice to study how human evaluation process works and model the automatic process likewise. Such approach would definitely take MT Evaluation to the level of human evaluation. Also, we would like to extend the idea of MT evaluation to answer Church-Turing hypothesis where we want to distinguish whether a given test translation is human translated or automatically translated by a machine.

