











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. Introducción
El ruido en aeropuertos es una preocupación importante en las sociedades modernas. La extensión así como la cantidad de aeropuertos que están siendo construidos es cada vez mayor, con el fin de poder manejar el tráfico aéreo en crecimiento 1-3. En este sentido, mucho esfuerzo se ha realizado para abordar el problema del ruido. Las principales áreas donde se viene trabajando para lograr mejoras en el entorno acústico de los aeropuertos son la reducción en la fuente, la planificación y gestión del uso del suelo, los procedimientos operativos de reducción y las restricciones de operación 4.
La clave en relación con los esfuerzos anteriores es la identificación de un problema de ruido en el aeropuerto 4. En general existen dos técnicas para evaluar la situación sonora, que son medir o estimar los niveles de ruido en ubicaciones alrededor del aeropuerto. Por un lado, se han definido varios métodos para calcular las curvas de ruido alrededor de los aeropuertos 5-9. Una curva de ruido es una línea de valor constante que representa el promedio durante largos períodos de tiempo calculado con base en un día común en el año. Por otra parte, el monitoreo permanente del ruido y las operaciones de aeronaves en las proximidades de los aeropuertos se ha convertido en una práctica común 10-12. En estos casos, las señales registradas en cada evento se utilizan solamente para el cálculo de algunos indicadores estadísticos, tales como el nivel sonoro continuo equivalente.
La condición sonora de los puntos en tierra debido a las aeronaves que vuelan hacia y desde un aeropuerto depende de una serie de factores. Entre ellos, la clase de aeronave que usa el aeropuerto es el más importante, cuando se lleva a cabo una evaluación o acción en particular 4. Por ejemplo, todas las aeronaves que aterrizan o despegan del Ronald Regan National Airport después de las 9:59 pm y antes de las 7:00 am están sujetas a la regulación DCA Night-time Noise Rule impuesta por la Metropolitan Washington Airports Authority 13.
En este sentido y a fin de extraer mayor información de las señales registradas, se propone el reconocimiento de la clase de aeronave a partir de patrones del ruido en el despegue con base en la segmentación de las señales, así como la estimación de la trayectoria georreferenciada, añadiendo así potencialidad y robustez en el monitoreo y evaluación sin excluir la posibilidad de validación a partir de múltiples fuentes de información.
2. Reconocimiento de la clase de aeronave usando segmentación en tiempo
El espectro del ruido de las aeronaves cambia en amplitud y frecuencia durante un despegue debido a múltiples factores. La señal muestreada x(t) en un punto receptor puede ser definida de acuerdo a (1), donde Aij es la amplitud, wj, es la frecuencia y φj es la fase. La señal x(t) puede ser representada con matrices como se muestra en la Eq. (2), donde cada fila denota un lapso de tiempo disjunto mientras que cada columna define una componente de frecuencia como se muestra en la Eq. 1 y 2:
cualquier frecuencia puede o no estar presente si la amplitud relativa Aij es despreciable o no:
Cada operación de despegue produce una combinación única de parámetros Aij, wj y φj, debido a muchos factores como la atenuación atmosférica 14,15, el efecto Doppler y otras cuestiones inherentes al ruido de las aeronaves como el mecanismo de generación de ruido que tiene direccionalidad variable 16 y la atenuación lateral 17, 18. Una revisión completa está disponible en 19. Este fenómeno se ilustra en la Fig. usando espectrogramas. Las áreas azules denotan frecuencias despreciables mientras que las áreas rojas representan las significativas.
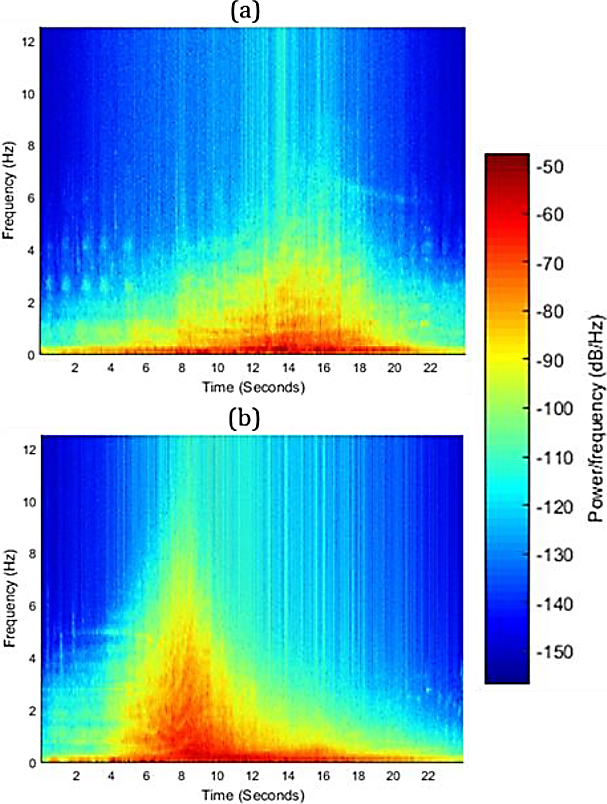
Fig. 1 Espectrograma de dos señales de ruido de aeronaves muestreadas a 25 kHz: (a) ATR 42-500, (b) Boeing 737-200
Más aún, la distribución en tiempo de las componentes de frecuencia es diferente en cada espectrograma.
Varios métodos han sido propuestos para identificar la clase de aeronave que despega usando rasgos del espectro de la señal 20-23.
Todos ellos usan la señal completa como entrada principal para la extracción de rasgos. Sin embargo, la señal del ruido de las aeronaves es un proceso no estacionario que conlleva a la variación del espectro durante el despegue. Por lo tanto, al usar la señal completa se pudiera enmascarar ciertos rasgos temporales que solo están presentes durante un corto período de tiempo durante el despegue. En esta sección se propone un modelo computacional para identificar las clases de aeronaves con base en la extracción selectiva de rasgos a partir de diferentes segmentos de la señal.
2.1. Segmentación de la señal en tiempo
La segmentación en el tiempo implica definir un punto común para todas las señales, a partir del cual se pueda extraer los segmentos. En esta sección, dicho punto es nombrado Tmid e intenta representar la posición de la aeronave respecto al punto de medición más cercana durante el despegue. Encontrar este punto no es un problema trivial ya que no se cuenta con información espacial. Varios métodos conocidos son evaluados con el objetivo de hallar Tmid, tales como el máximo de amplitud, el máximo de energía y el centro de masa 24. Todos generan resultados erróneos en un porcentaje significativo de las mediciones, lo que se discute a detalles en 19.
En esta sección se propone un algoritmo para estimar Tmid utilizando la energía y el cruce por cero, como se muestra en la Fig. 2.
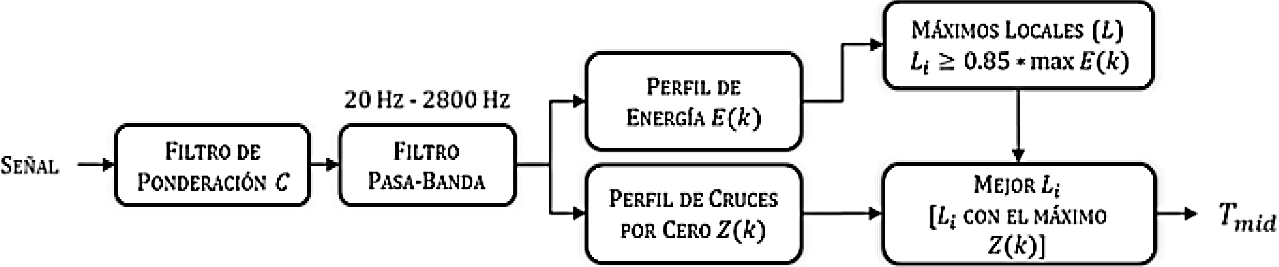
El punto Tmid es definido como el instante de tiempo correspondiente al máximo local, superior o igual al 0.85[ max E(q)] con el mayor valor Z(q), donde E(q) es el perfil de la energía calculado usando (3) y Z(q) es el perfil de cruce de ceros obtenido mediante la Eq. (4 y 5):
donde q denota un fragmento de la señal y(x), SE representa que la longitud del fragmento q, N denota la longitud de la señal, sign [ ] simboliza el operador signo,
En esta sección se usan los siguientes valores: SE = 200 ms,
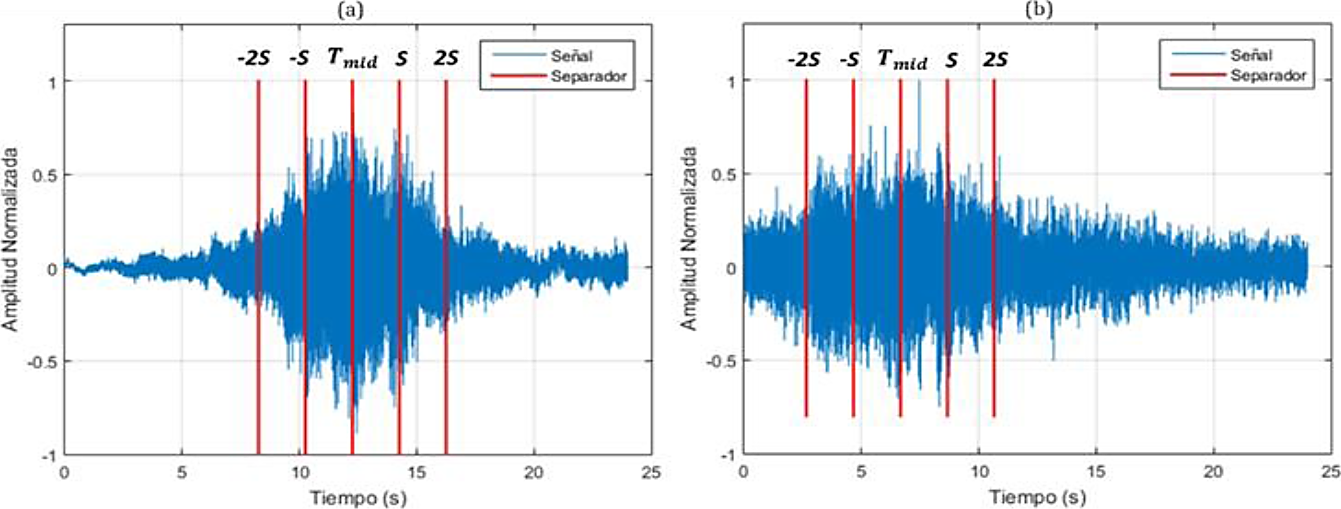
La ubicación de los segmentos se determina de la siguiente manera: si el número de segmentos (Nf) es par, se seleccionan Nf/2 segmentos del mismo tamaño a cada lado de Tmid, si Nf es impar, entonces se seleccionan (Nf - 1)/2 + 1 segmentos delante de Tmid y (Nf - 1)/2 detrás de Tmid. La Fig. 3 muestra las ubicaciones de cuatro segmentos extraídos para dos señales diferentes.
2.2. Extracción de rasgos
Dado que la frecuencia de muestreo es de 25 kHz, el rango espectral es 12 kHz (Fs/2). Además, como la longitud de los segmentos es de 2s, se tienen 50000 muestras en cada segmento. Consecuentemente, la precisión espectral es de 0.5 (Fs/N) y la longitud del espectro es 25000 puntos. A fin de hacer la clasificación computacionalmente aceptable, se debe realizar una reducción dimensional.
Los coeficientes LPC se obtienen mediante el análisis de predicción lineal 25. En general, estos coeficientes se utilizan para describir el tracto vocal como un filtro IIR (Respuesta Infinita al Impulso). Este filtro puede ser descrito usando la Eq. (6):
Las técnicas que usan coeficientes LPC están fuertemente relacionadas con la idea de un codificador de voz mediante la simulación del tracto vocal humano 26-28. Sin embargo, estos también han sido usados para representar la envolvente del espectro de frecuencia de una señal y lograr una reducción dimensional del mismo 21, 22. El procedimiento de selección de rasgos hasta la obtención de los conjuntos de patrones X1, X2, X3 y X4 se muestra en la Fig. 4, (Refiérase a 19 para más detalles).
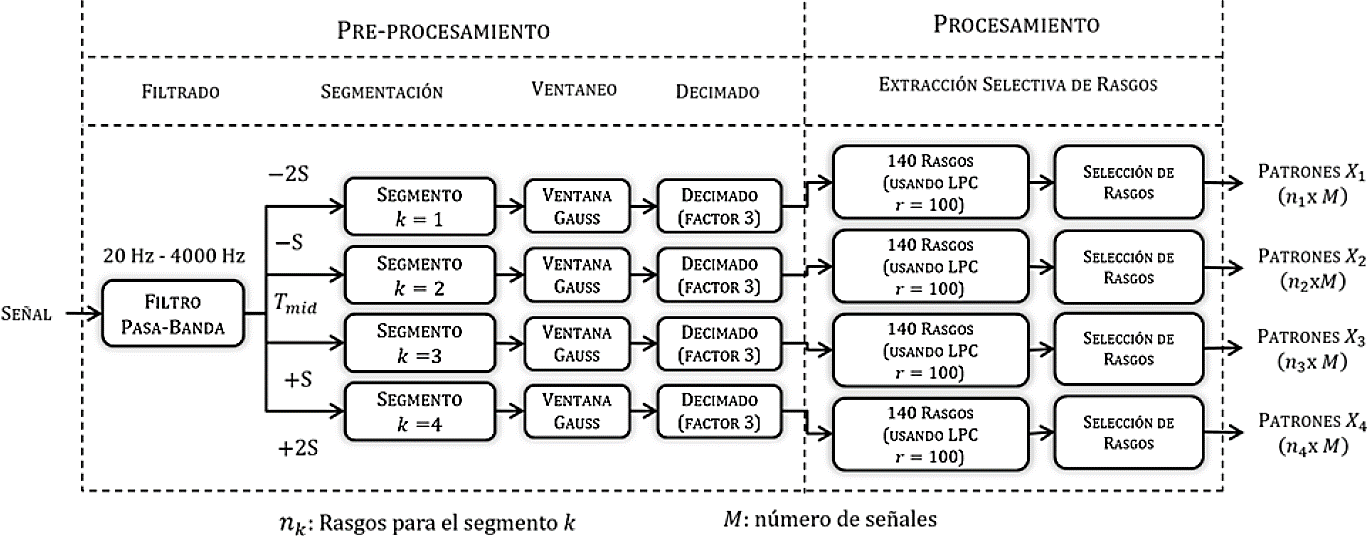
Con el objetivo de mejorar la clasificación es necesario qué rasgos son redundantes o irrelevantes. En esta sección se utiliza el método de selección de rasgos para redes neuronales MLP propuesto por 29. Este utiliza un criterio
El criterio
En esta sección, se aplica el método de selección de rasgos MLP-FSPP-RFE para cada segmento. En una iteración, la red neuronal correspondiente al segmento analizado se entrena 10 veces y se pone a prueba con 39 patrones (3 para cada clase), obteniéndose así el error de prueba. La red con el error de prueba más bajo se selecciona para calcular
Tabla 1 Clases y Distribución de Patrones entre Conjuntos de Entrenamiento, Validación y Prueba
| Clases de aeronave (Etiqueta en el modelo) | Conjuntos de patrones Entrenamiento/ Validación/ Prueba |
|---|---|
| A320 1 (A320 1) | 08/03/2005 |
| A320 2 (A320 2) | 08/03/2006 |
| A320 3 (A320 3) | 08/03/2006 |
| A320, B737-800 (A320_B737-800) | 08/03/2007 |
| ATR-42 (ATR-42) | 08/03/2003 |
| B737-100, B737-200 (B737-1/200) | 08/03/2011 |
| B737-600, B737-700 (B737-6/700) | 08/03/2009 |
| B747-400 (B747-400) | 08/03/2004 |
| F100 (F100) | 08/03/2006 |
| F100 2 (F100 2) | 08/03/2006 |
| F100, B737-200 (F100 B737-200) | 08/03/2003 |
| F100, B737-200 2 (F100 B737-200 2) | 08/03/2004 |
| MD87, MD88 (MD) | 08/03/2009 |
| TOTAL | 104/39/79 |
2.3. Modelo computacional
Dado que cada red neuronal genera una salida, se necesita un modelo que tome ventaja de estas múltiples respuestas. En esta sección se propone un nuevo modelo computacional que mejora la clasificación por medio de cuatro redes neuronales con diferentes rangos de acuerdo a su desempeño, las cuales interactúan como en un sistema de votación. La Fig. 5 muestra la topología del modelo computacional.
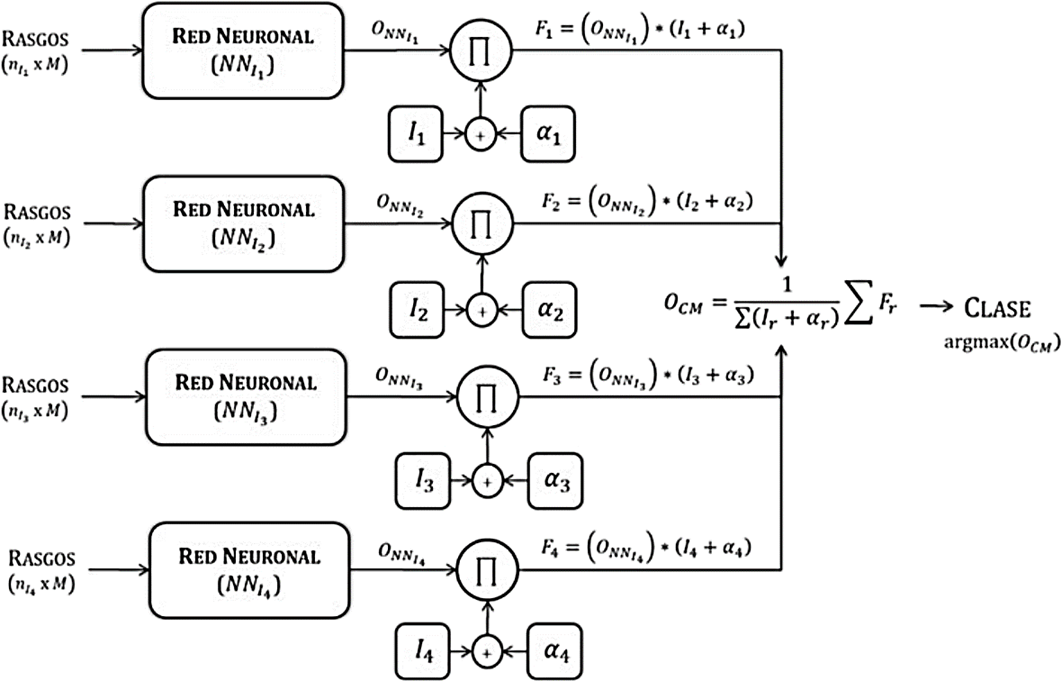
Cada red neuronal tiene un rango Ir∈{1,2,3,4}, relacionado con su
rendimiento durante el entrenamiento y calculado con (7). El subíndice
r no está asociada con el número del segmento y cada rango
Ir debe cumplir con (8), de
modo que
Cada salida
Además, los valores a3 y a4 se actualizan de acuerdo a las siguientes reglas:
cuando ar ≠ 0, lo que se busca es aumentar la importancia de la salidas de la red
2.4. Resultados y discusión
La base de datos introducida en 22, es usada para entrenar las redes neuronales y probar el modelo computacional. Por lo tanto, se utilizaron 143 señales para entrenamiento y 79 para prueba. En resumen, el modelo propuesto en esta sección se desempeña mejor que los modelos existentes, reduciendo el número de errores del 9/79 a 4/79. Esta mejora está relacionada fundamentalmente con dos factores. En primer lugar, el proceso de selección de rasgos mejora el desempeño individual de la red neuronal de cada segmento. En segundo lugar, el modelo se beneficia de múltiples respuestas. Ambos factores son posibles debido a la segmentación de la señal que se propone en esta sección, la cual permite extraer información relevante de la frecuencia con respecto al tiempo, lo cual no se había realizado, incluso para el seguimiento continuo de la similitud del ruido de entrada y los sonidos de las aeronaves 30.
Además, se realizaron mediciones en cuatro días distintos con el fin de probar el modelo computacional en tiempo real. En total, 83 mediciones de despegue se clasificaron en tiempo real bajo diferentes condiciones climáticas (con excepción de lluvia) y diversos ruidos ambientales, como aves, aeronaves rodando, ladridos, entre otros. La efectividad mínima obtenida es del 85%, al menos un 5% superior a la reportada en 22.
3. Agregación jerárquica dinámica de salidas paralelas
El modelo propuesto en la sección anterior demuestra que la extracción de rasgos de segmentos adyacentes de la señal de ruido en el despegue aumenta el porcentaje de reconocimiento que al usar toda la señal. La motivación para la segmentación surge de considerar el ruido de las aeronaves en el despegue como un proceso no estacionario con espectro dinámico. El objetivo es dividir la señal en K segmentos con características espectrales diferentes. En este sentido, el modelo propuesto en la Sección 2.3 utiliza una red NNk por cada segmento k y rasgos basados en los LPC.
Por otra parte, en 23, se evalúan
concurrentemente rasgos extraídos a partir de los MFCC y bandas de 1/24 de octava
evaluados por dos redes paralelas. En ambos modelos se define un algoritmo de
agregación para ponderar las múltiples salidas producidas por las redes. En la
Sección 2 la agregación se basa en una ponderación dinámica de la salida
Por otra parte, la agregación propuesta en 23 se realiza con base en la suma ponderada
Además,
En esta sección se define un modelo para la identificación de la clase p con base en la agregación jerárquica dinámica de las salidas
3.1. Definición analítica del modelo de la sección 2
El modelo de la Sección 2 propone una red NNk para cada segmento de señal k.
Dicho modelo propone la ponderación jerárquica dinámica de las salidas
3.2. Modelo propuesto
En el algoritmo de agregación anterior las salidas
Más aún, el rendimiento de las redes neuronales NNk| k = 1, 2,..., K no se adhiere necesariamente a (16):
en este sentido, cuando la red neuronal NNk tiene un buen rendimiento con respecto a la clase p pero pobre rendimiento en relación a la clase p + n, es decir,
3.2.1. Método de agregación
En esta sección, se propone una agregación con base en una jerarquía específica de las redes
NNk| k =
1, 2,..., K por cada clase p. La etiqueta
prevista para una entrada {x1,…,
xK}, se calcula por medio
de (17) y (18). La matriz de criterios de ordenamiento R =
[P × K], establece el rango de las
redes neuronales NNk |
k = 1,2,..., K, con respecto a todas
las clases p. El vector
R(p) representa la fila
p de la matriz R y contiene todos los
rangos de las redes neuronales
NNk| k =
1,2, ..., K con respecto a los pesos
Por lo tanto, la componente R(p,k), indica el
rango de la red neuronal NNk
con respecto a la clase p de modo que un valor más alto
indica una mayor importancia. La expresión
considerando R(p) = [1,2,...,
K] y
R(p+n) = [K,
K - 1, …, 1] esto implica que la red neuronal
NNk=1 es la de menor rango
con respecto a la clase p dado que
R(p, 1)=
1 (peso
Sin embargo, dado
En este sentido, la matriz de confusión Ck = [P × P] dada en (23) representa el desempeño de la red neuronal NNk durante la etapa de validación e incluye verdaderos positivos
Dado que
En este sentido, en esta sección se propone calcular

Fig. 6 Relación de la exhaustividad η(p, k), precisión ϕ(p, k) y la métrica Fβ con respecto a tres valores diferentes de β
Cuando β = 1, la exhaustividad η(p, k) y la precisión φ(p, k) tienen influencia similar sobre la métrica Fβ tal como se muestra en la Figura 6b. Sin embargo, cuando β = 0.1, la métrica Fβ depende principalmente de la precisión φ(p, k), ya que cualquier variación de η(p, k) solo produce un ligero cambio en la métrica Fβ como se ilustra en la Fig. 6a. Lo opuesto sucede cuando se usa β = 10 como se demuestra en la Fig. 6c.
En consecuencia, ahora la jerarquía de las redes neuronales
NNk |
k = 1,2, ..., K con respecto a la
clase p se define no solo con base en
η(p, k) sino también
con base en φ(p, k). De
acuerdo con (26 y 28), los pesos
Por otra parte, la agregación dinámica propuesta en (17) Eq. (17) está relacionada con la función f(k,p) que depende del factor
Dado que
3.2.2. Arquitectura del modelo
Cada patrón de entrada xk es un vector correspondiente al segmento k con J - rk rasgos, donde J denota el número de rasgos inicialmente extraídos y rk el número de rasgos eliminados después de un proceso de selección de rasgos. La red neuronal NNk devuelve un vector
3.2.3. Extracción de rasgos
El proceso de extracción de rasgos aplicado se divide en tareas de pre-procesamiento y procesamiento con base en aquel propuesto en la Sección 2.2. Luego, se definen las entradas xk para ser evaluadas por las redes neuronales NNk I k = 1,2,..., K.
La Fig. 7 representa la respuesta en frecuencia del filtro IIR respecto al segmento k = 1 de una señal de un B737-200. Además en dicha figura se muestra la FFT del segmento k = 1. Similar a lo propuesto en el Sección 2.2, se seleccionan los primeros 140 puntos de los 256 disponibles, lo cual cubre frecuencias hasta 2278 Hz. La Fig. 7 confirma la estrecha relación entre los rasgos basados en los LPC y el espectro de la señal de ruido del segmento k = 1.
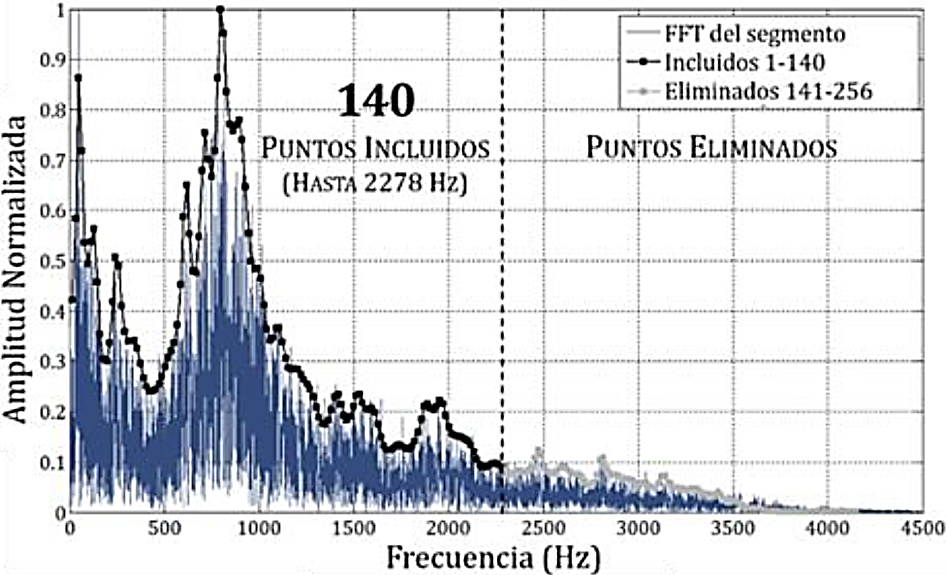
Fig. 7 Respuesta en frecuencia del filtro IIR obtenida a partir de los coeficientes a ⃗ para el primer segmento de la señal del ruido en el despegue de un Boeing 737-200
El siguiente paso es la selección de rasgos lo cual implica la eliminación de aquellos redundantes o irrelevantes. Para ello se utiliza el método para redes neuronales MLP propuesto por 29, el cual se describe en la Sección 2.2. El método calcula la importancia del rasgo jth usando un criterio de ordenamiento
El criterio orden
3.3. Experimentos
En esta sección se utiliza la misma base de datos usada en la Sección 2 para evaluar el rendimiento del nuevo modelo propuesto en esta sección contra el propuesto en la Sección 2.3. En total se usan P = 13 clases.
Ya que el mismo número de segmentos es usado (K = 4) para ambos casos, las mismas redes neuronales (topología y pesos) se utilizan para los experimentos en esta sección con el fin de comparar ambos modelos con respecto al algoritmo de agregación. Sin embargo, el modelo propuesto en esta sección también es aplicable a cualquier otro conjunto de K redes neuronales paralelas.
La Tabla 2 muestra las topologías de las redes neuronales resultantes de la Sección 2. Estas topologías se determinaron después de la aplicación del algoritmo de selección de rasgos descrito en la misma. Las salidas
Tabla 2 Topología de la red neuronal NNk
| k | Topología de NNk (Neuronas por capa) | nk |
|---|---|---|
| 1 | 95-30-13 | 45 |
| 2 | 140-30-13 | 0 |
| 3 | 95-30-13 | 45 |
| 4 | 85-30-13 | 55 |
En esta sección varios valores de β fueron evaluados a fin de analizar experimentalmente la contribución de la precisión φ(p, k) y la exhaustividad η(p, k) respecto a la salida final. Para este caso en particular, un mejor rendimiento se obtiene generalmente al usar valores que cumplen con β < 1. Esto refuerza la motivación para el cálculo de los pesos
La Tabla 3 muestra los pesos
Tabla 3 Pesos
| p / k | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 1 | 0.1976 | 0.0535 | 0.0682 | 0.9802 |
| 2 | 0.3699 | 0.7370 | 0.4925 | 0.4225 |
| 3 | 0.4925 | 0.7370 | 0.2693 | 0.6535 |
| 4 | 0.7370 | 0.7370 | 0.9612 | 0.3936 |
| 5 | 0.4925 | 0.5905 | 0.6535 | 0.7370 |
| 6 | 0.4225 | 0.5905 | 0.3289 | 0.4925 |
| 7 | 0.5905 | 0.9612 | 0.4225 | 0.1060 |
| 8 | 0.0341 | 0.1647 | 0.0848 | 0.0309 |
| 9 | 0.7370 | 0.9612 | 0.9802 | 0.9612 |
| 10 | 0.0267 | 0.0449 | 0.0848 | 0.9802 |
| 11 | 0.5905 | 0.4913 | 0.4225 | 0.7370 |
| 12 | 0.3267 | 0.6535 | 0.3284 | 0.1795 |
| 13 | 0.7370 | 0.7370 | 0.7370 | 0.7370 |
Haciendo referencia a la Tabla 3, el peso de la red
NN2 con respecto a la clase p =
2 es
Por otro lado, la matriz R que se da en (31) se construye a partir de los
pesos que se presentan en la Tabla 3 y
refleja los rangos de las redes NNk
| k = 1,2,..., K con respecto a la clase
p = 1,2, ..., P. En este sentido, la
matriz R muestra que la red de mayor rango
Por otra parte, la red NN4 es la de mayor rango con respecto a la clase p = 1 = (R(1,4) = 4) pero la segunda de menor rango con respecto a la clase p = 2 (R(2,4) = 2).
En relación con la dinámica introducida en el nuevo modelo por medio de (17) y (18), el término
Similarmente, j = 1 cumple con = j l R(p,j) - 1 dado que R(p,k) = 3 y R(1,4) -1 = 3. En consecuencia, si las redes neuronales NN3 y NN1 coinciden, es decir,
La Tabla 4 presenta las salidas
Tabla 4 Salidas del modelo con respecto a una medición de la clase B737-600/700
| p | Etiqueta de Clases |
|
|
|
|
Modelo de la Sección 2.3
a
|
Modelo introducido en esta sección
b
|
|---|---|---|---|---|---|---|---|
| 1 | MD | 0.0733 | 0.0678 | 0.0665 | 0.0684 | 0.0687 | 0.0690 |
| 2 | F100_B737-200 2 | 0.0740 | 0.0676 | 0.0665 | 0.0685 | 0.0689 | 0.0685 |
| 3 | F100_B737-200 | 0.0733 | 0.0676 | 0.1670 | 0.1280 | 0.1100 | 0.0980 |
| 4 | F100 2 | 0.0733 | 0.0734 | 0.0924 | 0.1170 | 0.0878 | 0.0858 |
| 5 | F100 | 0.1160 | 0.0676 | 0.0665 | 0.0712 | 0.0787 | 0.0765 |
| 6 | ATR-42 | 0.0739 | 0.0676 | 0.0665 | 0.0684 | 0.0688 | 0.0689 |
| 7 | A320_B737-800 | 0.0733 | 0.0676 | 0.0665 | 0.0684 | 0.0687 | 0.0690 |
| 8 | A320 3 | 0.0768 | 0.0676 | 0.0665 | 0.0684 | 0.0695 | 0.0684 |
| 9 | A320 2 | 0.0733 | 0.0676 | 0.0665 | 0.0684 | 0.0687 | 0.0683 |
| 10 | A320 1 | 0.0733 | 0.0677 | 0.0665 | 0.0684 | 0.0687 | 0.0683 |
| 11 | B747-400 | 0.0733 | 0.0676 | 0.0718 | 0.0684 | 0.0702 | 0.0702 |
| 12 | B737-6/700 | 0.0733 | 0.1830 | 0.0706 | 0.0684 | 0.1030 | 0.1230 |
| 13 | B737-1/200 | 0.0733 | 0.0676 | 0.0665 | 0.0684 | 0.0687 | 0.0686 |
a El modelo será referido de aquí en adelante como Modelo ESW
b El modelo será referido de aquí en adelante como Nuevo Modelo
Respecto al Modelo ESWA, las salidas
Las clases p = 3, p = 4, p = 5 y p = 12 son las más relevantes en el ejemplo de la Tabla 4; la última de ellas es la clase objetivo a identificar. Respecto a la clase p = 5, las salidas
Respecto a la clase p = 4, las salidas
Respecto a la clase objetivo p = 12, solamente la salida
3.4. Resultados y discusión
Con base en los extensos experimentos con la base de datos de mediciones del ruido en el
despegue, el modelo propuesto en este sección (Nuevo Modelo)
mejora el reconocimiento de clases de aeronaves con los modelos existentes en la
literatura y aquel introducido en la Sección 2.3. La comparación global entre el
Nuevo Modelo y el Modelo ESWA se presenta
en la Fig. 8. Ambos modelos dependen de la
agregación de las salidas

El mejor rendimiento del Nuevo Modelo está estrechamente relacionado con la capacidad de cambiar la dinámica de agregación con respecto a cada clase p, es decir, la agregación de las salidas
Además, dada las redes neuronales NNk y
NNk+m | m Є ℤ
- {0} ∧ 1≤ k + m ≤ K entonces
se cumple que
Otro factor que contribuye al mejor desempeño del Nuevo Modelo es la función f(p, k) introducida en la Sección 3.2.1. La función f(p, k) devuelve un factor único
Más aún, el factor
Además, dado que la arquitectura propuesta para el Nuevo Modelo se basa en
decisión por comité, el resultado final es alcanzado por un conjunto de redes
neuronales NNk | k
= 1,2,..., K en lugar de un clasificador único. En
consecuencia, si un clasificador falla pero las salidas de los otros coinciden,
aún es posible obtener una salida final correcta. Esto depende del desempeño de
las redes NNk | k
= 1,2,..., K y de la agregación de las salidas
Por otra parte, dado que cada segmento de señal k sólo es analizado por la red NNk, las alteraciones encontradas durante el tiempo cubierto por el segmento de señal k, sólo puede afectar al rendimiento de NNk y no aquel de la red NNk+m | m Є ℤ - {0} ∧ 1≤ k + m ≤ K, es decir, cualquier otra red. Algunas perturbaciones tales como perros ladrando, personas hablando o gritando, canto de pájaros y claxon de autos, están presentes en las mediciones obtenidas del ruido en el despegue.
Sin embargo, en la mayoría de los casos sólo algunas de las características de los segmentos de señal en los extremos (k = 1 y k = 4) se ven afectados debido a que dichas perturbaciones no son efectivas, en general, a lo largo del espectro completo de la señal del ruido en el despegue, lo cual no deteriora por completo el desempeño de la red neuronal correspondiente.
Además, de acuerdo con la segmentación de la señal descrita en la Sección 2.1, los segmentos interiores (k = 2 y k = 3) están siempre más cerca del punto de mayor amplitud como se muestra en la Fig. 3, donde es poco probable que se enmascarare la señal del ruido de los aviones por su gran intensidad durante dicha etapa en el despegue. En consecuencia, dichos segmentos y las redes asociadas (NN2 y NN3), se ven menos afectadas por perturbaciones tales como las mencionadas anteriormente.
4. Modelo multicapa neuro-difuso
En la Secciones 2 y 3, se utiliza una red neuronal NNk para cada segmento k (véase (19, 31)) mientras que en 23 se usan dos redes paralelas para evaluar dos tipos diferentes de rasgos extraídos de la misma señal. En todos los casos se establece un algoritmo de agregación para construir la respuesta final a partir de las múltiples salidas producidas por todas las redes neuronales. El algoritmo de agregación es muy importante ya que involucra la ponderación de múltiples respuestas sobre el mismo espacio de clases p = 1,2,..., P incluyendo las salidas erróneas. Hasta ahora los algoritmos propuestos anteriormente sólo permiten ponderar cada clase p individualmente, por lo que las relaciones entre las salidas
4.1. Arquitectura multicapa neuro-difusa
Los sistemas híbridos que combinan redes neuronales y lógica difusa han demostrado su eficacia en una amplia variedad de problemas reales 32-34. Los 140-nk rasgos iniciales extraídos como se presenta en la Sección 2.2 son básicamente una reducción dimensional del espectro de la señal del ruido en el despegue, donde nk se determina a partir del método de selección de rasgos descrito en la misma sección. Sin embargo, todavía es complicado derivar de manera sencilla, un mapeo directo entre los rasgos del segmento k y las clases. Por tanto, una red NNk para cada k Є {1,2,..., K} es utilizada para pre-procesar los 140 - nk rasgos y transformarlos al espacio RP, donde P es el número de clases. La transformación anterior representa cuán relacionada está la entrada xk con cada clase p Є {1,2,..., P}, con base en los patrones de entrada que se usan durante el entrenamiento supervisado de las redes.
La salida
donde
En general, las salidas
Las condiciones anteriores indican que la red neuronal NNk clasifica totalmente la entrada xk como clase y, es decir, NNk no detecta similitud alguna con respecto a las clases y'. Bajo una buena generalización NNk normalmente devuelve salidas que no cumplen con una o ambas condiciones. Más aún, las salidas
La agregación descrita en la Sección 4 se lleva a cabo con base en la ponderación independiente de K salidas para la clase y, es decir, ∀k Є {1,2,..., K},
El algoritmo de agregación propuesto en la Sección III-B-1 permite cambiar dinámicamente el
peso
En este caso, f(k, p) devuelve un factor
Por lo tanto, las asociaciones entre y e y' no están modeladas bajo coincidencia parcial, lo que podría llevarse a cabo con base en la cuantificación del valor de verdad de
De acuerdo a lo anterior, se propone una arquitectura neuro-difusa. El modelo calcula el valor de membresía cp a la clase p Є {1,2, ...,P} con base en un sistema de inferencia difuso del tipo Mamdani (FIS). Las entradas
La salida difusa Zp | p = 1,2,
..., P representa el grado de membresía a la clase
p. Cinco valores lingüísticos son definidos para cada
salida difusa (Muy Baja, Baja, Media, Alta y Muy
Alta). Después, las relaciones entre entradas difusas
Las reglas de agregación conllevan a un conjunto difuso Reglas rendimientos de agregación a un conjunto Cp con respecto a la clase p, el cual es defuzificado con base el método del centroide, obteniendo el valor real de membresía cp. A continuación, la etiqueta y predicha para una entrada {x1, …,xK} está dada por (36):
La nueva arquitectura permite la combinación de cualquier número i = 1,2, K × P de entradas difusas con el fin de representar el conocimiento con base en la inferencia difusa mediante reglas. La integración de múltiples salidas
1. Jerarquía y ponderación individual de clases:
SI
La membresía difusa a una clase Zp será alta si la entrada difusa
Por otra parte, sólo las reglas que tengan Zp como consecuente afectarán a la salida respecto a la clase p. Si una regla tiene un consecuente compuesto que consiste de R > 1 salidas difusas, entonces dicha regla pudiera ser descompuesta en R reglas con el mismo antecedente y sólo una salida difusa Zp.
2. Ponderación de la "concordancia de respuestas":
SI
La membresía difusa a una clase Zp va a ser muy alta si las salidas de las redes neuronales NNk, NNk+1 y NNk+2 concuerdan regresando valores altos respecto a la clase p.
3. Anular clasificaciones erróneas individuales:
SI
Suponiendo que la red neuronal NNk+1 encuentra
cierta correlación entre la clase p y p +
n con respecto a la entrada
xk+1, que en realidad
pertenece a la clase p la regla anterior explota el hecho anterior combinando
Además, el nuevo modelo introduce un enfoque flexible para cambiar la salida final respecto a la clase p con base en la generación de conocimiento a través de la adición o supresión de reglas o el ajuste de las funciones de membresía, sin volver a calcular los pesos o reentrenar las redes neuronales.
4.2. Experimentos
Extensos experimentos se llevan a cabo con dos bases de datos con mediciones reales del ruido en el despegue. Una descripción general de ambas bases de datos se da en la Tabla XI. Los experimentos incluyen lo siguiente: 1) dividir la señal del despegue en segmentos; 2) extraer los rasgos; 3) aplicar el algoritmo de selección de rasgos; 4) entrenar y evaluar las redes neuronales; 5) definir las funciones de membresía para las entradas y salidas difusas; 6) crear las reglas de inferencia; y 7) evaluar el desempeño del modelo neuro-difuso. Más información de estos experimentos se puede encontrar en 35.
Los experimentos descritos en la Sección 4.2.2 se utilizan para comparar el desempeño del modelo propuesto y aquellos definidos en 19, 22, 23 usando ambas bases de datos de la Tabla 5. Los experimentos de la Sección 4.2.2 utilizan una nueva base de datos más compleja y actualizada, estrictamente construida a partir de mediciones en tiempo real y usando varias fuentes para verificar el horario del despegue, el tipo de aeronave y motor de avión.
Tabla 5 Descripción de las bases de datos
| Nombre a | Mediciones | P | Introducida por |
|---|---|---|---|
| BD Anterior | 305 | 13 | Sánchez-Fernández et al. 22, Sección 2 |
| BD Nueva | 426 | 13 | Sección 4.2.2 |
a Los nombres serán usados a partir de aquí para referirse a las BD
4.2.1. Experimentos con la BD anterior
Las mismas redes neuronales (topología y pesos) obtenidas en la Sección 2 se utilizan para los experimentos descritos en esta sección a fin de comparar ambos métodos solo con respecto al algoritmo de agregación. La Tabla 2 muestra la topología de las redes anteriormente referidas.
Cada salida
En esta sección
Del mismo modo, las salidas difusas Zp están
etiquetadas de acuerdo a Clase + Etiqueta Corta de
Clase de Aeronave de modo que la salida correspondiente a la
clase ATR-42 se etiqueta como Clase ATR-42. Del mismo modo,
la definición de los conjuntos difusos
En este sección
Se utiliza un sistema disyuntivo de reglas SI-ENTONCES. Las reglas se derivan aprendiendo por ejemplos; es decir, identificando relaciones entre las entradas difusas
1. ∀(a, b, c) | a, b, c Є {1,2,..., K}, a ≠ b ≠ c;
SI
2. ∀(a, b, c) | a, b, c Є {1,2,..., K}, a ≠ b ≠ c;
SI
Dado que K = 4, 2P[K!/(3! (K - 3)!)] = 104 reglas se crean con base en los criterios anteriores. Después, el sistema de inferencia difuso se mejora mediante la adición de siete reglas más. Tres de estas reglas están relacionadas con la Clase A320 1:
Regla 105: SI A320 1 NN4 es Alta Y A320_B737-800 NN4 no es Baja Y A320 3 NN4 no es Baja ENTONCES Clase A320 1 es Alta.
Regla 106: SI A320 1 NN2 es Alta ENTONCES Clase A320 1 no es Baja.
Regla 109: SI A320 1 NN1 no es Baja ENTONCES Clase A320 1 no es Baja.
La agregación de reglas resulta en un conjunto difuso Cp representado por
La contribución individual de la regla r con respecto a Zp está determinada por la fuerza de disparo de la regla r y la función de membresía
El valor de membrecía final cp se calcula utilizando (55). La Fig. 9 presenta la agregación de reglas para una medición correspondiente a la Clase A320 1:
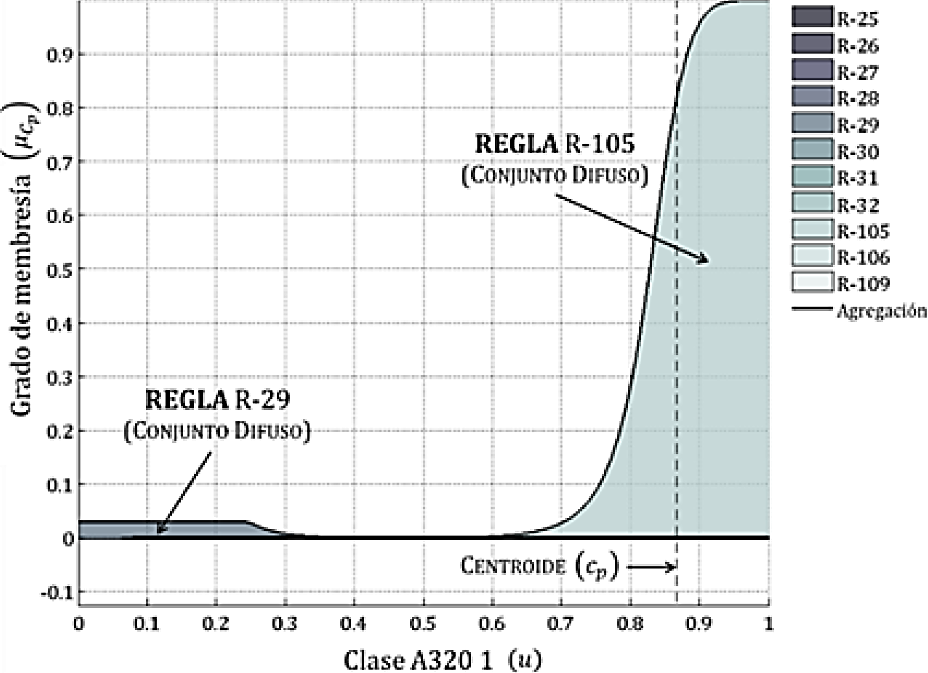
La contribución resaltada de la Regla 105 es mayor que la contribución de otras reglas y produce el valor real más alto de membrecía como se muestra en la Tabla 6.
Tabla 6 Salidas del Modelo con respecto a una Medición de la Clase A320 1
| p | Modelo propuesto en este sección a | Modelo propuesto en el 19 b | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Etiqueta |
|
|
|
|
Final (Cp) |
|
|
|
|
Final (Cp) | ||
| Etiqueta | - | - | - | - | 0.897 | 0.950 | 0.949 | 0.846 | ||||
| 1 | Clase MD | 3.77E-09 | 5.87E-08 | 6.38E-05 | 3.9E-14 | 0.0774 | 0.0689 | 0.068 | 0.0676 | 0.0551 | 0.0654 | |
| 2 | Clase F100_B737-200 2 | 0.000404 | 0.000676 | 2.94E-07 | 2.07E-06 | 0.0774 | 0.0689 | 0.0681 | 0.0676 | 0.0551 | 0.0654 | |
| 3 | Clase F100_B737-200 | 0.000166 | 0.000527 | 9.86E-05 | 1.02E-10 | 0.0774 | 0.0689 | 0.068 | 0.0676 | 0.0551 | 0.0654 | |
| 4 | Clase F100 2 | 0.00232 | 2.38E-07 | 5.18E-06 | 0.00866 | 0.0774 | 0.0691 | 0.068 | 0.0676 | 0.0556 | 0.0655 | |
| 5 | Clase F100 | 4.68E-12 | 1.11E-15 | 1.36E-06 | 0.00014 | 0.0774 | 0.0689 | 0.068 | 0.0676 | 0.0551 | 0.0654 | |
| 6 | Clase ATR-42 | 0.0727 | 0.00135 | 2.02E-12 | 0 | 0.0774 | 0.0741 | 0.0681 | 0.0676 | 0.0551 | 0.0666 | |
| 7 | Clase A320_B737-800 | 0.00587 | 0.753 | 0.0275 | 0.996 | 0.5 | 0.0693 | 0.144 | 0.0695 | 0.149 | 0.107 | |
| 8 | Clase A320 3 | 2.85E-05 | 0.124 | 1 | 0.998 | 0.564 | 0.0689 | 0.077 | 0.184 | 0.149 | 0.121 | |
| 9 | Clase A320 2 | 1.89E-05 | 0.000873 | 0.038 | 2.87E-13 | 0.0774 | 0.0689 | 0.0681 | 0.0702 | 0.0551 | 0.0662 | |
| 10 | Clase A320 1 | 0.00814 | 0.368 | 2.42E-07 | 0.999 | 0.866 | 0.0695 | 0.0983 | 0.0676 | 0.15 | 0.0939 | |
| 11 | Clase B747-400 | 0.874 | 0.000266 | 0.00438 | 2.21E-12 | 0.0774 | 0.165 | 0.068 | 0.0679 | 0.0551 | 0.0868 | |
| 12 | Clase B737-6/700 | 0.0217 | 0.000113 | 0.00204 | 1.66E-05 | 0.0774 | 0.0704 | 0.068 | 0.0677 | 0.0551 | 0.0658 | |
| 13 | Clase B737-1/200 | 2.91E-10 | 5.26E-07 | 8.77E-09 | 0 | 0.0774 | 0.0689 | 0.068 | 0.0676 | 0.0551 | 0.0654 | |
a El modelo será referido de aquí en adelante como Nuevo Modelo
b El modelo será referido de aquí en adelante como Modelo ESWA
La Tabla 6 muestra los resultados después de aplicar ambos modelos, el propuesto en este sección (Nuevo Modelo) y aquel presentado en 19 (Modelo ESWA) para una medición perteneciente a la Clase A320 1 (p = 10). La Fig. 9 también destaca la contribución individual de la siguiente regla:
1. Regla 29: SI A320 1 NN1 es Baja Y A320 1 NN2 es Baja Y A320 1 NN3 es Baja ENTONCES Clase A320 1 es Muy Baja.
Sin embargo, dados los conjuntos difusos
La Tabla 7 muestra una comparación general entre los modelos existentes y el nuevo modelo con respecto a la BD Anterior. Se evalúan un total de 162 mediciones. El Nuevo Modelo clasifica correctamente el 90.7% de estas.
Tabla 7 Comparación general contra modelos existentes
| p | Total | Clasificaciones correctas | |||
|---|---|---|---|---|---|
| Modelo en 22 | Modelo en 23 | Modelo ESWA 19 | Nuevo Modelo 35 | ||
| 1 | 12 | 10 | 10 | 10 | 12 |
| 2 | 15 | 13 | 14 | 14 | 14 |
| 3 | 14 | 10 | 11 | 11 | 12 |
| 4 | 17 | 15 | 14 | 16 | 16 |
| 5 | 7 | 6 | 6 | 7 | 7 |
| 6 | 18 | 15 | 15 | 15 | 16 |
| 7 | 17 | 13 | 13 | 13 | 16 |
| 8 | 9 | 7 | 7 | 7 | 7 |
| 9 | 13 | 11 | 11 | 11 | 11 |
| 10 | 10 | 9 | 10 | 10 | 10 |
| 11 | 6 | 3 | 3 | 3 | 3 |
| 12 | 8 | 6 | 6 | 6 | 8 |
| 13 | 16 | 12 | 15 | 15 | 15 |
| TOTAL (%) | 162 (100%) | 130 (80%) | 135 (83.3%) | 138 (85.2%) | 147 (90.7%) |
4.2.2. Experimentos con la BD Nueva
La nueva base de datos utilizada en esta sección contiene mediciones del ruido en el despegue de aeronaves modernas actualmente en servicio. Un sistema de adquisición de datos similar al propuesto en 38 se utiliza para registrar el ruido de en el despegue durante 24 segundos a una frecuencia de muestreo de 51.2 kHz. Refiérase a 35 para más detalles.
Con el fin de identificar detalladamente el modelo de las aeronaves despegando, las autoridades aeroportuarias suministraron una lista completa de los despegues realizados durante el período de mediciones de cinco días diferentes. La lista incluye entre otras cosas: hora exacta del despegue, línea aérea, etiqueta corta del modelo (A320, AT42, B737, etc.), etiqueta única de registro (identifica plenamente la aeronave, por ejemplo, N833UA), y el número de vuelo.
Varias bases de datos, especificaciones de los fabricantes y páginas web de aerolíneas fueron revisadas para identificar con precisión el modelo de la aeronave 39-41. Los resultados de la búsqueda en las bases de datos realizadas con base en la información provista por el aeropuerto se cotejaron con las observaciones en sitio durante las mediciones (hora del despegue, identificación visual del modelo de la aeronave y aerolínea así como el número de la medición). Las clases de aeronaves se definen con base en el modelo del fuselaje, el tipo de motor y las clases acústicas introducidas en 9, 42. Por lo tanto, las clases que aparecen aquí son muy específicas. La Tabla 8 muestra la descripción de la BD Nueva.
Tabla 8 Descripción de la nueva base de datos
| p | Clase de Aeronave Modelo del Fuselaje (Tipo de Motor) | Total | Conjuntos Entrenamiento/ Validación/ Prueba |
|---|---|---|---|
| 1 | SU95 (SaM 146) | 26 | 15/4/7 |
| 2 | ERJ190 (CF34-10E) | 36 | 15/4/17 |
| 3 | ERJ170/175 (CF34-8E) | 32 | 15/4/13 |
| 4 | ERJ145(AE3007) | 37 | 15/4/18 |
| 5 | B737-7xx (CF56-7B22-) | 38 | 15/4/19 |
| 6 | B737-8xx (CF56-7B22+) | 39 | 15/4/20 |
| 7 | B737-3xx (CFM56-3) | 32 | 15/4/13 |
| 8 | ATR72-600 (PW127M) | 28 | 15/4/9 |
| 9 | ATR42-500 (PW127E) | 30 | 15/4/11 |
| 10 | ATR42-300 (PW120) | 25 | 15/4/6 |
| 11 | A319-1xx (V25xx) | 28 | 15/4/9 |
| 12 | A320-2xx (V25xx) | 34 | 15/4/15 |
| 13 | A320-2xx (CFM56-5) | 41 | 15/4/22 |
| TOTAL | 426 | 195/52/179 |
Cuatro segmentos de señal (K = 4) se extraen de cada medición siguiendo el método descrito en la Sección 2.1, mientras que los 140 rasgos iniciales son definidos para cada segmento de acuerdo con la Sección 2.2. Una red neuronal NNk con topología 140-m-13 se define para el segmento k. El número de neuronas ocultas m se determina con base en un proceso de validación cruzada por diez sobre el espacio {5, 10,15,...,60}. El número m con el promedio de error de prueba más bajo entre diez realizaciones es elegido. Posteriormente, el método de selección de rasgos descrito en la Sección 4.2.2 es aplicado a cada segmento k. El análisis y resultados del método anterior puede consultarse en 35. La Tabla 9 presenta las topologías de las redes resultantes de la aplicación del método MLP-FSPP-RFE.
Tabla 9 Topología de la Red Neurona NNk
| k | Topología de NNk (Neuronas por capa) | nk |
|---|---|---|
| 1 | 85-30-13 | 55 |
| 2 | 90-30-13 | 50 |
| 3 | 110-30-13 | 30 |
| 4 | 130-30-13 | 10 |
Cada salida
1. ∀(a, b, c) | a, b, c Є {1,2,..., K}, a ≠ b ≠ c;
SI
2. ∀(a, b, c) | a, b, c Є {1,2,..., K}, a ≠ b ≠ c;
SI
3. ∀(a, b, c) | a, b, Є {1,2,..., K}, a ≠ b ;
SI
Con base en los tipos de reglas anteriores y dado que K = 4, P{2[K!/(3!( K - 3)!)] + K!/(2! (K -2)!)} = 182 reglas son generadas. Posteriormente, se incluyen 23 reglas más para mejorar el sistema de inferencia difusa. La Tabla 10 presenta las salidas de ambos modelos con respecto a una medición de la Clase ATR42-500 (PW127E) (Respecto al Modelo ESWA, la importancia de la red NNk se recalcula con base en los nuevos entrenamientos). Tres clases son relevantes en la medición anterior: ATR72-600 (PW127M) (p = 8), ATR42-500 (PW127E) (p = 9), y ATR42-300 (PW120) (p = 10).
Tabla 10 Salidas del Modelo con respecto a una Medición de la Clase ATR42-500 (PW127E)
| p | Nuevo Modelo | Modelo ESWA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
Final (Cp) |
|
|
|
|
Final(Cp) | |
| - | - | - | - | 0.500 | 0.654 | 0.558 | 0.519 | |||
| 1 | 1.26E-07 | 1.14E-11 | 3.5E-13 | 1.66E-06 | 0.0774 | 0.0702 | 0.0695 | 0.0749 | 0.0664 | 0.0696 |
| 2 | 5.87E-05 | 0.112 | 6.83E-09 | 2.5E-06 | 0.271 | 0.0702 | 0.0777 | 0.0749 | 0.0664 | 0.0713 |
| 3 | 0.00311 | 4.53E-06 | 0.0324 | 3.04E-08 | 0.0774 | 0.0705 | 0.0695 | 0.0773 | 0.0664 | 0.07 |
| 4 | 4.03E-05 | 4.47E-07 | 9.36E-11 | 7.14E-10 | 0.0774 | 0.0702 | 0.0695 | 0.0749 | 0.0664 | 0.0696 |
| 5 | 0.284 | 0.0882 | 5.97E-05 | 1.36E-05 | 0.0824 | 0.0933 | 0.076 | 0.0749 | 0.0664 | 0.0781 |
| 6 | 0.336 | 6.09E-10 | 2.01E-05 | 0.547 | 0.439 | 0.0983 | 0.0695 | 0.0749 | 0.115 | 0.0938 |
| 7 | 1.2E-07 | 2.58E-12 | 2.26E-10 | 5.81E-10 | 0.0774 | 0.0702 | 0.0695 | 0.0749 | 0.0664 | 0.0696 |
| 8 | 0.343 | 0.011 | 0.212 | 0.845 | 0.129 | 0.099 | 0.0703 | 0.0925 | 0.155 | 0.11 |
| 9 | 1.41E-05 | 3.86E-06 | 4.82E-05 | 5.78E-05 | 0.528 | 0.0702 | 0.0695 | 0.0749 | 0.0664 | 0.0696 |
| 10 | 0.0919 | 0.767 | 0.0509 | 3.98E-05 | 0.0829 | 0.077 | 0.15 | 0.0788 | 0.0664 | 0.0895 |
| 11 | 2.53E-06 | 1.45E-09 | 1.99E-08 | 7.1E-05 | 0.0774 | 0.0702 | 0.0695 | 0.0749 | 0.0664 | 0.0696 |
| 12 | 0.000315 | 7.63E-07 | 2.29E-13 | 3.69E-05 | 0.0774 | 0.0703 | 0.0695 | 0.0749 | 0.0664 | 0.0696 |
| 13 | 5.64E-06 | 0.00514 | 0.0377 | 5.44E-08 | 0.0774 | 0.0702 | 0.0699 | 0.0777 | 0.0664 | 0.0701 |
Las redes neuronales regresan principalmente valores no despreciables para dos de estas clases p = 8 y p = 10. Como se muestra en la comparación técnica de la Tabla 11 43-45, las clases p = [8,9,10] están muy correlacionadas entre sí.
Tabla 11 Comparación técnica entre p = [8,9,10]
| p | Aeronave | Modelo del motor | Longitud | Extensión de las alas |
|---|---|---|---|---|
| 8 | ATR72-600 | PW 127M | 27.17 m | 27.05 m |
| 9 | ATR42-500 | PW 127E/M | 22.67 m | 24.57 m |
| 10 | ATR42-300 | PW 120/1 | 22.67 m | 24.57 m |
Dicha correlación produce incertidumbre entre las salidas
La comparación global de ambos modelos con respecto a la BD Nueva se
muestra en la Tabla 12. Se evaluaron
un total de 179 mediciones, de las cuales el 87,2% son clasificadas
correctamente por el Nuevo Modelo. El mejor desempeño del
modelo propuesto está estrechamente relacionado con la capacidad de cambiar
el resultado final respecto a la clase p con base en
cualquier salida
5. Conclusiones
Mediante la segmentación de la señal en el tiempo se logra identificar una disimilitud apreciable entre los espectros de cada segmento, confirmando que el ruido de las aeronaves en el despegue es un proceso no estacionario, que varía tanto en amplitud como en frecuencia. Además, se demuestra que la identificación de la clase de aeronave a partir de un modelo que combine los patrones extraídos por cada segmento es superior al uso de los patrones extraídos de la señal completa.
Dichos modelos con K clasificadores paralelos, uno por segmento k = 1,2,..., K, generan múltiples salidas
Asimismo, se introduce un modelo multicapa neuro-difuso que permite decidir sobre la clase p no solamente con base en las salidas
Más detalles de la metodología y resultados obtenidos en este trabajo pueden ser consultados en 19, 22, 23, 31, 35, 38.

